
基于圖像和特征聯合優化的跨模態行人重識別研究
2023-06-03 09:45:25張輝劉世洪鐘武
荊楚理工學院學報 2023年2期
張輝 劉世洪 鐘武


摘要:跨模態行人重識別(VI-ReID)旨在匹配可見光和紅外攝像頭下捕獲的行人圖像,十分具有挑戰性。為減小可見光圖像和紅外圖像之間的模態差異,本文提出了異質圖像增廣方法和跨模態特征對齊方法來優化跨模態行人重識別網絡,利用輕量級異質圖像卷積生成器對可見光圖像進行增廣,采用色彩抖動方式對紅外圖像進行增廣,并使用正樣本優化輕量級異構圖像卷積生成器來約束損失。在此基礎上,使用兩個模態分類器和跨模態特征對齊損失作為指導,不斷學習獲得模態共享的特征。在兩個數據集上的大量實驗表明,我們的方法具有優異的性能,在SYSU-MM01和RegDB數據集上分別達到了rank1/mAP 57.82%/54.35%和80.39%/75.05%的精度。
關鍵詞:跨模態行人重識別;模態差異;異質圖像增廣;跨模態特征對齊
中圖分類號:TP391.41? ? ? 文獻標志碼:A? ? ? 文章編號:1008-4657(2023)02-0009-09
0? ? ? ? 引言
可見光-紅外的跨模態行人重識別(Cross-Modality? Person? Re-identification)是安防監控領域中非常重要的一項技術,具有重要的研究意義和廣泛的應用場景。Ye等[ 1-2 ]設計了由特征提取和距離度量組合成的端到端學習框架,采用雙流卷積神經網絡,同時處理跨模態和模態內差異。Dai等[ 3 ]引入了生成對抗學習框架,通過改進三元組損失函數和交叉熵損失函數共同約束身份類別和模態類別。Wang等[ 4-5 ]討論了在跨模態行人重識別中,基于雙流卷積神經網絡的共享參數問題,并借鑒中心損失[ 6 ](Center? Loss)思想提出基于異質中心的三元組損失(Hetero-Center? based? Triplet? Loss)。以上方法都是在特征層面上試圖對兩種模態的特征進行約束,提升網絡匹配跨模態圖像的性能,然而不同光譜圖像之間是像素級的劇烈不平衡,因此效果仍然無法令人滿意。
圖像層面上,一些工作利用生成對抗網絡來減小模態差異的影響,Wang等人[ 7 ]先將當前模態圖像生成對應另一模態的圖像,通過生成圖像和原圖像在通道上疊加后組合成多光譜圖像,統一圖像的模態后,再將多光譜圖像作為特征提取網絡的輸入。一種對齊生成對抗網絡[ 8 ](Alignment? Generative? Adversarial? Network,AlignGAN)將跨模態行人重識別任務分為像素對齊、特征對齊和聯合鑒別器三個模塊,減小了跨模態和模態內行人圖像變化所帶來的影響。但是,生成對抗網絡需要依賴大量的訓練數據,收斂速度慢,計算成本比較高,而且生成圖像不同于原始圖像的結構,生成圖像的分辨率更低,并引入了許多噪聲。
雖然目前在跨模態行人重識別領域中已經出現了很多方法,但是仍然面臨著兩個主要挑戰,第一是處理由光照不同、行人姿態變化、跨攝像頭視角變化帶來的行人樣本間的外觀差異[ 9 ],第二是處理由于可見光、紅外兩種模態下攝像頭捕獲的行人圖像高度異構而產生的模態差異。本文在傳統單模態行人重識別方法的基礎上,構建了應用于跨模態場景的雙流網絡[ 10 ],利用批次樣本三元組損失[ 11 ]度量高維特征空間內行人特征的距離,并使用基于交叉熵計算的身份分類損失對行人類別進行約束,在網絡訓練過程中不斷減小同一行人多個樣本間外觀差異帶來的影響。
