
基于回訪機制的無人機集群分布式協同區域搜索方法
2023-07-29 03:04:42文超董文瀚解武杰蔡鳴劉日
航空學報 2023年11期
文超,董文瀚,解武杰,蔡鳴,*,劉日
1.空軍工程大學 研究生院,西安 710038
2.空軍工程大學 航空工程學院,西安 710038
3.空軍哈爾濱飛行學院 理論訓練系,哈爾濱 150000
近年來,受益于人工智能與無人系統的蓬勃發展,無人機(Unmanned Aerial Vehicle,UAV)被廣泛應用于軍事作戰領域,而采用多架UAV以集群網絡形式協同執行區域搜索、目標跟蹤、飽和打擊等任務正逐漸成為UAV 作戰的發展趨勢。其中,區域搜索任務作為UAV 集群協同作戰的關鍵環節,能夠為后續作戰任務決策提供有效的全局信息支撐,得到了國內外學者的廣泛關注[1-5]。
UAV 集群協同區域搜索是指UAV 成員利用機載探測設備偵察指定任務區域,并通過通信網絡交互共享探測信息,從而協作完成對任務目標的捕獲[6-7]。目前,諸多學者主要圍繞任務環境建模與協同搜索策略2 個方面對UAV 集群協同區域搜索問題進行了廣泛而深入的探究,并取得了豐碩的成果。
在任務環境建模方面,現有成果大多基于柵格化方法來構建任務環境的搜索圖模型,主要包括目標分布概率圖、數字信息素圖及確定度圖等[8-15]。Yang 等[8]為準確描述動態未知環境下傳感器對目標觀測信息的實時獲取與更新,分別基于貝葉斯準則與D-S 證據理論構建了目標分布概率圖,并借此引導集群對威脅場景下的目標進行合作定位。Khan 等[9]考慮到不確定環境下各UAV 的局部探測信息可能存在偏差,通過占用柵格合并技術對目標分布概率圖進行融合,進一步增強了概率圖對潛在目標的指示能力。沈東等[11]為實現集群對廣域目標的協同搜索,分別定義了數字信息素的吸引和排斥屬性,前者用于記錄UAV 對搜索區域的訪問特性,后者用于協調集群成員之間的搜索行為。吳傲等[13]通過將信息素圖作為多機協同的載體,實現了集群對未知區域的高效覆蓋搜索。Saadaoui 和el Boua‐nani[14]將確定度引入未知區域內離散柵格單元,借此來描述UAV 對搜索環境的認知程度,進而指導其自主搜索決策過程。彭輝等[15]在確定度圖的基礎上,借鑒生物細胞中荷爾蒙的擴散-傳播機理,提出一種基于擴展搜索圖的多UAV 協同搜索決策方法,較好地激發了多機系統的自組織性。總而言之,搜索圖模型本質上都是通過建立一個二維離散柵格地圖來反映UAV 對當前搜索環境的認知情況。隨著任務的推進,UAV 持續探測柵格,并不斷更新本機搜索圖,在每個決策時刻,UAV 能夠根據實時探測信息進行在線搜索決策。因此,搜索圖對于引導UAV 集群遂行動態協同搜索任務具有較好的適應性。
在協同搜索策略方面,提出的方法主要包括區域分割覆蓋掃描[16-20]、模型預測控制(Model Predictive Control,MPC)[21-25]和潛在博弈等[26-27]。其中,前兩者的應用最為廣泛。文獻[16-17]首先基于Voronoi 構型劃分搜索區域,然后結合概率圖信息設計合理的控制律引導UAV成員收斂至各自的Voronoi 質心,從而實現對任務子區域的覆蓋搜索。這種分割方法原理相對簡單,但具有較高的不確定度和計算復雜度。文獻[18]分別針對凸和非凸的多邊形任務區域提出了基于UAV 來向均衡劃分策略與凹點凸分解策略,同時采用“Z”型路徑與Dubins 轉彎路徑來規劃子區域內的覆蓋掃描路徑,實現了集成區域分割與路徑規劃的整體調用。文獻[19]根據UAV 的初始位置和搜索面積將任意凸多邊形區域分割為若干不同子區域,并將UAV 集群的總轉彎次數作為主要指標評估分割結果,通過數值仿真證明了所提方法的有效性。
上述方法對于靜態未知環境下的區域搜索問題表現出良好的適應性,但難以求解動態搜索規劃問題,具有一定的現實局限性。為了提高UAV 動態決策能力,文獻[21]重點研究了不確定環境下通信約束對于多UAV 協同搜索效能的影響,通過引入MPC 思想使UAV 在決策時能夠充分兼顧長短期收益,有效解決了UAV 決策后期易陷入局部最優的問題。文獻[22]基于MPC思想提出一種UAV 集群分布式搜索意圖交互決策機制,通過定制環境更新算子與環境融合算子,實現了集群在未知威脅場景下的高效覆蓋搜索。文獻[24-25]為了將集群系統的大規模優化決策分解為各UAV 子系統的分布式優化決策,基于分布式模型預測控制(Distributed Model Predictive Control,DMPC)方法提出一種廣泛適用的多UAV 動態搜索規劃框架,通過結合滾動時域優化(Receding Horizon Optimization,RHO)與智能優化算法來迭代求解各UAV 成員的搜索路徑,有效降低了問題求解維度,提高了UAV 實時在線決策能力。
