基于自生成標簽的玉米苗期圖像實例分割
2023-08-15 16:19:00趙露露鄧寒冰周云成張羽豐
農業工程學報 2023年11期
趙露露 ,鄧寒冰 ,2※,周云成 ,2,苗 騰 ,2,趙 凱 ,楊 景 ,張羽豐
(1. 沈陽農業大學信息與電氣工程學院,沈陽 110866;2. 遼寧省農業信息化工程技術研究中心,沈陽 110866)
0 引 言
隨著信息技術與農業生產過程的不斷融合,計算機視覺技術被廣泛用于獲取植物表型信息。智能化植物表型監測技術能夠監測農作物生長情況,通過分析表型特征并采取對策,有效緩解由氣候變化、耕地減少等原因導致的糧食安全問題,加速育種與現代化農業的進步。相較于人工獲取植物表型信息,傳統的計算機視覺技術可以針對目標區域提供一種基于圖像的非接觸式檢測手段[1],如基于Otsu 與分水嶺結合的兩級分割算法結合梯度Hough 圓變換[2],基于LAB 顏色空間的圖像分割[3]、基于統計直方圖K-means 聚類算法的圖像聚類分割[4]等,這些方法可以在圖像背景信息相對簡單時發揮分割優勢。而當圖像背景復雜度提高時,可以使用基于樸素貝葉斯分類的圖像分割方法,通過引入概率因素提高分割準確率,實現復雜背景下植物特定區域的信息提取[5]。另外,基于多階段柯西灰狼算法的多閾值圖像分割優化器也成功實現了分割[6]。然而,利用傳統計算機視覺方法獲得較好的分割結果需要圖像質量、構圖內容、主要目標占比和位置等素滿足一定要求,因此這些方法往往不具有普適性和通用性。
近些年深度學習技術蓬勃發展,特別是在圖像的實例分割技術領域取得了實質性的進步[7]。自HARIHARAN等[8]首次利用深度學習模型同步實現“目標檢測+分割”任務以來,基于深度學習技術的實例分割方法開始迅速發展,并通過不斷優化使實例分割模型的性能得到顯著提升[9-12]。研究人員利用圖像實例分割技術能夠實現更精準的單體植株、葉片、器官、果實等信息提取,通過使用深度卷積神經網絡提高實例分割模型對圖像復雜背景的適應能力[13-14]。如孫紅等[15]利用SSDLite-MobileDet網絡模型實現了玉米冠層的快速檢測;王璨等[16]通過改進雙注意力機制結合形態學處理方法,實現玉米圖像中的雜草目標分割;TURGUT 等[17]采用基于注意力機制的深度學習架構,通過提取上下文特征并進行特征傳播,以分層方式處理點區域實現植物器官分割;ZENKL 等[18]利用DeepLab V3+模型實現室外條件下冬小麥植物分割。
然而,目前的深度學習方法多采用全監督學習模式,即模型訓練時需要提供“圖像+像素級標簽”,模型精度依賴于大規模的、精細到像素粒度的人工標注數據集。而植物表型領域的公開數據集較少,且數據種類單一,不具有普適性,研究人員往往要根據需求創建個性化的數據集,導致人工標注成本一直居高不下。為了緩解這一問題,一些研究人員嘗試降低模型訓練過程對標簽精度的要求,通過使用圖像級標簽[19-22]或邊界框標簽[23-25]這種非精準標簽訓練深度學習模型,在弱監督學習、無監督學習的模式下實現分割,DiscoBox[26]以及FreeSOLO[27]等方法顯著縮小了與完全監督學習的差距,為農業圖像實例分割技術提供了有效的技術方法;趙亞楠等提出基于邊界框標注掩膜的深度卷積神經網絡,利用偽標簽代替像素級標簽作為訓練樣本實現玉米植株圖像的高精度分割[28];ZHUANG 等[29]利用深度卷積神經網絡,基于框級標注和顏色相似性的弱監督學習方式對綠葉蔬菜實現了實例分割;周云成等[30]提出基于稠密卷積自編碼器的無監督深度估計模型,以番茄植株的雙目圖像為訓練數據,通過估計深度誤差以及閾值的精度為依據實現番茄植株圖像的深度估計;LU 等[31]以無人機航拍圖像獲取冠層面積、冠幅、位置等信息,提出一種無監督圖像分割方法,用于在自然光照條件下快速獲取果樹冠層。
