基于多圖卷積神經(jīng)網(wǎng)絡的主汽溫系統(tǒng)故障診斷
2023-02-22 14:15:48吳錚,張悅,董澤
動力工程學報 2023年2期
吳 錚, 張 悅, 董 澤
(1.華北電力大學 控制與計算機工程學院,北京 102206;2.河北省發(fā)電過程仿真與優(yōu)化控制技術創(chuàng)新中心,河北保定 071003)
隨著我國“2030年實現(xiàn)碳達峰,努力爭取2060年前實現(xiàn)碳中和”宏偉目標的提出,火力發(fā)電機組面臨著低碳排放改造和新能源發(fā)電并入等一系列困難與挑戰(zhàn)。現(xiàn)階段,火力發(fā)電機組大多采用容量大、效率高的大型鍋爐,主汽溫系統(tǒng)的結構也變得愈發(fā)復雜。主蒸汽溫度系統(tǒng)能否安全、穩(wěn)定運行對火電機組的運行可靠性具有關鍵作用。主蒸汽溫度過高會降低金屬部件受熱面的整體強度,機組發(fā)生故障的風險增加;主蒸汽溫度過低則會大幅降低機組運行效率,從而影響機組的運行功率。同時,主汽溫的劇烈變化也會對汽輪機運行的穩(wěn)定性產(chǎn)生影響,所以主汽溫系統(tǒng)的故障診斷研究具有重要意義。基于數(shù)據(jù)驅動的故障診斷方法可以充分利用已有的熱工過程數(shù)據(jù)資源,可以準確高效地識別機組的故障類別。基于數(shù)據(jù)驅動的故障診斷方法已被廣泛應用于電力系統(tǒng)[1]、熱能工程[2]、航空航天[3]、新能源汽車[4]和化工[5]等領域。
目前,各地燃煤電站的智能化系統(tǒng)軟件中儲存著大量的機組歷史運行數(shù)據(jù),這為基于數(shù)據(jù)驅動的故障診斷方法的研究提供了信息基礎。工業(yè)故障診斷方法主要分為定性分析和定量分析兩類方法。其中,定性分析方法包括圖論方法[6]、專家系統(tǒng)[7]和定性仿真[8]等,定量分析方法包括基于解析模型[9]和數(shù)據(jù)驅動[10]等方法。文成林等[11]對近年來基于深度學習的工業(yè)故障診斷技術進行了綜述與探討。韓旭東等[12]提出了一種基于知識圖譜的火電機組智能診斷方法,通過結合專家信息構建知識圖譜,建立了火電機組智能輔助診斷系統(tǒng)。王文標等[13]針對工業(yè)鍋爐系統(tǒng)的多模態(tài)特性,利用交叉分段主成分分析方法進行故障診斷。顧崇寅等[14]提出了基于CatBoost算法的故障診斷方法,實現(xiàn)了在小規(guī)模訓練集下對不同程度故障的準確診斷。但上述所提方法通常只對某些特定對象的故障診斷具有較高的識別精度,泛化能力較差。針對主蒸汽溫度系統(tǒng)具有大遲延、大慣性、非線性和時變性等特性,筆者嘗試采用基于深度學習的數(shù)據(jù)驅動方法來提高主汽溫系統(tǒng)的故障診斷精度。
