基于植被指數的Sentinel-1失相干評估
2023-09-04 07:46:48潘建平趙瑞淇蔡卓言袁雨馨李鵬霞
測繪通報 2023年5期
潘建平,趙瑞淇,蔡卓言,袁雨馨,李鵬霞
(重慶交通大學智慧城市學院,重慶 400074)
Sentinel-1A數據從2014年10月對全球用戶開放以來[1],已經被廣泛應用于地震與地質構造監測[2-3]、火山與冰川監測[4-5],以及其他形變監測領域[6-8],現已成為合成孔徑雷達干涉測量(interferometric synthetic aperture radar,InSAR)領域內重要的C波段數據源(波長為5.6 cm)。但是其短波長的特性給其應用帶來了諸多限制,特別是在植被區,C波段的雷達信號通常難以穿透植被的表層或頂層(如樹枝和樹葉),衛星重訪周期內植被的理化特性變化,甚至是枝葉的微小運動,都會導致干涉失相干現象的發生,并將誤差引入InSAR地表形變監測。
以往的研究表明,植被區的失相干程度可以在兩景單視復數影像(single look complex,SLC)發生干涉后由相干系數(coherence)進行評估[9],相干系數反映兩幅SLC影像的相似程度,可以衡量干涉條紋的質量與SLC影像中像素間的相位和振幅信息的變化[10]。但是干涉后評估必然會導致SAR數據存在選擇的盲區,使得研究者不能選擇最有效的干涉對,從而降低InSAR對地表形變監測的效率,增加了時間與經濟成本。對于短波長的Sentinel-1A數據,如果失相干能在干涉前得到精確評估,將十分有助于克服上述干涉后評估的缺點,從而提高監測效率。
作為應用最廣泛的植被指數,歸一化差分植被指數(normalized difference vegetation index,NDVI)與植被覆蓋度密切相關,可用于監測植被的動態變化,對于地表覆被的可靠表征為建立其與InSAR失相干之間的定量模型提供了可能。
以往針對NDVI與Sentinel-1A相干系數的研究主要集中于定性說明兩者的關系[11-12],其定量關系尚不明確。基于此,本文選擇位于四川的一個植被覆蓋區作為研究區,在同極化(VV)與交叉極化(VH)模式下利用免費光學影像Landsat 8計算得到的NDVI,分別建立其與Sentinle-1A相干系數之間的定量模型,并在鄰近區域對模型進行驗證。
