
基于既有醫療數據構建研究型數據庫的方法學探討及實例解讀(一):變量清單和數據庫架構的確定
2023-08-23 10:39:10趙國楨閆世艷郭玉紅宋爽胡雅慧郭詩琪徐霄龍葉浩然朱泠霏杜元任志穎盧海天胡晶李博劉清泉
中國中醫藥信息雜志 2023年8期
趙國楨 ,閆世艷 ,郭玉紅 宋爽 ,胡雅慧 ,郭詩琪 ,徐霄龍 葉浩然 朱泠霏 杜元 任志穎 ,盧海天 胡晶 李博 劉清泉
1.首都醫科大學附屬北京中醫醫院,北京市中醫藥研究所,北京 100010;2.北京中醫藥循證醫學中心,北京 100010;3.北京中醫藥大學,北京 100029;4.天津中醫藥大學,天津 301617
既有醫療數據是真實世界數據(real-world data,RWD)的重要組成部分,而基于RWD開展的真實世界研究(real-world study,RWS)所產生的真實世界證據(real-world evidence,RWE),對醫療衛生決策產生重要影響[1]。與西藥新藥開發模式不同,中藥新藥在開發前往往已經具有大量臨床人用經驗,積累了較豐富的醫療數據,為RWE的產生提供了有力保障[2]。國家藥品監督管理局發布的《真實世界證據支持藥物研發與審評的指導原則(試行)》指出,RWE可以支持藥物監管決策,包括為新藥注冊上市提供有效性和安全性證據、為已上市藥物的說明書變更提供證據、為人用經驗總結和臨床研發提供證據支持等[3]。此外,國務院辦公廳發布的《關于加快中醫藥特色發展的若干政策措施》,要求充分利用數據科學等現代技術手段,建立中醫藥理論、人用經驗、臨床試驗“三結合”的中藥注冊審評證據體系,積極探索建立中藥真實世界研究證據體系[4]。目前,國內已發表多篇相關技術規范,指導從既有醫療數據到RWE,其關鍵點之一在于研究型數據庫的建設[5-6]。然而,因RWD來源廣、容量大、中醫藥數據復雜等特點,數據庫建設的具體實施過程仍面臨挑戰。
本文以“中西醫結合治療新型冠狀病毒感染研究型數據庫”為例,對基于既有醫療數據構建研究型數據庫中變量清單及數據庫架構的確定方法進行介紹。本研究已獲得首都醫科大學附屬北京中醫醫院醫學倫理委員會批準(2022-BL02-033-01),并且在中國臨床研究注冊中心注冊(ChiCTR2200062917)[7]。
1 相關概念和總體設計
既有醫療數據屬于回顧性資料,其特點是未針對特定的研究目的而收集[8]。因此,從既有醫療數據,到可直接用于統計分析的分析數據庫,仍需要一定的數據處理過程。不同的RWS對數據的處理方法存在一定差異,但其中共有的且必要的一步是建立研究型數據庫。研究型數據庫可基于既有醫療數據形成,但又不同于既有醫療數據,兩者的主要區別見表1。本課題中研究型數據庫的構建可分為2個階段:①確定變量清單及數據庫架構;②數據治理。本文重點對變量清單及數據庫架構的確定方法進行論述及實例解讀。

表1 研究型數據庫與既有醫療數據的主要區別
2 確定變量清單
2.1 明確臨床問題及研究目的
研究目的來源于臨床問題。明確研究目的,是開展各類型研究的首要步驟。本研究主要待解決的臨床問題有2 個:①中醫藥治療新型冠狀病毒感染(Coronavirus Disease 2019,COVID-19)的有效性和安全性如何?②哪些具體的中醫治療措施可以有效且安全地用于COVID-19的治療?
