基于頻譜增強的軟件多故障定位
2023-08-30 06:59:16周世健鄔凱勝
計算機測量與控制 2023年8期
陳 琪,周世健,樊 鑫,2,鄔凱勝,2,肖 鵬,2
(1.南昌航空大學 軟件學院,南昌 330038;2.南昌航空大學 軟件測評中心,南昌 330038)
0 引言
軟件正成為低成本實現各種系統中復雜功能的首選技術,日常生活的許多方面都依賴于軟件的正確操作,因此保證軟件的質量和及時的維護在每個開發過程中都起著至關重要的作用。測試指的是檢查軟件的正確性和它是否符合給定的規范的實踐狀態。雖然測試用例自動生成工具愈漸成熟,仍然存在部分由開發人員手工制作的測試用例,在暴露錯誤行為方面測試是有效的,但識別失敗背后的根本原因仍然主要是一種手動活動,需要大量的時間和成本。
各種故障定位方法用來幫助開發人員定位故障的根本原因,例如,基于頻譜的故障定位[1-6],基于切片的故障定位[7-8],基于機器學習的故障定位[9-10],和基于突變的故障定位[11-14]。其中,基于頻譜的故障定位技術是研究最廣泛的故障定位技術之一。盡管SBFL是一種特別輕量級的方法,但與其他方法相比,它已被證明具有競爭力,且具備與語言無關、易于使用,并且在測試執行時間相對開銷較低的特性。
理想的故障定位技術總是將故障程序實體排在前列。然而在實踐中,盡管已經提出了各種SBFL技術,如Jaccard/Ochiai[2],Op2[4]和Tarantula[1],沒有一種技術可以總是表現最好的,開發人員通常必須在找到真正的錯誤之前檢查各種非故障實體(即程序頻譜中的一個維度)。利用失敗和成功的測試用例提供的證據,根據被測實體參與錯誤行為的懷疑程度進行分析和排序。直觀地說,一個實體在測試用例失敗時使用得越多,它就越可疑,即它就越有可能與這種不正確性的原因有關。類似地,成功的測試用例所使用的實體越多,它就越被認為不可疑。
現有的SBFL技術的一個局限性是,它們不能完全捕獲每個已執行的測試用例的結果與所涉及的程序單元之間的本地關系。例如,SBFL技術,如Dstar[15],會假設兩個失敗的測試用例對在兩個測試用例中執行的一個程序單元的懷疑性貢獻相同,而不管在測試用例中涉及的程序實體的數量不同。在實踐中,一個失敗的測試用例可能比其他用例更有價值,因為它只涉及幾個程序實體。其次,在許多現有的SBFL技術中,存在一個被忽略的事實,即程序實體可能以不同的方式協作貢獻每個測試用例的結果。