1 研究區概況與數據預處理
1.1 研究區概況
本文的研究區位于四川省,其西部為川西高原,東部緊鄰成都平原,面積約為340 km2,如圖1紅色實線框所示。研究區內植被覆蓋茂盛,主要分布有林地和耕地(主要作物為水稻),并伴隨有少量村落分布,屬于InSAR地表形變監測中的低相干地區,在該區域建立模型有助于提高模型的普適性與應用價值;同時選擇位于研究區西南的鄰近區域(圖1黑色實線框所示)作為驗證區,以驗證模型的可靠性,以及區內地形和植被覆蓋狀況與研究區類似。

圖1 研究區位置與影像覆蓋范圍
1.2 數據預處理
本文使用的光學影像為Landsat 8 OLI影像,成像時間為2019年8月11日,云量為0.89%,空間分辨率為30 m,覆蓋范圍如圖1中黑色虛線框所示。對光學影像進行大氣校正和輻射校正兩步處理,并按照研究區和驗證區矢量范圍進行裁剪,最后計算NDVI,公式為
(1)
式中,PNIR、PRED分別代表近紅外和紅光波段的反射率。NDVI的值介于[-1,1],隨著地表植被覆蓋度的增加而增大。NDVI為負值時代表地表覆蓋有水或雪,NDVI為0表示地表為巖石或裸土,NDVI為正值表示地表有植被覆蓋。研究區和驗證區的NDVI分布如圖2所示。
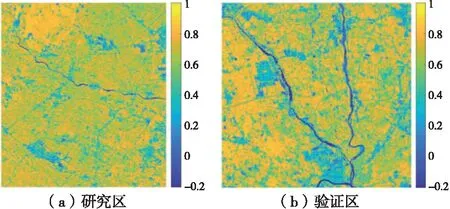
圖2 研究區和驗證區NDVI分布
Sentinel-1A影像分別為成像時間為2019年7月3日和8月20日的干涉寬幅模式下的SLC影像,時間基線為48 d,分別作為干涉對的主影像和輔影像,其覆蓋范圍如圖1中紅色虛線框所示。SLC影像的預處理包括3部分: ①使用雙過差分對主、輔影像進行差分干涉,并分別使用精密軌道數據和SRTM DEM(30 m)消除軌道誤差和模擬地形相位; ②對干涉對進行多視處理以消除斑點噪聲并使SAR影像與Landsat 8影像保持相同的分辨率;③使用文獻[13]提出的公式消除空間失相干的影響,并計算研究區和驗證區的相干系數,公式為
(2)
式中,γ代表相干系數;E[·]代表數學期望;μ*代表SLC影像的共軛復數。相干系數的值介于[0,1],當主輔影像完全相干時,相干系數的值為1;當兩者完全失相干時(如干涉圖完全被噪聲污染),其值為0。
