
基于GASF與MSVM的放射性核素識別方法
2023-07-07 04:51:06周思益張江梅劉灝霖馮興華張草林
西南科技大學學報 2023年2期
周思益 張江梅 劉灝霖,3 馮興華 張草林
(1.西南科技大學信息工程學院 四川綿陽 621010;2.核廢物與環境安全國防重點學科實驗室 四川綿陽 621010;
3.中國科學技術大學自動化系 合肥 230026)
核素識別技術是保障核安全的一項基本技術,對于核安全發展具有重要的現實意義[1]。核素識別是指在真實探測環境中利用探測器接收放射性同位素發出的γ射線并生成能譜數據,對能譜進行分析實現對核素種類的識別。傳統核素識別的核心思想是尋找能譜中的全能峰,在能量刻度基礎上與核素庫中核素能量進行對比,得到核素判別信息[2]。但是基于傳統尋峰核素識別方法在真實能譜衰減(環境噪聲和探測距離加大造成能譜被淹沒)環境中誤差較大,識別率較低,不能得到很好的識別效果。近年來,隨著機器學習的發展[2],基于機器學習的新興核素識別方法逐漸出現,主要有基于神經網絡[3-5]、AdaBoost集成學習理論[6]、模糊理論[7]和基于信息理論空間投影[8]等方法,這些方法雖然在一定程度上提高了核素識別的準確率,但不能有效處理重疊峰,且難以準確消除“假峰”。此外,大多數的研究者都是直接將一維的能譜數據作為模型輸入去尋找核素能譜的有效特征,有效特征不易于提取,而采用全能峰面積、位置等作為輸入特征,不能有效克服噪聲影響。
針對以上問題,筆者從全譜分析的角度進行核素識別,將原始能譜視作一維序列,提出基于分段聚合近似的格拉姆角和場(Gram angle sum field,GASF)算法將一維能譜數據二維化,從新的角度、新的維度去認識和探究核素能譜信息,利用雙向二維主成分分析(Bidirectional two dimensional principal component analysis,2D-2D-PCA)對二維能譜進行空間投影,獲取不同核素能譜的特征空間,實現對核素的識別,提高核素識別準確率。
1 算法分析
1.1 基于GASF的一維數據二維化方法
格拉姆角場(Gramian matrix field,GAF)是基于格拉姆矩陣提出的一種序列轉化方法[9]。GAF的基本思路是將經典的笛卡爾坐標系下的序列轉移到極坐標系中,利用三角函數可將一維的序列轉化為二維的GAF矩陣,實現一維序列二維化。對于一個待轉化的核素能譜序列Y={y1,y2,…yN},將能譜序列中的每一個值通過式(1)進行處理,使處理后的能譜序列中的每一個值處于[-1,1]。