實際上,弱監督學習仍然依賴于包含強大本地化信息的標注,盡管采取邊界框標注圖像的時間少于像素級標注,但為了獲取更精準的分割結果,往往需要大量的訓練數據,對于大田玉米圖像,由于拍攝中存在光照、葉片重疊、雜草等影響,弱監督學習需要的標簽依舊存在標注成本高的問題。而無監督學習不存在標注成本問題,但是由于沒有標簽對目標區域的范圍界定,其分割精度不足以支撐對植物特征信息的描述,尤其是玉米植株這種形態復雜的對象,其分割效果不具優勢,因此弱監督與無監督學習不適用于大部分的農作物圖像實例分割任務。為了有效降低人工標注成本,又能較好地描述圖像細節得到高精度的分割結果,本研究設計了一種基于自生成標簽的實例分割網絡,以弱監督實例分割模型為基礎,在主干網絡前加入弱標簽自生成模塊,利用顏色空間轉換、輪廓跟蹤和最小外接矩形在玉米苗期圖像(頂視圖)中生成目標邊界框(自生成標簽),利用自生成標簽代替人工標簽參與弱監督模型訓練,最終在無人工標簽條件下實現玉米苗期圖像的實例分割。
1 試驗材料與數據采集
本試驗選擇的玉米品種為“先玉 335”,該品種的植物性狀表現為在幼苗期長勢較強,成株葉片數在 20 片左右,具有高抗莖腐病,中抗黑粉病、彎孢菌葉斑病,大斑病、小斑病、矮花葉病等,其優越的抗病性可以讓玉米在其營養生長期保持個體健康和株形完整。玉米播種時間在 4 月份,播種方式為機播,播種行距為 50 cm,株距為 30 cm。
在苗期階段(單體株高在20~30cm,葉片數3-4 葉),試驗數據由無人機(大疆“精靈4-RTK”)高空俯視平行地面拍攝獲取。為保證玉米植株的基本形態穩定以及數據采集時光照條件的相似性,航拍時選擇在晴朗無風的天氣,采集時間在9:00-11:00,無人機航飛高度距地面8m,采集數據過程中,飛行航線自動覆蓋玉米植株生長的整片試驗田。
試驗中獲取的原始圖像像素大小為5472×3078,人工篩選出500 張滿足試驗要求玉米苗期圖像(俯視圖且去除擁有大面積雜草的圖像),每張圖像包含7~9 列玉米幼苗。為了適應模型的網絡深度,降低模型的過擬合幾率,提高網絡的泛化能力,試驗對基礎數據集中的原始圖像進行數據增強處理。對全部原始圖像進行鏡像翻轉、添加高斯噪聲、隨機改變亮度等操作實現數據增強,其中增強操作可以疊加使用,默認至少有一種增強生效,每張圖像增強兩次,將數據集擴增到1 500 張,在基礎數據集和數據增強的數據集中分別按照8∶1∶1 的比例隨機劃分訓練集、驗證集與測試集,以保障數據分布的合理差異性,其中1 200 張作為訓練數據,150 張作為驗證數據集,150 張作為模型的測試數據集。
2 基于自生成標簽的實例分割模型
2.1 總體模型框架和訓練平臺
本研究旨在構建具備標簽自動生成的弱監督圖像實例分割模型,以實現大田環境下低成本、高精度的玉米苗期圖像實例分割,總體模型框架主要包括:1)圖像采集與預處理:通過無人機采集大田玉米苗期頂視圖,并根據試驗需要人工篩選可以進行訓練和測試的圖像,通過數據增強方法提高樣本多樣性;2)標簽自生成模塊:在HSV 顏色空間中進行閾值分割、膨脹前景植株區域并刪除小噪聲點得到僅含前景玉米植株的二值圖像,利用二值圖像信息進行輪廓檢測并生成最小外接矩形,在原始圖像中自動產生主要目標對象的邊界框信息,并利用閾值篩選最終邊界框,自動生成圖像的弱標簽;3)構建并優化弱監督深度卷積神經網絡模型:利用弱標簽對弱監督深度學習模型進行訓練,最終獲得可用于玉米苗期圖像實例分割的網絡模型。具體如圖1 所示。
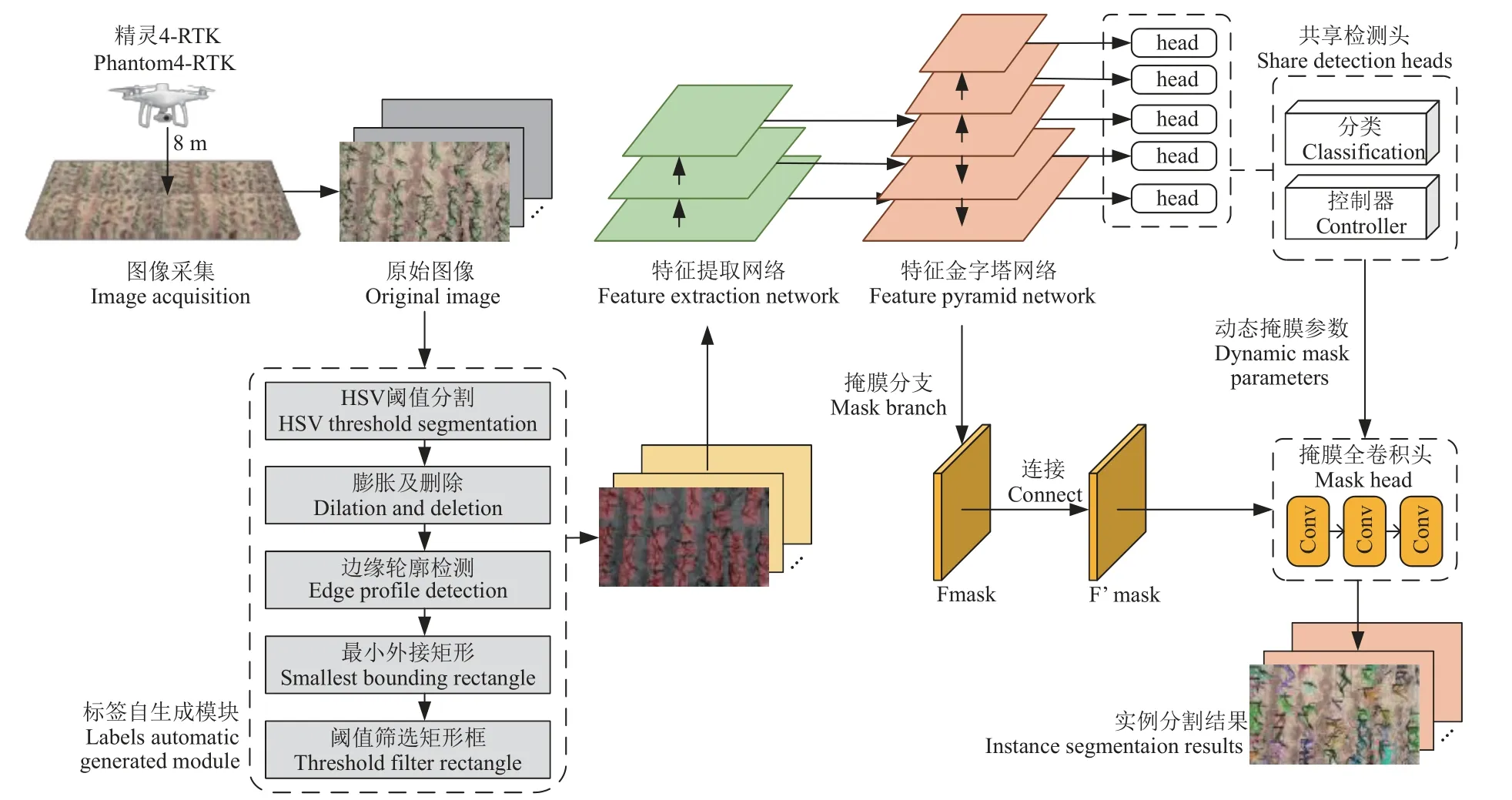
圖1 總體模型框架圖Fig.1 Overall model framework
為了保證模型訓練過程的公平性,同時提高訓練效率,試驗中使用2 種計算平臺,平臺的具體參數如表1 所示,其中平臺1 由于計算卡性能更優,承擔所有模型的預訓練任務;平臺2 用于所有預訓練模型的遷移學習和調優。

表1 試驗平臺參數Table 1 Parameters of experimental platform
2.2 圖像標簽自生成方法
在標記熟練的情況下使用LabelMe 軟件標注單幅玉米苗期圖像(頂視圖),像素級標注時間約為1 127 s,邊界框標注時間約為100 s,雖然采用邊界框標注能節省標記的時間,但當數據增多時,即便邊界框標注也需要耗費大量的時間成本,因此,本研究設計了圖像標簽自生成方法,整個過程不需要對圖像進行人工標注,便能夠根據圖像中玉米植株的位置自動生成邊界框(弱標簽)。
弱標簽自生成模塊主要包括2 個部分:1)顏色閾值分割:將圖像由RGB 轉換為HSV 顏色空間,通過設定玉米植株的顏色閾值范圍將圖像背景區域去除,消除地面影子、土地等對前景信息的影響;2)基于輪廓跟蹤的最小外接矩形法:將閾值分割后的二值圖像進行邊緣檢測,得到前景植株的輪廓點集,最后利用得到的輪廓點集坐標生成前景目標的最小外接矩形從而獲得邊界框標簽。
