技術倫理視角下ChatGPT對學生培養的辯證影響研究
2023-09-03 15:46:16魯云鵬李春玲
中國大學教學 2023年7期
魯云鵬?李春玲

摘 要:從技術倫理角度出發,依照“數據—算法—功能”運作邏輯,辯證分析了ChatGPT對學生培養的影響。總體來看,ChatGPT性能高效穩定、對用戶友好且互動性強,具有較強的場景通用性,是培養學生的有效技術工具;但ChatGPT也會引發對學生培養的反向馴化、認知弱化、偏見學習等諸多倫理風險。基于此,本文利用技術倫理中的“規約”思想,提出面向學生培養的人工智能“RED”規約模型,即通過綜合運用制度規約、技術設備規約,以及課程設置規約,推動ChatGPT與學生培養體系間的動態平衡與互適。
關鍵詞:ChatGPT;技術倫理;學生培養;影響機理
一、問題的提出
人工智能研究公司OpenAI于2022年底面向社會公眾發布的聊天程序ChatGPT,其依靠龐大的語料庫支撐、高度通用化的使用場景、強自然語言交互能力等諸多優勢,能夠迅速捕捉用戶的真實意圖,高質量完成論文撰寫、翻譯、編程等任務,也因此僅用兩個月時間,便獲得超過1億活躍用戶的青睞。ChatGPT在文字處理上的能力,也迅速滲透教育、科研領域中。一方面ChatGPT能夠啟發學生寫作靈感,降低機械化課業負擔;另一方面,學生利用該智能工具代寫論文、考試作弊等現象也屢見不鮮,對教育公平、科研誠信等帶來直接沖擊。對此,Nature一周內連發兩篇文章討論ChatGPT對學術圈所產生的影響,巴黎政治學院、香港大學等高校更是直接禁止學生及教職工使用ChatGPT完成任何教學任務,若違規則最高面臨被開除的風險。
然而,從技術倫理的視角來看,科技發展具有不可逆的特征。面對ChatGPT這一具有“現象級”影響力的人工智能工具,在教育領域中對其“一禁了之”,并不能解決現有問題。事實上,包括谷歌公司的BERT、微軟旗下的Turing NLG,以及百度的“文心一言”等一眾“類ChatGPT”產品,也在不斷完善自身的數據庫與算法,高性能人工智能時代來襲的趨勢,已越發明朗。與此同時,技術上的革新也帶來社會對人才能力需求的變化。特別是對于相對缺少創造力、程序化的中等技術工作,均較高程度上面臨被人工智能替代的風險。但焦慮并非理性之舉,通過倫理介入,推動ChatGPT這類高性能人工智能工具與現有教育的人才培養體系互適,才是實現兩者在結構張力上保持動態平衡的良性路徑。
二、ChatGPT對學生培養的辯證影響機理
ChatGPT的工作流程是基于“數據—算法—功能”的邏輯展開的,其中數據是訓練與優化ChatGPT的必要材料,而算法作為處理數據的手段,將直接影響到ChatGPT的性能表現,功能則是ChatGPT工具屬性的具體表征形式,是算法應用目標實現的直接體現。因此要細化分析ChatGPT對學生培養的影響,關鍵在于有效識別這三個基本要素作用機理。
1.ChatGPT的數據對學生培養的影響機理
(1)數據的產生過程
