基于屬性特征知識圖譜的細粒度葡萄園害蟲識別
2023-08-15 16:18:48鄭增威李彥臻林中琦向正哲何夢竹
農業工程學報 2023年11期
鄭增威 ,李彥臻 ,3,劉 益 ,3,林中琦 ,向正哲 ,何夢竹 ,孫 霖 ※
(1. 浙大城市學院計算機與計算科學學院,杭州 310015;2. 智能植物工廠浙江省工程實驗室,杭州 310015;3. 浙江大學計算機科學與技術學院,杭州 310027)
0 引 言
中國葡萄種植面積大、產量高,是主要的水果之一[1]。在葡萄園作物栽培管理過程中,蟲害是制約其品質改良和產量增長的主要因素,正確診斷作物害蟲類別是科學防治的必要前提。 隨著人工智能技術的發展,利用計算機視覺技術對農作物害蟲圖像進行自動識別和診斷已經成為國內外一大研究熱點。
深度學習作為其中一項關鍵技術,彌補了傳統圖像分類方法特征提取能力差、效率低等缺陷,被廣泛應用于農作物害蟲的識別與診斷中。AYAN 等[2]集成Inception-V3[3]、Xception[4]和MobileNet[5],提出了GAEnsemble 模型,通過遺傳算法確定預訓練模型權重,該模型具備良好的穩定性和作物害蟲識別準確性。蘇仕芳等[6]利用ImageNet-21k 預訓練VGG-16[7-8],并在葡萄葉片病害數據集上微調,通過數據增強技術結合遷移學習的訓練方式,該模型對褐斑病、黑腐病等葡萄葉常見病害的識別準確率均達到90%以上。孫鈺等[9]將VGG-16 用于無人機上對森林害蟲進行檢測。梁萬杰等[10]提出一種卷積神經網絡模型的水稻害蟲識別方法。TURKOGLU 等[11]提出了一種基于LSTM(long short-term memory)[12]的卷積神經網絡模型MLP-CNNs,實現了蘋果害蟲的精確識別。王林惠等[13]優選MoblieNet 作為害蟲圖像特征提取網絡對柑橘害蟲進行準確識別。
雖然上述研究在一定程度上解決了農作物害蟲的識別問題,但是目標種物僅僅局限于小麥、蘋果、柑橘等,對于葡萄園中的害蟲識別仍然存在識別精度不足、針對性不強等問題。針對此,找到一種能夠更加精準識別葡萄園害蟲種類的模型和方法已成為葡萄園提高產量和品質的迫切需求。
知識圖譜(knowledge graph, KG)作為一種能夠精確描述領域內復雜知識的數據模型,被廣泛應用于智能搜索、個性化推薦等領域。在農業領域知識圖譜方面,于何龍等[14]構建了包含害蟲種類、病害類別、病斑顏色、發病階段等信息的水稻病害蟲本體,并開發了知識圖譜與確定性因子模型相結合的水稻病害蟲知識推理和智能診斷系統,該系統支持領域知識檢索,能夠為水稻作物生產實踐提供指導。戈為溪等[15]提出了一種基于知識圖譜和案例推理的水稻精準施肥推薦模型,該施肥推薦模型能夠輸出詳細的施肥方案和精確的施肥量。吳賽賽等[16]提出了一種基于深度學習的實體-關系抽取模型,成功實現多源數據中有用知識的準確抽取,所構建的病害蟲知識圖譜能夠為其他農作物相關下游任務提供高質量的知識基礎。鄭泳智等[17]對荔枝和龍眼害蟲知識進行了研究,并基于知識圖譜開發了智能問答系統,為害蟲診斷和防治提供指導。知識圖譜技術的引入實現了數據信息的有效利用,同時提高了專業知識在農業領域的應用能力。
