
基于改進YOLOv5的割草機器人工作環境障礙物檢測方法研究
2023-06-17 06:14:39王新彥易政洋
中國農機化學報 2023年3期
關鍵詞:深度學習
王新彥 易政洋
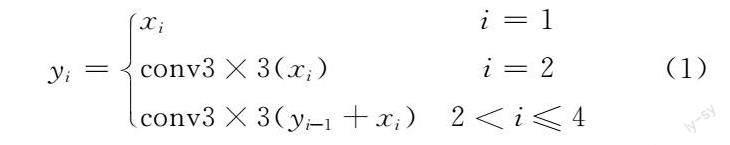
摘要:為實現割草機器人在計算資源有限的情況下快速、準確地定位并識別工作環境中的障礙物,提出一種基于濾波器剪枝的改進YOLOv5s深度學習模型的割草機器人工作環境下障礙物的檢測方法。首先,將YOLOv5模型中的Bottleneck殘差塊改為分層殘差結構,以更細粒度地表示多尺度特征,同時增加網絡感受野;另外,在殘差塊尾部加入SE模塊,用來對特征圖重新標定;其次,對改進后的算法進行濾波器剪枝;最后,針對割草機器人工作環境中的常見障礙物建立相關數據集,并使用剪枝后改進YOLOv5s作為深度學習模型進行檢測。試驗結果表明:改進后的YOLOv5模型大小減少18.8%,mAP增加0.1%。對改進YOLOv5模型進行剪枝后,比原YOLOv5模型計算量降低36.6%,模型大小降低33.3%,推理速度減少1.9 ms。剪枝后本文模型的mAP值分別比YOLOv4,YOLOv4-tiny,YOLOv3,YOLOv3-tiny高1.3%,9.5%,5.8%,22.1%。
關鍵詞:深度學習;割草機器人;目標檢測;模型剪枝
中圖分類號:TP391.4
文獻標識碼:A
文章編號:2095-5553 (2023) 03-0171-06
Abstract: In order to realize the fast and accurate positioning and identification of obstacles in the working environment by lawn mowing robot with limited computing resources, an obstacle detection method of mowing robot based on improved YOLOv5s deep learning model with filter pruning is proposed. Firstly, the YOLOv5 model uses a layered residual structure to represent multiscale features with finer granularity, and the network receptive fields are added. In addition, SE module is added to the tail of the residual block to recalibrate the feature map. Secondly, the filter pruning is performed for the improved algorithm. Finally, the relevant data sets were established for common obstacles in the working environment of lawn mowing robot, and the improved YOLOv5s after pruning was used as a deep learning model for detection. Experimental results show that the size of the improved YOLOv5 model is reduced by 18.8%, and the mAP is increased by 0.1%. After pruning the improved YOLOv5 model, the computational amount and the model size are reduced by 36.6%, 33.3%, and 1.9 ms, respectively, compared with the original model. After pruning, the mAP of the final model is 1.3%, 9.5%, 5.8% and 22.1% higher than that of YOLOv4, YOLOV4-tiny, YOLOv3 and YOLOV3-tiny, respectively.