綜上所述,現有國內外研究雖然使UAV 集群在動態未知環境中具備了一定的協同搜索能力,但仍存有以下問題有待解決:
1)區域搜索任務中未能兼顧對地面動目標的搜索需求,僅以區域覆蓋率為評價指標衡量集群協同搜索效率。
2)未針對傳感器的探測性能局限可能造成的目標誤判和漏檢問題制定具體解決方案。
3)UAV 成員在基于傳統DMPC 方法實時更新本機搜索圖時,通常需要接收來自通信網絡共享的它機預測狀態信息或決策信息。從通信層面考慮,這種耦合更新方式會導致某UAV 成員一旦受干擾發生通信中斷,通信范圍內其他成員的搜索圖將會不可逆地缺乏該成員的歷史決策信息,進而降低集群后續協同搜索效能。
針對上述問題,論文主要開展了以下工作:
1)為實時描述未知搜索環境的變化情況,構建了環境認知圖模型,并借此引導UAV 對未知任務區域進行覆蓋搜索。在此基礎上,通過利用動目標位置分布先驗信息,進一步構建了目標分布概率圖模型,用于引導UAV 搜索地面動目標。
2)為減少UAV 在搜索過程中錯失動目標情況以及由傳感器虛警概率導致的目標誤判情況,通過定制信息素引導的回訪機制,驅動UAV對全局柵格進行可控回訪;為緩解由傳感器探測概率導致的目標漏檢問題,通過定制權系數動態切換引導的回訪機制,驅動UAV 對發現可疑目標的區域進行回訪復檢。
3)借鑒DMPC 思想,設計了一種基于信息融合的UAV 集群分布式協同搜索決策機制,確保各UAV 成員在分布式最優決策的基礎上實現對本機搜索圖的獨立更新,以進一步增強系統魯棒性。
本文剩余部分的組織結構如圖1 所示,共分為6 節:第1 節簡要描述了UAV 集群協同區域搜索任務的典型想定,并構建了相應的任務區域柵格模型與UAV 系統狀態模型;第2 節面向動態未知搜索區域,建立了綜合態勢信息圖模型及其更新機理;第3 節重點考慮機載傳感器的探測性能約束,提出了2 種區域回訪機制,在此基礎上,結合所建立的綜合態勢信息圖,設計了UAV 搜索效能函數;第4 節詳細介紹了基于信息融合的UAV 集群分布式協同搜索決策流程,并提出回訪機制驅動的UAV 集群分布式協同搜索決策算法;第5 節進行了數值仿真實驗,以驗證所提回訪機制、決策機制和算法的有效性;第6 節給出了結論。
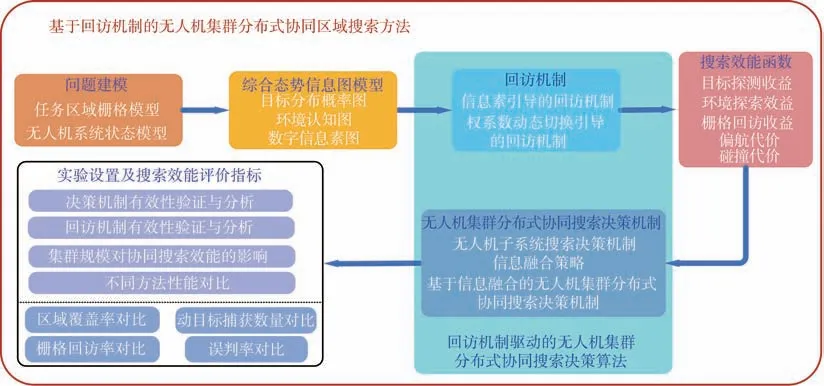
圖1 論文組織結構Fig.1 Paper organization structure
1 問題建模
UAV 集群協同區域搜索任務的典型想定如圖2 所示。假設某一指定的未知任務區域Ω內分布有若干動目標,現派遣Nu架(Nu≥2)UAV 組成搜索集群,利用各自攜帶的探測設備(激光、視覺等傳感器)對Ω進行偵察,要求在捕獲盡可能多的動目標的同時,實現對Ω的最大化覆蓋搜索,以為指戰員提供相對全面和準確的戰場態勢信息。

圖2 無人機集群協同區域搜索任務Fig.2 UAV swarm cooperative area search mission
為保證任務順利進行,UAV 在偵察期間應重點探測環境認知程度低、目標分布概率大的區域。同時,需要引導UAV 對指定任務子區域進行回訪復檢,以盡可能減少UAV 遺漏和誤判目標情況。
1.1 任務區域柵格模型
為了簡化UAV 搜索決策的解空間,在笛卡爾坐標系下對Lx×Ly的矩形任務區域Ω進行柵格化處理,即將其劃分為若干大小為Δx×Δy的離散柵格單元,如圖3 所示。則任意柵格單元的位置坐標表示為
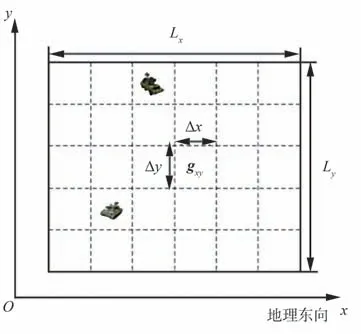
圖3 任務區域柵格Fig.3 Grid mission area
1.2 UAV 系統狀態模型
通常情況下,為保證傳感器成像尺寸的一致性,UAV 在搜索期間一般不進行高度機動[22]。因此,為便于研究,將UAV 視為二維空間中的平動質點,記k時刻第i個UAV 的狀態矢量為
式中:Pi(k)=(xi(k),yi(k))為第i個UAV 位置坐標;ψi(k)為UAV 偏航角。
則第i個UAV 的離散系統狀態模型表示為
式中:v為UAV 飛行速率;Δt為時間步長;ui(k)=Δψi(t)為UAV 的決策變量,即偏航角變化量。
進而可以表示第i個UAV 的狀態轉移方程為
式中:f(?)為狀態轉移函數,由式(3)確定。
