一種面向二維三維卷積的GPGPU cache旁路系統(tǒng)
2023-05-11 12:51:08賈世偉張玉明孫成璐
西安電子科技大學(xué)學(xué)報 2023年2期
賈世偉,張玉明,秦 翔,孫成璐,田 澤
(1.西安電子科技大學(xué) 微電子學(xué)院,陜西 西安 710071;2.西安翔騰微電子科技有限公司,陜西 西安 710068;3.中國航空計算技術(shù)研究所 集成電路與微系統(tǒng)設(shè)計航空科技重點實驗室,陜西 西安 710068)
1 引 言
近年來GPGPU等硬件平臺算力的大幅度提升,對深度神經(jīng)網(wǎng)絡(luò)算法的實際應(yīng)用提供了有效的支持[1]。而卷積神經(jīng)網(wǎng)絡(luò)因其自組織、自學(xué)習(xí)、強泛化性的特點[2-3],被廣泛應(yīng)用在目標(biāo)識別檢測領(lǐng)域,目前在人臉識別、車牌識別等靜態(tài)、低速場景中已十分成熟[4-9]。未來卷積神經(jīng)網(wǎng)絡(luò)面向車輛、無人機、導(dǎo)彈等動態(tài)強實時目標(biāo)識別領(lǐng)域的不斷擴展,以及新網(wǎng)絡(luò)運算量的不斷增加,對硬件平臺的計算能力、存儲性能均提出了更高的要求,研究面向卷積神經(jīng)網(wǎng)絡(luò)的平臺優(yōu)化方案十分重要[10-11]。而卷積操作作為卷積神經(jīng)網(wǎng)絡(luò)的核心算子,其包含了大量的計算與訪存操作,因此是硬件平臺優(yōu)化設(shè)計的重中之重。
許多研究人員進行了相關(guān)的探索研究。文獻[12]提出了硬件結(jié)構(gòu)通過轉(zhuǎn)換矩陣減少卷積中的乘運算,但當(dāng)網(wǎng)絡(luò)模型增大時會增加大量的加運算。文獻[13]使用索引表記錄非0權(quán)重,計算中通過表解碼來去除0元素引入的無效計算。在訪存優(yōu)化方面,文獻[14]通過大量的處理元件(Processing Element,PE)單元實現(xiàn)卷積操作的并行,單元內(nèi)包含保存權(quán)重值的靜態(tài)存儲以降低訪存延時。文獻[15]觀察到權(quán)重值的重用性,因此在PE中使用buffer一次性緩存一行特征值,通過PE滑動來計算一行的結(jié)果。上述的優(yōu)化策略均基于網(wǎng)絡(luò)算法與硬件平臺緊密耦合的設(shè)計思路,雖然得到了一定的性能優(yōu)勢,但均缺乏通用性與可擴展性,只能在部分算法中取得良好的效率。且由于核內(nèi)存儲的工藝成本昂貴,上述的架構(gòu)設(shè)計難以增加更多的片上資源,因此無法適用于網(wǎng)絡(luò)規(guī)模較大的情況。而GPGPU因其海量多核并行計算架構(gòu)的特點,天然適合于大規(guī)模卷積的并行計算[16]。2012年,HINTON等正是在GPGPU上首次部署AlexNet網(wǎng)絡(luò),并以顯著的功性能優(yōu)勢贏得了ILSVRC 2012比賽,從而引領(lǐng)了計算機視覺的新一波浪潮;此后面向卷積神經(jīng)網(wǎng)絡(luò),GPGPU架構(gòu)也進行了多次優(yōu)化。NVIDIA考慮到通用矩陣乘(GEneral Matrix Multiplication,GEMM)是神經(jīng)網(wǎng)絡(luò)的核心數(shù)學(xué)操作,在GPGPU Volta架構(gòu)中首次增加了張量(Tensor)核心專用于執(zhí)行矩陣乘加操作。NVIDIA同時還提供了神經(jīng)網(wǎng)絡(luò)專用加速庫cuDNN,確保程序開發(fā)者以最優(yōu)的效率使用張量核心[17]。