基于注意力機制改進殘差神經網絡的軸承故障診斷方法
2023-09-05 01:19:42韓爭杰牛榮軍馬子魁崔永存鄧四二
振動與沖擊 2023年16期
韓爭杰, 牛榮軍, 馬子魁, 崔永存, 鄧四二
(1. 河南科技大學 機電工程學院,河南 洛陽 471003;2. 舍弗勒(上海)貿易有限公司(研發中心),上海 201804)
機械故障是風力電設備、航空發動機、高檔數控機床等大型機械裝備安全可靠運行的“潛在殺手”[1]。故障診斷是用于保障設備安全、平穩運行的重要技術手段,在故障診斷技術的發展的早期階段,相關研究和工程技術人員大多通過對設備生命周期中出現故障時的具體物理參數或損傷進行相應的記錄和分析,從而依靠不斷累積的經驗知識對設備故障進行診斷[2]。近年來,隨著計算機科學發展的進步,軸承故障診斷已由傳統方法向智能化方向轉變[3],尤其是深度學習方面,基于數據驅動的智能機械故障診斷方法取得了較大發展[4]。
傳統的故障特征提取方法主要基于時域,頻域和時頻域,而時頻域分析既包含時域信息也包含頻域信息,在軸承故障診斷中得到廣泛應用。時頻分析方法中小波變換(wavelet transform,WT),短時傅里葉變換(short time Fourier transform,STFT)、希爾伯特黃變換(Hilbert-Huang transform,HHT)及其他改進算法[5-6]等通常將原始時域振動信號轉換到時頻域上,并提取出信號的統計特征[7],將這些構造出的特征作為故障分類算法的輸入。傳統的故障分類算法[8-10],屬于淺層機器學習的方法,要與特征提取方法結合,使用人工特征提取方法,針對具體的任務,帶來了人為因素的干擾,很難應用于所有情況的特征,具有較低的泛化性。
而深度學習是讓計算機自動學習特征的方法,能夠直接從原始的信號中學習到重要的特征,目前主要的深度學習的方法有卷積神經網絡(convolutional neural network, CNN),循環神經網絡(recurrent neural network,RNN),自編碼網絡(auto encoder, AE)[11-12]。隨著深度學習在故障診斷中的應用,也隨之暴露了一些缺點,比如說隨著訓練層數和參數的增加,從頭開始訓練一個大型的深度學習模型要有足夠的樣本、算力和時間[13],而故障診斷想獲取大量數據比較困難。
