
結合關鍵點和注意力機制的人員著裝檢測方法
2023-03-14 03:50:40孔華永聶志勇隋立林張金祿
重慶理工大學學報(自然科學) 2023年2期
孔華永,聶志勇,隋立林,張金祿
(1.國家能源集團信息公司 綜合自動化部, 北京 100011;2.武漢大學 測繪遙感信息工程國家重點實驗室, 武漢 430072)
0 引言
大規模集中工業化生產線可以提高工業生產效率和質量,在實際的工業生產環境中,工作人員的安全保障和監管系統對構建持續化高質量的工業生產系統有著至關重要的作用。其中,對于工作人員的著裝規范性檢測對防范安全事故尤為重要——比如在礦場的工作人員,如果不按照要求進行著裝,防護措施不到位將對工作人員生命安全和生產線造成不可挽回的損失。但是,目前關于工業生產場景下的安全監管系統大多數依賴人工完成,消耗了大量人力成本,并缺乏統一的規范化管理和評判標準。并且,工作人員著裝的檢測和監管具有出現頻率稀疏和持續時間短的特點,依賴人工的監管系統往往存在較多漏報,且無法滿足從海量視頻大數據信息中快速檢測篩選有效信息的需求。因此,人員著裝規范性檢測方法的研究具有十分重要的現實意義和應用價值。
人員著裝檢測首先要對人體進行檢測,目前的人員檢測方法往往依賴于現有的成熟的目標檢測技術,然后在目標檢測方案的基礎上進行細粒度的特征提取、分析和識別,使模型達到判斷人員是否規范著裝的目的。最初,傳統方法的監控系統中的目標檢測技術往往通過人工構建的幾何特征或紋理特征[1-3]完成對圖像的分析,但這種方法由于缺少數據驅動的特性,往往只能在部分常規場景中保持較好的效果,但在異常環境(如黑暗的礦井,多人互遮擋的入口處等)中的檢測效果會有漏檢、誤檢等嚴重問題。之后,隨著深度學習的發展,出現了很多基于神經網絡(neural network)的數據驅動方法,可以在大規模數據集中取得更好的效果。YOLO系列[4-7]方法作為一階段目標檢測方法的代表,由于其在效率和檢測質量上取得較好的平衡,因此在實際工業場景取得了廣泛的應用和推廣。對人體的檢測往往傾向于使用更快速的YOLO系列方法高效地獲取人體區域,從而可以對后續的各區域著裝規范性判斷進行更復雜、細致地處理,并保持實時性處理性能。此外,在人員著裝檢測任務中,主要面臨的問題是人體的互遮擋、人體姿態變化和尺度變化,精確的目標定位(便于人體不同區域的定位),密集和遮擋的目標檢測,加速檢測等問題,面對這些問題,需要魯棒性和針對性更強的設計方案。
在現階段的研究中,對于人員的著裝檢測,現有的方法往往將其視為目標檢測任務[8-11],即將畫面中的人體各部位(如頭部、腿部、軀干等)分別進行定位、裁剪,然后送入對應的神經網絡模型中進行檢測與識別。但這些方法會帶來3個問題:
首先,區域的定位操作往往是基于先驗知識和人體解剖結構對圖片中的信息進行的,雖然方式簡單,但無法有效處理下蹲、彎腰等復雜姿態情況,這會帶來人體區域定位準確度較低的缺陷,進而影響分類的精度。