值得說明的是,式(3)僅描述了UAV 在相鄰決策時刻的狀態信息,這就意味著當前時刻的UAV 只能獲取下一時刻的目標柵格位置和航向信息。然而,在實際搜索過程中,UAV 是連續機動的,因此,需要根據每步決策結果所確定的目標柵格位置,為UAV 在線規劃出從當前柵格到目標柵格的飛行航跡。這涉及UAV 航跡規劃領域,不是本文的研究重點,故不作詳述。
鑒于上述分析,對UAV 的動作空間進行離散化處理。則第i個UAV 在k時刻有8 個可選航向,數字化表示為ψi(k)∈{0,1,2,3,4,5,6,7}。圖4 展示了各個數字代表的UAV 飛行方向。考慮到UAV 本體性能約束,基于k時刻航向限定k+1 時刻UAV 的航向為:左偏航45°;直飛;右偏航45°。則有ψi(k+1)∈{ψi(k)?1,ψi(k),ψi(k)+1}mod 8,此處是數字化描述無人機在k+1 時刻的可選航向,mod8 表示對8 取余,用于約束可選航向的取值范圍。
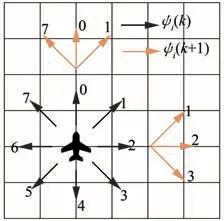
圖4 無人機離散動作空間Fig.4 Discrete action space of UAV
2 綜合態勢信息圖模型及其更新機理
本節將建立包含目標分布概率圖(Target Distribution Probability Map,TDPM)、環境認知圖(Environment Cognition Map,ECM)與數字信息素圖(Digital Pheromone Map,DPM)在內的綜合態勢信息圖模型及其更新機理,從而為UAV 進行實時在線搜索決策奠定基礎。在綜合態勢信息圖中,每個柵格單元均包含以下3 種屬性:
式中:下標xy表示(x,y),為柵格單元坐標;k為決策時刻;pxy(k)為目標存在概率;χxy(k)為環境不確定度;ηxy(k)為信息素濃度。
2.1 目標分布概率圖
在UAV 實際執行搜索任務前,動目標的大致位置分布區域通常可以借助衛星偵察等情報搜集手段來預先獲取[6]。因此,為有效利用先驗情報信息,引入pxy(k)∈[0,1]來描述柵格中存有動目標的概率,pxy(k)越大,表示柵格中存在動目標的概率越大。假設先驗信息給定的目標預估位置為() (n=1,2,…,NT),采用式(6)所示的高斯分布初始化TDPM。
考慮到傳感器在探測過程中存在噪聲、遮擋等因素干擾,因此,UAV 在搜索過程中根據貝葉斯準則持續更新TDPM,數學描述為[10]
式中:pd、pf分別為傳感器的探測概率和虛警概率,反映了傳感器的探測性能;bxy(k)∈{0,1}為傳感器對目標的探測狀態,取值為1 時認為探測到目標,反之即認為未探測到目標。
2.2 環境認知圖
為實時描述UAV 對未知區域的搜索認知情況,將不確定度χxy(k)∈[0,1]引入離散柵格單元。χxy(k)越小,表示UAV 對柵格內靜目標信息的認知越完全。
考慮到香農熵能夠有效量化不確定性信息,因此,采用靜目標初始存在信息的香農熵來描述搜索環境的初始不確定度,具體為
式中:γ∈(0,1]為衰減系數,當γ=1 時,表示UAV 僅需對柵格進行一次訪問便可完全確定柵格內的靜目標信息;c(k+1)為截止到k+1 時刻柵格的累積搜索次數。
2.3 數字信息素圖
自然界生物普遍涌現出集群協同行為,其中較為經典的是蟻群覓食,即螞蟻個體通過跟蹤自身及蟻群其他成員共同分泌的化學信息素來快速尋找和獲取食物源[28]。不難看出,蟻群覓食機理與集群協同搜索過程具有高度相似性,因此,為進一步提高UAV 搜索效率,借鑒蟻群覓食機理構建DPM 為
式(10)表示采用一個Lx×Ly的信息素濃度矩陣M來數字化構建DPM。
值得說明的是,數字信息素種類較多,有吸引類、排斥類和跟蹤類等,可根據具體任務需求選定。此外,由于數字信息素是對生物信息素進行的模擬,因此,數字信息素同樣具備分泌、傳播、揮發等仿生特性,具體可視任務需求定義。
定義數字信息素為吸引信息素,且具有分泌、傳播和揮發3 種物理屬性,用于引導UAV 對受訪時間間隔較長的區域進行回訪復檢(詳見3.1.1 節)。吸引信息素按照如式(11)所示的規則進行動態更新[11]:
式中:Ga,Va∈[0,1]分別為傳播系數和揮發系數;二值變量Wxy∈{0,1}為信息素分泌開關因子;oxy(k+1)表示柵格自主分泌的信息素量;sxy(k+1)表示(k,k+1]時間段內相鄰柵格傳入的信息素總量,計算方法為
3 回訪機制與搜索效能函數
3.1 回訪機制
對于存有動目標的未知任務區域,UAV 進行覆蓋搜索時需要著重考慮2 方面的問題:①相對于靜目標,動目標存在運動至UAV 已搜索區域的可能性,增大了后續搜索過程中UAV 遺漏目標概率;② 傳感器的虛警概率和探測概率造成的目標誤判和漏檢情況。為此,分別設計了信息素引導的回訪機制和權系數動態切換引導的回訪機制,以進一步提高集群協同區域搜索效能。
