基于雙向迭代的航空發動機試驗知識圖譜構建方法研究
2023-03-26 00:34:42張聰,梁丹,劉振
燃氣渦輪試驗與研究 2023年3期
張 聰,梁 丹,劉 振
(中國航發四川燃氣渦輪研究院,四川 綿陽 621000)
1 引言
隨著現代航空發動機研制需求的不斷提高,對其研制活動中重要環節的試驗驗證也提出了更高的要求。一方面,需要進一步降低試驗成本和試驗風險,提升試驗對多樣化驗證要求的技術支撐和實施效率;另一方面,需要試驗環節獲取的信息能夠主動為正向研發提供系統性的知識支撐,助力推動發動機研制進程。
航空發動機試驗一般分為試驗設計和試驗實施兩部分。試驗設計包括試驗規劃、測試設計、試驗流程設計等環節;試驗實施包括車臺改造、試驗件上臺、試驗準備、試驗現場測試執行、試驗數據分析等環節。每個環節都會產生大量復雜信息數據。這些信息以試驗件為核心,涉及諸如人員、設備、工具、環境等人機協同的物理要素,關系錯綜復雜,數量日漸龐大。目前,信息存儲主要以傳統關系型數據庫、半結構化文件和非結構化文檔形式為主,分布在不同的信息化平臺甚至是本地終端,提供的信息獲取方式以關鍵字字面含義匹配為主。這一現狀使得數十年的試驗學科知識、業務經驗積累與工程數據沒有形成相應的知識體系和直觀形象的知識表達,從而無法滿足對發動機研制工作的有效支撐。
知識圖譜通過描述真實世界中的實體和概念及其關系,可以實現在機器層面對信息的語義理解。相較于列表和段落文字,知識圖譜對復雜知識體系的圖形化表達方式,更符合人類的認知習慣,可以有效輔助快速獲取關鍵知識信息。知識圖譜分為通用領域知識圖譜和行業領域知識圖譜,通用領域知識圖譜構建技術較為成熟,代表性的成果有國外多語言的DBpedia[1]和經過高質量評估的YAGO[2],國內的CN-Probase 和百度構建的“知心”等。這類知識圖譜數據來源主要是開源百科和互聯網公開網頁資料,覆蓋范圍廣,但是知識深度較淺。行業領域知識圖譜構建技術目前主要以民用金融和醫療領域為主,其特點是高度依賴行業領域數據,知識范圍不廣但深度較深,以基于海量文本和深度學習的自動化構建技術為主。近年來,軍用領域也開始積極探索知識圖譜構建技術,包括雷達情報裝備知識圖譜[3]、武器裝備信息知識圖譜[4-5]、裝備維修保障知識圖譜[6]等。該類知識圖譜信息主要來源,一部分是開源百科和網頁公開資料,一部分是行業專家手動構建的本體,以及內部的結構化數據庫,以傳統詞法分析和統計學習技術與本體論結合的半自動化構建技術為主。
面向行業領域的知識圖譜技術是與行業知識特點和業務應用深度結合的技術,不同的知識范疇、業務應用目的和信息來源需要探索不同的構建技術。航空發動機試驗領域是具有一定保密性的大型協同工程科學,相關有效信息難以公開、直接獲取,實體關系復雜度高、深度深,高度依賴特定的業務經驗,導致上述常規自動化構建技術難以實施。同時,涉及的很多經驗型知識,由于存在大量隱含背景常識和業務專家理解不完全一致等特點,使得難以直接通過統一本體建模進行業務工程層面的知識指導,導致上述軍用領域的以本體論為基礎的半自動化構建技術同樣難以復用。