其次,對于不同人體部位服裝的識別在特征提取過程中往往相互獨立,只在最后的分類層進行融合,或直接從整個人體區域進行提取。這種做法雖然有利于提升計算效率,但有些部位具有像素低、特征區分較弱的特點,因此不同部位(如胸部、腿部、肘部等)特征提取的互不相關會導致最終不同區域的檢測與分類難度提升。
最后,環境的復雜性和多變性(如光照、顏色等)對于人員著裝檢測的準確性有很大的影響,但這方面很少被關注。
針對上述人員著裝檢測領域存在的問題,對該任務進行深入調研,提出以下解決思路:
1)人體姿態估計算法可以從圖像或視頻當中估計人體各個關節的關鍵點,相比基于圖像的算法,人體姿態估計算法具有魯棒性高、對先驗知識的依賴性較低的特點,基于這種特點,人體區域的定位可以基于人體姿態估計方法進行,而不完全依賴先驗知識和人體解剖結構。
2)人體不同區域的特征提取應該是全局-局部交互進行的,而不只是從圖像的某一個區域或整幅圖像獲得特征,注意力機制具有對圖像全局建模的操作符(operator),并且具有出色的局部到全局的映射能力,因此本文考慮將注意力機制引入人員著裝檢測方法,優化人體不同區域的特征提取過程和建立不同區域的特征之間的交互關系。
3)由于人員著裝檢測方法落地的場景往往復雜度高、差異性大,但人員著裝具有高統一性的特點,因此對于圖像空間的預處理操作,將場景差異性和不同的背景語義信息進行統一是至關重要的,觀察到RGB-HSV色彩空間的轉換可以有效解耦圖像空間中的色調(hue)、飽和度(saturation)和亮度(value),在HSV空間可以對背景信息進行高效地過濾。
1 相關工作
1.1 目標檢測方法
近年來,隨著視頻監控系統的普及和成熟應用,海量的視頻數據被捕獲和分析。基于圖像處理的目標檢測方法得到快速發展,如在傳統方法中,目標檢測技術首先對圖像進行人工特征提取,常見的特征提取手段包括Harr (harr-like features) 方法[1],SIFT(scale invariant feature transform)方法[12]等。然后將提取到的特征送入分類器中進行分類,常見的分類器有SVM(support vector machine)[13]和AdaBoost[14]等。但傳統的目標檢測方法存在魯棒性較差、泛化性弱、時間復雜度高等缺陷,缺少數據驅動特性,導致其在大規模數據場景下的效果遠不如理論實驗效果。隨著深度學習的廣泛應用和卷積神經網絡(CNN)[15]的快速發展,自從深度神經網絡推廣后,目標檢測作為一項基礎視覺任務受到啟發,開始結合卷積神經網絡(CNN)進行研究。根據檢測結果的回歸過程,目前主流的目標檢測研究方法可以被分為兩階段和一階段2種方式,其中前者將檢測結果(檢測框)的獲取定義為一種從粗到細的精細化過程,而一階段方法將檢測任務結果定義為一步到位的流程,直接獲取檢測框。以R-CNN[16]為主的兩階段方法主張先提取候選框,然后再對候選框進行篩選和分類。YOLO是第一個基于深度學習方法的一階段檢測器。本文中使用了一個完全不同的檢測方案,即將單個神經網絡應用于整個圖像的檢測,將圖像直接回歸得到候選框。從驗證結果上看,YOLO系列工作相比R-CNN系列工作的最大不同在于YOLO系列[4-6]更好地兼顧了效率和精度的平衡。本文中使用了最新的YOLO系列版本即YOLOv4作為檢測任務的基準網絡。
