基于改進YOLOv5的復雜背景下交通標志識別研究
2023-06-25 18:49:55李翔宇王倩影
現代信息科技 2023年10期
李翔宇 王倩影

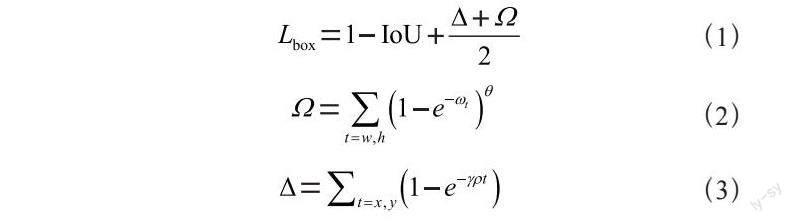
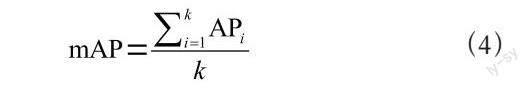
摘? 要:針對復雜路況背景下交通標志檢測任務存在辨識度低、漏檢嚴重等問題,提出一種基于改進YOLOv5s的輕量級交通標志檢測模型。首先,引入坐標注意力模塊,增強重要特征關注度;其次,對損失函數進行改進,降低邊框回歸時的自由度,加速網絡收斂;最后,在中國交通標志檢測數據集上進行實驗。結果表明,模型在保持原有YOLOv5s模型體量的情況下,mAP@0.5提高了2.7%,檢測速度達到91 FPS,對各種交通場景變化具有更好的魯棒性。
關鍵詞:交通標志檢測;YOLOv5;注意力機制;損失函數
中圖分類號:TP391.4;TP18? 文獻標識碼:A? 文章編號:2096-4706(2023)10-0030-04
Abstract: Aiming at the problems of low recognition and serious leakage in traffic sign detection tasks in the context of complex road conditions, a lightweight traffic sign detection model based on improved YOLOv5s is proposed. Firstly, the coordinate attention module is introduced to enhance the attention of important features. Secondly, the loss function is improved to reduce the degree of freedom during border regression and accelerate network convergence. Finally, experiments are conducted on the Chinese traffic sign detection dataset. The results indicate that while maintaining the original YOLOv5s model volume, model's mAP@0.5 improves by 2.7%, with a detection speed of 91FPS, and it has better robustness to various traffic scene changes.
Keywords: traffic sign detection; YOLOv5; attention mechanism; loss function
0? 引? 言
隨著社會經濟與信息技術的快速發展,無人駕駛技術也突飛猛進。交通標志作為交通系統的重要組成部分,對車輛的流量、流向起著重要的調節、疏導和控制作用,對人們出行與車輛行駛安全具有重要的保障作用。交通標志檢測作為無人駕駛系統的重要一環,受到越來越多的科研工作者的關注。傳統的交通標志檢測方法,主要通過是顏色、邊緣信息、圖片形狀等進行信息提取然后再結合機器學習方法進行檢測,其檢測精度與檢測速度往往不能令人滿意。隨著深度學習的興起,科研工作者開始將深度學習檢測算法應用到交通標志檢測任務中來。其中研究主要分為兩個方向,一類是以R-CNN[1]和Fast R-CNN[2]為代表的兩階段檢測算法,這類算法具有較高的精度,但檢測速度慢;一類是以SSD[3]與YOLO系列[4,5]為代表的單階段算法,這類算法的優勢在于檢測速度快,可以更好地勝任實時檢測任務。
目前大部分研究是基于簡單交通場景下標志識別,無法滿足現實要求。僅有的一小部分針對復雜場景的識別算法也都是針對某種特定背景,不具有普適性。董天天等人[6]先采用小波分解技術減少特定雨雪場景對檢測任務造成的干擾,然后再采用改進后的YOLOv3算法進行交通標志檢測。呂禾豐等人[7]對YOLOv5中的邊框回歸損失函數和非極大值抑制方法進行改進,雖然檢測效果有一定提升,但后處理方式較為耗時。
為了更好地解決由于天氣、光照、遮擋等復雜路況背景造成的交通標志識別度低、漏檢嚴重等問題,本文提出了一種基于改進YOLOv5s的輕量級檢測算法。改進主要包括以下兩個方面:1)在主干網絡末端引入坐標注意力模塊來應對復雜背景下的其他干擾,增加模型對重要特征的關注度。2)對邊框回歸損失函數進行改進,引入所需回歸之間的向量角度,減少預測框在收斂過程中的自由度,加速網絡收斂,提高檢測效果。
1? YOLOv5概述