最后使用SRTM DEM(30 m)對NDVI分布圖和相干系數圖進行配準,配準后完成數據預處理,數據預處理流程如圖3所示。
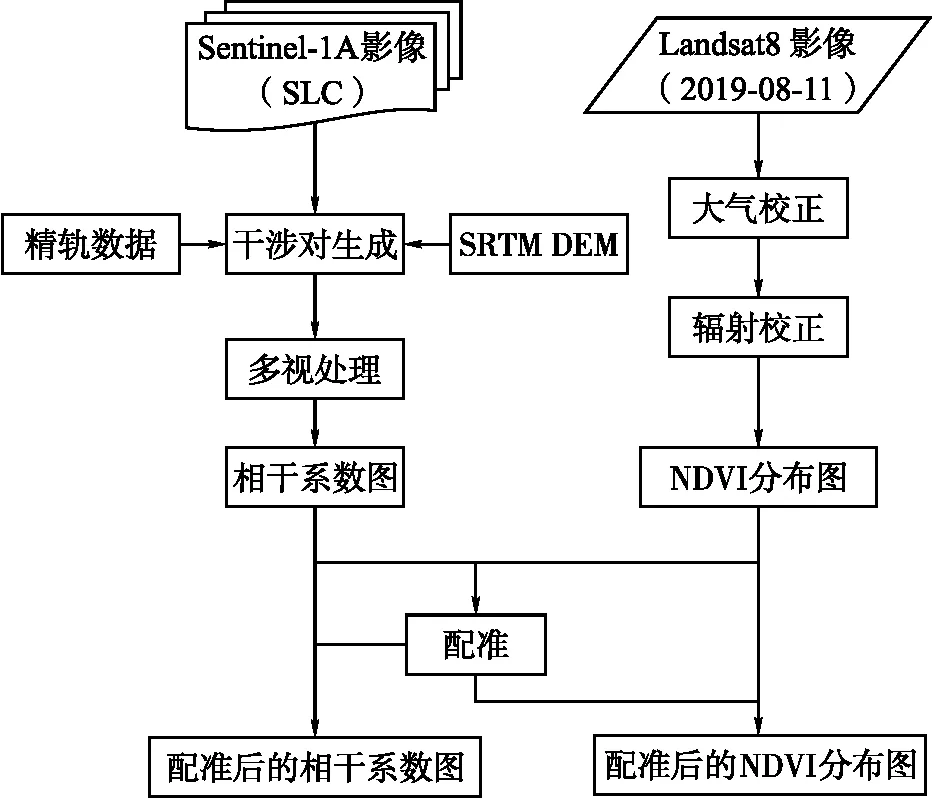
圖3 數據預處理流程
2 試驗方法
2.1 時間失相干對相干系數的影響
文獻[14]提出了對相干系數產生影響的各個因素,主要有空間失相干、時間失相干及熱噪聲失相干。其中,熱噪聲失相干可以忽略不計;空間失相干由于研究區較為平坦的地形(平均坡度小于15°)并不明顯,且已通過文獻[13]提出的公式消除;通過建立時間基線與相干系數的模型削弱時間失相干對相干系數的影響。
基于多主影像策略,利用覆蓋研究區的Sentinel-1A影像生成了若干干涉對,干涉對的時間基線為12~696 d,時間基線與相干系數的關系如圖4所示。
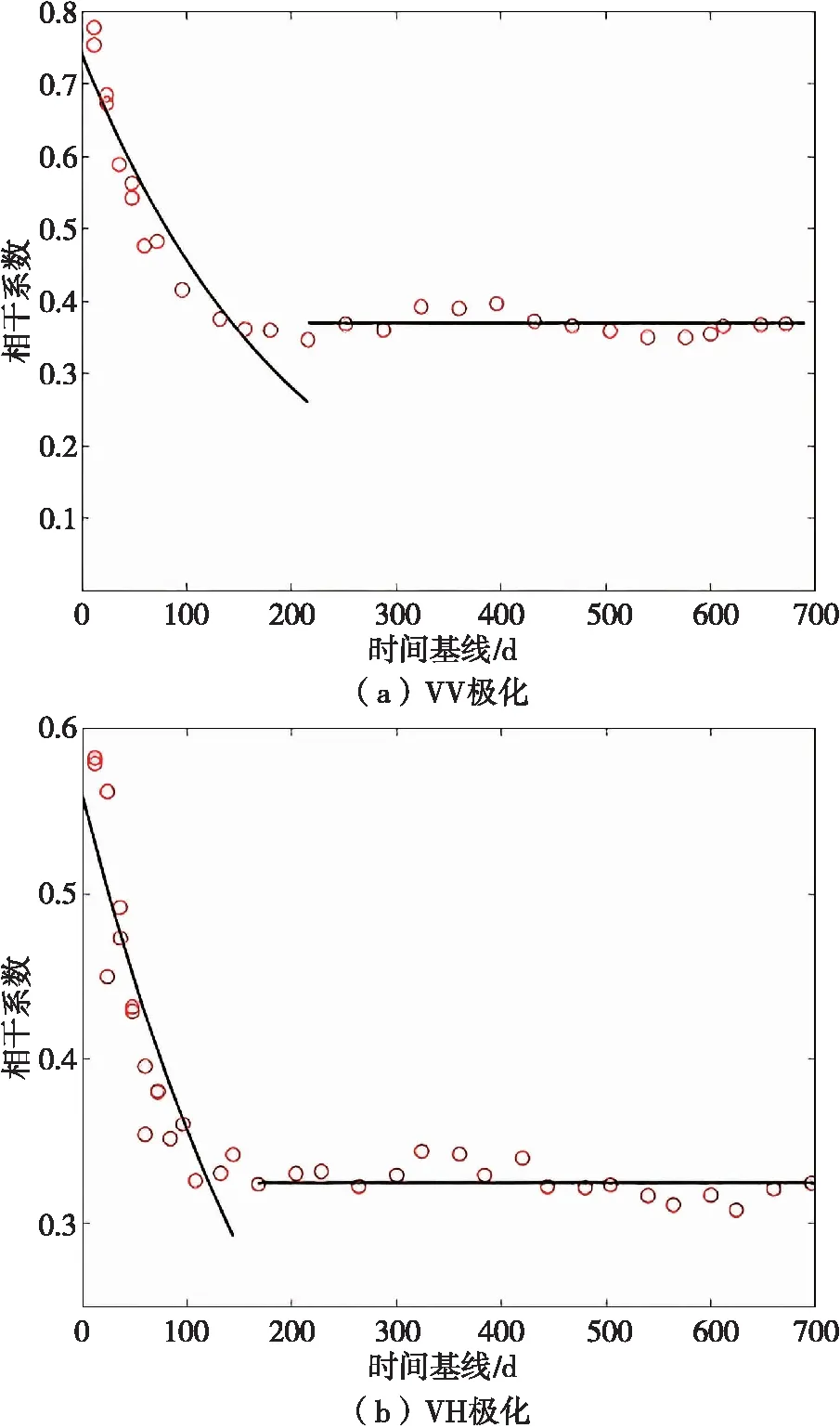
圖4 時間基線與相干系數的關系
圖4(a)顯示,VV極化下相干系數在時間基線≤216 d時隨著時間基線的增加呈現指數衰減,其擬合曲線為y=A1·exp(-x/t1),其中A1=0.743,t1=206 d。在216 d之后沒有明顯的衰減趨勢,相干系數在0.370左右浮動。圖4(b)顯示,VH極化下相干系數在時間基線小于168 d時呈現指數衰減,其擬合曲線為y=A2·exp(-x/t2),其中A2=0.560,t2=222 d。在168 d之后沒有明顯的衰減趨勢,在0.325左右浮動。本文所使用的干涉對時間基線為48 d,因此有必要考慮時間失相干對相干系數指數衰減的作用。
2.2 基于皮爾遜相關系數絕對值的建模方法
試驗表明,將配準后的NDVI分布圖與相干系數圖的所有像素進行擬合分析會引入非常大的全局誤差,從而無法建立起NDVI和相干系數之間的可靠模型,因此本文考慮使用文獻[15]中提出的窗口采樣方法。該方法包括3個步驟。
(1)對NDVI分布圖設置一個采樣窗口,同時對相干系數圖設置一個相同大小的采樣窗口,使用采樣窗口對兩張圖像同時進行采樣,直至窗口遍歷整張圖像。
(2)對兩個窗口中的NDVI像素值和相干系數像素值計算皮爾遜相關系數[16],公式為