作為高性能的大型語言模型,ChatGPT的數據產生渠道廣泛,包括但不限于公共網頁、維基與百度百科、開放數據源等,涵蓋各類語言、文化與主題。在數據生產的規模上,ChatGPT的模型參數量超過1750億。依照大模型的性能遵循伸縮率(Scaling Law)的原則,大模型的參數越多,數據集的規模越大,其性能與泛化能力就越強,并且這一性能并非簡單提升,當數據規模突破千億時,其上下文學習、利用思維鏈等能力,會有跳躍性增長[1]。寬范圍、大規模的數據產生方式,使得ChatGPT建起頗為豐富的數據池,這不僅能在很大程度上增強數據魯棒性,同時也能夠提升其場景的通用性,為不同領域的學生在識記性知識、推理性問答、多語言翻譯等方面提供數據支撐。
但另一方面,數據作為能夠被ChatGPT識別的數字符號集合,其產生的過程仍舊遵循弱人工智能的實證主義邏輯。將包括思想文明、生活經驗等在內的各類信息進行單一且精確的量化衡量,以轉化為弱人工智能可以理解的語言,并通過可重復試驗的方式,預測與回應人的需求[2]。然而,ChatGPT在數據產生過程中的量化思維,并非完全適合學生培養,因為在教育過程中,存在大量無法測度的“知、情、意”等默會知識,并且學生培養本身就應該充滿不確定性與模糊性,目的在于保護學生的天賦,為學生個性化發展提供更多可能性。正如多梅爾所提及的,無論我們的意圖多么符合科學精神,只要開始量化,就會造成狹隘性[3]。
并且這種數據生產邏輯的狹隘性,容易被ChatGPT數據產生的范圍廣、規模大所掩蓋,引導學生形成“一切皆可量化”的數據崇拜,盲目追捧大數據所帶來的知識的“真與全”,而忽視難以被數據量化表達的“善與美”。
(2)數據的采集過程
數據采集是基于數據源獲取數據的過程,對于ChatGPT而言,其首先是在人工干預下,確定數據采集的需求,包括數據采集的來源、類型、頻次等指標,并依照歐盟的《通用數據保護條例》、中國的《網絡安全法》等,明確數據采集的法律與倫理標準。其次,ChatGPT依照數據采集的實際需求與標準,自動設計與運行數據采集器。再次,對抓取的數據進行清洗,涉及自動對數據去重、格式化、標準化等。為了保證數據質量,這一過程也會有少量人工參與,對數據清洗進行評價與優化。最后,對采集到的數據進行存儲與管理。
聯合國教科文組織在《教育中的人工智能:可持續發展的挑戰與機遇》中指出,數據采集要重視公正性、避免數據歧視等技術倫理問題。盡管ChatGPT在現有的技術范圍內,盡可能擴大數據樣本量,人工評估數據清洗結果,但仍舊無法避免因數據本身的缺失、語言理解差異、算法缺陷等原因,造成的特定區域、社會群體或文化背景的數據采集頻率失衡的現象。ChatGPT只是相較于GPT-3等技術,在“有毒”回答的輸出的概率上會有所降低。
(3)數據的共享過程
在教育領域中,因人工智能在數據共享過程中造成的用戶信息泄露,是現有技術倫理關注的重點問題。這一方面是由于數據本身具有高傳播、高流通、再生再創等特性,另一方面則是受到利益驅動的影響,關于學生的數據會成為智能教育商業機構相互交易或分享的商業數據,部分組織甚至非法利用這些數據,進行惡意欺騙[4]。對此,ChatGPT的所屬公司OpenAI,高度重視保護數據隱私和安全,在其組織章程中將“開發安全和負責任的人工智能”作為使命,并從技術角度,通過數據脫敏、限制訪問權限、多重加密與身份驗證技術等多種方式加以保障。
