基于XGBoost算法的光伏陣列故障診斷方法研究
2023-02-09 06:43:28段震清孫建民李庚達崔青汝
太陽能 2023年1期
段震清,孫建民,梁 凌,李庚達,崔青汝,伍 權
(國家能源集團新能源技術研究院有限公司,北京 102209)
0 引言
由于地面光伏電站長期運行在野外惡劣環境中,且規模較大,隨著其服役年限增加,光伏陣列的故障發生率逐漸升高。一旦光伏陣列發生故障,若不及時發現并處理,將會進一步釀成惡性事故。因此,快速有效地識別出光伏電站直流端的故障對提升其系統效率和降低維護成本具有重要的意義[1]。
文獻[2-3]通過分析光伏方陣的I-V電氣參數曲線與參考電氣曲線之間的差異得出故障診斷結果,但該方法需要光伏陣列離線進行掃描,無法實現在線實時診斷與分析。文獻[4-5]通過建立光伏陣列數學模型,計算出光伏陣列的理論輸出功率,并與光伏陣列實際輸出功率進行比較,進而實現光伏陣列故障診斷,但該方法的準確度依賴于模型的精度。文獻[6-7]采用紅外圖像法,通過檢測光伏組件在不同運行狀態下對應的溫度實現故障診斷,但紅外圖像易受外界影響,導致故障診斷會出現誤差。文獻[8]提出基于局部離群因子方法對光伏陣列是否發生異常進行檢測,但該方法無法進一步判斷出光伏陣列的故障類型。事實上,由于光伏陣列易受外界復雜環境的影響,導致其故障類型具有復雜性和耦合性,現有的故障診斷技術和方法難以滿足光伏電站現場運行過程中診斷的需要。因此,快速有效地對光伏陣列進行實時在線故障診斷有待進一步完善與發展。
針對上述問題,本文提出了一種基于極度梯度提升(XGBoost)算法的光伏陣列故障診斷方法,首先建立光伏陣列仿真模型,通過分析正常、短路、開路、老化、陰影遮擋這5種光伏陣列運行狀態的特性,提取出表征故障的特征變量;然后基于實驗仿真數據構建XGBoost故障診斷模型;最后將5種光伏組件運行狀態下的特征參數輸入故障診斷模型,對故障模式進行識別與診斷驗證。此外,XGBoost故障診斷模型會輸出重要特征的排序,重要特征可以更好地識別光伏陣列故障類型。
本文所提到的數據處理、故障診斷模型及解釋歸因功能,將基于web系統以功能模塊的方式嵌入部署在光伏電站生產管理大區(I區)的服務器監控系統上,基于I區服務器監控系統采集到光伏陣列數據,經數據處理、故障診斷等模塊計算后,實現對光伏陣列的在線故障診斷,并及時發送故障報警,以便盡快實施故障維護。