針對深度學習上述不足,在機械故障診斷領域中引入了遷移學習的方法。在單源域遷移學習中,基于預訓練的不同的網絡模型,實現模型的遷移,并利用該數據微調預訓練模型,實現了較高的故障診斷準確率和訓練效率[14-15]。對于多源域遷移學習,Zhu等[16]通過搭建多源域適應網絡,實現目標域數據的識別。Li等[17]提出一種適用于任何基于梯度學習規則訓練模型的方法,在數字和動作識別試驗中取得了較好的試驗結果。無論是單源域還是多源域遷移學習,當在同一工況內進行模型遷移訓練效果一般較好,但當遷移到不同工況時,尤其是不同工況內無訓練樣本時,其訓練效果將會變得很不理想。
針對遷移學習不同工況訓練中存在的不足,提出了一種基于注意力機制改進殘差神經網絡的軸承故障診斷方法,本算法的創新點在于:
(1) 通過遷移學習方法,利用殘差神經網絡在二維時頻域圖像上實現不同工況下樣本的直接遷移,是在一定工況訓練好模型,直接遷移到其他工況進行測試,相比較傳統將不同工況的數據集劃分為訓練集和測試集的樣本遷移,本文提出的網絡具有更強的泛化性。
(2) 在注意力機制的基礎上,提出了注意力模塊中的擠壓與激勵網絡(squeeze and excitation networks, SENet)和卷積模塊的注意力模塊(convolutional block attention module, CBAM)對殘差神經網絡進行優化,都達到了優化殘差神經網絡的目的。SENet模塊是只關注通道的注意力機制,CBAM模塊是即關注通道,也關注空間的注意力機制,兩種模塊可以嵌入到現在任何流行的網絡。
1 理論基礎
1.1 連續小波變換
小波變換包括連續小波變換(continue wavelet transform,CWT)和離散小波變換(discrete wavelet transform,DWT),本文主要對軸承的振動信號分析,采用CWT進行時頻域分析。假設Z(t)是輸入的原時域信號,連續小波變換可以表示為
(1)
式中:a為伸縮因子;τ為時間平移因子;ψ(·)為小波基函數,是滿足一定條件的基本小波函數。
1.2 卷積神經網絡
卷積神經網路(convolutional neural network,CNN)是一類強大的處理圖像數據的神經網絡,傳統的CNN模型主要由卷積層、池化層、全連接層和Softmax分類器構成。傳統的CNN結構圖如圖1所示。