基于以上2 個臨床問題,確定研究目的如下:①對中醫藥治療COVID-19的總體療效及安全性進行評價;②對清肺排毒湯、化濕敗毒方、連花清瘟膠囊等中醫治療COVID-19 具體措施的療效及安全性進行評價。
2.2 臨床問題解構
為更好地確定研究所需變量,需基于研究目的,按照循證醫學的“PICO原則”對臨床問題進行解構。臨床問題解構是確定變量清單的核心步驟。本研究以對中醫藥總體的療效評價為例,對臨床問題解構示例見表2。

表2 對中醫藥總體療效評價的臨床問題及解構示例
2.3 變量分類及確定
完成研究所需要的變量,稱為關鍵變量[5]。根據臨床問題解構結果,可確定本研究的關鍵變量。關鍵變量主要分為四類:①與研究對象(納排標準)相關的變量;②與研究治療措施/暴露因素相關的變量;③與結局指標相關的變量;④與混雜因素[9]相關的變量。不同類別的變量需存儲在不同的數據集或數據模塊中,各數據集或數據模塊需通過鏈接變量[6]相連。關鍵變量需要根據循證醫學證據、專家臨床經驗和既有數據情況共同確定。
以上述臨床問題解構中的“西醫常規治療”為例。為存儲患者住院期間接受西醫治療情況的相關數據,設立西醫治療數據集,該數據集中的變量在本研究中屬于與混雜因素相關的變量。根據COVID-19指南及診療方案推薦[10],西醫治療包括:阿比多爾、α-干擾素、利巴韋林等抗病毒治療;人免疫球蛋白、康復者恢復期血漿等免疫治療;糖皮質激素治療;呼吸支持及其他治療。根據專家討論,補充奧司他韋、洛匹那韋利托那韋2種抗病毒藥物;根據既有數據情況,去除恢復期血漿治療。確定本研究所需的西醫治療措施后,將各項措施的天數及有無作為變量,列入西醫治療變量集的變量清單。同時,該變量集還包含鏈接變量及其他相關變量。
2.4 衍生變量計算
研究所需要的部分變量,不能從既有數據中直接提取,而是需要通過數據轉換計算而得,這類變量稱為衍生變量[11]。衍生變量的計算需要基于一定規則。例如在上述西醫治療數據集中,課題組僅可從既有數據中提取各患者各藥物的使用天數,但是否可以認為該患者使用了該藥物,則需要基于天數來計算。若阿比多爾使用天數≥3 d,可認為患者使用了該藥物,以“1”表示,否則以“0”表示。其中,“阿比多爾使用天數”就是原變量,而“是否使用阿比多爾”則是衍生變量。
3 評估既有數據