1.2 人體姿態估計方法
人體姿態估計是一項從圖像或視頻中得到預先定義的人體關鍵點(如肘部、腿部、頭部等)的視覺任務。本文中僅考慮面向圖像的2D人體姿態估計算法。當前的研究工作大多數集中于多人場景,根據高級語義特征或低級圖像像素(即先檢測人體還是先檢測關鍵點),2D人體姿態估計方法可以被分為自上而下(top-down)方法和自下而上(bottom-up)方法。
自下而上(bottom-up)方法主張首先預測輸入圖像中每個人的身體部位,然后通過關鍵點匹配算法(如動態規劃、匈牙利算法、貪婪算法等)得到每個人的關鍵點姿態,根據不同的方法,檢測的最小單位可以是關節或肢體模板區域。而自上而下(top-down)方法主張首先檢測人體,將人體檢測進行裁剪、精細化等處理后,再對單個人體分別檢測關鍵點。AlphaPose[17]使用了檢測方法中常見的非極大值抑制(NMS)和沙漏網絡(hourglass network)[18]提高多人姿態估計的準確性。總的來說,自上而下方法通過將現有的檢測網絡和單個人體姿態估計網絡結合可以輕松實現自上而下的人體姿態估計方法,但是,這種方法的性能會受到人檢測結果的影響,并且實際推理速度(使用GPU設備)通常不是實時的。
綜上所述,自上而下和自下而上方法分別都取得了較好的表現并保持了各自的特點。但隨著圖像中人數的增加,自上而下方法的計算成本顯著增加,而自下而上方法則保持穩定。 但伴隨著人體互遮擋、低分辨率等問題,自下而上的方法將會有更大的精度損失。基于本任務中已有且必須具備的人體檢測功能,在本文方法中,將兩階段的自上而下方法(即檢測人體和單人姿態估計)進行解耦,利用檢測出的人體進行單人姿態估計得到每個人員的人體關鍵點,同時降低模型計算量,提高模型推理速度。在已有行人檢測結果的基礎上,本文的姿態估計方法可以接近自下而上方法的效率。
1.3 注意力機制
注意力機制(attention mechanism)目前已經被廣泛應用于計算機視覺領域的各項任務中(圖像分類、目標檢測、姿態估計等)[1-3,19-20]。圖像任務中的注意力機制相關的研究工作大多數使用掩碼矩陣作為圖像中注意力的表征形式。自注意力機制(self-attention)屬于注意力機制的一種,也是在圖像任務中最廣泛應用的注意力機制之一。在首先被ViT[1]應用于圖像分類任務后,在取得亮眼表現的同時,也促進了自注意力機制在視覺任務中的改進。對于圖像分類任務和目標檢測任務而言,注意力機制已經取得了非常矚目的成績,但自注意力機制尚未被很好地應用到人員著裝檢測任務當中。因此,本文也是第一個嘗試將自注意力融入到人員著裝檢測任務的基準方案中的,以使得網絡自適應地關注人員著裝分類的重點區域,從而提高著裝分類的整體精度。
2 算法設計與模型結構
2.1 任務定義與算法流程
