基于字詞特征融合的中文地址匹配算法
2023-08-26 03:08:11陳劍
電腦知識與技術 2023年19期
陳劍
關鍵詞:地址匹配;深度學習;特征融合
0 引言
地址是描述某種具體空間位置的文本標識,具有重要的地理信息價值。中文地名的匹配和解析是進行中文地址標準化和規范化的基礎[1]。但中文地址具有來源多樣性和描述差異化的特點,在智慧城市建設和大數據背景條件下,如何提高地址匹配的準確率和有效率是開展后續任務的關鍵因素。當前對中文地址匹配的研究主要包含以下三塊內容[2-4]:一種是基于規則的地址匹配方法,這種方法分為兩個階段,第一階段是通過比較兩個地址字符串的相似程度,進而判斷是否為同一地址,此類方法不需要對地址進行解析,沒有考慮到地址的語義信息,匹配準確率較低;第二階段是基于地址要素的地址匹配方法,該方法是根據地址要素特征詞進行中文地址的提取,進而實現對地址要素的匹配,但基于地址要素匹配的方法對非標準地址或者復雜地址難以有效解析和提取,適應性較差;另外一種是基于統計和機器學習的方法,該方法是通過大規模語料庫獲取地名匹配的統計模型,其在考慮地名短語的詞法信息之外,結合了在句子上下文信息,可以在一定程度上解決語義歧義問題;最后一種是基于深度學習的方法,通過挖掘數據中潛在的規律特征實現對地址匹配的目的[5-8]。
顯然基于規則和統計的方法有一定的局限性,匹配準確度低,依賴標準地址庫的構建。對錯亂和缺失的地址無法有效處理,缺乏對地址語義的理解,不能有效地提取地址的語義信息。基于神經網絡的方法能有效解決語義信息的缺失,和對于地址要素之間的各類差異的效果欠佳問題,但對于這類模型來說,如何有效融合全局與局部范圍的上下文信息是一個重要的問題。本文通過分析中文地址結構的特點,提出一種基于字、詞特征融合的中文地址匹配方法,該方法不依賴于地址特征庫,從地址語義理解的角度出發,實現對中文地址的精準匹配。
1 模型結構
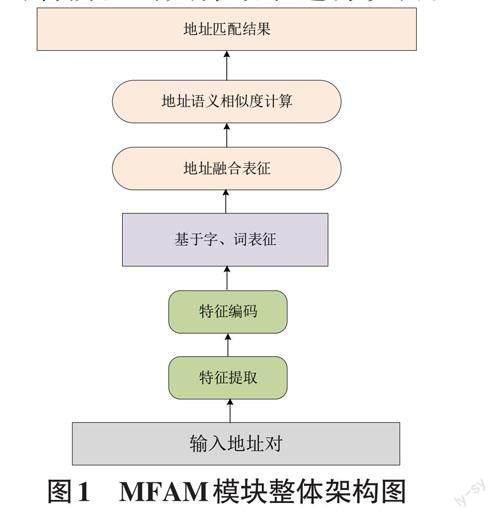
中文地址包含地址要素、詞性和句法三大類特征。中文地址的最小語義單元是地址要素,一個中文地址通常是由多個要素構成,每個地址要素屬于地名實體中的一個獨立部分。地址要素由普通字符與特征字構成,其中特征字更能體現地址要素間的本質區別,并反映出地址的真實語義與位置信息。中文地址要素包含多個層級,將中文地址要素劃分多個層級。如省、直轄市為第一層級,省會、地級市為第二層級,區、縣為第三層級,街道、鄉鎮為第四層級,以街道、鄉鎮為例,可能包含對應地址要素特征集合為:鎮、鄉、辦事處、居委會、社區、街道。因此,特征字是區分地址要素、劃分地址層級的標志。在本節中,筆者根據中文地址結構的特點,提出一種基于字、詞以及地址特征融合的深度學習網絡架構模型。該架構的第一個重要組件負責將字、詞標記及其特征轉換為向量表示,然后將得到的句子進行融合向量表示獲取地址語義信息,最后根據地址語義相似度實現地址的匹配。
1.1 主要模塊
本文提出一種基于字詞特征融合的中文地址匹配模型,根據中文地址的特點,融合中文地址的字、詞屬性,建立字詞特征融合的中文地址語義匹配模型。具體來說,地址語義匹配模型分為三個階段:第一階段為字符嵌入表征,通過融入字符的局部和全局特征,將地址字符信息轉變為向量表達。第二階段為詞嵌入表征,通過獲取地址文本中詞的前向和后向的上下文依賴關系,挖掘基于詞的地址語義信息,并且基于地址特征字的關系屬性,聯合地址要素綜合得到地址語義表征。第三階段為地址的匹配,通過使用地址語義相似度算法,根據設定閾值判斷地址是否相似。