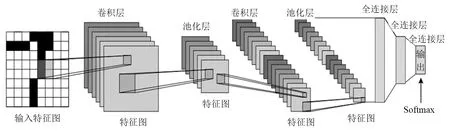
圖1 傳統的CNN結構圖Fig.1 Traditional CNN structure diagram
卷積運算的的數學表達式為
(2)

池化層分為最大池化層和平均池化層,運算符由一個固定形狀的窗口組成,以輸入步幅的大小在所有區域上滑動,其計算的方式如圖2所示。
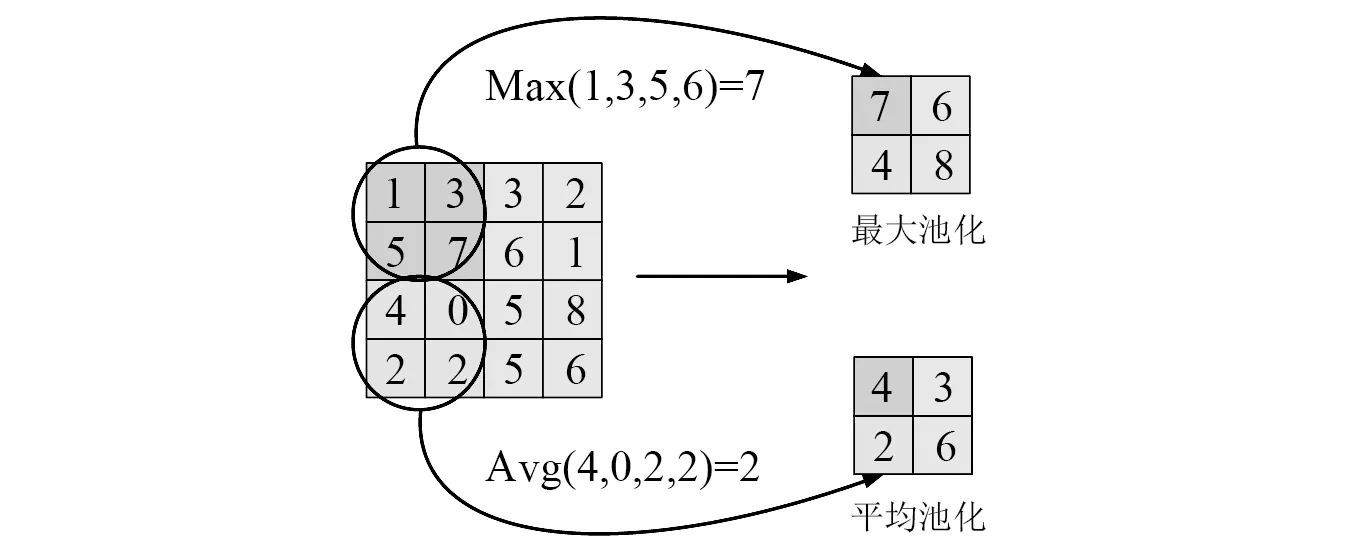
圖2 池化層計算方式Fig.2 Calculation method of aggregation layer
CNN的最后一層為一個全連接層,用于執行分類或回歸任務,其數學定義為
(3)
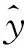
對于分類任務通常使用Softmax激活函數,其定義如下
(4)
在CNN的訓練中,通常使用交叉熵函數,來評估真實標簽與預測概率之間誤差,定義如下
(5)
式中:1{·}為指示函數,當大括號內的判斷為真時,取值為1,否則為0;假設訓練集的樣本總數為N,則交叉熵損失函數定義如下
(6)
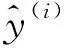
1.3 殘差神經網絡
隨著神經網絡層數的不斷加深,網絡就會變得難以訓練,并且網絡的訓練精度達到飽和,出現網絡退化的現象。因此,He等[18]提出了殘差網絡(residual network,ResNet)結構來解決該問題,ResNet采用快捷連接方式實現了網絡層恒等映射的多個殘差模塊堆疊構成。
殘差模塊沒有去擬合多個網絡層堆疊的直接映射,而是擬合殘差映射。讓我們聚焦于神經網絡局部:如圖3所示,假設我們的原始輸入為X,而希望學出的理想映射為F(X)(作為圖3下方激活函數的輸入)。圖3左圖正常塊直接擬合出該映射F(X),而右圖部分則需要擬合出殘差映射F(X)-X。殘差映射在現實中往往更容易優化。在殘差塊中,輸入可通過跨層數據線路更快地向前傳播。能有效降低映射的學習難度,加快模型的收斂速度。
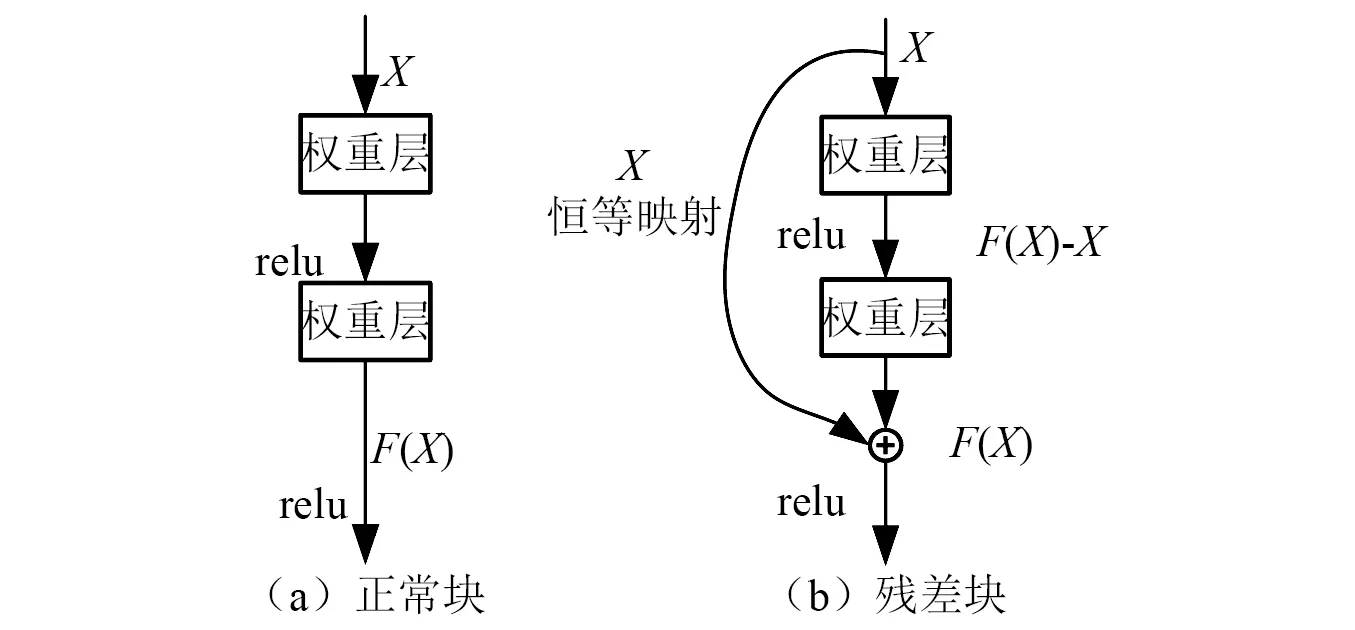
圖3 正常塊和殘差塊Fig.3 Normal block and residual block
在ResNet模型中殘差塊結構形式如圖4所示,降采樣層用來保持特征圖的尺寸和通道數一致。