人員著裝檢測方法的輸入為待檢測的圖像序列,幀率為25幀/s,對于輸入的每幅圖像,算法需要檢測人員所在區域并準確定位到人員的不同著裝部位(頭盔、工裝馬甲、工靴和除頭部以外的整體工裝),并對每個部位是否正確著裝進行判別,輸出多分類概率結果,對于著裝違規的人員,記錄日志信息(時間、相機設備編號、人員坐標、違規著裝圖片等)。人員著裝檢測算法是一個系統的,包含多個模型的多任務框架(人體檢測,2D人體姿態估計,局部圖像分類)。如圖1所示,本文的方法首先使用基于YOLOv4的人體檢測模型得到待檢測圖像序列中的人體區域,然后輸入到2D人體姿態估計算法中,得到每個人體區域的2D關鍵點,然后使用人體著裝定位得到每個人體要進行識別的區域,最終使用一個簡單的圖像分類網絡對著裝區域進行多分類,得到每個區域的分類結果。整個流程將人體著裝檢測任務解耦為多個子任務,由于解耦后的每個子任務都屬于較為通用的任務場景,因此大規模數據集預訓練模型的遷移學習效果很好,大大減少了算法的數據需求,同時可以保證數據驅動帶來的模型通用性和良好的泛化性。

黑色框為程序步驟,藍色框為算法調用的網絡模型
2.2 基于YOLOv4的人員檢測方法
本文的方法基于YOLOv4作為baseline,并結合YOLOv5方案的優點,在此基礎上根據實際情況進行具體模型的選擇和模型的修改。借鑒了YOLOv5中的Focus操作,具體來說,在1張圖片中間隔像素進行取值得到近鄰下采樣的結果,得到4張下采樣的圖片,4張圖片將輸入通道維度擴充了4倍,即由原始圖片的RGB三通道模式變成了12個通道,最后將得到的新圖片再經過卷積操作,最終得到了沒有信息丟失情況下的二倍下采樣特征圖。此外,由于傳統的SPP(spatial pyramid pooling)的多級卷積過程依然是檢測任務推理過程中的瓶頸,通過統一卷積核尺寸,應用一次卷積和分級池化的策略將SPP升級為SPPF(spatial pyramid pooling-fast),金字塔池化模塊可以進一步提高推理速度,降低了卷積層的計算量,網絡在實際訓練中的運算速度也得到提升。在訓練時,首先加載預訓練的YOLOv4權重,并修改最后一層的檢測結果,使其只檢測本文需要的結果,即行人類別,最后,在自己收集的小規模數據集上進行遷移學習,優化行人檢測的效果。此外,本文還添加了部分后處理操作,對圖像中的非規則人體、缺失人體或極小目標進行篩選,此過程基于檢測框比例和人體結構的先驗知識,無需占用計算量即可快速完成篩選。
2.3 基于人體姿態估計的區域定位方法
在基于人體姿態估計的區域定位方法部分,本文使用了基于AlphaPose的2D人體姿態估計網絡獲取每個人員的身體關鍵點,并基于獲得的人體關鍵點檢測結果和區域定位策略,準確定位不同姿態下的人體局部區域,從原圖裁剪各區域并輸入后續多級特征自注意力機制和多分類模型,實現著裝特征提取和違規工裝的識別。
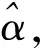