但同時OpenAI多以保護數據安全、知識產權、技術競爭、成本等為理由,并未對ChatGPT實現開源并有效公開其訓練的數據集。這實質上不僅違背其作為非營利組織在推動人工智能發展、創造透明人工智能技術上的承諾與初衷,也與聯合國在《人工智能倫理問題建議書》中所倡導的算法可解釋、可理解不相符。這顯然對立了數據保護與數據共享間的關系。源代碼、數據等未能有效共享,也將加劇技術壁壘、數據獨裁等問題產生。對于學生培養而言,由于無法獲取到足夠的數據與源代碼資源,也將使得教育者難以通曉ChatGPT在教育領域中的算法原理、過程等,削弱教育主體對于學生培養過程中風險管理與控制能力,放大基于數據黑箱而帶來的倫理風險。
2.ChatGPT的算法對學生培養的影響機理
(1)深度學習模型
ChatGPT的深度學習算法具體為卷積神經網絡、生成對抗網絡等。成熟、多樣的深度學習算法,使得ChatGPT能夠應對龐大規模且多樣態的數據資源,并高效提取數據特征,建立復雜的非線性關系,推動自然語言生成的連貫性與準確性,特別是上下文對話的銜接能力,能夠有效提升包括學生在內的用戶體驗感。
但需要注意的是,在無有效的倫理規約與技術限制條件下,ChatGPT的高性能容易讓學生產生依賴性。而對于技術物的過度依賴,容易侵犯教育場域的連續性與完整性,并弱化學生作為教育主體,對于教育現實的感知[4]。連續且完整的教育場域是由教師、同學、教室、教材、學習氛圍等諸多物質與精神元素構成的有機統一體,其內在的豐富性塑造學生個體在知識、技能、情感交流等各方面的發展。ChatGPT雖然能夠借助深度學習模型,高度模仿人類,提供基于對話式的虛擬學習空間,但若沉溺其中,則會破壞學生對教育現實的參與度,進而加劇個人主義學習,肢解圖書館、教室等傳統學習場所的公共性。教育場域中的虛擬與現實失衡,往往也會帶來學生在學習過程中的情感生成與社交表達困境,并誘發學生的情感遮蔽,形成現實本我與虛擬非我的主體性異位現象。
(2)強化學習模型
強化學習是人工智能依據特定環境反饋,學習如何采取最佳行動,以實現獎勵信號的最大化。以與ChatGPT模型高度相似的InstructGPT為例,InstructGPT通過標記員的人工標記的方式來訓練反饋模型,讓反饋模型再訓練原有的GPT-3模型,從而實現基于人類反饋的強化學習。ChatGPT在InstructGPT的基礎上,借助其用戶界面,在每次生成對話答案旁,均有類似“有用”和“無用”圖標,用于實時獲取更為廣泛的用戶反饋信息,利用強化學習模型,不斷優化其語言表達與信息傳遞準確性,提升人機的交互效果。
ChatGPT基于人類反饋的強化學習模型,其技術的出發點是凸顯人的主體性的地位與價值。即使ChatGPT性能再優異,仍舊是圍繞人類的需求展開。畢竟計算機只有和人結合在一起才能實現其價值,人賦予人工智能活動的意義,這是由其作為技術工具屬性所決定的。然而,在現實的教育場域中,卻容易出現截然相反的結果,人工智能沖擊學生主體性的地位,使其再次成為“被塑造”的對象。ChatGPT通過及時捕捉學生的反饋,借助Q-Learning、自然語言處理技術等,在動態調整與優化答案、增加學生信任的同時,也能夠不斷分析特定領域、專業的學生的行為與偏好特征,進而對學生進行“標簽化”處理。這并不利于學生開闊自身視野,ChatGPT會基于學生偏好不斷強化學生的特定認知,從而容易將其塑造成狹隘、封閉的個人。此外,缺乏足夠的辨別能力,過度信任人工智能的“出色”表現,會使得學生發展的可能性從最初便被人工智能所規劃,違背學生發展的基本規律[5]。