然而,現有研究中知識圖譜主要用于農業領域的知識檢索和智能診斷,很少涉及將知識圖譜與計算機視覺技術相結合以提高害蟲圖像識別精度的研究。同時對于覆蓋果蔬作物害蟲知識圖譜的深入研究較少,尤其是針對葡萄園害蟲這一垂直領域的系統仍有待開發。為解決上述問題,本研究提出了一種基于屬性特征知識圖譜的細粒度葡萄園害蟲識別方法ACKGViT(attribute characteristics knowledge graph enhanced vision transformer),利用從農業科學等網站收集的大量葡萄害蟲相關知識語料,由領域專家指導構建了害蟲屬性特征知識圖譜,用于增強視覺編碼器對害蟲圖像細粒度特征信息的感知能力,從而實現葡萄園害蟲精確識別。該方法可作為葡萄園害蟲信息檢索、智能推薦等下游應用的知識庫基礎,可以有效應用于作物品種選擇、害蟲防控等農業生產方面。
1 葡萄園害蟲知識圖譜構建
1.1 葡萄園害蟲知識獲取與預處理
由于葡萄園害蟲領域暫時沒有公開可用的資料庫和數據庫能夠直接作為試驗材料,本研究涉及的葡萄害蟲相關知識和數據通過專業農業網站、昆蟲科學網站、維基百科、百度百科等知識庫獲取。利用Scrapy 框架,共爬取包括綠盲蝽、大青葉蟬、葡萄二星葉蟬等21 種葡萄園常見害蟲在內的數據1 264 條。通過正則表達式等數據清洗方式,將爬取的數據轉化為規范化的葡萄害蟲語料。清洗后的數據包括半結構化和非結構化兩種類型:
1)半結構化數據。數據包括例如“形態特征”“生活習性”等目錄或標題在內的半結構化信息,通過構造相應規則直接進行實體抽取。
2)非結構化數據。將整段、整篇文本作為屬性的數據,采用深度學習模型Bi-LSTM-CRF[18]對該類型的數據進行實體抽取,以將實體-屬性抽取轉換為序列標注任務。
1.2 葡萄園害蟲屬性特征知識圖譜建模
知識圖譜構建包括“自底向上”和“自頂向下”兩種方式。自底向上是一種數據驅動方式,適用于開放領域的知識圖譜構建;而自頂向下的構建方式是指在構建知識圖譜之前,預先定義本體和模式。根據本研究是垂直于“葡萄園”種植行業的研究這一特性,采用自頂向下的方式構建葡萄園害蟲屬性特征知識圖譜。將實例集合定義為 <害蟲類別,關系,屬性特征> 的三元組,并選用圖數據庫Neo4j 作為知識存儲方式。
為了更加精準地描述葡萄園害蟲實體、屬性特征以及實體關聯信息,本文確定了常見葡萄園害蟲的種類、生命周期、分布區域,以及它們對葡萄產量和品質的影響程度,從而更全面地理解葡萄園害蟲問題。此外,還研究了針對不同害蟲種類的防治策略和方法,在這項研究中,對害蟲的屬性特征進行了細致的分析,包括顏色特征、紋理特征和輪廓特征。這些特征有助于區分不同種類的害蟲,為識別模型提供了豐富的信息,使得模型識別準確率得以上升。除此之外,還深入研究了害蟲的生物學特性,如生活習性、繁殖方式、天敵關系等。通過對害蟲的分類體系的了解,可以為知識圖譜構建提供更為精細的分類依據。在收集了大量葡萄害蟲相關知識語料后,本研究構建出了一個能夠精確反映葡萄園害蟲實體屬性和關聯信息的知識圖譜,最終知識圖譜部分搭建效果展示如圖1 所示。
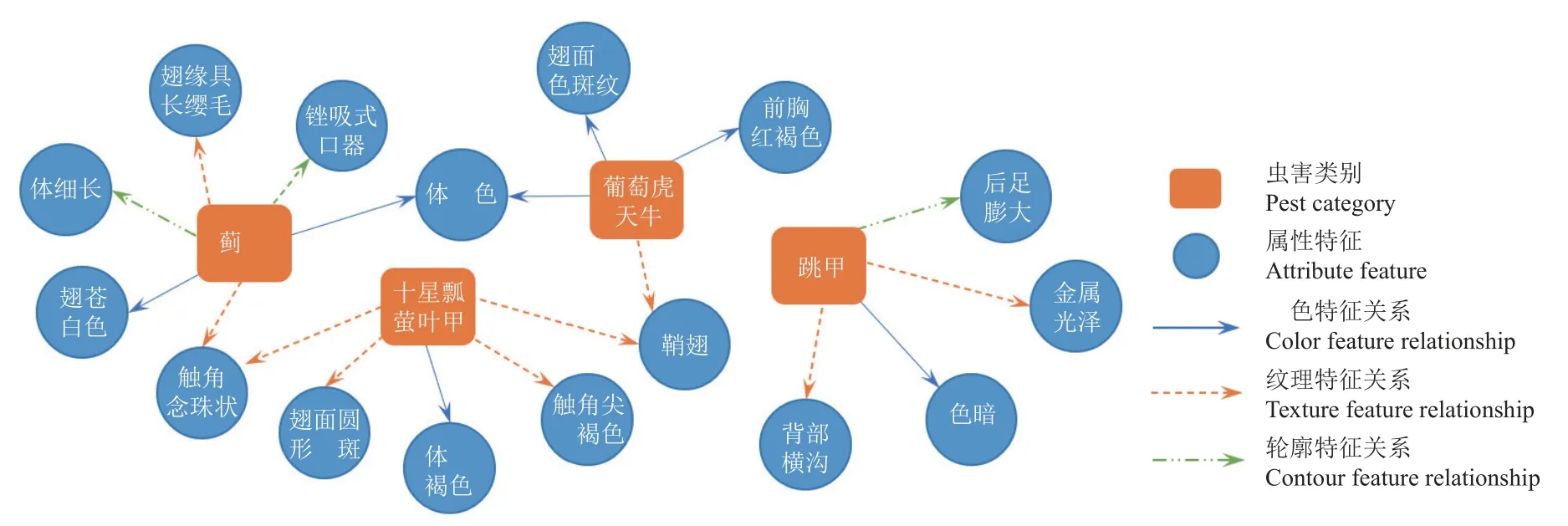
圖1 知識存儲示例Fig.1 Example of storing knowledge
2 ACKGViT 模型介紹