Keywords: deep learning; mowing robot; object detection; model pruning
0引言
人工割草是一項單調且耗時的工作,并且還需要面臨草坪坡度、障礙物、碎石,甚至是草叢有害昆蟲的威脅,割草機器人的出現使這些問題得到了解決。市場上的割草機器人避障系統主要依靠接觸傳感器、導線技術等傳統手段,效率不高且易損壞障礙物[1]。隨著近幾年深度學習的快速發展,基于深度學習的目標檢測技術可以使割草機器人更智能、有效地識別障礙物[2]。通過檢測障礙物的種類,可以制定相關的避障策略。同時,可以對草坪環境中的綠植和公共設施進行監管,以便后期維護。
為了使割草機器人擺脫傳統方法,周結華等[3]基于移動機器人平臺設計了一款運用高精度差分GPS技術采集機場草坪邊界和障礙物的位置信息的大型割草機器人。謝忠華依據CCD攝像機和超聲波測距傳感器,重點進行了割草機器人草地識別和非接觸避障兩方面的研究。而深度學習可以自行學習相關障礙物特征,并隨著訓練數據量的增加,可以顯著提高精度。左錦等[4]設計了基于計算機視覺導航的割草機器人,通過攝像頭采集草坪場景的圖像,利用基于深度學習的圖像分割技術識別草坪已割區域和未割區域,提取區域間的分割線作為機器人的規劃路徑,取得很好的效果。
割草機器人計算資源有限,且具有一定危險性,需要在保證檢測精度和速度的同時對模型進行壓縮。為此,采集大量草坪環境障礙物圖像作為模型訓練數據,并提出了一種基于改進YOLOv5模型的割草機器人工作環境障礙物檢測方法。在YOLOv5模型Bottleneck殘差塊中構造分層殘差連接,增加網絡感受野的同時,以更細粒度地表示多尺度特征。在殘差塊中,通過1×1卷積進行特征融合后,加入SE模塊,用來對特征圖重新標定。最后,為了進一步輕量化模型,對改進后的算法進行濾波器剪枝。通過該算法可實現割草機器人在草坪環境下快速有效識別障礙物,為割草機器人自主避障及草坪環境智能化管理提供技術參考。
1材料與方法
1.1數據采集
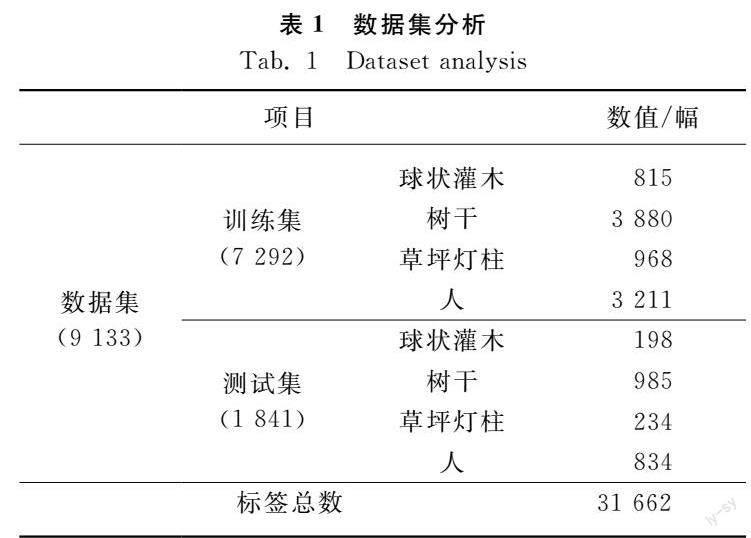
圖像數據采集于中國鎮江地區。數據集采集時間從2020年11月13日至2021年3月7日,涉及晴天、陰天、強光等光照條件。選取4類目標包括樹干、球形灌木、草坪燈柱和人作為數據集對象,另外,從基準數據集PASCAL VOC 2012和網絡中獲取一部分類別為人的圖像補充進數據集。數據集共9 133幅圖像,存在樹干圖像4 838幅、人類圖像4 045幅、草坪燈柱1 202幅、球形灌木1 013幅。
1.2數據預處理
采用LabelImg軟件對9 133幅圖像中的目標障礙物使用2D矩形框進行標注,標注文件保存為PASCAL VOC格式的XML文件。將亂序后的數據集按照8∶2的比例將數據集分成訓練集和測試集,具體參數見表1,使用訓練集中的圖片樣本訓練模型,而測試集被用來模擬現實場景,測試模型的泛化能力。
1.3YOLOv5模型
