基于IoTDB 的航空發動機試驗數據清洗與升維方法
2023-03-26 00:34:44李曉瑜孫婧博
燃氣渦輪試驗與研究 2023年3期
陸 超,李曉瑜,孫婧博
(1.中國航發四川燃氣渦輪研究院 高空模擬技術重點實驗室,四川 綿陽 621000;2.電子科技大學 信息與軟件工程學院,成都 610054;3.中國航發航空發動機研究院,北京 101300)
1 引言
充分有效地利用航空發動機試驗產生的豐富數據資源,對發動機研發過程具有重大意義。但由于試驗數據體量大、增速快,不同部門間數據傳遞效率低下;且傳統的數據庫技術側重于存儲,對數據應用的支持有限,不能有效地開展數據挖掘與分析工作。同時,發動機試驗過程中還會產生一些非傳感器的數據,如視頻、圖像、文檔等形式的信息,而已有的平臺和技術難以將這些多媒體數據與試驗數據相關聯,因此需要對數據進行清洗和升維,之后再使用數據融合技術,對這些來自各部門的多源異構數據進行整合關聯。傳統的關系型數據庫(如Oracle)對結構化數據的存儲較為有效,但隨著數據體量的增加、發動機研發需求的提高以及大數據技術的興起,這類數據庫面向時序型數據時存在效率低下、功能單一等問題,難以滿足發動機研發的業務需求。如試驗中針對某次發動機故障,往往需要將常規測試、特種測試、視頻音頻、各專業的后處理圖表等信息整合后進行綜合分析,面對這種情況,關系型數據庫就難以勝任,而通過人工手段將這些割裂的信息關聯、整合,費時耗力且效果不理想。
本文簡要介紹了航空發動機試驗在數據存儲和管理上的痛點和新需求,并對航空發動機試驗過程中產生的時序型傳感器數據的清洗和升維方法進行了研究,提出了一種面向航空發動機試驗的多源數據融合平臺,并對該平臺進行了簡要的測試和試驗,驗證了該平臺的技術可行性。
2 技術方案
2.1 多源異構數據
航空發動機在試驗過程中會產生大量的傳感器數據,這些數據由各傳感器以固定的采集頻率獲取,可將其稱為時間序列數據。如果和普通數據一樣采用關系型數據庫對時間序列數據進行存儲,將存在諸多弊端,如按時間區間檢索數據的效率較低、支持的查詢功能單一等,且這些傳統的關系型數據庫也難以應對傳感器屬性的升維要求。存儲在數據庫中的數據很難在時間軸上自動對齊,不同設備下的不同傳感器在數據中難以管理。此外,試驗過程中不止產生由傳感器采集到的時序數據,還會產生一些視頻文件、圖像文件,以及某次試驗后人為產生的分析報告等輸出文檔。如果對這些多源異構數據按屬性、時間等信息關聯,難以在現有數據平臺下實現。正是由于傳統數據庫存在著上述弊端,加之航空發動機試驗中又不斷提出新的需求,就要求研發一種新的數據存儲與管理平臺,來提供高效的數據讀寫、查詢、檢索及分析功能,并支持對傳感器型數據的靈活擴展[1]。
2.2 時序數據管理——IoTDB
IoTDB[2]是一種新型的針對時間序列數據的開源數據管理引擎。IoTDB 最早由清華大學大數據系統軟件團隊研發,并于2018 年捐贈給Apache,隨后進行了為期近兩年的孵化,最終于2020 年9 月,由Apache 軟件基金會(ASF)宣布成為Apache 頂級項目。IoTDB 具有時序數據收集、存儲與分析一體化的功能,以及體量輕、性能高、易使用的特點。此外,IoTDB 還提供了低硬件成本的存儲解決方案,10 億數據點硬盤成本低于1.4 元;高通量的時間序列數據讀寫,支持百萬級低功耗連接設備數據接入;面向時間序列的豐富查詢語義,實現跨設備、跨傳感器的時間序列對齊;能完美對接Hadoop 與Spark 生態,適用于工業互聯網應用中海量時間序列數據高速寫入和復雜分析查詢的需求。
航空發動機試驗過程產生的數據為時間序列數據,由各傳感器按照一定頻率采集得到,這與IoTDB 中所存儲與管理的數據類型基本一致。同時,由于IoTDB 國產自主可控,具有存儲成本低、數據寫入速度快(百萬數據點秒級寫入)、數據查詢速度快(TB 級數據毫秒級查詢)、功能完備(數據的增刪改查、豐富的聚合函數、相似性匹配)、查詢分析一體化(一份數據,滿足實時查詢與分析挖掘)、簡單易用等特點,使用IoTDB 作為多源數據融合的基礎數據存儲與管理平臺將大大提升數據存取效率。