XGBoost故障診斷模型工程化部署至現場的具體工作方式及流程為:首先,基于現場光伏陣列歷史運行數據,經數據預處理后,離線構建XGBoost故障診斷模型,并將訓練好的模型部署在現場;其次,基于I區服務器監控系統實時采集光伏陣列數據,傳輸至數據預處理模塊,經數據清洗、特征處理后輸入XGBoost故障診斷模型;最后,故障診斷模塊根據光伏陣列的輸出功率及氣象信息,每天定時進行計算,以分析是否產生故障及故障類型;此外,通過XGBoost故障診斷模型重要性分析對導致光伏陣列產生故障的因素做解釋歸因。
1 光伏陣列典型故障的仿真和分析
1.1 建立光伏陣列仿真模型
以實際運行的光伏陣列的電氣數據和氣象環境數據為依據,主要對光伏陣列正常、短路、開路、老化、陰影遮擋這5種運行狀態進行研究。為了得到不同條件下的數據樣本,通過Matlab Simulink仿真技術建立光伏陣列仿真模型,以獲取其不同運行狀態下的數據[9-10]。
該光伏陣列仿真模型共有3串光伏組串,每串光伏組串由5個封裝好的模塊組成,每個模塊內包含4塊光伏組件,即每串光伏組串有20塊光伏組件。光伏陣列仿真模型如圖1所示。圖中:T1為給定的環境溫度特征變量;S1為給定的太陽輻照度特征變量;I為光伏陣列輸出電流;U為光伏陣列輸出電壓;P為光伏陣列輸出功率。
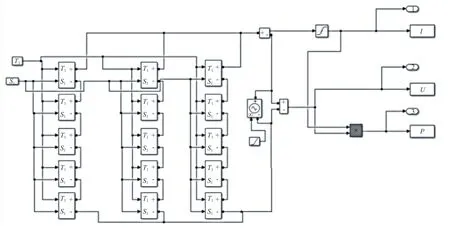
圖1 光伏陣列仿真模型Fig. 1 Simulation model of PV array
搭建的光伏陣列仿真模型僅需根據光伏組件廠家提供的標準銘牌參數,就能在一定精度范圍內還原光伏陣列在不同環境及運行狀態下的輸出特性。單塊光伏組件的標準銘牌參數如表1所示。
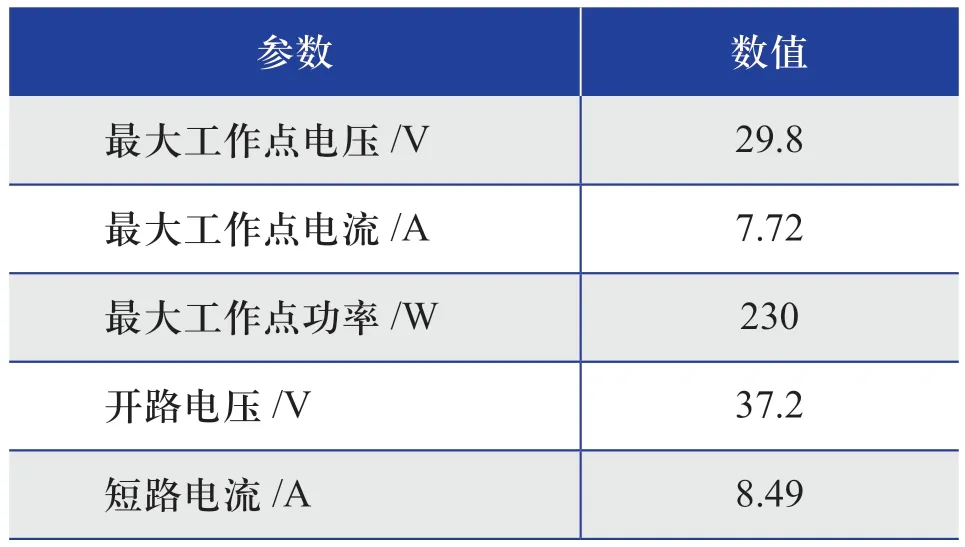
表1 單塊光伏組件的標準銘牌參數Table 1 Standard nameplate parameters of single PV module
本研究在太陽輻照度R為100~1000 W/m2、環境溫度T為5~35 ℃范圍內進行測量,采集5種運行狀態下光伏陣列的電氣參數和氣象環境參數。
1.2 故障特征提取
特征變量之間具有交互作用,很難直接發現特征數據和故障之間的相關聯系,當故障診斷模型中的特征變量之間存在多重共線性時,樣本數據特征變量的選擇不同將會導致預測結果的顯著變化,進而會出現誤判、漏判光伏陣列故障的現象。