YOLOv5是Ultralytics公司于2020年5月份開源的一種新型單階段目標檢測器,集成了眾多先進成果,本文采用的是最新的6.0版本,共包括四個模型,從小到大依次是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,模型越大代表參數量與計算量越大,模型越復雜,檢測精度也越高。為了保持模型的輕量化,本文在YOLOv5s的基礎上進行改進。YOLOv5的網絡結構主中要包括輸入端、主干網絡(Backbone)、特征融合網絡(Neck)和輸出端四部分。輸入端主要包括Mosaic4數據增強、K-means聚類生成錨框以及圖片縮放等圖像預處理操作。6.0版本與之前版本相比在Backbone部位有些許改動,首先,用一個6×6卷積層替換了之前網絡第一層Focus模塊進行下采樣操作,兩者在理論上是等價的,但是對于現有的一些GPU設備(以及相應的優化算法)使用6×6大小的卷積層比使用Focus模塊更加高效。其次,用SPPF層替換了之前的SPP層,之前的SPP層由尺寸大小分別為5×5、9×9、13×13的池化層并聯而成,現在的SPPF使用三個5×5的池化層進行串聯,兩者效果相同,但SPPF速度提升了兩倍。此外主干網絡還包括CBS復合模塊和C3模塊,CBS模塊中封裝了卷積層、批處理層與激活函數。Neck主要由基于FPN的PANnet特征融合網絡構成,用來加強信息傳播。最后輸出端通過CIoU來計算邊界框回歸損失,并對3個不同尺度的特征圖進行預測。
2? YOLOv5 改進
2.1? 坐標注意力機制
注意力機制是機器學習中的一種數據處理方法,可以顯著提高神經網絡的特征提取能力,廣泛應用在自然語言處理、計算機視覺等機器學習任務中。目前應用范圍較廣的注意力機制都存在一些缺陷,比如壓縮-激勵模塊僅僅建模了通道間的關系來對每個通道加權,并沒有考慮到空間結構和位置信息。混合域卷積注意力模塊將通道注意力和空間注意力進行串聯,嘗試在降低通道數后通過卷積來提取位置注意力信息,但依靠卷積只能提取到局部信息,缺少了長程依賴。
針對以上問題,Hou等人[8]提出了一種新型坐標注意力模塊(Coordinate Attention, CA),如圖1所示,為了緩解2D全局池化造成的位置信息丟失,CA將通道注意力分解為兩個沿著不同方向聚合特征的1D特征編碼過程,使得模塊可以沿著其中一個空間方向捕獲長程依賴,沿著另一個空間方向保留精確的位置信息。然后,將生成的特征圖分別編碼,形成一對方向感知和位置敏感的特征圖,互補地應用到輸入特征圖來增強感興趣的目標的表示。經試驗證明,引入的CA模塊增強了網絡對目標的精確定位能力,提高了模型對重要特征關注度,明顯改善了模型檢測效果。
2.2? 損失函數改進
目標檢測任務的有效性在很大程度上取決于損失函數的定義,YOLOv5中的CIoU雖然具有較好的寬高擬合效果與偏離趨勢度量能力,但沒有考慮到所需真實框與預測框之間不匹配的方向。這種不足導致收斂速度較慢且效率較低,因為預測框可能在訓練過程中“四處游蕩”并最終產生更差的模型。為了彌補這種不足,本文使用SIoU[9]作為YOLOv5中的邊框損失函數,SIoU考慮到了所需回歸之間的向量角度,并且重新定義了懲罰指標。SIoU損失公式為:
其中θ表示一個超參數,控制著對形狀損失的關注程度,ωw和ωh表示預測框和真值框之間的真實寬高比。
3? 實驗結果與分析
3.1? 實驗環境與參數設置
本文實驗環境計算機硬件配置如下:CPU 為Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz 45 GB,GPU 為RTX 2080 Ti 11 GB,采用 Ubuntu操作系統和PyTorch 1.10深度學習框架作為實驗的運行環境。
為保證對照實驗結果的有效性,所有模型均采用相同的超參數,其中,輸入圖像尺寸為640×640、初始學習率為0.01、動量參數為0.937,最終學習率為0.1,BatchSize為32,在訓練開始后進行3輪預熱,后續采用余弦退火策略更新學習率,總共訓練300個epoch。
3.2? 數據集準備與數據增強
本文所采用的數據集為長沙理工大學制作的中國交通場景數據集[10](CCTSDB-2021),為了面向更加真實全面的交通場景圖像,2022年開源的CCTSDB-2021數據集新增加了4 000張困難樣本,其中不僅包括高速、城市、鄉鎮等多種路況,還具有雨、雪、霧、夜晚弱光、晝夜強光等多種復雜天氣,大大提升了檢測難度。該數據集將交通標志分為指示(mandatory)、禁止(prohibitory)、警告(warning)三大類。實驗過程中,選取這4 000份困難樣本按3:1的比例劃分為訓練集和測試集。使用的數據增強包括平移、左右翻轉、色調、飽和度、曝光度以及Mosaic4六方面。前五項的使用概率分別為0.5、0.1、0.015、0.7、0.4、Mosaic4是指在訓練過程中隨機選取四張圖進行拼接,來增強小目標的檢測效果。
3.3? 評價指標
為了從多個角度綜合的評價模型效果,本文選取了模型參數數量Params(M)、閾值為0.5時的平均精度mAP@0.5以及檢測速度(FPS)作為檢測算法衡量標準。mAP(mean Average Precision)是指各類別AP的平均值,計算公式為:
其中k表示類別數,AP表示PR曲線下面積。