2.3 其他相關數據管理
對高空試驗數據進行綜合分析和處理時,通常涉及到試驗傳感器產生的時序數據以及相關試驗場景下產生的視頻文件、圖像文件、分析報告等其他相關數據文件。在確定時序數據存儲和管理平臺的基礎上,也需要選擇合適的數據平臺對這些非時序型數據文件進行存儲管理,為此選擇Hadoop 作為數據融合的分布式平臺。
Hadoop[3]是一個開源的、高效的分布式計算平臺,可在分布式環境下為用戶提供海量數據的存儲和處理能力。HDFS[4]是Hadoop 的核心模塊之一。當1 個文件被存儲到HDFS 中時,它不是作為1 個完整的單一實體存儲,而是被切分成了多個較小的部分(稱為“數據塊”),且這些數據塊通常具有相同的大小。如HDFS 可能將每個數據塊的大小設定為128 MB,這意味著1 個500 MB 的文件將被切分成4 個128 MB 的數據塊和1 個88 MB 的數據塊,且這些數據塊被存儲在HDFS 集群的多個節點上。通過將文件的不同部分存儲在不同的節點上,從而實現數據的分布式存儲。為了提高可靠性,每個數據塊通常會在集群中的不同節點上進行多次復制。如1 個數據塊可能有3 個副本,每個副本存儲在不同的節點上。這樣,即使某個節點發生故障,文件的該部分數據也不會丟失。這種將文件切分成等大數據塊的方法,使得HDFS 能夠有效地處理和存儲大型文件,同時也便于在集群的不同節點上并行處理數據。通過這種方式,Hadoop 能夠進行高效的大數據分析和處理。
IoTDB 可無縫支持Hadoop 生態,為此可以通過結合IoTDB與Hadoop生態搭建多源數據融合平臺。
2.4 多源數據融合分析架構
基于IoTDB 處理時序數據時的各種優勢以及Hadoop 成熟的生態及應用,提出了一種面向航空發動機試驗的多源數據融合平臺,該平臺架構如圖1所示。數據采集端按照一定的采集頻率收集各個傳感器的通道數據,采集段所獲取的數據通過JDBC接口將數據存入時序數據庫IoTDB 部署的服務器中;IoTDB 可以將存儲的數據定時以TsFile 文件的形式上傳至Hadoop/Spark 集群中,方便后續進行各種數據挖掘與數據分析操作。為了不影響已有業務,存入IoTDB 的數據來自于原來存儲時序數據的數據庫,這樣IoTDB 中的數據并不是實時的,因此IoTDB 中的數據主要用于數據挖掘與分析。虛線方框部分為平臺的大數據集群框架,圖中只給出了4個節點,包括3 個數據節點和1 個主節點,實際應用中節點數量可以根據自身需求和數據量來分配[5]。
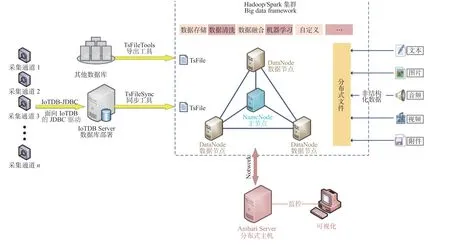
圖1 發動機簡化模型Fig.1 Simplified engine model
對于文本、圖片、視頻、音頻、附件等非結構化數據,可直接存儲在Hadoop 生態下的分布式文件系統HDFS 中。使用MapReduce 或Spark 對平臺下存放的各種數據進行分析處理,整個平臺提供數據存儲、數據清洗、數據融合、機器學習、大數據分析等功能。通過Ambari[6-8]對集群進行管理。Ambari 是一種支持Hadoop 集群部署、監控和管理的開源工具,相較于傳統手工部署方式,其極大地提高了Hadoop 集群部署的效率。在本文提出的多源數據融合平臺中,Ambari 被單獨部署在另外1臺服務器中(分布式集群的監控主機)。Ambari 對服務器性能要求不高,通過Ambari 可監控集群狀態和進行節點管理,如節點的新增和刪除,以及集群組件的部署安裝。Ambari 以Web 形式提供相應的服務,通過外接顯示器可視化展示集群狀態。
3 功能測試結果
3.1 IoTDB 存儲性能測試
為了驗證IoTDB 存儲成本低的特性,對存儲在IoTDB 中時序數據所占硬盤容量的大小進行相應的測試。假設傳感器數目為500,且1 min 采樣50 次,對500 個傳感器的插入進行測試,插入10 000條數據大約32.4 MB,平均插入1條數據約3.3 KB,為了直觀地展示500 個傳感器在采樣頻率為50 Hz 的情況下所產生的時序數據在IoTDB 中的存儲容量隨時間變化的特點,表1 以不同刻度的時間對比展示出了容量變化。可看出,傳感器無休止地采集數據1 年,數據所占硬盤容量僅需82 GB。顯然,在實際的航空發動機研制過程中,傳感器并不是無休止地采集數據,因此實際所占容量只會比這更小,由此驗證了IoTDB 低存儲成本的特性。