目前,基于深度學習的目標檢測方法主要分為兩種,一種是二階段算法,如R-CNN[5]、SPP-Net[6]、Fast R-CNN[7]等。這些算法首先生成候選區域,然后對候選區域進行分類,精度提高了,但速度不滿足割草機器人實時性的要求。另一種是單階段算法,如YOLO系列[811]以及SSD系列[1215]為主,該類算法丟棄了生成候選區域這一步,將物體檢測視為一個回歸問題,從而大幅度提升了檢測速度,也由此導致精度的降低。
YOLO算法作為單階算法,首先,通過模型中的特征提取模塊對輸入圖像提取特征,得到S×S大小的特征圖,然后將輸入圖像分成S×S個網格單元。在YOLOv3和YOLOv4中,當目標的真實邊界框中心落入某網格單元中時,則由該網格單元進行檢測,每個網格單元會預測3個不同尺度的邊界框和置信度信息。而在YOLOv5中,則通過真實邊界框中心最近的3個網絡單元進行預測,可以預測3~9個邊界框和對應的置信度信息,這使得模型訓練速度得到了提高。
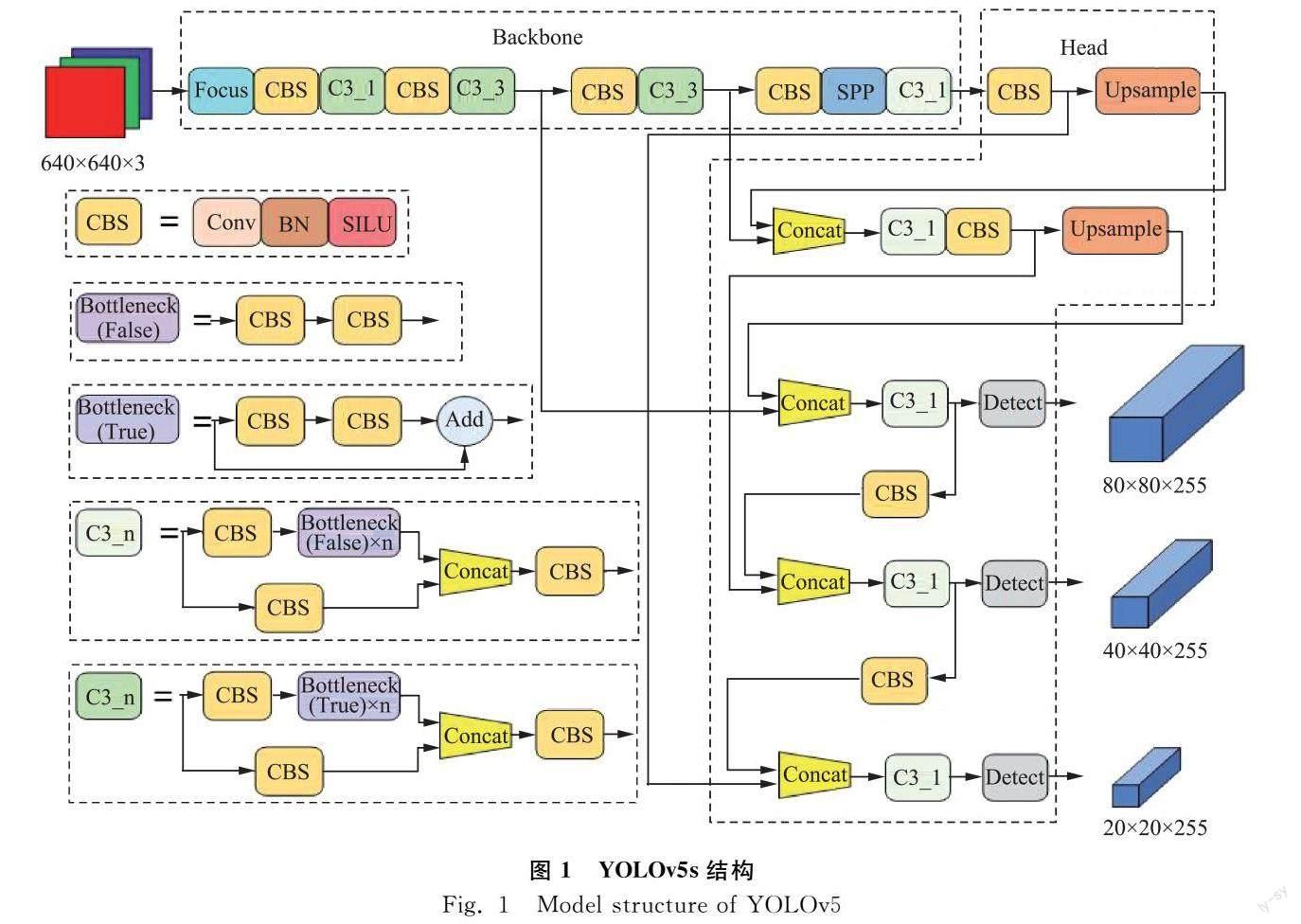
YOLOv5模型通過控制網絡的規模可以分為s,m,l,x四個不同復雜度的模型,本文在YOLOv5s的基礎上進行改進,YOLOv5s結構如圖1所示。在YOLOv5s中將整個模型分為了主干和頭部,在YOLOv5s的主干部分包括了Focus、Conv、C3和SPP(Spatial Pyramid Pooling)[16]四個模塊。當640×640×3的圖片輸入模型時,首先使用Focus模塊對圖片進行切片,得到4個320×320×3的互補特征圖,再經過Concat以及1個3×3的Conv模塊,最終特征圖變為320×320×32,相對于普通下采樣操作,可以減少信息的損失。Conv是一個基本模塊,由Convolution層、Batch normalization層和SILU激活函數依次組合而成,可以用來作為其他模塊的組成部分,也可以用來進行下采樣等操作。C3模塊是主干部分的主要組成模塊,用來進行殘差學習。C3在BottleneckCSP模塊的基礎上去掉了兩個Conv模塊和一個BN層,使網絡更加簡潔,降低了計算量和內存成本。SPP模塊使用多個池化窗口對圖像進行最大池化,增大感受野的同時不會降低檢測速度。
YOLOv5s模型的頭部由PAN(PathAggregation Network)模塊以及Detect模塊組成。PAN在FPN(Feature Pyramid Network)的基礎上增加了一個自底向上的特征金字塔,不僅能增強語義信息,還對定位信息進行了傳遞。同時,PAN具有動態特征池化和全連接層融合的特點,對分類和位置更加有利。YOLOv5s的Detect模塊與YOLOv4、YOLOv3基本相同,從三個不同尺度特征圖中分別檢測大、中、小三種規格的目標。
1.4改進YOLOv5模型
如圖2所示,把YOLOv5s作為基礎模型,借鑒Gao等[17]所提出Res2Net的思想,首先在圖2(a)中的Bottleneck中構造分層的殘差連接,改進后的Bottleneck模塊如圖2(b)所示。將經過1×1卷積后的輸出特征圖劃分為4個通道數相等的子集,從第二個子集x2開始進行3×3卷積操作,其輸出的特征圖y2與x3相加并輸入相應3×3卷積核。簡而言之,yi可以表達為式(1)。