目前,航空發動機試驗領域還未形成適用于本領域的知識圖譜構建方法及其相應圖譜。為此,針對航空發動機試驗領域面向不同場景的業務應用需求,基于試驗領域統一遵守的標準規范條文和權威手冊條目,結合業務過程中積累的大量數據表、技術文件,從知識圖譜構建角度,對知識自動化獲取關鍵技術開展綜述研究。并在此基礎上提出基于雙向迭代的領域圖譜構建技術方法,充分利用現有數字化資源,最小化減少人力投入,以便精準高效構建知識圖譜用于有效輔助基層業務技術工作與發動機設計研發工作。
2 知識自動化獲取關鍵技術
知識自動化獲取技術主要用于從非結構化文本中發現和識別實體與關系,以及補全現有知識網絡,從而構造結構良好的大規模知識圖譜,以便于在實際工作中結合工程業務模型,提供可解釋性的智能知識服務。知識獲取關鍵技術主要包括實體發現技術、關系抽取技術和知識補全技術[7]。
2.1 實體發現技術
由實體發現技術根據不同的知識獲取目的,可分為實體識別、實體鏈接和實體對齊。實體識別(NER),主要是對文本中的實體角色確定邊界,是知識獲取的基礎。經典實體識別技術主要分為3 類:第1 類基于規則和詞典,以語言學專家手工構建模式和字符串匹配為主要手段[8],適用于規則明確,范圍單一,風格統一的領域文本提取;第2 類是基于統計的方法,利用人工標注的語料進行訓練,代表性算法為基于隱馬爾可夫模型[9],基于條件隨機場[10]等。第3 類為基于規則和統計的多種類融合,通過借助規則知識,縮小統計方法的搜索空間,達到提升效率的目的[11]。由于中文在語言學特性上與英文差距大,因此國內學者通過引入先驗概率[12],最大熵混合[13]等方法,用于提升中文實體識別準確率和召回率。
實體鏈接主要是將文本中的指稱(mention)鏈接到知識庫中對應的實體(entity)上。實體鏈接需要解決兩方面的問題,分別是同一個實體有不同的指稱,以及同一個指稱在不同上下文表征不同的實體。傳統采用候選實體生成方法,主要基于百科、日志、人工標注構建別名詞典,也是目前工業領域常用方法。而新一代實體消歧技術主要基于上下文獨立特征和上下文依賴特征,自動從文本中學習到指稱與實體的對應性,主要分為3 類方法:排序法,概率法和基于圖的方法。近期較為代表性的學術成果是通過深度學習直接學習到知識庫實體的圖特征、上下文特征和先驗概率特征,綜合采用這3 類方法最終輸出指稱對應于實體的概率排序[14]。
2.2 關系抽取技術
關系抽取技術主要用于從非結構化文本中自動提取實體之間未知的關系事實,即構建知識的語義聯系,是構建大規模知識圖譜的關鍵,分為基于知識工程的方法和基于機器學習的方法。前者主要基于領域知識結合語言學知識抽取有效的關系信息,代表性的包括人工編寫規則進行匹配[15],謂語信息判定語義關系[16]以及句法分析結合人工標注識別復雜語義[17]等。后者則主要通過自動學習標注語料的特征訓練模型提取有效的關系,根據對標注語料的依賴程度可分為有監督學習、弱監督學習和無監督學習。
有監督學習將關系抽取視為分類問題,代表性的方法為通過啟發式方法選取多層次的語言學特征顯式構造向量用于訓練分類器[18],以及通過計算文本字符串或者句法分析樹結構的相似度訓練分類器[19]。弱監督主要是基于自舉的思路:首先根據人工構造少量關系實例作為種子集合,然后利用模式學習擴展迭代更多實例集合[20]。無監督學習主要是采用聚類技術利用大規模預料的冗余性挖掘出潛在關系集合[21]。