緊接著,NVIDIA在GPGPU Turing架構(gòu)中推出了第2代張量核心設(shè)計。考慮到神經(jīng)網(wǎng)絡(luò)具備一定的誤差容忍性,第2代張量核心新增加了INT8與INT4工作模式[18]。雖然網(wǎng)絡(luò)的計算精度有所降低,但張量核心的執(zhí)行效率被大幅度提升,因此Turing 架構(gòu)GPGPU被廣泛用于加速高誤差容忍場景下卷積神經(jīng)網(wǎng)絡(luò)的計算。2020年,NVIDIA推出的GPGPU Amper架構(gòu)在前一代架構(gòu)基礎(chǔ)上進一步引入了對神經(jīng)網(wǎng)絡(luò)稀疏性開發(fā)的硬件支持。Amper架構(gòu)能夠根據(jù)神經(jīng)網(wǎng)絡(luò)稀疏性來壓縮權(quán)重,并提供了專用的稀疏矩陣乘累加運算單元。該運算單元能夠動態(tài)檢測并跳過網(wǎng)絡(luò)中零值的計算,因此進一步提高了張量核心的計算吞吐[19]。2022年,NVIDIA最新的GPGPU Hopper架構(gòu)進一步為張量核心引入了轉(zhuǎn)換引擎(Transformer Engine)控制邏輯。首先,轉(zhuǎn)換引擎會在神經(jīng)網(wǎng)絡(luò)執(zhí)行時動態(tài)分析張量核心的輸出,并確定下一神經(jīng)網(wǎng)絡(luò)層的類型與數(shù)據(jù)精度需求。其次,轉(zhuǎn)換引擎會根據(jù)分析結(jié)果動態(tài)轉(zhuǎn)換后續(xù)網(wǎng)絡(luò)層計算的數(shù)據(jù)精度,進而充分開發(fā)張量核心在不同精度下的強大計算性能[20]。通過歷代GPGPU架構(gòu)回顧可以發(fā)現(xiàn),NVIDIA在面向深度神經(jīng)網(wǎng)絡(luò)優(yōu)化時采取了以下3種思路:根據(jù)場景特征設(shè)計專用加速單元、增加對多種數(shù)據(jù)精度的支持以及不斷增加計算核心數(shù)量。然而,各代GPGPU架構(gòu)在其訪存流水線方面除了增加片上存儲資源容量與帶寬外,并未針對卷積因子的訪存特征進行相應(yīng)的優(yōu)化。
基于上述研究,筆者從二維、三維卷積在GPGPU上執(zhí)行時的訪存特征出發(fā),提出一種GPGPU L1Dcache動態(tài)旁路系統(tǒng)設(shè)計。本設(shè)計能夠動態(tài)識別出二維、三維卷積中具有低局域性的訪存請求數(shù)據(jù)并控制其對L1Dcache旁路,進而降低訪存阻塞周期。與此同時,高局域性的數(shù)據(jù)能夠更有效地利用旁路操作所節(jié)省下來的L1Dcache資源,訪存效率也因此而提升。為此,首先通過一組訪存特征功能域來記錄訪存請求在L1Dcache中分配數(shù)據(jù)的局域性開發(fā)狀態(tài),然后優(yōu)化了多線程調(diào)度策略以加速訪存狀態(tài)的采集,最后基于訪存狀態(tài)特征動態(tài)決定后續(xù)訪存請求數(shù)據(jù)對L1Dcache的旁路。采用GPGPU-sim(3.2.2版本)架構(gòu)模擬器實現(xiàn)了L1Dcache旁路優(yōu)化設(shè)計,并運行標(biāo)準(zhǔn)二維、三維卷積進行功性能驗證。實驗結(jié)果表明,提出的設(shè)計相比基礎(chǔ)架構(gòu)分別降低了約7.63%與21.40%的訪存阻塞周期,性能提升分別達到約2.16%與19.79%,證明了設(shè)計的有效性。
2 背景知識
2.1 GPGPU體系結(jié)構(gòu)與存儲系統(tǒng)