在使用既有醫療數據前,需先評估既有數據能否為待建數據庫提供可靠的數據,包括數據的準確性、完整性、數據覆蓋日期跨度、研究人群代表性、樣本量等。若存在數據質量問題,最好是對數據進行溯源。在評估期間,還需了解既有數據的數據庫結構及變量清單,并與待建數據庫所需的變量清單比對,重點關注以下問題:①既有數據能否為待建數據庫各變量提供可靠數據支持;②待建數據庫的變量在既有數據中的來源是否單一;③若數據多源,還需對比不同來源數據的質量,建立重復/矛盾數據優先級。
以本研究中基本信息數據集的“入院日期”變量為例。在評估既有數據中與入院日期有關的變量時,發現共有4個數據來源:入院記錄、出院記錄、死亡記錄、病案首頁中的入院日期變量。此外,還有2個衍生變量可為入院日期的確定提供參考:首次病程記錄日期、首次醫囑日期。經數據質量評價,以上6個變量均有較好的可靠性。因此,“入院日期”會根據4個不同來源的變量進行數據提取,并根據2個衍生變量進行數據核查。
4 明確數據集結構
4.1 數據庫及數據集的概念
數據集是各數據的集合,通常以表格形式出現,每列代表一個特定變量,每行對應某一患者的具體數據內容[12]。由于一個研究型數據庫涉及的變量數極多,通常會根據數據結構及數據內容將其拆分成不同的數據模塊,存儲進不同的數據集中。根據數據結構類型,數據集可分為橫斷面數據、時間序列數據和縱向數據3種結構。各數據集間通過鏈接變量相互連接。在研究型數據庫建立完成后,若需要進行統計分析,則可從各數據集中提取相關的變量數據,建立分析數據庫,開展統計分析工作。
本研究根據數據結構及數據內容,將變量清單中的變量分別存儲于15個數據集。各數據集名稱、數據結構類型及介紹見表3。
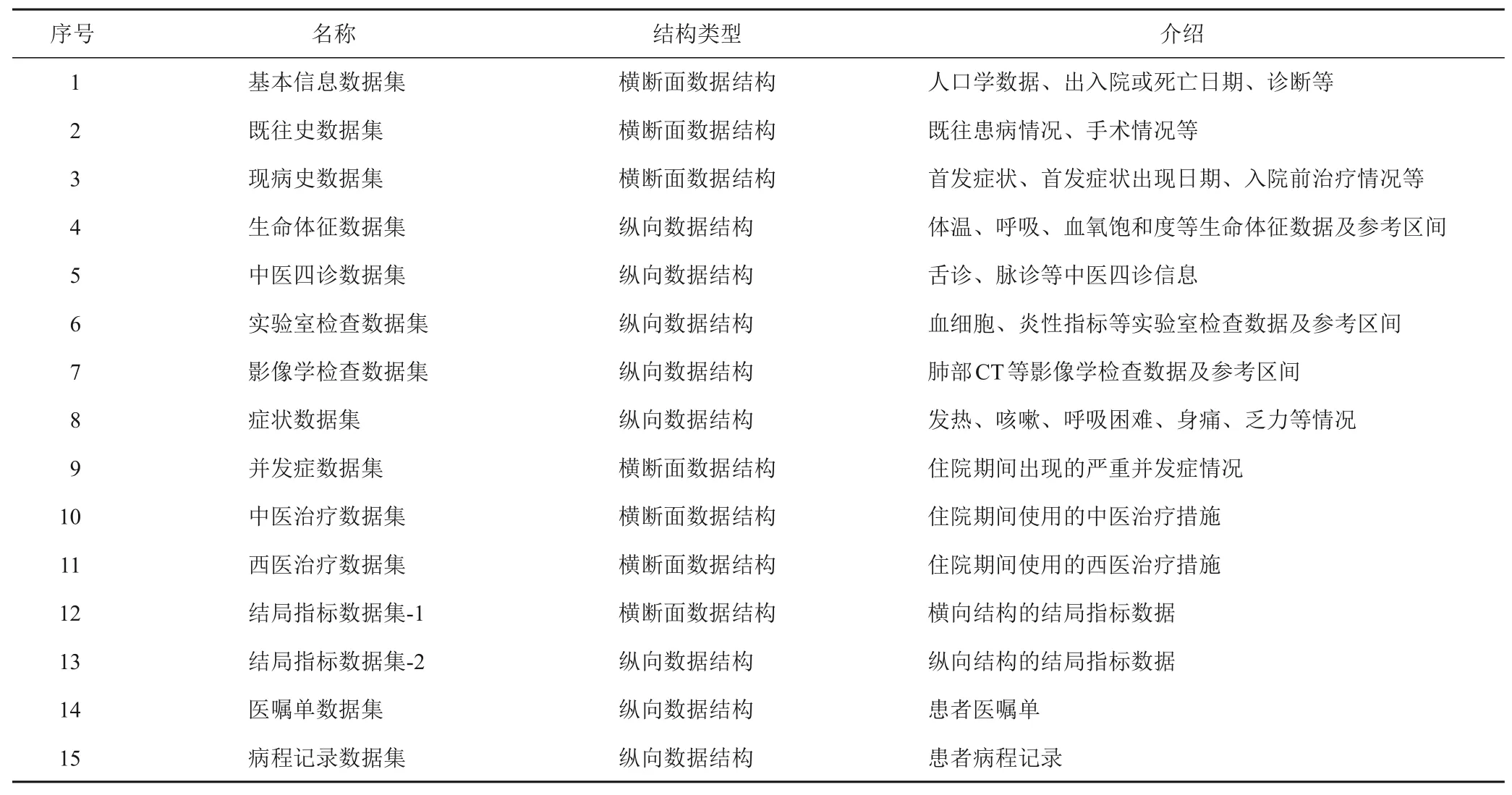
表3 中西醫結合治療COVID-19研究型數據庫數據集
4.2 橫斷面數據結構
橫斷面數據(cross-sectional data)是指在同一時間收集的不同對象的數據[13]。雖然在定義上要求同一時間,但實際上不同的數據采集時間會存在一定的時間差異,但這種差異可以忽略,具體判斷標準是時間上的差異不足以改變所獲取變量的性質。橫斷面數據結構是研究型數據庫的常見結構之一。