式中:φi表示反三角化后的角度且φ∈[0,π];ri表示第i個道址的半徑;N表示道址總數。因此,能譜中的計數值會隨著道址數的不斷增加而在極坐標上發生彎曲。
通過利用每個點之間的角度和格拉姆矩陣來進行GAF定義,格拉姆矩陣如式(3)所示:
式中I=[1,1,…1],是一個單位行向量。
通過將兩個數的內積公式定義為如式(4)所示的形式:
GAF根據采用的三角函數是余弦函數還是正弦函數會分別得到兩種不同的格拉姆場,分別是格拉姆角和場(GASF)和格拉姆角差場,由于GASF可實現逆變換,故本文采用余弦函數構造GASF。
通過GASF矩陣就可以將一維的能譜序列轉化為二維形式,同時保留了能譜序列中所有的關鍵信息。以60Co的能譜序列為例,采用GASF對其實現二維化,將結果以GASF熱力圖形式進行展示,整個過程如圖1所示。
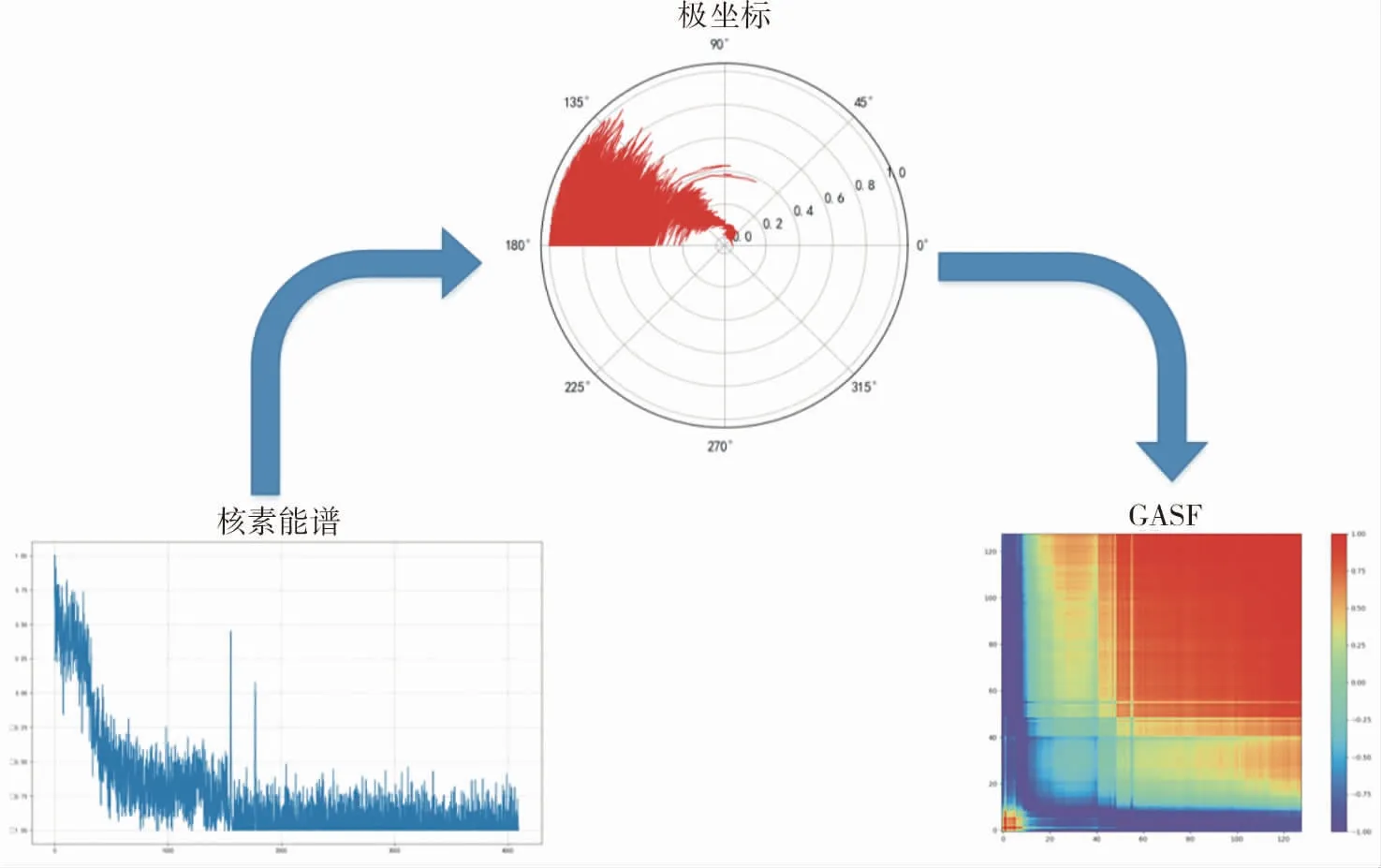
圖1 基于GASF的核素能譜二維化過程圖Fig.1 Two-dimensional process diagram of nuclide energy spectrum based on GASF
1.2 2D-PCA理論原理
1.2.1 1D-PCA理論原理
一維主成分分析(One-dimensional principal component analysis,1D-PCA)即傳統的主成分分析方法,是最重要和最常用的一種降維方式,它通過一個線性變換將原始空間中的樣本投影到新的維度空間中[10]。1D-PCA只適合用于一維數據的處理,其思想是通過線性變換找一組最優的單位正交基(即主成分),用它們的線性組合來重建原樣本,并使重建后的樣本和原樣本的誤差最小。
1D-PCA基本原理如下:假設存在N組1×M維數據樣本Xi(i=1,2,…N),對其進行1D-PCA等價于尋找樣本集的協方差矩陣C=XXT的前n(1≤n≤M)個特征值對應的特征向量矩陣W,W即為樣本數據Xi進行空間變換的最佳投影矩陣。然后,對每一個樣本Xi進行如下變換:
其中:Zi為Xi經過1D-PCA變換在新空間中超平面上的投影;Fi為Xi經過1D-PCA變換的特征向量。
1.2.2 2D-PCA理論原理
2D-PCA是1D-PCA的繼承和發展。對于二維矩陣,1D-PCA在構造協方差矩陣時需要把樣本矩陣變成一維向量,之后將所有樣本向量構成一個大規模的協方差矩陣,然后求解此協方差矩陣的特征值及特征向量來構建映射矩陣。2D-PCA分析二維圖像矩陣時,協方差矩陣是直接在圖像矩陣上計算的,因此可以保留圖像的空間結構信息,并且可以避免維數災難和小樣本問題,這也使得其在圖像處理方面具有廣泛的應用[11-12]。