如圖2 所示,本文所提出的ACKGViT 模型采用雙分支結構,構建包括:基于屬性特征知識圖譜(attribute characteristics knowledge graph, ACKG)的害蟲屬性特征及關聯特征提取分支,和基于深度學習網絡ViT[19](vision transformer, ViT)的害蟲圖像高層語義表征提取分支,結合兩個分支獲取的特征向量,用于葡萄害蟲圖像分類研究。ACKG 通過圖卷積網絡實現映射。其中值得說明的是,在僅使用單一知識圖譜進行訓練時,網絡初始化參數可能會對最終優化效果造成干擾,因此,為了讓知識圖譜學習到的關系更符合實際領域知識,本文還引入了傳統特征信息,作為知識圖譜特征學習的目標,用于優化訓練。
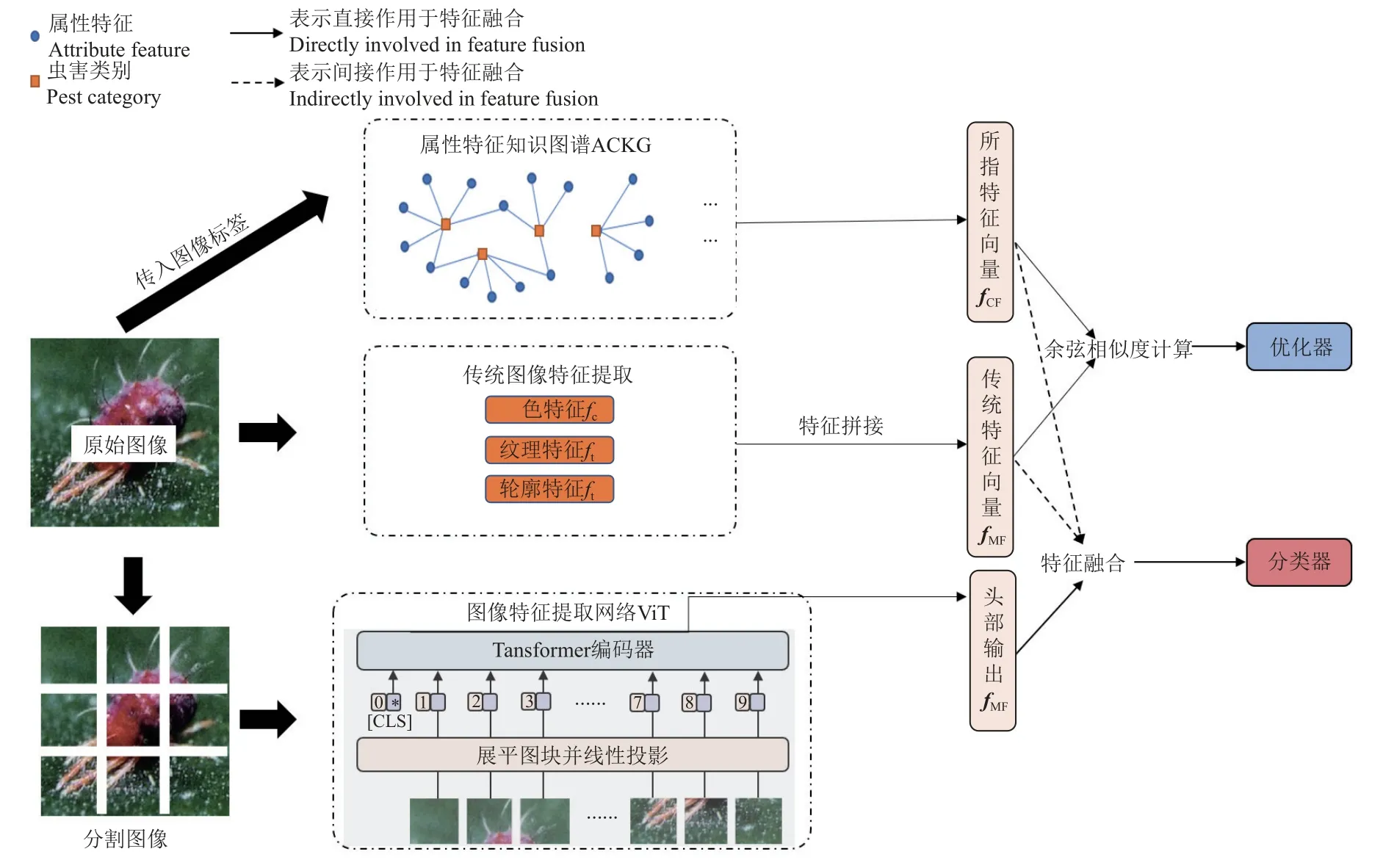
圖2 ACKGViT 模型示意圖Fig.2 Illustration of the ACKGViT(attribute characteristics knowledge graph enhanced vision transformer) model
2.1 細粒度害蟲屬性特征提取網絡
2.1.1 傳統特征提取模塊
ACKGViT 組合顏色特征、紋理特征和輪廓特征作為傳統手工特征向量。對于輸入的每一張圖像,將顏色矩作為圖像顏色表征,定義為fc;使用局部二值模式(local binary patterns)[20]和灰度共生矩陣(gray-level co-occurrence matrix)[21]分別提取圖像紋理特征并進行拼接(Concatenate),所得向量作為全局紋理特征ft;輪廓特征fo基于Canny 邊緣檢測算法進行提取。最終傳統特征fMF由上述3 種特征通過拼接操作得到:
2.1.2 屬性特征知識圖譜ACKG本研究利用GAT(graph attention network, GAT)[22]網絡將葡萄園病害蟲知識圖譜ACKG 映射為可以進行訓練的神經網絡模塊。GAT 是由VELICKOVIC P 等[22]在2018 年提出的一種圖卷積網絡模型,由堆疊圖注意力(Attention)層構成,利用自注意力機制(Self-attention)聚合鄰居節點信息,通過在訓練過程中自適應學習鄰居權值的方式,使得模型具備良好的可解釋性和準確性。知識圖譜中的點包括害蟲類別Nl和害蟲特征Nf兩種類型:
式中n和m分別代表害蟲類別總數和圖譜中所有屬性節點的數量。l0代表害蟲類別的第一個索引。式(2)表示知識圖譜中害蟲類別節點的集合,其中Nl0是第一個害蟲類別節點,Nl1是第二個害蟲類別節點,依次類推,直到Nln為第n個害蟲類別節點。同樣,式(3)表示知識圖譜中害蟲特征節點的Nf集合,包括m個特征節點。
ACKG 的訓練包括兩個步驟:首先,基于輸入害蟲圖像的標簽(Label)在知識圖譜中進行索引,得到該類害蟲在知識圖譜中對應節點的屬性特征向量,記為fCF;然后,與手工特征向量fMF進行余弦相似度計算,得到相似度損失 Ls:
式中,k代表特征向量的維度,與害蟲類別總數相等。fMFi代表手工特征向量fMF的第i個分量,fCFi代表屬性特征向量fCF的第i個分量。式(4)計算的是相似度損失Ls,其目的是衡量手工特征向量fMF與知識圖譜中屬性特征向量fCF之間的相似度。這里使用了余弦相似度作為相似度的度量方法,因為它能夠很好地捕捉兩個向量之間的角度關系,而不受長度影響。式(4)的分子部分計算了fMF和fCF之間的點積,而分母部分計算了各自的模長乘積。通過將點積除以模長乘積,可以得到兩個向量之間的余弦相似度。這個相似度值可以用于評估手工特征與知識圖譜中屬性特征之間的一致性。在訓練過程中,希望最小化相似度損失 Ls,以便使得手工特征與知識圖譜中的屬性特征更加一致。
