面向圖像篡改檢測(cè)的雙流卷積注意力網(wǎng)絡(luò)
2023-02-28 16:09:44張玉金張立軍
智能計(jì)算機(jī)與應(yīng)用 2023年11期
孫 冉,張玉金,張立軍,郭 靜
(上海工程技術(shù)大學(xué)電子電氣工程學(xué)院,上海 201620)
0 引 言
隨著圖像編輯技術(shù)的發(fā)展,圖像篡改成為了低成本的操作,不同的人群篡改圖片的目的不同,但都會(huì)使圖像內(nèi)容的真實(shí)性得不到保障。 已有的研究工作表明,圖像篡改類型主要包括:復(fù)制-粘貼篡改[1]、拼接篡改[2]和修復(fù)篡改[3]。 其中,復(fù)制-粘貼篡改是指在同一幅圖像上,把某一部分區(qū)域復(fù)制后粘貼到該圖像的另一個(gè)位置,從而達(dá)到以假亂真的目的;拼接篡改是指將一幅圖像的某個(gè)部分復(fù)制下來粘貼到其他圖像中以合成一幅偽造圖像;修復(fù)篡改是指基于圖像原有信息還原缺失部分或移除原圖某一區(qū)域。 目前,主流的圖像篡改檢測(cè)方法可以分為主動(dòng)檢測(cè)和被動(dòng)檢測(cè)(盲檢測(cè))[4],二者的主要區(qū)別在于是否在圖像中預(yù)先嵌入附加信息,如數(shù)字水印等。
圖像拼接使用的源圖像一般來自兩幅或多幅不同圖片,人們?cè)趯?duì)圖像進(jìn)行篡改時(shí),往往只關(guān)注RGB 域的逼真程度,而忽略圖像噪聲域的統(tǒng)計(jì)特性變化。 圖像噪聲是指存在于圖像數(shù)據(jù)中的干擾信息,圖像成像過程中,CCD 和CMOS 傳感器采集數(shù)據(jù)時(shí)一般會(huì)受到傳感器材料屬性、工作環(huán)境和電路結(jié)構(gòu)等影響而引入各種噪聲[5]。 由于拼接篡改使用的圖像通常來源于不同成像設(shè)備,而這些設(shè)備的噪聲分布往往具有一定的差異,因此,噪聲的不一致性對(duì)圖像拼接篡改的分析與鑒定具有較好的輔助作用。
2012年,以Alex-Net[6]為代表的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)在特征提取方面表現(xiàn)優(yōu)異,隨后一些學(xué)者開始使用深度學(xué)習(xí)技術(shù)來解決圖像篡改檢測(cè)問題。 Yuan 等學(xué)者[7]首次將卷積神經(jīng)網(wǎng)絡(luò)用于數(shù)字圖像篡改檢測(cè),該方法從RGB 彩色圖像自動(dòng)學(xué)習(xí)特征層次表示,并采用特征融合技術(shù)得到最終判別特征。 Johnson 等學(xué)者[8]提出了全卷積網(wǎng)絡(luò)并應(yīng)用于語義分割任務(wù),實(shí)現(xiàn)了像素級(jí)別的分類。 Salloum 等學(xué)者[9]對(duì)此網(wǎng)絡(luò)結(jié)構(gòu)稍作修改,提出一種基于邊緣強(qiáng)化的多任務(wù)圖像被動(dòng)取證框架用于像素級(jí)別的篡改區(qū)域分割,該算法采用VGG16 網(wǎng)絡(luò)提取圖像篡改特征,并利用篡改區(qū)域掩碼對(duì)篡改區(qū)域進(jìn)行修正。 Bondi 等學(xué)者[10]結(jié)合圖像成像設(shè)備屬性的特點(diǎn),提出利用相機(jī)指紋進(jìn)行圖像篡改檢測(cè)和定位,該算法采用神經(jīng)網(wǎng)絡(luò)從圖像塊中提取相機(jī)模型特征,對(duì)拼接篡改具有良好的檢測(cè)效果,但不適用于復(fù)制-粘貼的篡改類型。 