(3)
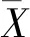
(3)設置一個閾值,若兩個采樣窗口中的像素值皮爾遜相關系數大于該閾值,則將窗口中的像素值保留,參與后續分析;否則,將窗口中的像素值舍棄。
該方法被用于建立NDVI與L波段ALOS數據相干系數之間的關系,但是ALOS數據由于其長波段特性失相干現象較弱,NDVI與相干系數之間的負相關關系并不明顯。初步試驗表明,Sentinel-1A數據的相干系數與NDVI之間呈現較強的負線性相關關系,直接使用該方法將會忽略掉大量像素值,導致模型精度大幅降低。因此,本文對該方法的相似性測度進行了改進,在步驟(3)中計算皮爾遜相關系數的絕對值,以顧及采樣窗口中NDVI與Sentinel-1A相干系數大量呈負線性相關的像素值。最佳采樣窗口大小和預設閾值大小的設定需要通過試驗確定,改進后的窗口采樣方法如圖5所示。
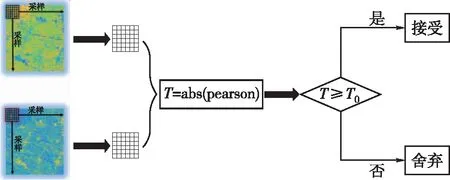
圖5 改進相似性測度的窗口采樣方法
圖5上下兩張圖像分別為研究區NDVI分布圖和相干系數圖,T為皮爾遜相關系數的絕對值,T0為預設的閾值。大量試驗表明,對于VV極化,最佳的采樣窗口大小為5×5,閾值大小為0.7,VH極化下的最佳采樣窗口和閾值大小為9×9和0.6。將滿足閾值條件的保留像素值進行分析,得到了VV和VH極化下NDVI和相干系數的關系,如圖6所示。

圖6 NDVI和相干系數的關系
圖6中藍色星星為真實像素值,兩條直線分別為VV和VH極化下的擬合曲線。由于時間失相干對相干系數的衰減作用,因此需要在模型中加入時間失相干指數衰減因子,在95%的置信區間下采用最小二乘擬合得到了VV和VH極化模式下NDVI和Sentinel-1A相干系數的定量模型,分別為
(4)
(5)

3 試驗結果與討論
3.1 試驗結果與誤差分析
基于式(4)和式(5),利用NDVI分布圖模擬得到了VV和VH極化下的研究區相干系數圖,與研究區真實相干系數的對照如圖7所示。

圖7 研究區相干系數