測試時,利用每張圖像的手工特征向量,與ACKG中所有表示害蟲類別的節點所對應的特征向量進行余弦相似度計算,組合得到屬性相似性特征向量fCL。用lk表示害蟲類別節點索引,則fCL表示為
2.2 害蟲圖像高層語義表征提取網絡ViT
由于視覺編碼器ViT[19]在多種預訓練網絡模型中表現最為優異,本研究將ViT 作為提取圖像高層語義表征信息的骨干網絡。
ViT 是由Google 團隊在2020 年提出的一種圖像分類模型,通過在視覺任務中引入Transformer[23]機制,ViT 表現出了良好的性能與可擴展性,現被廣泛應用于各類視覺任務。
對于輸入圖像X∈RH×W×C,即高、寬、通道數分別為H、W、C,ViT 會首先將其切分為多個子圖塊(Patch),并展平為一維輸入序列。令圖塊大小為P×P,則該子圖塊序列表示為
式中,N表示子圖塊數目。
接下來,將每個子塊投影為固定長度D的向量再輸入到Transformer 編碼器,即有:
在序列頭部嵌入特殊字符CLS,從而將視覺問題轉化為seq2seq 問題。經過位置編碼、層歸一化以及多層感知機進行維度變換之后,得到最終圖像表征輸出向量,記為fSF。為了獲得更好的遷移效果,本研究所使用的是經過ImageNet-21k 預訓練的ViT 網絡。
2.3 分類器
ACKGViT 結合知識圖譜提取的圖像屬性特征和ViT 提取的圖像高層語義表征特征用于訓練分類器。訓練、測試時融合后的特征ftrain、ftest分別表示為
分類器由全連接網絡和Softmax 函數構成。輸入是害蟲圖像特征向量,即ftrain或ftest,輸出是害蟲類別。
模型損失 L用交叉熵損失函數 Lc和余弦損失函數Ls表示:
式中,yi和y?i分別表示輸入害蟲圖像的真實標簽和預測標簽,p(y?)表示y?的預測概率。
訓練分類器方法依據與原理如下:1)圖像屬性特征提取:利用知識圖譜中的概念節點和它們之間的關系來捕捉圖像中的屬性信息。知識圖譜通過對領域知識的結構化表示,為模型提供了關于病害蟲的高級信息。利用圖注意網絡(graph attention networks,GAT)對知識圖譜進行編碼,從而為每個概念節點生成一個特征向量。這些特征向量可以視為害蟲類別的屬性特征。2)高層語義表征特征提取:使用ViT 從圖像中提取高層語義表征特征。ViT 通過將圖像分割為固定大小的patches,并將它們線性嵌入到特征空間中,然后應用Transformer 結構進行特征抽取。這樣,ViT 可以捕獲圖像中的全局上下文信息,從而生成具有高層語義的特征表示。3)訓練階段:將知識圖譜提取的圖像屬性特征與ViT 提取的高層語義表征特征進行融合。融合通過特征加法操作進行融合。融合后的特征向量包含了病害蟲的屬性信息和圖像的高級語義信息,可以更好地表征害蟲類別,提高分類性能。這樣做可以進一步引導模型關注與目標類別相關的特征,減小背景噪聲的影響。具體過程如圖3 所示。
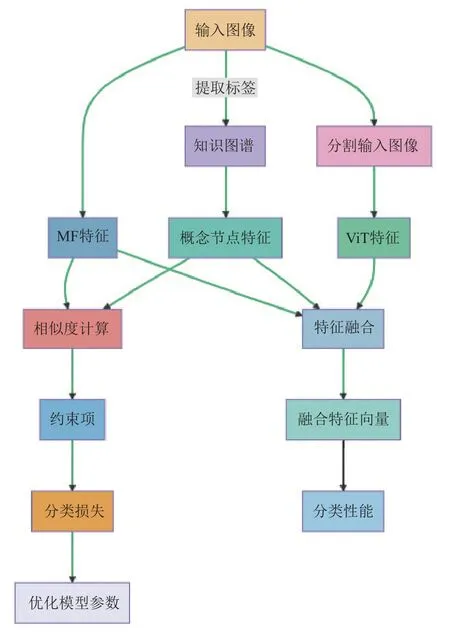
圖3 ACKGViT 模型具體運作機理Fig.3 Specific operating mechanism of ACKGViT(attributecharacteristics knowledge graph enhanced vision transformer) model