表1 時序數據在IoTDB 中容量變化Table 1 Time series data capacity changes in IoTDB
3.2 IoTDB 數據檢索效率測試
對IoTDB 的數據檢索效率進行對比測試,對比數據庫為MangoDB,對比結果如表2 所示。MangoDB 從1 個表中隨機查詢150 條數據,總共耗時596 s,平均查詢1 條數據耗時4 s。而IoTDB 的數據查詢效率為毫秒級,隨機以時間戳為條件查詢1 條數據,耗時在10~100 ms。相較于被廣泛使用的NoSQL 數據庫MangoDB,查詢效率明顯提高,由此驗證了IoTDB 高效的時序數據檢索效率[9-10]。
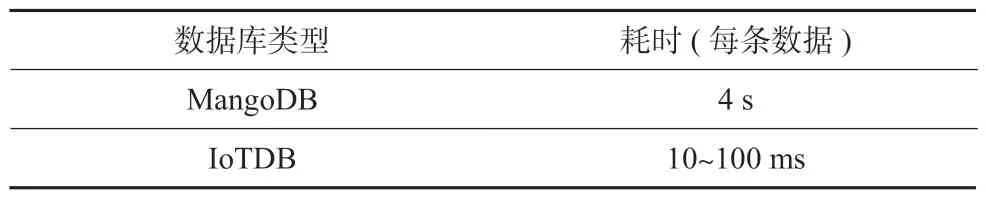
表2 IoTDB 與MangoDB 檢索耗時對比Table 2 Comparison of retrieval time between IoTDB and MangoDB
3.3 基于IoTDB 的時間序列數據管理
使用IoTDB 創建時間序列時,可以為其添加別名及額外的標簽和屬性信息。在IoTDB 中,標簽和屬性的唯一區別是,IoTDB 為標簽信息在內存中維護了1 個倒排索引,可以通過設置的標簽信息作為查詢條件對通道信息(即傳感器信息)進行查詢。為此,可以使用IoTDB 提供的標簽存儲數據升維后的各個屬性,標簽值為對應的屬性值。在實際的試驗測試中發現,IoTDB 在通道數為2 000 時以標簽信息來查詢所匹配的通道的效率也是毫秒級,單次查詢平均為幾十毫秒。
4 基于IoTDB 的數據清洗與升維
航空發動機試驗數據在進入IoTDB 數據庫存儲與管理前,需要經過數據接入、數據清洗及數據升維3 個步驟,如圖2 所示[11]。數據升維是數據由單一“數值”變為“多維數據”的蛻變過程,其主要內容是通過什么樣的方法和規則、對數據增加哪些屬性。原有數據系統在設計和存儲形式上難以對數據屬性進行升維,也無法提供快速的針對航空發動機試驗數據的基于屬性的查詢。根據航空發動機專業特點擬定了升維屬性條目,主要包含基本屬性、測試屬性、表達屬性、應用屬性、關聯屬性等類別,并對原始數據庫的屬性進行擴充,以此構建內涵更加豐富的數據,為實現多數據檢索數據功能及數據關聯研究提供了保證。而屬性升維通過IoTDB 提供的標簽點功能來實現,IoTDB 為標簽信息在內存中維護了1 個倒排索引,據此可使用標簽作為查詢條件快速檢索內容。通過對升維后的屬性進行關聯,可以將包含相同屬性內容的傳感器關聯起來,并提供基于升維后屬性的多條件查詢功能。
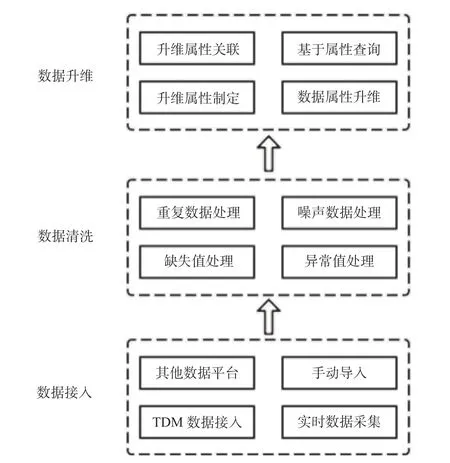
圖2 基于IoTDB 的數據清洗與升維流程圖Fig.2 Data cleaning and dimension improvement flow chart based on IoTDB
5 結束語
為解決傳統航空發動機試驗過程中多源異構數據難以得到充分、有效利用的不足,提出一種面向航空發動機試驗的多源數據融合平臺。該平臺以開源時序型數據庫IoTDB 和大數據存儲與分析平臺Hadoop/Spark 為核心組件構建,不僅能對傳感器采集的時間序列數據進行高效的存儲、檢索、管理和分析,還能對發動機試驗中產生的各種非結構化數據進行分布式存儲和處理。對IoTDB 性能和功能的測試表明,IoTDB 能滿足面向航空發動機試驗的多源異構數據融合的需求。最后,基于IoTDB 數據平臺,對航空發動機試驗過程中產生的時間序列型數據的清洗、升維方法進行了測試和驗證,證明以該平臺為依托,可以構建面向航空發動機試驗的大數據生態。
猜你喜歡
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