本文使用皮爾森相關系數計算特征變量之間的相關性,當相關系數大于0.8時,認為兩個特征變量高度線性相關,將在兩個特征變量中舍去1個[11]。特征變量的共線性分析結果如圖2所示。圖中:Impp為光伏陣列的最大工作點電流;Umpp為光伏陣列的最大工作點電壓;Pmpp為光伏陣列的最大工作點功率;Uoc為光伏陣列的開路電壓;Isc為光伏陣列的短路電流。
根據圖2的分析結果,本研究去除了太陽輻照度、光伏陣列的短路電流、光伏陣列的最大工作點功率這幾個特征變量,最終保留環境溫度、光伏陣列的開路電壓、光伏陣列的最大工作點電流、光伏陣列的最大工作點電壓作為故障診斷模型的輸入特征。
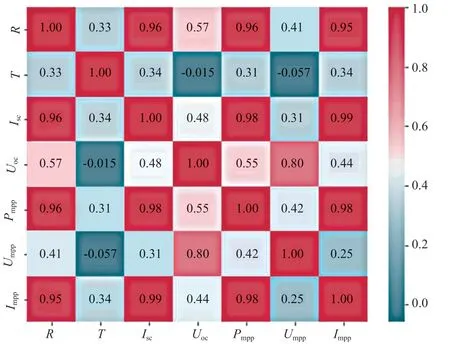
圖2 特征變量的共線性分析結果Fig. 2 Results of collinearity analysis of characteristic variables
1.3 故障特征數據分布
本研究使用的特征變量均為連續變量。觀察特征變量的特征數據分布情況[12],其中,環境溫度、光伏陣列的最大工作點電流和光伏陣列的最大工作點電壓均屬于正態分布,使用均值(mean)和標準差(standard deviation,SD)來描述特征數據分布情況;光伏陣列的開路電壓為非正態分布,使用中值(median)和四分位數([Q1, Q3])來描述不滿足正態分布的特征數據分布情況。光伏陣列不同運行狀態下特征變量的統計描述如表2所示。
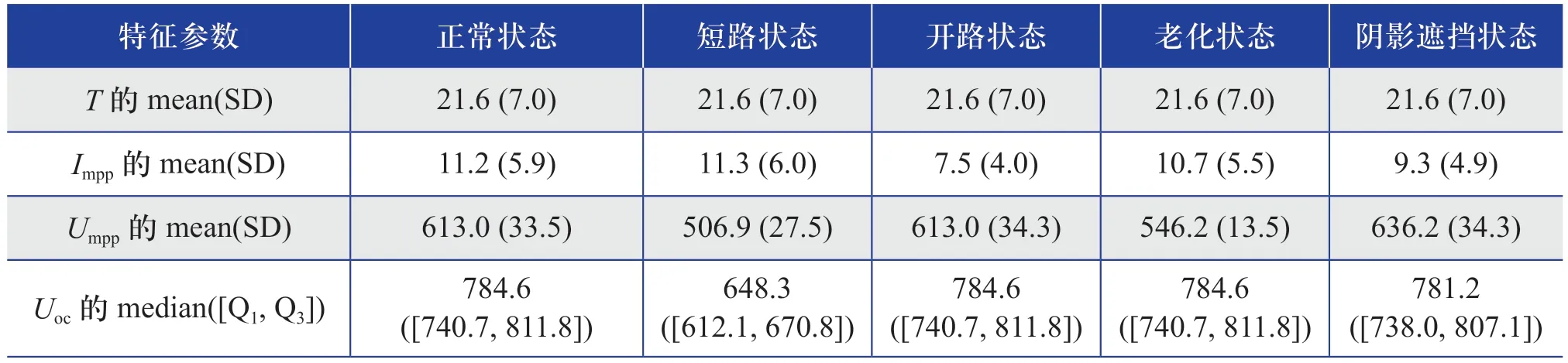
表2 光伏陣列不同運行狀態下特征變量的統計描述Table 2 Statistical description of characteristic variables of PV array under different operating conditions
2 基于XGBoost算法的光伏陣列故障診斷方法
2.1 XGBoost故障診斷模型原理
XGBoost算法可對樣本數據進行智能檢測與識別,該算法把若干分類器整合為1個分類器,通過不斷對誤差進行進一步分類來解決一般機器學習算法泛化能力差、過擬合、準確率不高等問題,因此,十分適用于光伏陣列故障診斷樣本數據少的情況。
XGBoost算法由華盛頓大學博士陳天奇于2014年提出,主要用于分類分析(處理離散數據)和回歸樹分析(處理連續數據),是一種集成式學習模型[13]。XGBoost算法要求每加入1棵樹,均使目標函數結果最小。