(3)自適應學習模型
對于ChatGPT而言,自適應學習模式是通過搜集與分析數據,利用Transformer架構、多層自注意力機制來挖掘數據間的規律性與關聯性,以迭代、更新其自身算法與知識庫的過程,其目的在于不斷適應外部環境與任務的變化,是ChatGPT靈活性與智能性的集中體現。現有觀點多認為,具備自適應學習能力的弱人工智能,能夠依照學生的學習進度、學習風格與學習能力等信息對學生的學習任務實施精細化管理,為學生提供個性化、動態化的學習建議與培養方案[6]。該特性是現階段推廣智能教育的重要優勢所在。
但ChatGPT只是從技術角度上,能夠為學生個性化學習提供可能,并沒有有力的證據表明,引入ChatGPT等弱人工智能就一定能實現學生個性化學習。相反,教師簡單布置任務,學生被動詢問,人工智能負責判斷提供,反而可能會妨礙學生個性化發展潛能的激活。ChatGPT所應用到的自適應學習、深度學習等,本質上仍舊是基于概率統計的算法模型。依照學生偏好所提供的答案,是基于數據庫中的頻率“多”,是大眾化、普遍化、平均化的行為或決策反應,那些新奇、“意外”的信息,會因為數量上的“少”而被算法過濾掉,這反而會誘發學生同質化發展。與此同時,ChatGPT依照學生不同需求快速篩選出的答案,只是在形式與結果上看似個性化,但其底色仍舊是基于效率導向的標準化,甚至在自適性學習、強化學習的引導下變得“媚俗化”,這顯然也與教育所期待的學生個性化發展理念所不符。
3.ChatGPT的功能對學生培養的影響機理
(1)學生培養過程中ChatGPT的功能鏈
ChatGPT的功能主要是基于大規模數據與算法,模擬人類在語言上的能力。具體包括:其一,語言生成功能。ChatGPT能夠依據學生輸入信息的提示與要求,自動生成多種類型的文本,如文章、對話、評論等。這是ChatGPT在學生群體中,使用頻率較高的實用功能,據在線課程供應商Study.com的調查顯示,有89%的美國大學生借助ChatGPT生成作業文本。其二,語言理解功能。ChatGPT能夠依照上下文和語義信息,回答學生提出的各類問題,并給出建議。如果提供的是豐富的文字材料,還能進行文本的總結與推理等。其三,語言翻譯功能。ChatGPT還支持包括中、俄、德等超過50種語言之間的實時翻譯與轉換。此外,隨著OpenAI開放了ChatGPT的接口,諸多可應用于教育領域中的軟件或平臺也接入ChatGPT中,從而形成更為豐富的功能鏈。
(2)審慎對待ChatGPT在教育領域中的功能鏈
首先,過分強調ChatGPT所帶來的減負性與趣味性,容易引發情感投入與認知投入的失衡,弱化學習的嚴肅性。依據學習投入理論的觀點來看,高質量的學習涉及認知投入、情感投入與行為投入這三個關鍵要素[7]。ChatGPT利用其減負性與趣味性,增加學生的情感投入,但ChatGPT也容易掩蓋認知投入的重要性,即學生個體需要對所學的內容進行獨立思考、理解與記憶。ChatGPT瞬時呈現答案,這種帶有“不勞而獲”意味的學習方式,容易滋生學生認知投入的惰性。更為重要的是,學生個體必要的認知投入,包括復述、記憶等低階認知,在“熟能生巧”機制的催化下,是批判性、創新性等高階思維產生的必要條件。而ChatGPT的長期介入,替代初級信息加工的方式,則會打斷這一過程,加之上文提到的學生可能產生的數據與算法崇拜、自主性缺失等問題,淺表性思維、慣性思維等反而會得到固化,不利于學生精致思考、意義構建與自我指導。
