雙線性圖卷積網絡的環南海地區濕地遙感分類
2023-09-04 07:46:50李心媛樓桉君
測繪通報 2023年5期
李心媛,賀 智,2,樓桉君,肖 曼
(1. 中山大學地理科學與規劃學院,廣東 廣州 510275; 2. 南方海洋科學與工程廣東省實驗室(珠海),廣東 珠海 519082)
濕地具有強大的固碳功能[1],在實現我國碳達峰、碳中和目標,構建新發展格局中發揮著重要作用。環南海地區是我國建設“21世紀海上絲綢之路”的關鍵對象[2]。20世紀60年代以來,區域內快速城市化發展導致濕地面積減少,生態功能下降。對環南海區域開展濕地遙感監測,有利于推動全區域濕地整體性、統籌性保護。
濕地類型多樣、斑塊小、類間差異小[3],高分辨率遙感影像能更好地滿足濕地解譯需求。深度學習能有效挖掘遙感數據的深層信息[4],近年來被逐漸應用于濕地分類領域,如卷積神經網絡(convolutional neural network,CNN)、生成對抗網絡(generative adversarial network,GAN)等已在濕地分類中取得了一定成效[5-7]。
圖卷積網絡(graph convolution network,GCN)可對全局空間關系建模,能充分利用深層特征及挖掘對象間的關系[8],在濕地分類中具有巨大潛力。雙線性模型[9]于2015年被提出,適用于細粒度分類,在提高濕地分類精度中具有廣闊前景。基于此,本文提出基于雙線性圖卷積網絡(bilinear GCN,BiGCN)的環南海地區濕地分類方法,以期為環南海地區的濕地監測和保護提供支持。
1 研究區與數據源
1.1 研究區概況
環南海地區共包括9個國家,地處亞熱帶和熱帶太平洋西部區域,全年濕潤,降雨豐富[10]。該區域地理位置優越,具有重要的經濟與軍事價值[11]。本文基于FROM-GLC全球10 m分辨率地表覆蓋數據[12],以分布集中且涵蓋濕地類別多為原則,在環南海海岸帶選擇3塊研究區,如圖1所示。