2.4 數據集
本研究測試所用數據集包括從大規模公開數據集IP102[24]中挑選的GP21 數據集和從農業生產基地實地采集的GP8 數據集。
GP21 數據集。GP21 數據集來源于IP102[24]數據集,該數據集包括從專業農業網站和昆蟲科學網站上收集的共計75 222 個樣本。由于本任務聚焦于葡萄園害蟲的細粒度識別問題,所以從中挑選了21 種葡萄園常見害蟲圖像,構成GP21 數據集,用于分類研究,其中,訓練樣本和測試樣本總數分別為10 303 和1 714。
GP8 數據集。該數據集采集于杭州浙大城市學院植物工廠基地。如表1 所示,在3 位農業專家指導下,利用遠程可視化自動害蟲監測系統iMETOS iSCOUT,采集了包含綠盲蝽、大青葉蟬和麥二叉蚜等在內的8 種當季葡萄園害蟲圖像,通過人工篩選和標注,最終獲得GP8 數據集,如圖4 所示,其樣本總數為1 365。將GP8數據集按照3:1 的比例進行劃分,得到訓練集和測試集。其中,訓練樣本總數為1 023,測試樣本總數為342。

表1 GP8 數據集包含害蟲類別及相應樣本量Table 1 Taxonomy and its corresponding sample size of the GP8 dataset

圖4 GP8 數據集中的樣本示例Fig.4 Different example images of the GP8 dataset
2.5 試驗設置
本文所提出的ACKGViT 模型采用兩層的GAT 網絡,所含MLP(multi-layer perceptron, MLP)隱藏層維度為16,注意力頭Z設置為4,輸出結點數目與數據集中害蟲類別總數保持一致;ViT 使用默認參數配置。在將圖像輸入到網絡進行特征提取之前,通過縮放操作(Resize)保證其空間尺度為224× 224。訓練時觀察到模型在50 個輪次時已完全收斂,本試驗將訓練輪次設置為50,學習率設置為0.001。
相關試驗在裝有NVIDIA RTX 3 090 GPU 和Intel Core i9 10900K CPU 的機器上進行。訓練過程使用SGD優化器,GP21 數據集和GP8 數據集完成50 個輪次的訓練分別需要大約4 和0.5 h。與其他數據集相關文獻一致,本試驗將準確率(accuracy,A)作為評估模型性能的指標,同時也列舉了F1 分數(F1),精確率(precision,P),召回率(recall,R)指標的計算結果。
式中,Tp是正確預測的正樣本數量,Tn是正確預測的負樣本數量,Fp是錯誤預測的正樣本數量,Fn是錯誤預測的負樣本數量。
2.6 模型算法的復雜度分析
在評估所提出的葡萄園害蟲識別模型的性能之外,還需要關注算法復雜度和計算量等方面的分析。這些分析有助于了解模型在實際應用中的效率和可擴展性。
首先,考慮模型的時間復雜度。模型的主要組成部分包括視覺編碼器(ViT)和圖卷積網絡(graph convolutional network,GCN)。對于ViT,其時間復雜度主要取決于圖像的分辨率和ViT 的層數。假設輸入圖像的大小為H×W,ViT 的層數為L,那么ViT 的時間復雜度大致為O(L×H×W)。對于GCN,其時間復雜度主要取決于圖的節點數和GCN 的層數。假設知識圖譜有N個節點,GCN 的層數為K,那么GCN 的時間復雜度大致為O((K×N)2)。因此,整個模型的時間復雜度大約為O(L×H×W+(K×N)2)。