2D-PCA的基本原理如下:假設X為n維列向量,將m×n維的矩陣A通過矩陣X映射到另一個子空間,即有:
式中Y為投影后的特征向量矩陣。
2D-PCA通過最大化投影數據的總離散度來尋找最優投影矩陣,其投影樣本的總離散度可以由投影特征向量Y的協方差矩陣的軌跡來表征,即:
式中G=E[(A-EA)T(A-EA)],稱為圖像協方差矩陣。因此,式(9)可改寫為:
圖像協方差矩陣G通過簡單的方式計算:
2D-PCA的投影準則是尋找d個投影軸X=[X1,X2,…Xd]使得準則J(X)最大,即有:
對于每個給定的樣本Ai矩陣進行如下變換:
由此可得經過2D-PCA變換的圖像特征向量矩陣Y。
1.2.3 2D-2D-PCA理論原理
2D-2D-PCA是對2D-PCA的進一步改進與發展[13]。2D-PCA可直接由二維數據構造協方差矩陣,避免了二維矩陣轉化成一維向量時的計算負擔。但2D-PCA僅僅只在水平方向上對二維數據進行了壓縮降維,而忽略了豎直方向上的數據冗余性。為了解決這一問題,提出改進的2D-PCA方法,即2D-2D-PCA,其能夠同時對原始的二維數據在水平和豎直方向進行2D-PCA降維,擁有良好的數據壓縮和降維效果。2D-2D-PCA方法的實現過程如下:
(1)選取M個二維樣本數據,每個樣本數據的大小為m×n,同時計算M個樣本數據的平均樣本矩陣,分別從水平和豎直方向上構造2D-PCA的協方差矩陣G和C,其計算公式如下:
式中:矩陣G的維度為n×n;矩陣C的維度為m×m。
(2)分別求取矩陣G和矩陣C的特征值與特征向量。選取矩陣G的前p個最大特征值對應的特征向量構成行方向上的最佳投影矩陣X,矩陣大小為n×p,同時選取矩陣C的前q個最大特征值對應的特征向量構成列方向上的最佳投影矩陣Z,矩陣大小為q×m。
(3)對于每個給定的樣本矩陣Ai在X和Z上進行壓縮投影,獲得經過2D-2D-PCA方法壓縮降維的特征矩陣為:
從式(17)可知,使用2D-2D-PCA方法可將大小為m×n的樣本數據投影為q×p維特征矩陣。2D-2D-PCA方法很好地壓縮了原始二維數據中的維數據,同時將原始數據的關鍵信息也很好保留下來。
將2D-2D-PCA方法運用到放射性核素識別中,將一維能譜數據利用GASF方法進行二維化。將一個一維能譜序列視為寬平穩隨機信號,將其表達為一個長度為n的序列:
對一維能譜序列y進行GASF后,得到對應GASF矩陣,其矩陣大小為n×n,通常n的大小為1 024,2 048或4 096,導致獲得的GASF矩陣非常大,故采用2D-2D-PCA對其進行數據降維并提取特征。整個過程如圖2所示。