以輸入、輸出通道數32為例,原來3×3卷積參數量為9 216,改進后的3個3×3卷積參數量為1 728。由于考慮到推理速度的因素,并沒有進一步將這些較小的3×3卷積改為分組卷積。之后,將4組輸出的特征圖進行拼接操作,并輸入到1×1卷積中進行特征融合。最后加入SE(SqueezeandExcitation)block[18],在通道維度上對原始特征重新標定,能夠以少量的計算量為代價來提升精度。改進后模塊內部的分層殘差結構可以更好地進行特征重用,以更細粒度表示多尺度特征并獲得不同感受野的特征組合。在大量減少計算量的同時,彌補了原本特征提取能力不足的缺點。
在YOLO系列模型訓練前,需要在數據集上使用 K-means算法進行聚類,得到9個錨框尺寸。而YOLOv5使用了自適應錨框的方法,采用K-means和遺傳學習算法自動計算出最佳錨框值。另外,訓練超參數設置為輸入圖像大小640×640,初始學習率0.01,批大小4,迭代次數300次。
實驗平臺的處理器為i7-9700kf、內存為16 G和圖形處理器為顯存11 GB的GeForce RTX2080Ti,使用的系統為Ubuntu18.04,Python版本為3.6,并且安裝了CUDA和cuDNN庫。
從圖3可以看出,訓練曲線收斂速度較快,隨著迭代次數增加,總損失函數值Loss平穩下降。當達到迭代次數epoch為250時,模型的學習效率飽和,mAP(mean Average precision)基本不再變化。結果表明,改進后的模型在割草機器人工作環境障礙物數據集上有較好的精度,為模型修剪過程奠定了基礎。
1.5基于濾波器剪枝算法的改進YOLOv5s
改進后的YOLOv5s模型的檢測精度達到預期要求,但由于割草機器人計算資源的限制,需要對模型的計算量和推理速度進行進一步優化。模型剪枝是模型壓縮和加速的一個重要方向,其主要分為權重剪枝[1920]和濾波器剪枝[2122]。濾波器剪枝相比于權重剪枝,可以得到規則的網絡模型,并加速模型的推理速度。通常,濾波器剪枝方法是通過比較濾波器范數大小,刪除范數最接近于零的濾波器。He等[23]發現實際濾波器范數的標準差太小,或者最小范數值仍然很大,并由此得出基于幾何中位數的濾波器剪枝方法。
基于幾何中位數的濾波器剪枝方法的基本思想是若第i層中存在與幾何中位數相近的濾波器,則認為這個濾波器的信息與其他濾波器相重合,甚至冗余,可以被其他濾波器所表示。首先,從改進YOLOv5s模型中的所有可學習參數中篩選出95個filter layer,對于filter layer中的每一個filter,計算該filter和其他所有filter的歐式距離之和,其中歐氏距離之和最小的filter便是所求的幾何中位數。之后,將離幾何中位數最近的(n×Pruning rate)個filter置零。在剪枝訓練過程中,被置零的filter梯度強制為0。等模型收斂后,對模型進行去零操作,得到最終剪枝后的改進YOLOv5s模型。
剪枝結果如表2所示,測試結果表明,經過濾波器剪枝后,改進YOLOv5s模型參數量減少了18%,mAP減少1.9%,模型尺寸減少了2.1,推理速度減少了5 ms。濾波器剪枝可以有效簡化并加速模型。
2.2模型性能