圖1為GPGPU基礎(chǔ)架構(gòu)。GPGPU采用單指令多數(shù)據(jù)(Single Instruction Multiple Data,SIMD)計算架構(gòu),通過少量控制資源控制大量執(zhí)行核心,并行執(zhí)行不相關(guān)的多線程任務(wù),以帶來極高的算力與能效比。所有的執(zhí)行核心被均勻地劃分為多個執(zhí)行組統(tǒng)一管理,這些執(zhí)行組在GPGPU中被稱為流處理器(Streaming Processor, SM)。一個SM的所有執(zhí)行核心共享一組片上資源,這些片上資源包括指令cache,取指-譯碼單元、L1Dcache、共享存儲、warp 調(diào)度器等。在不發(fā)生阻塞的條件下,SM中的每個執(zhí)行核心在每一周期都能獨立地執(zhí)行一條線程指令。

圖1 GPGPU架構(gòu)示意圖
當(dāng)不同應(yīng)用領(lǐng)域場景程序在使用GPGPU加速時,編程者需要解析程序中的可并行部分,并將這部分任務(wù)定義成核(kernel)函數(shù)的形式以供程序主函數(shù)調(diào)用。當(dāng)程序運行時,CPU通過互聯(lián)總線將需要處理的數(shù)據(jù)搬運到GPGPU存儲中,接著完成kernel函數(shù)的啟動。GPGPU線程分發(fā)單元首先根據(jù)kernel函數(shù)參數(shù)生成海量多線程,接著將這些線程以線程塊(Thread Block,TB)為單位下發(fā)到各個SM中。進入到SM中的線程以線程束(warp)為單位進行調(diào)度與執(zhí)行,一個線程塊通常包含多個warp。每一周期warp調(diào)度單元按預(yù)定義的調(diào)度排序策略對SM中的所有warp進行優(yōu)先級排序,并根據(jù)排序結(jié)果來依次判定各warp是否可以發(fā)射執(zhí)行。在不同的周期中各warp通過交替調(diào)度執(zhí)行來隱藏指令的執(zhí)行延時,確保GPGPU計算核心得到有效利用。
為支持海量多線程的高效訪存,GPGPU設(shè)計了復(fù)雜多層級存儲系統(tǒng),如圖1所示的GPGPU存儲系統(tǒng)一共分為4級。第1級為寄存器文件,其內(nèi)部集成了大量高速寄存器,并為SM中每個線程都分配了獨立的寄存器空間。寄存器文件訪問效率最高,但工藝開銷也最大。第2級存儲包括共享存儲與L1Dcache,與寄存器文件不同,二級存儲由SM內(nèi)部的所有線程共享。共享存儲面向編程者開放,用于靜態(tài)保存程序中最需要頻繁讀取的數(shù)據(jù),該存儲中保存的數(shù)據(jù)需要編程者在主程序中手動指定。而L1Dcache作為影響訪存流水線性能的核心組件,動態(tài)保存訪存指令請求的數(shù)據(jù)。當(dāng)warp執(zhí)行一條訪存指令時,其內(nèi)部的所有線程會首先對比各自請求數(shù)據(jù)的地址以進行訪存合并,由此產(chǎn)生多個訪存請求。接著各訪存請求會依次訪問L1Dcache以進行數(shù)據(jù)查找,如果數(shù)據(jù)已存在于L1Dcache中,則L1Dcache將此數(shù)據(jù)直接返回到寄存器中;如果數(shù)據(jù)不存在,則L1Dcache會尋找其內(nèi)部能夠被替換的數(shù)據(jù)空間,并將訪存請求傳輸給更下一級存儲。當(dāng)請求數(shù)據(jù)從下級存儲中返回時,L1Dcache會將其寫入到可被替換的數(shù)據(jù)空間中以完成保存。第3級存儲為L2Dcache,其與L1Dcache的功能一致,但由各個SM所共享,由于工藝限制,片上cache的資源十分寶貴,其容量無法像片內(nèi)計算核心數(shù)量一樣在不同代的GPGPU架構(gòu)中快速增加。最后一級存儲為全局DRAM,該存儲的容量最大,但訪問的效率也最低,一般用于保存GPGPU與CPU交互的輸入輸出數(shù)據(jù)。