地址語義匹配模型接受地址輸入,并分別基于字、詞生成地址的語義向量表示,接著通過字詞特征融合表征地址語義,最后使用地址語義相似度算法實現地址匹配。模型整體構造如圖1所示。MFAM模型整體分為編碼模塊、語義表征模塊、相似度計算模塊組成,下文對各階段的具體細節進行說明。
1.2 地址語義表征
本文采用結合字詞特征融合的地址語義表征。具體來說,首先從輸入句子中獲取基于字符嵌入向量表示,并通過卷積網絡實現最大時間離散化,生成的基于字符的標記序列表示被傳遞Bi-LSTM的輸入層;其次,輸入序列通過分詞和預訓練語言模型進行詞向量表征,并連接到詞嵌入層。
1) 基于字符表征
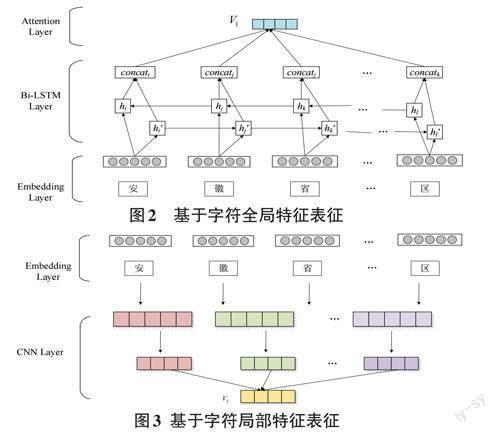
1) 基于字符表征本文將中文地址中的漢字字符特征作為一個特征輸入,分別從全局和局部的角度學習語義信息。具體來說,首先使用BiLSTM對輸入字符進行雙向語義表征學習,然后使用自注意力機制有效獲取任意兩個字符之間的關系,獲取字符全局信息。接著使用卷積神經網絡對字符進行特征提取,基于最大池化的方法獲取主要信息,獲取字符的局部特征。基于字符全局特征表征結構如圖2所示。
對于在t 時刻的地址字符wt',首先采用預訓練語言模型BERT將其轉換為字符嵌入形式wt,BERT模型采用了雙向Transformer語義模型,可以充分獲取字詞的上下文信息,接著將字符的嵌入表征輸入BiLSTM 網絡,獲取字符表征輸出為ht = [ ht ; ht ],其中ht 和ht分別表示BiLSTM網絡的前向和后向的輸出。BiL? STM是一種改進的循環神經網絡模型,通過引入門結構可以有選擇地保存上下文信息,對于長距離信息進行有效利用,可以有效克服梯度爆炸問題。在BiL? STM網絡的輸出結果之上,采用自注意力機制捕獲任意兩個字符之間的關系,相關計算公式如下所示:
其中,ct 是上下文向量,wa,wb,wc 是權重矩陣,χ 是隨機初始化的參數向量。
基于字符局部特征表征結構如圖3所示。
使用卷積神經網絡提取字符的局部特征,并且疊加最大池化操作從學到的特征中保留最主要的特征。對于一個輸入字符,采用CNN進行特征提取,相關公式如下所示:
2)基于詞表征
本文在使用字符級特征基礎之上,采用詞級別特征,引入基于字詞編碼的方法,充分利用詞的邊界和語義信息。將模型的字符和詞的信息編碼成聯合表示。具體地,該方法為每個字符分配B、M、E和S共4 個標簽,其中B表示當前字開頭的潛在詞集合,M表示中間包含當前詞的集合,E表示當前字結尾的潛在詞集合,S表示當前字本身。
為每個詞定義一個集合,集合包含了該詞以及該詞對應的B、M、E和S的集合,并使用基于詞頻計算的權重加權方式求和多個詞向量,最后拼接當前字的向量表示及其對應的B、M、E和S的集合的向量表示作為字詞信息的聯合表示,用作模型的最終輸入:
1.3 特征融合
對于已獲取的字符級特征,包含全局特征和局部特征,使用字詞特征融合的策略進行表示。字詞特征融合是一種具有魯棒性和高效性的策略,能充分利用最顯著的特征達到更好的效果。基于字符級的特征融合能將多個相關特征組合成原始輸入序列的全局信息表示。在特征融合階段,采用一種能自適應的連接策略對全局和局部特征進行融合,字詞特征融合表示如下:
其中,htA 和htC 是從1.2節中獲取的特征,u1 是用來調節這兩個特征重要性程度的參數。
最后,將融合的字符級表示ht 和增強的字詞編碼表示Emb(B,M,E,S) 進行特征的拼接,得到最終輸入層的表示。
2 地址語義相似度計算