圖7(a)和圖7(c)分別為研究區VV和VH極化下的真實相干系數,圖7(b)和圖7(d)分別為VV和VH極化下的模擬相干系數。利用真實相干系數減去模擬相干系數得到了圖7(e)和圖7(f)所示的誤差分布圖。由誤差分布圖可以看出,VV極化下誤差分布除研究區內河流分布區域外其他區域不明顯,VH極化下誤差分布除了河流區域外主要集中在圖7(f)中的村落分布區域。對誤差分布進行統計,如圖8所示。研究區VV極化下誤差均值為-0.037,標準差為0.205,大部分誤差集中在-0.3~0.3之間,誤差整體基本服從正態分布。研究區VH極化下誤差均值為0.045,標準差為0.200,大部分誤差同樣集中分布在-0.3~0.3之間,雖然誤差整體高于VV極化,但是仍然基本服從正態分布。
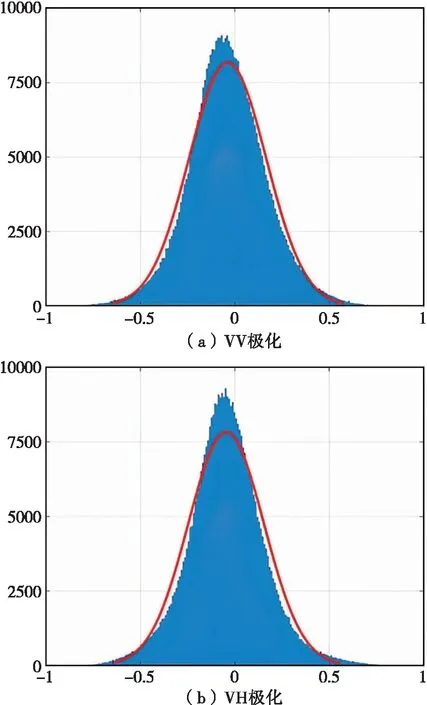
圖8 研究區誤差統計
3.2 模型驗證
為了驗證模型的可靠性,在驗證區進行了相同的試驗,數據處理方式與研究區保持一致,驗證區的相干系數如圖9所示。圖9(a)和圖9(c)分別為驗證區VV和VH極化下的真實相干系數,圖9(b)和圖9(d)分別為VV和VH極化下的模擬相干系數,利用真實相干系數減去模擬相干系數得到了圖9(e)和圖9(f)所示的誤差分布。由于驗證區分布有兩條明顯的河流,因此由誤差分布圖可以看出,驗證區的誤差主要分布在河流分布區域及區域南部的村落分布區。對驗證區誤差分布進行統計,如圖10所示。驗證區VV極化下的誤差均值為-0.067,標準差為0.256,VH極化下的誤差均值為-0.065,標準差為0.230。兩種極化下的誤差均集中分布在-0.3~0.3之間,且服從正態分布。綜合圖7(e)、圖7(f)、圖9(e)和圖9(f)的差值及圖8和圖10的誤差分布情況來看,利用式(4)和式(5)模擬得到的相干系數沒有隨機誤差分布,模型可靠。
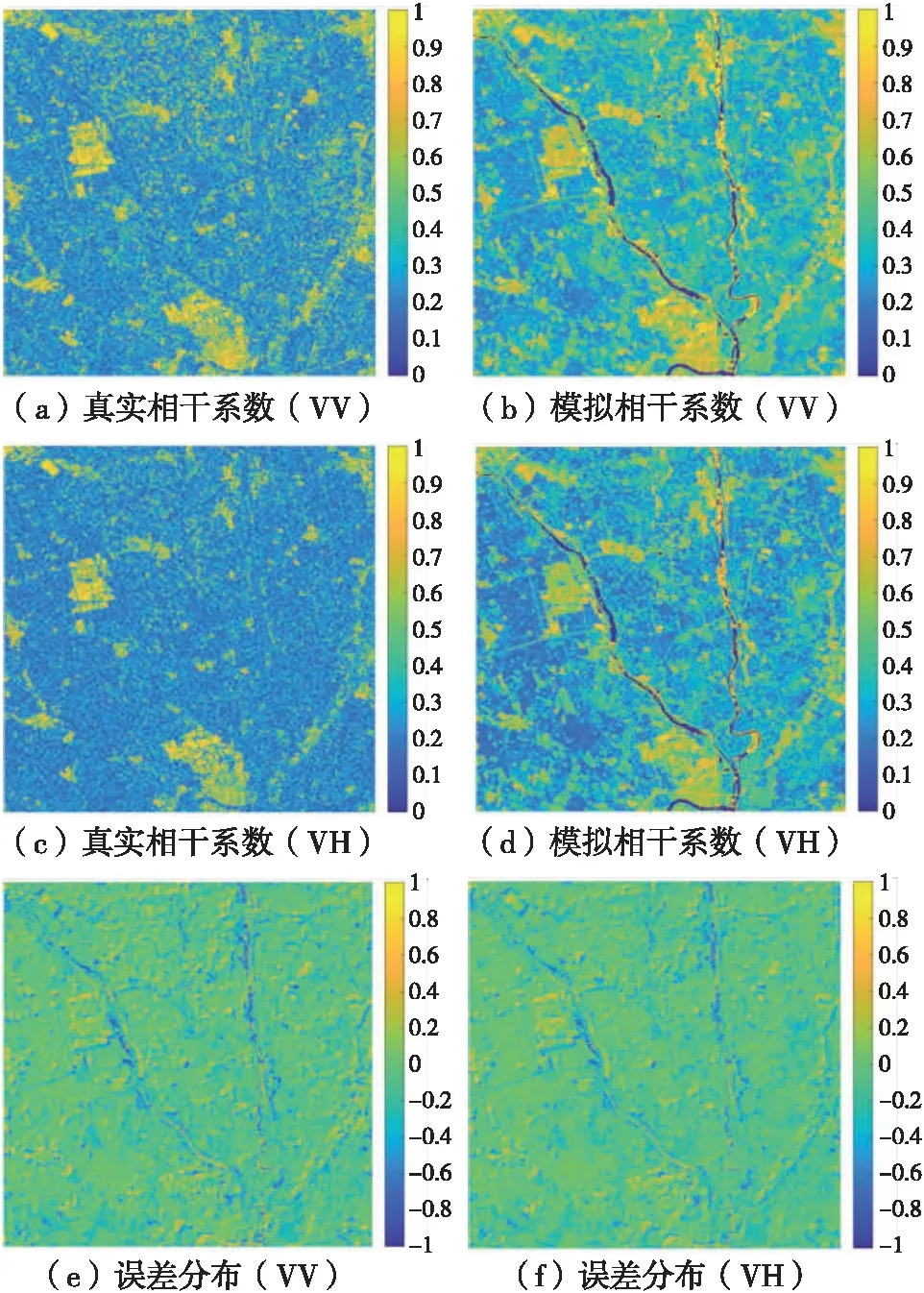
圖9 驗證區相干系數

圖10 驗證區誤差統計
3.3 結果討論
從研究區和驗證區的角度來看,兩種極化模式下驗證區模擬相干系數的誤差分布更離散且整體大于研究區,主要原因有兩點:①盡管驗證區的地形與研究區相似,但仍存在微小差異,雖已去除空間失相干的影響,但是微小地形差異引起的空間失相干會將誤差引入模型中;②相較于研究區,驗證區分布有兩條明顯的河流,河流區域的誤差成為驗證區的主要誤差來源。