2.2 存在問題
為了解當(dāng)前二維、三維卷積在GPGPU上執(zhí)行時的訪存特征,筆者在3種不同的L1Dcache配置下運行了二維、三維卷積并收集其訪存請求訪問L1Dcache的缺失率。L1Dcache容量越大,表示數(shù)據(jù)能夠保留的周期越長,也即L1Dcache提供的數(shù)據(jù)局域性開發(fā)能力越強。實驗結(jié)果如圖2所示。

圖2 不同容量下二維、三維卷積L1Dcache缺失率
可以看到,隨著容量的增加,二維、三維卷積的L1Dcache缺失率不斷下降;特別是三維卷積,其缺失率由16 KB L1Dcache對應(yīng)的77.12%下降為512 KB對應(yīng)的37.99%。這說明受L1Dcache容量的限制,二維、三維卷積中部分數(shù)據(jù)局域性未得到充分開發(fā)。
為得到更細致的訪存特征信息,逐一分析了二維、三維卷積中每條訪存指令在不同L1Dcache容量下的請求缺失率。為了確保實驗可靠,對每一條訪存指令都隨機采集其50次執(zhí)行時的狀態(tài),并通過求平均的方式得到其L1Dcache缺失率。三維卷積的實驗結(jié)果如圖3所示。
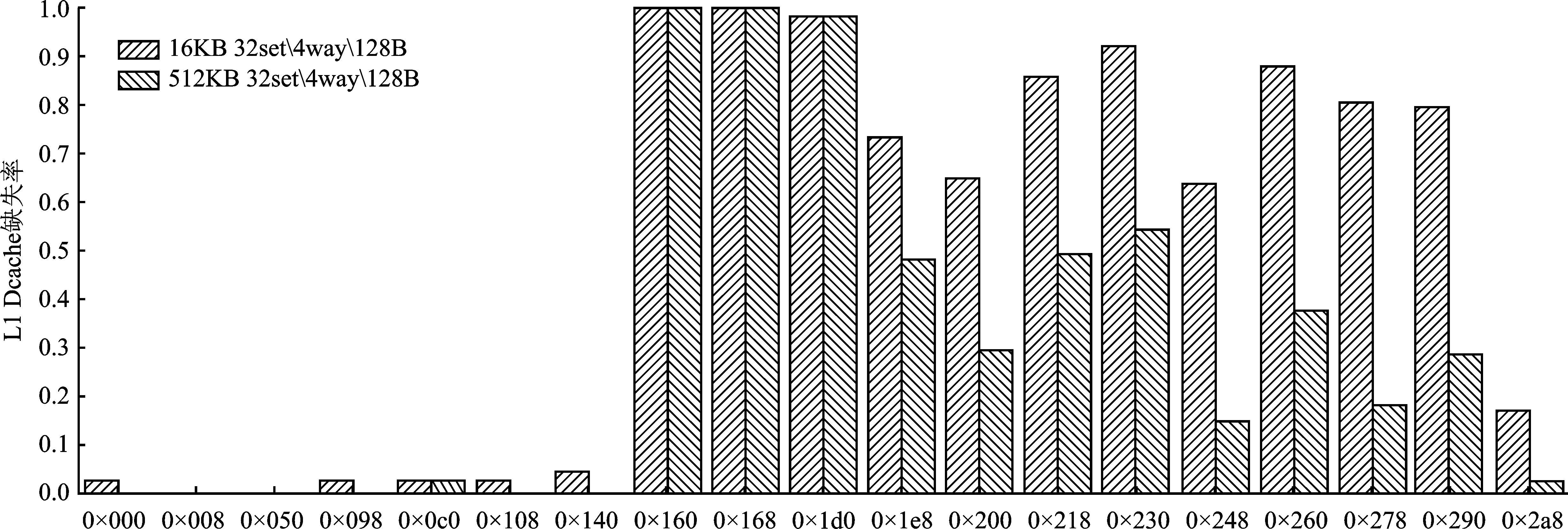
圖3 不同L1Dcache容量下三維卷積各訪存指令L1Dcache缺失率
可以看到,隨著容量的增大,三維卷積中訪存指令0×1e8、0×200、0×218等指令的L1Dcache缺失率顯著降低,這說明這些指令請求的數(shù)據(jù)本具有更高的局域性,但由于L1Dcache容量限制,這些數(shù)據(jù)的局域性未能得到充分開發(fā)。由此,提出一種能夠動態(tài)識別出訪存數(shù)據(jù)局域性的L1Dcache旁路設(shè)計。通過旁路低局域性數(shù)據(jù)在L1Dcache中的保存來將空間留給高局域性的請求數(shù)據(jù),由此降低L1Dcache缺失率與訪存阻塞延時,進而提高二維、三維卷積執(zhí)行時的訪存效率與性能。
3 面向二維、三維卷積的GPGPU L1Dcache動態(tài)旁路系統(tǒng)
文中提出的基于訪存特征的L1Dcache動態(tài)旁路系統(tǒng)包含兩部分,分別是在圖1的warp調(diào)度與L1Dcache部分進行了架構(gòu)優(yōu)化創(chuàng)新。首先,提出了一種線程塊優(yōu)先的warp調(diào)度策略,該策略預(yù)定義一個優(yōu)先執(zhí)行的線程塊,即在warp調(diào)度排序時始終將來自此線程塊的warp置于序列的首位。由此來自該線程塊的warp總是能夠被優(yōu)先執(zhí)行,從而加速訪存狀態(tài)采樣。其次,提出了一種L1Dcache動態(tài)旁路系統(tǒng),該系統(tǒng)在原先的L1Dcache設(shè)計中增加訪存狀態(tài)記錄表以動態(tài)記錄不同訪存指令請求L1Dcache時的狀態(tài)。當(dāng)訪存狀態(tài)采樣結(jié)束時,根據(jù)表中記錄的狀態(tài)信息動態(tài)決定后續(xù)訪存請求的數(shù)據(jù)是否需要保存在L1Dcache中。下面對關(guān)鍵模塊的設(shè)計與工作原理進行詳細闡述。
3.1 線程塊優(yōu)先的warp調(diào)度策略