目標函數包含損失函數L和正則函數Ω兩項,損失函數用來計算預測結果和真實結果的誤差,實際計算中基于最小誤差對損失函數進行約束;正則函數用于檢測模型的復雜度,避免出現過擬合或欠擬合[14]。正則函數和損失函數可以根據實際情況具體給定。
目標函數Obj(k)可表示為:
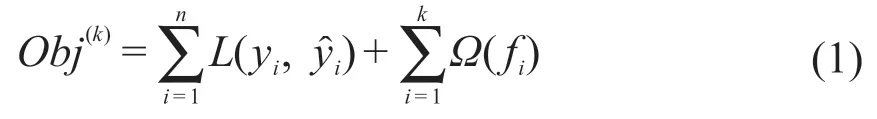
式中:i為第i個樣本;n為樣本總數;k為訓練樣本時的第k棵樹(即預測中的迭代次數);yi為第i個樣本的真實標簽;為第i個樣本的預測標簽;fi為第i個樣本在增加k棵樹時相比k-1棵樹時的誤差。
對于正則函數的第k棵樹,具體可表示為:

增加第k棵樹后,相比第k-1棵樹的誤差值可表示為:

式中:ωq(xi)為第i個樣本落在第k棵樹的第q(xi)個葉子節點所得分數。
第k棵樹的正則函數Ω(fk)可表示為:

式中:τ為1棵樹上的葉子總數;j為第j個葉子;ωj為第j個葉子的得分值;γ和λ均為防止過擬合參數。
將式(1)~式(4)合并,并使用二階泰勒公式,把對于樣本的歷遍轉換成對葉子節點的歷遍,目標函數變形為式(5),即:
式中:gi為第j個葉子節點里面的一階梯度;hi為第j個葉子節點里面的二階梯度;Ij為每個葉子節點里面的樣本集合。
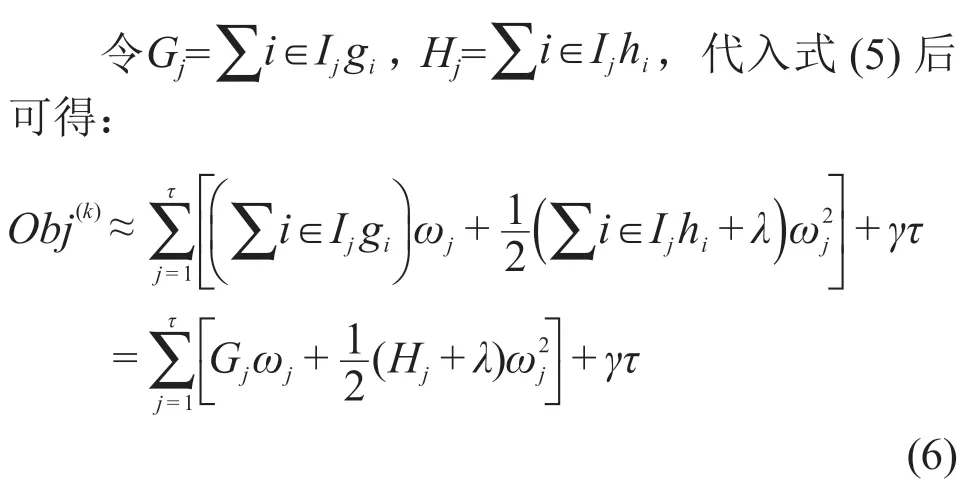

將式(7)代入式(6),可獲得最終的目標函數,如式(8)所示。
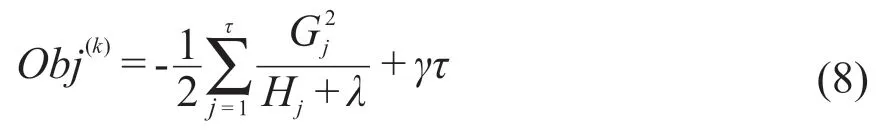
對于光伏陣列故障診斷大數據而言,基于XGBoost算法來識別光伏陣列故障類型的研究很少。本研究使用仿真數據建立光伏陣列正常、開路、短路、老化、陰影遮擋5種運行狀態下的XGBoost故障診斷模型,應用XGBoost算法識別光伏陣列故障類型。XGBoost算法優于其他的機器學習方法,即使采用預測結果和訓練數據差值進行訓練,也可以在樹的不斷迭代過程中提升準確率。此外,XGBoost故障診斷模型可以從數據訓練過程中提煉并展示出模型學習比較重要的特征變量,這些重要特征變量有助于幫助光伏電站及時識別光伏陣列故障類型并進行有效維護。
本研究采用500例仿真數據,按照8:2的比例劃分訓練集和測試集。針對400例訓練集數據,基于10折交叉驗證將其平均分成10份,其中9份用于訓練,1份用于驗證。基于XGBoost算法的光伏陣列故障診斷方法的流程圖如圖3所示。
