基于MD&A多文本特征的財務風險預警模型研究
2023-03-02 12:15:06喬冰琴段全虎趙丹
會計之友 2023年5期
喬冰琴 段全虎 趙丹
【摘 要】 以2017—2020年滬深主板A股非金融上市公司為樣本,提取其年報MD&A章節中反映不同文本特征的多個文本指標,并引入上市公司財務風險預警模型。采用人工神經網絡和卷積神經網絡兩種方法對模型的預測能力進行實證。結果表明,在常規財務風險預警模型中引入MD&A多文本特征可提升模型預測的AUC值。在此基礎上繼續增加融資約束、財務困境指數測度、非效率投資程度和過度負債程度等指標,模型預測的AUC值提升更顯著。對比兩種實證方法得到結論:基于卷積神經網絡方法的MD&A多文本特征上市公司財務風險預警模型的預測能力更高、誤報率和漏報率更平衡。
【關鍵詞】 管理層討論與分析; 財務風險預警; 卷積神經網絡; 文本分析
【中圖分類號】 F275? 【文獻標識碼】 A? 【文章編號】 1004-5937(2023)05-0016-08
一、引言
數據對于我國當前數字經濟發展、數字產業化、產業數字化的重要性不言而喻。傳統的數據主要以結構化數據形式進行存儲和提取。“大智移云物”等新技術的深入發展及場景化應用,極大豐富了非結構化數據的形式,擴大了非結構化數據的數量。非結構化數據的主要呈現形式有文本、圖片、視頻、日志等,其中,文本作為非結構化數據的重要組成部分,頻繁地出現在社交網絡、新聞媒體、政府文件、公司公告、公司年報及數字出版物等各類載體中。
劉云菁等[1]指出,財務與會計領域的文本數據具有較高的研究價值,可基于特定技術從文本數據中挖掘出情緒、隱含語義、文本可讀性和相似度等,以增強和改進傳統的預測分析與因素分析。胡楠等[2]基于上市公司年報中的管理層討論與分析(Management Discussion and Analysis,MD&A)章節進行管理者“短期視域”文本提取,并對管理者短視是否會影響企業長期投資進行了研究。苗霞等[3]研究了財務報告前瞻性信息中的管理層超額樂觀語調對企業財務危機預測的價值,隨后苗霞[4]又研究了上市公司年報中的管理層語調和相關媒體報道對企業財務危機預測的影響。趙納暉等[5]基于上市公司文本型年報中的MD&A章節建立了識別企業財務報告舞弊模型。
綜上可知,從文本中提取和挖掘信息用于企業經營預測和決策,已是當前數字經濟時代眾多學者的研究方向。而年報MD&A章節的文本更是暗含了企業管理層對企業現狀和未來發展的態度、情緒傾向、語調語義等特征,這對于企業財務風險預測的價值更是不容小覷。基于此,本文將從年報MD&A章節中提取出多個反映文本隱含語義特征的指標,并引入企業財務風險預警模型;同時,將反映企業融資約束、財務困境指數測度、非效率投資程度及過度負債程度等指標也引入財務風險預警模型,實證分析多文本分析指標和多樣化指標對模型預測能力大小的影響,分別以人工神經網絡(Artificial Neural Network,ANN)和卷積神經網絡(Convolutional Neural Networks,CNN)兩種方法進行實驗。結果表明,引入多文本指標及增強指標多樣化均能顯著提升財務風險預警模型的預測能力,并且基于卷積神經網絡方法的模型的誤報率和漏報率更加平衡。
二、文獻回顧與理論分析