圖卷積神經(jīng)網(wǎng)絡(graph convolution network,GCN)是由頻譜卷積神經(jīng)網(wǎng)絡(Spectral CNN)和切比雪夫網(wǎng)絡(ChebNet)演變而來的模型[15]。圖卷積神經(jīng)網(wǎng)絡采用卷積操作和傅里葉變換等方法對圖信息進行處理,結合深度圖卷積結構實現(xiàn)數(shù)據(jù)的分類與回歸。GCN可以建立各個節(jié)點間拓撲結構的連接關系,同時利用圖卷積結構自適應地提取輸入數(shù)據(jù)間的各項特征,所以在復雜工業(yè)運行數(shù)據(jù)的建模方面具有優(yōu)勢[16]。目前,圖卷積神經(jīng)網(wǎng)絡已被成功應用于多個領域的故障診斷工作。Li等[17]建立了一種基于圖神經(jīng)網(wǎng)絡的新型智能故障診斷與預測模型,模型在多個數(shù)據(jù)集中均取得了良好的診斷效果。Gao等[18]針對小樣本機械故障診斷困難的問題,提出一種基于半監(jiān)督圖卷積神經(jīng)網(wǎng)絡(SSGCN)的智能故障診斷方法。Zhang等[19]提出采用剪枝圖卷積網(wǎng)絡(PGCN)進行特征提取與故障診斷,通過圖結構的剪枝方法有效地從過程故障數(shù)據(jù)中提取重要信息,結果表明PGCN在特征提取和過程故障診斷方面的性能優(yōu)于其他典型方法。然而,圖卷積神經(jīng)網(wǎng)絡在國內(nèi)火力發(fā)電生產(chǎn)建模方面的應用還處于探索階段。
筆者提出了一種基于多圖融合的圖卷積神經(jīng)網(wǎng)絡(MG-GCN)模型,引入特征權重和截斷參數(shù)來融合多圖特征信息,將火電機組歷史運行數(shù)據(jù)擴展為非歐式空間的圖數(shù)據(jù)。同時,利用深層圖卷積結構建立歷史數(shù)據(jù)與系統(tǒng)運行狀態(tài)間的映射關系,實現(xiàn)主汽溫系統(tǒng)的故障診斷。
1 圖卷積神經(jīng)網(wǎng)絡
GCN主要包括空域卷積和頻域卷積,通過深度學習思想對圖結構數(shù)據(jù)進行學習。空域卷積采用卷積神經(jīng)網(wǎng)絡中的卷積操作直接對圖進行卷積。頻域卷積通過圖傅里葉變換和圖傅里葉逆變換等進行圖卷積[20]。所提出的多圖卷積神經(jīng)網(wǎng)絡模型主要基于頻域圖卷積思想。