2.3 知識補全技術
由于知識圖譜在構建過程中存在固有的缺失性,因而需要知識補全技術添加新的三元組,包括兩項子任務,分別是實體預測和關系預測。知識補全技術通常分為人工補全和機器自動化補全兩類。人工補全主要是通過構建規則推理實現補全,機器自動化補全則是通過表征空間、打分函數、編碼模型和輔助信息構建知識表征學習模型實現補全。目前機器自動化補全采用的表征空間是低維度的嵌入式表示,因此通常采用基于嵌入的方法,代表性方法是基于TransE 編碼模型計算替換了實體的三元組打分排序結果作為評價指標。
3 基于雙向迭代的航空發動機知識圖譜構建技術
航空發動機試驗領域知識特征具有3 點特殊性:①航空發動機試驗領域具備一定的保密性,不具備大規模獲取開放性有效數據的資源環境;②航空發動機試驗領域既屬于較深層次的子領域,又屬于與其他學科專業深度結合的跨學科綜合獨立領域,淺層次的材料梳理和結構化表單無法直接用于構建知識體系;③航空發動機試驗領域是大型協同工程,知識信息的關鍵關聯來源于業務實踐經驗,屬于隱性知識,通常離散分布在不同的信息系統和文檔中,難以先構建統一的本體模型對知識體系進行規劃約束。這些特殊性導致垂直領域常用的人工構建與通用領域常用的自動化構建技術存在較大的應用難度。為此,基于以上3 點特殊性,本文提出了面向航空發動機試驗領域的知識圖譜框架結構,并在此基礎上提出了基于雙向迭代的領域圖譜構建技術。通過在線閉環反饋的人機協同機制,將自上而下的知識數據模式設計和自下而上的弱監督自動化知識獲取結合,從而有效構建航空發動機領域知識圖譜。
3.1 航空發動機試驗領域知識圖譜總體框架設計
基于不同的業務需求和數據特性,航空發動機試驗領域知識圖譜框架結構如圖1 所示。主要由兩類知識圖譜構成,分別是基礎知識圖譜和專題知識圖譜。基礎知識圖譜用于表示面向各類試驗業務通用的基礎背景知識,主要分為術語詞匯概念知識、試驗標準規范知識和試驗專業系統背景知識。具體可橫向擴展不同圖譜庫,可包括航空渦輪噴氣與風扇發動機試驗詞匯概念圖譜庫、地面整機與高空模擬試驗標準規范圖譜庫、試驗中測試專業系統背景知識圖譜庫等。專題知識圖譜是面向具體的試驗業務工作開展和決策輔助需求,構建更為細粒度和深層次的知識關聯體系,主要分為靜態主題和動態主題。該層圖譜可根據實際業務變化進行橫向或者縱向擴展,可包括試車臺資源實例圖譜庫,試車臺作業知識圖譜庫,面向參數有效性決策支持知識圖譜庫,面向某型號的故障跟蹤知識圖譜庫等。
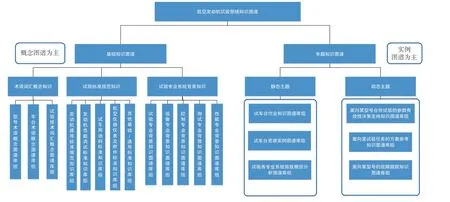
圖1 航空發動機試驗領域知識圖譜總體框架結構Fig.1 General framework of aero-engine test knowledge graph