國內外對財務風險預警的研究主要集中在計量工具及模型的改進研究方面。國外財務風險預警模型從1932年Fitzpatrick以財務比率預測財務困境開始,歷經1966年Beaver建立的單變量模型、1968年Altman建立的多元判別分析Z模型,到1980年Ohlson建立的Logit回歸模型、1988年Franco et al.建立遺傳算法財務風險預測模型、1990年Sharda et al.建立BP神經網絡財務困境預測模型,1997年Martin建立邏輯回歸財務困境預測模型,再到1998年Bradley et al.建立的支持向量機財務困境預測模型等過程,財務風險預測模型從傳統模型轉向現代模型,從單變量分析轉向多變量分析,從單純的財務指標分析轉向基于財務指標和非財務指標的分析[6-7]。
國內財務風險預警模型研究相對于國外起步較晚,受限于數字技術應用成熟度,國內財務風險預警模型多是基于結構化數據庫中的數值類財務指標進行研究。1996年周首華等建立了F分數模型,2007年鮮文鐸等建立了混合Logit模型,2009年郭德仁等建立了模糊聚類預測模型[6-7]。
隨著現代數字技術的迅猛發展,將文本數據引入財務風險預警模型無論在文本數據來源還是在模型構建技術方面都具備了充分的條件。陳藝云等[8]從公司年報MD&A章節提取文本特征詞構建公司經理人違約傾向指標,進而與財務數值指標一起構建財務困境預測模型,并分別采用Logistic回歸和SVM方法對模型進行實證。隨后,陳藝云[9]又從管理層語調角度實證了文本分析能對財務困境預測提供增量信息,提高預測準確性。梁龍躍等[10]在前人研究的基礎上,進一步提取了上市公司年報中MD&A章節和審計報告章節的文本特征,構建兩種文本指標和財務數值指標融合的財務風險預警模型,并分別采用Logistic回歸、XGBoost決策樹、人工神經網絡及卷積神經網絡四種方法對模型預測效果進行驗證。
對上述文獻從財務風險預警模型指標體系構成、財務風險預警模型訓練方法兩個方面進行分析,并提出本文的研究內容。
(一)財務風險預警模型指標體系
從文本中提取與企業財務風險預警相關的文本指標,并將其納入到財務風險預警指標體系中,均能有效提高財務風險預警模型的預測能力,但同時也可以發現以下問題。其一,上述文獻在財務風險預測模型中引入的文本指標大多為1至2個,相比十幾個乃至幾十個財務數值指標而言,文本指標所占的比重及所起的作用并不明顯。其二,模型所涉及的財務指標多是單純的財務指標,而能對企業經營進行多方面、多維度刻畫的內部治理指標、違約風險指標等非財務指標應用不多。其三,將融資約束、財務困境指數測度、非效率投資程度及過度負債程度等經營困境類指標應用于財務風險預測模型的討論也相對較少。故而上述模型并不能全面地反映企業所處的經營內外部環境可能給企業財務帶來的風險。
(二)財務風險預警模型訓練方法
在模型訓練方法方面,上述文獻的很多作者采用了神經網絡、決策樹、遺傳算法、支持向量機等方法訓練財務風險預警模型,個別作者采用深度學習方法提取文本和訓練模型。然而深度學習發展迅猛,新技術和新方法不斷迭代更新。將性能更優、用法更簡單的深度學習技術引入財務風險預警模型,這將對提升模型預測能力大有裨益,將給企業財務風險發現和預警帶來更多機會。
基于上述分析,本文擬從擴大文本指標數量和增選融資約束、財務困境指數測度、非效率投資程度及過度負債程度等指標入手,建立兩種企業財務風險預警模型:(1)融合多文本指標和常規財務指標的財務風險預警模型;(2)融合多文本指標、融資約束指標、財務困境指數測度指標、非效率投資程度指標及過度負債程度指標、常規財務指標的財務風險預警模型。