假設存在圖結構G(V,E),節(jié)點間鄰接關系用圖結構中全部邊的集合E來進行描述,V為所有節(jié)點的集合,節(jié)點總數(shù)為N,節(jié)點特征數(shù)為T。將每個節(jié)點i的特征定義為xi,整體特征矩陣表示為XN*T。拉普拉斯矩陣L用于描述圖結構G(V,E)的特征信息,具體公式為:
(1)
式中:A為鄰接矩陣;D為頂點的度矩陣;IN為N階單位矩陣。
通過特征分解所獲得的特征向量和特征值可用于表示圖結構中的信息。矩陣L分解后的結果為:
(2)
式中:λl為特征值,l=1,2,…,N;U為特征向量矩陣;Λ為分解后所得的特征值矩陣。
通過傅里葉變換后的圖信息F(λl)為:
(3)
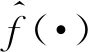
圖卷積公式可以表示為:
g*x=UgθUTx=
(4)
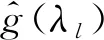
在上式中,特征向量矩陣U的復雜度為O(N2)。當圖結構比較龐大時,過大的計算量容易導致模型的運行效率降低。針對上述問題,Hammond等提出了利用Chebyshev多項式來進行處理:
(5)
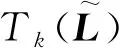
圖卷積層通過提取和融合圖結構中的特征信息,對輸出數(shù)據(jù)進行壓縮處理,最終輸出故障診斷結果。圖卷積隱含層信息傳遞的公式為:
(6)
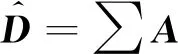
式中:σ為激活函數(shù);W(l)為權重參數(shù)矩陣;H(l)為第l層的圖節(jié)點矩陣。
圖卷積神經(jīng)網(wǎng)絡的基本結構如圖1所示。
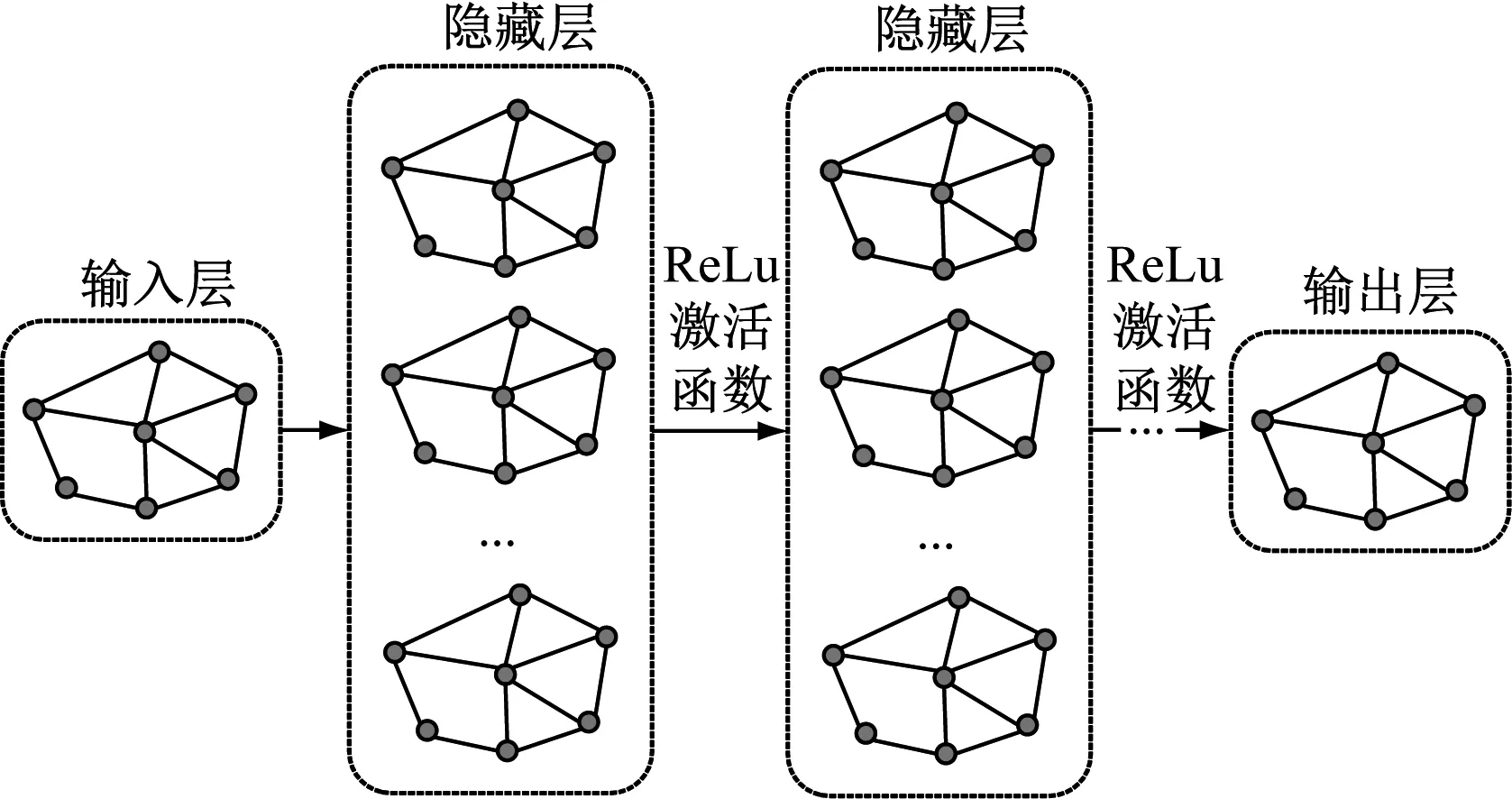
圖1 圖卷積神經(jīng)網(wǎng)絡結構
2 模型整體結構
2.1 鄰接矩陣的建立
圖的生成是建立圖卷積神經(jīng)網(wǎng)絡模型的關鍵。圖數(shù)據(jù)形式可以有效地融合主汽溫系統(tǒng)中各監(jiān)測參數(shù)間的鄰接關系和運行數(shù)值信息,形成拓撲結構,從而降低系統(tǒng)延遲、慣性程度高的影響。如果構建的圖拓撲結構不能有效地反映節(jié)點間的相關性,系統(tǒng)延遲和慣性的干擾將會增加,從而降低故障診斷精度。
在構建圖時,需要保證具有強信息相關性的變量間相互連接。目前針對于工業(yè)數(shù)據(jù)集,機理分析[21]和最近鄰算法[22]是建立圖數(shù)據(jù)的常用方法。為了更全面地度量主汽溫系統(tǒng)中運行數(shù)據(jù)的特征信息關系,完成圖拓撲結構的構建,筆者建立鄰接特征圖和相關性特征圖,并利用圖融合方法結合多圖信息,生成樣本數(shù)據(jù)間的拓撲結構。