我們的關鍵見解是,存在一種更豐富的頻譜增強形式,考慮了如何增強失敗的測試用例中的頻譜分析,可以提供更有效的故障定位。詳細來說,存在兩個測試和,它們都是失敗的測試,其中覆蓋了100個程序實體,而只覆蓋了10個程序。根據我們的直覺,在故障定位方面比較有幫助,因為有一個更小的搜索空間來定位故障(s)。由于每一個執行失敗的測試用例都必然執行了錯誤語句,即錯誤語句必然被覆蓋,那么[16]已經證實了在單故障情況下,將所有執行失敗的測試用例的覆蓋情況取交集,則會縮小故障語句的覆蓋范圍,從而提高查找效率。經過頻譜增強后的測試用例作為新的增強版測試用例來對程序進行驗證。傳統的SBFL技術忽略了這些有用的信息,并認為和在SBFL上做出了相同的貢獻,例如,和執行的程序實體將被作為相同的處理,而不管測試所覆蓋的實體數量。
為了克服現有的SBFL技術的局限性,我們通過明確地考慮失敗測試用例的貢獻,更有效地增強了現有的程序頻譜。基于以上見解,我們提出了基于頻譜增強的軟件多故障定位方法(SBFL(E),spectrum-based fault localization(enhanced)),充分利用了執行失敗測試用例的程序語句覆蓋情況,縮減了運行時的執行失敗測試用例數量,對基于頻譜的故障定位方法進行改良,并將單故障擴展到多故障實驗,極大提高了軟件故障定位的效率和有效性。
1 軟件故障定位
1.1 基于頻譜的故障定位
SBFL使用程序頻譜和測試結果來定位軟件故障。程序頻譜是測試用例的覆蓋信息和執行結果的集合。一個程序的頻譜,通常以一個矩陣的形式出現,它描述了該程序的動態行為。測試結果將記錄測試用例是否失敗或通過。通過較多失敗測試用例的實體,通過較少成功測試用例的實體就越可疑[17-18]。相反,實體通過越少的失敗測試用例,通過越多成功的測試用例,實體的可疑度值就越低。程序譜中所涉及的實體類型可以是語句、分支、函數、謂詞等,本文以語句作為實體。
SBFL的主要思想是與故障相關的執行信息更有可能是導致程序失效的原因,這些信息往往包含在失敗的測試用例,而更少發生在成功的測試用例當中。如圖1所示,SBFL分析了實體與測試用例通過或失敗之間的動態相關性,這個相關性近似于一個實體導致程序失效的可能性。頻譜信息矩陣由M個測試用例和每個測試用例中的N條語句構成,最后得到測試結果向量R。對于一個語句X_MN,其值是二進制的(0/1),“1”表示相應的語句被測試用例執行,“0”表示相應的語句沒有被測試用例執行。在結果向量R中,其值也是二進制的,“0”表示測試用例的結果為通過,“1”表示測試用例的結果為失敗。

圖1 SBFL覆蓋信息矩陣圖
程序執行信息從圖1中提取,表示為四元組(Nef,Nep,Nnf,Nnp),其中Nef代表語句被執行的失敗測試用例數,Nep代表語句被執行的通過測試用例數,Nnf代表語句未被執行的失敗測試用例數,Nnp代表語句未被執行的通過測試用例數。根據以上4個參數,程序中各單元元素的可疑值可以通過表1中的可疑值計算公式來計算,這里只列出了部分但常用的公式。如果一個語句的Nef值相對較高,而Nep值較低,則該語句的可疑分值較高。