Bappy 等學(xué)者[11]采用了一個(gè)混合的CNN-LSTM 模型來捕捉篡改區(qū)域和非篡改區(qū)域之間的區(qū)分特征,LSTM(Long Short Term Memory)[12]是長短期記憶模型,能夠記錄圖像上下文信息,并將LSTM 和CNN 中的卷積層相結(jié)合來理解篡改區(qū)域和相鄰非篡改區(qū)域共享邊界上像素間的空間結(jié)構(gòu)差異。 Zhou 等學(xué)者[13]基于Faster R-CNN 網(wǎng)絡(luò)[14]提出一種雙流網(wǎng)絡(luò),并對(duì)其進(jìn)行端到端的訓(xùn)練,以檢測(cè)可疑的篡改區(qū)域。
在上述雙流網(wǎng)絡(luò)中,RGB 流能夠有效地反映圖像篡改特性,噪聲流則能更好地體現(xiàn)不同設(shè)備源圖像進(jìn)行拼接后的差異,故RGB 流和噪聲流對(duì)于圖像篡改檢測(cè)具有一定的互補(bǔ)性,但由于Faster R-CNN最優(yōu)性能的限制,該網(wǎng)絡(luò)仍存在提升空間。 因此,本文在前人工作基礎(chǔ)上改進(jìn)了卷積注意力機(jī)制(Convolutional Block Attention Module,CBAM)[15]加入到特征提取網(wǎng)絡(luò),并在RPN 模塊引入Soft-NMS算法[16],構(gòu)建了一種面向圖像篡改檢測(cè)的雙流卷積注意力網(wǎng)絡(luò)。 改進(jìn)的卷積注意力機(jī)制可有效抑制圖片中冗余信息,達(dá)到對(duì)有效信息的專注檢測(cè),Soft-NMS 算法可以有效地降低漏檢概率。 本文所提的雙流網(wǎng)絡(luò)可以學(xué)習(xí)更豐富的圖像特征,以提高圖像篡改檢測(cè)準(zhǔn)確度。
1 網(wǎng)絡(luò)總體框架
本文所提雙流卷積注意力網(wǎng)絡(luò)的整體流程如圖1 所示。 RGB 流將原圖輸入網(wǎng)絡(luò)中,通過加入改進(jìn)卷積注意力機(jī)制的特征提取網(wǎng)絡(luò)從RGB 圖像中提取特征,捕捉RGB 域中的邊緣異常、顏色反差等篡改痕跡;噪聲流首先利用SRM 模型[17]提取噪聲信息,再通過特征提取網(wǎng)絡(luò)分析圖像真實(shí)區(qū)域和被篡改區(qū)域噪聲間的不一致性;最后,將2 個(gè)支流中提取到的特征信息在雙線性池化層[18]融合得到最終的特征圖,送入最后的全連接層進(jìn)行分類和位置精修。
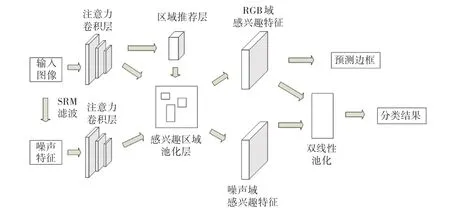
圖1 網(wǎng)絡(luò)整體框架Fig. 1 The framework of the network
1.1 改進(jìn)的卷積注意力模塊
注意力機(jī)制是提升網(wǎng)絡(luò)性能的一種方式,在傳統(tǒng)的卷積池化過程中,默認(rèn)特征圖的每個(gè)通道的重要性是相同的,而實(shí)際并非如此,SE block[19]即是為了解決該問題而研發(fā)的。 一個(gè)SE 模塊分為壓縮(Squeeze)和激發(fā)(Excitation)兩個(gè)步驟,通過對(duì)前一個(gè)卷積層輸出的特征圖進(jìn)行全局平均池化操作得到1?1?C的壓縮特征量,再經(jīng)過2 個(gè)全連接層,先對(duì)特征壓縮量進(jìn)行降維、再升維,增加了更多的非線性處理,更好地?cái)M合通道之間復(fù)雜的相關(guān)性。 最后與原始的特征圖進(jìn)行矩陣的對(duì)應(yīng)元素相乘得到不同通道權(quán)重的特征圖。