同時,鑒于深度學習強大的性能及Python的Keras深度學習庫的簡潔易用等特點,本文將基于Keras分別構建多層Dense堆疊神經網絡模型和Convolution1D卷積神經網絡模型,對多文本指標及多樣化指標是否能夠提高財務風險預警模型的預測能力進行實證檢驗。在檢驗過程中,對模型1和模型2的預測效果進行對比分析,評測多文本指標和融資約束指標、財務困境指數測度指標、非效率投資程度指標及過度負債程度指標在提升企業財務風險預警模型預測能力方面的價值。
三、指標設計
下面說明本文構建的財務風險預警模型所選取的指標及其含義。
(一)常規財務風險預警模型指標的選取
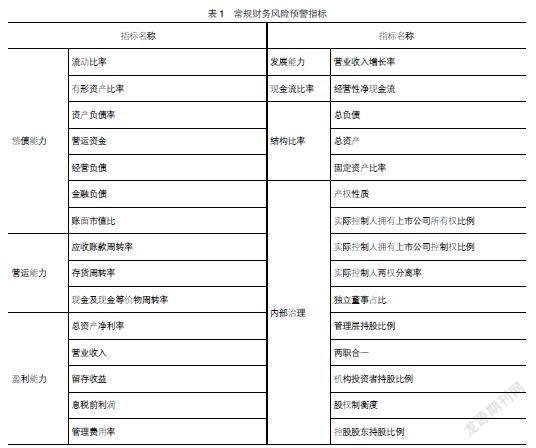
根據已有文獻的研究思路,選取常規的可以用作財務風險預警的指標作為本文財務風險預警模型的基本指標組成。考慮到深度學習優秀的數據特征挖掘能力,盡可能選取更多的常規財務風險預警指標及公司內部治理指標來描述企業財務風險特征。表1所示為選取的常規財務風險預警指標,包括償債能力、營運能力、盈利能力、發展能力、現金流比率、結構比率和內部治理7類30個指標。
(二)文本指標的選取
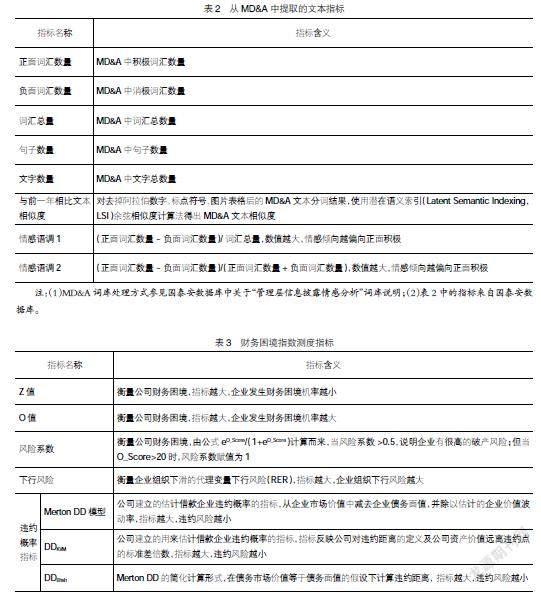
從公司年報MD&A章節中提取多種文本特征,旨在從不同角度反映MD&A章節所蘊含的管理層情緒和態度等信息。選取的文本指標如表2所示。
其中,正面詞匯數量、負面詞匯數量、詞匯總量、句子數量、文字數量是基礎指標,而與前一年相比文本相似度、情感語調1、情感語調2是進一步計算得到的指標。兩類指標均納入本文構建的財務風險預警模型,利用深度學習技術自動學習指標特征及指標關系,以期得到更好的模型。
(三)融資約束、財務困境指數測度、非效率投資程度及過度負債程度指標的選取
影響企業陷入財務困境和經營困境的因素有很多,融資約束、財務困境指數測度、非效率投資程度、過度負債程度等都會對企業財務及經營產生一定的影響。
1.融資約束指標的選取
當企業融資管理出現效率缺口時,企業的債務違約風險增加,進而使得財務風險增加,企業陷入財務困境的可能性也將增大。為體現融資約束對財務風險預警模型的影響,本文創新性地將目前在融資約束研究中占主流的、衡量融資約束的四項指數——SA指數、KZ指數、WW指數和FC指數引入模型,由深度學習技術自動刻畫融資約束特征對企業財務風險預警模型的影響。
2.財務困境指數測度指標的選取
在傳統的財務困境研究中,Z_Score模型、O_Score模型、RLPM模型及Merton DD模型常用于對企業財務困境的評價。為豐富本文所建模型,提取出這四種模型中的常用指標,與本文的常規財務指標和多文本分析指標相結合,構建財務風險預警模型,以提升本文所建模型的預測能力。財務困境指數測度指標如表3所示。
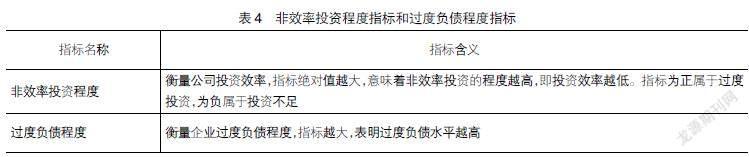
3.非效率投資程度指標及過度負債程度指標的選取
投資過度及投資不足構成的非效率投資也是造成企業出現財務風險的因素之一。非效率投資程度是基于相關財務指標分年度進行OLS回歸,模型估計的殘差絕對值為公司非效率投資程度。殘差絕對值越大,意味著非效率投資的程度越高,即投資效率越低。殘差為正表示過度投資,殘差為負表示投資不足。本文選取非效率投資程度指標納入企業財務風險預警模型,以提升財務風險預測效果。
過度負債程度是實際負債率減去目標負債率的差額,其中,實際負債率為賬面資產負債率,用總負債與總資產的比值來計算;目標負債率為通過Tobit回歸方法對實際負債率、產權性質、權益凈利潤、資產負債率、總資產增長率、固定資產占比、公司規模、公司第一大股東比率分年度進行回歸得到。過度舉債會加劇企業財務風險,而高財務杠桿也是企業出現財務風險的因素之一。因此,本文將過度負債程度指標也納入上市公司財務風險預警模型。