2.1.1 鄰接特征圖
鄰接特征圖GN(V,E,AN)用于描述相鄰近節(jié)點之間的空間特征關系。將每一個樣本數(shù)據(jù)點作為一個節(jié)點,AN表示鄰接特征矩陣,具體計算公式為:
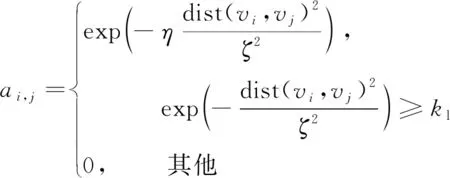
(7)
(8)
式中:aij為樣本數(shù)據(jù)vi與vj之間邊的權值;dist(vi,vj)2為樣本數(shù)據(jù)vi與vj之間的歐式距離;ζ為距離的標準差;η為常數(shù)項,取值為10;kl為用于確保特征矩陣稀疏性的閾值,取值為0.1。
2.1.2 相關性特征圖
相關性特征圖GS(V,E,AS)可表示空間距離較遠但仍存在強關聯(lián)性節(jié)點間的依賴關系。采用皮爾遜相關系數(shù)(Pearson Correlation Coefficient, PCC)來評估各節(jié)點之間的相似性程度。各樣本數(shù)據(jù)間的皮爾遜相關系數(shù)值構成了相關性特征矩陣AS,具體計算公式為:
(9)
(10)
式中:bij為樣本數(shù)據(jù)vki與vkj之間的皮爾遜相關系數(shù)值;xki和xkj均為輸入變量。
2.1.3 特征圖融合
特征圖融合主要是指將建立的鄰接圖和相關圖合并,充分提取各圖拓撲關系之間的內(nèi)在特征聯(lián)系。現(xiàn)階段的多圖融合方式主要分為多圖累加[23]和網(wǎng)絡優(yōu)化[24]等方式。針對小樣本數(shù)據(jù)集,為防止模型過于復雜,出現(xiàn)訓練時間長、收斂效率慢等問題,筆者采用多圖累加方法,引入特征權重Wi和截斷參數(shù)C來約束各節(jié)點間相關性,優(yōu)化拓撲結構。具體計算公式如下:
(11)
(12)
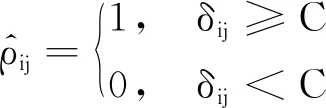
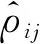
2.2 模型基本流程
圖2為多圖卷積神經(jīng)網(wǎng)絡結構示意圖。其中,a1~a7、b1~b6、X1~X10、Y1~Y6均表示圖節(jié)點,1~6表示故障類型。圖3為模型的整體流程圖。基于多圖卷積神經(jīng)網(wǎng)絡的主汽溫故障診斷模型的具體步驟為:首先,對數(shù)據(jù)集進行預處理,歸一化處理樣本數(shù)據(jù),消除各項特征值間的差異,采用組合特征選擇方法進行特征提取,再使用KPCA方法提取主成分,降低非線性影響,生成特征矩陣,提升整體運行的精度和效率;其次,計算鄰接特征矩陣AN和相關性特征矩陣AS,引入特征權重Wi和截斷參數(shù)C,采用多圖累加的