本研究中,基本信息數據集就是橫斷面數據結構。其每行代表1名患者,不同行代表不同患者,且患者間無重復;其每列代表1個變量,如性別、年齡、民族、身高、體質量等。橫斷面數據結構示例見表4。
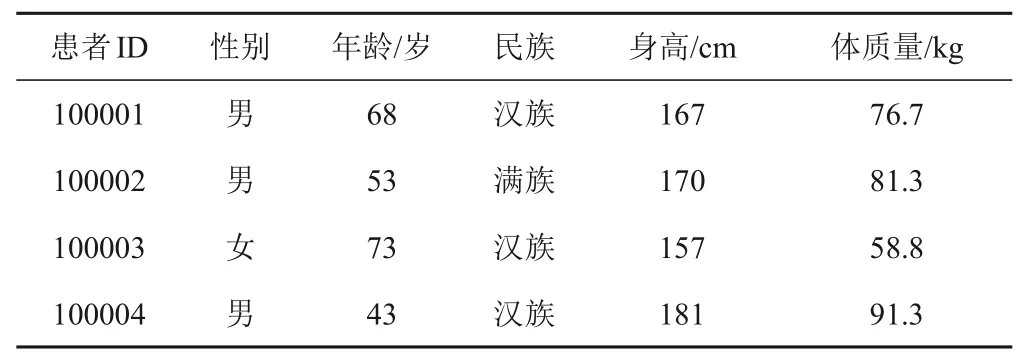
表4 橫斷面數據結構示例
4.3 時間序列數據結構
時間序列數據(time-series data)是指對同一對象在不同時間連續觀察所取得的數據,重點反映該對象在時間順序上的不同變化[13]。但研究型數據庫通常涉及多個研究對象,很少會使用時間序列數據結構。
4.4 縱向數據結構
縱向數據(longitudinal data)也稱作面板數據(panel data)或合并數據(pooled data),指不同對象在不同時間連續觀察所得到的數據[14]。縱向數據既可以體現不同研究對象間的差異情況,又可描述同一研究對象的動態變化特征。縱向數據結構是橫斷面數據和時間序列數據相結合的一種數據結構,是研究型數據庫的另一種常見結構,其與橫斷面數據結構相比,特點在于引入時間維度。本研究中,生命體征數據集是縱向數據結構。患者的生命體征始終處于動態變化中,因此需動態記錄每名患者每日的生命體征數據。該數據集中,每名患者每日的數據占一行,不同行代表的患者存在重復;每列仍代表對應的變量,如體溫、呼吸頻率、心率、收縮壓、舒張壓、血氧飽和度等。縱向數據結構示例見表5。
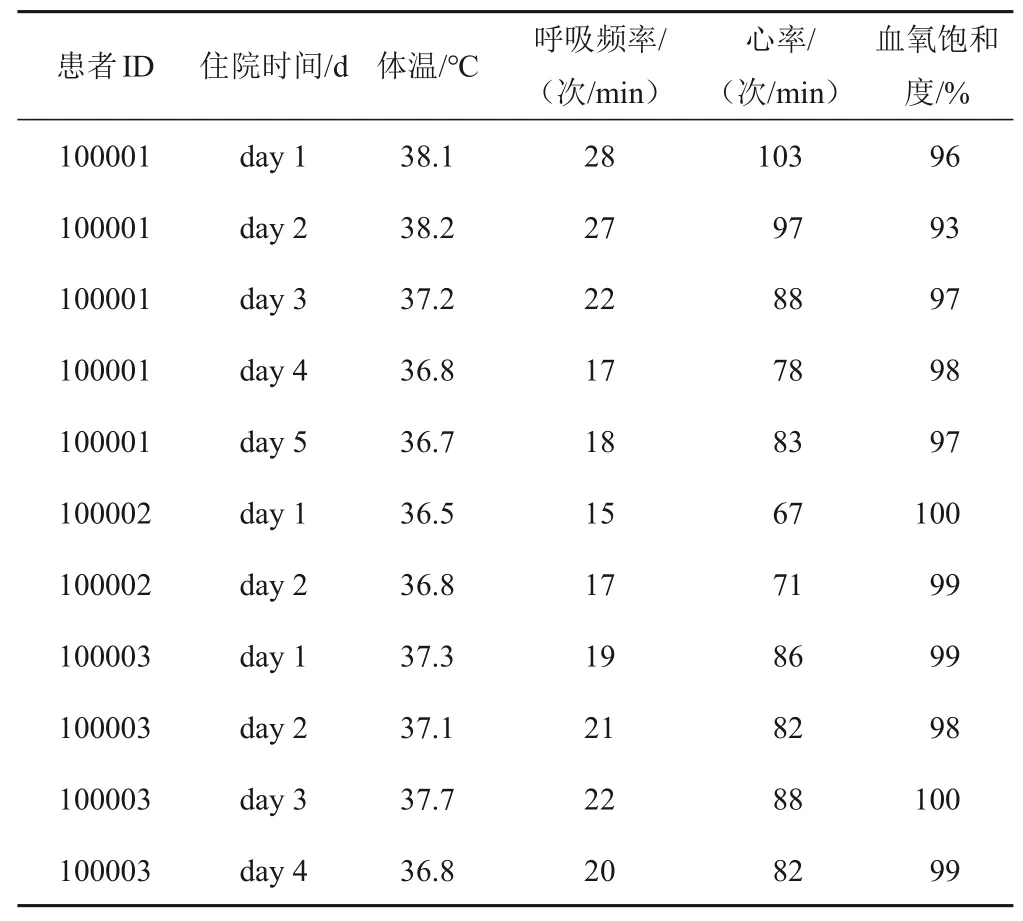
表5 縱向數據結構示例
5 制定變量字典
研究型數據庫通常包含眾多變量,不同變量有不同的名稱和含義,以及不同的變量類型、變量來源等,因此需要一種數據模型以實現對眾多變量的管理。變量字典即是滿足這一需求的數據模型[6]。數據庫中每個變量的信息都須記錄在變量字典中。一個制定良好的變量字典,不僅可供數據庫建立者回顧,更可為其他研究者快速熟悉數據庫提供幫助。變量字典應包含但不限于:變量名稱、變量含義、變量類型、變量編碼、數據來源、衍生規則和數據采集方式。變量字典的制定將伴隨數據庫建庫的整個階段,期間對數據庫格式結構、變量的任何調整,均應及時更新在變量字典中。中醫治療數據集的變量字典部分示例見表6,其中方名分類方法[15]、各衍生變量的衍生規則,需根據循證醫學證據、專家臨床經驗和既有數據情況綜合確定。