其次,過分強調ChatGPT所帶來的減負性與趣味性,也容易制造學生培養的“虛假需求”。馬爾庫塞認為,技術理性以控制并滿足個體“虛假需求”為作用機制,促使個體對于否定性、批判性、超越性的喪失,進而喪失“自由”,成為“單向度的人”[8]。ChatGPT通過多樣化的功能表征,極大滿足學生對于效率的需求。特別是在人才競爭日趨激烈的當下,效率成為檢驗該工具“有用性”的最為重要的衡量標準。但從技術倫理角度來看,效率并非是教育主體的真實需求。真實需求是以自由、平等為基礎,建立在主體性、主體間性以及他者性間的主體呼喚[9]。無論是對自由、平等抑或是責任的價值理性追求,是不能因為ChatGPT的技術理性所帶來的效率需求所掩蓋,一味追捧效率只會為教育相關者帶來功利主義。
再次,過分強調ChatGPT所帶來的減負性與趣味性,也會導致教師在學生培養中的角色錯位的現象。這種現象可利用技術倫理中的“反向馴化”加以解釋。技術物能夠按照人類意圖實現自身功能,協助人類“解蔽”,其本身可看作是一種對技術物的“馴化”過程。然而,隨著技術物與人類不斷融合,兩者之間的關系則會存在異化的可能,技術的意向結構,逐步“規訓”人類,給人類打上技術的“烙印”,實現反向馴化[10]。典型的如智能手機已經改變了人類閱讀偏好以及語言表達的習慣。對于教師而言,人工智能本應被馴化為協助教學、分擔部分重復性知識傳遞工作的工具。但由于人工智能的高性能表現,教師反而會依照人工智能的算法,決定如何傳遞教育內容,采用何種教育方式,教師從學生培養過程中的創造者,反而變成了“消費者”[3]。教師被人工智能反向馴化,站在“消費者”的視角將使其難以對學生培養保持應有的洞察力,以及失去對學生示范性引領的魅力。
綜合上述,圖1依照“數據—算法—功能”的邏輯,總結了ChatGPT對學生培養的影響機理。總體來看,ChatGPT性能高效穩定,對用戶友好且互動性強,具有較強的場景通用性,是培養學生的有效工具;但ChatGPT具有打斷性特征,在使用過程中也會引發反向馴化、認知弱化以及偏見學習等倫理風險。
三、ChatGPT影響下學生培養的創新模式
針對ChatGPT打斷原有的學生培養體系的平衡態,可能引發諸多倫理問題,本文基于技術倫理中的“規約”思想,提出面向學生培養的人工智能“RED”規約模型,即通過綜合運用制度(Regulation)規約、技術設備(Equipment)規約、課程設置(Discipline)規約,以主動適應ChatGPT等高性能人工智能所帶來的影響。
1.制度規約:基于“敏捷治理”設計教育人工智能共識體系
當前從技術倫理角度,各國、區域性合作組織等均對人工智能進行制度規約,基本形成了人工智能設計與應用的共識體系。但現有的制度規約多以“倡導式”的軟約束為主,多具有形式上的威懾效果,但實際的實施效力多取決于OpenAI等人工智能公司的自愿性。采用這種相對溫和的制度規約方式,主要是由于現階段包括ChatGPT在內的人工智能仍停留在弱人工智能階段,處于發展初期,若強硬監管很可能會出現“把嬰兒和洗澡水一起倒掉”的風險,影響人工智能的發展進程。考慮到平衡制度規約與人工智能技術關系的約束性,本文主張在現有軟約束的基礎上,設計基于“敏捷治理”的制度規約。