從極化方式來看,無論研究區還是驗證區,VV極化下的相干系數整體均高于VH極化下的相干系數,這是由于研究區和驗證區的地表覆被主要為耕地(主要作物為水稻),其次是林地,已有研究表明水稻的理化參數與反射特性與VH極化的關系比VV極化更強[16],導致其對VH極化的雷達波更敏感,相同時間基線下的失相干相較于VV極化更嚴重。同時研究區和驗證區VV極化下的整體誤差均低于VH極化下的整體誤差,這是由于盡管經過大量試驗得到了兩種極化方式下的最佳采樣窗口與閾值,但是VH極化下的像素值相較于VV極化分布更離散(如圖6所示),整體擬合精度低于VV極化,從而導致VH極化下模型精度低于VV極化下模型精度。
綜合上述模型的誤差源與缺點,在未來的研究中還需考慮如何完全去除空間失相干對模型的影響,另外水系不可避免地會出現在植被覆蓋區,因此應考慮如何消除水系對模型的影響,如建立光學遙感水體指數與相干系數的定量模型并融入已建立的模型),從而提高模型的普適性與可靠性。其他諸如研究區的天氣狀況、地表植被類型及影像不同的成像視角(升軌與降軌)等因素也應當在模型中加以考慮。除了本文建立的NDVI與C波段Sentinel-1A相干系數之間的定量模型之外,NDVI與同極化L波段的ALOS-1/PALSAR-1相干系數之間的定量模型已經建立[15],因此在未來的工作中需要建立NDVI與交叉極化的L波段數據的相干系數及與X波段數據的相干系數之間的定量模型。
4 結 語
本文建立了兩個基于Landsat 8影像計算得到的NDVI與Sentinel-1A不同極化方式下干涉相干系數之間的二階線性模型,從而得到了InSAR失相干與地表植被覆蓋之間的定量關系。相干性隨著植被覆蓋度的增加而呈線性減小,且線性減小的趨勢因極化方式的不同而有所區別,同時這兩個模型在驗證區得到了驗證,表明了模型的可靠性。基于本文建立的模型,可以利用免費光學影像計算得到的NDVI在進行InSAR處理之前(即SLC影像干涉之前)對研究區的InSAR失相干現象做出定量評估;同時在干涉前對SAR數據選擇提供指導,從而提升研究者的效率并減少時間與經濟成本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
