基于兩階段降維的復合數據股票趨勢預測
2023-06-28 01:37:54趙澄秦楚劉煒周潔
上海管理科學 2023年3期
關鍵詞:深度學習
趙澄 秦楚 劉煒 周潔
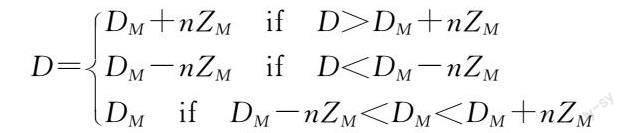
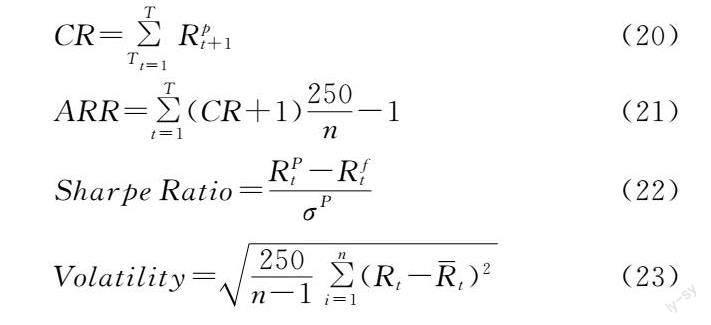
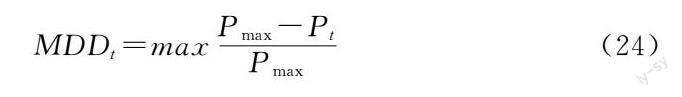
作者簡介:趙澄(1985—),男,博士,高級工程師,研究方向:金融工程、人工智能;秦楚(1996—),女,碩士研究生,研究方向:金融工程、量化投資。
文章編號:1005-9679(2023)03-0117-08
摘 要: 包含豐富種類衍生變量的股票數據有利于更全面地分析市場變化,但其同時包含連續和離散數據,難以充分利用,并且高維數據的訓練效率不高,且各維度之間存在不同程度的相關性,使得機器學習預測的效果欠佳。對此,研究提出了一種兩階段降維方法,通過結合無監督和有監督降維,在除去冗余特征、降低特征間相關性的同時,可以有效地將離散數據融入連續數據,將降維結果作為時變數據通過長短期記憶神經網絡(Long Short-term Memory , LSTM)進行分析預測。實驗結果證明,預測模型在預測精度、魯棒性和回測收益方面相比于傳統方法,均得到了提高。
關鍵詞: 兩階段降維;高維復合數據;股票趨勢預測;深度學習;長短期記憶網絡
中圖分類號: TP 391
文獻標志碼: A
Abstract: Stock data containing a rich variety of derived variables are useful for more comprehensive analysis of market changes, but they contain both continuous and discrete data, which are difficult to fully utilize. Moreover, the inefficient training of high-dimensional data and the varying degrees of correlation among dimensions make machine learning prediction ineffective. In this regard, a two-stage dimensionality reduction method is proposed, which can effectively integrate discrete data into continuous data by combining unsupervised and supervised dimensionality reduction to remove redundant features and reduce correlation between features. The dimensionality reduction results are analyzed and predicted as time-varying data by Long Short-term Memory (LSTM) neural network. Experiments prove that the prediction model has been improved in terms of prediction accuracy, robustness and backtesting gain compared with the traditional method.