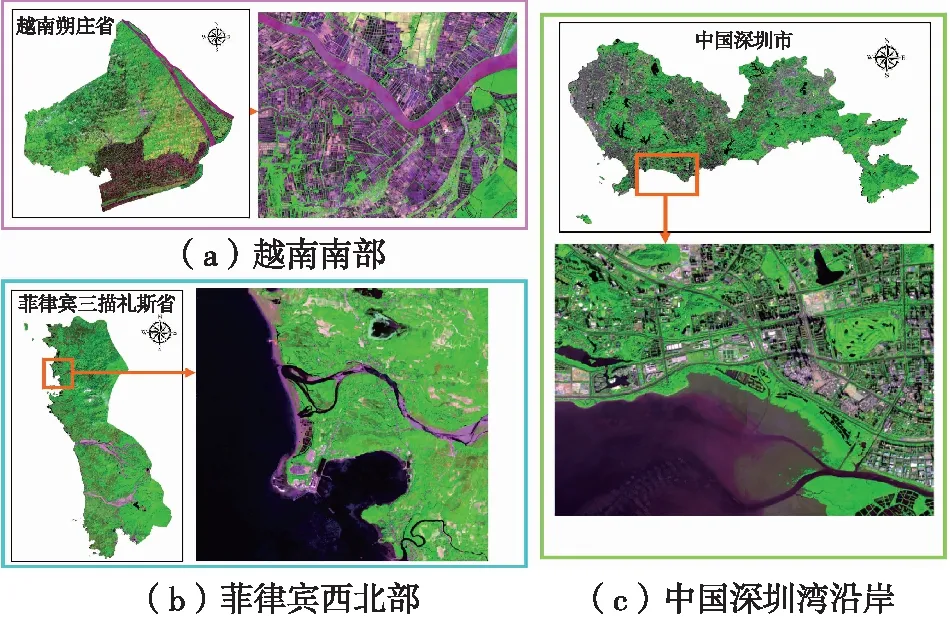
圖1 研究區分布
1.2 數據源與數據預處理
針對濕地分類,選取Sentinel-2多光譜影像為主要數據源,從Google Earth Engine平臺獲取研究區2020年云覆蓋率小于10%的Sentinel-2影像并求出均值;針對濕地特性,選取雷達、河網、地形、物候數據作為輔助,輸入深度學習網絡,以提高對不同類別濕地的辨別能力。數據源信息見表1。其中,雷達數據選用Sentinel-1,GRD級數據產品;河網數據選用OSM(open street map)矢量數據中的water和waterways;地形數據選用SRTM DEM;物候數據在Google Earth Engine上利用全年Sentinel-2影像求出區域空間上每個位置的年最大歸一化植被指數和歸一化差異水體指數,即全年最綠圖和全年最濕圖。
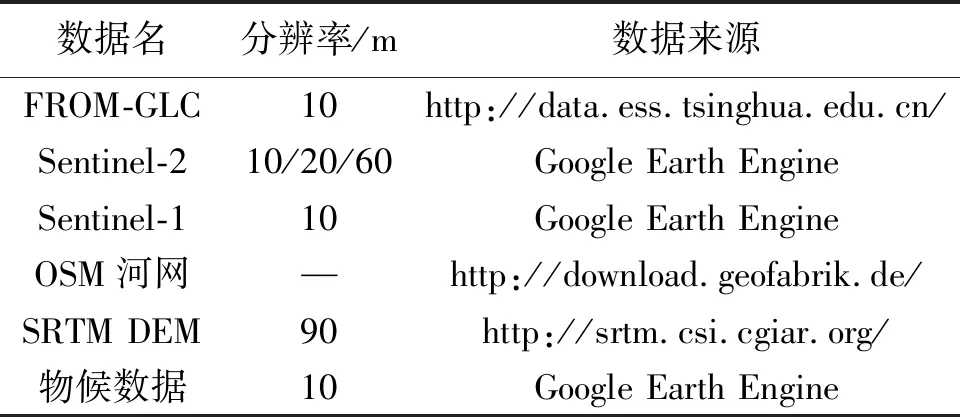
表1 數據源信息
1.3 濕地分類體系與數據集構建
綜合考慮研究區實際情況和現有濕地分類標準,構建環南海地區濕地二級分類體系。遵循各類樣本數目盡量均衡且在空間上均勻零散分布的原則,對3塊研究區進行樣本標記,分別構建越南南部數據集、菲律賓西北部數據集、中國深圳灣沿岸數據集,3個研究區大小分別為959×760、815×885、897×642像素。濕地分類體系及各數據集標記樣本數見表2,標記樣本分布如圖2所示。試驗隨機選取50%的標記樣本作為訓練集,其余為測試集。
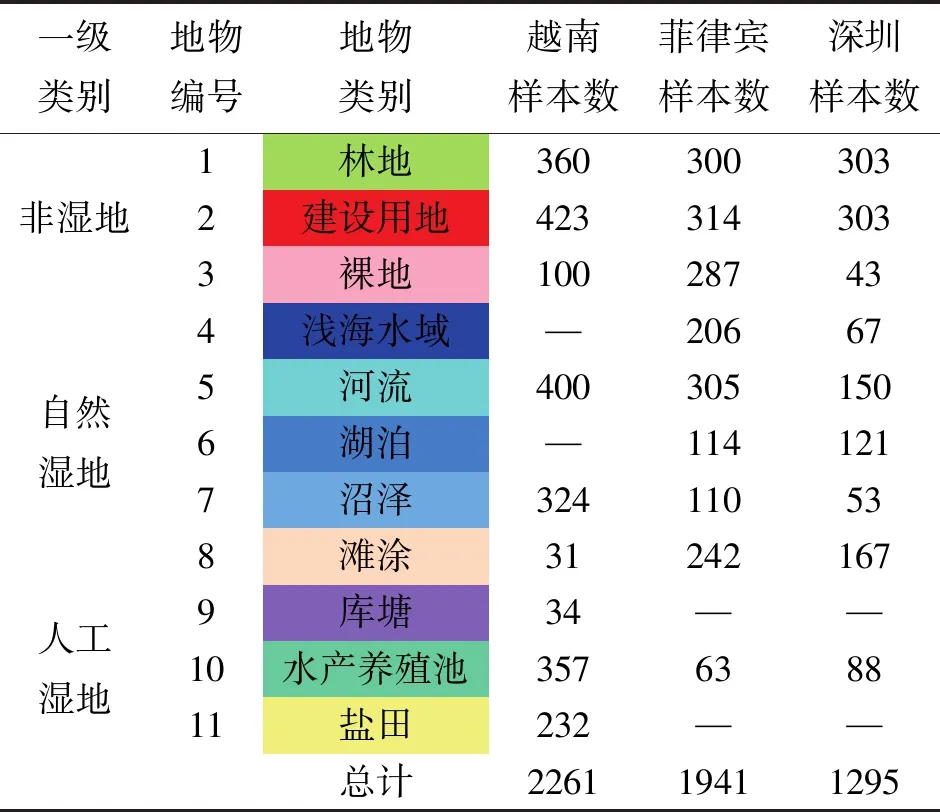
表2 濕地地物分類體系及各數據集標記樣本信息 個