2.2.1 顏色閾值分割
在大田環境下,玉米植株受光照影響會在植株周圍地面形成影子,這些影子在頂視圖中會呈現出與植株形態相似的像素區域。試驗中發現,直接在RGB 圖像上進行閾值分割容易將植株影子劃入前景信息,導致后續生成邊界框時將影子也框入邊界框,降低邊界框標簽質量,并且陰影與植株邊緣信息極度相似,影響分割精度。為解決陰影對前景植株信息的影響,本試驗將圖像由RGB顏色空間轉為HSV 顏色空間再進行閾值分割。HSV 能夠描述圖像的色調(H)、飽和度(S)以及明度(V),在HSV 顏色空間上可以準確地對指定的顏色進行分割。對于存在多種顏色的數據集,可參考HSV 基本顏色分量增設不同顏色的閾值進行分割。圖2 為本試驗中玉米苗期圖像分別在H、S 與V 分量上的像素值分布,根據圖2設置H 的像素值范圍為[15, 35] 和[45, 70] ,S 的像素值范圍為[15, 255] ,V 的像素值范圍為[40, 255] 。
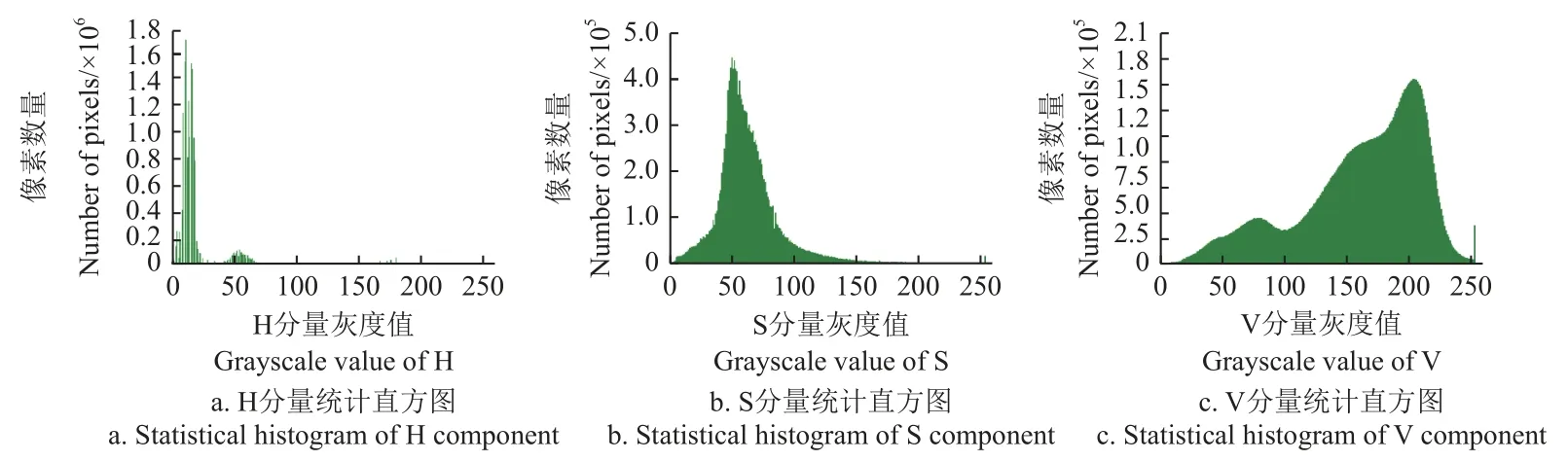
圖2 玉米苗期圖像的H、S、V 分量統計直方圖Fig.2 Statistical histogram of H, S, V components of maize seedling images
基于HSV 閾值的分割結果如圖3 所示,通過觀察發現圖像中存在一些離散的小面積噪聲點,因此本試驗在顏色閾值分割后增加一次膨脹處理,刪除小聯通區域的冗余噪聲點,分割結果如圖3d,由圖3c 與3d 中前景植株內部孔洞對比可以看出,通過膨脹處理可以有效解決閾值分割造成的小部分像素缺失,保持了玉米植株的實例完整,刪除小連通區域既去除了冗余噪聲點,又有效抑制了膨脹后未成功連接到玉米植株實例的小面積區域,避免了一個實例被隔開的情況。

圖3 基于HSV 顏色空間的閾值分割Fig.3 Threshold segmentation based on HSV color space
2.2.2 基于輪廓跟蹤的最小外接矩形法
在獲得圖像前景信息(玉米植株)后,需要根據玉米植株的位置獲得對應的邊界框信息,本研究采取的方法為在二值圖像中對前景目標進行邊緣檢測,識別前景目標邊緣后再繪制其最小外接矩形。為了獲取前景目標輪廓,本研究采用文獻[32] 的方法解析二值圖像的拓撲結構,獲取二值圖像前景的邊界的包圍關系。具體算法如下:
1)確定點邊界類型。定義輸入的二值圖像F={fij},初始化邊界序號NBD=1,前一個邊界的編號LNBD=1,并且每一行掃描開始,LNBD重置為1。使用光柵掃描輸入的二值圖像,找到點(i,j)滿足邊界跟蹤初始點的條件則終止掃描。條件為:若fij= 1 并且fi,j-1= 0,則(i,j)是外邊界開始點,NBD=NBD+ 1,(i2,j2) = (i,j-1),該點是一個外邊界;若fij≥ 1 并且fi,j+1= 0,則(i,j)是孔邊界開始點,NBD=NBD+1,(i2,j2) = (i,j+1)。如果fij≥ 1,則LNBD=fij,該點是一個孔邊界。
如果點(i,j)同時滿足以上2 個條件,則該點作為外邊界的起始點。
2)基于邊界類型決定當前邊界的父邊界。判斷規則如表2 所示。

表2 新邊界的父邊界判斷規則Table 2 Judgment rules for parent boundary of new boundary
3)從邊界起始點(i,j)開始,跟蹤已檢測到的邊界。以(i2,j2)為起始點,按順時針方向查找以(i,j)為中心的8 鄰域的第一個非0 像素點(前景目標),記錄為(i1,j1);再以(i1,j1)的下一個點為起始點,按逆時針方向查找以(i3,j3)為中心的8 鄰域的第一個非0 像素點為(i4,j4);更新邊界序號NBD,迭代更新起始點,直至掃描到圖像的右下角頂點時結束,邊界序號相同的像素點屬于同一個邊界。
利用該算法得到的玉米苗期輪廓圖像如圖4 所示,通過提取圖像前景目標的邊界信息,得到玉米植株的外輪廓點集S= {S1,S2, …,Sn}后,遍歷一個植株點集Sk內所有像素點,將Sk內i值最小與j值最大的點記為(imin,jmax),作為外接矩形的左上頂點,將Sk內i值最大與j值最小的點記為(imax,jmin),作為外接矩形的右下頂點。