非效率投資程度指標和過度負債程度指標如表4所示。
四、模型構建與訓練
為驗證本文所選取的MD&A多文本指標(下文標記為①)、融資約束指標、財務困境指數測度指標、非效率投資程度指標和過度負債程度指標(下文標記為②)對財務風險預警模型的作用,下面分別構建(1)融合①和常規財務指標的財務風險預警模型、(2)融合①、②及常規財務指標的財務風險預警模型,并分別采用多層Dense堆疊神經網絡和1維卷積神經網絡進行實證。
(一)樣本選擇
本文所有數據均來自國泰安數據庫。選擇2017—2020年滬深兩市主板A股上市公司為研究樣本,剔除金融類企業,剔除缺失數據比率超過30%的企業。
借鑒已有的研究思路,將上市公司被ST作為其陷入財務困境的標志。同時,鑒于上市公司陷入財務困境是一個動態的、持續變化的過程和狀態,即大多數公司在被ST之前都會經歷財務風險增加直到陷入財務困境,因此,財務異常樣本集定義為t年被ST公司的t-1年至t-4年的年度數據。最終得到623條財務異常樣本數據。
對于財務正常樣本的選取,按照ST與非ST行業匹配、規模匹配及樣本量比率為1■1的原則,同樣取得623條財務正常樣本。所有樣本共計1 246條。
(二)財務風險預警模型構建
1.融合①和常規財務指標的財務風險預警模型
此模型包括的指標主要是表1所示的30個常規財務風險預警指標和表2所示的8個MD&A文本特征指標,共計38個指標。
2.融合①、②及常規財務指標的財務風險預警模型
此模型包括的指標主要是表1所示的30個常規財務風險預警指標、表2所示的8個MD&A文本特征指標、融資約束及表3的財務困境指數測度和表4的非效率投資程度與過度負債程度等13個指標,共計51個指標。
(三)實證方法選擇
參考梁龍躍等[10]使用的財務風險預警模型訓練方法,本文引入人工神經網絡和卷積神經網絡兩種方法完成財務風險預警模型的訓練,以期得到更有效、性能更好的財務風險預警模型。文中所有實證均基于Python的Keras深度學習庫完成。實驗環境采用Anaconda3,conda版本是4.10.1,Python版本是3.8.8,Jupyter Notebook版本是6.3.0,Keras版本是2.7.0。
1.多層Dense堆疊神經網絡
Dense是Keras中的全連接(Fully Connection)層,也叫密集連接層(Densely Connected Layer)或密集層(Dense Layer)。由多個Dense層連接形成的神經網絡模型稱為Dense堆疊神經網絡模型。
由于財務風險預警模型的數據量較小,指標特征相對也較少,因此,Dense網絡僅需4層即可完成模型訓練。同時,為降低過擬合,前三個Dense層后各接一個Dropout層,最后一個Dense層采用sigmoid激活函數完成輸出分類即可。
2.Convolution1D卷積神經網絡
Convolution1D是Keras中的一維卷積神經網絡模型,對于文本分類、時間序列等簡單任務,構建小型的Convolution1D網絡可以使模型訓練速度更快。一維卷積層可以從財務風險預測樣本中提取局部樣本特征,并能利用一維卷積神經網絡的平移不變性將提取到的特征在樣本其他位置進行識別。