3.1.1 信息素引導的回訪機制
為降低UAV 遺漏和誤判目標概率,基于DPM 引導UAV 對受訪時間間隔較長的區域進行回訪復檢。假設柵格前一次的受訪時刻為ts,當前時刻為t,規定回訪時限為τ。則信息素引導的回訪機制的觸發條件為
具體作用機理為:當柵格的未受訪時長大于規定回訪時限時,意味著UAV 需要對柵格進行回訪復檢。此時,打開信息素分泌開關,即設定Wxy=1,柵格將持續分泌信息素并不斷傳入鄰近柵格,最終形成一種關于信息素濃度的梯度分布,如圖5 所示。在吸引信息素作用下,UAV 將前往高信息素濃度柵格進行重搜索,從而實現對長時間未被探測柵格的回訪。
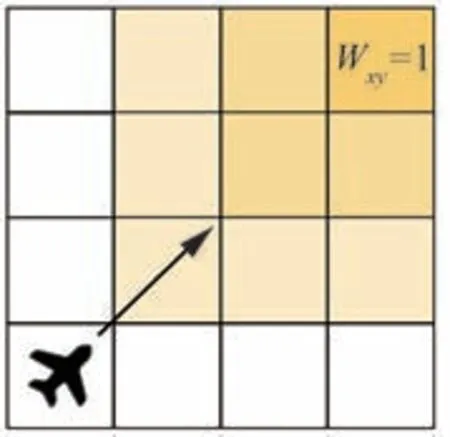
圖5 信息素引導的回訪機制原理Fig.5 Principle of pheromone-guided revisit mechanism
基于上述分析可知,開關因子Wxy的取值是實現由信息素引導UAV 進行回訪的關鍵。因此,定義信息素引導的回訪機制的終止條件為:一旦有UAV 對柵格進行重搜索,則關閉信息素分泌開關,即設定Wxy=0。此后,柵格內的信息素將隨時間逐漸揮發,濃度隨之減小,直到柵格再次滿足回訪機制的觸發條件時,設定Wxy=1。通過定制具有周期分泌能力的吸引信息素來驅動UAV 對全局柵格進行可控回訪,從而盡量減少UAV 遺漏和誤判目標情況。
3.1.2 權系數動態切換引導的回訪機制
為進一步緩解由傳感器探測性能限制造成的目標誤判和漏檢問題,基于搜索效能函數(詳見3.2 節)定制了權系數動態切換引導的回訪機制,該機制在UAV 認為探測到可疑目標時觸發。為便于闡述,記UAV 探測到可疑目標的區域為Β。權系數的動態切換規則為
具體來說,就是當UAV 探測到區域Β 中的可疑目標時,通過提高一定規劃時域內目標探測收益的權系數,快速引導該UAV 或鄰近UAV 重點回訪Β 以便再次確認目標真偽,進而降低UAV漏檢和誤判目標概率。在UAV 完成回訪后,切換權系數為初始值,即在決策時刻tk+q終止回訪機制。
3.2 搜索效能函數
以最大化UAV 集群協同搜索效率為優化目標,同時兼顧各UAV 偏航代價與飛行安全,建立式(15)所示的UAV 搜索效能函數:
式中:Si(k)、Ui(k)分別為第i個UAV 的N步預測狀態集與N步決策輸入集(詳見4.1 節);各優化子目標的具體定義如3.2.1~3.2.5 節所示。
3.2.1 目標探測收益
目標探測收益JD描述為UAV 搜索過程中探測到目標可能性的度量,用于引導UAV 重點搜索目標存在概率大的區域。因此,采用第i個UAV 搜索航跡所覆蓋的探測區域Ri的目標存在概率累加和來定義JD為[6]
式中:ζxy(k)為UAV 對(x,y)柵格中是否存有目標的判定結果,數學描述為
其中:δp∈(0.5,1]為目標存在閾值,取δp=0.8;ζxy(k)=1 表示(x,y)柵格中存有目標,反之則表示目標不存在。
3.2.2 環境探索效益
環境探索效益JE描述為UAV 搜索過程中環境不確定性信息的減少量,用于引導UAV 探索未知環境,從而提高對靜目標的發現概率。因此,基于環境不確定度的衰減量定義JE為
3.2.3 柵格回訪收益
柵格回訪收益JR描述為UAV 對受訪時間間隔較長的柵格進行重搜索時所獲得的信息素收益,用于引導UAV 重點探測高信息素濃度區域。因此,定義JR為
3.2.4 偏航代價
為減少UAV 執行任務期間的轉彎油耗與飛行時間損耗,建立UAV 偏航角調整代價函數JT為
式中:N為滾動優化長度(詳見4.1 節);|·|為絕對值。由式(20)可以看出,當UAV 在任意相鄰決策時刻保持直飛航向時,偏航代價最小。
3.2.5 碰撞代價
機間避撞對于UAV 集群協同作業至關重要。現有方法大多采用人工勢場法來實現UAV成員間的防相撞[29],借鑒其斥力勢場思想,建立碰撞代價函數JC為
式中:‖·‖為歐氏距離。
4 回訪機制驅動的UAV 集群分布式協同搜索決策算法
4.1 UAV 集群分布式協同搜索決策機制
MPC 方法能夠使智能體在決策時充分兼顧長短期收益,因此對動態規劃問題具有良好的適應性。針對UAV 集群協同區域搜索問題,基于MPC 的集中式優化求解方法雖然使UAV集群具備了良好的全局最優決策能力,但系統魯棒性不強,且隨著集群規模的擴大,由于受到中央節點的計算能力、網絡通信能力等諸多方面限制,UAV 可能難以進行實時任務決策[25]。DMPC 方法能夠有效解決上述問題,但其耦合更新搜索圖的方式限制了集群系統魯棒性的提升。