敏捷治理是源于軟件開發領域中的“敏捷方法”,其強調通過迭代等持續改進的方式,快速響應外部變化,以創造高價值。其治理目標是在不犧牲治理有效性的前提下,盡早作出反應與決策,高效準確地回應智能時代復雜的倫理與社會問題。具化到ChatGPT等高性能人工智能在學生培養領域中來,由于對人工智能技術快速且打斷性的發展缺乏預測性,因此制度的規約目標應隨著學生培養的變化而及時調整,這需要在尊重人工智能發展規律的前提下,敏銳捕捉并重視新人工智能技術可能引發的新技術倫理風險。在此基礎上,基于現有人工智能規約的共識原則,政府監管部門應積極組建針對教育領域的跨區域人工智能治理專業委員會,并協同人工智能開發商、學校等主體,將捕捉到的倫理風險,通過持續優化原有制度規約的方式,及時回應社會所關注的學生被量化、數據崇拜、自主性受侵等熱點問題。
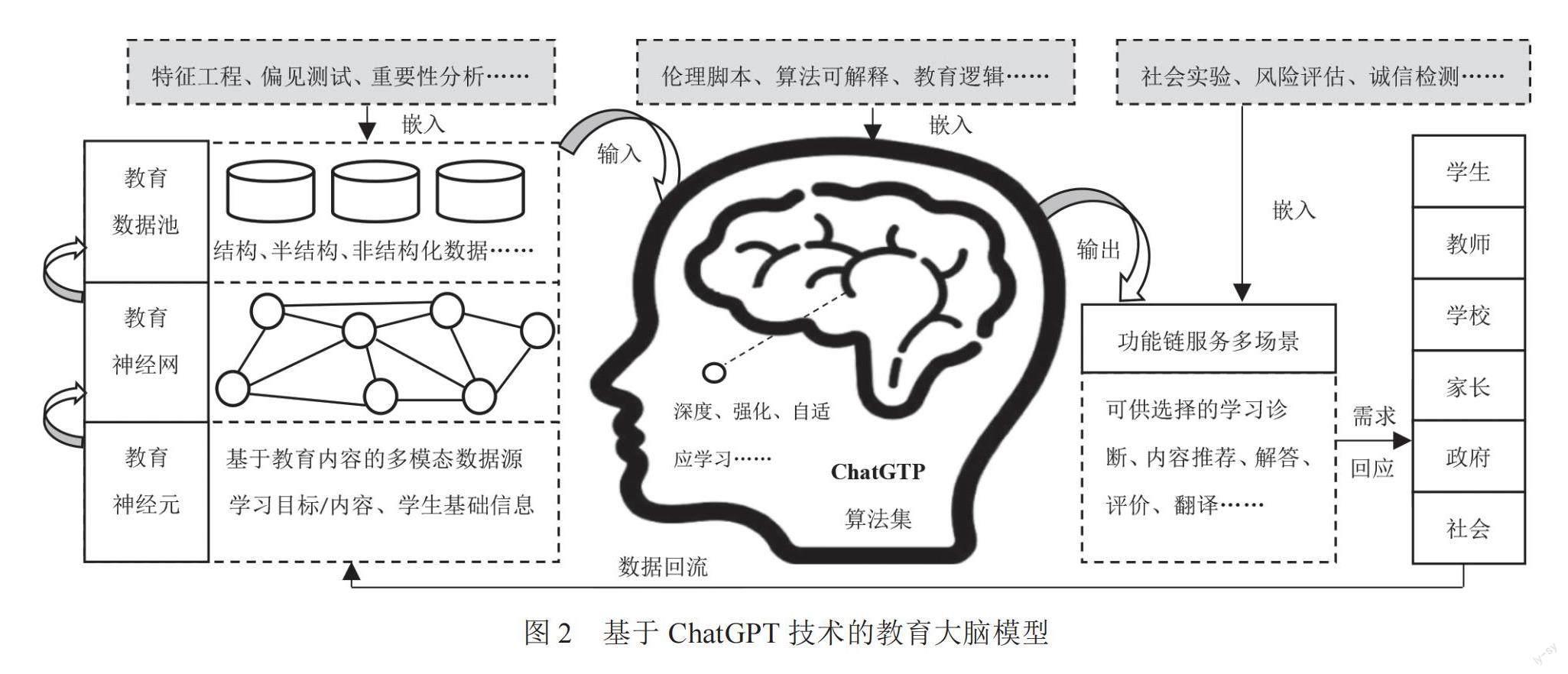
2.技術設備規約:協同構建基于ChatGPT的“教育大腦”
雖然ChatGPT表現出較強的場景通用性,但是教育領域具有默會性、模糊性等特殊屬性,若想真正將ChatGPT技術融入學生培養,則需要依照教育的實際問題、教育邏輯、教育規則等內容,從技術設備角度對ChatGPT進行規約,主動開發專屬于教育的核心模型、框架,而不應是其他領域的“模仿者”。結合現有智能教育發展趨勢,以及ChatGPT對學生培養的影響,圖2通過嵌入技術設備規約的方式,嘗試構建了基于ChatGPT技術的“教育大腦”模型。所謂教育大腦,是人工智能作為海量教育數據模型、深度學習算法等智能化技術的融合體,能夠模擬人類大腦接收、處理信息的特質,并根據實時反饋進行動態調整[11]。其構建的目的在于智能時代下,解決教育學生培養創新問題,提升人工智能技術與學生培養體系相融合的理想度水平。教育大腦的構建多是遵循人腦“輸入—計算—輸出”的基本邏輯展開,這與上文所提及的ChatGPT依照“數據—算法—功能”運作方式是相吻合。
在輸入環節中,ChatGPT將學生基礎信息、培養目標、學習內容、教學活動等作為專業化的外部信息源,利用自身在處理文本、圖像、語音等多模態信息上的能力,進行數據采集。每一份數據可看作是類腦的教育神經元,這些龐大數據彼此相互聯系,構成教育神經網絡,并以結構化、半結構化等多元形態進行存儲與加密,為類腦運算提供“燃料”。在這一過程中,需要嵌入特征工程、偏見測試、重要性分析等技術,用以規約ChatGPT在數據產生、采集、存儲等環節中,所可能引發的數據歧視、偏見學習等倫理問題。
在計算環節中,ChatGPT利用深度學習、強化學習等算法集,模擬人腦對規約后的輸入信息進行編碼,并完成比較、轉換、推理等“思維”活動。在該過程中,可通過“道德矩陣”、監督學習等技術規約的方式,對算法進行調適,以嵌入符合人才培養期望的倫理腳本,調解技術意向性在教育情境中的價值指向。此外,由于教育是一種解釋性的行為,教育過程正是不斷將緘默知識透明化的過程,因此它要求教育者需通曉整個教育原理、內容與過程,這也決定將ChatGPT應用于人才培養領域中,需要算法保持可解釋性,開發者應對教育領域的算法進行規范化的闡釋與說明。例如可通過局部敏感性分析技術、人機交互、可視化等技術方式,協助教師、學生明確這些算法的前提假設,算法可能忽略的因素,以及因此可能帶來的主體異化、同質化等負面影響,為真正的個性化教育提供更優算法支撐。