CBAM 是輕量級(jí)的卷積注意力模型,是對(duì)SE block 的一種改進(jìn),由通道注意力機(jī)制和空間注意力機(jī)制級(jí)聯(lián)而成,CBAM 對(duì)特征圖進(jìn)行操作,使提取到的特征更加精煉。 其中,通道注意力和SE block 類似,只是多了一個(gè)并行的全局最大池化的操作,研究認(rèn)為不同的池化意味著提取到的高層次特征更豐富。 圖2 展示了通道注意力的過程。
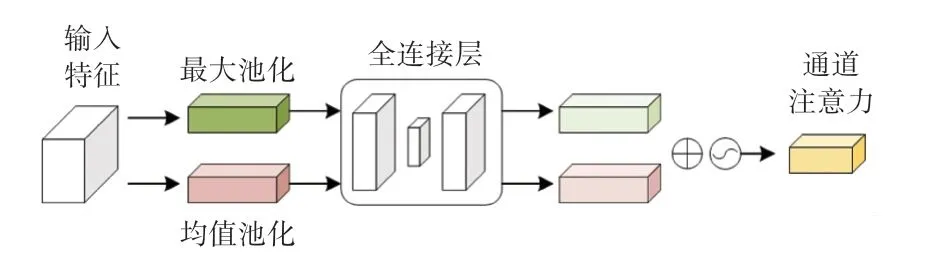
圖2 通道注意力Fig. 2 Channel attention
空間注意力關(guān)注的是同一通道間不同位置像素的重要性,該模塊的輸入是上一個(gè)通道注意力的輸出。 圖3 為空間注意力過程。
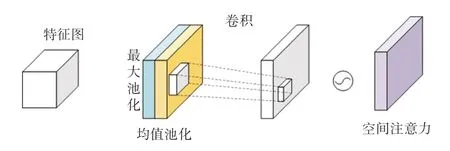
圖3 空間注意力Fig. 3 Spatial attention
文獻(xiàn)[20]中實(shí)驗(yàn)表明,SE block 中的2 個(gè)全連接層中的降維操作會(huì)給通道注意力預(yù)測(cè)帶來副作用,并且所捕獲到通道之間的依存關(guān)系效率不高,研究提出一種有效的通道注意力機(jī)制(Efficient Channel Attention,ECA)模塊,在不降維的情況下進(jìn)行逐通道全局平均池化后,考慮每個(gè)通道及其k個(gè)近鄰來捕獲本地跨通道交互。 受這種做法的啟發(fā),本文給出了改進(jìn)的CBAM 注意力模型(Improved CBAM,ICBAM),將2 個(gè)全連接層換成大小為k的快速一維卷積生成權(quán)值,k值的大小通過學(xué)習(xí)自適應(yīng)確定,結(jié)構(gòu)如圖4 所示。 整個(gè)過程可以用公式(1)表示:
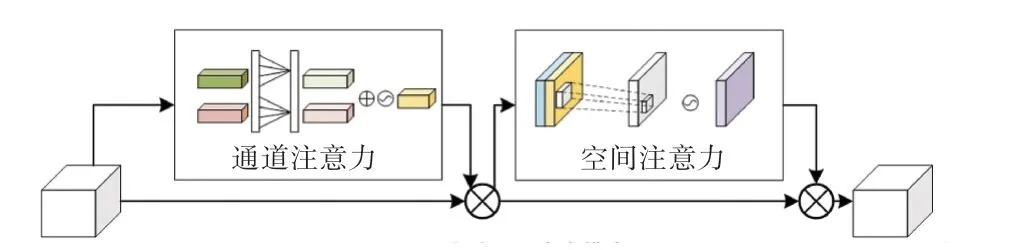
圖4 改進(jìn)的卷積注意力模塊Fig. 4 Advanced CBAM block
其中,F(xiàn)為輸入特征;Mc為通道注意力特征;Ms為空間注意力特征;“ ?”表示逐項(xiàng)元素相乘。
在通道注意力模塊,輸入特征F經(jīng)過并行的平均池化和最大池化得到2 個(gè)通道描述子,分別通過卷積核大小為k的一維卷積計(jì)算權(quán)重,將得到的特征元素逐項(xiàng)求和,經(jīng)由sigmoid函數(shù)得到權(quán)重系數(shù)Mc,和輸入特征F相乘得到新的特征。 見式(2):
其中,σ表示激活函數(shù),Ek表示一維卷積后的權(quán)重。
在空間注意力模塊,輸入是上一個(gè)通道注意力的輸出,把帶權(quán)重的通道特征送入2 個(gè)大小為列通道維度的池化(最大池化和平均池化)得到H?W?2 大小的特征圖,對(duì)該特征圖進(jìn)行卷積操作和sigmoid激活之后,和該模塊帶權(quán)重的輸入對(duì)應(yīng)元素相乘得到最后的結(jié)果。 研究推得的計(jì)算公式為:
其中,σ表示激活函數(shù),f7?7表示7?7 卷積操作。
本文采用通道注意力機(jī)制在前、空間注意力機(jī)制在后的級(jí)聯(lián)形式,將卷積注意力機(jī)制加到ResNet[21]第一個(gè)卷積層和最后一個(gè)卷積層之后。ResBlock+I(xiàn)CBAM 結(jié)構(gòu)如圖5 所示。

圖5 Resblock+I(xiàn)CBAM 結(jié)構(gòu)Fig. 5 Resblock with ICBAM
1.2 Faster R-CNN