Key words: two-stage dimensionality reduction; high-dimensional complex data; stock trend prediction; deep learning; LSTM
本文從高維復合數據的處理入手,提出一種基于兩階段降維的時序數據預測模型,并通過實際市場回測進行驗證,結果表明本文提出的方法在預測精度、魯棒性和回測收益方面相比于傳統方法均有提高。
1 相關工作
為了減少各個因子間的相關性,降低數據的噪聲,研究人員使用無監督降維技術來進行降維。Chong等人使用主成分分析(Principal Component Analysis, PCA)處理財務時序數據以更好地預測股票價格,實驗表明PCA提高了模型預測精度,但它只限于處理線性可分的數據。針對股票數據非線性的特點,Yu等人將局部線性嵌入(Local Linear Embedding, LLE)用于降低影響股票價格特征的維度,實驗結果表明該方法在降維的同時保留了股票數據的流形結構,提高了預測模型的泛化能力,但對參數精度的要求較高。
相比于無監督降維,有監督降維側重于發現類別間的判別特征,可以利用先驗信息提取重要特征。如Ntakaris等人基于線性判別分析(Linear discriminant analysis, LDA)實現在線特征選取,從270個股票市場因素中提取重要特征,結果表明該方法能夠取得較好的預測效果,但受限于降維的維度,在處理高維復雜數據方面可能造成重要信息丟失。Jiang等將隨機森林(Random Forest, RF)等基于樹結構的方法提取重要特征用于模型預測,從實驗結果看出其預測性能有所提高,但股票數據間的相關性可能導致有監督降維選取出冗余特征,并且過度擬合結果也會影響模型泛化能力。
本文針對結合了財務數據、技術指標、行業板塊數據構建的復合股票數據,提出一種兩階段降維方法。該方法通過結合無監督和有監督降維的方式,在除去冗余特征、消除特征間相關性的同時,根據標簽數據獲取對股票趨勢預測影響重要的特征,合理地融合了離散和連續型數據,并將獲取的時序特征通過LSTM進行趨勢預測。
2 方法
2.1 復合數據描述及數據預處理
2.1.1 數據描述
本文獲取的股票市場因子如表1所示,包括43個基本面因子、23個技術面因子和2個行業概念因子,行業概念根據申萬二級劃分,行業為124類,板塊為247類,如表1所示。
2.1.2 數據預處理
為了更好地預測股票走勢,本文對于股票連續數據進行了以下的預處理:
1)股票市場的波動性和一些特殊事件可能導致數據出現偏離正常邏輯的離群值,可能降低模型的泛化能力。因此,我們采用絕對值中位數法(Median Absolute Deviation, MAD)來處理離群值,如公式(1)所示:
2)股票數據也會出現缺失值、股票停牌、數據獲取失敗等,本文取缺失值前后現有值的平均值來填充。
3)不同數據間的影響使得選取出的股票具有不希望看到的偏向,如股票市值和投資取向的高相關性導致選出的股票比較集中在某些特定市值區間,本文通過中性化來減少偏差和影響,如公式(2)所示:
其中,殘差εi為因子i中性化后的值,Di表示i因子值,β表示市值的權重,MktVali表示i股票的總市值。
4)不同股票數據間單位尺度不統一,本文通過Z-score將數據集標準化,消除特征間單位和尺度差異的影響,如公式(3)所示:
其中,FCi表示標準化后i特征的數據集,i表示i特征均值,δ為標準差。
對于行業、板塊類的離散數據,通過一維離散向量無法有效表示市場信息,直接作為特征輸入模型又不符合實際的金融市場狀況,而獨熱編碼將行業特征映射到高維空間使其歐氏距離更合理。它通過將板塊類型編碼為多個1和多個0的形式以表現不同板塊在樣本中的影響,使模型可以有效提取板塊信息,編碼方式如公式(4)所示:
其中,FDt表示t時刻編碼后的數據集。
2.2 兩階段降維——LLE-PCA_RF
本文結合有監督和無監督降維方法提出了一種兩階段降維方法——LLE-PCA_RF,該方法的具體流程如圖1所示。在第一階段中,針對連續數據高維非線性的特點,使用非線性降維方法LLE處理,而獨熱編碼向量化的離散數據經過行業劃分后二次PCA降維處理,第二階段通過RF提取出第一階段重要的股票特征,用于股票趨勢預測。該方法針對離散和連續數據的特性分別采用無監督降維方法在降低維度的同時減少特征間的相關性,而有監督降維根據先驗知識確保了降維后的重要信息不丟失。
2.2.1 LLE降維
圖1第一階段的股票連續數據(FC)包括基本面、技術面的眾多指標,具有高維非線性的特點。而線性降維方法難以有效處理非線性數據,基于流形學習的LLE降維方法通過在低維保持高維空間的流形結構以提取數據信息,它劃分局部區域以線性表示樣本點,并計算降維前后的權重系數使其盡可能相同以最小化誤差。對于股票數據來說,相關性較高的股票數據點間的歐氏距離相近,局部區域內可以線性表示,LLE能盡可能在保留不同股票數據間的非線性結構的同時減少輸入模型的特征維度。
3 參數設置及優化
3.1 第一階段降維參數