圖4 基于二值圖像生成的內部輪廓圖像Fig.4 Interior contour images based on binary images
通過這2 個頂點可以得出外接矩形的頂點與長寬,繪制出輪廓的垂直邊界最小矩形,這個矩形與圖像上下邊界平行,保證了與手動標注矩形框在方向上的一致性,同時解決了由手動標注的隨機性導致的冗余背景、前景植株框定不完全等問題。
此外,本研究對自動生成的邊界框做優化處理:1)自動生成的邊界框(初始矩形框,如圖5a)中會有一些不包含植株的矩形區域(例如小面積雜草),這些信息是在顏色閾值分割后殘留的信息,因此在自動生成矩形時要設定矩形長與寬的閾值,使小于閾值的矩形框不被繪制;2)相鄰玉米植株葉片部分可能出現互相遮擋的情況,因此在生成輪廓點集時會有多株玉米被分在一個輪廓里,導致生成的邊界框包含多個玉米植株,影響分割效果。為此,本研究統計了全部自動生成矩形邊框的長、寬值,利用長、寬的均值作為邊界框大小的閾值,將長、寬值過大的矩形框進行均分,以保證一個邊界框只有一株玉米植株,處理結果如圖5b 所示。將自動生成的邊界框信息作為弱監督學習模型的標簽信息(偽標簽),由于標簽生成方過程中沒有人工標注,因此不產生人工成本,偽標簽及其可視化圖如圖5c 和5d 所示。

圖5 最小外接矩形和自動生成的邊界框標簽Fig.5 Smallest enclosed rectangle and automatic generated bounding box labels
2.3 弱監督圖像實例分割網絡及關鍵評價指標
以基于邊界框標注的弱監督實例分割模型(BoxInst[33])為基礎,增加標簽自生成模塊,對玉米植株RGB 圖像上的目標區域(植株)自動生成邊界框,替代構建訓練樣本中的人工標注過程。以全卷積的方式利用動態卷積濾波器在全圖上動態獲取每一個實例的掩膜,由于對每個實例都是在全圖尺度上的預測,因此可以更好地分割不規則的形狀,適用于大田環境下玉米苗期圖像的實例分割。而大田場景下的玉米苗期圖像背景復雜,需要對株型、葉片細節等部分的特征進行精確提取,雖然越深的網絡分類準確度越高,但考慮到本試驗的數據樣本類別單一,數據集相較于公開數據集(COCO)小很多,為了減少網絡過深造成的過擬合風險,因此選擇ResNet50 作為主干特征提取網絡,并采用雙向特征金字塔網絡(bidirectional feature pyramid network,BiFPN)作為特征提取網絡,BiFPN 能夠在不增加原有模型計算量的情況下在不同特征層進行加權以平衡不同尺度的特征信息,達到更高效的多尺度融合,其中高分辨率的特征保留空間位置信息,低分辨率的特征保留類別相關的抽象信息,能夠對目標進行準確分類并減少小目標的漏檢情況。
模型結構如圖6 所示,主要分為2 部分:第一部分利用全卷積網絡提取特征做逐像素回歸,根據共享檢測頭得出目標實例的類別和動態生成濾波器參數,其中分類分支(classification)預測每個像素的類別,控制器分支(controller)用于產生掩膜分支(mask branch)的網絡參數,該參數可在全局上對每個實例生成一個掩膜。
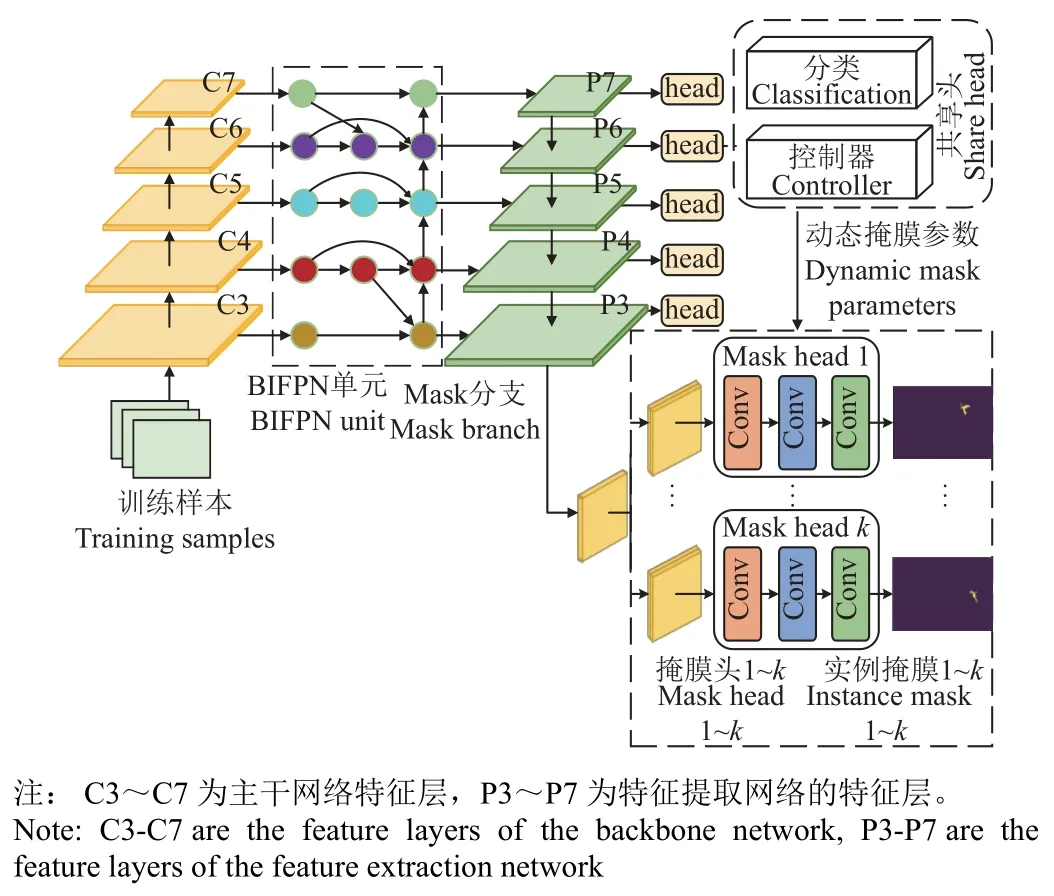
圖6 動態掩膜過程Fig.6 Dynamically mask process
第二部分為掩膜分支,根據第一部分檢測頭動態產生的掩膜參數,結合經過主干網絡特征提取后卷積生成的掩膜特征圖作為輸入,且由于每個實例都獨有對應掩膜分支,包含實例的形狀和大小等信息,所以當掩膜分支作用于全局掩膜特征圖上時,就可以區分當前實例和背景信息,從而預測出每一個實例的掩膜。圖6 中Mask head 有3 個1×1 卷積,每個卷積有8 個通道,采用ReLU函數作為激活函數,不使用歸一化層,最后一層有一個輸出通道,并使用Sigmoid 預測每個類別的概率。具體步驟如下:
1)原始圖像經過標簽自生成模塊得到用于網絡訓練的帶有邊界框掩膜的訓練樣本;
2)利用卷積神經網絡提取特征并在分類分支上實現分類和中心度檢測,過濾效果不好的檢測框;
3)利用動態卷積濾波器對多個實例動態生成多個不同的掩膜參數,結合經主干網絡特征提取再卷積生成的掩膜特征,區分當前實例和背景信息,從而預測出每一個實例的掩膜。
