改進DeeplabV3+模型的河流水體提取
2023-09-02 02:25:46張晗濤胡榮明姜友誼胡亞軒
遙感信息 2023年3期
張晗濤,胡榮明,姜友誼,胡亞軒
(1.西安科技大學 測繪科學與技術學院,西安 710000;2.中國地震局第二監測中心,西安 710054)
0 引言
隨著遙感技術在自然資源監測的廣泛應用,如何準確地獲取河流水體信息已經成為遙感應用領域的一個關鍵研究方向。當前,利用DeeplabV3+[1]網絡模型進行遙感信息提取已取得了較多的成就,如陳前等[2]利用DeeplabV3網絡對高分遙感影像水體提取進行研究,證明了深度學習方法的有效性。Li等[3]通過密集局部特征壓縮網絡融合遙感圖像的空間和光譜信息,從不同的遙感圖像中提取水體,并與傳統的水體提取方法以及U-Net、DeeplabV3+等模型進行了對比。茍杰松等[4]通過利用DeeplabV3+方法證明了在養殖水體信息提取方面,DeeplabV3+方法均高于歸一化差分水體指數法和最大似然監督分類法。Chen等[5]通過改進LinkNet模型進行了寒旱區河流水體提取,并與U-Net、DeeplabV3+等神經網絡模型進行了對比。
綜上所述,DeeplabV3+網絡雖然在遙感信息提取領域有些許成就,但是針對于高分辨率遙感影像進行河流水體信息提取仍存在研究不足。本文通過建立不同骨架網絡模型的DeeplabV3+網絡,探究不同骨架網絡模型在河流水體提取的應用能力,同時針對研究中所存在的小目標河流提取精度不足的問題,對DeeplabV3+網絡模型進行了優化,提出了一種基于改進DeeplabV3+網絡的河流提取方法。
1 研究區概況與數據源
1.1 研究區概況
為了探究深度學習模型在不同遙感影像中河流提取的應用能力,選擇山區、城市、云霧等4種不同遙感影像下的河流水體作為研究對象。
1.2 數據源
本文遙感影像數據集采用的是高分二號和高分七號影像。實驗數據集主要是由遙感影像數據以及人工經過目視解譯,利用Labelme圖形圖像注釋工具進行標注的二值圖標簽數據組成。影像標簽數據采用的是Pascalvoc數據集格式,影像分辨率為1 024像素×1 024像素,共由7 551張訓練數據構成。該數據集主要由長江流域水系構成,影像采集時間主要為第二季度,去除了結冰水面干擾。河流水體語義分割訓練數據集如圖1所示。

圖1 河流水體語義分割訓練集
2 研究方法
2.1 DeeplabV3+網絡結構