因此,借鑒DMPC 思想,設計了基于信息融合的UAV 集群分布式協同搜索決策機制,確保集群在分布式協同最優決策的基礎上對成員態勢信息圖進行解耦式更新。
4.1.1 UAV 子系統搜索決策機制
為提高UAV 自主決策能力,首先基于MPC思想建立圖6 所示的UAV 子系統搜索決策機制。
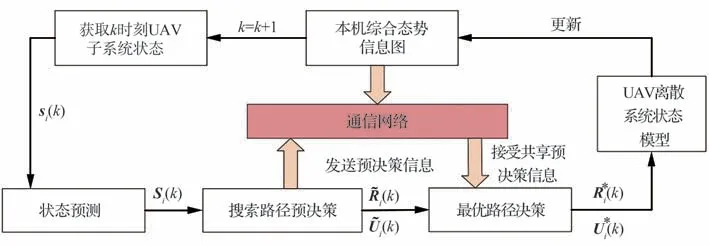
圖6 無人機子系統搜索決策流程Fig.6 Search decision process for UAV subsystem
在每個決策時刻k,UAV 子系統搜索決策機制分為以下4 個步驟:
步驟1基于k時刻UAV 當前狀態si(k),對未來N個時刻的子系統狀態Si(k)={si(k+1|k),si(k+2|k),…,si(k+N|k)}進行預測。根據1.2 節定義的UAV 離散系統狀態模型及動作空間,可將UAV 在未來N個時刻的所有可行航路點表示為一種樹狀結構。圖7 展示了N=3 時UAV 的路徑決策樹。
步驟4將最優控制序列的首項作為k時刻UAV 離散系統狀態模型的決策輸入,從而引導UAV 探測目標柵格。同時,根據傳感器探測結果更新本機綜合態勢信息圖。直到k+1 時刻最優控制指令介入,返回步驟1。
對于第i個UAV 子系統,基于滾動優化思想建立局部有限時域滾動優化模型為
式中:Si(k)和Ui(k)分別為第i個UAV 子系統的N步預測狀態集與N步決策輸入集;分別為其他UAV 的N步預測狀態集與N步決策輸入集;Θ和Ξ分別表示UAV 的容許輸入集和可行狀態集。
4.1.2 信息融合策略
在UAV 利用傳感器實時觀測信息對本機綜合態勢信息圖進行獨立更新后,通常需要將其與其他UAV 更新后的綜合態勢信息圖進行整合,以確保后續決策周期中UAV 能更全面準確地認知搜索環境并進行最優決策。因此,為進一步提高UAV 搜索效能,設計TDPM、ECM 和DPM 的融合規則為
4.1.3 UAV 集群分布式協同搜索決策機制
綜上所述,基于信息融合的UAV 集群分布式協同搜索決策機制如圖8 所示。
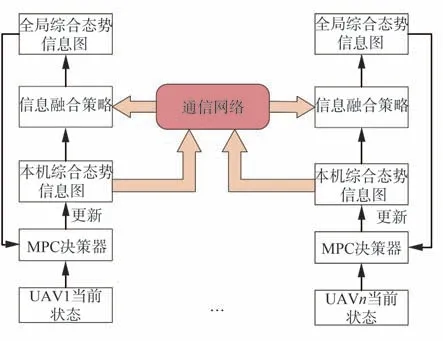
圖8 無人機集群分布式協同搜索決策流程Fig.8 Distributed cooperative search decision process for UAV swarms
首先,各UAV 成員基于當前時刻的自身狀態,分別利用MPC 決策器生成各自最優決策信息。接著,根據各自最優決策信息獨立更新本機綜合態勢信息圖。然后,通過信息融合策略將其與通信網絡共享的其他UAV 的綜合態勢信息圖進行融合計算,得到全局綜合態勢信息圖并作為下一決策周期的本機綜合態勢信息圖,進而實現集群的分布式協同最優決策。
4.2 回訪機制驅動的UAV 集群分布式協同搜索決策算法
將回訪機制引入上述決策機制,提出一種回訪機制驅動的UAV 集群分布式協同搜索決策(Distributed Cooperative Search Decision with Revisit Mechanism,RM-DCSD)算法,主要流程如算法1 所示。
5 仿真實驗與分析
為全面驗證所提RM-DCSD 算法的有效性,基于 Windows 10(64 位),Intel Core i7-7700HQ CPU(2.8 GHz),24 GB RAM 的實驗平臺對圖2 所示的典型協同區域搜索任務想定進行數值仿真實驗。

5.1 實驗參數設置
設定矩形任務區域Ω的大小為50 km×50 km,將其均勻劃分為50×50 的離散柵格,則每個柵格單元大小為1 km×1 km。根據先驗情報信息,假定Ω中x∈[10,40] km,y∈[12,42] km范圍內分布有若干動目標,現派遣4 架同構UAV組成搜索集群對Ω執行協同搜索任務,分別將區域覆蓋率和動目標捕獲數量作為主要評價指標衡量集群對靜目標和動目標的搜索效率。表1~表4 給出了UAV 集群初始狀態信息、傳感器性能參數、綜合態勢信息圖參數以及算法參數。初始化TDPM 與ECM 分別如圖9 和圖10 所示。設定仿真時長為9 000 s,決策周期Td=10 s,規定回訪時限τ=10Td。

表1 無人機集群初始狀態信息Table 1 Initial state information of UAV swarms

表2 傳感器性能參數Table 2 Parameters of sensor performance
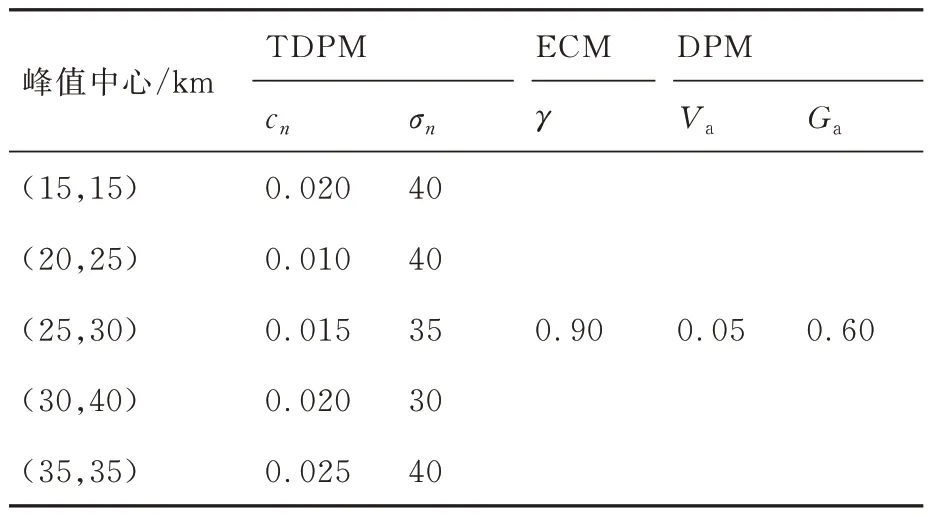
表3 綜合態勢信息圖參數Table 3 Parameters of comprehensive situational information map