對于深度學習模型,網絡越深模型收斂所需要的訓練樣本數越多。為了避免樣本數量少導致模型普適性差的問題,采用公開數據集對模型進行預訓練,再將學習到的特征遷移到新的學習任務中。本文首先利用COCO公開數據集對主干網絡進行預訓練,將預訓練權重遷移到本文網絡模型中,將模型卷積層參數初始化,以提高卷積層的特征提取能力和泛化能力。采用隨機梯度下降進行網絡訓練,由于訓練中使用的GPU 顯存有限,而原始圖像的分辨率較高,因此設置較小的batch size,具體參數及其初始值為:圖像批量數為2,學習率 為0.01,訓練步數2 000,初始動量0.9。
在試驗中,為了保證模型評估的公平性,AutoLNet以及所有其他弱監督模型的訓練過程都使用自生成的邊界框標簽,有監督模型使用像素級人工掩膜標簽。
本文的分割任務是實現大田場景下的玉米苗期圖像實例分割,為了解決圖像像素不均衡問題,本研究采用的損失函數計算式為
式中Lfcos表示檢測頭產生的損失,Lmask表示實例分割的掩膜損失,通過權重 λ平衡兩個損失,Lcls表示分類損失,Lloc表示回歸損失,Lctr表示中心度損失,Lpro j表示投影損失,Lpairwise表示成對損失。
由于訓練模型使用自動生成的邊界框掩膜作為訓練樣本,需要驗證自動生成邊界框的精度。本文選取距離交并比DIoU作為評價指標,如式(2)所示,距離交并比不僅考慮2 個邊界框的交并比,同時考慮邊界框的距離、重疊率及尺度,可以更好地衡量自動生成邊界框的精度。
式中num表示樣本集合,k表示一個樣本中的實例個數,G代表真值標注圖像,A代表自動標注圖像,(G∩A)表示第i個樣本中第j個實例真值標注與自動生成邊界框的交集面積,(G∪A)表示第i個樣本中第j個實例真值標注與自動生成邊界框的并集面積,b代表邊界框的中心點,c為包含2 種邊界框的最小閉合區域的對角線距離, ρ代表兩點間的歐氏距離。
余弦相似度用向量空間中兩個向量夾角的余弦值衡量兩個個體間的差異大小,將圖像表示成一個向量,通過計算向量間的余弦距離表征兩張圖像的相似度,可以檢測二維空間中兩張圖像的相似度,用于不同分割方法生成的二值圖像與真值圖像的對比,其中前景像素值為1 (白色),背景像素值為0(黑色)。按照式(3)計算余弦值。
式中P代表預測生成的二值圖像,T代表真值圖像,表示第i個預測的分割圖像中第j個向量,表示第i個真值標簽圖像中的第j個向量,k表示每個圖像的像素點個數。
為了驗證網絡模型的圖像分割精度,本文采用的評價指標為平均精度(average precision,AP),如式(4)所示。
式中AP 的值為PR 曲線下的面積,p為精度,r為召回率,計算式如式(5)和式(6)所示。
式中TP 表示真正例,表示預測掩膜置信度大于置信度閾值且真實掩膜覆蓋度最高的像素集合;FP 為預測掩膜像素集合減去TP 像素集合;FN 為真值掩膜像素集合減去TP 像素集合。精度p代表被預測為正例的結果占真正例的比值,召回率r代表真樣本中被預測為正例的比值,AP 值越大,模型的性能越好。
3 結果與分析
3.1 自生成標簽質量評估
為了評估標簽自生成模塊得到的邊界框標簽質量,選取大津閾值分割、全局閾值分割和自適應閾值分割方法,分別用分割后的二值圖像以及生成的邊界框與真值進行對比。邊界框質量與分割產生的二值圖掩膜質量密切相關,根據2.2 節,使用式(3)獲得掩膜與真值間的余弦相似度,使用式(2)獲得掩膜對應的邊界框與真值標注的邊界框間的距離交并比。圖7 給出了相關分割方法得到的二值圖像及對應的邊界框信息與真值的對比情況。

圖7 不同分割方法的二值掩膜與邊界框標簽對比Fig.7 Comparison of binary masks and bounding box labels with different segmentation methods
如圖7 所示,標簽自生成模塊能夠生成與真值圖像基本一致的二值掩膜圖,并且由此得到的邊界框標簽也與真值有相同的空間分布。表3 給出了不同方法產生的掩膜及標簽與真值之間的余弦相似度與距離交并比。標簽自生成模塊對應的掩膜圖像與真值圖像的余弦相似度達到94.10%,自生成的邊界框與真值邊界框的距離交并比達到95.23%,2 個指標都遠高于其他方法。
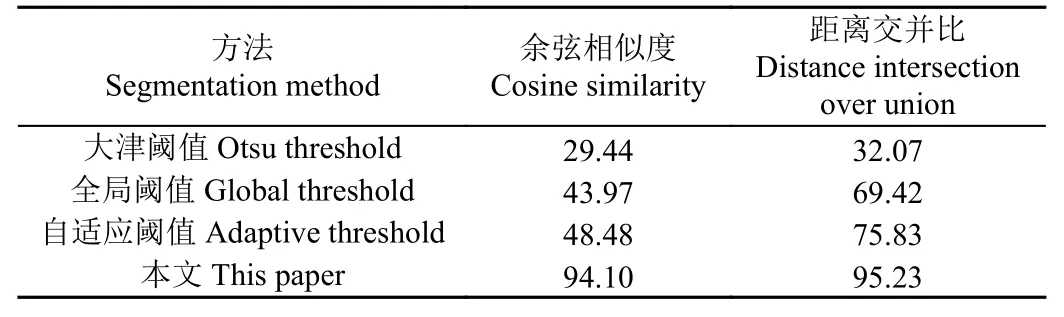