為保證訪存狀態(tài)采樣的準(zhǔn)確性與完備性,將自kernel函數(shù)發(fā)射至第一個線程塊完成所有任務(wù)執(zhí)行的周期定義為訪存狀態(tài)采樣周期。傳統(tǒng)warp調(diào)度采用羅賓環(huán)策略,其特點是靜態(tài)賦予來自不同線程塊的所有warp以相同的執(zhí)行優(yōu)先級。在這種策略的約束下所有warp會以相同的進度交替發(fā)射執(zhí)行指令,導(dǎo)致訪存狀態(tài)采樣無法盡早完成。而文中提出的線程塊優(yōu)先warp調(diào)度策略賦予了單一線程塊中的warp以最高的調(diào)度優(yōu)先級。該策略通過預(yù)定義一個線程塊并始終優(yōu)先其內(nèi)部warp的執(zhí)行來加速訪存狀態(tài)采樣過程,確保完成采樣的狀態(tài)記錄表能夠被充分有效地利用。模塊設(shè)計如圖4所示。

圖4 線程塊優(yōu)先的warp調(diào)度策略工作原理
可以看到,模塊的輸入除了需要排序的warp序列外,還包括最近執(zhí)行warpID與優(yōu)先線程塊ID,其中最近執(zhí)行warpID是指上一周期被調(diào)度執(zhí)行warp的下一個warp的ID,其與預(yù)定義的優(yōu)先線程塊ID共同確定本周期內(nèi)應(yīng)排在整個序列首位的warp。由于本調(diào)度策略規(guī)定排在調(diào)度序列首位的warp一定來自于優(yōu)先線程塊,因此首先判定最近執(zhí)行warpID是否來自于優(yōu)先線程塊,若判定通過,則就將此warp排在序列首位;若不通過,則將優(yōu)先線程塊中的第一個warp排在序列首位。接著,按順序?qū)?yōu)先線程塊中的剩余warp排在當(dāng)前序列的尾部,由此優(yōu)先線程塊內(nèi)的所有warp首先完成了排序,并被放置在整個warp序列的最前端。這些warp有最高的優(yōu)先級被調(diào)度、發(fā)射與執(zhí)行。接下來需要對輸入warp序列中的剩余warp排序。這里根據(jù)第一步的判定結(jié)果分為兩種情況:如果最近執(zhí)行warpID屬于優(yōu)先線程塊,則以優(yōu)先線程塊后第一個warp為首warp,將剩余的warp按順序排列在序列的末尾;如果不屬于,那么還是要以最近執(zhí)行warpID為首,將剩余warp按順序排在序列末尾。這種方式保證除去優(yōu)先線程塊外,剩余的所有warp具有一致的優(yōu)先級。最后將完成排序的warp序列輸出到warp調(diào)度單元,以進一步完成后續(xù)warp發(fā)射與執(zhí)行的判定。
3.2 基于訪存狀態(tài)的L1Dcache動態(tài)旁路
文中L1Dcache旁路設(shè)計的思想就是動態(tài)決定保存在L1Dcache中的訪存請求數(shù)據(jù),通過將L1Dcache存儲空間保留給具有較高局域性的數(shù)據(jù),達到降低L1Dcache缺失率與存儲阻塞周期,提高性能的目的。為此,首先構(gòu)建能夠反映訪存請求狀態(tài)的數(shù)據(jù)結(jié)構(gòu),接著以此數(shù)據(jù)結(jié)構(gòu)作為項(entry)來構(gòu)建訪存特征記錄表并添加到當(dāng)前的L1Dcache設(shè)計中,用以記錄所有訪存指令的L1Dcache請求狀態(tài)。數(shù)據(jù)結(jié)構(gòu)如圖5所示。

圖5 訪存請求狀態(tài)數(shù)據(jù)結(jié)構(gòu)
各功能域的含義如下:
(1) m_pc:記錄了各訪存請求的PC值,訪存指令通過此功能域?qū)ふ冶碇袑?yīng)的項。
(2) m_count:記錄了采樣周期內(nèi)本表項對應(yīng)的cache數(shù)據(jù)塊在被替換出cache時被命中的次數(shù)的累加。這里本表項對應(yīng)的cache數(shù)據(jù)塊是指分配這些cache數(shù)據(jù)塊的訪存請求的PC值均為本項的m_pc。