每個知識圖譜庫組包括多個知識圖譜庫,每個知識圖譜庫內部有多個關聯的知識圖譜。圖譜類型分為概念圖譜和實例圖譜,概念圖譜主要是用于表示型號、車臺設備、試驗任務中多類別多層級的術語概念、功能角色、屬性分類;實例圖譜主要用于表示指代對象和屬性值,可繼承概念圖譜的結構進行擴展,也可獨立存在。總體而言,基礎知識圖譜以概念圖譜為主,專題知識圖譜以實例圖譜為主。因此,專題知識圖譜與基礎知識圖譜是監督與補全的交互迭代構建關系。即專題知識圖譜前期主要通過基礎知識圖譜的部分知識,以弱監督形式結合其他數據源快速搭建框架,后期則可通過對庫組中具體圖譜內容擴充的歸納總結,為基礎知識圖譜提供知識補全。
3.2 基于領域文檔的航空發動機試驗知識自動化獲取技術方案
航空發動機試驗領域文檔隱含和積累了大量的知識要素,通過分析領域文檔的信息特征,提出了基于領域文檔的航空發動機試驗知識自動化獲取技術方案,如圖2 所示。方案主要由4 部分構成,分別為外部采集、語料生成、預處理和知識要素獲取。領域文檔分為內部資料和外部資料,內部資料包括技術文件、內部標準規范;外部資料包括公開標準規范、行業專家叢書和學術論文報告以及百科和公共詞庫。算法支持主要分為兩類,一類為規則解析,這類規則主要依賴人工及公開詞庫與百科進行初步發現和最后的組合計算;另一類為模型預測,主要采用深度神經網絡智能模型進行閱讀理解或者實體識別與關系抽取。
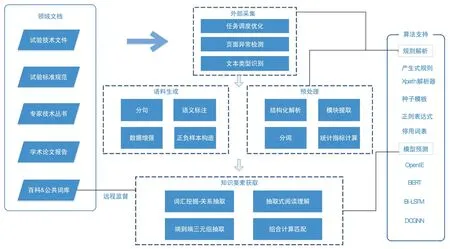
圖2 基于文檔的航空發動機試驗領域知識自動化獲取技術方案Fig.2 Automatic acquisition technical proposal of aero-engine test knowledge graph based on document
外部采集主要是通過爬蟲技術,從互聯網中自動獲取頁面上的領域相關文本內容,具體而言采用了動態任務調度機制、基于驗證碼屏蔽的頁面檢測異常和文本類型識別。其中文本類型識別是用于判別該頁面內容類別為長文本、富文本、表格、清單等種類。針對不同種類的預處理方法有所不同,預處理主要包括結構化解析、模塊提取、分詞及其統計指標計算。其中結構化解析、模塊提取主要針對富文本進行層次化的結構處理。分詞是基于正則表達式等規則進行的初步指代詞識別,并對其統計指標進行計算從而獲取該詞匯的統計特征屬性。語料生成主要用于智能模型的訓練集與測試集構造,以及對規則模板的構造與匹配,包括分句、語義標注、數據增強和正負樣本構造。知識要素獲取主要是基于深度神經網絡智能模型對文本語義片段和語義三元組進行自動化獲取,主要包括詞匯挖掘-關系抽取流水線處理技術、抽取式閱讀理解、端到端三元組抽取和組合計算匹配。其中詞匯挖掘-關系抽取流水線處理技術,主要采用遠程監督技術利用外部百科和公共詞庫對領域文本進行新詞發現和關系抽取;抽取式閱讀理解主要是針對長文本的語義問答知識進行識別;端到端三元組抽取主要是采用語義框架和值抽取技術提取形式化的知識要素;組合計算匹配主要采用就近匹配原則,將提取到的知識元素進行初步的重構形成顯性的知識要素。
3.3 基于雙向迭代的領域圖譜構建方法