Faster R-CNN 是一種兩階段目標(biāo)檢測(cè)算法,在目標(biāo)檢測(cè)領(lǐng)域取得優(yōu)異成績,該算法主要由4 個(gè)部分組成:特征提取網(wǎng)絡(luò)、區(qū)域推薦網(wǎng)絡(luò)(Region Proposal Network,RPN)、RoI(Region of Interest)池化層、分類和回歸。 其中,特征提取網(wǎng)絡(luò)提取圖像的特征圖送到RPN,RPN 用于生成多個(gè)建議框,RoI 池化層綜合特征圖和RPN 的建議框信息送入全連接層和softmax層進(jìn)行分類,同時(shí)進(jìn)行bounding box 回歸得到最終預(yù)測(cè)的目標(biāo)位置。 結(jié)構(gòu)流程如圖6 所示。
1.3 RGB 流
RGB 流是一個(gè)基礎(chǔ)Faster R-CNN 網(wǎng)絡(luò),在特征提取模塊,采用帶卷積注意力機(jī)制的ResNet 網(wǎng)絡(luò)學(xué)習(xí)RGB 圖像中篡改的特征。 RGB 流中的RPN(region proposal network)模塊用來推薦可能存在篡改的區(qū)域,這一層使用softmax層分類器判斷建議框是正、還是負(fù),RPN 模塊的損失函數(shù)如下:
其中,gi表示候選框i可能被篡改的概率;表示候選框i為正樣本標(biāo)簽;fi和是候選框的四維標(biāo)簽;Lcls表示RPN 網(wǎng)絡(luò)的交叉熵?fù)p失;Lreg表示建議邊框的L1回歸損失;Ncls表示RPN 網(wǎng)絡(luò)中批量的大小;Nreg表示建議邊框的數(shù)量;λ表示用于平衡2 個(gè)損失的超參數(shù),本文選取λ=10。
1.4 噪聲流
RGB 流對(duì)篡改圖像進(jìn)行檢測(cè)和定位精度和準(zhǔn)確度有限,尤其是當(dāng)篡改圖像經(jīng)過一些后處理操作、如濾波等,導(dǎo)致拼接區(qū)域的邊緣不一致信息被隱藏,因此需要引入噪聲流輔助檢測(cè)和定位。
噪聲流的設(shè)計(jì)是為了更關(guān)注噪聲而不是圖像的語義信息,富隱寫分析模型(Steganalysis Rich Model,SRM)在圖像隱寫任務(wù)中表現(xiàn)優(yōu)異,該模型主要從相鄰像素中提取局部噪聲。 本文同樣使用SRM 模型來提取噪聲輸入到噪聲流。 在SRM 的30個(gè)基礎(chǔ)濾波器中,只使用3 個(gè)濾波器也可以達(dá)到與30 個(gè)濾波器近似的效果,另外的27 個(gè)濾波器對(duì)噪聲提取效果并沒有明顯的提升,因此本文采用3 個(gè)濾波器,濾波器的權(quán)重如圖7 所示。

圖7 SRM 濾波器Fig. 7 SRM filter
本文將提取出來的噪聲特征直接輸入到噪聲流,噪聲流的網(wǎng)絡(luò)也采用Faster R-CNN,并且和RGB 流共用RoI 池化層的權(quán)重。
1.5 雙線性池化
圖像分別經(jīng)過RGB 流和噪聲流的特征提取網(wǎng)絡(luò)后,需要將2 個(gè)特征圖融合后再進(jìn)行篡改的檢測(cè)和定位操作。 雙線性池化主要用于特征融合,對(duì)于從同一個(gè)樣本提取出來的特征X和特征Y,將2 個(gè)特征相乘得到矩陣b,對(duì)所有位置進(jìn)行求和池化操作得到矩陣ξ,最后把矩陣ξ張成一個(gè)張量,記為雙線性向量x,對(duì)x進(jìn)行歸一化操作之后,就得到融合后的特征。 為了加速計(jì)算和節(jié)省內(nèi)存,本文采用文獻(xiàn)[22] 提出的緊湊雙線性池化。 池化層之后的輸出是:
其中,fRGB是RGB 流的RoI 特征,fN是噪聲流的RoI 特征。