對連續型股票數據使用LLE降維,其降維效果主要受降維后的維度和鄰近值k的影響。本文先采用最大似然方法估計降維后的維度,然后在確定維度的基礎上優化鄰近值k。通過最小化重構誤差(Reconstruction error)確定最佳的近鄰點k,結果如圖3所示。從圖3中可以看出,最優的k值為6。
對編碼后離散型股票數據進行PCA降維,過PCA降維后的主成分解釋數據集的累計比例如表2所示。這些主成分是根據其解釋能力進行排序的,表2列出的第一個主分量表示最大特征值對應的特征向量,即最有影響力的主分量。從表2中可以看出,前27個主成分可以解釋數據集近90%的變化,之后的成分解釋能力不足10%,因而可以忽略。
3.2 第二階段降維參數
為了保證計算重要特征的穩定性,本文將決策樹數量m設置成相對較大的值,為1000。圖4反映了上述特征對股票趨勢預測的影響程度,并按照降序排列。從圖4中可以看出,第26位之后的特征對股票趨勢預測的貢獻程度低于1%,可以忽略。
3.3 降維比例參數
本文對一、二階段的降維比例參數P和連續、離散數據的取值比參數G進行了分析。兩參數不同取值在測試集上股票預測正確率的結果如圖5所示。從圖5中可以看出,參數的取值對預測結果有較大影響,當P取值為13且G取值為8時,預測準確率最高。
3.4 LSTM參數設置
通過實驗調參,LSTM的參數設置如下:1)向量長度根據時間步長設置為5;2)LSTM隱藏層數設置為2層,每個隱藏單元數量為45;3)激活函數采用Relu函數。
4 實驗設置和結果分析
4.1 實驗設置
本文選取滬深300市場(HS300)作為研究對象,剔除了被標記為特殊處理(Special treatment, ST)、上市未滿3個月、停牌以及退市的股票。使用的原始數據集來源于聚寬量化交易平臺。數據集時間段為2009年1月至2020年1月,訓練集和測試集劃分比例為4∶1。實驗是在CPU為2.90GHz Intel Corei 5,內存為16GB的計算機上運行的,編程語言為Python 3.7,集成開發環境為PyCharm。
4.2 實驗對比分析
為了進一步驗證本文方法的有效性,將從三個方面對比分析:1)將兩階段降維與其他降維方法進行比較,評估該降維方法對模型性能預測的效果;2)評估降維結果對不同學習模型的性能;3)根據模型預測結果進行模擬交易,評估該方法在市場交易中的可行性。對比實驗均對HS300市場成分股進行測試,結果取平均值。
4.2.1 降維方法對比分析
將PCA、LLE、RF、LLE-PCA、PCA_RF、LLE-RF與本文提出的兩階段降維方法進行對比,通過準確率(Accuracy)、召回率(Recall)和馬修斯相關系數(Matthews correlation coefficient, MCC)指標評估降維方法對模型趨勢預測的影響,指標計算公式如下:
Accuracy=TP+TNTP+FP+TN+FN(17)
Recall=TPTP+FN(18)
MCC=TP×TN-FP×FN(TP+FP)(TP+FN)(TN+FP)(TN+FN)(19)
其中,TP、TN、FP、FN分別為預測上漲趨勢正確、預測上漲趨勢錯誤、預測下跌趨勢正確以及預測下跌趨勢錯誤。
不同降維方法在測試集上的預測結果如表3所示,結果顯示,LLE-PCA_RF在準確率、召回率以及馬修斯相關系數方面均優于其他模型。因為LLE-PCA_RF針對不同統計特性的股票數據分別采用相對合適的方法消除股票數據的冗余以及相關性,并通過RF的重要性度量提取出對股票趨勢預測重要的特征,而單階段的PCA、LLE、RF無法在降低維度的同時既考慮股票數據間的相關性,又選取出影響股票市場的重要特征。盡管PCA_RF、LLE_RF的準確率、召回率相對較高,但馬修斯相關系數遠不如本文提出的LLE-PCA_RF方法。此外,RF的馬修斯相關系數值在所有模型中最低,可能是特征間相關性影響了LSTM的整體預測結果。
不同降維方法在訓練集和測試集的平均預測準確率如圖6所示。從圖6可以看出,相比其他降維方法,LLE-PCA_RF在訓練集、測試集都明顯有著更高的準確率,同時整體預測結果較為穩定,魯棒性更好。LLE-PCA_RF在訓練集上達到了約85%的準確率,而且在測試集上也達到了約60%的準確率。RF、LLE、PCA這些方法無法處理離散型數據,因而無法充分利用數據,以至于結果不如LLE-PCA_RF。
不同降維方法在訓練集和測試集的迭代過程中的loss變化曲線分別如圖7、圖8所示。從圖8中可以看出,相比其他降維方法,LLE-PCA_RF在測試集上的loss最低值更低,且由于過擬合產生的loss上升更平緩,這是因為LLE-PCA_RF不單純依靠于RF這樣的后驗式降維算法,因而提高了其抗過擬合性。
4.2.2 模擬交易對比分析
本文針對LLE-PCA_RF_LSTM、LLE_RF_LSTM以及LLE-PCA_RF_RNN方法在HS300市場進行模擬交易對比,根據模型預測趨勢結果進行買賣操作,當預測收益率大于0時,買入該股票,而預測收益率小于0時,賣出該股票,同時與買入并持有策略(Buy_Hold)進行對比。交易時間為2019年1月至2020年1月,在交易過程中不考慮產生的交易費用。通過累計收益率(Cumulative return, CR)、年化收益率(Annualized rate of return, ARR)、夏普比率(Sharpe Ratio)、波動率(Volatility)、最大回撤(Maximum Drawdown, MDD)來評估模型在市場中的性能,計算公式如下:
模擬交易回測結果如圖9所示,所有模型均優于買入持有策略模型。從圖9中可以看出,在整個交易過程中,LSTM模型的超額收益波動率較大,且收益遠遠低于LLE-PCA_RF_LSTM、PCA_RF_RNN以及LLE_RF_LSTM模型,這說明降維處理后的數據去除了噪聲,更好地表現了市場變化,提高了時序數據處理的效率。從圖9中可以看出LLE-PCA_RF_LSTM的超額收益逐步增加并一直高于其他模型,在交易過程中取得了最高的收益。
不同模型在HS300市場的整體表現如表4所示。LLE-PCA_RF_LSTM在年化收益率、夏普比率、最大回撤這些指標上的表現均優于其他模型,同時保持較低的最大回撤,表明該模型合理平衡了收益和風險程度。經過兩階段降維處理的LSTM模型有效提取了市場的重要信息,從而提高了模型預測精度和穩定性;而單個LSTM模型的表現顯然不如其他模型,其波動率指標最高,達到了0.221;另外,無論是單層降維方法還是其他降維方法,結果均不如LLE-PCA_RF_LSTM模型,這也驗證了LLE-PCA_RF_LSTM模型在HS300市場能更好地處理高維復合數據,并獲取穩定的超額收益。
5 總結
本文針對將復合數據用于股票預測問題提出了一種兩階段降維方法。通過結合有監督和無監督降維方法對連續和離散數據進行處理,在減少冗余、相關特征的同時選取出對股票趨勢預測重要的特征。實驗對比了不同降維方法,驗證了兩階段降維方法的有效性。另外,將兩階段降維后的數據用于LSTM模型預測股票趨勢,并制定投資策略,在模擬交易中獲得較高的超額收益,證明了本文提出算法的有效性。未來的工作主要是進一步拓展不同類型股票數據用于股票預測,包括股民情緒、K線圖等影響股市的因素。
參考文獻:
[1] CHONG E, HAN C, PARK F C. Deep learning networks for stock market analysis and prediction: methodology, data representations, and case studies[J]. Expert Systems with Applications, 2017(83): 187-205.
[2] YU Z, QIN L, CHEN Y, et al. Stock price forecasting based on LLE-BP neural network model[J]. Physica A: Statistical Mechanics and Its Applications, 2020, 553: 124197.
[3] ZHANG Y, ZHANG Z, QIN J, et al. Semi-supervised local multi-manifold isomap by linear embedding for feature extraction[J]. Pattern Recognition, 2018(76): 662-678.
[4] NTAKARIS A, KANNIAINEN J, GABBOUJ M, et al. Mid-price prediction based on machine learning methods with technical and quantitative indicators[J]. Plos one, 2020, 15(6): e0234107.
[5] JIANG M, LIU J, ZHANG L, et al. An improved Stacking framework for stock index prediction by leveraging tree-based ensemble models and deep learning algorithms[J]. Physica A: Statistical Mechanics and its Applications, 2020(541): 122272.
[6] 劉乾超. 基于離散選擇模型的推薦系統改進算法[J]. 上海管理科學, 2020: 1.
[7] 劉英鐸, 陳奕. 企業人工智能戰略驅動因素研究:基于 LASSO 回歸和 CART 算法的分析[J]. 上海管理科學, 2019: 6.
[8] MA J, YUAN Y. Dimension reduction of image deep feature using PCA[J]. Journal of Visual Communication and Image Representation, 2019(63): 102578.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