圖4 標準殘差塊和帶降采樣層的殘差塊Fig.4 Standard residual block and residual block with falling sampling layer
1.4 注意力機制
注意力機制的產生來源于人類的視覺注意力。人類特有的視覺信息處理系統能夠讓人們僅依靠有限的注意力資源從待處理信息中得到關注焦點,注意力機制的核心邏輯就是從關注全部到關注重點。本文對ResNet模型優化,使用了注意力模塊中的SENet和CBAM。
SENet由Hu等[19]在2017年的ImageNet競賽中提出,SENet的結構如圖5所示。

圖5 SENet的結構圖Fig.5 Structure diagram of SENet
圖5是提出的SENet模塊的示意圖。與傳統的CNN不一樣的是通過Squeeze和Excitation 2個操作來重標定前面得到的特征。首先是Squeeze操作,順著空間維度來進行特征壓縮,將每個二維的特征通道變成一個實數,使得靠近輸入的層也可以獲得全局的感受視野,具體算法公式為
(7)
式中,xi為輸入為尺寸h×w的第i個特征圖。
其次是Excitation操作,主要由2個全連接層和2個激活函數組成,算法公式為
yi=Fex[Fsq(xi),ω]=σ{ω2δ[ω1Fsq(xi)]}
(8)
式中:σ為ReLU激活函數;δ為Sigmoid激活函數;ω1為第一個全連接層;ω2為第二個全連接層;Fsq(xi)為Excitation操作后的輸出值。
CBAM[20]是由通道注意力模塊(channel attention module,CAM)和空間注意力模塊(spatial attention module,SAM)構成的,CBAM的結構如圖6所示。
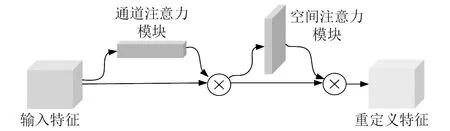
圖6 CBAM的結構圖Fig.6 Structure diagram of CBAM
CAM與SENet相比,只是多了一個并行的Max Pooling層,CAM的結構如圖7所示。
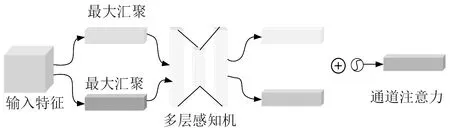
圖7 CAM的結構圖Fig.7 Structure diagram of CAM