1.6 Soft-NMS 算法
非極大值抑制算法[23]( Non - maximum suppression,NMS)是目標(biāo)檢測(cè)框架中的重要組成部分,主要用于去除冗余的建議框,找到最佳的目標(biāo)檢測(cè)位置。 具體做法是將RPN 推薦的建議框按照置信度得分排序,將得分最高的建議框作為候選框,刪除與該框重疊面積比例大于設(shè)定閾值的其他建議框。 為了解決在預(yù)設(shè)的重疊閾值之內(nèi)篡改區(qū)域檢測(cè)不到的問題,本文采用Soft-NMS[16]算法,該算法改良了傳統(tǒng)NMS 算法,對(duì)非最大得分的建議框檢測(cè)分?jǐn)?shù)進(jìn)行衰減,降低了目標(biāo)區(qū)域被漏檢的概率。
傳統(tǒng)的NMS 的分?jǐn)?shù)重置函數(shù)如下:
其中,si表示置信度分?jǐn)?shù);M表示當(dāng)前得分最高的候選框;bi表示建議框;iou(Intersection over Union)表示交并比;Nt表示iou閾值。
在Soft-NMS 算法中,建議框bi與候選框M重疊區(qū)域比例越大,出現(xiàn)漏檢的可能性就越高,相應(yīng)的分?jǐn)?shù)衰減應(yīng)該更嚴(yán)重,于是Soft-NMS 中的分?jǐn)?shù)衰減函數(shù)設(shè)計(jì)如下:
當(dāng)2 個(gè)建議框的iou大于設(shè)定的閾值時(shí),si的值就會(huì)相應(yīng)減小,降低了因徹底移除而造成漏檢的概率,從而達(dá)到檢測(cè)精度的提升。
1.7 損失函數(shù)
圖像經(jīng)過特征提取網(wǎng)絡(luò)的全連接層和softmax層之后得到了RoI 區(qū)域,還需要對(duì)這些RoI 區(qū)域做分類和邊框回歸。 總的損失函數(shù)如下:
其中,Ltotal表示總損失;LRPN表示RPN 網(wǎng)絡(luò)中的RPN 損失;Ltamper表示基于雙線性池化特征的交叉熵分類損失;Lbbox表示bounding box 回歸損失;fRGB和fN是來自RGB 和噪聲流的RoI 特征。
網(wǎng)絡(luò)的訓(xùn)練是端到端的,輸入的圖像和提取的噪聲特征的寬度調(diào)整為600 像素。 2 個(gè)支流RoI 池化后的特征維度均為7?7?1 024。 雙線性池化之后的特征尺寸為16 384。 訓(xùn)練過程中RPN 推薦的batch size是64,測(cè)試時(shí)設(shè)為300。 算法一共訓(xùn)練110 000 次,初始學(xué)習(xí)率設(shè)置為0.001,從第40 000步開始減小為0.000 1,Soft-NMS 的閾值設(shè)為0.2。
2 實(shí)驗(yàn)結(jié)果和分析
為了驗(yàn)證雙流卷積注意力網(wǎng)絡(luò)算法的有效性,本文在CASIA[24-25]、COVER[26]和Columbia[27]三個(gè)主流圖像數(shù)據(jù)集上評(píng)估算法的性能。 CASIA 數(shù)據(jù)集提供了多種物體的拼接和復(fù)制-粘貼操作,該數(shù)據(jù)集有CASIA 1.0 和CASIA 2.0 兩個(gè)版本,其中CASIA 1.0 包含800 張真實(shí)圖像和921 張篡改圖像,CASIA 2.0 包含7 491 張真實(shí)圖像和5 123 張篡改圖像。COVER 數(shù)據(jù)集是較小的復(fù)制-粘貼數(shù)據(jù)集,包含真實(shí)圖像和篡改圖像各100 張。 