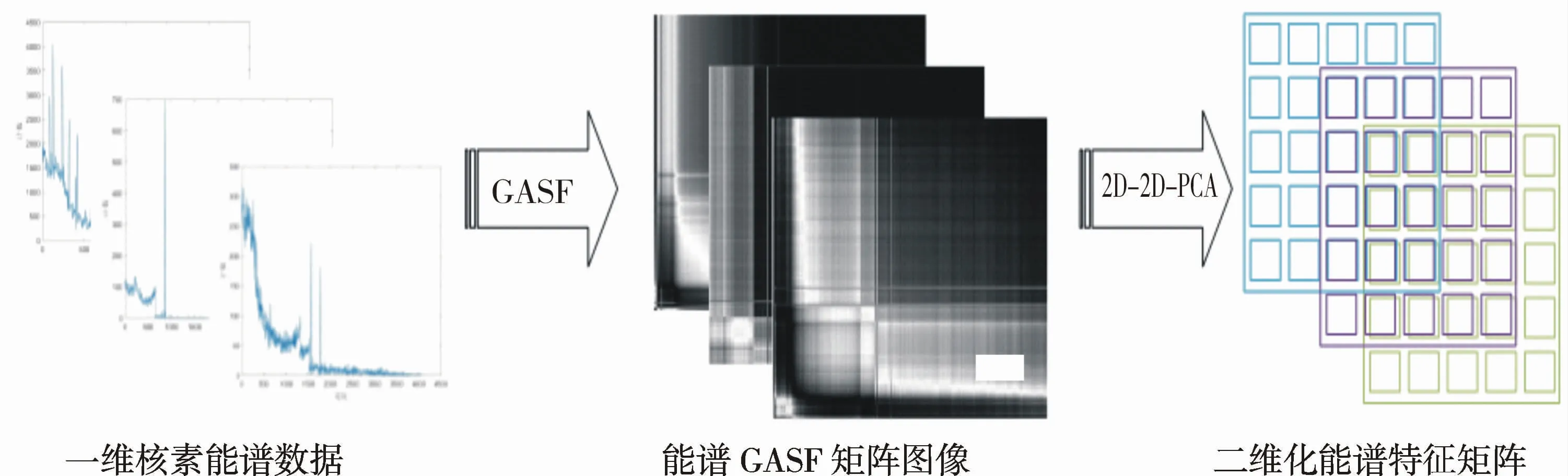
圖2 基于S變換與2D-2D-PCA的二維能譜特征提取Fig.2 Two-dimensional energy spectrum feature extraction based on S transform and 2D-2D-PCA
1.3 基于Mahalanobis距離的SVM分類器設計
支持向量機(SVM)是在統計學習理論的結構風險最小化理論基礎上發展而來的一種機器學習方法[14-15],其具有較強的學習能力與泛化能力,能夠有效解決小樣本、非線性以及局部極值等問題,在處理二分類和多分類的問題上具有優異的準確性。但傳統的SVM在進行分類時存在只抽取樣本局部信息的缺點,忽略了不同樣本間包含的屬性信息,影響了SVM泛化能力的提高。而Mahalanobis距離判別是樣本類間可分性度量分析的一種可靠方法[16],它能夠將不同樣本間包含的隱藏信息考慮進來,利用樣本的全局信息尋找各種特征之間的聯系,因此能夠有效度量不同樣本總體的相似程度。結合SVM和Mahalanobis提出基于Mahalanobis距離的SVM(MSVM)分類器,設計一種用于確定二維化核素能譜的類間的分類算法。該算法基本思想如下:
假設存在多個訓練樣本,其類間和類內協方差矩陣分別表示為Sb和Sw,同時設St=Sb+Sw為樣本的總體協方差矩陣。在SVM方法中通過分類決策函數f(x)=wTx+b確定分類超平面,結合間隔最小原則,可以將其轉化為二次優化問題,即:
基于考慮樣本的全局信息,本文在優化問題中采用wTStw去代替wTw,將其代入式(19)獲得的支持向量機則表示為:
在式(20)中,樣本的總體協方差矩陣計算為St=E{[φ(x)-E(φ(x))][φ(x)T-E(φ(x)T)]},C為懲罰參數,ζi代表每個樣本的松弛變量。
對式(20)進行拉格朗日變換[17],有:
式中ai為拉格朗日乘數。同時對馬氏距離定義有:
將上式代入式(21)則基于Mahalanobis距離的支持向量機為:
從而得到基于Mahalanobis距離的支持向量機的決策函數:
式中s為支持向量的數目。
1.4 本文算法概述
根據前文所述,本文針對在真實能譜衰減環境中許多傳統核素識別方法只利用部分能譜曲線、易受噪聲影響及識別準確率較低等問題,設計基于GASF和2D-2D-PCA的γ能譜核素特征提取算法,同時設計基于MSVM的核素識別分類器,實現對核素能譜的高性能識別,整個算法過程如下:
(1)將原始γ能譜核素數據通過GASF轉化為二維圖像矩陣,并劃分為訓練集和測試集;