將輸入的特征圖F∈Rc×h×w分別經過基于h和w的全局最大池化和全局平均池化,得到2個c×1×1的特征圖,接著,再將它們分別送入全連接層運算后相加,生成一維通道注意力Mc∈Rc×1×1。然后與輸入特征圖F相乘,調整后獲得F1其過程公式為
F1=Mc(F)?F
(9)
式中:Mc(F)為F經過通道注意力的輸出權值; ?為特征圖加權乘法運算符號。
SAM的結構如圖8所示。
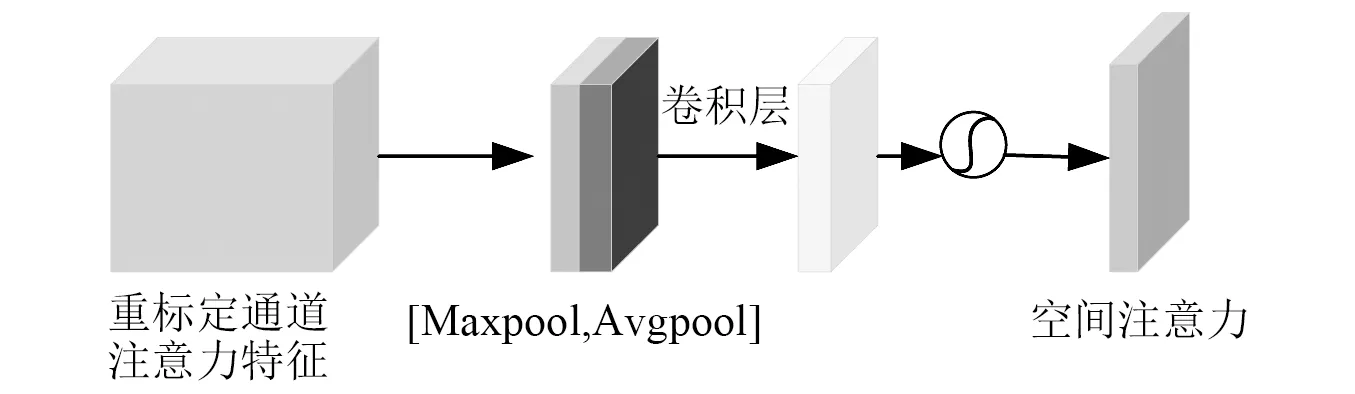
圖8 SAM的結構圖Fig.8 Structure of SAM
將通道注意力模塊輸出的特征圖F1作為本模塊的輸入特征圖。首先做一個基于通道的全局最大池化和全局平均池化,得到2個1×h×w的特征圖,將這2個特征圖基于通道做拼接操作。然后進行卷積操作得到二維空間注意力Ms∈R1×h×w,最后與F1按元素相乘。其過程公式為
F2=Ms(F1)?F1
(10)
式中,Ms(F1)為F1經過空間注意力的輸出權值。
2 算法詳解
本文提出的基于注意力機制對殘差神經網絡進行優化,能夠從時頻圖中自動提取出軸承的故障特征信息。本算法的框架如圖9所示,ResNet模型詳細參數如表1所示,具體分為時頻圖像生成、訓練模型和優化模型3個步驟。
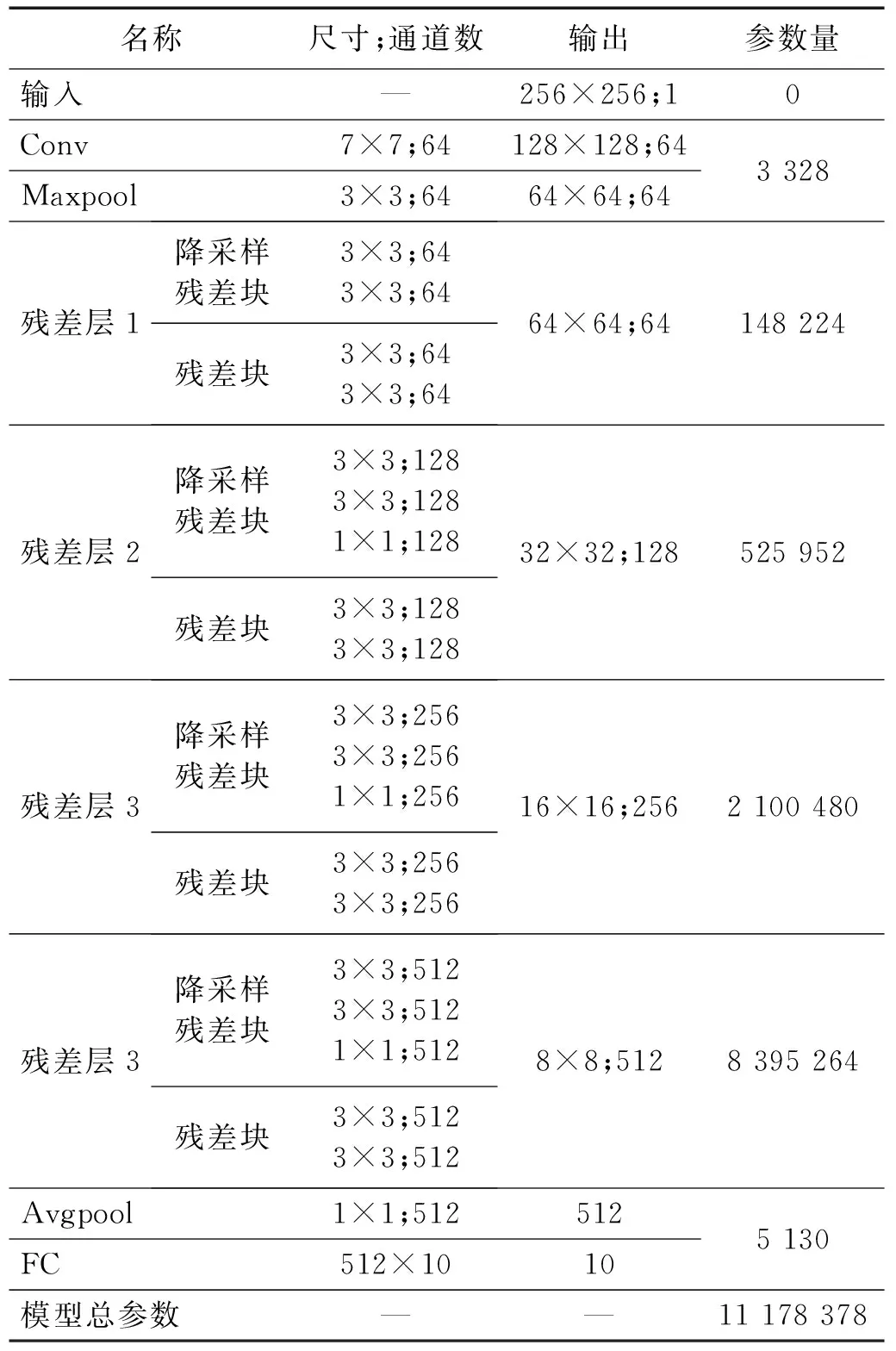
表1 ResNet模型詳細參數Tab.1 ResNet model detailed parameters
(1) 時頻圖像生成:將原始時域信號每2 048個數據點組成一個樣本,為了保證每個數據點都能采集到,每2個樣本點會有重疊的548個數據點,滑動窗口的步長為1 500,然后將這些樣本點經過連續小波變化生成時頻域的圖像。
(2) 訓練模型:本文的預訓練模型是在ImageNet圖像數據集上訓練的ResNet18模型上改進的。如果直接遷移ResNet18模型,收斂速度很慢,迭代到139次才開始收斂,而且迭代時波動性比較大。本文提出的ResNet模型在保留原始ResNet18模型的大部分架構,將殘差層中的帶采樣殘差塊BatchNorm層去掉,只用conv1×1的卷積層,殘差塊引用2個卷積層和2個BatchNorm層,迭代到第10次就開始收斂,而且兩者最后收斂的準確率一致,大大加快了模型的運算速度。兩種模型的迭代對比如圖10所示。
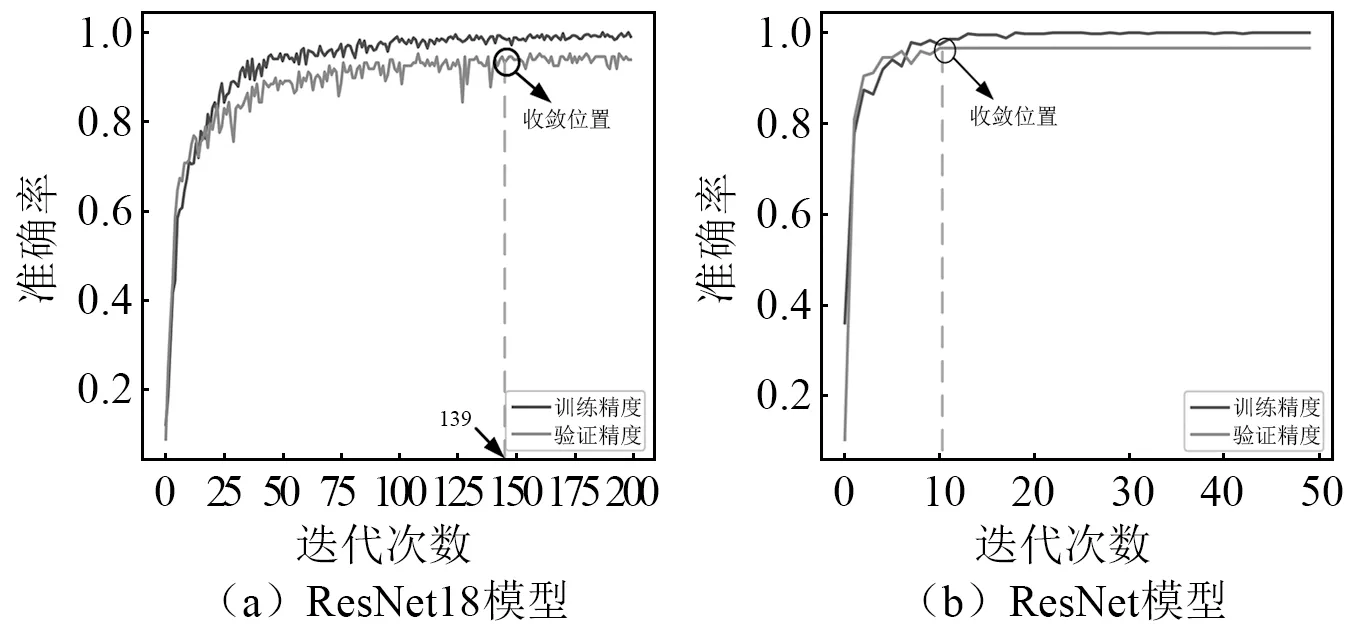