Columbia 數(shù)據(jù)集是未壓縮的拼接數(shù)據(jù)集,包含180 張拼接篡改圖像,183張真實(shí)圖像。 由于現(xiàn)有標(biāo)準(zhǔn)數(shù)據(jù)集的圖片數(shù)量仍然較少,尚不能滿足深度學(xué)習(xí)的訓(xùn)練過程,因此,本文在文獻(xiàn)[13]合成的數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,Zhou 等學(xué)者在COCO 數(shù)據(jù)集[28]中復(fù)制圖像內(nèi)容后粘貼到其他圖像上,復(fù)制的依據(jù)是圖像的分割標(biāo)注信息,真實(shí)圖像和篡改圖像各42 000 張。
2.1 評(píng)價(jià)指標(biāo)
本文使用F1分?jǐn)?shù)和AUC值來評(píng)估所提出的雙流卷積注意力網(wǎng)絡(luò)的性能。F1分?jǐn)?shù)是將精確率(P) 和召回率(R)結(jié)合的一種度量,精確率是指正確分類的正樣本個(gè)數(shù)占分類器判定為正樣本的樣本個(gè)數(shù)的比例,見式(9):
召回率指分類正確的正樣本個(gè)數(shù)占真正的正樣本個(gè)數(shù)的比例,見式(10):
F1分?jǐn)?shù)是精確率和召回率的調(diào)和平均值,見式(11):
其中,TP為正確檢測(cè)到的篡改像素?cái)?shù),F(xiàn)P為錯(cuò)誤檢測(cè)到的篡改像素?cái)?shù),F(xiàn)N為錯(cuò)誤檢測(cè)到的未篡改像素?cái)?shù)。
F1分?jǐn)?shù)越高,說明模型越穩(wěn)健。AUC值是ROC曲線下的面積值,AUC值的大小反映模型泛化能力,AUC值越大,模型泛化能力越強(qiáng)。
2.2 網(wǎng)絡(luò)預(yù)訓(xùn)練
本文將合成數(shù)據(jù)集的90%用來預(yù)訓(xùn)練,余下的用來測(cè)試。 訓(xùn)練的過程是端到端的,特征提取網(wǎng)絡(luò)分別對(duì)比使用了CBAM - ResNet101 和改進(jìn)的CBAM-ResNet101。 本文對(duì)比了文獻(xiàn)[13]的預(yù)訓(xùn)練結(jié)果,見表1,這里使用平均精度(Average Precision,AP) 進(jìn)行評(píng)估,結(jié)果表明精度有了明顯提升。 預(yù)訓(xùn)練之后,網(wǎng)絡(luò)需要在公共數(shù)據(jù)集上做進(jìn)一步訓(xùn)練,表2 給出了訓(xùn)練集和測(cè)試集的劃分。

表1 合成數(shù)據(jù)集平均精度比較Tab. 1 Comparison of the average accuracy of synthetic datasets

表2 訓(xùn)練集和測(cè)試集的劃分Tab. 2 The division of training and testing sets
表1 中,RGB Net 是一個(gè)單獨(dú)的RGB 網(wǎng)絡(luò),Noise Net 是單獨(dú)的噪聲流網(wǎng)絡(luò),RGB-N 是雙流網(wǎng)絡(luò),RGB-N+CBAM 為加入卷積注意力的算法,最后一行為是本文改進(jìn)的算法。 由表1 中數(shù)據(jù)可知,單一的RGB 流或噪聲流提取的信息有限,雙流網(wǎng)絡(luò)綜合RGB 流和噪聲流的特征信息后,平均精度有了明顯提升。 在雙流網(wǎng)絡(luò)中引入卷積注意力機(jī)制后,提取到的特征圖包含更豐富的篡改特征信息,經(jīng)過Soft-NMS 算法降低漏檢的概率后,平均精度有所提高。 改進(jìn)的注意力機(jī)制避免了降維帶來的副作用,更有效地利用了不同通道間的依賴關(guān)系,進(jìn)一步提升了網(wǎng)絡(luò)的特征提取能力。