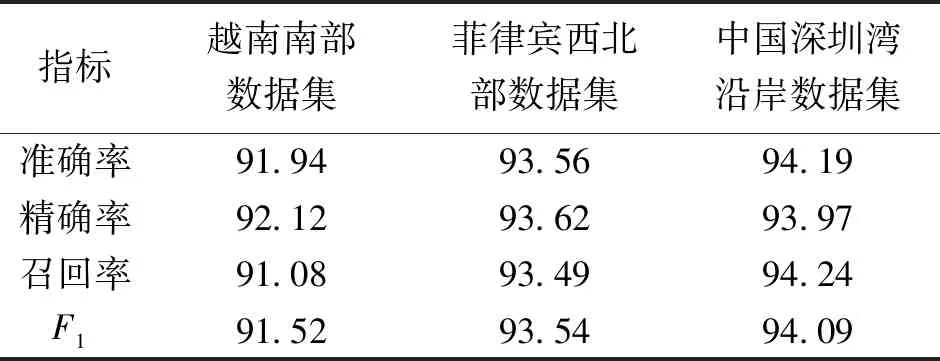
表3 RF二分類精度 (%)
2 研究方法
本文提出的基于BiGCN濕地分類方法如圖3所示。首先,采用多尺度分割方法將多光譜遙感影像提取為對象塊;其次,使用面向對象的隨機森林(random forest,RF)[13]區分濕地與非濕地;然后,對濕地部分基于BiGCN與多源輔助數據進行二級分類,非濕地部分采用隨機森林方法進行二級分類;最后,將兩部分的分類結果相疊加,得到研究區影像分類結果。
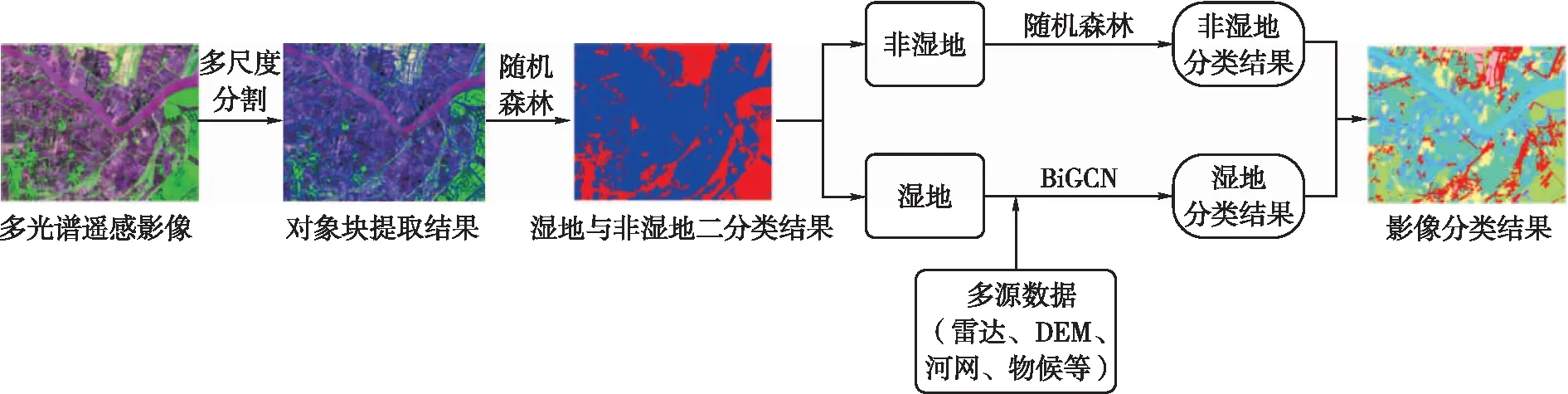
圖3 基于BiGCN的濕地分類方法
2.1 基于多尺度分割的對象塊獲取
采用多尺度分割方法獲取影像對象塊,越南南部數據集、菲律賓西北部數據集、中國深圳灣沿岸數據集分割后的對象塊數目分別約為2000、3300、3000,3個研究區的分割結果如圖4所示。

圖4 多尺度分割結果
2.2 基于RF的濕地與非濕地二分類
為了減小圖卷積的運算量,并提升濕地類內緊湊性和類間的可分離性,利用RF區分濕地與非濕地,獲取濕地掩膜。3個數據集上得到的分類結果如圖5所示。

圖5 濕地與非濕地二分類結果
使用準確率、精確率、召回率、F1值評價二分類結果的精度(見表 3),3個數據集上的分類精度均在91%以上。
2.3 基于雙線性圖卷積網絡的濕地分類
2.3.1 圖卷積網絡
光譜信號間的關系可以表示為
G=(V,E,A)
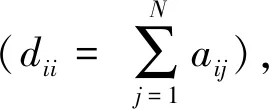
L=D-A
為了提高圖的泛化能力,使用對稱歸一化拉普拉斯矩陣
式中,I為單位矩陣。
定義濾波器gθ=diag(θ)對圖G進行節點構建,它可以理解為標準化圖拉普拉斯矩陣L的特征值的函數。一個圖的光譜卷積可以定義為圖信號s與濾波器gθ的乘積,公式為