3.4? 消融實驗
為了驗證本文提出算法在復雜路況背景下對交通標志的檢測效果,以及各項改進的有效性,設計了4組消融實驗,如表1所示。在原YOLOv5基礎上引入CA模塊后模型mAP@0.5提升了1.0%,且幾乎不帶來額外計算開銷。在此基礎上繼續對損失函數進行改進,在引入SIoU后,模型mAP@0.5提升了1.7%,與原YOLOv5模型相比,模型mAP@0.5提升了2.7%,在大幅提升檢測效果的同時,保持了模型的輕量化。圖2展示了消融實驗各階段改進的檢測精度對比。其中橫坐標表示訓練輪次,縱坐標表示IoU閾值為0.5時的平均精度。
3.5? 對比實驗
為了進一步驗證本文改進算法的有效性與先進性,我們設計了6組對照實驗,與目前主流算法在本文數據集上進行對比,如表2所示,我們分別從模型大小、檢測精度以及檢測速度三個維度對6個模型的檢測效果進行比較,無論是在相同體量的模型中對比檢測精度,還是以檢測精度為基準對比模型體量與檢測速度,均可以證明本文改進算法的有效性與先進性。
3.6? 定性評價
為了更加直觀展現算法改進前后的檢測效果,在測試集中抽取了部分交通標志檢測圖像進行定性評價,如圖3所示。左側圖像為雨夜道路伴有局部強光與反光,路況復雜、干擾嚴重,右側圖像為夜晚弱光道路目標識別,能見度低。在兩組實驗中,原YOLOv5(上面兩幅圖)均出現了漏檢,改進后的算法(下面兩幅圖)不僅檢測到了所有正確目標,并且預測框的置信度得分普遍高于原模型,說明改進后的算法捕獲到了更加準確的位置信號與語義信息,具有更強的檢測效果。
4? 結? 論
針對復雜路況背景下交通標志識別度低、漏檢嚴重等問題,本文提出了一種基于YOLOv5s的改進算法。通過引入坐標注意力來應對復雜背景下的其他干擾,提高特征關注度;增加角度損失組件來減少預測框在收斂過程中的自由度,更快貼合真實目標,提高檢測效果。本文所提改進算法與原YOLOv5相比mAP@0.5提高了2.7%,并且維持了原有的體量與檢測速度。與目前主流模型相比,本文模型在同等體量下檢測精度更高,在同等精度下體量更小、檢測速度更快,對各種場景變化具有更好的魯棒性。
參考文獻:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[2] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer vision(ICCV).Santiago:IEEE,2015:1440-1448.
[3] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [J/OL].[2022-11-18].https://arxiv.org/pdf/1512.02325.pdf.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:779-788.
[5] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. Yolov4: Optimalspeed and accuracy of object detection [J/OL].arXiv:2004.10934 [cs.CV].[2022-11-18].https://arxiv.org/abs/2004.10934.
[6] 董天天,曹海嘯,闞希,等.復雜天氣下交通場景多目標識別方法研究 [J].信息通信,2020(11):72-74.
[7] 呂禾豐,陸華才.基于YOLOv5算法的交通標志識別技術研究 [J].電子測量與儀器學報,2021,35(10):137-144.
[8] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attention for Efficient Mobile Network Design [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville:IEEE,2021:13708-13717.
[9] GEVORGYAN Z. SIoU Loss: More Powerful Learning for Bounding Box Regression [J/OL].arXiv:2205.12740 [cs.CV].[2022-11-19].https://arxiv.org/abs/2205.12740.
[10] ZHANG J M,ZOU X,KUANG L D,et al. CCTSDB 2021: A More Comprehensive Traffic Sign Detection Benchmark [EB/OL].[2022-11-20].http://hcisj.com/articles/?HCIS202212023.
作者簡介:李翔宇(1997—),男,漢族,河北石家莊人,碩士研究生在讀,研究方向:機器學習與大數據分析、目標檢測;王倩影(1984—),女,漢族,河北保定人,副教授,博士研究生,研究方向:深度學習。