對待匹配地址和標準地址集中的每一個地址進行相似度計算,獲取到與待匹配標準地址的相似度,設定相似度閾值,查找到符合閾值的相似地址。
3 實驗
3.1 實驗環境
本文使用基于CUDA 10.0的深度學習框架Keras i27.3-.707構00建 In網tel絡(R)模 C型ore,(T實M驗) C在PU內,存NVDIDDIRA4 G3e2FGo,rc3e.6 GGTHXz 1080 Ti的Ubuntu 18.04 LTS系統上進行。
3.2 數據集
為了評估本文提出模型的穩定性,本文使用標準地址庫構建了一個包含約30W條蕪湖市地址信息的數據集,將其中的25W條數據作為訓練集,剩余5萬條數據作為測試集數據,其中訓練集和測試集的正負樣本比例約為3:1。
3.3 實驗設置
本文將漢字字符特征的維度設定為 20維度,用 word2vec模型對每個漢字進行編碼向量化,將不足20 維的地址數據編碼用0補足為20維編碼,然后將地址數據中的每個單詞表征為對應詞向量,并將其融合作為整個地址數據的向量表示。在超參的設置上,針對地址數據可能的長度,在語義表征層中,設置每一個詞的輸出維度為768維,表征后輸出的地址數據語義表征維度均為100維,完成語義表征后,將獲得的兩個語義向量分別輸入下一層網絡結構中。
3.4 實驗結果與分析
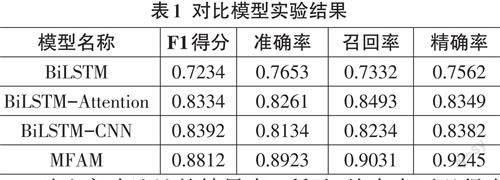
在評價指標上,為了對預測結果進行有效的評價,本文選取相應的參考指標去衡量最終結果,包括準確率(accuracy) 、精確率(precious) 、召回率(recall) 與F1得分(F1-score) 。其中準確率越高,證明模型對于地址相似度計算結果越精確;而F1得分越高,證明模型整體性能越好。
為了驗證本文提出的MFAM模型的有效性,將本文提出的模型與經典模型進行對比實驗,本文設置以下幾組對比模型實驗:第一組使用BiLSTM模型;第二組使用BiLSTM模型,并添加注意力機制進行實驗;第三組結合CNN網絡獲取局部上下文信息,使用BiLSTM-CNN模型進行實驗;最后一組即為本文所提出的MFAM模型,在BiLSTM 中引入注意力機制,并結合CNN網絡進行共同訓練。
對比實驗地址的結果表1所示,從表中可以得出本文提出的MFAM模型在準確率、召回率以及F1值上均取得了最好的結果,表明本文方法在中文地址匹配方面的有效性。從表1中可以看出,第二組采用結合注意力機制的地址匹配方法,使得模型的整體效果都得到了提升,表明添加注意力機制,可以從全局的角度學得有效特征,有助于模型的訓練。而從第三組實驗結果中,發現使用CNN獲取局部有效特征也可對模型的性能進行提升。同時,對比第四組、第二組和第三組實驗結果,可以看出本文提出的模型在F1得分上相比其他模型性能提升了5~7百分點,這個結果證明了在僅考慮注意力機制或者CNN獲得的局部信息的情況下,模型無法有效地捕捉地址中的部分關鍵信息,導致模型的整體性能下降。同時,F1得分證明,MFAM模型的精度提升并非受到數據集中正負樣例的比例影響,而是模型的整體學習能力相較于其他消融模型確實獲得了增強。
4 結論
本文在分析現有中文地址數據特征的基礎上,研究了中文地址要素并分析了可能存在的組合模式,針對傳統的中文地址匹配方法存在的不足,提出了一種基于字詞特征融合的中文地址語義匹配模型。在自主構建的數據集上,本文提出的方法相對于傳統的方法提高了5~7 個百分點,驗證了MFAM 方法的有效性,為中文地址的匹配提供了新的方法和思路。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