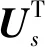
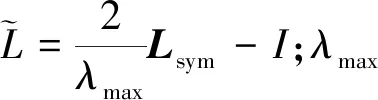
因此,GCN的傳播規則為
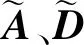
2.3.2 網絡模型結構
BiGCN模型結構如圖6所示,以Sentinel-2、多源輔助數據、分割對象塊及濕地掩膜為輸入,利用多層圖卷積提取抽象特征,最終輸出濕地分類結果。
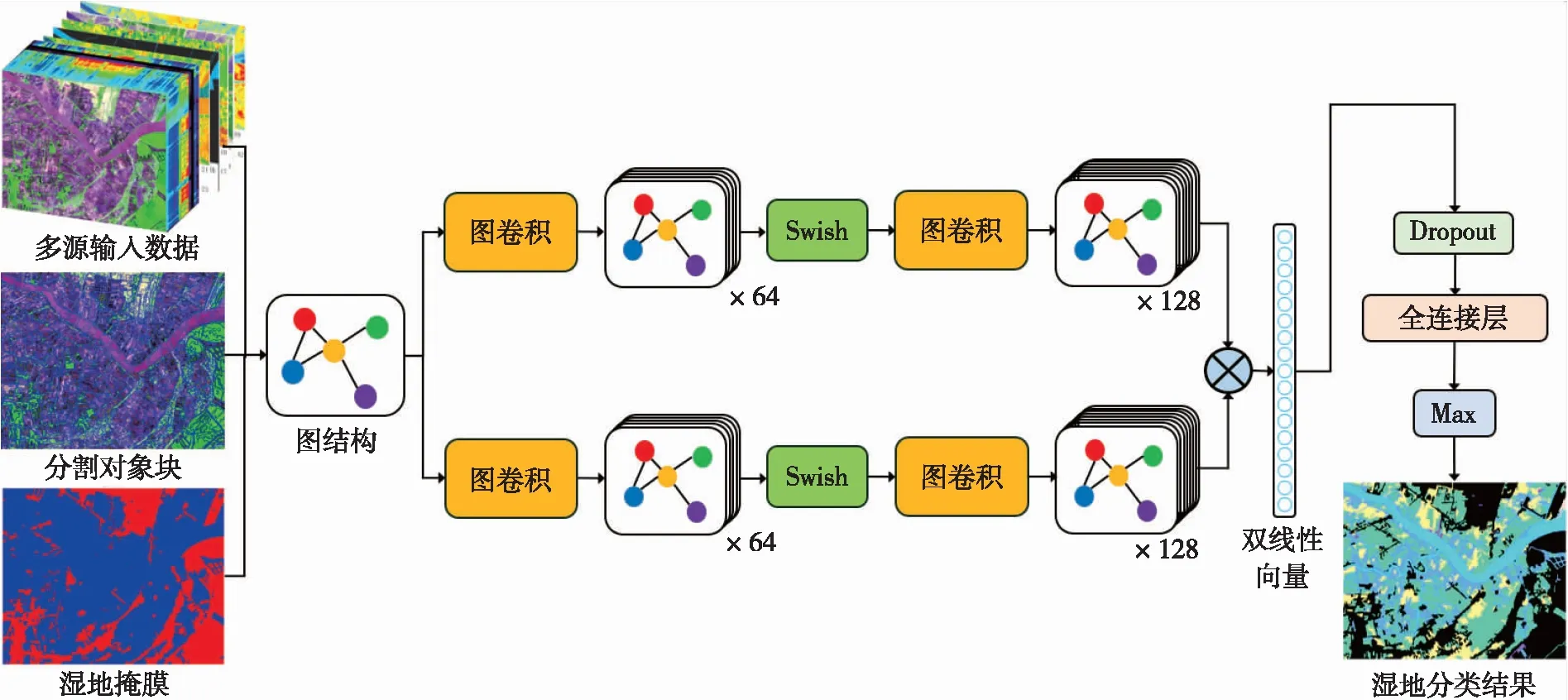
圖6 BiGCN模型結構
(1)根據多源數據和分割結果構建圖結構,查找每個對象的鄰接對象是構建圖結構的基礎。如圖7所示,對象v1與對象v2、v3、v4以邊相鄰接,而與對象v5、v6、v7以點相鄰接。原始GCN中的查找方法能夠搜索到每個對象周圍以邊相鄰接的對象,但以點鄰接的對象間關系同樣十分密切。因此,本文在鄰接對象的查找上作出改進,在僅查找以邊鄰接對象的基礎上增加了以點相鄰接的對象。
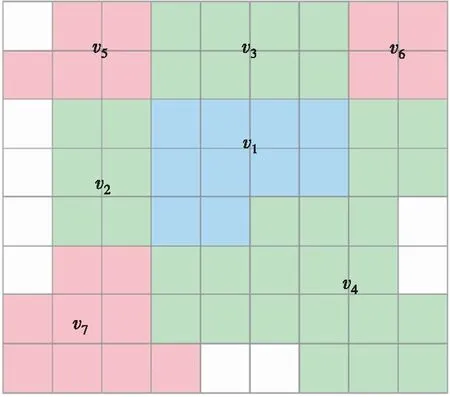
圖7 考慮點鄰接的圖結構
(2)建立圖結構后,采用雙線性模型思想搭建兩路并行的子網絡,每路網絡中包含兩層圖卷積,分別包含64和128個隱藏單元。兩層圖卷積之間使用Swish激活函數,它同ReLU一樣有下界無上界,能夠防止梯度飽和問題,具有非單調且平滑的特點,能夠有效提升網絡性能,公式為
(3)對兩路網絡的輸出特征進行雙線性池化運算,將兩路網絡的特征融合,公式為
bilinear(l,I,fA,fB)=fA(l,I)TfB(l,I)
式中,I為輸入影像;l為輸出特征圖的位置序號;fA和fB分別為兩路網絡的特征。通過兩路并行的網絡進行特征提取及雙線性池化操作,兩路網絡可以分別實現區域檢測和特征提取的功能,且互為補充,能夠有效實現細粒度分類。