表1 SBFL可疑度值計算公式
1.2 單故障與多故障定位
單故障程序指的是在程序中只存在唯一確定的一處故障,導致整個程序的失效;多故障程序則指錯誤數目不定,存在兩處或兩處以上的故障影響導致程序失效。盡管各種故障定位技術已經被提出,但它們在多故障程序中的應用仍然有限。多故障定位(MFL,multiple fault localization)是指在一個有故障的軟件程序中識別多重故障(一個以上的故障)的定位行為。與單故障定位(SFL,single fault localization)假設軟件系統中只包含一個故障的傳統做法相比,這種方法更加復雜、繁瑣,而且成本高。工作流程對比如圖2所示。
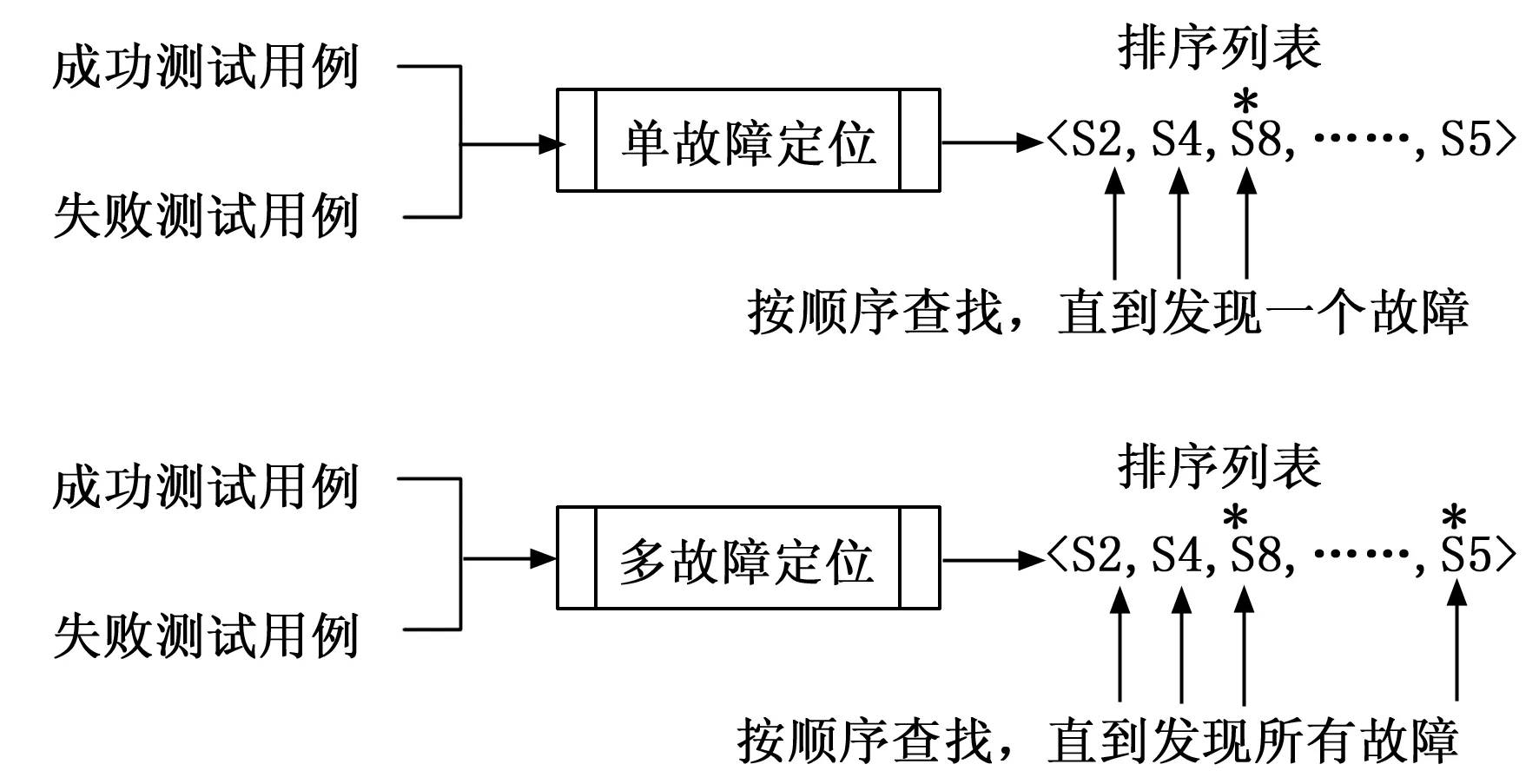
圖2 單故障與多故障定位
單故障程序中所有失敗的測試用例均指向相同的故障,因此測試用例的數量與質量則顯得尤為關鍵,成為優化故障定位方式的突破口。在多故障環境下,除了受到測試用例的影響,更令人棘手的是故障干擾的問題。
這些相互作用可能表現為導致測試用例失敗,而通常情況下,由于任何單一故障的存在都不會失敗。另外,一個測試通常由于一個故障而失敗的測試用例,在增加了另一個故障后,該測試用例可能不再失敗,因為它干擾了第一個故障的導致程序失效的作用。當然也存在多個故障于同一個程序中,但不會以通過檢查測試用例可以觀察到故障的方式相互干擾。在這種情況下。程序中每個故障的影響似乎是獨立于其他故障。本文則對故障干擾不做出假設,專注于提升測試用例尤其是失敗的測試用例,使用傳統的定位技術同時定位多個故障是困難的,因為它們依賴于失敗的測試執行來識別錯誤的語句。
綜合來看,單故障與多故障定位的差異除了存在于需要定位的故障數目的不同,也不免對測試用例的統計處理以及失敗測試用例的質量造成消極影響。當故障之間的干擾導致程序包含多個故障時,現有故障定位技術的有效性會降低。程序中的故障越多,開發人員就定位故障的復雜性就越高,從而大大增加故障定位的難度與開銷成本。
2 動機實例
SBFL是基于程序執行的統計數據設計的,其中包括測試覆蓋率和測試結果。執行統計數據可以被視為SBFL分析的信息源,其中決定了SBFL的準確性的關鍵在于測試用例的性質。冗余的測試用例大大增加了開發人員的時間成本與故障定位的精確性,一個含故障程序實例如表2所示。
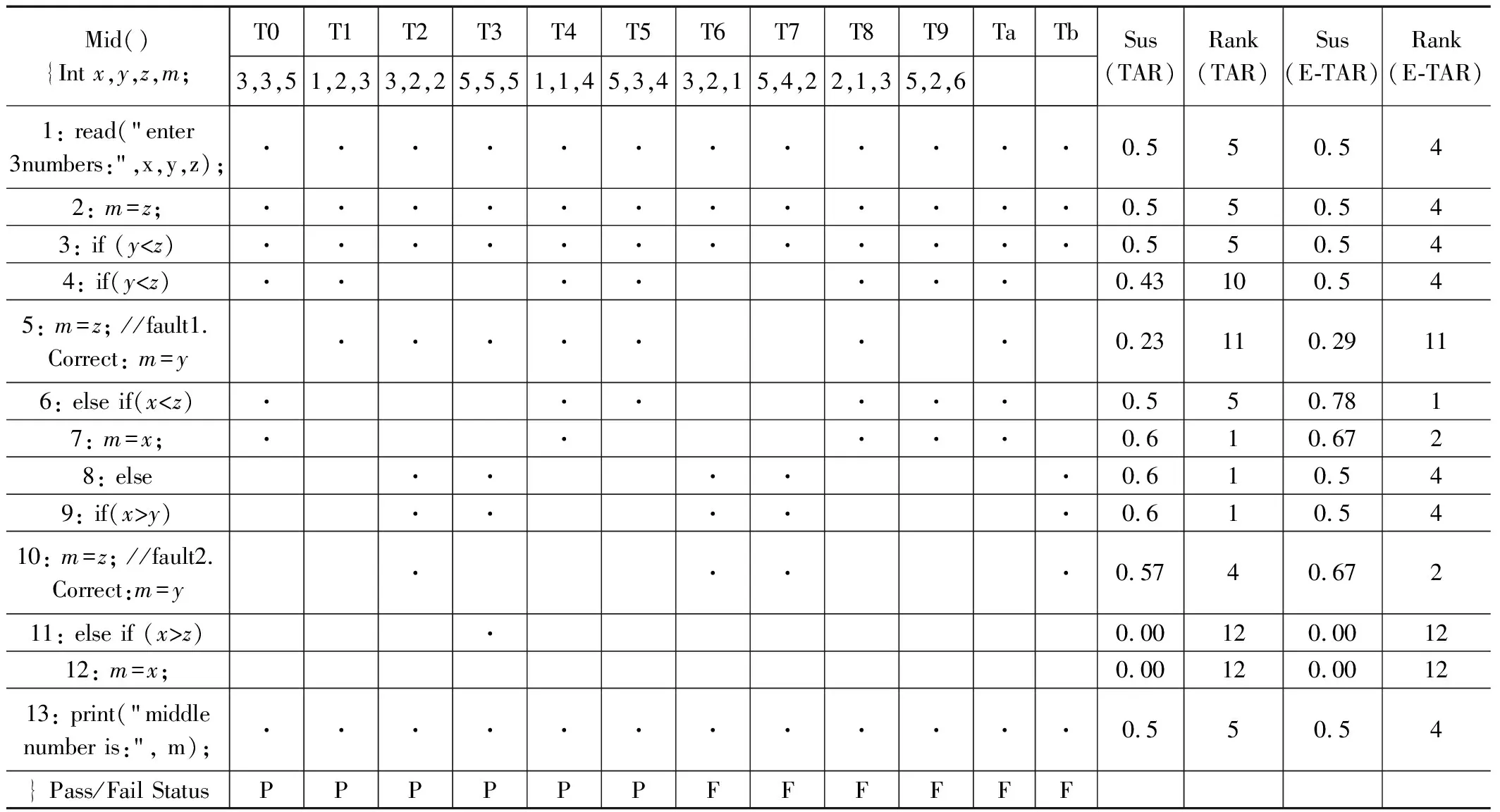
表2 多故障實例