在輸出環節中,應進一步利用ChatGPT在語言生成、理解與翻譯等方面的能力,協同教師、學生、學校、家長等多元主體,通過整合現有教育資源,開發更具專業性的功能應用,用以涵蓋學習診斷、內容推薦與問答、教學評價與反饋等完整的人才培養環節,實現教育大腦與內外環境的互動。開發基于ChatGPT技術的教育大腦的應用,應堅持教學導向而非技術導向,由教育利益相關者需要什么樣的人才與培養模式來決定需要什么樣的應用,而非反向馴化關系。對于教育主動權的把握,可通過社會實驗、風險評估、誠信檢測等技術手段進行規約。在回答學生提問時,也應保持開放性原則,其答案盡量減少確定性詞匯的描述,并提供更多備選方案,引導學生主動思考。
3.課程設置規約:更廣范圍下有機嵌入人工智能素養
ChatGPT在人才培養過程中,所帶來的反向馴化、認知弱化等倫理問題,在很大程度上是由于學生、教師等對于高性能的人工智能還未“準備好”。以我國為例,根據教育部公開數據顯示,截至2022年我國共有902所高等院校(含高職)開設或備案人工智能專業,雖然總量穩步提升,但僅占院校總量的29.94%,且大部分是針對計算機專業的學生,通識課、相關基礎課開設數量比例偏低。但人工智能的影響,將涉及各教育水平和收入水平的職業[12]。面對ChatGPT等高性能人工智能對學生在職業技能與自我認知方面的現實要求,應有規劃地面向更廣泛的專業、不同年級的學生,開設人工智能相關課程,優化現有人才培養的課程體系,提升學生人工智能的綜合素養。具體可從人工智能基礎知識、高階認知能力、人文教育三個部分著手。
在人工智能技術基礎知識方面,可圍繞數據素養、算法素養、情景化問題解決的培養開設課程。在數據素養的培養中,學生應能夠理解人工智能如何對數據進行搜集、處理、分析、存儲,以及對整個數據周期進行管理等;在算法素養中,應能理解算法本質、識別算法類型的示例、典型人工智能的算法過程;在情景化問題解決方面,學生需討論與評估ChatGPT等典型人工智能解決實際問題的能力與適用性,并能有效識別特定技術產品、作品是否使用人工智能。
由于ChatGPT在程序化、機械式的初級信息加工任務上具有出色的性能表現,這凸顯出高階認知能力對學生培養的重要性,其主要包括設計思維、批判性思維、創新思維、交互思維與終身學習能力的培養。例如,針對設計思維而言,可開設人機交互課程,強化學生“以人為本”的設計理念,強化個體自主性意識,防范因過度依賴人工智能而帶來思考淺層化、形式化。此外,高階認知能力的培養也對教師在開放性、探究性的任務布置,激發學生思考欲望的教學重點上提出了更高要求。
人工智能越發展,人文教育越重要。這是工具理性與價值理性動態平衡發展的必然要求,也是教育回歸“促進人的全面發展”的具體體現。人文關懷是人區別于弱人工智能的重要標尺,對人工智能技術創新具有價值引領、價值選擇、價值參照等“以道馭技”的重要作用。上文關于ChatGPT教育大腦的構建,所涉及的倫理腳本、偏見測試,均是從人文角度進行的技術規約。重視技術倫理、思想道德建設、美學、科技哲學史等人文課程在各專業、各階段學生培養中的設置與考核比重,是強化學生社會責任感、自我認同感、誠信與平等意識,解決ChatGPT等高性能人工智能所帶來的情感遮蔽、反向馴化等問題的重要手段。