(4)對兩路特征融合后的向量執行一個概率為0.5的Dropout層、一個全連接層,并根據全連接層輸出中最大值的位置確定濕地地物類別。
2.3.3 試驗環境及參數設置
本文深度學習框架使用Tensorflow,硬件設備為Intel(R)Core(TM)i7-6700 CPU @ 3.40 GHz 3.41,內存為8 GB。BiGCN模型學習率設置為0.001,最大迭代次數設置為300。
3 結果與分析
3.1 分類結果
為驗證濕地分類方法的有效性,選取5種典型分類模型進行對比試驗,包括支持向量機(support vector machine,SVM)[15]、RF、K近鄰法(K-nearest neighbor,KNN)[16]、CNN、GCN。各模型在已構建的3個數據集上得到的分類結果如圖8—圖10所示。

圖8 越南南部數據集分類結果
可以看出,SVM、RF、KNN這3種非深度學習方法在3個數據集上的總體分類精度(overall accuracy,OA)均在85%以下,低于3種深度學習方法;而在3種深度學習方法中,兩種GCN方法的分類精度高于CNN;使用本文分類方法得到的濕地分布圖與真實情況的吻合度最高且OA最高,3個數據集上的OA均超過92%。
由圖8可以看出,對于越南南部數據集,CNN和GCN的OA略微高于3種非深度學習方法,本文方法分類精度顯著高于其余5種方法。對非濕地和濕地的判別,RF、KNN和CNN中存在較多將濕地誤判為建設用地的情況。對濕地二級類的判別,深度學習方法能夠將河道邊緣的沼澤與河流本身區分開;GCN分類結果圖中存在將河流誤判為水產養殖池的情況,而CNN與本文方法對河流的分類正確且完整;影像最右側區域中間部位有一處網格狀分布、沼澤穿插于間隙的林地,CNN將穿插的沼澤誤判為建設用地,原始GCN將整塊區域誤判為林地,沒有將林地格網間的濕地判別出來,而本文方法則判別準確。