在現有的研究方法中,我們考慮了一個有缺陷的程序來評估我們技術的效率。Zakari等人[19]用一個例子來解釋3種方法:一次調試方法、并行調試方法和多次調試方法。在本文中,我們采用了同樣的例子程序來展示我們的方法的工作過程。余曉菲等人[16]已經證實了頻譜增強在單故障程序中的有效性,因此表2實例僅對多故障程序進行詳細分析。在表2中,我們顯示了示例程序。原始的程序測試套件T由10個測試用例(T0,T1,T2,T3,T4,T5,T6,T7,T8,T9)和13條程序語句組成,其中語句5和語句10都是錯誤的。標有“●”的語句執行標志著該語句在該測試運行中被測試用例執行,否則為空。測試用例(T6,T7,T8,T9)是失敗的測試用例,而(T0,T1,T2,T3,T4,T5)是通過的測試用例。在這個例子中,每個語句的可疑性是用Tarantula系數計算的,這是SBFL中常用的故障定位技術之一。
對于單次故障的調試很簡單,根據語句的可疑度得分,開發人員通過使用Tarantula,檢查4條語句就能清楚地識別出有故障的語句10(可疑度值為0.57)。然而,在多故障情況下,在語句10中發現的故障必須被修復,并且程序必須被重新測試以發現第二個故障語句5(可疑度值為0.23)。在多故障調試過程中,開發人員在找到語句10中的第一個故障后不會停止,而是繼續搜索下一個故障,直到找到所有故障或預先指定的搜索上限。設置上限的方法(即開發人
員在進入下一個迭代之前可以搜索可疑語句排名列表的70%或60%)已被現有研究采用[20-21]。在我們的研究中,我們沒有設置搜索上限,而是在找到所有故障之前停止搜索。
采取多故障場景下頻譜增強的方法,實例為雙故障程序,覆蓋第一個故障語句5的失敗測試用例僅為T8,因此頻譜增強后的測試用例Ta保留T8的覆蓋信息并剔除原有T8。失敗測試用例T6和T7覆蓋了第二個故障語句10,且覆蓋信息高度重合,對二者進行測試用例精簡,采取邏輯與運算得到測試用例Tb,并將T6和T7從測試用例集中去除。頻譜增強后可用測試用例為T0~T5以及T9~Tb,再進行SBFL可疑度值計算。
表2清楚地顯示,Tarantula計算的錯誤語句的等級為4和11。在采用頻譜增強的方法進行優化后,我們的技術分別給有問題的語句分配了等級2和等級11。這表明,我們的研究方法比其他現有的方法更有效地優化了可疑性分數,并且能夠定位那些使程序失效的語句。
3 基于頻譜增強的軟件故障定位
對基于頻譜的故障定位方法而言,故障定位的效果和效率都高度依賴于測試用例,所以測試用例的選取以及使用測試用例的多少都對實驗有至關重要的影響。針對測試用例的研究,本文引入頻譜增強方法,充分利用了執行失敗測試用例的程序語句覆蓋信息,精簡了運行時的執行失敗測試用例數量,從而提升了測試用例的質量以及軟件故障定位的效率。