圖10 訓練速度對比圖Fig.10 Comparison of training speed
(3) 優化模型:本文采用基于注意力機制的方法對ResNet進行優化,分別將注意力機制里的SENet模型和CBAM添加到ResNet模型里的4個殘差層中,得到SE-ResNet模型和CBAM-ResNet模型。
3 試驗驗證
為驗證本文提出基于注意力機制優化殘差神經網絡故障診斷算法的有效性,仿真試驗使用的深度學習框架為pytorch,編程語言為Python,在AMD Ryzen 5 4600H,8 G內存,GTX1650,Windows 10操作系統下,每次訓練的批量大小設置為7個樣本,采用SGD優化方法,反向傳播更新深度學習模型的參數,學習率設置為0.001,使用經典的交叉熵損失函數。
3.1 軸承故障數據源與處理
本文使用凱斯西儲大學(Case Western Reserve University,CWRU)的滾動軸承數據集,試驗平臺如圖11所示。

圖11 CWRU試驗平臺Fig.11 CWRU test platform
CWRU數據集中使用的是由SKF公司生產,型號為6205和6203的滾動軸承來開展故障診斷試驗。本次試驗采用了12 kHz采樣頻率的驅動端軸承的故障數據,并采集了4種不同工況時(0,735 W, 1 470 W, 2 205 W)的滾動軸承振動信號。在每種工況下,對滾動體、內滾道和外滾道分別引入直徑為0.177 8 mm,0.355 6 mm,0.533 4 mm的單點故障的滾動軸承進行了試驗,加上正常滾動軸承的試驗數據,每個工況都有10種不同的故障類型,如表2所示。
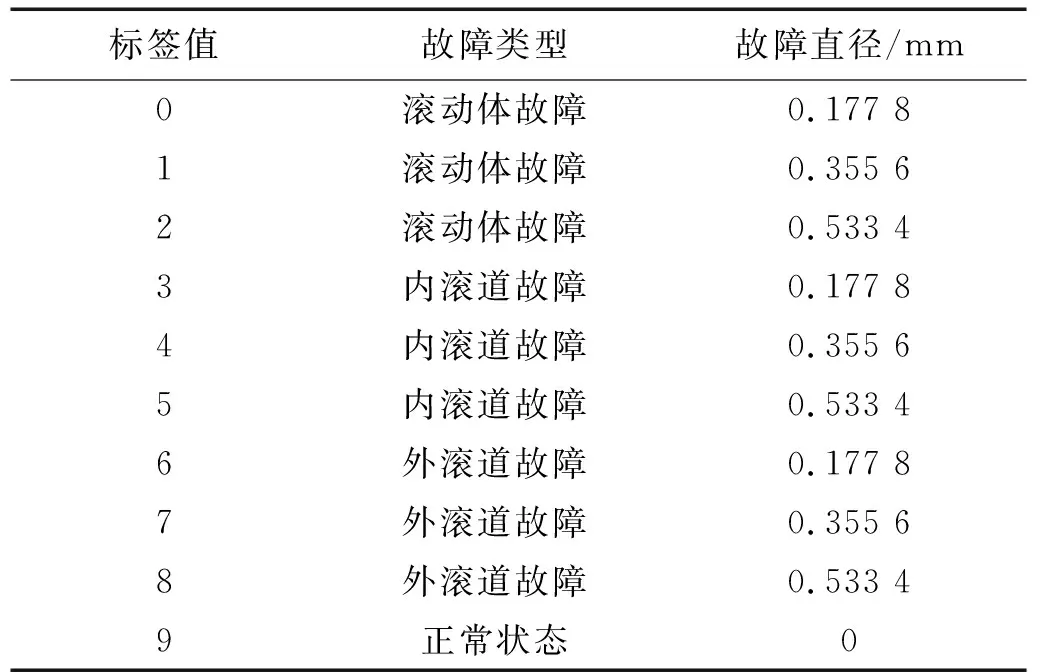
表2 CWRU軸承故障分類及標簽值Tab.2 CWRU bearing fault classification and label value
將原始時域信號每2 048個數據點組成一個樣本,每2個樣本點會有重疊的548個數據點,滑動窗口的步長為1 500,訓練集、驗證集和測試集的具體設置如表3所示。
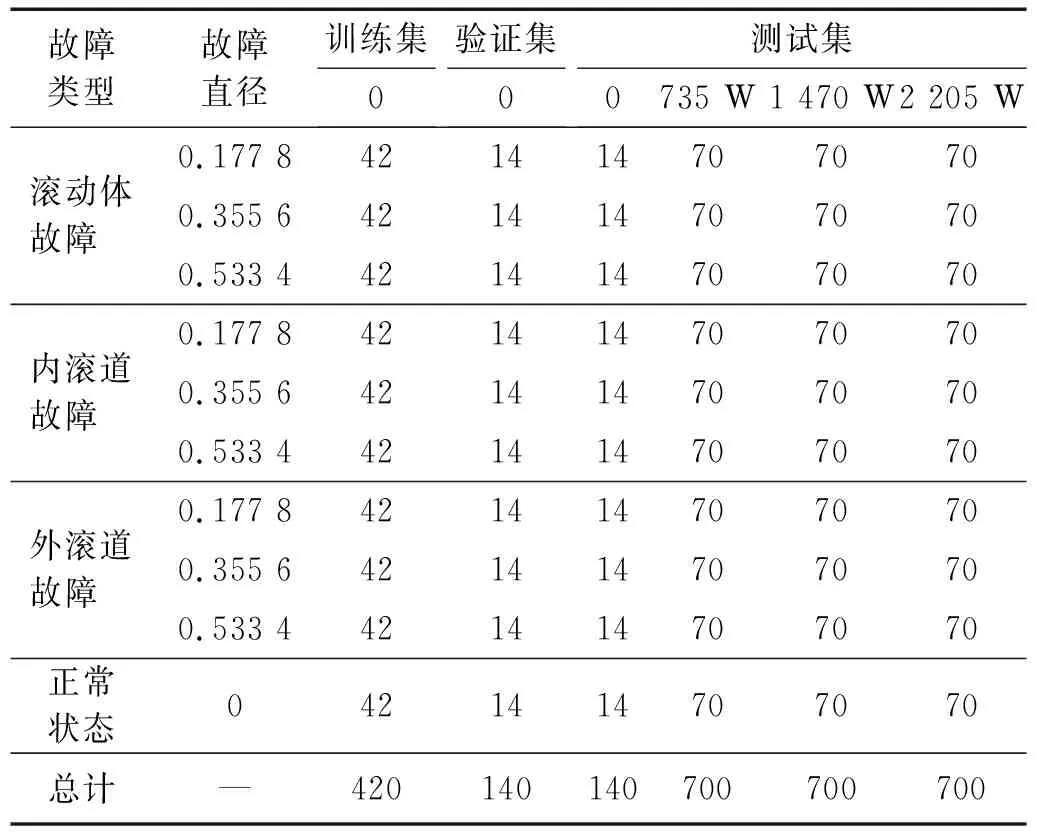
表3 試驗數據說明Tab.3 Experimental data description