由圖9可以看出,對于菲律賓西北部數據集,3種非深度學習方法的OA均低于77%;而深度學習方法的OA均大于83%。RF、GCN和本文方法對灘涂的判別更為準確,而SVM、KNN和CNN對沿海地區的灘涂存在漏分現象;對于該區域北部的兩片湖泊,多數方法將其誤判為河流、裸地或海洋,CNN和本文方法則能將其較為完整、勻質地判別出來。此外,該區域內河流東部河道中存在較多沼澤,用于對比的幾種方法大多將沼澤誤判為建設用地,而本文方法能將其正確判別。

圖9 菲律賓西北部數據集分類結果
由圖10可以看出,對于中國深圳灣沿岸數據集,該區域北部有一處L形湖泊,SVM、RF和KNN均將其誤判為水產養殖池,而深度學習方法均分類正確,且準確判別了深圳灣沿岸林地與灘涂間的過渡帶沼澤。CNN和GCN對二級濕地類的分類精度均優于SVM、RF、KNN,但在南部淺海水域和灘涂的交界處,GCN存在將其誤判為水產養殖池的情況,在最南部的灘涂和林地交界處,CNN和GCN分別將其誤判為水產養殖池和湖泊,而本文方法則分類正確。總之,本文方法在該數據集上的OA相較于GCN顯著提升,提升幅度超過4%。
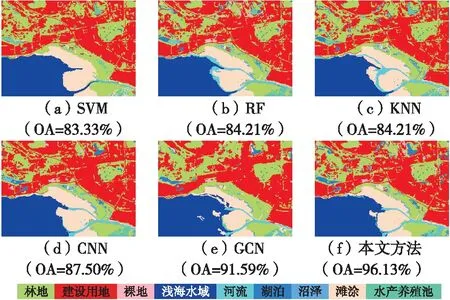
圖10 中國深圳灣沿岸數據集分類結果
3.2 消融試驗
設計5組消融試驗進一步檢驗本文模型各部分的作用,使用OA、平均準確率(average accuracy, AA)和Kappa系數對分類結果進行精度評價,消融試驗的分類精度與用時見表 4,可以得到如下結論。
(1)相較于雙線性模型的網絡,僅使用單通道網絡的運算用時大幅縮短,但精度較低,3個數據集上單通道網絡的OA比雙線性網絡分別降低3.01%、1.72%、3.52%。可見,構建雙線性網絡進行濕地分類,盡管消耗更長的模型訓練時間,但分類精度有顯著提升。