由于語句執行的覆蓋信息都為二進制表示方法,因此將所有失敗測試用例的覆蓋信息做邏輯與運算,則能夠精簡頻譜信息,從而縮小查找故障語句的范圍,并且通過頻譜增強后的測試用例一定會覆蓋存在故障的語句。我們將與運算操作取得的覆蓋信息這個操作稱為頻譜增強。再使用增強過的頻譜信息進行SBFL可疑度值計算,最后根據優化后的可疑度排名列表進行更高效的故障定位。整體流程如圖3所示。
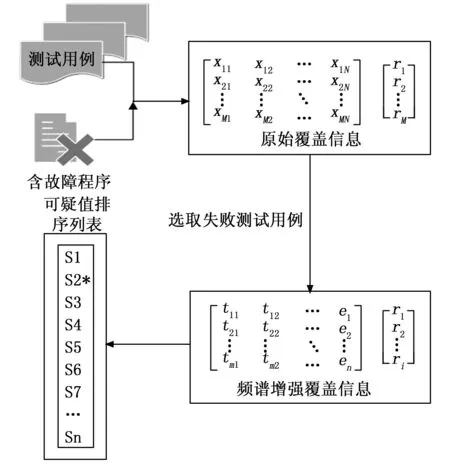
圖3 SBFL(E)流程圖
單故障場景下,頻譜增強后得到唯一的失敗測試用例。程序運行時,唯一的故障語句必然被所有失敗測試用例所覆蓋,否則測試用例通過,運行結果正確,程序成功執行。而多故障場景中,并不是所有的故障語句都被每一個失敗測試用例所覆蓋,我們采取根據多故障數量k進行頻譜增強的方式,最后得到k個頻譜增強后的失敗測試用例。
將失敗測試用例集設為T,T={T1,T2,…,Ti,…,Tm},其中Ti為第i個失敗測試用例的執行情況,具體失敗測試用例的覆蓋信息設為集合t,t={ti1,ti2,…,tij,…,tin},其中i為執行失敗測試用例編號,j為語句行號,n為總語句數,ti為第i個執行失敗測試用例的執行情況,tij為第i個執行失敗測試用例的第j條語句的覆蓋情況,覆蓋情況取值為0或1,0為未被覆蓋語句,1為被覆蓋語句b。頻譜增強E={e1,e2,…,el,…,en},其中:
(1)
以表2中多故障程序Mid為例,執行失敗測試用例數為4,語句總數為13,故障,有4個失敗執行覆蓋t6,t7,t8和t9,其中以t6為例,t6={1,1,1,0,0,0,0,1,1,1,0,0,1}。利用頻譜增強的定義,通過頻譜增強方法可以得到該例子中E1={e1,e2,…,el,…,en}。
4 實驗結果與分析
為驗證本文方法的有效性,實驗比較了SBFL(未經過頻譜增強)和SBFL(E)(經過頻譜增強)的故障定位性能。實驗運行環境為Windows10和Ubuntu系統,2.60 GHz Intel(R)i5四核處理器,16 GB 物理內存。
4.1 實驗數據集
我們采取基準程序進行了5個案例研究,其中3個程序是西門子(Siemens)程序套件的一部分,其余兩個程序來自Defects4j,數據集的詳細信息在表3中列出。基于人工故障的西門子程序選取了Tcas,Totinfo和Printtokens2;基于真實故障的Defects4j程序選取了Apache Common Lang和JFree Chart。這些C語言(Siemens)和JAVA(Defects4j)程序被廣泛用于軟件測試和故障定位的實驗中,也用于我們之前的研究工作當中。
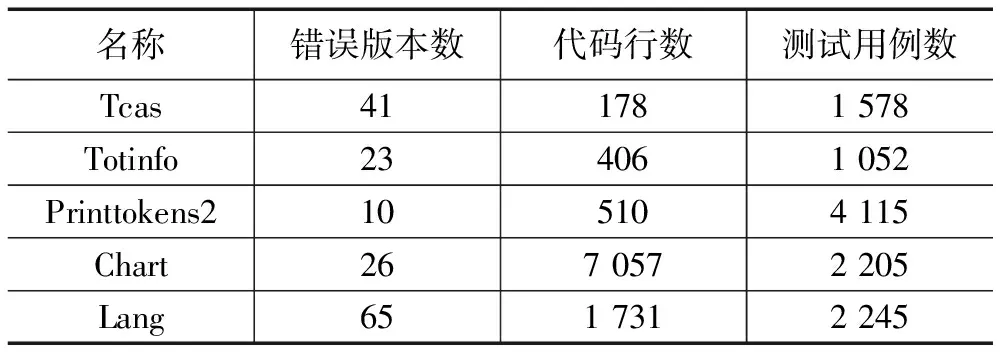
表3 數據集