(3) m_times:記錄本PC值下已被替換出cache的數(shù)據(jù)塊數(shù)量。
(4) m_use:標(biāo)記本表項的PC值對應(yīng)的訪存請求數(shù)據(jù)是否可以保存在cache中。
(5) m_finish:標(biāo)記當(dāng)前表項是否已經(jīng)完成訪存狀態(tài)采樣。
(6) m_valid:標(biāo)記當(dāng)前表項是否有效。
整個系統(tǒng)包括cache旁路判定及訪存狀態(tài)記錄表更新兩部分,其中cache旁路判定通過查詢狀態(tài)記錄表的方式完成。系統(tǒng)設(shè)計如圖6所示。
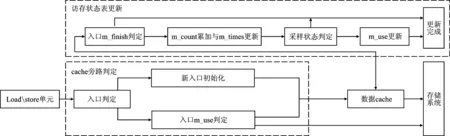
圖6 LIDcache旁路判定與訪存狀態(tài)表更新原理
3.2.1 LIDcache旁路判定
LIDcache旁路判定部分以從Load/store單元發(fā)出的訪存指令為輸入,判定此指令的請求數(shù)據(jù)是否能夠保存在LIDcache中。首先根據(jù)指令PC值在訪存狀態(tài)記錄表中判定對應(yīng)的項是否存在。若判定失敗,則使用本指令的PC值初始化一個新表項并將其m_use功能域初始化為true,表示當(dāng)前此PC值下所有訪存請求的數(shù)據(jù)需要在LIDcache中保存,后續(xù)當(dāng)LIDcache數(shù)據(jù)塊被替換時才能使用其被命中的次數(shù)更新訪存狀態(tài)記錄表。若判定成功,則進一步判定表項的m_use功能域;如果m_use功能域的狀態(tài)為false,則表示此PC值下的請求數(shù)據(jù)不應(yīng)保存在LIDcache中。由此當(dāng)數(shù)據(jù)從低一級存儲中返回時不會再寫入到LIDcache中保存;如果狀態(tài)為true,則數(shù)據(jù)返回時會保存在先前分配好的LIDcache空間中。
3.2.2 訪存狀態(tài)記錄表更新
訪存狀態(tài)記錄表在任何數(shù)據(jù)塊被替換出LIDcache時進行更新,用以保存各PC值對應(yīng)的LIDcache數(shù)據(jù)塊被命中的總次數(shù),從而為低局域性數(shù)據(jù)的旁路提供依據(jù)。狀態(tài)記錄表的更新過程分為以下4部分:
(1) 根據(jù)被替換數(shù)據(jù)塊的PC值在表中找到對應(yīng)的表項并判定表項的m_finish域狀態(tài)。如果狀態(tài)為false,則表示本表項的狀態(tài)采樣未完成,由此進入步驟(2);如果狀態(tài)為true,則表示本表項已經(jīng)完成了訪存狀態(tài)采樣,不執(zhí)行任何更新操作。
(2) 使用當(dāng)前數(shù)據(jù)塊自分配入LIDcache至替換出被請求命中的總次數(shù)來累加表項的m_count功能域,數(shù)值被用來反映數(shù)據(jù)塊所具有的數(shù)據(jù)局域性程度,數(shù)值越高,則說明此數(shù)據(jù)塊被命中的次數(shù)越多,也即其保存的數(shù)據(jù)具有更高的局域性。與此同時,將表項的m_times功能域增加1,表示此PC值下完成了一次訪存狀態(tài)更新。
(3) 判定本PC值對應(yīng)的狀態(tài)采樣是否完成,通過優(yōu)先線程塊的執(zhí)行狀態(tài)來決定。如果優(yōu)先線程塊已完成執(zhí)行,則表明采樣周期已結(jié)束,并需要判定后續(xù)此PC值對應(yīng)的訪存請求是否能夠?qū)?shù)據(jù)保存到LIDcache中,由此設(shè)置本表項的m_finish域為true并進入步驟(4);如果優(yōu)先線程塊還未完成執(zhí)行,則不再更新剩余的功能域。