DeeplabV3+網絡結構主要分為編碼層和解碼層兩部分。編碼層的主體由兩部分組成,首先是深度卷積神經網絡(deep convolutional neural networks,DCNN)[6],其通常采用的是Xception或ResNet[7-8]等常用的分類骨架網絡,其次是帶有空洞卷積的空間金字塔池化模塊(atrous spatial pyramid pooling,ASPP)[9]。空洞卷積是在不改變特征圖大小的同時控制感受野,多尺度地獲取影像關鍵信息。空間金字塔池化模塊則是通過采用不同空洞率的空洞卷積來進一步提取多尺度信息。解碼層主要是通過采用1×1的卷積對提取到低層次(low-level)特征信息進行壓縮,然后通過與高層次(high-level)特征信息進一步融合,其次將融合后的結果通過3×3的卷積來細化特征,最后經過一個4倍上采樣來輸出最終結果,進而提升分割邊界準確度。
2.2 改進的DeeplabV3+網絡結構
本文針對河流提取研究,對DeeplabV3+網絡結構進行了改進,改進后的模型結構如圖2所示,網絡主體同樣分為編碼層和解碼層兩大部分,其中深度卷積神經網絡所采用的是在本河流提取研究中表現較為優秀的ResNet-50骨架網絡,具體的改進由編碼區改進ASPP模塊和解碼區增加不同層次的輸入圖像特征構成。
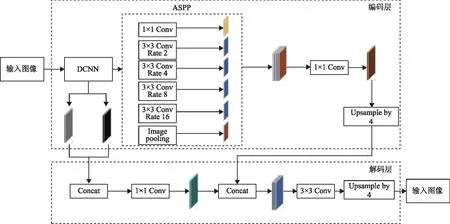
圖2 改進的DeeplabV3+網絡結構
1)編碼區改進空間金字塔池化模塊。空間金字塔池化模塊主要作用是對輸入的特征圖進行多尺度語義信息提取,其由多個卷積操作和全局平均池化操作并行構成,其中除了1×1的卷積外,其余的卷積核都帶有不同的空洞率來進行卷積操作[10]。之所以要帶有不同的空洞率進行卷積,是因為隨著網絡模型逐步提取圖像特征,原始特征圖的分辨率會逐漸變小。此時,攜帶著空洞率值較大的卷積核,更加適合分割大尺寸目標物。同樣地,攜帶著空洞率較小的卷積核更加適合分割小尺寸目標物。因此,本研究為了增加模型分割不同大小目標的能力,在ASPP模塊中使得網絡結構具有多尺度的卷積核。如圖2所示,在該模塊,本研究為了能夠提取出小目標的狹長河流水體,將原始DeeplabV3+網絡空間金字塔池化模塊中空洞率值為6、12、18的空洞卷積優化為空洞率值分別為2、4、8、16的空洞卷積操作。
同時,本研究將空間金字塔池化模塊中原有的標準卷積替換成深度可分離卷積。深度可分離卷積中每個卷積核只考慮自己所負責的通道,而不像標準卷積那樣,每個卷積核要考慮所有通道的語義信息。首先通過在逐個通道中進行深度卷積學習空間相關性,然后進行點卷積操作學習特征。深度可分離卷積以其較低的參數數量和運算成本取得了較大的優勢,在訓練過程中大大減少了所需參數量,同時深度可分離卷積還在對預測精度影響不大的前提下提高了網絡模型的訓練效率。