(2)加入多源輔助數據后,由于數據量明顯增加,運算速度有小幅降低,但3個數據集的分類精度都得到明顯提升,其中菲律賓西北部數據集OA提升約3.79%。
(3)考慮點鄰接對象后,3個數據集運算用時均縮短了約3%,且分類精度均有小幅提升。點鄰接對象加入后,每個對象的空間信息量更為豐富,提升了網絡的辨別能力,提高了濕地分類效率。
(4)相較于ReLU,使用Swish激活函數在3個數據集上得到的OA、AA和Kappa均有小幅提升,其中中國深圳灣沿岸數據集提高最多,3項指標均提高1%以上;兩種激活函數運算時間基本相當,ReLU的用時稍短于Swish。可見,Swish激活函數的運算量略大于ReLU,但分類表現更優。
(5)不加掩膜時,分類精度較低且模型訓練耗時更長;加入掩膜后,3個數據集的分類用時分別縮短195.70、842.22、1 003.69 s。可見,使用分層分類的方法首先把差異較大的濕地和非濕地分開,然后對濕地部分進行細分,有助于同時提高分類精度與分類效率。
4 結 語
本文針對環南海地區濕地監測需求,利用Sentinel-2影像制作了3組環南海地區濕地分類數據集,并提出一種基于BiGCN的濕地分類方法。該方法基于面向對象的分層分類思想,首先區分濕地與非濕地,然后構建適用于濕地細粒度分類的BiGCN模型,并對濕地類型進行細化,且采取多種策略對分類效果進行優化(如使用雙線性模型、在構建圖結構時考慮以點鄰接的節點及采用性能更優的Swish激活函數等)。試驗結果表明,在所構建的3組數據集上,本文方法均能夠達到92%以上的總體分類精度,比原始圖卷積網絡提高4%以上,且分類耗時大幅縮短,同時也優于多種常用的濕地分類方法。未來研究將聚焦于小樣本上的濕地高精度分類。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