領域知識數據模式設計是領域知識圖譜構建的前提。一般而言,自頂向下的模式設計方法為從頂層概念逐步向下細化形成分類學層次結構,并將文本中的指代實體鏈接到概念中。但是這種方法在大量隱性經驗知識分散在文本中的多專業協同工程領域重構代價很高,且難以統一。為此,提出了一種基于雙向迭代的航空發動機試驗領域知識圖譜構建方法,如圖3 所示。該方法主要包括兩個部分的工作,分別是知識數據模式設計和領域知識自動化獲取。模式設計為概念圖譜和知識自動化獲取提供不同形式的知識表示,隨后知識自動化獲取在概念圖譜的指導下依次獲取文本中的指代實體、鏈接概念和對應關系,并在此基礎上進行知識補全和知識糾錯,從而形成實例圖譜。專家根據機器自動獲取的實例圖譜比對原始文本進行模式設計的完善和優化等更新工作。即首先是自上而下地通過預定義的數據模式獲取了一定的指代實體,再通過機器學習泛化抽取的指代實體自下而上地歸納抽象、補充完善、優化數據模式。

圖3 基于雙向迭代的航空發動機試驗領域知識圖譜構建方法Fig.3 Construction method of aero-engine knowledge graph based on bi-directional iteration
知識數據模式設計是根據文本內容特征和該圖譜使用目的進行的。根據圖1 所示的航空發動機試驗領域圖譜,總體框架包括了基礎術語/主題概念關聯結構、試驗業務活動流程結構、專業系統運行邏輯約束、事實要素劃分和典型句式模板。具體的表示形式分為結構、規則、標簽、表格和文本模板。結構在本文中主要指樹狀的層次結構,標簽主要指類別標簽,文本模板主要是句式結構簡單的短文本。結構可直接作為概念圖譜內容,其余知識表示形式可作為知識自動化獲取工作部分中的監督標簽、先驗條件、處理邏輯和預定義模板,因此知識自動化獲取現在可以結合概念圖譜進行實體發現、關系抽取和知識補全。關系抽取包括了同義關系、分類學關系、屬性關系、結構關系和基于模板的約束關系。其中,分類學關系主要用于表示上下位層次關系;結構關系體現整體-部分關系;屬性關系是多維度的關系概念,某個概念實例可以作為另一個概念實例的屬性值進行關聯;基于模板的約束關系則是為了匹配不屬于上述任何一種關系的特定描述。
4 方法驗證及試驗效果
本文以渦扇發動機的整機試驗測試相關知識及其文檔資料為試驗對象,進行方法驗證和圖譜效果演示。
4.1 渦扇發動機整機試驗測試知識數據模式設計
根據圖1 的框架可知,在基礎知識圖譜中構建渦扇發動機整機試驗相關的術語詞匯概念知識結構,以及以測試專業為例的背景知識結構。圖4 給出了部分結構設計示例,該部分主要是表示型號術語、車臺術語、試驗技術術語、關聯的國軍標等知識。在專題知識圖譜中選擇構建面向某型號臺份試驗的參數有效性決策信息圖譜,部分結構設計示例如圖5 所示。
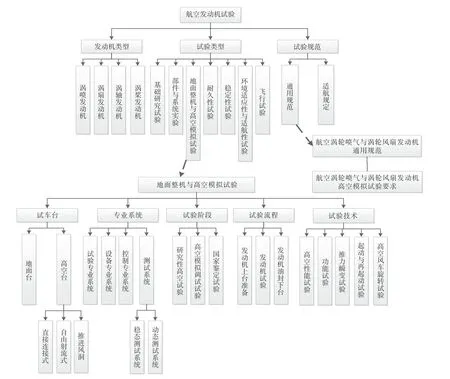
圖4 渦扇發動機整機試驗的知識數據模式示例Fig.4 Schema example of turbofan engine test domain
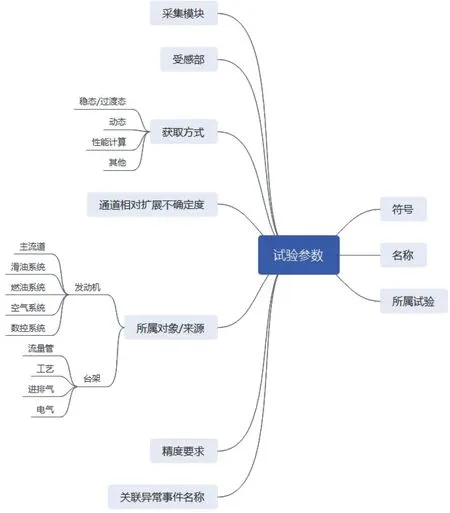
圖5 試驗參數有效性專題圖譜的知識數據模式示例Fig.5 Schema example of the thematic graph of aero-engine test parameter for validity evaluation