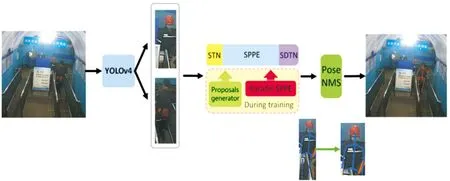
圖2 2D人體姿態估計方法
在得到人體姿態估計的結果后,對每個人體進行切分定位。如圖3所示,具體的各部位定位策略為:頭和脖子均被檢測到時定位到頭部區域,高度為頭部到脖子的距離適當擴增,寬度則根據左右肩部關節點與胸部關節點的中點進行定位;馬甲(上衣)定位由左右肩部和左右臀部進行確定;工靴定位則由左右膝蓋和左右腳部構成的矩形區域完成。
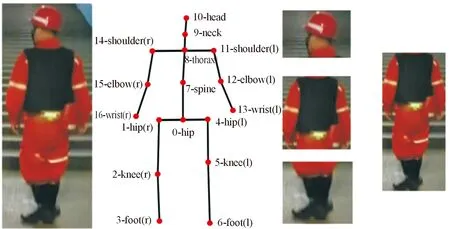
圖3 人體工裝定位示意圖
2.4 RGB-HSV空間變換預處理
使用RGB到HSV空間的變換對人體的整體區域進行篩選,為工裝分類提供輔助參考,該操作無需神經網絡參與,且操作簡單,計算量可以忽略不計。顏色空間又稱為彩色模型,以某些通常可以接受的方式對該空間中的所有色彩加以表示和說明。在顏色空間中,通常由3個獨立的屬性來描述顏色,常見的有 RGB、HSV、CMY、YUV 等[4]。在 RGB 顏色空間中,各顏色分量的數值越小表示亮度越低,數值越大表示亮度最高,各顏色分量的強度范圍為 0~255。任意顏色的 RGB 顏色空間構成的數學表達式為:
F=r[R]+g[G]+b[B]
(1)
HSV顏色空間是一種亮分離顏色空間,分別為色相(hue)、飽和度(saturation)和明度(value)。色相是色彩的基本屬性,在六角錐體模型中通過從0°~360°的不同角度來度量顏色。飽和度按照顏色與光譜色的接近程度來度量,也就是色彩的純度。某種光譜色與白色混合得到一種顏色,其中光譜色所占的比例愈大,顏色接近光譜色的程度就愈高,顏色的飽和度也就愈高。明度用于衡量顏色明亮的程度,當衡量光源的顏色時,發光物體的明亮程度決定了明度值的大小。
通過RGB-HSV轉換后,可以輕易地利用色彩、亮度和飽和度對人員整體著裝區域進行區分,以獲取第一步判別(即整體工裝是否穿戴正確)的結果(如圖4所示),該操作無需任何神經網絡參與,基于現有工裝的先驗特征即可設定合適的色相、飽和度、明度的閾值進行篩選,所需計算量可以忽略不計。通過RGB-HSV預處理篩選的結果可以輕易識別整體工裝是否正確,當判別結果為不正確時,本文方法直接進行報警記錄。這樣既可以實現不依賴神經網絡模型的快速檢測,提高檢測效率,同時又可以一定程度上避免模型過擬合帶來的低泛化能力。

圖4 RGB-HSV變換預處理效果
2.5 基于注意力機制的多區域特征提取和分類
在各區域工裝判別分類階段,在圖像分類模型之前引入自注意力機制,通過訓練學習少量額外參數,使分類模型將注意力集中于輸入工裝部位中的重要區域,從而提升違規著裝識別的準確率。如圖5所示,對于自注意力模塊,基于ViT[21]的圖像任務處理模式,將輸入圖像的不同區域視為不同的切塊,使用padding填充和雙線性插值的方式將圖像上采樣到相同大小。經過以上預處理步驟后,再將得到的4個切塊進一步切分(每個切塊切分為4個小patch)得到16個patch,通過一個由全連接層構成的線性嵌入層(linear embedding layer)映射到高維特征空間,輸入到多頭自注意力機制計算相互之間的注意力掩碼矩陣,賦給原始patch映射的高維特征。將添加過注意力的圖像維特征恢復到原始大小,輸入到一個簡單的 Resnet-50[22]網絡中,添加全連接分類層(共8類),得到最終的分類結果。