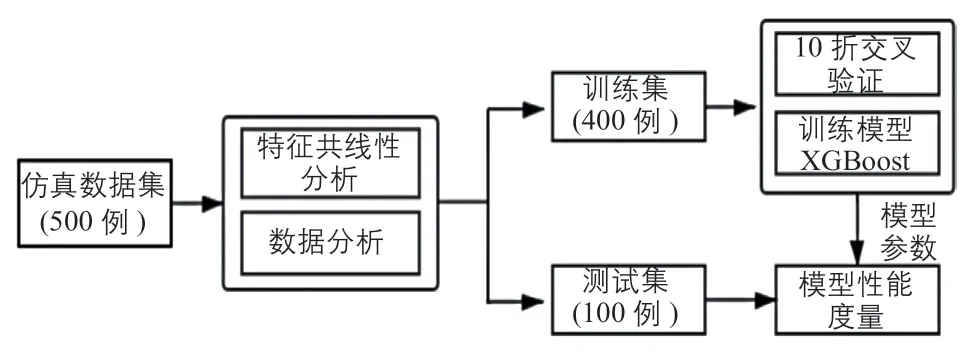
圖3 基于XGBoost算法的光伏陣列故障診斷方法的流程圖Fig. 3 Flow chart of fault diagnosis method for PV array based on XGBoost algorithm
2.2 模型性能度量指標
本研究選擇的模型性能度量指標包括準確率(accuracy)、查全率(recall,又稱召回率)、查準率(precision),以及F1評分。根據真實結果與預測結果的不同,將樣本數據劃分為真正例(TP)、真反例(TN)、假正例(FP)和假反例(FN)[15]。
準確率Acc表示查出的正確的樣本數占樣本總數的比值,其可表示為:
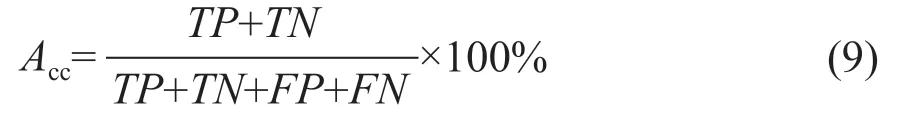
查準率Pre表示預測的正確的樣本中有多少樣本是有用的,其可表示為:

查全率Re表示有用的樣本中有多少樣本被查出,其可表示為:

F1評分表示查準率與查全率的調和平均值,F1評分更重視查準率與查全率兩個指標中的較小值,較小值的變動比較大值的變動對F1評分的影響更大。F1評分可表示為:

2.3 模型診斷結果評價及特征變量重要性分析
基于測試集的5種光伏陣列運行狀態下的100例數據,對XGBoost故障診斷模型的診斷結果進行評價。不同運行狀態下模型性能度量指標的分析結果如表3所示。
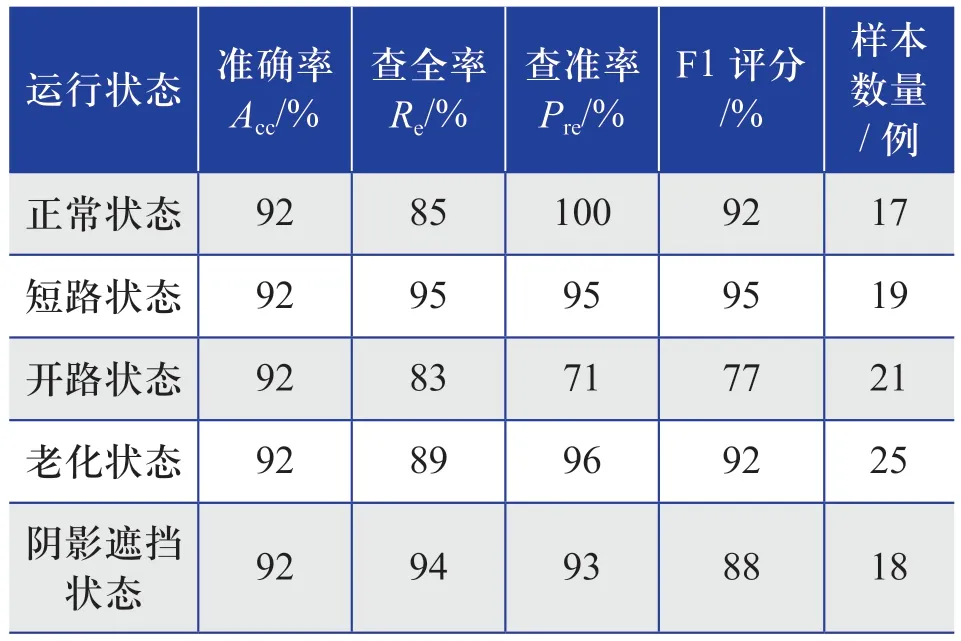
表3 不同運行狀態下模型性能度量指標的分析結果Table 3 Analysis results of model performance measurement index in different operating conditions
從表3可以看出:不同運行狀態下,XGBoost故障診斷模型的準確率均為92%。在光伏陣列正常運行狀態下,XGBoost故障診斷模型的查全率為85%,查準率為100%,F1評分為92%,其中查準率在4個指標中最優;在光伏陣列短路狀態下,模型的查全率、查準率和F1評分均為95%,在4個指標中均為最優;在光伏陣列開路狀態下,模型的查全率為83%,查準率為71%,F1評分為77%,其中查準率在4個指標中最低;在光伏陣列老化狀態下,模型的查全率為89%,查準率為96%,F1評分為92%,其中查全率在4個指標中最低;在光伏陣列陰影遮擋狀態下,模型的查全率為94%,查準率為93%,F1評分為88%,其中F1評分在4個指標中最低。