CNN常用于圖像領域。由于圖像的特征維度很高,為減少特征數量,CNN層常與最大池化層連接,通過最大池化層的下采樣達到降低維度和擴大卷積層觀察窗口的作用。同時,對于具有高維特征的圖像而言,最大池化層的下采樣也基本不會影響圖像識別結果。而將CNN應用于本文的財務風險預警模型時,由于模型的特征指標數量很少,且每個指標都各有其意義,因此,針對財務風險預警模型的這一特性,本文在設計CNN模型時,沒有使用最大池化層,僅在各卷積層下接Dropout層以降低過擬合。
同樣,由于財務風險預警模型較小,故CNN模型僅需4層,每層卷積核大小為3;每個卷積層后接一個Dropout層。最后對卷積輸出進行展平,在其后再接一層Dense層,利用Sigmoid激活函數完成輸出分類即可。
(四)實驗步驟
實驗步驟如圖1所示。
(五)實驗結果
為了對比本文所建財務風險預警模型與已有模型的預測效果,分別建立如表5所示的四種財務風險預警模型,所有模型均在相同的樣本集上選擇如表5所示的指標數據。
分別以Dense堆疊網絡和Convolution1D卷積神經網絡對表5中的4種預警模型進行訓練,所得模型在測試集上的AUC值(Area Under Curve,ROC曲線下面積)和混淆矩陣比較如表6所示。
五、結果分析
(一)四種財務風險預警模型對比
下面分別從財務風險預警模型指標體系構成和實證方法兩方面對這些模型的預測效果進行對比分析。
1.從模型指標體系構成方面進行對比
(1)AUC值對比
在深度學習中,AUC是非常重要的檢測模型好壞的指標,AUC值越接近1,表示模型預測能力越高。從表6可以看出,無論是以Dense堆疊網絡還是Convolution1D網絡建立的預警模型,其M1到M4的AUC值均在不斷升高,這意味著預警模型的預測能力在不斷提升。
在Dense訓練的預警模型中,相比M1,M3的AUC提升是因為增加了8個MD&A多文本指標;相比M2和M3,M4的AUC提升是因為M4包含了全部51個指標。同理,在Convolution1D訓練的預警模型中,相比M1,M3的AUC提升是因為增加了8個MD&A多文本指標;相比M2和M3,M4的AUC提升是因為M4包含了全部51個指標。
(2)漏報率與誤報率對比
預測模型中,漏報率(FNR)是指將有風險的公司預測為無風險的比率;誤報率(FPR)是指將無風險的公司預測為有風險的比率。降低預警模型的這兩類錯誤是判斷模型好壞的標準之一。
從表6可以看出,以Dense訓練的四種預警模型中,M4模型的FNR與FPR之和(0.32)最低,并且相對持平(FNR與FPR相差0.02),說明M4模型預測的兩類錯誤率較低且比較平衡。以Convolution1D訓練的四種預警模型中,M4模型的FNR與FPR之和(0.33)稍高于M2模型(0.32),但M4模型比M2模型的預測要平衡得多(M4模型的FNR與FPR相差0.01),說明M4模型預測比較平衡。
由此得知,將MD&A中提取的多文本特征引入上市公司財務風險預警模型,能有效提高模型的預測能力,印證了出自企業內部管理層之手的MD&A章節文本內容能夠體現管理層對企業未來的主觀判斷。同時,擴充指標后的模型表現出更好的風險預測能力,印證了模型指標類型越豐富、數量越多,其預測風險的能力也越高,結果越穩定。因此,構建上市公司財務風險預警模型時,合理加入MD&A的多文本特征及一些通過建模和計算得到的復合型指標來提升模型預測能力是可行和可靠的。
2.從實證方法方面進行對比
(1)AUC值對比