2.3 結(jié)果對(duì)比
現(xiàn)有圖像篡改取證方法分為傳統(tǒng)算法和基于深度學(xué)習(xí)的算法,本文與以下方法進(jìn)行對(duì)比分析。
(1)ELA[29]:識(shí)別圖像中處于不同壓縮因子的區(qū)域的算法。 對(duì)于JPEG 圖像,整個(gè)圖像應(yīng)處于大致相同水平,如果某個(gè)區(qū)域壓縮因子明顯不同,則表示可能被篡改。
(2)CFA1[30]:基于CFA 模型的評(píng)估算法。 利用相鄰像素來估算彩色濾波器陣列并推理出篡改區(qū)域。
(3)MFCN[9]:基于邊緣強(qiáng)化的多任務(wù)圖像被動(dòng)取證框架。
(4)RGB-N[13]:融合噪聲信息的雙流神經(jīng)網(wǎng)絡(luò)算法。
(5)RGB+ELA[31]:基于雙流Faster R-CNN 的像素級(jí)圖像拼接篡改定位算法。
本文采用F1分?jǐn)?shù)和AUC值對(duì)比上述5 種算法,結(jié)果見表3、表4。 表3、表4 的數(shù)據(jù)表明,基于深度學(xué)習(xí)的算法優(yōu)于傳統(tǒng)特征提取算法,原因是ELA 和CFA1 算法都只關(guān)注單一篡改特征,并且不能包含全部篡改信息。 在深度學(xué)習(xí)算法中,本文所提算法表現(xiàn)優(yōu)于MFCN,在CASIA 和COVER 數(shù)據(jù)集表現(xiàn)優(yōu)于RGB-N。 MFCN 性能較差的原因是采用小尺寸卷積核和上采樣操作導(dǎo)致底層特征損失,因此對(duì)小區(qū)域篡改不敏感。 RGB-N 采用大小不同的錨框(anchor)進(jìn)行定位,較小區(qū)域的篡改也可以被檢測(cè)到,本文在特征提取模塊引入改進(jìn)的CBAM 注意力機(jī)制,并在預(yù)測(cè)時(shí)采用Soft-NMS 降低漏檢概率,檢測(cè)結(jié)果在3 個(gè)數(shù)據(jù)集上都有所提升。 文獻(xiàn)[31]通過將SRM 濾波器替換為錯(cuò)誤等級(jí)分析算法使提取到的噪聲信息包含更多篡改信息,并添加一個(gè)預(yù)測(cè)分支做到了像素級(jí)分類。 相比文獻(xiàn)[31],本文算法在Columbia 數(shù)據(jù)集上略優(yōu),由于CASIA 數(shù)據(jù)集拼接區(qū)域較為復(fù)雜,并且錯(cuò)誤等級(jí)分析對(duì)篡改特征的提取效果優(yōu)于SRM,故本文算法性能略低于文獻(xiàn)[31]算法。 因?yàn)镃OVER 數(shù)據(jù)集是復(fù)制粘貼數(shù)據(jù)集,所以來自噪聲流提供的特征信息幾乎失效,因此在該數(shù)據(jù)集表現(xiàn)較差。
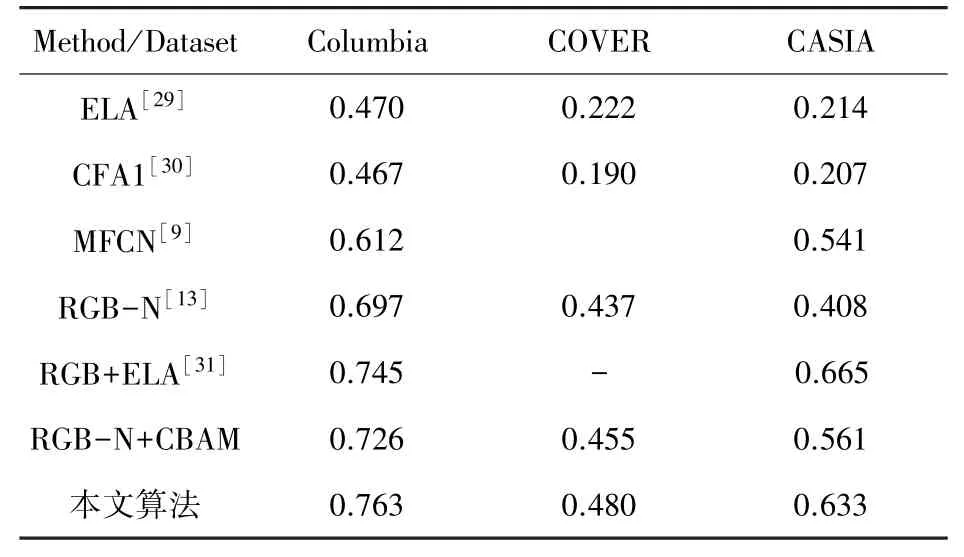
表3 3 個(gè)公共數(shù)據(jù)集F1 分?jǐn)?shù)對(duì)比Tab. 3 Comparison of F1 scores from three public datasets

表4 3 個(gè)公共數(shù)據(jù)集AUC 值對(duì)比Tab. 4 Comparison of AUC values for three public datasets
2.4 檢測(cè)結(jié)果分析