訓練完成的模型以batch size為16的640×640像素圖片進行測試。通過表2,可以發現改進YOLOv5s的計算量減少了23.8%,權重大小減少了2.7 MB,這是由于在將原先Bottleneck中的3×3卷積分成3個卷積后,模型參數量大量減少。改進YOLOv5s的精度幾乎保持不變,表明分層殘差結構能夠很好地補償卷積分組后的精度。其推理速度相比YOLOv5s增加了3.1 ms,改進YOLOv5s模型讀取數據總量的增加導致了推理速度變慢。本文模型的推理速度為69.8 ms,比改進YOLOv5s減少了5 ms,并且超過了YOLOv5s,這說明對模型進行濾波器剪枝可以有效加速模型。
表3為剪枝后本文模型與其他模型的比較結果。
可以發現YOLOv4-tiny的FPS和模型計算量與YOLOv3-tiny較為相近,屬于輕量化模型,然而在計算量、權重大小以及FPS上都沒有本文模型好。同時,本文模型的mAP比YOLOv4高了1.3%,計算量低82.6%,權重大小低96.3%,檢測速度快了近8倍。
2.3基于濾波器剪枝的特征圖可視化
如圖4所示,將位于改進YOLOv5s中Focus模塊后的第一個卷積層的特征圖可視化。帶有紅色框(9,21,23,25,29,32,59,60)的特征圖是要修剪掉的通道。這些選定的特征圖包括人、樹干、草坪燈柱的輪廓,可以被其余通道的特征圖所代替。
在圖5(a)和圖5(b)中,剪枝后的改進YOLOv5s可以檢測到遠處樹干,但在對圖5(a)中被遮擋的球形灌木有漏檢。在圖5(d)中,被遮擋的人未檢測出。結果表明,剪枝后的改進YOLOv5s對大面積遮擋目標的魯棒性較差,但在通常情況下,其檢出率高于其他模型。對于割草機器人工作環境的障礙物而言,剪枝后的改進模型更適用于該場景。
3結論
采用為了使割草機器人在計算資源有限的情況下更加快速、準確地檢測障礙物,使其在后期工作中能夠對草坪環境的植物以及公共設施進行監管維護,提出使用基于濾波器剪枝的改進YOLOv5s模型來對割草機工作環境中的障礙物進行定位及分類。根據訓練和檢測結果可以得到以下結論。
1)? 所提出的改進方法能夠在保證精度的情況下輕量化YOLOv5s模型,與原模型相比,模型大小減少18.8%,mAP增加0.1%。經過剪枝后,本文模型比原YOLOv5模型計算量降低了36.6%,模型大小降低33.3%,推理速度減少1.9 ms。
2)? 本文模型與YOLOv4、YOLOv4-tiny、YOLOv3、YOLOv3-tiny模型相比,mAP分別提高了1.3%、9.5%、5.8%、22.1%,模型大小分別減小了96.3%、59.1%、96.1、72.3%,識別速度分別是7.5倍、1.6倍、5.4倍、1.3倍,滿足在計算資源有限的條件下精準、快速檢測割草機器人工作環境障礙物的要求。
參考文獻
[1]Franzius M, Dunn M, Einecke N, et al. Embedded robust visual obstacle detection on autonomous lawn mowers [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2017: 44-52.