2)解碼區增加不同層次的圖像特征。在解碼區部分,本文將兩個經過編碼區骨架網絡不同層次的輸入圖像特征圖提取出來,相比于原始DeeplabV3+網絡結構實現了同時提取兩個特征圖映射作為解碼器的特征輸入信息,并將提取出的兩個低維特征以融合的方式使其更具有豐富的低維特征信息。然后,對融合后的低維特征和編碼器中獲取的高維特征進行處理融合,再次豐富完善特征信息。最后,在經過3×3卷積和4倍的上采樣處理后,將特征信息進行細化,恢復特征所應具有的空間信息,最終將得到的分割結果圖進行輸出[11]。
3 實驗結果與分析
實驗程序所采用深度學習框架為PyTorch。超參數[12]設置為:初始學習率0.003,權重衰減0.000 2,總共進行100次訓練迭代,批尺寸大小(batch size)為12。本次研究中采用平均交并比(MIoU)為主要的評價指標。MIoU是語義分割領域常用的評價指標,代表模型語義分割預測的結果與其人工創建的標簽真值之間的像素重合度。本文中MIoU的取值范圍為[0,1],如果MIoU值越大,則說明預測的分割結果圖越準確[13]。
3.1 不同骨架網絡模型對比
通過目視解譯表1中的不同骨架網絡結構分類結果可以發現,4種骨架網絡結構對于大面積區域范圍的河流水體均進行了有效的提取,但是對于小面積區域范圍的河流水體,不同骨架網絡結構之間的提取能力相差較大,這一點在區域(a)和區域(b)中表現明顯。其中Xception骨架網絡的河流水體提取結果與ResNet骨架網絡的河流水體提取結果相比差距較大,提取結果不夠完整,存在著明顯的間斷與缺失漏提,在小面積河流水體研究區表現最為嚴重。縱觀4塊區域的影像分類結果,ResNet-50的河流水體提取效果相較于其他網絡結構存在著小幅提高,這一點在區域(b)和區域(d)中有明顯的體現,同時在云霧的山區河流水體研究區表現出較好提取效果,但在城市區域的細長河流水體區域存在明顯的漏提。

表1 不同骨架網絡結構分類結果
3.2 不同方法河流水體提取對比
本文選取了最鄰近分類法、隨機森林分類法、支持向量機分類法(support vector machines,SVM)[14]、原始DeeplabV3+模型法、改進DeeplabV3+模型法5種分類方法進行對比,各算法提取結果如表2所示。其中區域(a)、區域(b)、區域(c)以山區河流水體為主,區域(d)以城市河流水體為主,各區域中均包含了難以提取的小目標河流水體。區域(b)包含了云霧陰影干擾,區域(c)和區域(d)更是在河流水體顏色上與區域(a)和區域(b)進行了區分,以此驗證本研究模型在不同河流水體的提取適用性。