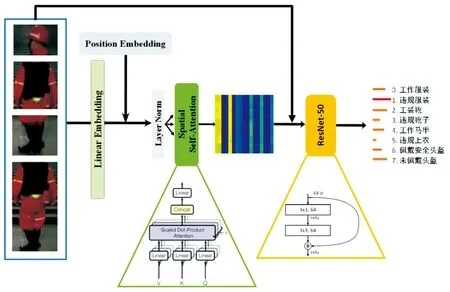
圖5 工裝分類模型框架與網絡結構
3 實驗及結果分析
3.1 數據集和實驗配置
所有實驗均在單張NVIDIA RTX 2080Ti上進行,代碼基于Pytorch構建,系統環境為Ubuntu 18.04。公平起見,本文的實驗在公開數據集MSCOCO上測試人體檢測的效果,并在本文自定義的工裝數據集中驗證最終的工裝檢測效果。
3.2 MSCOCO數據集
使用MSCOCO2017 val set目標檢測數據集驗證本文的人體檢測模型的精度。分別使用準確率(AP,AP50,AP75)和推理速度(FPS)對模型進行驗證,并將最好的結果進行標粗。如表1所示,實驗結果表明,相比通用的檢測方案,本文方法在人體檢測任務中表現優異,在AP50和FPS推理速度上均達到了最優結果,因此可以證明本文基于YOLOv4改進的人體檢測方案可以實現快速推理的同時,保持幾乎和通用檢測方案相同的精度表現。
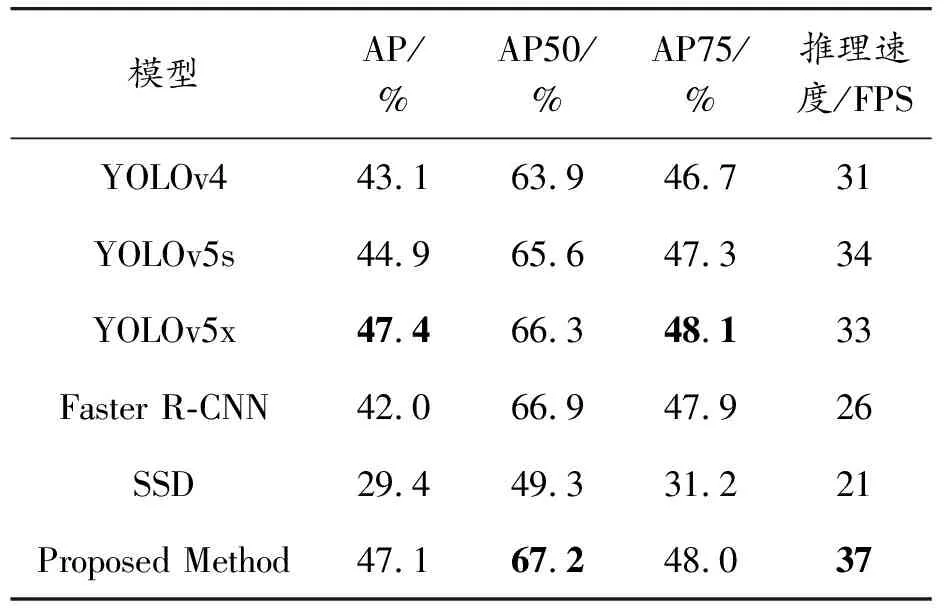
表1 COCO2017人體檢測數據集實驗結果
3.3 自定義煤礦場景人員著裝檢測數據集
由于煤礦場地作業場景的特殊性,以及待檢測的安全帽和工裝馬甲,即工靴類別特征少見的特性,目前尚無統一的公開數據集支持任務驗證。為了推進該任務在領域內發展以及合理驗證本文方法的有效性,構建了煤礦工作場景(安檢通道、礦井等)下的人員著裝數據,針對煤礦作業構建專用數據集。具體來說,對3 000張無序圖片分別進行安全帽、工裝(藍色和橙色)、工裝馬甲和工靴進行人工標注,圖片分辨率為1 920 × 1 080,且其中2 030張圖像中均包含佩戴安全帽及防毒面具的工作人員。鑒于違規著裝的服裝多樣性,因此負樣本的搜集不能僅限于指定的工作場景中,從DeepFashion[23]篩選了1 000張站立全身著裝圖,分別進行人工標注和定位,添加到違規著裝的負樣本類別中。數據集樣本類別及數量見表2。

表2 自定義煤礦場景數據集樣本類別與數量
在自定義煤礦場景數據集中使用基于注意力機制的區域特征表示和多分類網絡進行著裝分類實驗,得到結果如表3所示,實驗證明本文的方案在該工作場景中可以達到優異的效果,在開放世界中的推理結果的可視化實驗見圖6。本文的方法在單張RTX 2080Ti上未經任何推理加速方案(如Tensor RT等)即可達到29幀/s的檢測速度,完全可以滿足實時檢測任務的需求。

表3 人員著裝檢測結果

圖6 樣本可視化檢測場景
3.4 消融實驗