針對不同模態下行人樣本間的模態差異,在圖像層面上,提出了一種基于雙流網絡的異質圖像增廣(Heterogeneous? Image? Augmentation,HIA)方法,原始可見光圖像經過輕量級異質圖像卷積生成器轉變為異質圖像,紅外圖像經過色彩抖動處理后轉變為亮度、對比度和飽和度不斷變化的新紅外圖像。異質圖像和新紅外圖像都是在原始圖像上的增廣圖像,它們與原始圖像共同作為雙流網絡的輸入,可以減小圖像層面上的模態差異,使網絡更容易學到模態間的共享特征。在特征層面上,提出了一種基于模態分類的跨模態特征對齊方法(Cross-modality? Feature? Alignment,CFA),對可見光和紅外模態設置預定義標簽,雙流網絡提取出兩種模態的特征后,模態分類器對兩種模態特征按照預定義標簽來分類,并更新模態分類器部分權重參數,然后通過設計跨模態特征對齊損失,在優化特征提取網絡中使模態分類器將兩種模態特征分類為相反標簽。在不斷迭代的過程中,模態分類器和特征提取網絡交替更新各自模型參數,引導網絡學習模態共享特征,減小了特征層面上的模態差異。
1? ? ? ?圖像和特征聯合優化方法
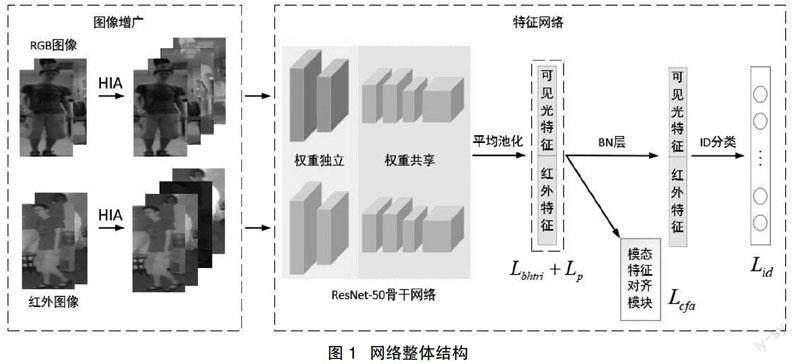
本文提出的方法是在圖像和特征兩個層面上來減小跨模態行人重識別中的模態差異,進而優化跨模態行人重識別網絡的性能,該方法主要包含兩個部分。(1)異質圖像增廣(HIA):設計輕量級異質圖像卷積生成器用于可見光圖像的增廣,采用色彩抖動處理方式進行紅外圖像的增廣,設計正樣本對約束損失Lp用于優化異質圖像卷積生成器。(2)跨模態特征對齊(CFA):在兩個模態的圖像特征共同嵌入時,設計模態特征對齊模塊Lcfa,用于在統一特征空間內拉近兩個模態的特征。
將本文方法應用到跨模態行人重識別的整體網絡結構后(圖1),其工作步驟是:
(1)兩種模態的圖像進行增廣后,通過權重獨立的淺層網絡提取各自模態的特征,再通過權重共享的網絡將兩種模態的特征映射到統一的特征空間內,經過全局平均池化(Global Average Pool,GAP)后得到可見光和紅外模態2048維度的高維特征。在網絡訓練反向傳播的過程中,利用正樣本對約束損失Lp,優化可見光圖像經過異質圖像卷積生成器后生成的異質圖像。
(2)在高維特征空間中,采用批次難樣本三元組損失函數Lbhtri進行特征距離度量,使用設計的模態特征對齊模塊Lcfa減小模態差異帶來的影響。然后,高維特征經過批量歸一化層(Batch? Normalization,BN)以保證網絡穩定收斂,并使用參數共享的全連接層(Fully? Connected? Layers,FC)對模態共享信息進行建模,最后計算基于交叉熵的身份分類損失對行人身份進行分類。
其中圖2(a)為灰度-零填充:由于紅外圖像中不含顏色信息,因此文獻[ 3 ]提出了一個深度零填充的特征學習網絡框架,將所有行人圖像灰度化后零填充,形成兩通道圖像,輸入到權重共享的單流網絡中學習。然而這樣的處理方式未利用到所有信息,它忽略了可見光圖像中重要的顏色信息。
圖2(b)為RGB-灰度:文獻[ 1 ]采用雙流網絡,直接使用RGB三通道的可見光圖像和由單通道重復擴展為三通道的紅外圖像作為輸入,然后將特征嵌入到統一空間中學習跨模態特征表示,網絡性能的提升證明了顏色信息對跨模態行人重識別任務是有益的。此后,為了適配網絡的輸入,將紅外圖像的單通道重復擴展為三通道灰度圖像。
圖2(c)為GAN生成:生成對抗網絡[ 11 ](GAN)可以生成當前模態對應的另一域的行人圖像,在圖像層面上達成“模態統一”,其思想就是應用圖像風格遷移的方式,將跨模態轉換成單模態下的行人重識別。但是GAN生成圖像與原始圖像相比,噪聲增加,清晰度和分辨率下降,部分有益信息會丟失。另外,如果利用GAN將紅外圖像生成可見光圖像,由于沒有顏色信息的監督,生成圖像將更加不可靠。