其次,關注模型的空間復雜度。同樣地,模型的空間復雜度主要取決于ViT 和GCN。對于ViT,其空間復雜度主要與圖像分辨率和ViT 的參數數量有關。設ViT的參數數量為Pv,那么ViT 的空間復雜度大約為O(Pv)。對于GCN,其空間復雜度主要與知識圖譜的節點數和GCN 的參數數量有關。設GCN 的參數數量為Pg,那么GCN 的空間復雜度大約為O(Pg+N)。因此,整個模型的空間復雜度大約為O(Pv+Pg+N)。
最后,討論模型的計算量。計算量主要受輸入圖像大小、模型參數數量以及訓練迭代次數等因素的影響。在訓練階段,模型需要對大量圖像進行前向傳播和反向傳播,以更新模型參數。設訓練迭代次數為T,那么整個模型的計算量大約為O(T(L×H×W+(K×N)2))。
綜上所述,本研究所提出的模型在時間復雜度、空間復雜度和計算量方面的分析表明,雖然引入知識圖譜和圖卷積網絡增加了一定的計算負擔,但總體上仍在可接受范圍內。此外,隨著硬件性能的提升和算法優化技術的發展,該模型在實際應用中將具有較高的效率和可擴展性。
3 結果與分析
3.1 不同模型在數據集上的性能比較
表2 分別列出了預訓練網絡VGG-16、ResNet-152[21]、Inception-V3、 Xception、 MobileNet、 SqueezeNet[22]和ViT 在GP21 和GP8 測試集上的性能。
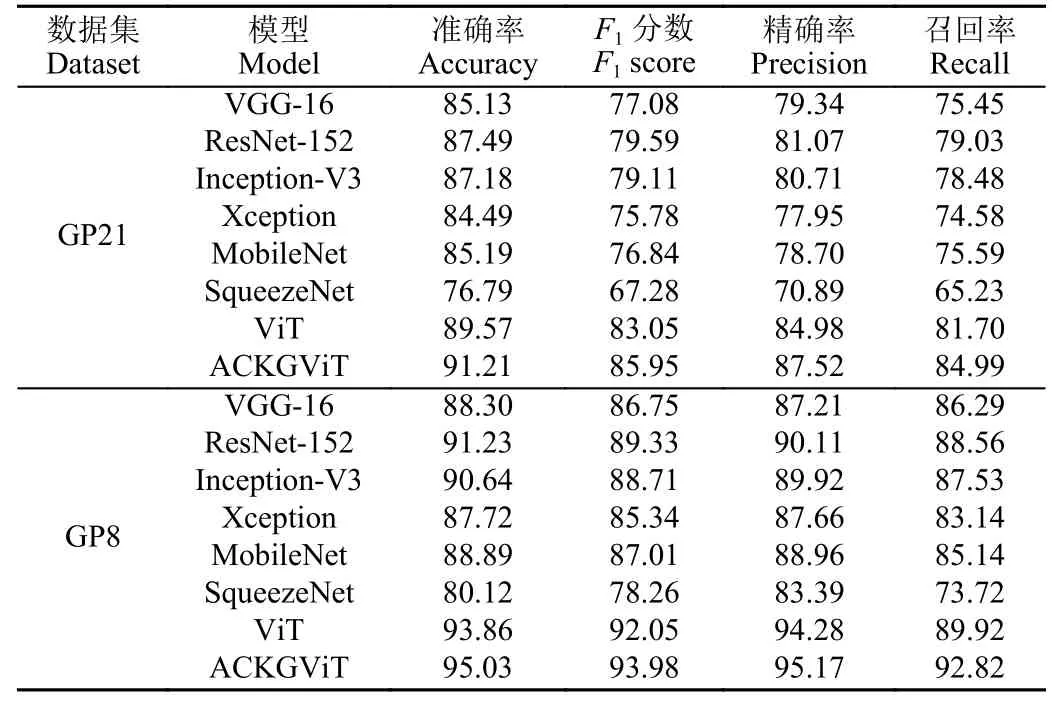
表2 不同模型在GP21 和GP8 數據集上的性能對比Table 2 Performance comparison of the different models on the GP21 and GP8 datasets.%
從表2 中可以看出,ViT 模型在Accuracy 和F1指標上都明顯優于其他模型。相比于目前視覺任務中最高頻使用的模型之一ResNet-152,ViT 的Accuracy 和F1 值在GP21 數據集上分別提高了2.08 和3.46 個百分點,在GP8 數據集上分別提高了2.63 和2.72 個百分點。這是因為相比于卷積神經網絡模型,ViT 的注意力機制使得它具備低層的全局特征學習能力,所以利用ViT 提取的高層表征能夠更精細地整合害蟲圖像全局和局部信息,因此,本研究將ViT 作為骨干網絡構建ACKGViT 模型。
ACKGViT 的性能在表3 最后一行展示,相比于ViT,ACKGViT 的Accuracy 和F1值在GP21 數據集上分別提高了1.64 和2.90 個百分點,在GP8 數據集上分別提高了1.17 和1.93 個百分點,這是因為ViT 在識別形狀相似的物體時能力不足[27],而知識圖譜能夠提供不同類別害蟲之間的細節信息,從而輔助ViT 區分害蟲類型。
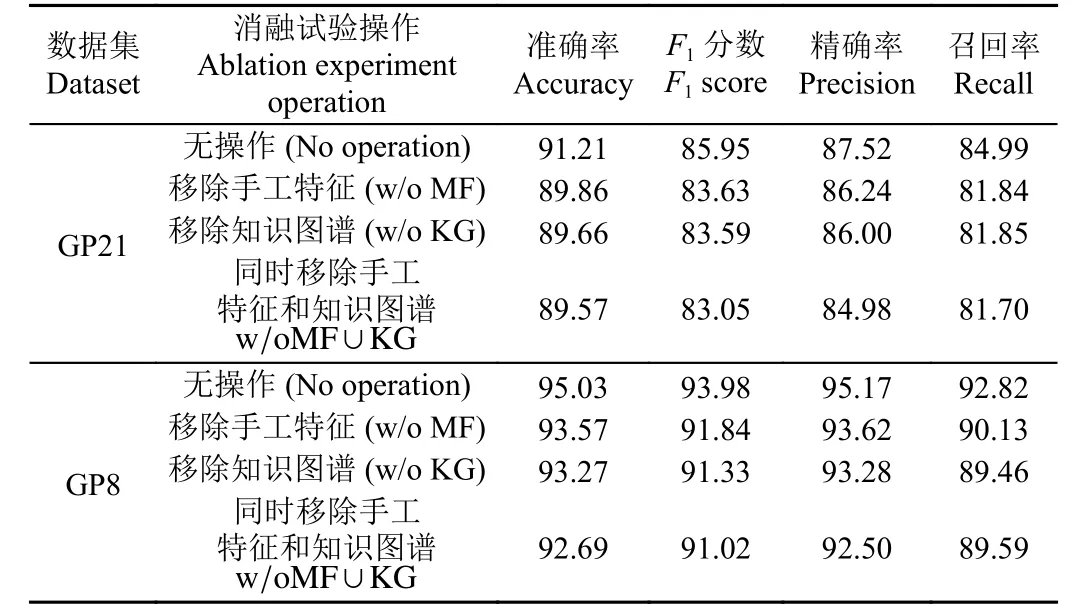
表3 知識圖譜和手工特征消融試驗結果Table 3 Ablation study results of knowledge graph and handcrafted features%
3.2 消融試驗
為了進一步分析知識圖譜的引入對于葡萄園害蟲分類性能的提升作用,本研究設計了3 組消融試驗:1)將ACKGViT 模型移除手工特征(w/o MF),使提取的手工特征不參與特征融合;2)將ACKGViT 模型移除知識圖譜(w/o KG),使知識圖譜提取的屬性特征不參與特征融合;3)同時移除手工特征和知識圖譜(w/oMF∪KG),使得手工特征和知識圖譜提取的屬性特征均不參與特征融合。