[2]Daniyan I, Balogun V, Adeodu A, et al. Development and performance evaluation of a robot for lawn mowing [J]. Procedia Manufacturing, 2020, 49: 42-48.
[3]周結華, 代冀陽, 周繼強. 面向大型機場草坪的割草機器人路徑規劃及軌跡跟蹤控制研究[J]. 工程設計學報, 2019, 26(2): 146-152.
Zhou Jiehua, Dai Jiyang, Zhou Jiqiang, et al. Research on path planning and trajectory tracking control of mowing robot for large airport lawn [J]. Chinese Journal of Engineering Design, 2019, 26(2): 146-152.
[4]左錦, 倪金鑫, 陳章寶. 視覺導航草坪修剪機器人控制系統設計[J]. 工業控制計算機, 2020, 33(2): 81-82.
Zuo Jin, Ni Jinxin, Chen Zhangbao. Design of control system for visual navigation mowing robot [J]. Industrial Control Computer, 2020, 33(2): 81-82.
[5]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[6]He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[7]Girshick R. Fast R-CNN [J]. Computer Science, 2015.
[8]Redmon J, Divvala S, Girshick R, et al. You only look once: unified, realtime object detection [J]. IEEE, 2016.
[9]Redmon J, Farhadi A. YOLO9000: Better, faster, stronger [C]. IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017: 6517-6525.
[10]Redmon J, Farhadi A. YOLOv3: An Incremental Improvement [J]. arXiv eprints, 2018.
[11]Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection [J]. arXiv Preprint arXiv: 2004.10934, 2020.
[12]Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector [C]. European Conference on Computer Vision. Springer, Cham, 2016: 21-37.
[13]Fu C Y, Liu W, Ranga A, et al. Dssd: Deconvolutional single shot detector [J]. arXiv Preprint arXiv: 1701.06659, 2017.
[14]Li Z, Zhou F. FSSD: Feature fusion single shot multibox detector [J]. arXiv Preprint arXiv: 1712.00960, 2017.
[15]Zhang S, Wen L, Bian X, et al. Singleshot refinement neural network for object detection [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4203-4212.
[16]He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[17]Gao S H, Cheng M M, Zhao K, et al. Res2net: A new multiscale backbone architecture [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(2): 652-662.
[18]Hu J, Shen L, Sun G. Squeezeandexcitation networks [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141.
[19]Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network [J]. Advances in Neural Information Processing Systems, 2015, 28.
[20]CarreiraPerpinán M A, Idelbayev Y. “learningcompression” algorithms for neural net pruning [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8532-8541.
[21]Li H, Kadav A, Durdanovic I, et al. Pruning filters for efficient convents [J]. arXiv Preprint arXiv: 1608.08710, 2016.
[22]Yu R, Li A, Chen C F, et al. Nisp: Pruning networks using neuron importance score propagation [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 9194-9203.
[23]He Y, Liu P, Wang Z, et al. Filter pruning via geometric median for deep convolutional neural networks acceleration [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 4340-4349.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