現有的圖像生成方法大多是利用GAN達到“模態統一”,但此方法沒有充分利用可見光圖像的顏色信息,顏色信息對于每個模態下的行人聚類是有益的。所以,為了解決RGB圖像與紅外圖像之間高度異構的問題,本文提出了一個新的異質圖像增廣方法,即圖2(d)。
圖2(d)為本文方法:采用雙流網絡作為基礎網絡,通過異質圖像卷積生成器生成的異質圖像減小模態差異,使用色彩抖動對紅外圖像進行處理,模擬光照變化。生成圖像作為原始圖像的增廣樣本,在減少模態差異的同時,還利用了原始行人圖像中顏色、紋理等有益信息。
對于可見光圖像,如圖3所示,輕量級異質圖像卷積生成器采用的卷積核,將尺寸為(通道數/高度/寬度)的RGB三通道圖像在通道上降維壓縮成單通道圖像,隨后采用修正線性單元(Rectiflied Linear Unit,ReLU)和批量歸一化(Batch Normalization,BN),以改善模型的非線性表達能力,輸出的單通道圖像擴展為與紅外一致的三通道圖像。通過異質圖像卷積生成器生成的新樣本與紅外圖像一起輸入到雙流網絡中統一進行訓練,隨著損失函數的逐漸收斂和網絡反向傳播優化,訓練過后的異質圖像卷積生成器能夠生成近似紅外的新圖像。
實驗結果表明,異質圖像增廣方法(HIA)在兩種搜索模式下均達到了很好的效果,在常用的全搜索模式下,將本文構建的基礎雙流網絡(Baseline)與應用HIA方法的雙流網絡(Baseline+HIA)進行對比,后者在rank-1和mAP上的絕對百分比提高了6.21%和4.31%。將Baseline與應用HIA和CFA方法的雙流網絡(Baseline+HIA+CFA)進行對比,后者在在rank-1和mAP上的絕對百分比提高了9.30%和6.20%。
如表4所示,分別在RegDB數據集的兩種測試模式(可見光檢索紅外和紅外檢索可見光)下進行測試實驗。實驗結果表明,在可見光檢索紅外模式下,與Baseline相比,HIA方法使rank-1和mAP值絕對百分比分別提升了5.62%和5.11%,HIA和CFA聯合優化方法使rank-1和mAP值絕對百分比分別提升了8.38%和7.30%。
3? ? 結論
為了減少可見光圖像和紅外圖像之間的模態差異,在圖像層面上,我們提出了基于雙流網絡的異質圖像增廣方法,利用輕量級異質圖像卷積生成器從原始可見光圖像生成異質圖像,采用色彩抖動方式從原始紅外圖像生成新紅外圖像,在此基礎上,我們還設計了基于異質圖像的正樣本對約束損失,用于優化輕量級異質圖像卷積生成器。在特征層面上,我們提出了基于模態分類的跨模態特征對齊方法,通過兩個模態分類器和跨模態特征對齊損失不斷引導網絡學習模態共享特征。在兩個公開數據集SYSU-MM01和RegDB上的實驗結果表明了本文方法的優越性。
參考文獻:
[1] Ye Mang,Wang Zheng, Lan Xiangyuan, et al. Visible thermal person re-identification via dual-constrained top-ranking[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence. San Francisco:Margan Kaufmann,2018: 1092-1099.
[2] Ye Mang,Wang Zheng,Li Jiawei,et al. Hierarchical discriminative learning for visible thermal person re-identification[C]//Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. 2018:7501-7508.