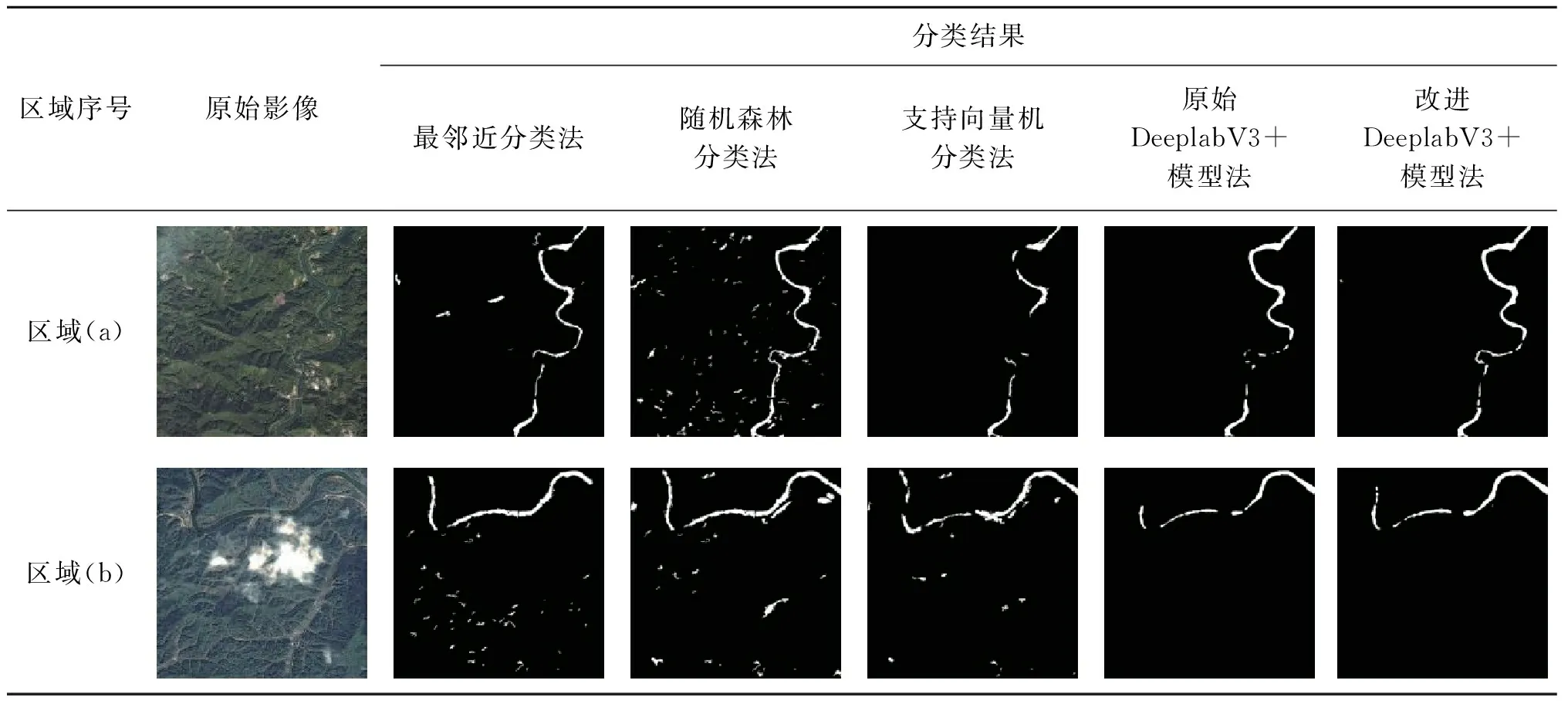
表2 不同方法河流水體分類結果
通過目視解譯表2中的河流水體提取結果可以發現,采用最鄰近分類方法進行河流水體的提取,可以較為精確地提取到大面積區域的河流水體,但是在陰影和小面積河流水體區域的容易造成漏提,同時在光譜和紋理與河流水體相似的區域容易造成誤提。采用隨機森林分類方法和SVM方法進行河流水體的提取,雖然能很好地區分出了水體,但是在非水體區域,尤其是山林區域、小面積河流水體和狹長狀地物區域,由于光譜和紋理相似性問題容易出現誤提和漏提,同時影像噪聲還會干擾分類結果,導致小面積河流水體提取困難。原始DeeplabV3+方法模型較好地提取出了大面積的河流水體,同時還沒有受到非水體區域的影響,很好地將河流水體和非水體區域區分了出來,河岸邊緣處的分類結果也比較理想,較隨機森林分類方法和SVM方法的分類結果更加光滑和精確,但是原始的DeeplabV3+模型方法對于小面積區域的河流水體和細長河流水體的提取能力不足,存在較為嚴重的漏提現象。本文針對此現象,提出了改進DeeplabV3+模型方法來提取河流水體,整體效果得到了一定的提升。改進后的DeeplabV3+方法不僅延續了原始方法能夠很好地區分水體和非水體區域,較為精確地提取到河流水體區域的同時,通過增強對小面積的河流水體的提取,有效地對小目標、小面積河流和細長河流提取能力不足的問題進行了改善。
3.3 不同方法提取結果精度評價
本文通過人工標注的河流水體數據作為參考圖像,分別對實驗中的5種提取方法和4塊研究區域進行了精度評價,結果如表3和表4所示。根據表中數據可以得出,在誤提率方面,隨機森林分類方法的誤提率最高,達55.74%;SVM方法和最鄰近分類方法的漏提率次之,達51.37%和45.85%,主要是因為小目標河流水體區域的周圍存在較多的干擾以及區域(b)中河流水體和植被紋理相似,導致傳統方法提取結果不夠精確。但是在區域(b)中,原始DeeplabV3+和改進DeeplabV3+模型方法的誤提率明顯低于傳統提取方法。同時在其他研究區域,深度學習的誤提率也明顯低于傳統方法。可以由此得出,深度學習方法在分類精確度上是明顯優于傳統分類方法的。在漏提率方面,改進DeeplabV3+模型方法的漏提率最低,達2.61%;SVM方法的漏提率最高,達42.36%。