(2)對變換后的二維圖像矩陣進行2D-2D-PCA變換,進行數據壓縮和特征提取;
(3)設計基于Mahalanobis距離的SVM分類器,對訓練數據進行訓練并利用測試集進行驗證,獲得分類結果。
本文方法的整體系統框圖如圖3所示。

圖3 算法整體系統框圖Fig.3 Overall system block diagram of the algorithm
2 核素能譜識別
2.1 核素能譜數據獲取及預處理
較多的核素樣本數據是核素準確識別的前提。本文使用Geant 4軟件,基于蒙特卡羅方法生成核素能譜,同時結合NaI探測器進行實驗測試獲取真實環境下的核素能譜作為核素能譜樣本集。核素能譜樣本主要包括60Co,137Cs,152Eu,60Co+137Cs,60Co+152Eu和137Cs+152Eu等6種單一類別核素以及混合核素。部分核素能譜樣本如圖4所示,可以看出所有的能譜數據都含有部分環境噪聲干擾。筆者采用GASF算法和2D-2D-PCA算法對所獲得的核素能譜進行特征提取,不同的核素能譜經過GASF變換后,獲得的二維化圖像如圖5所示。可以看出,不同核素二維化后存在明顯差異。由于經過S變換后的二維矩陣的維數過大,不僅增加計算負擔,而且含有較多的冗余信息,故采用2D-2D-PCA對其進行數據壓縮和降維,便于后續核素識別。
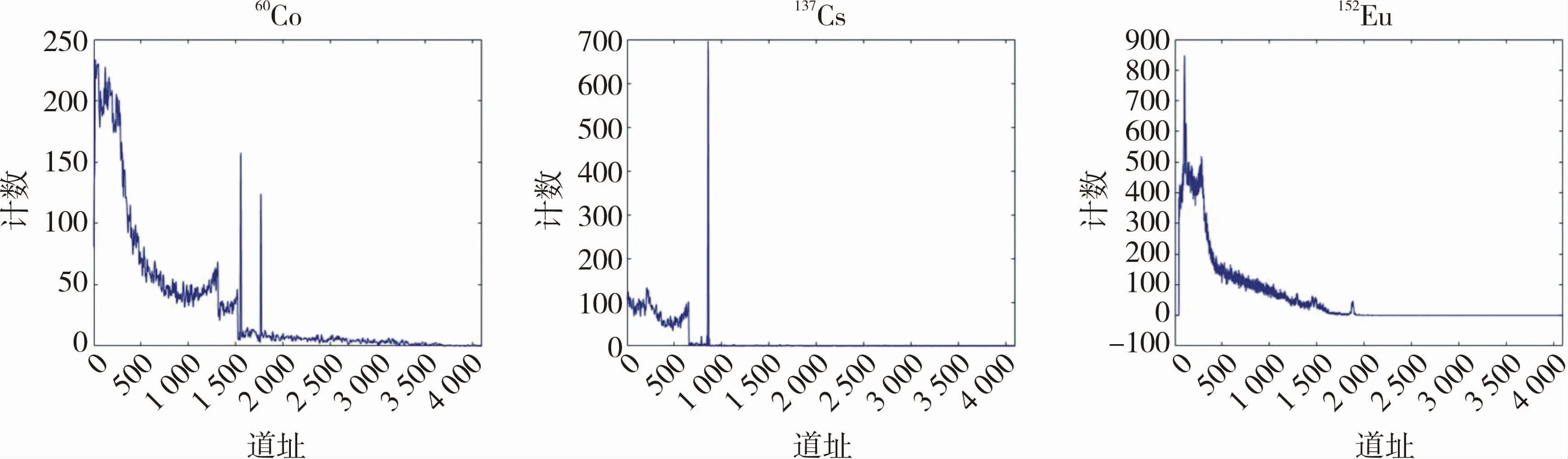
圖4 不同的核素能譜樣本Fig.4 Energy spectrum samples of different nuclides

圖5 不同核素的GASF變換圖Fig.5 GASF transform diagrams of different nuclides
2.2 核素識別模型訓練
原始核素能譜數據經過預處理后,將得到的二維核素能譜數據按照7∶3的比例分成訓練樣本和測試樣本,利用本文所設計的MSVM分類器對核素進行分類識別。此外,為獲得MSVM 的最優參數設定,本文引入遺傳算法(Genetic algorithm,GA)來尋找最佳參數。
將訓練樣本作為輸入,通過GA來進行最優參數的設定,如圖6所示,得到懲罰因子c和關聯參數g的最優參數值,并且平均分類準確率大于95%,最佳分類準確率為100%。

圖6 GA參數尋優Fig.6 Parameter optimization by GA
2.3 仿真核素數據識別結果及分析
在該實驗中,所使用的核素能譜數據都是基于Gent 4仿真軟件獲取的核素能譜仿真數據,仿真核素能譜識別包括單一核素的識別和混合核素的識別,將未參與模型訓練的測試樣本作為輸入,利用訓練好的MSVM對6種不同核素能譜數據進行識別,同時與傳統的尋峰方法和基于奇異值分解的支持向量機方法[18]進行對比,核素識別結果如表1所示。