表3 自動標注與人工標注的標簽質量對比Table 3 Label quality comparison of automatic labeled with manual labeled (%)
標簽質量対比結果表明,標簽自生成模塊可以生成用于弱監督訓練的有效標簽,在無人工參與情況下能夠實現大田圖像的高質量自動標注,而高質量的標簽可以保證模型訓練過程的穩定性。如圖8 所示,在相同硬件平臺和網絡訓練參數條件下,分別使用自生成標簽與人工標簽進行訓練,兩種樣本的6 種訓練損失的變化趨勢基本一致,即具有相似的收斂趨勢,可見標簽自生成方法產生的邊界框標簽樣本完全可以代替真值標注進行模型訓練,能夠獲得與真值標注樣本相似的穩定性。
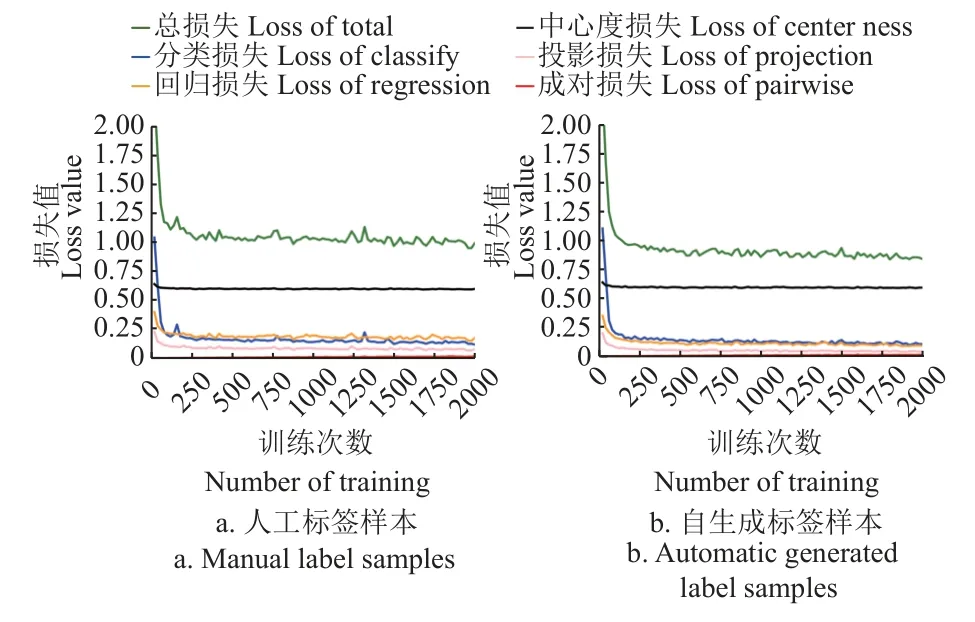
圖8 人工標簽與自動標簽樣本的訓練損失Fig.8 Training loss of manual label and automatic generated label samples
3.2 模型測試結果分析
選擇AP50~AP75、APL與AP 驗證網絡模型的實例分割精度(詳見表4)。在構建AutoLNet 模型時,分別選用4 種主干網絡進行測試。如表4 所示,使用自生成標簽為樣本進行訓練時,AutoLNet 模型使用ResNet50+BiFPN 主干網絡得到的預測框和掩膜精度最好,模型的AP 值分別為68.69%和35.07%,其中,模型在交并比閾值大于等于0.75 時(AP75),預測框精度為73.67%,掩膜精度為12.03%,當交并比閾值大于等于0.5 時(AP50),預測框精度達到96.39%,掩膜精度達到91.75%,表明隨著預測值與真值間交并比閾值的降低,AutoLNet 預測的平均精度隨之升高;主干網絡為ResNet50+BiFPN 時,由于BiFPN 可以引入學習權重學習不同輸入特征,并應用自頂向下和自底向上的多尺度融合方式進行特征提取,因此相較于ResNet50+FPN,其預測框和掩膜的平均精度提高了4.47 個百分點(其中ResNet50+BiFPN 的AP 值為68.69%,ResNet50+FPN 的AP 值為64.22%)和2.4 個百分點(其中ResNet50+BiFPN 的AP 值為35.07%,Res-Net50+FPN 的AP 值為32.67%);主干網絡為ResNet101+BiFPN 時,預測框和掩膜精度的AP 值分別下降了2.63(其中ResNet50+BiFPN 的AP 值為68.69%,ResNet101+BiFPN 的AP 值66.06%)和6.51 個百分點(其中ResNet50+BiFPN 的AP 值為35.07%,ResNet101+BiFPN 的AP 值28.56%),AP 值并未隨主干網絡的加深而提高,這是由于本試驗樣本數據僅有1 類,且樣本總體數量不及公開數據集,在僅使用邊界框標注進行訓練時,網絡深度的增加反而會導致某些淺層的學習能力下降,限制深層網絡的學習,從而降低特征提取能力。另外, AutoLNet 模型在交并比超過70%后的掩膜精度降幅明顯,而預測框精度降幅穩定,其原因是AutoLNet 模型以邊界框為監督,通過網絡學習的像素級細節不如有監督模型,當交并比閾值較高時,預測的掩膜精度通常不如預測框精度,易出現較大幅度下降。
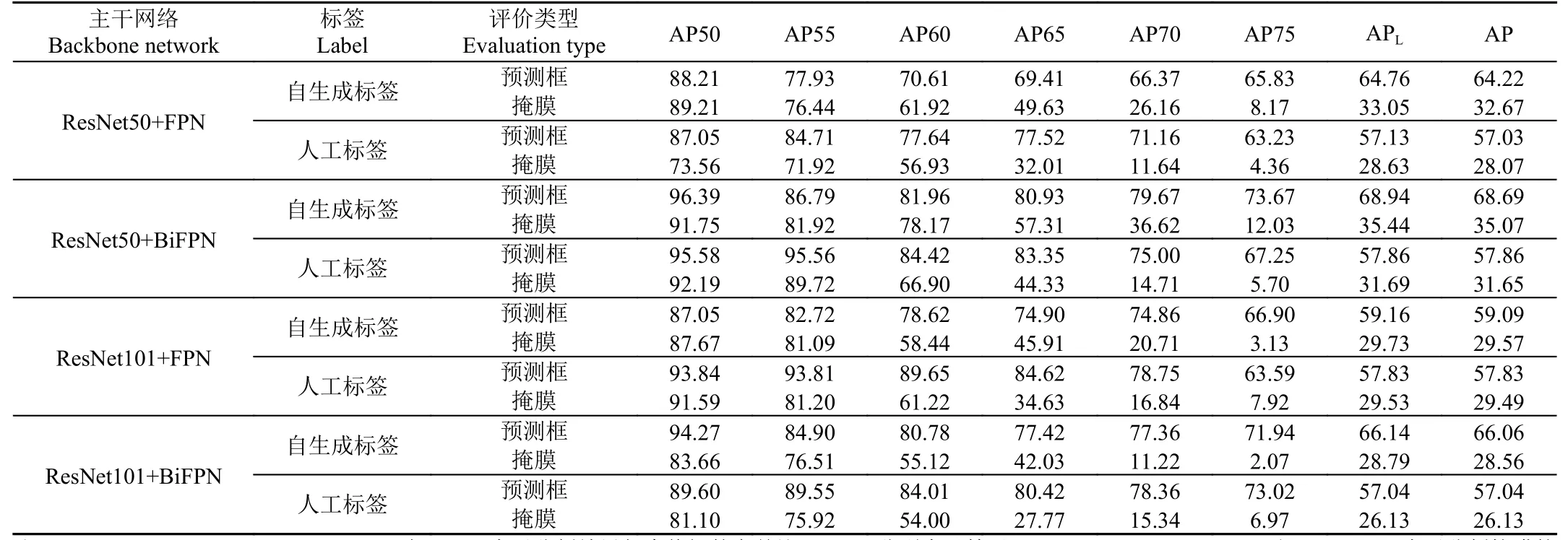
表4 AutoLNet 模型在不同主干網絡下的平均精度Table 4 Average precision of AutoLNet under different backbone network(%)
由表4 可知,自生成標簽與人工標簽皆在主干網絡為ResNet50+BiFPN 時有最好的精度表現,且自生成標簽在預測框與掩膜的平均精度(AP)分別高出人工標簽10.83(其中ResNet50+BiFPN 的自生成標簽AP 值為68.69%,人工標簽AP 值為57.86%)與3.42 個百分點(其中ResNet50+BiFPN 的自生成標簽AP 值為35.07%,人工標簽AP 值為31.65%),這是因為相較于人工標簽,自生成標簽能夠對目標實例的邊界進行更精準的定位,極大地減少了人工標注的隨機性與不確定性,使更精準的前景信息被模型網絡學習,從而獲得更高的精度。