對每個狀態的故障經過CWT處理轉換成二維時頻域圖像,其中工況0部分的轉換如圖12所示。
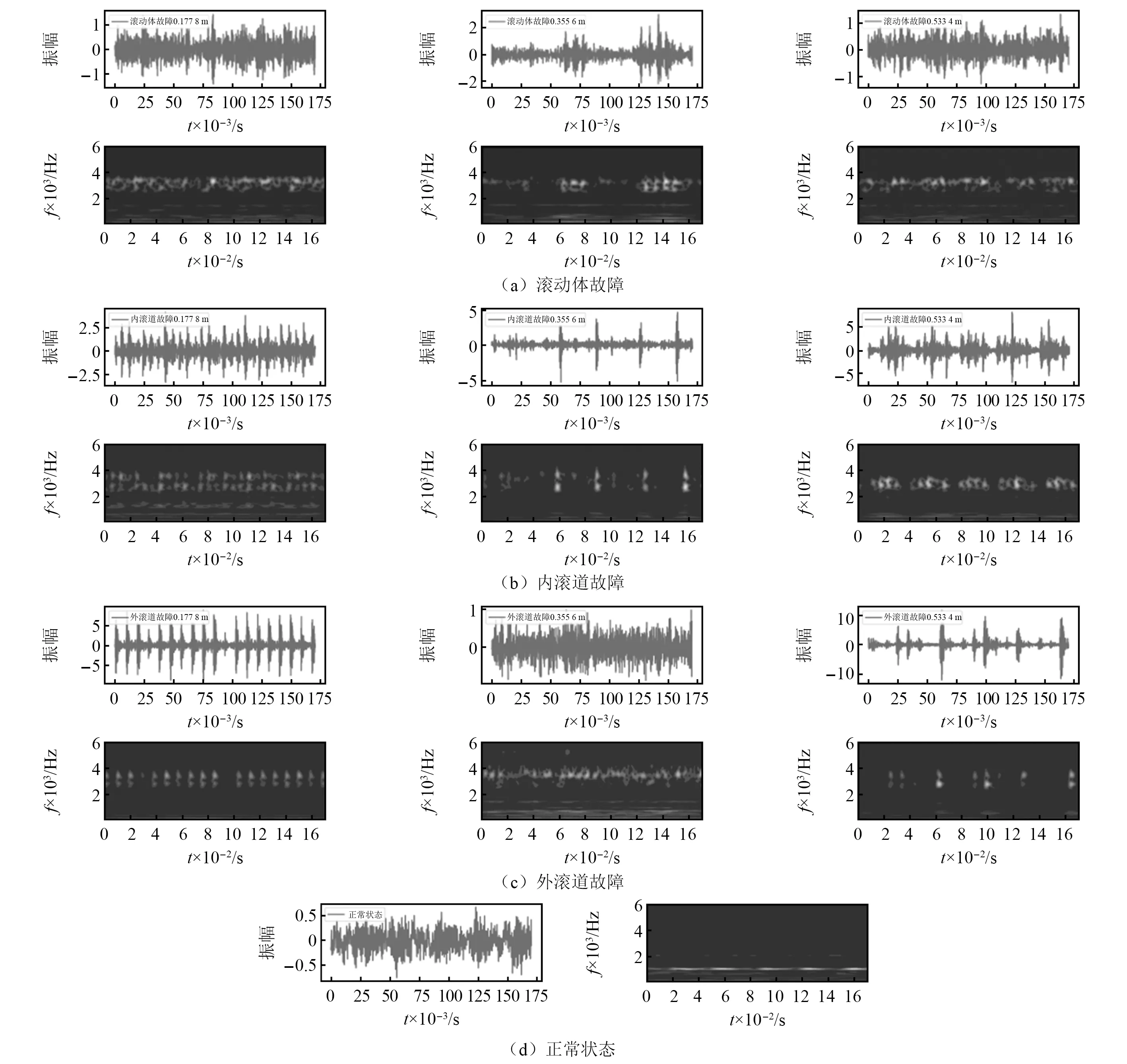
圖12 圖像數據集Fig.12 Image data set
3.2 不同預訓練模型的結果與分析
為驗證殘差神經網絡的有效性,采用不同深度學習常用模型對CWT變換后的二維時頻域圖像進行故障診斷分析,本文采用3種常用的深度學習模型(LeNet、CNN和BiLSTM)作為預訓練模型的對比試驗。
LeNet模型有2個卷積層。在傳統LeNet模型的基礎上把平均池化層改成了最大池化層,激活函數采用relu,后面把原先的3個全連接層換成了2個全連接層。采用的CNN模型有4個卷積層,模型中加入了批量規范化,可持續加速深層網絡的收斂速度。BiLSTM相比較于傳統單位LSTM添加了反向傳遞信息的隱藏層,可以進行雙向傳遞,以便于更好的處理信息。
模型訓練在0工況下,將該工況下的滾動軸承數據集樣本按照60%,20%,20%的比例隨機分配到訓練集、驗證集與測試集中。
圖13(a)和圖13(c)是在0工況條件下,4種算法在迭代50輪之后的訓練集和驗證集的損失,LeNet、CNN和ResNet訓練損失出現了明顯的下降,其中ResNet模型下降速度最快,而且訓練損失最小,達到0.012 4,驗證集損失達到0.001 9。圖13(b)和圖13(d)反映4種算法的訓練集和驗證集的準確率,CNN和ResNet模型上升趨勢明顯,而且收斂較快,特別是ResNet模型在迭代到第10輪時就出現了收斂,最后穩定在一個定值,訓練集穩定在100%,驗證集穩定在96.59%。
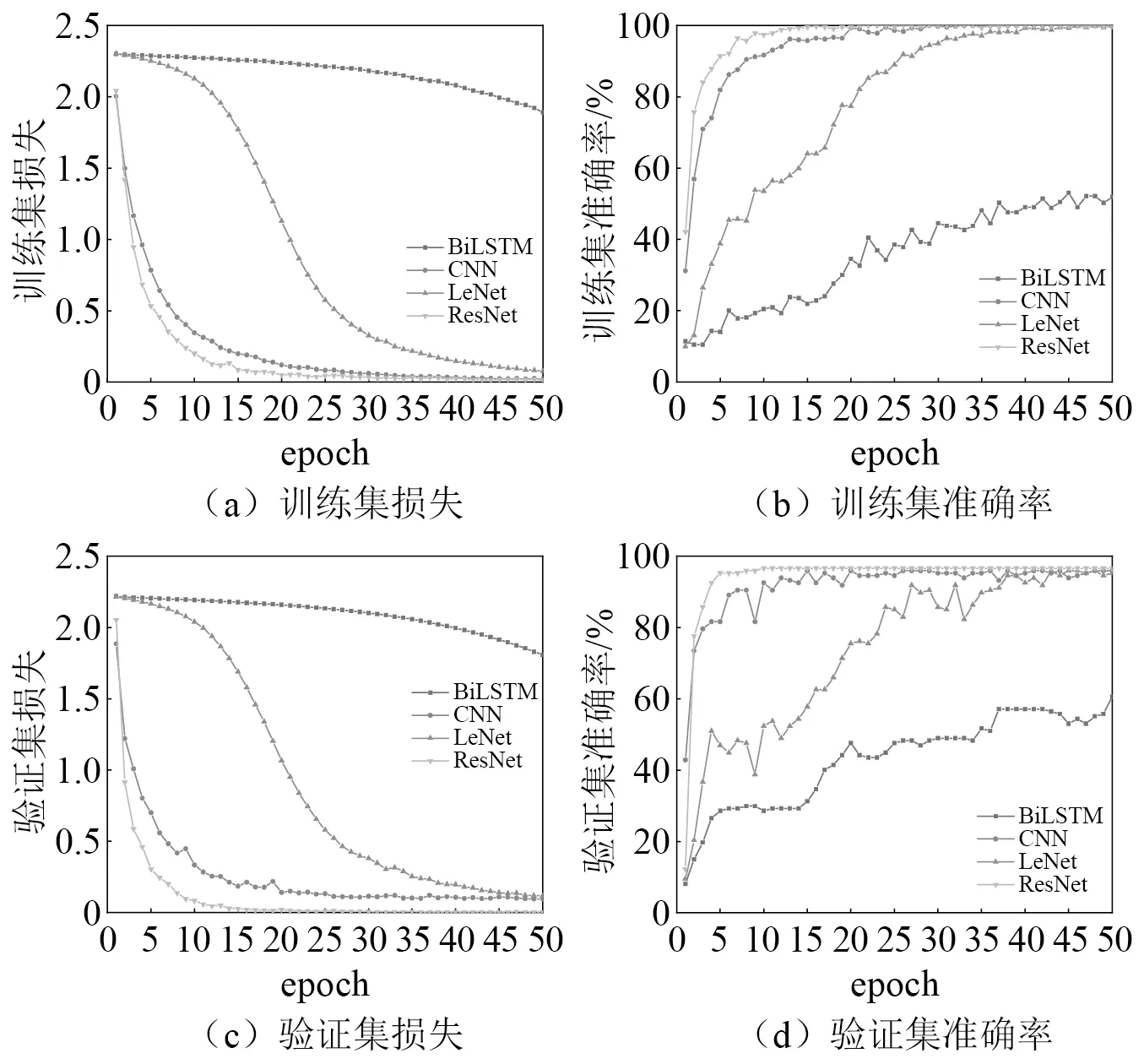
圖13 0工況下不同模型訓練Fig.13 Training of different models under 0 condition
表4給出了在0工況下測試集的準確率和測試時間,ResNet模型在測試集的準確率最高,但是測試時間相對較高,是因為ResNet模型里面有4個殘差層,相對于其他深度學習模型復雜度較高,隨之測試時間也比較長。

表4 0工況下不同模型測試集準確度Tab.4 Accuracy of test sets of different models under working 0 condition