表4 RM-DSCD 算法參數Table 4 Parameters of RM-DCSD algorithm
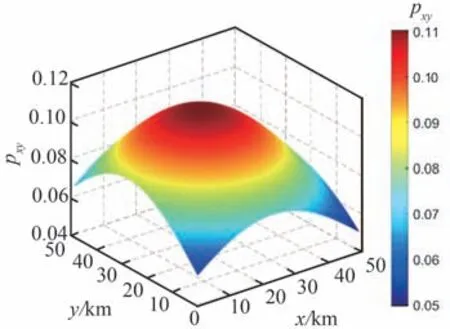
圖9 初始目標概率分布Fig.9 Initial distribution of target probability
圖10 初始環境不確定度分布Fig.10 Initial distribution of environmental uncertainty
5.2 協同搜索規劃結果
RM-DCSD 算法的規劃結果如圖11 所示。圖11(a)~圖11(c)分別為t=2 400,4 850,9 000 s的協同搜索規劃結果。
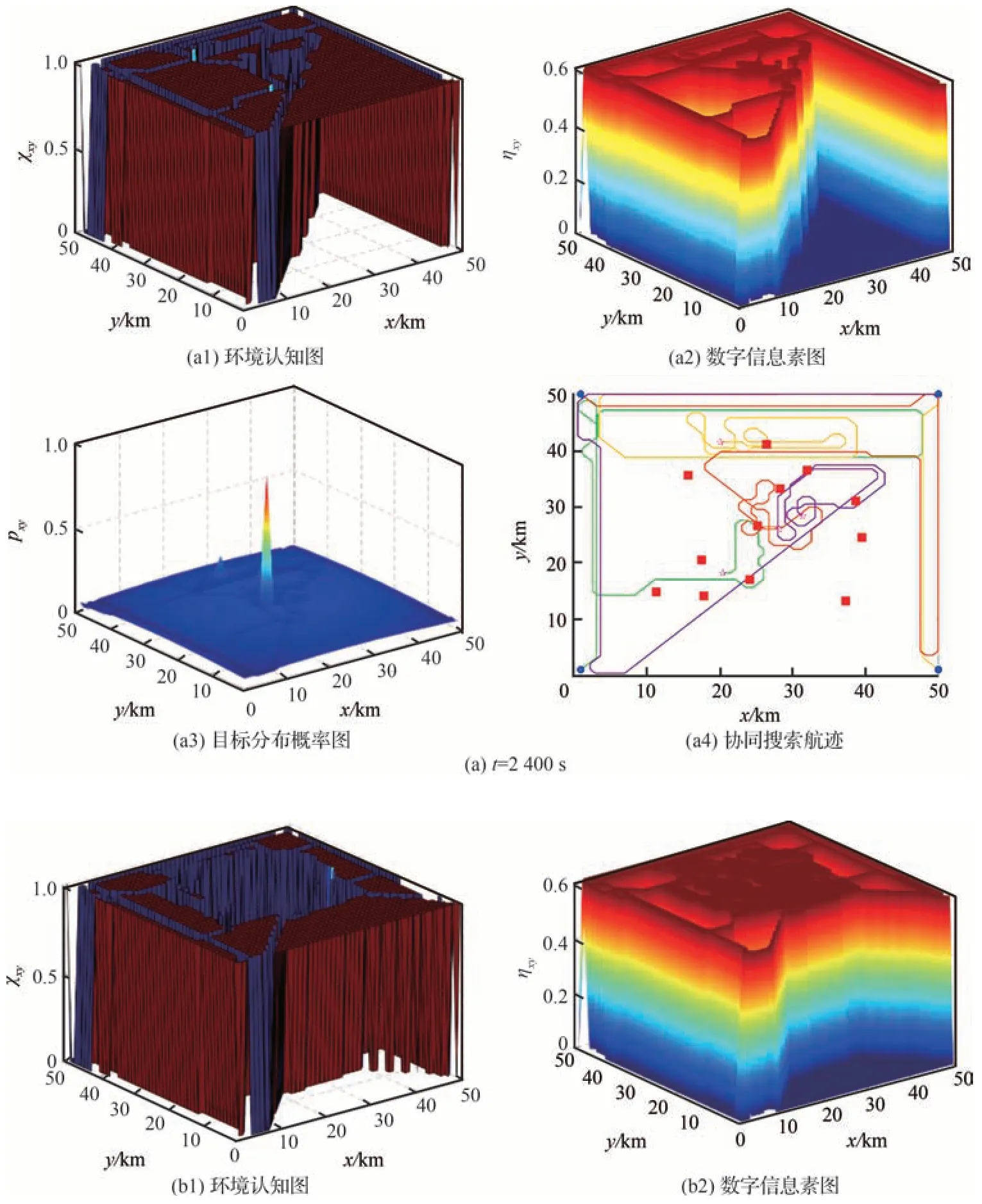
圖11 協同搜索規劃結果Fig.11 Results of cooperative search planning
由圖11(a1)、圖11(b1)和圖11(c1)可知,隨著任務的推進,ECM 能夠持續引導UAV 集群對未知區域進行覆蓋搜索,從而實現了對靜目標信息的有效獲取;由圖11(a2)、圖11(b2)和圖11(c2)可知,當柵格的未受訪時長大于規定回訪時限時,通過打開信息素分泌開關,柵格能夠持續分泌信息素并不斷傳入鄰近柵格;由圖11(a3)、圖11(b3)和圖11(c3)可知,通過引入動目標位置分布先驗信息構建TDPM,能夠有效引導UAV 對目標存在概率大的區域展開搜索,提高了UAV 對地面動目標的搜索能力。圖11(a4)中UAV 搜索航跡重疊部分表明,基于DPM 定制的信息素引導的回訪機制能夠有效驅動UAV 對受訪時間間隔較長的區域進行回訪復檢。此外,分析圖11(a4)和圖11(b4)可知,當UAV3 和UAV1 分別在(26,27)km 和(27,42)km 柵格內首次探測到可疑目標后,通過增大規劃時域內目標探測收益的權系數,能夠快速引導UAV3 自身以及UAV4 分別對發現可疑目標的區域進行回訪,進而再次確認動目標真偽,表明了權系數動態切換引導的回訪機制具有較高的合理性。綜上,RM-DCSD 算法能夠在引導UAV 集群對未知任務區域遂行覆蓋式協同搜索的基礎上,通過回訪機制驅動,有效兼顧對地面動目標的搜索及捕獲需求。
圖12 為集群協同執行搜索任務過程中,各UAV 成員間的實時最小距離變化曲線。可以看出,機間最小距離始終保持在24 m 以上,滿足UAV 集群的防碰撞要求。
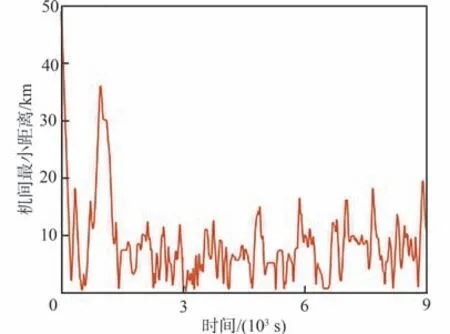
圖12 機間最小距離變化Fig.12 Minimum distance variation among UAVs
5.3 決策機制有效性驗證與分析
為進一步驗證所提出的決策機制在通信中斷情況下的有效性,分別將基于信息融合的UAV 集群分布式協同搜索決策機制(記作決策機制1)與文獻[24]提出的DMPC 決策機制(記作決策機制2)應用于搜索規劃全過程,并獨立進行30 次蒙特卡洛仿真,對比分析區域覆蓋率與動目標捕獲數量2 個評價指標。為確保實驗數據公平可靠,在應用兩種決策機制進行搜索規劃時均不考慮回訪機制的驅動,則令初始權系數κ3=0,其他參數設定同5.1 節。
假定搜索任務進行至2 500 s 時,UAV1 和UAV4 受干擾發生通信中斷,并于6 000 s 時恢復通信。仿真結果如表5 和圖13 所示。
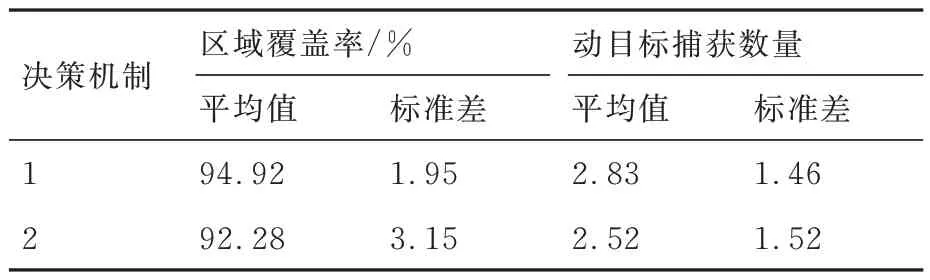
表5 評價指標的均值及標準差Table 5 Mean and standard deviation of evaluation indicators
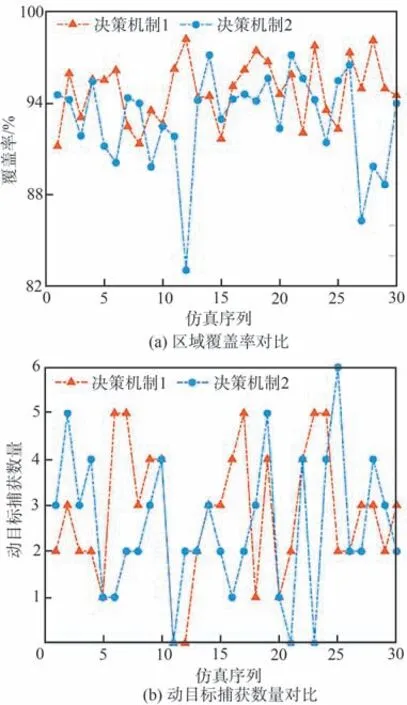
圖13 2 種決策機制規劃結果對比Fig.13 Comparison of planning results of two decisionmaking mechanisms
由表5 和圖13 可知,決策機制1 在2 個評價指標的均值及標準差上的表現均優于決策機制2,表明在通信中斷情況下,決策機制1 相比于決策機制2,具有更好的搜索規劃效能與更強的穩定性。分析其原因為:UAV 集群基于決策機制1 進行協同搜索規劃時,由于各成員是獨立更新本機綜合態勢信息圖的,因此,即使UAV1和UAV4 通信中斷一定時間,但只要通信恢復,其他UAV 便能通過信息融合策略快速恢復UAV1 和UAV4 的歷史決策信息,從而減少后續搜索過程中重復探測已知區域的情況,提高了集群對靜目標的覆蓋搜索效率。同理,也能通過信息融合后的全局TDPM 引導其他UAV 對UAV1 和UAV4 發現可疑目標的區域進行訪問,從而完成對動目標的協同捕獲。