表6 中醫治療數據集變量字典示例
6 討論
根據臨床問題及研究目的確定變量清單及數據庫架構,是建立研究型數據庫和開展數據治理的前提基礎[16]。其關鍵點可概括如下:①準確提出并解構臨床問題,根據解構結果確定關鍵變量;②對既有數據的可靠性及關鍵變量的數據來源進行評估;③根據各數據集特點,選擇恰當的數據結構;④制定變量字典,實現對各變量的良好管理。
RWS為中醫藥療效及安全性、預后、衛生經濟學、病因、診斷和臨床預測等臨床問題的研究提供了思路和方法[17]。中醫藥整體觀念、辨證論治的特點,使中醫藥RWS面臨挑戰。例如,在中醫藥療效評價研究中,混雜因素的選擇和測量更為復雜。除西醫RWS中通常考慮的混雜因素外,患者的中醫體質、舌脈都可能是影響治療和結局的混雜因素。但這些混雜因素數據存在稀疏性,即全部患者可能出現的中醫表型種類極多[18],而單個患者出現的表型種類較少;并且這些混雜因素通常缺少公認的、客觀的測量方法。盡管已有數據挖掘技術及統計分析技術可對數據進行降維處理,或使用舌診儀、脈診儀等智能設備對患者舌脈進行客觀化測量,但相關處理方法和測量方法仍存在局限性,且未得到公認。這些問題需要研究人員在今后的RWS及方法學研究中進一步探索。
本文以“中西醫結合治療新型冠狀病毒感染研究型數據庫”為例,對基于既有醫療數據建立研究型數據庫中變量清單及數據庫架構的確定方法及關鍵點進行介紹,可供基于既有數據建立研究型數據庫的研究人員參考。其中數據庫及數據集的基本結構、變量字典的制定方法,也可供開展前瞻性RWS的研究人員借鑒。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
現代臨床醫學(2021年3期)2021-07-16 07:36:44
中國民間療法(2021年5期)2021-06-09 09:21:42
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
知識經濟·中國直銷(2017年7期)2017-07-24 14:12:41
財經(2017年2期)2017-03-10 14:35:35
中國衛生(2016年11期)2016-11-12 13:29:24
財經(2016年15期)2016-06-03 07:38:02