3 組消融試驗結果如表3 所示。從表3 中可以看出,移除知識圖譜和手工特征(w/oMF∪KG)使得模型性能accuracy 和F1在GP21 數據集上分別下降1.64 和2.9個百分點,在GP8 數據集上分別下降2.34 和2.96 個百分點。移除手工特征(w/o MF)和移除知識圖譜(w/o KG)使得模型性能accuracy 在GP21 數據集上分別下降1.35 和1.55 個百分點,在GP8 數據集上分別下降1.46和1.76 個百分點,同時,F1在GP21 數據集上分別下降2.32 和2.36 個百分點,在GP8 數據集上分別下降2.10和2.60 個百分點。上述結果表明:1)通過引入知識圖譜的方式輔助ViT 獲取更加精確的害蟲信息是有效的;2)僅使用傳統特征和知識圖譜在提升模型性能上作用不大,主要原因是:傳統特征提取方法在表達圖像高層語義信息方面存在缺陷,而僅使用知識圖譜無法有效訓練圖卷積網絡,從而使得結點特征向量表征不足;3)在ACKGViT 模型學習中,知識圖譜作用大于傳統特征,這是因為除了圖像淺層表征外,知識圖譜還能夠提供不同類別之間的關聯特征等額外信息作為輔助分類的線索。例如,如圖1 所示,知識圖譜能夠通過“足”的長短、“后翅”顏色等屬性特征來區分都含有“體暗褐色”特征的“斜紋夜蛾”和“葡萄短須螨”。另一方面,知識圖譜基于卷積神經網絡實現,能夠從原始圖像中提取到復雜抽象的深層特征,這些特征可以增強模型對于分類任務的健壯性。
3.3 可視化案例子
為了驗證知識圖譜的引入在葡萄園害蟲特征挖掘方面的可用性,本研究進一步比較了ACKGViT 模型與骨干網絡ViT 模型學習到的害蟲特征向量,并利用可視化技術[28]直觀展示對比結果。
如圖5 所示,在不同復雜程度的背景條件下,對于不同類別的害蟲,ACKGViT 方法都可以準確關注到害蟲區域。

圖5 ACKGViT 和 ViT 可視化結果對比Fig.5 Visualization of ACKGViT method and ViT method
此外,相比于ViT 方法,ACKGViT 能夠更加準確地將害蟲區域和背景環境區分,并且描繪出更加清晰的輪廓曲線,證明ACKGViT 方法能夠捕捉到更加細節、更加完整的害蟲特征信息并用于分類研究。
3.4 不同相似度計算方法的對比試驗
在本章節中將對不同相似度計算方法進行對比試驗,以評估它們在葡萄園害蟲識別任務中的性能。相似度計算方法是評估兩個實體之間相似程度的關鍵因素,對于基于知識圖譜的葡萄園害蟲識別方法來說尤為重要。通過比較不同相似度計算方法,可以找到適合該任務的最佳方法,從而提高識別精度和效率。為了達到上述目的,本研究選取了以下幾種常見的相似度計算方法進行對比試驗:余弦相似度、歐幾里得距離、曼哈頓距離、皮爾森相關系數、Jaccard 系數。為了確保試驗結果的可靠性,將在相同的數據集上對各種相似度計算方法進行評估。試驗結果如表4 所示。
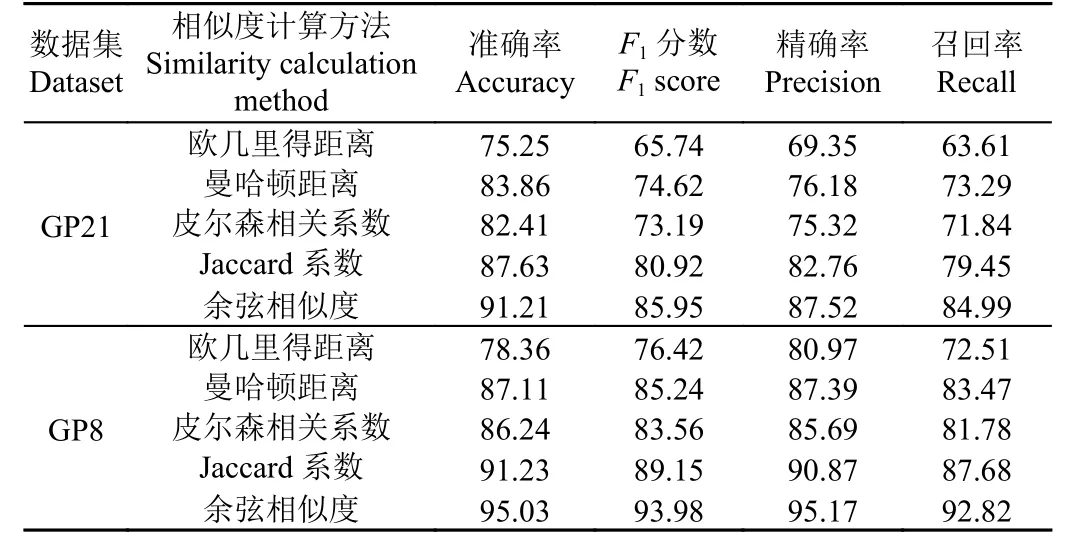
表4 不同相似度計算方法的性能對比Table 4 Performance comparison of the different similarity calculation methods%