(4) 通過表項的m_count功能域與m_times功能域數(shù)值共同決定PC值對應(yīng)的訪存請求數(shù)據(jù)是否需要旁路LIDcache。由于在當(dāng)前的存儲系統(tǒng)設(shè)計下,L1Dcache命中與缺失時的訪存性能有一個數(shù)量級的差異,因此定義旁路判定閾值的數(shù)值為10,并將m_times/m_count的數(shù)值與閾值比較。若數(shù)值小于旁路判定閾值,則認為此PC值對應(yīng)的訪存請求數(shù)據(jù)局域性值得被開發(fā),本表項的m_use功能域保持為true狀態(tài),表示后續(xù)此PC對應(yīng)的數(shù)據(jù)需要寫回到L1Dcache中。否則,本表項的m_use功能域被設(shè)置為false,表示返回數(shù)據(jù)需要旁路L1Dcache。
由此一次對訪存狀態(tài)記錄表的更新執(zhí)行完成。當(dāng)任何訪存請求訪問LIDcache的狀態(tài)為缺失時,其都會在訪存狀態(tài)記錄表中查找對應(yīng)的表項。并根據(jù)表項的狀態(tài)信息決定是否需要在LIDcache中預(yù)留保存數(shù)據(jù)的空間。
4 實驗方法與結(jié)果
4.1 實驗環(huán)境與參數(shù)說明
選用GPGPU-sim模擬器(3.2.2版本),這是當(dāng)前學(xué)術(shù)界公認的周期精確的GPGPU架構(gòu)模擬平臺,其支持NVIDIA CUDA編程框架。文中以模擬器提供的GTX480架構(gòu)為基礎(chǔ)進行實驗,模型內(nèi)部包含15個SM,每個SM最大包含1 536個線程,每32個線程被定義為一個warp,基礎(chǔ)warp調(diào)度算法為羅賓環(huán)調(diào)度算法,L1Dcache為16 KB。
文中在基礎(chǔ)架構(gòu)上實現(xiàn)了L1Dcache旁路優(yōu)化設(shè)計,并采用來自PolyBench測試集的標(biāo)準(zhǔn)二維、三維卷積作為測試激勵。
4.2 實驗結(jié)果
4.2.1 cache缺失率、阻塞周期以及IPC
采用L1Dcache缺失率(Cache Miss Rate)與L1Dcache阻塞周期(Reservation Fail)作為指標(biāo)因子來評估優(yōu)化設(shè)計對L1Dcache性能產(chǎn)生的影響,并使用每周期指令數(shù)(Instruction Per Cycle,IPC)作為總體性能的評估指標(biāo),測試性能面向基礎(chǔ)架構(gòu)下二維、三維卷積的執(zhí)行性能進行了歸一化處理。由于文中設(shè)計旁路了部分低局域性數(shù)據(jù)在L1Dcache中的保存,因此這些訪存請求在出現(xiàn)L1Dcache缺失時不需要等待數(shù)據(jù)空間的分配,這可以有效降低L1Dcache阻塞周期。圖7顯示了二維、三維卷積在基礎(chǔ)架構(gòu)與文中設(shè)計上執(zhí)行時的L1Dcache阻塞周期、L1Dcache缺失率與IPC對比情況。

(a) L1Dcache阻塞周期對比