所有基準程序的單故障版本可以分別從SIR(software-artifact infrastructure repository)和Defects4j資源庫下載。在多故障版本中,故障是手動播種到原始程序中的。由于大多數程序都是單故障,我們將單故障版本結合起來,建立多故障版本。Rui[22]和Zakari[19]也創建了包含2、3、4和5個故障的多故障版本,以產生Siemens-M案例研究。
4.2 評價指標
在本文中,我們采用EXAM和Top-N用于評估我們提出的SBFL(E)方法的性能的指標,并將其與其他故障定位技術的有效性進行比較。
根據Wong等人提出的評價標準[23],我們的研究采用EXAM作為評價指標,其定義為發現程序中所有故障時需要檢查的代碼行數占程序總代碼行數的百分比。具體公式為:
(2)
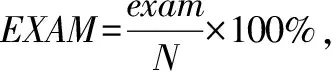
Top-N用于評估故障元素的絕對排名,它通過檢查排名列表的前n個位置來計算成功定位的故障總數。N越小,故障定位技術就越有效。值得注意的是,程序員在實踐中會更多地關注最可疑的元素,他們不是一個一個地檢查排名列表中的語句,而是在排名列表中的不同位置之間表現出某種形式的跳躍,直到關于故障原因的假設得到確認[25]。此外,排名靠前的位置很少被程序員跳過,所以Top-1對于評估故障定位技術的有效性和準確性極為關鍵。
4.3 結果分析
基于上述提出的方法,本節對實驗進行了詳細描述和分析。我們建立了一個名為SBFL(E)的故障定位技術,它通過頻譜增強來優化SBFL,為了評估我們方法的有效性,我們采用了4個常用的SBFL技術作為基準。
在我們的實驗研究中,我們執行了5個基準程序,包括3個西門子套件和兩個Defects4j實用程序,每個程序中都包含一個故障。圖4顯示了Dstar,Jaccard,Ochiai和Tarantula對3個西門子程序(Tcas,Totinfo和Printtokens2)的推廣技術的比較;Defects4j數據集中Chart和Lang的整體表現也可以在圖5中見證。在每張圖中,橫軸表示EXAM分數的百分比,而縱軸表示能檢測到存在故障版本的百分比。
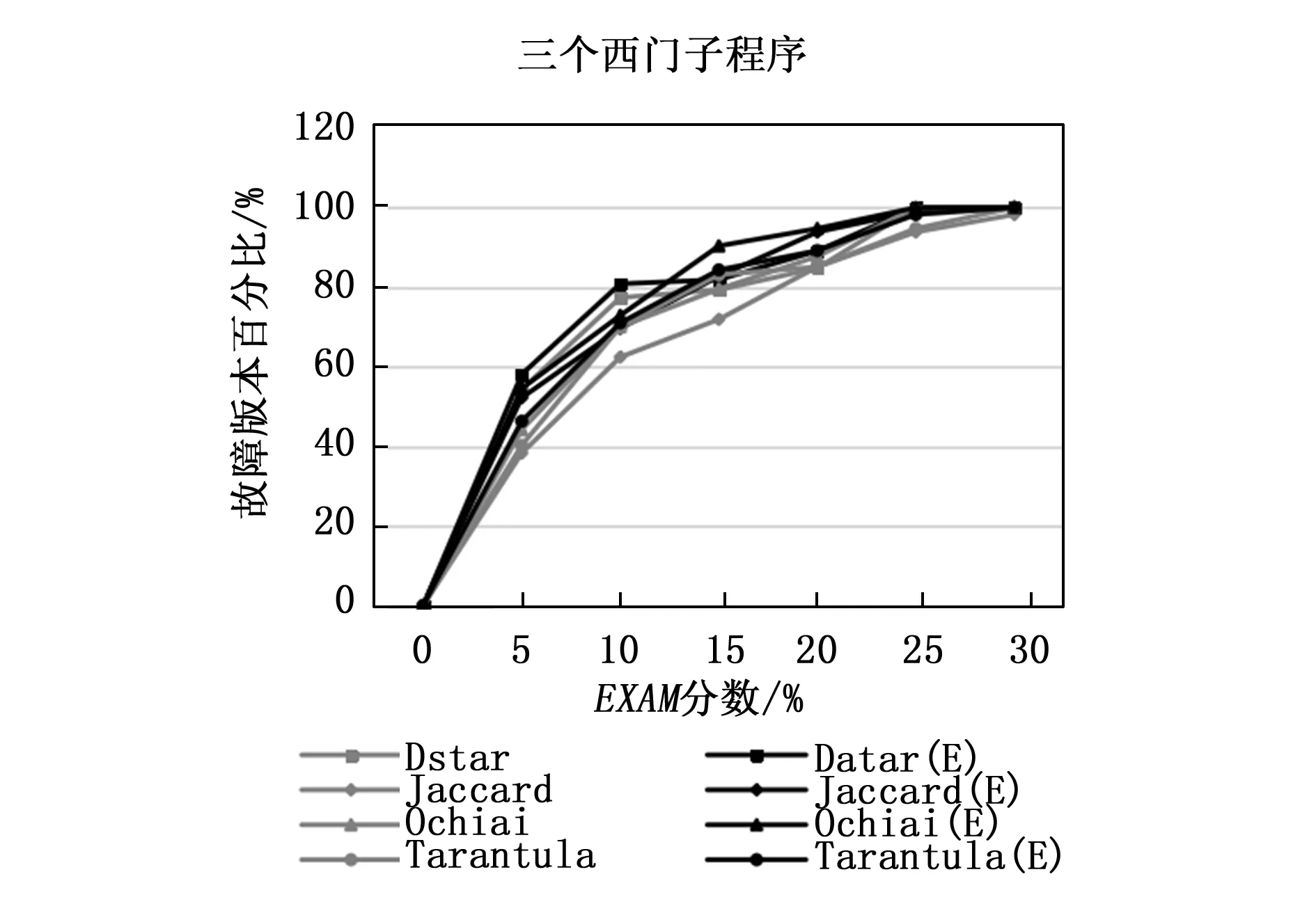
圖4 單故障西門子程序EXAM指數
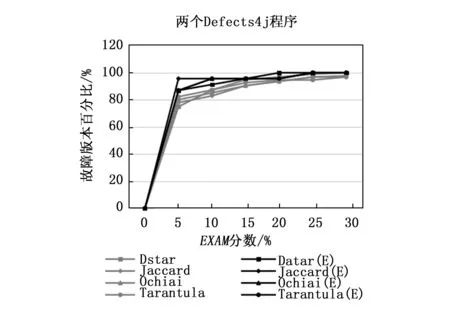
圖5 單故障Defects4j程序EXAM指數
從圖4和圖5的結果分析中,我們發現由頻譜增強的技術在尋找單一故障方面比現有的技術表現得更好,尤其是Ochiai(E)方法EXAM在分數為15%~20%時表現突出,它能夠定位90%以上的故障版本。Jaccard(E)和Dstar(E)也在圖5中的相同范圍內保持了類似的趨勢,能夠定位大約95%的故障版本。