方式融合多圖信息,建立圖網(wǎng)絡的拓撲結構,生成鄰接矩陣AT;設置圖卷積層的層級結構、學習率和迭代次數(shù)等參數(shù),選擇Adam方法優(yōu)化模型訓練過程;再輸入訓練數(shù)據(jù)集,對圖卷積神經(jīng)網(wǎng)絡模型進行訓練,在模型訓練過程中,結合訓練結果調節(jié)各參數(shù)的設定值,使模型達到最優(yōu)檢測性能;最后,輸入測試數(shù)據(jù)集,在深度圖卷積層中自適應地提取出圖數(shù)據(jù)的各項特征,得出主汽溫系統(tǒng)的故障診斷結果。
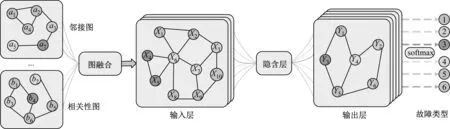
圖2 多圖卷積神經(jīng)網(wǎng)絡整體結構示意圖
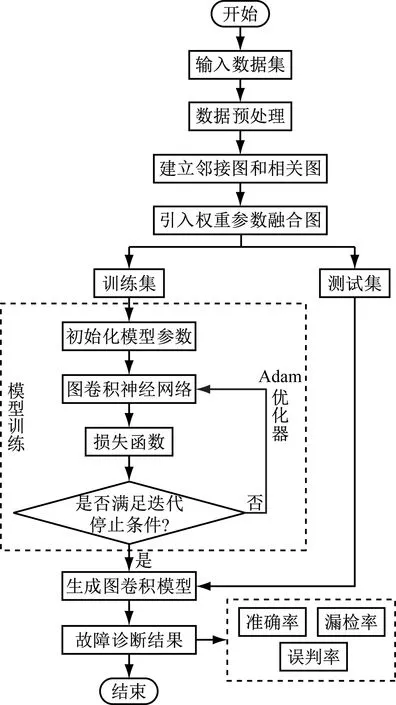
圖3 模型整體流程圖
3 仿真實驗結果與分析
3.1 實驗數(shù)據(jù)集及預處理
采用國電智深DCS控制系統(tǒng)和STS仿真機平臺進行故障模擬。筆者分別模擬了國電泰州電廠二次再熱機組800 MW穩(wěn)態(tài)工況下的5種主汽溫系統(tǒng)故障狀態(tài),采集各故障狀態(tài)和正常運行下的樣本數(shù)據(jù)并組成實驗數(shù)據(jù)集,驗證所提模型的有效性。原始數(shù)據(jù)共6 000組。其中,訓練集包括800組正常運行數(shù)據(jù)和4 000組故障數(shù)據(jù),每種故障類型數(shù)據(jù)各800組;測試集包括200組正常運行數(shù)據(jù)和1 000組故障數(shù)據(jù),每種故障類型數(shù)據(jù)各200組。表1給出了系統(tǒng)的故障及類別。

表1 系統(tǒng)主要故障類型
采用準確率、誤判率和漏檢率來評價模型的故障診斷效果,具體計算如下:

(13)

(14)

(15)
由于主汽溫系統(tǒng)各參數(shù)間的數(shù)值水平相差較大,為防止數(shù)值水平過高或過低的數(shù)據(jù)被過度削弱或凸顯,進而影響圖結構的構建,所以對原始數(shù)據(jù)集進行歸一化處理。同時,對數(shù)據(jù)集進行無效點去除、填補無效值和空數(shù)據(jù)等預處理。將各類別數(shù)據(jù)間差值大于整體均值5倍的數(shù)據(jù)定義為無效點,并用無效值與空數(shù)據(jù)前后25個點的均值進行填補。