從圖7(a)可以看到,文中設(shè)計在二維、三維卷積運算中分別降低了約7.63%與21.40%的阻塞周期,這轉(zhuǎn)化為部分IPC提升的來源。從圖7(b)中可以看到,在三維卷積中L1Dcache缺失率下降了約8.92%,說明本設(shè)計在三維卷積中有效提高了數(shù)據(jù)局域性的開發(fā),部分原本需要訪問全局存儲的訪存請求成功地在L1Dcache中命中;而二維卷積的L1Dcache缺失率小幅度上升了約0.67%;通過深入分析發(fā)現(xiàn)在二維卷積中基礎(chǔ)的GPGPU L1Dcache設(shè)計能相對較好地開發(fā)數(shù)據(jù)局域性,其L1Dcache缺失率僅為約35.89%,而通過旁路引入局域性開發(fā)的提升未能超過被旁路L1Dcache數(shù)據(jù)塊造成的局域性損失。然而,這種局域性的小幅度損失可以被L1Dcache阻塞周期降低所引入的性能優(yōu)勢掩蓋。圖7(c)顯示的IPC的比對結(jié)果證明了文中設(shè)計在二維、三維卷積中均取得了良好的效果,分別帶來了約2.16%與19.79%的性能提升,由于三維卷積中存在的L1Dcache競爭問題更嚴重,因此文中設(shè)計帶來的性能提升更明顯。
4.2.2 各訪存指令執(zhí)行狀態(tài)
為了更進一步地詳細分析文中設(shè)計對L1Dcache性能產(chǎn)生的影響,逐一分析了二維、三維卷積中每條訪存指令的L1Dcache缺失率。從圖8中可以看到在三維卷積中,文中設(shè)計識別0×160、0×200、0×278、0×290指令的訪存請求為低數(shù)據(jù)局域性,由此當(dāng)發(fā)生L1Dcache缺失時,這些請求訪問低級存儲取回的數(shù)據(jù)不會保存在L1Dcache中。而0×1d0、0×248指令的訪存請求L1Dcache缺失率均有一定程度的下降,說明節(jié)省下來的空間被成功用于數(shù)據(jù)局域性的開發(fā)。從圖9中可以看到在二維卷積執(zhí)行時,文中設(shè)計識別0×1b0指令為低數(shù)據(jù)局域性并旁路,雖然0×108指令的L1Dcache缺失率有所下降,但0×138、0×168等指令的L1Dcache缺失率均有小幅度上升,正是這部分指令訪問L1Dcache缺失率的上升造成了二維卷積中整體L1Dcache缺失率的小幅增加。不過正如節(jié)3.2.1中所述,旁路0×1b0指令的同時會降低L1Dcache阻塞周期,這可以有效隱藏L1Dcache缺失率小幅上升所帶來的性能損失。

圖8 三維卷積各訪存指令L1Dcache缺失率比對

圖9 二維卷積各訪存指令L1Dcache缺失率比對
5 結(jié)束語
筆者提出了一種面向二維、三維卷積的cache旁路優(yōu)化設(shè)計。該設(shè)計首先定義了能夠動態(tài)反映指令訪問L1Dcache特征的數(shù)據(jù)結(jié)構(gòu),然后采用優(yōu)先線程塊warp調(diào)度策略來加速訪存狀態(tài)采樣,最后根據(jù)訪存狀態(tài)得出各PC值下訪存請求對L1Dcache的旁路判定并動態(tài)完成部分低局域性數(shù)據(jù)對L1Dcache旁路。由此將L1Dcache空間保留給高局域性的數(shù)據(jù)并降低L1Dcache阻塞周期,進而提高執(zhí)行性能。文中使用二維、三維卷積進行了設(shè)計驗證,結(jié)果表明相比基礎(chǔ)架構(gòu),文中設(shè)計在面向二維、三維卷積時分別帶來約2.16%與19.79%的性能提升。通過實驗結(jié)果發(fā)現(xiàn),旁路判定策略可以進一步細化與完善,比如采取動態(tài)閾值作為判定L1Dcache旁路的準(zhǔn)則等,這是未來需要進一步改進優(yōu)化的方向。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
測控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電信科學(xué)(2016年10期)2016-11-23 05:11:56
西安航空學(xué)院學(xué)報(2014年5期)2014-07-13 01:27:52