我們在單故障程序中手動添加了一個故障,從而得到雙故障程序。我們執行每個有兩個故障的基準程序,計算了EXAMF和EXAML值,以評估我們技術的準確性,如圖6和7所示。并介紹了4種技術對西門子程序的EXAMF和EXAML的比較。同樣,對于Defects4j程序,4種技術的比較見圖8和9。從結果分析中,我們可以看到,所提出的技術SBFL(E)在大多數情況下都優于傳統SBFL。由于確保頻譜增強技術確實在多故障程序中起到了優化作用,我們在每個西門子和Defects4j基準程序中手動添加到3個故障,準備了三故障程序來進行進一步實驗研究。圖10~12分別給出了4種技術對西門子程序的EXAMF,EXAMM,以及EXAML值的比較。對于Defects4j程序,類似的比較如圖9所示。綜合來看,我們提出的技術比現有的SBFL技術表現得更好。
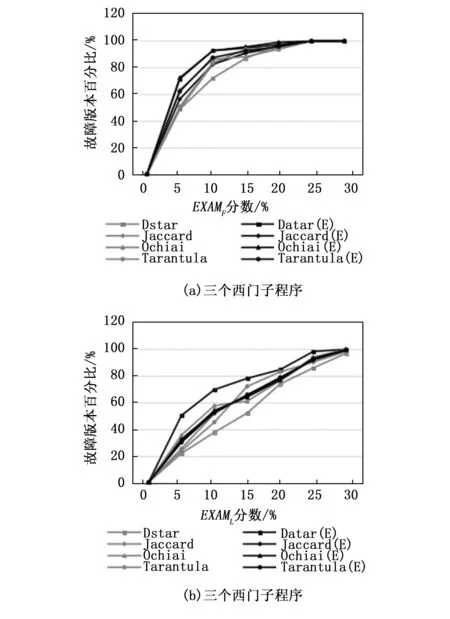
圖6 雙故障西門子程序EXAMF和EXAML指數
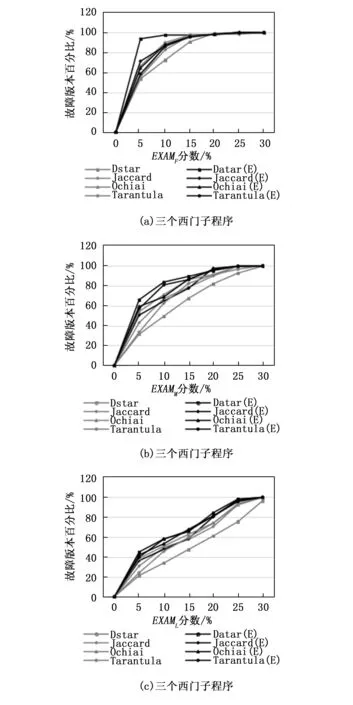
圖8 三故障西門子程序EXAMF、EXAMM和EXAML指數
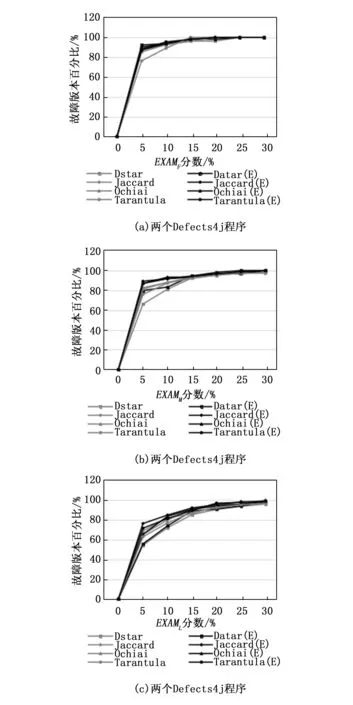
圖9 三故障Defects4j程序EXAMF、EXAMM和EXAML指數
為了評估他們對頂級可疑元素的表現,使用了Top-n作為測量指標。95%的審查都是從排序列表中的第1個可疑元素開始的,這意味著首位很少被程序員跳過。因此,如何提高故障定位的準確性,特別是Top-1可疑元素,對故障定位的實用性至關重要。如表4所示,SBFL(E)技術通過檢查單故障程序中的Top-1、Top-3和Top-5可疑語句,分別成功定位了數量更多的故障。表4突出了西門子程序的性能,每一種技術都得到了不同程度的改善,其他采用頻譜增強技術在Top-1上比傳統技術可以多定位到約20%以上的故障,在Top-3和Top-5上都有同比增長。同樣,表4也顯示了Defects4j中同樣的8種技術進行比較,所有的SBFL技術的效率都因為頻譜增強所提升。最明顯的變化是Dstar(E)在重要的Top-1上,故障定位數量從49增加到61。
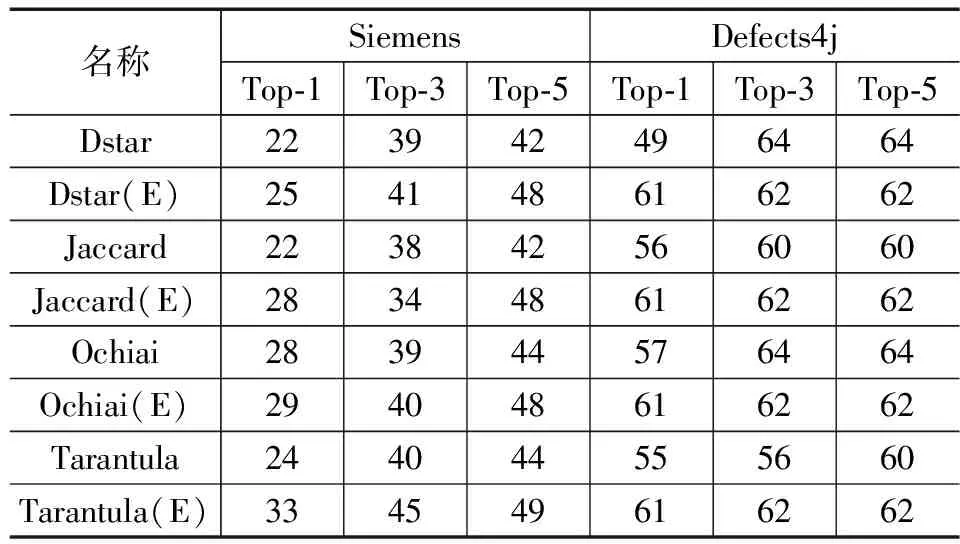
表4 單故障程序中Top-N指數名稱