通過對比原始DeeplabV3+模型方法和改進DeeplabV3+模型方法的漏提率,可以看出本研究DeeplabV3+模型方法的改進取得了明顯成效,漏提率相比于原始DeeplabV3+模型方法平均降低了46.97%,明顯低于傳統提取方法。在總體精度和Kappa系數方面,最鄰近分類方法略優于隨機森林分類方法和SVM方法,但都低于深度學習方法。改進后的DeeplabV3+方法較其他4種方法在總體精度和Kappa系數指標上均有提升,總體精度相比于傳統方法提升了1.22%,相比于原始DeeplabV3+模型方法提升了0.19%;Kappa系數相比于傳統方法提升了0.23,相比于原始DeeplabV3+模型方法提升了0.04。可以發現,改進后的DeeplabV3+模型方法的精度評價均優于其他方法。本研究所改進的DeeplabV3+模型方法可以有效區分河流水體和非河流水體區域,提高了原始DeeplabV3+模型方法的提取精度,對于原始DeeplabV3+模型方法進行了一定程度上的改善。
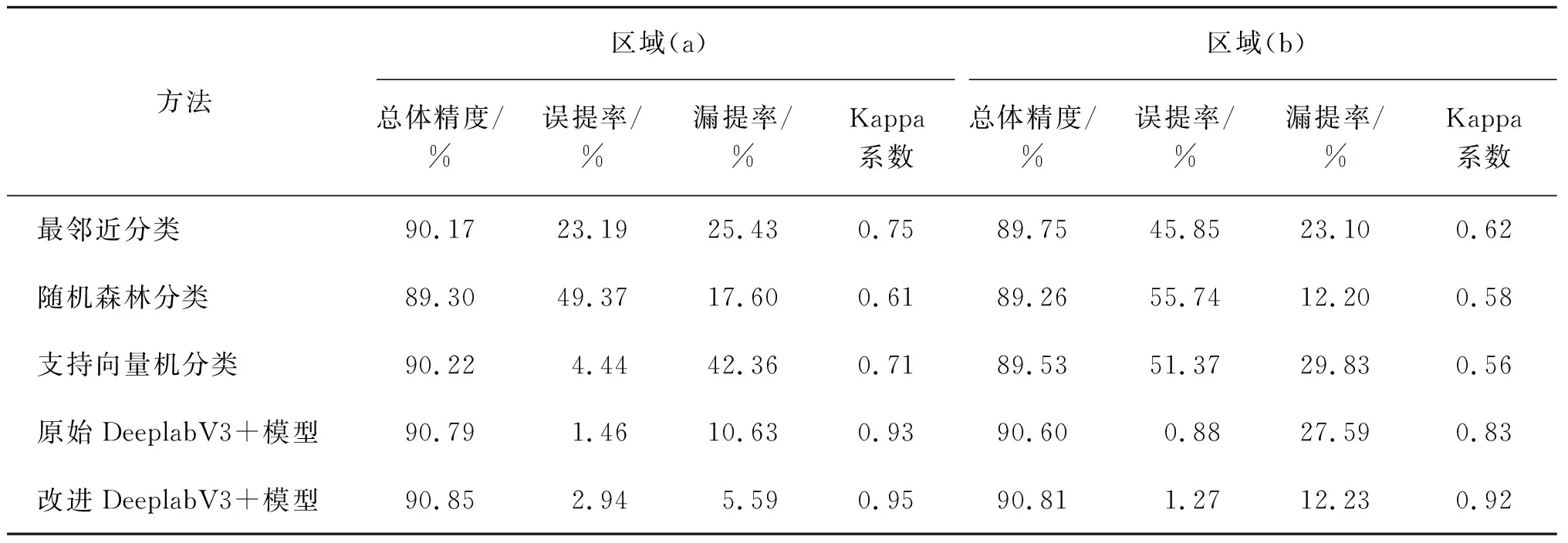
表3 區域(a)和區域(b)河流水體提取精度評價
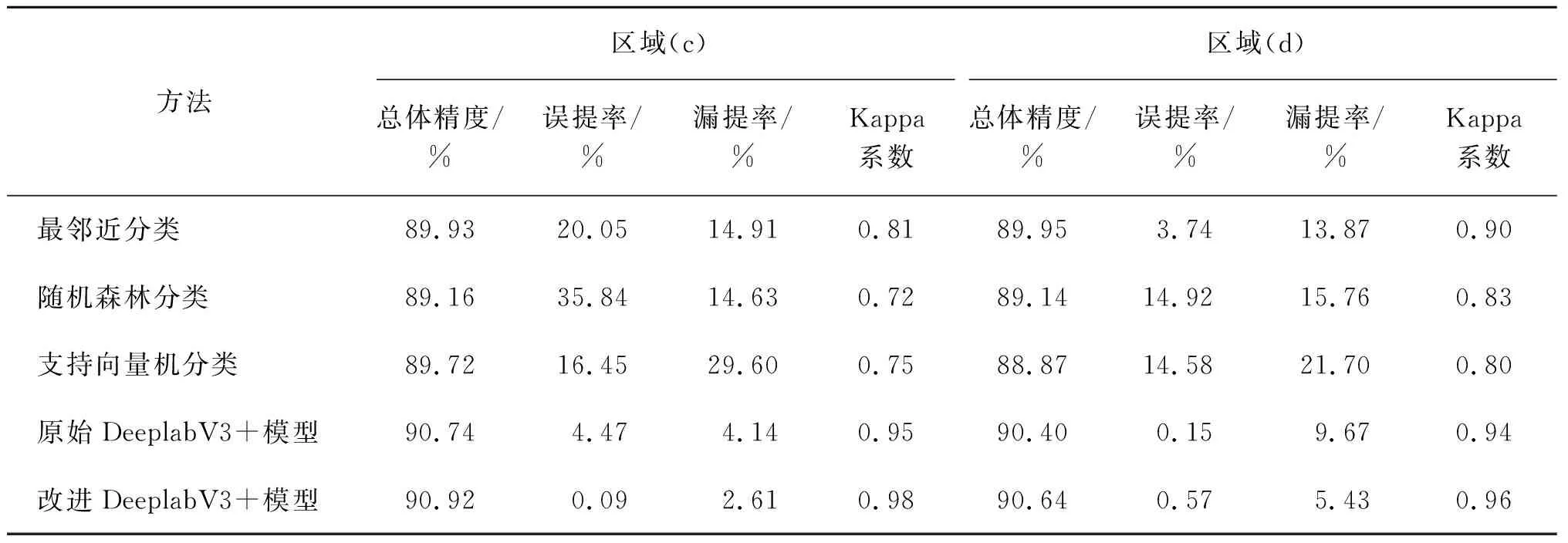
表4 區域(c)和區域(d)河流水體提取精度評價
4 結束語
本文基于高分辨率遙感影像,探究了DeeplabV3+模型在不同骨架網絡模型時的河流水體提取能力,通過構建ResNet-50、ResNet-101、ResNet-152、Xception 4種不同骨架網絡的DeeplabV3+模型進行河流水體提取研究的分析對比,得出了ResNet-50骨架網絡相比于其他骨架網絡模型具有更高的河流水體提取精度和較低的時間消耗,在河流水體提取更具有適用性。
同時本文針對小目標的河流水體,對DeeplabV3+模型方法進行了一定的改進,能有效地對小目標河流水體信息進行提取,而且具有抗云霧陰影和建筑物等干擾影響的提取適用性,且相對于原始DeeplabV3+模型方法有了小幅的精度提升,同時精度更優于最鄰近分類法、隨機森林分類法和支持向量機分類法等分類方法。
但是本文針對于小目標河流水體的提取研究僅獲得了一定的精度改善,未能完整地提取出小目標河流水體信息。因此,如何完整地提取出小目標河流水體信息,將是進一步研究的重點。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