為了驗證各模塊對網絡模型整體結構的貢獻,在MSCOCO數據集上設計了系統的消融實驗,分別驗證提出方法中2D姿態估計模型對著裝檢測的影響和改進網絡結構對參數量及實時性的影響。首先,使用多種不同的2D姿態估計模型(OpenPose,AlphaPose以及本文的姿態估計模型)分別進行著裝檢測任務的端到端訓練,并在MSCOCO Keypoint Challenge數據集和自定義著裝檢測數據集上分別驗證姿態估計精度和著裝檢測精度,結果如表4所示,本文的方法在精度上大幅優于之前的OpenPose和AlphaPose,且改進后的姿態估計模型相比AlphaPose模型推理速度也得到大幅提升,完全可以滿足實時性能的要求。
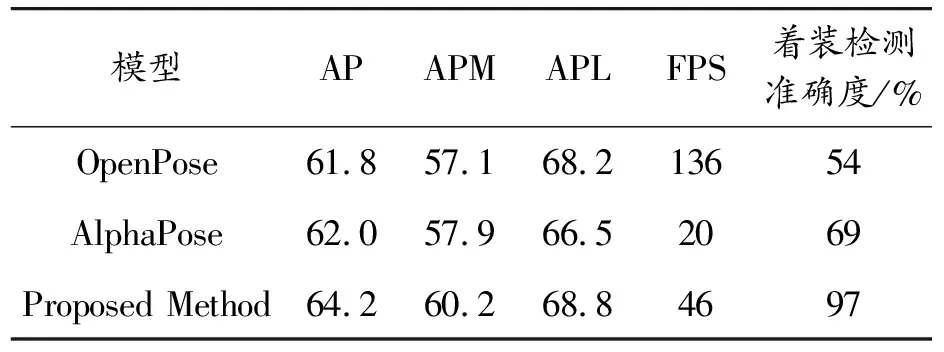
表4 COCO人體關鍵點數據集實驗結果及著裝檢測準確度
此外,為了驗證模型的泛化性,在MSCOCO數據集上訓練人體檢測數據集后,直接在自定義數據集中進行遷移學習,檢測數據集中的工裝及類別,同時對比本文所提出的方法(在MSCOCO訓練人體定位和姿態估計任務后,再遷移到自定義數據集中),結果如表5所示,直接使用檢測模型完成端到端的著裝檢測任務時,雖然推理速度略快于本文方法,但精確率和召回率方面均大幅落后于本文的方法。鑒于FPS指標均可以達到實時性能,且由于去除了著裝部位的檢測回歸模塊,同時還可以一定程度上降低參數量,具有更好的泛化能力和遷移學習能力,因此本文方法是更適用于著裝檢測任務的解決方案。綜上所述,實驗可以證明將著裝檢測任務解耦為人體定位與著裝分類任務具備更好的通用性。
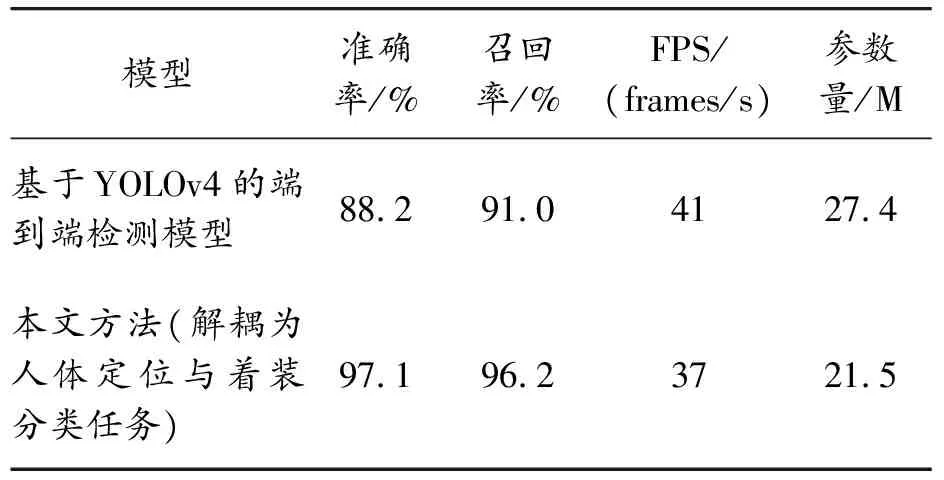
表5 自定義數據集上本文方法與檢測任務模型精度
3.5 本文方法的限制及未來工作
不同于傳統的檢測方案,本文方法將著裝檢測任務解耦為人體區域定位和圖像分類任務,有效提升了模型性能和效率。但同時本文方法存在小目標著裝檢測能力較弱的問題,這主要是由于小目標下的人體姿態難以準確估計,從而造成區域分割不準,且對于小目標人體,即使較小的姿態誤差也會造成分割區域的不準確,從而導致著裝分類準確率下降。并且由于現實場景中小目標常出現在畫面邊緣處,因此常常伴隨著邊緣畸變問題,這也增加了區域定位和分類的難度。因此之后的工作會集中在矯正畸變和考慮超分辨率重建等數據增強方案提升小目標情況下的著裝檢測效果。
4 結論
1) 提出一種新穎的人員著裝檢測算法,該方法基于改進的人體檢測算法和2D人體姿態估計模型對人員進行精準檢測和著裝區域的精準定位,結合注意力機制和一個簡單的多分類網絡完成最終的人員著裝檢測任務。
2) 實驗證明,得益于精確的人體區域定位和RGB-HSV色彩空間變換預處理,算法的精度和效率可以得到保證,廣泛適用于多種工作場景,具有較好的魯棒性。
3) 本文算法涉及的模型包括3個獨立模塊,并且在工靴檢測實驗中精度較低,因此,如何設計端到端優化的人員著裝檢測模型和提升小目標(工靴)檢測精度將是下一步的研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