為避免采用單一特征選擇方法在選取特征時存在原理性差異,采用組合特征選擇方法提取特征參數(shù)。依次使用最大互信息系數(shù)(MIC)、分類與回歸決策樹(CART)和XGBoost等方法計算各監(jiān)測參數(shù)與主汽溫間的相關性,對結果進行歸一化求和并取均值,設定閾值為2%,選取出具有強關聯(lián)性的重要運行參數(shù)。表2給出了所選主汽溫系統(tǒng)的關鍵運行參數(shù),圖4為各參數(shù)與主蒸汽溫度之間的相關性均值圖。其中,高過表示高壓過熱。
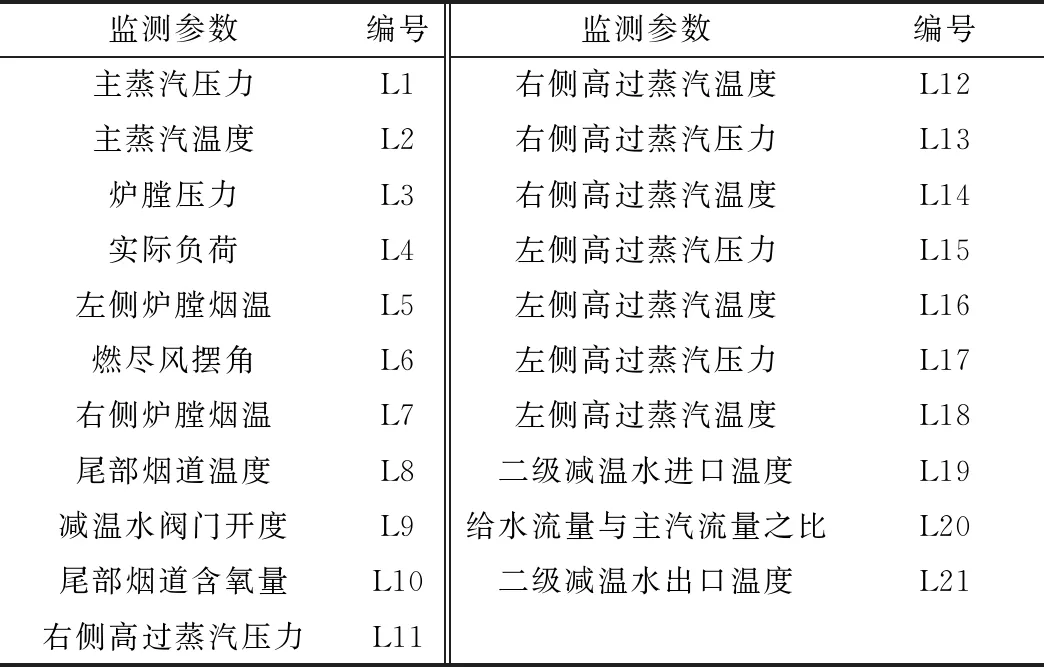
表2 主汽溫系統(tǒng)監(jiān)測參數(shù)

圖4 相關性均值圖
數(shù)據(jù)預處理完成后,選擇高斯徑向基函數(shù)作為核函數(shù),采用KPCA提取樣本數(shù)據(jù)的非線性特征,降低系統(tǒng)非線性對建模的影響。根據(jù)累計貢獻率大于95%的規(guī)則確定主元個數(shù)。圖5為主成分累計貢獻圖。由圖5可知,前11個主成分累計貢獻率已經(jīng)達到95%,因此主成分個數(shù)設置為11。

圖5 主成分貢獻圖
3.2 圖結構的生成
將提取的全部主成分數(shù)據(jù)作為各節(jié)點的特征信息來構建鄰接特征圖和相關性特征圖,引入特征權重Wi和截斷參數(shù)C融合生成多圖拓撲結構,建立鄰接矩陣。特征權重Wi主要用于衡量鄰接圖和相關性圖的融合比例程度,設定W1=W2=0.5。圖6給出了多圖融合后的特征矩陣圖和鄰接矩陣圖。
由圖6(a)可知,由于節(jié)點與自身的相關性最大,所以其對角線是一條明顯的突出亮線。由圖6(b)可知,選取不同的截斷參數(shù)C時,數(shù)據(jù)間也呈現(xiàn)不同的鄰接關系。當C較小時,節(jié)點間的鄰接關系較為松散,特征信息沒有充分融合,在降低模型運行效率的同時也引入了過多的非相關性向量;當C較大時,節(jié)點間的鄰接關系較緊湊,鄰接關系易出現(xiàn)過度關聯(lián),從而影響模型的故障診斷效果。

(a) 特征矩陣圖
構建完成圖結構的特征及鄰接關系后,將特征矩陣、鄰接矩陣等輸入多圖卷積神經(jīng)網(wǎng)絡進行迭代。通過若干層深度圖卷積結構的特征融合和維度變換,自適應學習網(wǎng)絡的權重參數(shù),生成拓撲結構與故障類型間的映射關系,輸出主汽溫系統(tǒng)的故障診斷結果。模型各項參數(shù)配置情況如表3所示。

表3 圖卷積神經(jīng)網(wǎng)絡參數(shù)
3.3 不同截斷參數(shù)和圖結構下的對比試驗
不同截斷參數(shù)會影響模型的故障診斷性能。為了進一步提高多圖卷積神經(jīng)網(wǎng)絡的整體性能,選擇多個截斷參數(shù)C進行模型的故障診斷性能對比,計算相應的模型評價指標。