為比較AutoLNet 模型與其他基于邊界框標簽的弱監督實例分割模型的平均精度,本試驗選取2 個較為成熟的弱監督模型DiscoBox 和Box2Mask 進行對比。為保證公平性,DiscoBox 和Box2Mask 使用與AutoLNet相同的人工標簽作為訓練樣本。由表5 可知,AutoLNet模型對應的預測框平均精度和掩膜平均精度都高于DiscoBox 和Box2Mask 模型。在全局平均精度(AP)方面,AutoLNet 預測框精度比DiscoBox 模型高11.28個百分點(其中AutoLNet 的AP 值為68.69%, DiscoBox的AP 值為57.41%),比Box2Mask 模型高8.79 個百分點(其中AutoLNet 的AP 值為68.69%,Box2Mask 的AP 值為59.90%);而掩膜精度方面,AutoLNet 比DiscoBox 模型高12.75 個百分點(其中AutoLNet 的AP 值為35.07%,DiscoBox 的AP 值為22.32%),比Box2Mask 模型高10.72 個百分點(其中AutoLNet 的AP 值為35.07%,Box2Mask 的AP 值為24.35%)。可以證明,AutoLNet 的網絡結構在全圖的掩膜特征中動態地為每一個實例生成一個掩膜的分割方式,在實現基于邊界框標注的弱監督實例分割方面是有效的,能夠以更高的精度完成大田環境下玉米苗期圖像的實例分割。
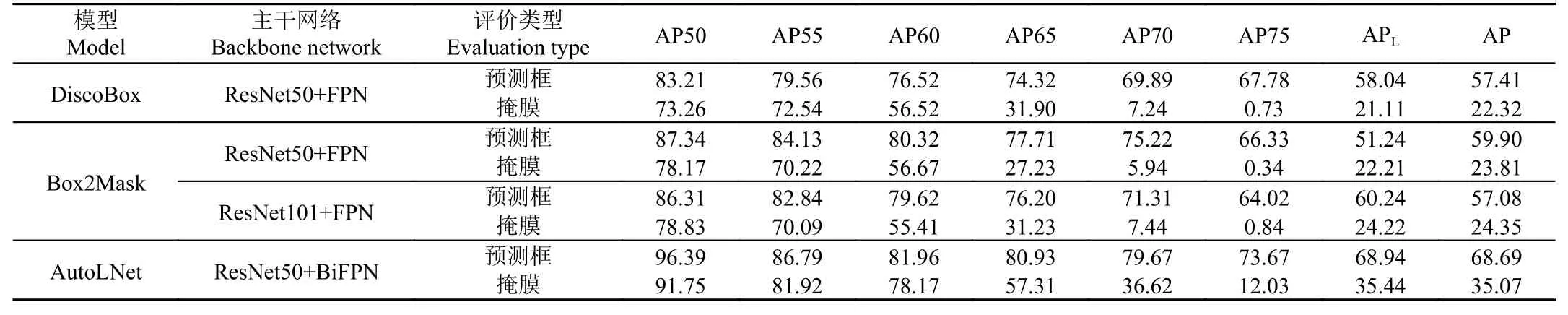
表5 AutoLNet 與弱監督模型(DiscoBox 和Box2Mask)的平均精度對比Table 5 Comparison of average precision between AutoLNet and weak supervised models (DiscoBox and Box2Mask)(%)
為了比較AutoLNet 模型在圖像實例分割精度上與全監督模型的差別,本文選擇全監督模型CondInst 和Mask R-CNN 與AutoLNet 進行對比。如表6 所示,與CondInst模型對比,AutoLNet 模型的預測框與掩膜精度略低于主干網絡為ResNet101+BiFPN 的CondInst 模型,分別達到CondInst 模型的94.32%和83.14%,全局平均精度(AP)分別相差4.14(其中CondInst 的AP 值為72.83%,AutoLNet 的AP 值為68.69%)和7.11 個百分點(其中CondInst 的 AP 值為 42.18%, AutoLNet 的 AP 值為35.07%),接近于主干網絡為ResNet50+FPN 的CondInst模型,掩膜的AP 值低3.84 個百分點(其中CondInst 的AP 值為38.91%,AutoLNet 的AP 值為35.07%),而預測框的AP 值則高出4.76 個百分點(其中AutoLNet 的AP 值為68.69%,CondInst 的AP 值為63.93%),尤其在交并比閾值大于等于0.5 時(AP50),AutoLNet 模型的預測框精度與掩膜精度高于CondInst 模型2.08(其中AutoLNet 的AP50 值為96.39%,CondInst 的AP50 值為94.31%)和3.81 個百分點(其中AutoLNet 的AP50 值為91.75%,CondInst 的AP50 值為87.94%),說明交并比閾值要求較低時,AutoLNet 模型優于CondInst 模型;與Mask R-CNN 模型對比,在預測框精度與掩膜精度上AutoLNet 模型皆優于Mask R-CNN 模型,相較于基于ResNet101+FPN 主干網絡的Mask R-CNN 模型,AutoLNet在全局平均精度(AP)上高出7.54(其中AutoLNet 的AP 值為68.69%,Mask R-CNN 的AP 值為61.15%)和3.28 個百分點(其中AutoLNet 的AP 值為35.07%,Mask R-CNN 的AP 值為31.79%)。結果表明,在玉米苗期圖像實例分割任務中,AutoLNet 模型的分割精度接近全監督模型CondInst,且優于Mask R-CNN 模型,原因是AutoLNet 模型雖然以邊界框為監督,但在自生成邊界框時利用圖像的紋理、色彩等基本特征對目標實例生成了最小包圍邊界框,能夠去除多余背景信息對模型學習效果的影響,因此AutoLNet 模型能夠達到接近于全監督的實例分割效果。