表1 仿真核素能譜識別結果Tab le 1 Recognition results of simulated nuclide energy spectrum
表1結果表明,本文算法對仿真的γ核素能譜具有良好的識別效果,能夠準確識別單一核素和混合核素,同時模型訓練速度快,能夠自動進行參數尋優,在本文的數據集下,其平均識別速度在38 s內。尋峰算法和基于奇異值分解的支持向量機方法雖然對單一核素的識別效果較好,但對于混合核素的識別性能都有一定程度的下降。此外,傳統的尋峰算法為獲得較好的識別率需要調節各種參數,基于奇異值分解的支持向量機方法在進行奇異值分解時也需要選擇合適的特征值才能獲得較好的核素識別準確率。
2.4 真實環境下核素識別結果
在本節實驗中,利用NaI(Tl)探測器(能量探測范圍為50 keV~3 MeV,能量分辨率低于8%(137Cs,662 keV))獲取不同探測距離的核素能譜數據,根據放射性源的放射強度、NaI(Tl)探測器的探測效率和成譜時間,將每次探測的測量時間定為每組60 s,同時為了減少NaI(Tl)探測器本身統計漲落的影響,在實驗過程中會就同一個探測點進行10次重復實驗,即在同一探測點測量10組核素能譜。此外,對同一類放射性源設定不同的探測距離,每次探測距離間隔為10 cm,探測距離范圍為0~20 cm。通過實驗驗證本文算法對真實環境下采集的核素能譜的識別性能。真實環境中不同距離下的核素識別結果如表2所示。
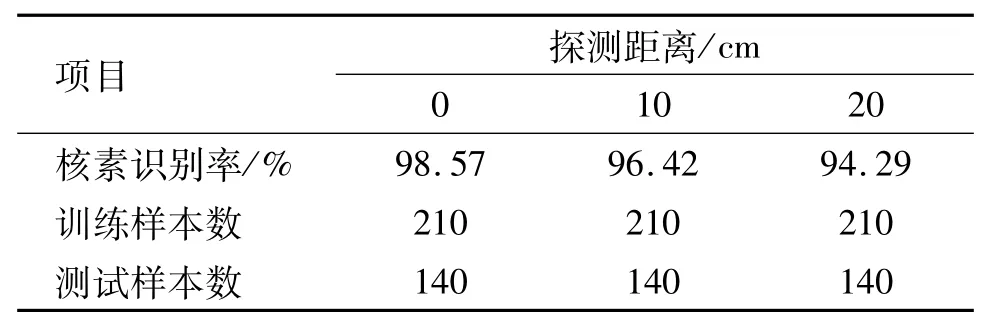
表2 真實環境中不同距離下的核素識別結果Table 2 Nuclide identification results at different distances in real environment
表2結果表明,在探測距離較小時,本文算法對不同核素的識別正確率相對較高,同時可以看出,在探測距離為20 cm內的條件下,本文提出的核素識別算法對真實探測環境中得到的不同探測距離的核素能譜均有較高的識別正確率,平均識別率均高于96%,表現出良好的識別性能。
3 結論
本文通過格拉姆角和場算法將一維能譜數據二維化,從全譜分析和二維角度去探究核素能譜的信息,設計并訓練了一種基于Mahalanobis距離的SVM分類器,并結合遺傳算法對模型參數進行設置和優化,與其他核素識別算法相比能夠有效提高核素識別的準確性。本文算法在真實環境下對單一核素和混合核素具有良好的識別正確率。