綜合來看,XGBoost故障診斷模型的準確率高達92%,查全率高達95%,查準率高達96%,F1評分高達95%。該結果表明,基于XGBoost算法的光伏陣列故障診斷方法可以有效應用于光伏陣列的故障類型識別。
訓練好的XGBoost故障診斷模型會給特征變量打分并輸出特征變量的重要性排序,排序的規則使用“weight”方法,即根據該特征變量在所有樹中被用作分割樣本的特征次數來表征特征變量的重要性。特征變量的重要性排序如圖4所示。
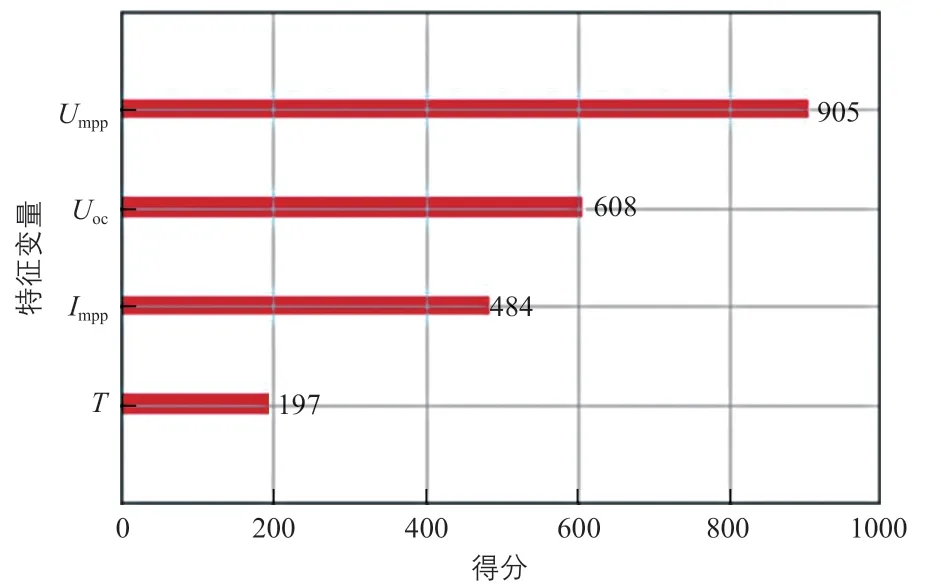
圖4 特征變量的重要性排序Fig. 4 Importance ranking of characteristic variables
從圖4可以看出:特征變量的重要性排序從高到低依次為最大工作點電壓、開路電壓、最大工作點電流、環境溫度。其中,最大工作點電壓被認為是最重要的特征變量。
3 結論
針對目前光伏陣列故障診斷方法無法實時在線識別故障類型且準確率不高等問題,本文提出了一種基于XGBoost算法的光伏陣列故障診斷方法。首先建立光伏陣列仿真模型,針對正常、開路、短路、老化、陰影遮擋5種光伏陣列運行狀態進行仿真,并獲取有效數據;其次,分析仿真數據特征變量之間的共線性關系,提取有效的特征變量作為模型的特征變量輸入;然后,基于特征變量構建了XGBoost故障診斷模型;最后依據模型性能度量指標對XGBoost故障診斷模型的診斷結果進行評價,并分析模型特征變量的重要性。研究得出以下結論:
1)該故障診斷方法不僅提高了光伏陣列故障診斷的準確率,而且提升了對光伏陣列故障類型的有效挖掘能力;
2)在一定的樣本測試條件下,該故障診斷方法可實現對正常、開路、短路、老化、陰影遮擋5種光伏陣列運行狀態的故障診斷,且故障診斷準確率可達到92%;
3) XGBoost故障診斷模型從數據訓練過程中提煉并展示出對于模型學習而言比較重要的特征變量,這些重要的特征變量有助于幫助光伏電站及時識別光伏陣列的故障類型并進行有效維護;
4)該故障診斷方法能簡單、高效、實時在線對樣本數據進行故障診斷,可為光伏電站現場運維人員提供技術支持。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