不同截斷參數(shù)下的故障診斷結果對比結果見表4。隨著截斷參數(shù)C的增大,故障診斷模型的性能也隨之變化。當C=0.95時,模型訓練集和測試集的評價指標均最佳,當截斷參數(shù)繼續(xù)增大時,模型精度下降,鄰接關系出現(xiàn)過度關聯(lián)。因此,選用0.95作為最佳截斷參數(shù)。

表4 不同截斷參數(shù)下的故障診斷結果
圖的生成是建立圖卷積神經(jīng)網(wǎng)絡模型的關鍵。圖構建的原則是保障信息相關性強的變量之間相互連接。為驗證多圖融合方法的有效性,分別使用鄰接圖、相關性圖和融合圖等方式生成圖數(shù)據(jù),其中模型參數(shù)保持不變。表5和圖7為不同圖結構下的故障診斷結果。由表5和圖7可知,與采用融合圖相比,僅使用鄰接圖或相關圖建立圖數(shù)據(jù)結構時整體故障診斷性能均較低,證明了所提出的多圖融合方法的有效性。
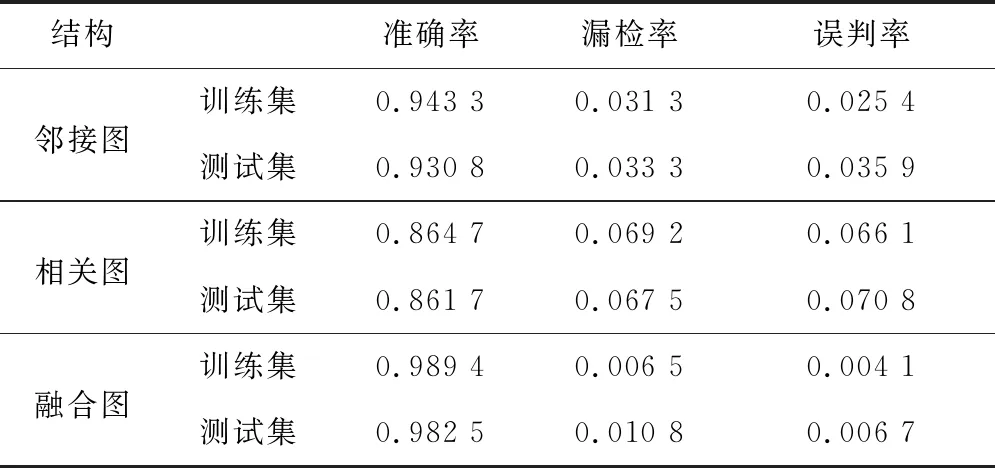
表5 不同圖結構下的故障診斷結果

(a) 鄰接圖
3.4 對比試驗
為進一步驗證模型的有效性,選取現(xiàn)階段故障診斷方法中效果較好的概率神經(jīng)網(wǎng)絡(PNN)、長短期記憶神經(jīng)網(wǎng)絡(LTSM)和最小二乘支持向量機(LSSVM)算法進行對比。所提MG-GCN模型的參數(shù)設置不變,截斷參數(shù)為0.95。各算法下的評價指標見表6。設定LSTM的學習率為0.001,網(wǎng)絡層數(shù)為3,隱層神經(jīng)元個數(shù)為100,訓練次數(shù)為3 000,模型優(yōu)化方法保持不變。設定PNN中平滑因子為0.83,其余參數(shù)與LSTM一致。LSSVM中核函數(shù)選用高斯核函數(shù),設定懲罰因子為45.56,核函數(shù)參數(shù)為0.13。相較于PNN、LTSM和LSSVM,MG-GCN的準確率分別提升了11%、7%和16%,說明該模型針對主汽溫系統(tǒng)有良好的故障診斷性能,極大地降低了誤檢、漏檢發(fā)生的概率,解決了系統(tǒng)具有大遲延、大慣性、非線性和時變性的問題,保證了火電機組的安全、穩(wěn)定運行。
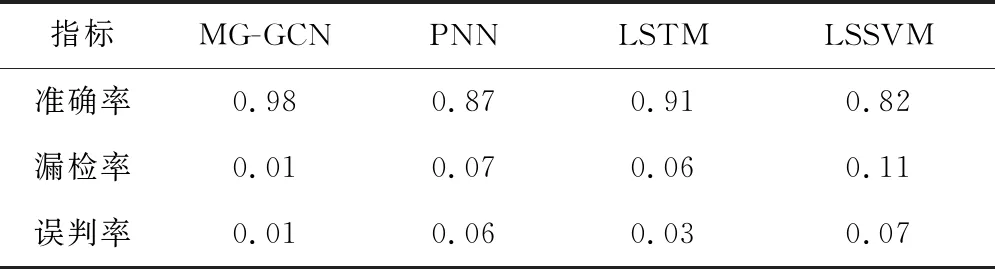
表6 各算法下的評價指標
4 結 論
相較于PNN、LTSM和LSSVM,所提MG-GCN模型的故障診斷準確率分別提升了11%、7%和16%,誤檢率、漏檢率均較低,具有良好的故障診斷性能,保證了火電機組運行的安全性和穩(wěn)定性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