本文算法篡改檢測(cè)定位效果如圖8 所示。 圖8中,(a)表示拼接篡改圖像,(b)表示ground-truth,(c)表示文獻(xiàn)[31]算法檢測(cè)定位結(jié)果,(d)表示RGBN+CBAM 定位結(jié)果,(e)表示RGB-N+I(xiàn)CBAM 定位結(jié)果。 圖像均來自于CASIA 1.0 數(shù)據(jù)集。 可視化結(jié)果顯示,對(duì)于拼接邊緣較為簡(jiǎn)單且篡改部分相對(duì)較小的區(qū)域如第3 列和第6 列,文獻(xiàn)[31]所提算法和本文算法都能給出較為精確的定位結(jié)果,而對(duì)于拼接邊緣較為復(fù)雜、且篡改部分相對(duì)較大的區(qū)域,文獻(xiàn)[13]給出的可視化結(jié)果表現(xiàn)欠佳,也會(huì)存在未檢測(cè)到的區(qū)域和檢測(cè)錯(cuò)誤的區(qū)域,本文算法則給出了篡改區(qū)域的矩形范圍。 改進(jìn)后的注意力通過有效的通道注意力使提取到的篡改痕跡更加豐富,體現(xiàn)在可視化結(jié)果中表現(xiàn)為定位的矩形區(qū)域更加接近Ground Truth。

圖8 拼接篡改定位可視化Fig. 8 Visualization of image splicing detection
2.5 魯棒性分析
為了驗(yàn)證本文算法的魯棒性,在CASIA1.0 數(shù)據(jù)庫上利用質(zhì)量因子QF =70 和QF =50 對(duì)圖像進(jìn)行JPEG 壓縮,表5 給出了本文算法、文獻(xiàn)[13]和文獻(xiàn)[31]所提算法的F1分?jǐn)?shù)對(duì)比。 結(jié)果顯示,在QF =70 時(shí),RGB-N 性能下降了23.0%,文獻(xiàn)[31]所提算法性能下降了27.9%,在QF =50 時(shí),RGB-N 性能下降了26.3%,文獻(xiàn)[31]所提算法性能下降了31.7%,而本文所提算法通過在通道和空間維度對(duì)篡改痕跡進(jìn)行更有效的特征提取,在QF =70 和QF =50 的情況下對(duì)比未壓縮時(shí)分別下降17.7%和25.6%。 從表5 中可以進(jìn)一步看出,除了在未壓縮時(shí)F1分?jǐn)?shù)略低于文獻(xiàn)[31]的算法,本文所提算法在2 種不同的質(zhì)量因子情況下性能均優(yōu)于現(xiàn)有算法,說明本文算法能夠更好地抵抗JPEG 壓縮攻擊。

表5 不同壓縮因子下算法的F1 分?jǐn)?shù)Tab. 5 The F1 score of the algorithm under different compression factors
3 結(jié)束語
本文提出了一種雙流卷積注意力網(wǎng)絡(luò)對(duì)圖像篡改區(qū)域進(jìn)行檢測(cè)和定位。 首先,改進(jìn)的卷積注意力機(jī)制能夠抑制圖片中無效信息,使提取到的特征更好地刻畫偽造特性,雙流網(wǎng)絡(luò)加入噪聲域信息可以學(xué)習(xí)更多豐富的特征;其次,通過引入Soft-NMS 算法降低了偽造區(qū)域漏檢的概率,提升了拼接篡改的檢測(cè)精度。實(shí)驗(yàn)結(jié)果表明,本文算法的檢測(cè)性能優(yōu)于一些現(xiàn)有算法,且對(duì)JPEG 壓縮也具有較好的魯棒性。 本文算法尚不能做到像素級(jí)定位,未來的工作將考慮改進(jìn)當(dāng)前網(wǎng)絡(luò),進(jìn)一步精準(zhǔn)定位篡改區(qū)域。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