4.2 基于領域文檔的整機試驗測試知識自動化獲取驗證結果
根據圖2 的自動獲取技術方案和上文設計的數據模式可知,用于驗證的領域文檔主要包括專家技術叢書《高空模擬試驗技術》,國軍標《航空渦輪噴氣與渦輪風扇發動機通用規范》、《航空燃氣渦輪動力裝置術語與符號》和《航空渦輪噴氣和渦輪風扇發動機高空模擬試驗要求》,某車臺的作業指導書和某型號臺份試驗的試驗測試相關的技術文件。方法驗證過程及其結果如下。
首先進行文本預處理,主要是結構化解析,根據目錄結構信息構建文檔結構樹,再將段落和字句作為單位掛載在結構樹節點上,形成JSON 形式,如圖6 所示。然后進行知識要素獲取,主要采用了端到端三元組抽取。由于上述文件均屬于富文本和長文本,并且缺少有效的標注信息,因此采用了針對特定關系的尾實體標注模塊,并在語料生成部分進行分句處理。針對國軍標的術語概念抽取結果如圖7 所示。
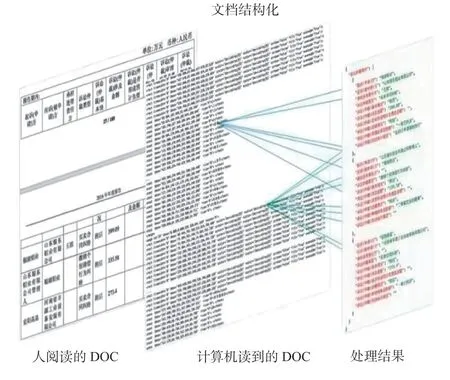
圖6 文檔結構化解析Fig.6 Structural transformation of document
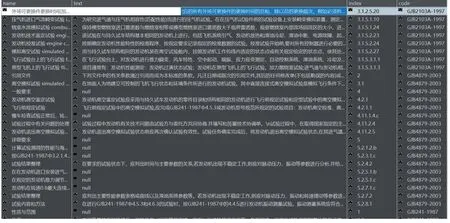
圖7 國軍標的術語概念抽取結果Fig.7 Extraction results of terms of national military standard
4.3 試驗測試知識圖譜演示效果
根據整機試驗測試相關的模式設計,通過文檔樹構建—實體識別和關系抽取-實體鏈接形成完整的知識三元組。圖8 展示了某車臺設備能力相關知識信息三元組示例。

圖8 圖譜的知識三元組示例Fig.8 Example of subject-predication-object
根據本文設計的動態主題圖譜的數據模式和相關試驗測試技術文件,對面向某試驗的參數有效性支持知識漫游進行了演示效果驗證。結果表明該知識點可擴展漫游至相關的車臺知識、專業系統知識、關聯異常事件信息等。
5 結論
針對航空發動機試驗領域的知識特征所具有的封閉性、層次結構深且多學科交叉以及分散的隱性知識三大應用難點,構建了面向航空發動機試驗領域的知識圖譜框架結構。結合知識自動化獲取關鍵技術研究,提出了基于雙向迭代的領域圖譜構建方法。以渦扇發動機整機試驗相關知識及其文檔作為方法驗證對象,實現了從不同類別知識圖譜數據模式設計,到雙向迭代構建的主題圖譜漫游效果演示,驗證了基于雙向迭代的領域圖譜構建方法的可行性。
下一步將持續深入開展有關航空發動機試驗領域的多種知識表示技術研究,進一步迭代完善知識圖譜框架體系;基于業務發展現狀擴充知識服務場景,積累更多數據資源,并設計開發形成生態閉環的工具系統;以切實提升試驗效率,助力航空發動機試驗數字化轉型和智能化升級。
猜你喜歡
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
汽車與新動力(2015年1期)2015-02-27 12:11:01
語文知識(2014年1期)2014-02-28 21:59:13
汽車與新動力(2014年2期)2014-02-27 12:10:15