[3] Dai Pingyang,Ji Rongrong,Wang Haibin,et al. Cross-modality person re-identification with generative adversarial training[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence. San Francisco:Margan Kaufmann,2018:677-683.
[4] Wang Zhixiang,Zheng wang,Zheng Yinqiang,et al. Learning to reduce dual-level discrepancy for infrared-visible person re-identification[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). NJ:IEEE,2019:618-626.
[5] Ye Mang, Lan Xiangyuan, Wang Zheng, et al. Bi-directional center-constrained top-ranking for visible thermal person re-identification[J]. IEEE Transactions on Information Forensics and Security,2019,15:407-419.
[6] Wen Yandong,Zhang Kaipeng,Li Zhifeng,et al. A discriminative feature learning approach for deep face recognition[C]//Computer Vision–ECCV 2016:14th European Conference. Cham:Springer,2016:499-515.
[7] Wang Guanan,Zhang Tianzhu,Cheng Jian,et al. RGB-infrared cross-modality person re-identification via joint pixel and feature alignment[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. NJ:IEEE,2019:3623-3632.
[8] Wu Ancong, Zheng Weishi, Yu Hongxing, et al. RGB-infrared cross-modality person re-identification[C]//Proceed-ings of the IEEE international conference on computer vision. NJ:IEEE,2017:5380-5389.
[9] Hao Yi,Wang Nannan,Li Jie,et al. HSME: hypersphere manifold embedding for visible thermal person re-identification[C]//Proceedings of the AAAI conference on artificial intelligence. Menlo Park:AAAI,2019,33(01):8385-8392.
[10] Zhu Junyan,Park Taesung,Isola Phillip,et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. NJ:IEEE,2017:2223-2232.
[11] Ian Goodfellow,Jean Pouget-Abadie,Mehdi Mirza,et al. Generative adversarial networks[J]. Communications of the ACM, 2020,63(11):139-144.
[12] Hermans A,Beyer L,Bastian L. In defense of the triplet loss for person re-identification[J/OL].[2022-12-23].http://arxiv.org/abs/1703.07737.preprint arXiv:1703.07737,2017.
[13] Nguyen Dat Tien,Hong Hyun Gil,Kim Wan Ki,et al. Person recognition system based on a combination of? body images from visible light and thermal cameras[J]. Sensors,2017,17(3):605-633.
[14] Luo Hao,Gu Youzhi,Liao Xingyu,et al. Bag of tricks and a strong baseline for deep person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. NJ:IEEE,2019:4321-4329.
[責任編輯:王妍]
Cross-modality Visible-infrared Person Re-identification
Based on Joint optimization of Image and Feature
ZHANG Hui1, LIU Shihong2, ZHONG Wu1
(1. Wuhan Melit Communication Co., Ltd., Wuhan 430075, Hubei;
2. Chongqing Jinmei Communication Co., Ltd., Chongqing 400030)
Abstract:Cross-modality Visible-infrared Person Re-identification (VI-ReID) aims to match the person images captured under visible and infrared cameras, which is very challenging. In order to reduce the modality difference between visible and infrared images, this paper proposes a heterogeneous image augmentation method and a cross-modality feature alignment method to optimize the VI-ReID network, uses lightweight heterogeneous image convolution generator to augment visible images, uses color jitter to augment infrared images, and optimizes lightweight heterogeneous image convolution generator by using positive samples to constrain loss. On this basis, two modality classifiers and cross-modality feature alignment loss continuously guide the network to learn modal shared features. Extensive experiments show that our method has excellent performance, achieving the accuracy of 57.82%/54.35% for rank1/mAP and 80.39%/75.05% on SYSU-MM01 and RegDB datasets respectively.
Key words:VI-reID;modality differences;heterogeneous image enhancement;cross-modality feature alignment
收稿日期:2023-01-02
作者簡介:張輝(1969-),男,湖北武漢人,武漢邁力特通信有限公司高級工程師,主要研究方向:有線無線通信系統傳輸接入交換技術;
劉世洪(1971-),男,重慶人,重慶金美通信有限責任公司高級工程師,主要研究方向:數字信號處理及光通信;
鐘武(1982-),男,湖北黃岡人,武漢邁力特通信有限公司工程師,主要研究方向:通信技術、圖像識別。