綜上所述,所提決策機制進一步增強了集群系統的魯棒性,確保了集群即便在通信中斷情況下,仍能相對穩定且高效地完成對靜目標的覆蓋搜索和對動目標的捕獲。
5.4 回訪機制有效性驗證與分析
在5.3 節基礎上,為進一步驗證所提2 種回訪機制的有效性,并分析其對集群協同搜索效能的影響,基于控制變量思想,在采用決策機制1 情況下,設置4 組回訪機制標準對照實驗,如表6 所示。其中,回訪機制1 和回訪機制2 分別表示信息素引導的回訪機制和權系數動態切換引導的回訪機制。針對每組實驗,分別在無干擾條件下獨立進行30 次蒙特卡洛仿真,每次仿真時長為6 000 s,其他參數設定同5.1 節。統計區域覆蓋率、動目標捕獲數量、柵格回訪率和誤判率4 個評價指標,結果如圖14 和圖15 所示。
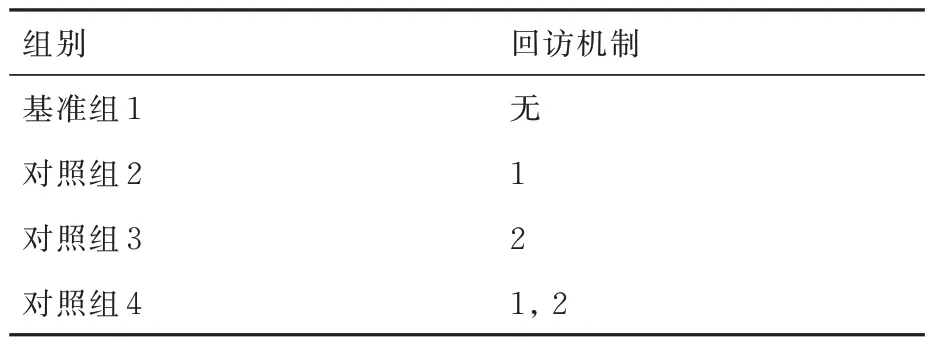
表6 回訪機制有效性驗證實驗設置Table 6 Experimental setup for validation of revisit mechanism
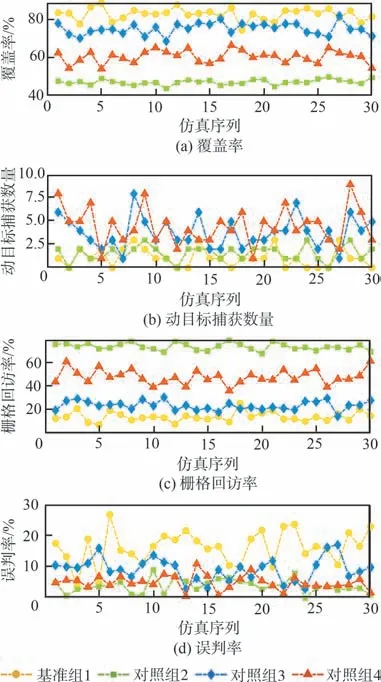
圖14 標準對照組實驗規劃結果對比Fig.14 Comparison of planning results of standard con‐trol group experiments
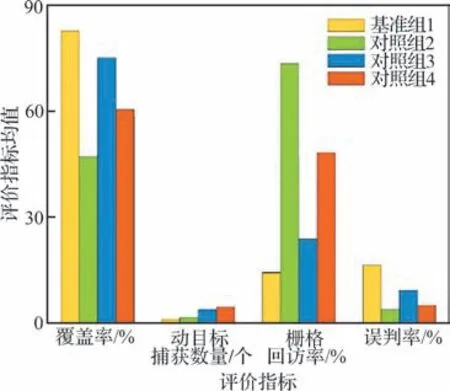
圖15 評價指標均值對比Fig.15 Comparison of mean of evaluation indicators
結合圖14(b)~圖14(d)和圖15 分析可知,對照組2 在柵格回訪率、動目標捕獲數量和誤判率3 個評價指標上的表現均優于基準組1,表明回訪機制1 能夠有效驅動UAV 對全局柵格進行可控回訪,從而減少UAV 遺漏目標情況,滿足了動目標的搜索需求。同時也表明回訪機制1 能夠有效緩解因傳感器虛警導致的目標誤判問題,證明了所提信息素引導的回訪機制的有效性。結合圖14(b)、圖14(d)和圖15 分析可知,相比于基準組1,對照組3 具有更多的動目標捕獲數量與更低的誤判率,表明回訪機制2 能有效引導UAV 對發現可疑目標的區域進行復檢確認,在降低誤判目標概率的同時,進一步提升了UAV 對動目標的捕獲性能,證明了所提權系數動態切換引導的回訪機制的有效性。綜合分析圖14 和圖15 可知,對照組4 相比于其他實驗組,具有更多的動目標捕獲數量,且柵格回訪率和誤判率僅次于對照組2,表明通過2 種回訪機制的聯合驅動,能更好地滿足UAV 集群對地面動目標的搜索需求。此外,從圖14(a)和圖14(c)可以看出,區域覆蓋率與柵格回訪率在整體上呈現出一種反比關系,表明2 種回訪機制在提高了UAV 回訪復檢能力的同時,均會不同程度地降低對靜目標的覆蓋搜索效率。可以發現,回訪機制1 相對于回訪機制2,具有更高的柵格回訪率與更低的區域覆蓋率,這主要是由于前者的觸發條件更為寬泛,且回訪對象為全局受訪時間間隔較長的已知區域。
值得說明的是,本文中2 種回訪機制主要是針對協同區域搜索任務中動目標的實際搜索需求以及傳感器虛警和漏檢情況提出的。因此,上述分析過程中并沒有將區域覆蓋率作為驗證回訪機制有效性的評判指標,而是僅將其作為參照用于討論2 種回訪機制對靜目標搜索效率產生的影響。
5.5 集群規模對協同搜索效能的影響
為定量分析集群規模對協同搜索效能的影響,分別指派由4、6、8、10、12、14 和16 架UAV 組成的搜索集群執行協同搜索任務。針對每種集群規模,分別進行30 次蒙特卡羅仿真,每次仿真時長為3 000 s,其他參數設定同5.1 節。不同規模下UAV 集群的區域覆蓋率與動目標捕獲數量統計結果如圖16 所示。
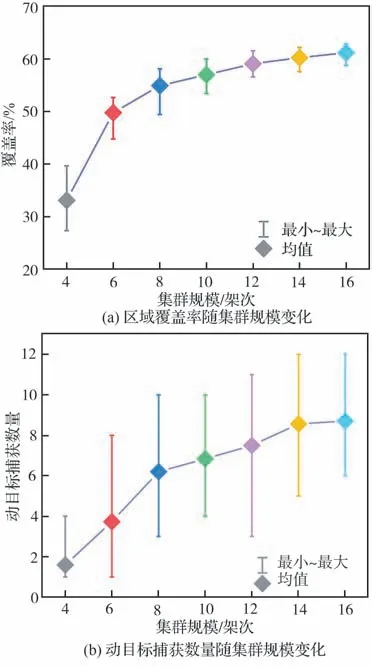
圖16 不同規模下UAV 集群的協同搜索效率Fig.16 Cooperative search efficiency of UAV swarms with different scales
由圖16(a)可知,隨著集群規模的擴大,區域覆蓋率整體呈增長趨勢。可以看出,在集群規模少于12 架次時,覆蓋率的增長速度較快,12 架次之后,覆蓋率的增長速度明顯放緩。由圖16(b)可知,當集群規模少于14 架次時,動目標捕獲數量隨著集群規模的擴大明顯增多,而當集群規模超過14 架次后,動目標捕獲數量基本保持不變。