在多故障程序中,Top-N在SBFL和SBFL(E)技術之間展示了不同程度的增長。如表5所示,在雙故障的西門子程序中,Dstar(E)通過檢查前1、3和5條可疑語句,可以分別定位24、53和66個故障(約占所有故障的20.3%、44.9%和55.9%)。Dstar(E)和Tarantula(E)保持著類似的趨勢,且表現比Ochiai(E)好。如表5所示,在3個故障的西門子程序中,Dstar(E)通過檢查前1、3和5條可疑語句,分別可以定位36、67和88個故障(約占所有故障的19.6%、36.4%和47.8%)。Jaccard(E),Ochiai(E)和Tarantula(E)的存在相同的趨勢,且差異較小。如表5和6所示,在多故障Defects4j程序中的優勢更為顯著,SBFL(E)在Top-1,Top-3以及Top-5中都保持較好的性能,盡管在少數情況下,與傳統的SBFL技術相比,它未能定位更多的故障。
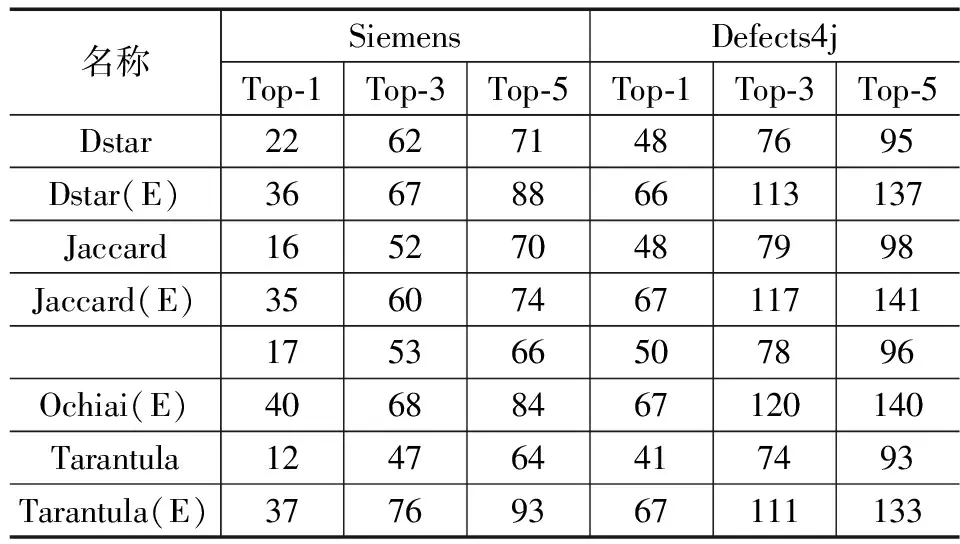
表6 三故障程序中Top-N指數名稱
5 結束語
故障定位是困難且代價高的,這就是為什么我們在過去20年中看到了各種故障定位技術被提出。多故障定位正在成為軟件測試研究領域中最關鍵的問題之一。在實踐中,我們發現在傳統的SBFL中冗余的失敗測試用例會給故障定位效率帶來消極影響,這阻礙了程序員在調試故障時的效率和生產力。此外,我們注意到使用頻譜增強的邏輯與運算可以有效精簡失敗測試用例的頻譜信息,優化可疑度值以提高故障元素的等級。
在本文中,我們提出了基于頻譜增強的多故障定位方法。首先,使用頻譜增強的方法精簡失敗的測試用例,再利用SBFL的統計公式對新的頻譜信息進行評估,并根據其可疑度對潛在的故障語句進行排序。最后,被SBFL(E)排在前N位的語句根據其新的分數排序。所提出的故障定位方法緩解了SBFL的缺點,提高了故障定位的準確性。通過使用5個開源基準程序的案例研究來評估我們框架的性能。為了顯示我們提出的技術的效率,將我們的工作與4個密切相關的故障定位技術,即Dstar、Jaccard、Ochiai和Tarantula進行了比較。實驗結果表明,與典型的SBFL定位方法相比,基于頻譜增強的方法可以顯著減少代碼檢查的范圍,尤其是在高性能范圍內(即EXAM5%和Top-1),明顯提高了故障定位的性能。
但是在這個領域還有很大的發展空間,也有一些問題需要解決。存在程序中如果失敗測試用例過少的問題,而測試用例質量及其數量對結果有很重要的影響;以及頻譜增強的思想能否運用到其他故障定位方法當中。后期研究人員還需要努力減少其負面影響,甚至解決這些問題。雖然本實驗選擇的基準程序在故障定位領域具有代表性,具有說服力,但在今后的工作中,我們將把重點放在更真實的工程程序上。總的來說,隨著研究界對SFL研究的極大興趣,以及最近該領域出版物的一致性,我們希望在未來幾年會有更多具體的解決方案來解決多故障問題。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