四、研究展望
2023年3月,OpenAI發布了比ChatGPT性能更為強大的GPT-4模型,包括微軟的office 365在內的更廣范圍的學習辦公軟件,也開始走向智能化。高性能人工智能技術快速發展,特別是其意向性、打斷性等特征,決定了人工智能對學生培養的影響是持續且變化的,這需要我們對此領域研究保持應有的專注度,并且這一專注度,是需要通過倫理學、社會學、教育學、計算機等科學間的交叉融合,才能有效實現的。
參考文獻:
[1] WEI J, WANG X, YANG Y, et al. Chain-of-thought: Efficient Content Planning with The use of Pretrained Language Models[C]. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022: 124-133.
[2] 孫田琳子,沈書生. 論人工智能的教育尺度:來自德雷福斯的現象學反思[J]. 中國電化教育,2019(11):60-65,90.
[3] 多梅爾. 算法時代[M]. 胡小銳,譯. 北京:中信出版社,2016:67.
[4] 董云川,韋玲. 人工智能促進教育發展的倫理糾偏[J]. 重慶高教研究,2021(2):51-58.
[5] 劉金松. 人工智能時代學生主體性的相關問題探討[J]. 現代教育技術,2021(1):5-11.
[6] 胡藝齡,趙梓宏,顧小清. 教育生態系統視角下AI驅動的學生核心素養發展模式研究:基于系統動力學方法[J]. 現代教育技術,2022(12):23-31.
[7] FREDRICKS J A, BLUMENFELD P C, PARIS A H. School Engagement: Potential of the Concept, State of the Evidence [J]. Review of Educational Research, 2004, 74(1): 59-109.
[8] 馬爾庫塞. 單向度的人[M]. 劉繼,譯. 上海譯文出版社,2008:104.
[9] 李育球. 主體性教育的三重性:主體性·主體間性·他者性:后形而上學主體性教育內涵的探索[J]. 教育理論與實踐,2010(4):3-6.
[10] SILVERSTONE R. Television and Everyday Life [M]. London: Routlege, 1994:44.
[11] 顧小清,李世瑾. 人工智能教育大腦:以數據驅動教育治理與教學創新的技術框架[J]. 中國電化教育,2021(1):80-88.
[12] FREY C B, OSBORNE M A. The Future of Employment: How Susceptible are Jobs to Computerization[J]. Technological Forecasting and Social Change, 2017, 114(2): 254-280.
[基金項目:國家社會科學基金青年項目(立項編號:22CZZ012)]
[責任編輯:余大品]