根據試驗結果分析,在GP21 數據集上,使用余弦相似度相比于歐幾里得距離、曼哈頓距離、皮爾森相關系數和Jaccard 系數,準確率分別提高了15.96 個百分點、7.35 個百分點、8.80 個百分點和3.58 個百分點;F1分數分別提高了20.21 個百分點、11.33 個百分點、12.76 個百分點和5.03 個百分點。在GP8 數據集上,使用余弦相似度相比于歐幾里得距離、曼哈頓距離、皮爾森相關系數和Jaccard 系數,準確率分別提高了16.67 個百分點、7.92 個百分點、8.79 個百分點和3.8 個百分點;F1分數分別提高了17.56 個百分點、8.74 個百分點、10.42 個百分點和4.83 個百分點。通過上述分析可以得出余弦相似度計算方法在葡萄園害蟲識別任務中性能表現最優的結論,通過對比試驗為該任務找到了最佳的相似度計算方法,從而為后續研究和實際應用提供了有益的啟示。
4 結 論
本研究基于領域農業專家的豐富經驗和害蟲知識語料構建了一套詳盡的葡萄園害蟲屬性特征知識圖譜。在此基礎上,本研究提出了一種基于知識圖譜的細粒度害蟲分類雙分支模型ACKGViT。該模型利用圖卷積網絡GAT 將知識圖譜轉化為可供訓練的神經網絡模塊,同時結合傳統特征對網絡參數進行訓練和優化。主要結論如下:
1)與骨干網絡ViT 相比,ACKGViT 在葡萄園害蟲分類任務中表現出了明顯的性能提升。具體而言,ACKGViT 在GP21 數據集上的準確率和F1指標分別提高了1.64 和2.90 個百分點,而在GP8 數據集上,這兩個指標分別提高了1.17 和1.93 個百分點。
2)知識圖譜和手工特征消融試驗結果表明:移除知識圖譜所在分支使得模型性能準確率和F1分數在GP21數據集上分別下降1.64 和2.90 個百分點,在GP8 數據集上分別下降2.34 和2.96 個百分點。移除手工特征和移除知識圖譜使得模型性能Accuracy 在GP21 數據集上分別下降1.35 和1.55 個百分點,在GP8 數據集上分別下降1.46 和1.76 個百分點,同時,F1在GP21 數據集上分別下降2.32 和2.36 個百分點,在GP8 數據集上分別下降2.10 和2.60 個百分點。證明本文所提方法的有效性。
3)不同相似度計算方法的性能對比試驗結果表明:在GP21 數據集上,使用余弦相似度相比于其他相似度計算方法,準確率和F1分數分別提高了最多15.96 個百分點和20.21 個百分點。相應地,在GP8 數據集上,準確率和F1分數相比于其他方法最多提高了16.67 個百分點和17.56 個百分點。這些結果充分證明,余弦相似度在葡萄園害蟲識別任務中的性能表現最優。
在未來的研究中將會繼續深入探索知識圖譜在害蟲圖像分類任務中的應用:1)圖譜權重優化:研究如何更有效地利用知識圖譜中的權重信息,進一步提高害蟲圖像分類的性能;2)動態知識圖譜構建:實時更新和擴展知識圖譜,以適應不斷變化的農業環境和新出現的病害蟲類型;3)多模態數據融合:探討將其他數據源(例如氣象數據、土壤信息等)與圖像數據融合,提供更豐富的上下文信息以提高分類準確性。通過以上研究方向的探索,期望為智慧農業的發展貢獻力量,從解決實際問題出發,促進農業生產的可持續發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