從表6可以看出,相比Dense訓練的四種預警模型,Convolution1D訓練的四種預警模型的AUC值分別高出0.027、0.030、0.026、0.017,說明Convolution1D比Dense訓練的效果好。這表明Convolution1D比Dense更能挖掘出上市公司的財務風險特征,更適合作為財務風險預警模型訓練的方法。不過模型優勢不是絕對的。通過交叉對比分析可以看出,指標數量不斷增加及指標含義更加豐富都可以彌補訓練方法的缺陷。比如,Dense訓練的M3模型使用了38個指標,其AUC值為0.887,超過了Convolution1D訓練的M1模型的AUC值,但是優勢特別微弱,僅為0.001。而當Dense訓練的M4模型的指標數量增加至51個時,其AUC值達到了0.903,超過Convolution1D訓練的M1模型的AUC值(超過0.017),模型優勢進一步擴大,說明指標的豐富程度能夠影響模型的預測能力。
(2)漏報率與誤報率對比
Convolution1D訓練的模型比Dense訓練的模型在預測時要更加平衡。對于M3模型,Dense網絡的FNR與FPR之和(0.33)小于Convolution1D網絡的FNR與FPR之和(0.36),但Dense網絡的FNR與FPR之差(0.17)遠大于Convolution1D網絡的FNR與FPR之差(0.06)。不過,指標的豐富程度降低了這種差異,對于M4模型,Dense網絡的FNR與FPR之和(0.32)及之差(0.02)幾乎與Convolution1D網絡的FNR與FPR之和(0.33)及之差(0.01)持平。
(二)與其他文獻對比
在同一領域的研究中,梁龍躍等[10]基于BERT-AE提取MD&A文本特征和審計報告文本特征,并分別使用Logistic回歸、XGBoost、ANN及CNN訓練加入兩種文本特征的財務預警模型,最終使模型的AUC值分別達到0.8577、0.8961、0.8757和0.8777。與本文所建的基于Convolution1D網絡的M3和M4模型相比,本文這兩個模型的AUC值均高于該文獻所有模型的AUC值。
袁美芬[11]所建預警模型共有45個財務和非財務指標,其中包含了“審計意見類型”指標,模型基于人工神經網絡進行訓練,在T-5時間步樣本集上得到0.901的AUC值。而在本文的前期實驗中,曾專門將審計報告中的審計意見類型提取并量化后加入到M4模型中,在Convolution1D方法的訓練下,M4模型的AUC值高達0.996,這印證了審計意見類型與企業是否陷入財務困境、是否可能被帶上ST帽子有著非常緊密和直接的聯系。然而審計意見類型由企業外部獨立的專業審計機構提供,不依賴外部審計而從企業內部管理層視角來測度財務風險,這對企業未來的可持續發展具有更為重要的意義。因此,本文所建的M3和M4模型沒有包含審計意見類型指標。但即便不包括對財務風險預測影響如此之高的指標,本文所建的基于卷積神經網絡訓練的M3和M4模型的AUC值也優于袁美芬[11]所建模型。
湯惠蓉[12]建立的基于深度學習網絡的預警模型用到27個純財務數值指標,其模型在T-3時間步上達到的AUC值為0.783,遠低于本文基于Convolution1D的M3模型和M4模型的AUC值。
與上述文獻的AUC值對比如表7所示。
六、結論
管理層討論與分析是上市公司年報中重要的信息披露部分,能夠體現企業內部管理層對未來的預期。將從MD&A章節提取的多文本指標加入常規財務風險預警指標體系可以提升模型預測的準確性。本文構建了基于MD&A多文本特征的上市公司財務風險預警體系,并分別用Dense網絡和Convolution1D網絡實證這兩種模型的預測能力。結論如下:
1.從MD&A章節提取的多文本特征可以提升上市公司財務風險預警模型的預測能力。文本分析技術能夠挖掘MD&A章節的文本特征,展示管理層語調和情緒,提升風險預警的敏感度。從MD&A章節提取的正面詞匯數量、負面詞匯數量、詞匯總量、句子數量、文字數量,以及經過處理的與前一年相比文本相似度、情感語調1和情感語調2等文本特征,能夠體現企業管理層甚或高層對于企業未來發展的信心、態度以及預期。實證表明,將MD&A多文本特征加入上市公司財務風險預警模型指標體系明顯提升了模型的預測能力。
2.豐富財務風險預警模型的指標體系可以提升模型的預測能力。在常規財務風險預警指標體系中,依次加入①指標、②指標,實證發現模型的AUC值不斷提升。②指標均是從融資管理、投資管理和風險角度選取的、經過一定計算得到的復合指標,其本身具有反映財務困境的能力,融入本文模型后,表現出有效的模型預測提升能力。
3.實證表明,深度神經網絡比傳統機器學習方法更能提升財務風險預警模型的預測能力,而卷積神經網絡比人工神經網絡更能提升財務風險預警模型的預測能力。Python的Keras深度學習庫提供了功能強大、簡單易用的深度學習工具包,它使模型的構建和訓練更加容易,僅需十幾行代碼就能完成財務風險預警模型的訓練,這為企業應用實踐財務風險預警模型預判可能的財務風險提供了便利性和靈活性,為企業日常經營決策活動提供了智能支持。
數字經濟時代,更多的企業經營信息以非結構化信息的形式涌現出來,充分挖掘這些信息間隱含的關聯,更精準地刻畫企業財務特征、更及時地為企業提供財務預警、更智能地輔助企業決策是未來一段時間的重要研究內容。同時,鑒于深度學習強大的性能,未來可以構建更加多樣化、維度更豐富的財務風險預警指標體系,使預警模型更加健壯,表征性更強,角度更全面。
【參考文獻】
[1] 劉云菁,張紫怡,張敏.財務與會計領域的文本分析研究:回顧與展望[J].會計與經濟研究,2021,35(1):3-22.
[2] 胡楠,薛付婧,王昊楠.管理者短視主義影響企業長期投資嗎?——基于文本分析和機器學習[J].管理世界,2021,37(5):139-156,11,19-21.
[3] 苗霞,李秉成.管理層超額樂觀語調與企業財務危機預測——基于年報前瞻性信息的分析[J].商業研究,2019(2):129-137.
[4] 苗霞.管理層語調、媒體報道與企業財務危機預測——基于年報前瞻性信息的分析[J].財會通訊,2019(27):17-21.
[5] 趙納暉,張天洋.基于MD&A文本和深度學習模型的財務報告舞弊識別[J].會計之友,2022(8):140-149.
[6] 朱永明,徐璐銘.引入社會責任的上市公司財務困境預測模型研究[J].商業研究,2015(3):92-97.
[7] 夏寧,宋學良.財務困境預測模型綜述[J].會計之友,2015(8):27-29.
[8] 陳藝云,賀建風,覃福東.基于中文年報管理層討論與分析文本特征的上市公司財務困境預測研究[J].預測,2018,37(4):53-59.
[9] 陳藝云.基于信息披露文本的上市公司財務困境預測:以中文年報管理層討論與分析為樣本的研究[J].中國管理科學,2019,27(7):23-34.
[10] 梁龍躍,劉波.基于文本挖掘的上市公司財務風險預警研究[J].計算機工程與應用,2022,58(4):255-266.
[11] 袁美芬.深度學習驅動的財務困境預測研究[D].南昌:江西財經大學碩士學位論文,2021.
[12] 湯惠蓉.基于深度學習的上市公司財務困境預測研究[D].南京:東南大學碩士學位論文,2020.