表6 AutoLNet 與全監督模型(CondInst 和Mask R-CNN)的平均精度對比Table 6 Comparison of average precision between AutoLNet and fully supervised models(CondInst and Mask R-CNN)(%)
圖9 為AutoLNet 與全監督實例分割模型CondInst和Mask R-CNN 的分割效果對比。從圖中可以看出,對于大田環境下無人機拍攝的玉米苗期圖像,AutoLNet 與全監督模型的分割結果非常接近。AutoLNet 的標簽自生成模塊能夠替代樣本標簽的人工標注過程,降低了人工時間成本,并能準確分割小目標的苗期玉米植株,去除圖像中由于光照產生的植株影子,避免影響對玉米植株的分割,達到無需標注的高精度實例分割。

圖9 不同模型的分割效果對比Fig.9 Comparison of segmentation effects of different models
4 結 論
本研究設計了一種基于自生成標簽的弱監督實例分割模型AutoLNet,利用大田場景下玉米苗期圖像的色彩信息自生成邊界框標簽作為弱監督訓練樣本,最終實現AutoLNet 模型的訓練。本文研究主要得到以下結論:
1)所設計標簽自生成模塊利用顏色空間轉換、輪廓跟蹤和最小外接矩形在玉米苗期圖像中自動生成目標前景的邊界框(自生成標簽),通過自生成標簽代替弱監督模型中的人工標簽,其標簽精度達到95.23%。
2)設計了基于自生成邊界框標簽的弱監督學習模型,在弱監督模型的基礎上優化了主干網絡,利用ResNet-50+BiFPN 提高特征提取能力,以動態卷積濾波器在全圖上動態地為每一個實例生成一個掩膜,在基于邊界框標簽的弱監督模型中對形態結構復雜的玉米苗期圖像實現高精度實例分割,在主干網絡為ResNet50+BiFPN 的AutoLNet 模型中,自生成標簽相較于人工標簽在預測框與掩膜的平均精度上分別高出10.83 和3.42 個百分點;與DiscoBox 和Box2Mask 弱監督模型相比,AutoLNet的預測框精度分別高11.28 和8.79 個百分點,掩膜精度分別高12.75 和10.72 個百分點。
3)在玉米苗期圖像實例分割任務中,AutoLNet 與全監督模型的分割效果相似。AutoLNet 可以在訓練中通過降低投影損失與成對損失實現弱監督學習精度的提高,在模型表現最好的主干網絡下,AutoLNet 的預測框與掩膜精度可以達到 CondInst 模型的94.32%(其中AutoLNet的AP 值為68.69%,CondInst 的AP 值為72.83%)與83.14%(其中AutoLNet 的AP 值為35.07%,CondInst 的AP 值為42.18%);而對比Mask R-CNN 模型,AutoLNet的預測框精度高7.54 個百分點,掩膜精度高3.28 個百分點。
綜上所述,針對無人機玉米苗期圖像(頂視圖)的實例分割任務,AutoLNet 模型可以在無人工標簽的條件下實現高精度實例分割。與同樣基于邊界框標簽的弱監督模型(DiscoBox 和Box2Mask)相比,AutoLNet 模型得到的掩膜精度和預測框精度都高于DiscoBox 和Box2Mask。而在交并比閾值大于等于0.5 的前提下,AutoLNet 的分割效果要優于全監督模型Mask R-CNN,且與CondInst 接近。因此,利用AutoLNet 可以實現在大田環境下玉米苗期圖像的實例分割,模型利用標簽自生成模塊代替手動標注過程,節省了大量的人工標注成本,可為大田環境下的玉米苗期圖像實例分割任務提供解決方案和技術支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
浙江人大(2014年5期)2014-03-20 16:20:28
浙江人大(2014年4期)2014-03-20 16:20:16