基于上述分析可知,在任務區域大小、目標數量以及搜索時長一定的情況下,不斷擴大集群規模并不能持續提升集群協同搜索效能,相反,還會造成資源浪費。因此,需要根據具體任務需求確定適合當前任務場景的最佳集群規模。
考慮到論文任務需求是在保證UAV 集群捕獲盡可能多的動目標的基礎上,最大化覆蓋搜索未知區域,因此,對于本文協同區域搜索任務想定而言,最佳集群規模為14。
5.6 不同方法性能對比
為了進一步驗證所提算法的有效性,分別采用光柵式掃描方法、并排回尋式掃描方法[30]以及RM-DCSD 算法對任務區域進行搜索規劃。為確保實驗數據公平可靠,每種方法在相同實驗平臺上獨立進行30 次蒙特卡羅仿真,仿真參數設定同5.1 節。統計區域覆蓋率、動目標捕獲數量和誤判率,結果如表7 和圖17 所示。
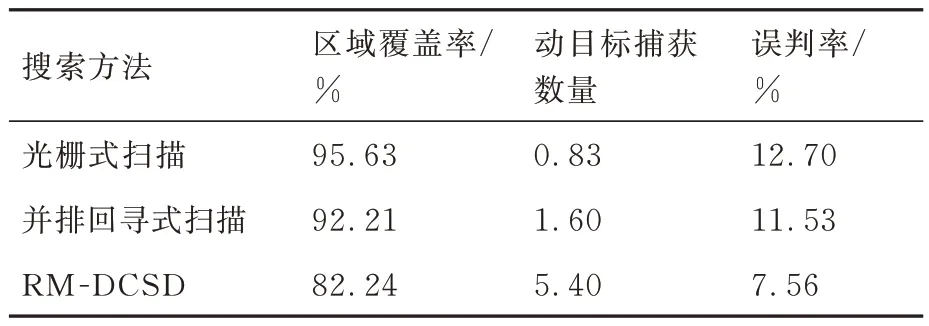
表7 評價指標均值Table 7 Mean of evaluation indicators
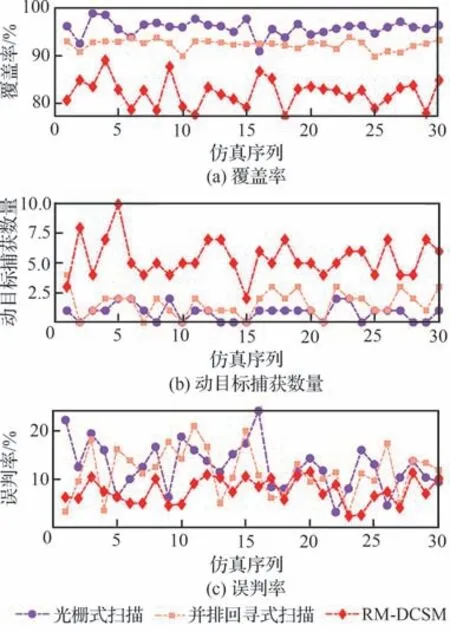
圖17 3 種方法規劃結果對比Fig.17 Comparison of planning results for three methods
由仿真結果可知,光柵式掃描方法與并排回尋式掃描方法雖然能夠相對穩定且高效地完成對靜目標的覆蓋搜索,但兩者均未有效利用先驗任務信息,且受限于UAV 的初始位置分布與固定的搜索模式,難以滿足動態環境下的搜索需求。其中,光柵式掃描方法引導的UAV 因回訪能力不足而造成大量遺漏和誤判目標情況,工程實用性較差。并排回尋式掃描方法雖然在一定程度上緩解了UAV 遺漏和誤判目標問題,提高了對動目標的搜索效率,但規劃過程中UAV 不能及時調整搜索航跡,回訪復檢效率不高,容易因傳感器漏檢而丟失目標,具有一定的現實局限性。相比于上述2 種對比方法,RM-DCSD 算法能夠有效利用先驗任務信息,從而實現UAV 實時在線自主決策,在回訪機制驅動下,通過犧牲較少的覆蓋搜索效率,高效引導UAV 對地面動目標進行捕獲,并保證較低的誤判概率。此外,對比分析5.4 節中對照組4 的實驗結果可知,在任務區域大小和目標數量一定的情況下,適當延長搜索時長可以在一定程度上緩解RM-DCSD因回訪機制造成的覆蓋搜索效率下降的問題。
綜上,所提出的RM-DCSD 算法能夠有效兼顧未知任務區域內地面靜目標和動目標的搜索需求,對動態未知搜索環境表現出良好的適應性。
6 結論
為提高協同區域搜索任務中UAV 集群對地面動目標的搜索效率,同時兼顧最大化覆蓋搜索效能,在考慮傳感器探測性能局限的基礎上,提出一種回訪機制驅動的UAV 集群分布式協同搜索決策算法。通過開展仿真實驗,得出以下結論:
1)通過引入環境認知圖,實現了UAV 集群對未知任務區域的覆蓋搜索;通過引入目標分布概率圖,提高了UAV 集群對動目標的搜索能力。
2)基于信息融合的UAV 集群分布式協同搜索決策機制實現了成員態勢信息圖的解耦式更新,進一步增強了集群系統魯棒性。同時,通過信息融合策略確保了集群的分布式協同最優決策。
3)通過信息素引導的回訪機制能夠有效驅動UAV 對全局柵格進行可控回訪,緩解了由于動目標的隨機特性導致的UAV 遺漏目標問題以及因傳感器虛警導致的目標誤判問題;通過權系數動態切換引導的回訪機制能夠快速驅動UAV對發現可疑目標的區域進行回訪復檢,進一步減少了由于傳感器的探測性能限制造成的目標漏檢和誤判情況。
4)集群規模與協同搜索效能之間呈現出一種非線性關系。因此,為避免資源浪費,在實際任務前應根據具體任務需求,通過數值仿真預先擬定合理的集群規模。
5)通過與光柵式掃描方法和并排回尋式掃描方法進行對比,表明所提出的RM-DCSD 算法能夠更好地引導UAV 在動態未知環境下進行實時在線搜索決策,從而增強了UAV 對動態搜索任務的適應性。同時,在2 種回訪機制的聯合驅動下,能夠有效緩解因傳感器的性能約束造成的目標漏檢和誤判問題,通過犧牲較少的覆蓋搜索效率,進一步提升了UAV 集群對動目標的捕獲效率。
猜你喜歡
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
中國衛生(2015年9期)2015-11-10 03:11:12
電測與儀表(2015年5期)2015-04-09 11:30:52
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
民生周刊(2012年10期)2012-10-14 09:06:46