3.3 不同工況間的模型遷移試驗結果與分析
利用在CWRU數據集提供的4種不同的工況,首先在0工況下訓練模型,直接遷移到735 W, 1 470 W, 2 205 W工況中,把全部的數據當成測試數據,其測試結果如圖14所示。ResNet模型雖然相較于有訓練集的測試準確率有所下降,但整體來說下降不多,下降最大幅度為3%,但是對于其他模型來說下降很明顯,尤其是CNN模型,在0工況下有訓練集的測試準確率為96.60%,但是在無訓練集時向其他3種工況直接遷移的測試準確率僅在55%~67%,下降最大幅度達到41%,由此可以看出CNN模型泛化性很差,相對于其他模型來說ResNet模型表現較好。
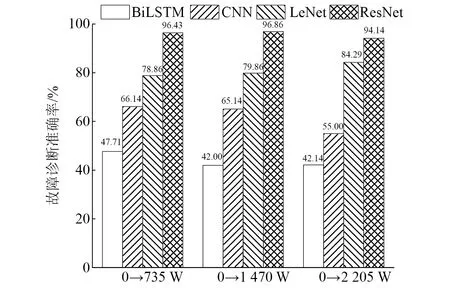
圖14 不同工況間的模型遷移對比圖Fig.14 Model migration comparison between different working conditions
3.4 基于注意力機制的ResNet模型優化
由3.3節可知,雖然ResNet模型相較于其他深度學習模型表現出了較強的泛化性,但整體還是有所下降,所以本小節在基于注意力機制對ResNet模型進行優化,來提高ResNet模型的泛化性。主要采用注意力模塊中的SENet和CBAM,構建SE-ResNet模型和CBAM-ResNet模型。
通過t-SNE分布領域嵌入算法可以提取出的故障特征,降維至二維平面,并以散點圖的形式呈現。將未經過時頻域處理的原始數據和經過ResNet模型變換后的數據進行可視化,降維可視化結果如圖15所示。從圖15中可以看出,ResNet模型具有出色的特征提取能力。
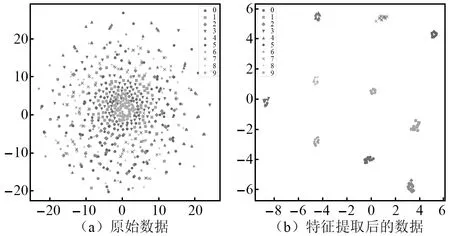
圖15 t-SNE可視化結果Fig.15 t-SNE visualization results
為了便于直觀地觀察優化后的SE-ResNet模型和CBAM-ResNet模型的準確率,本文還使用了混淆矩陣,通過混淆矩陣更加清晰的顯示測試集對滾動軸承狀態的識別狀況,不同工況間的模型遷移結果如圖16、圖17和圖18所示。
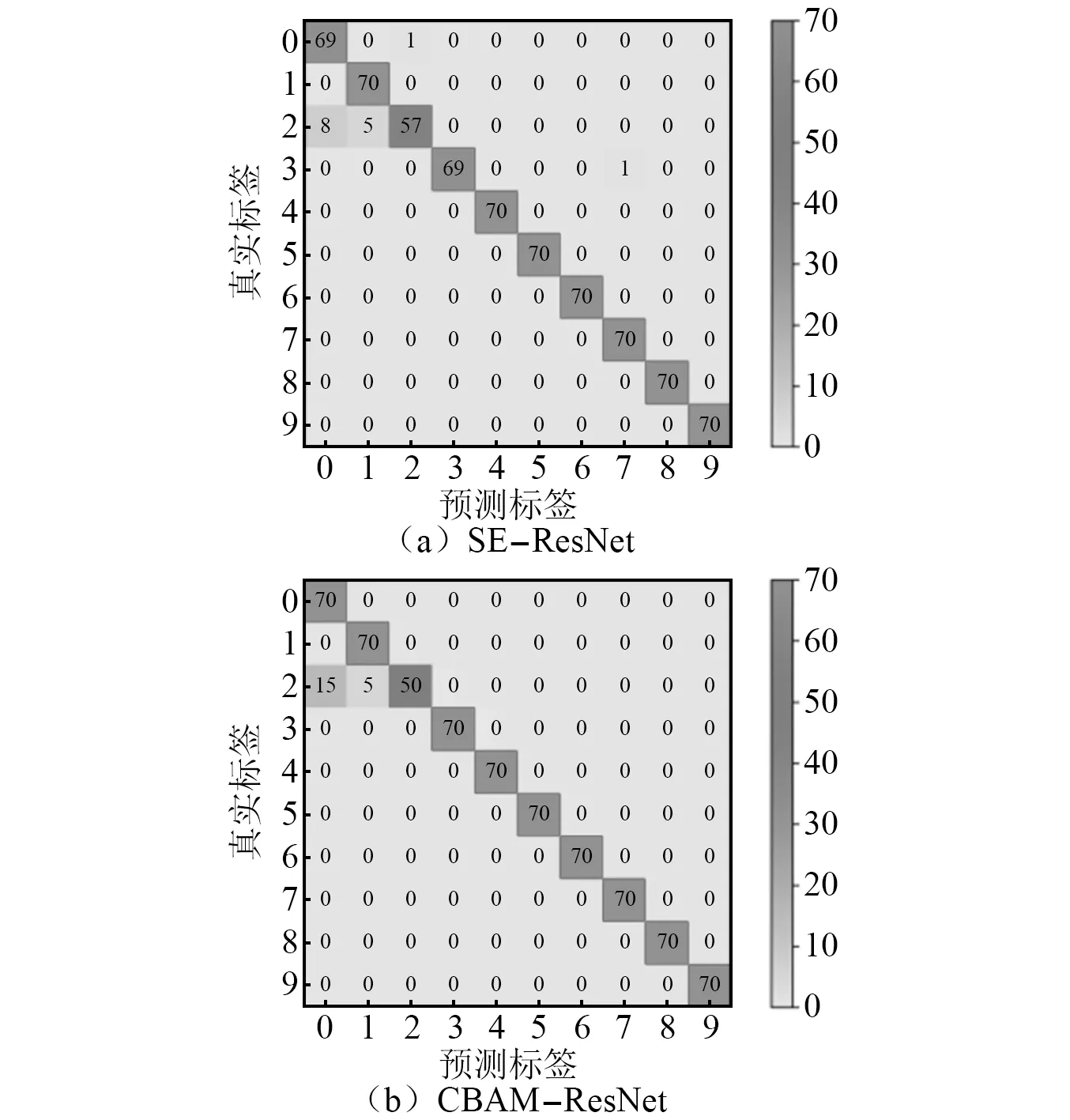
圖16 0→735 W混淆矩陣圖Fig.16 0→735 W confusion matrix diagram
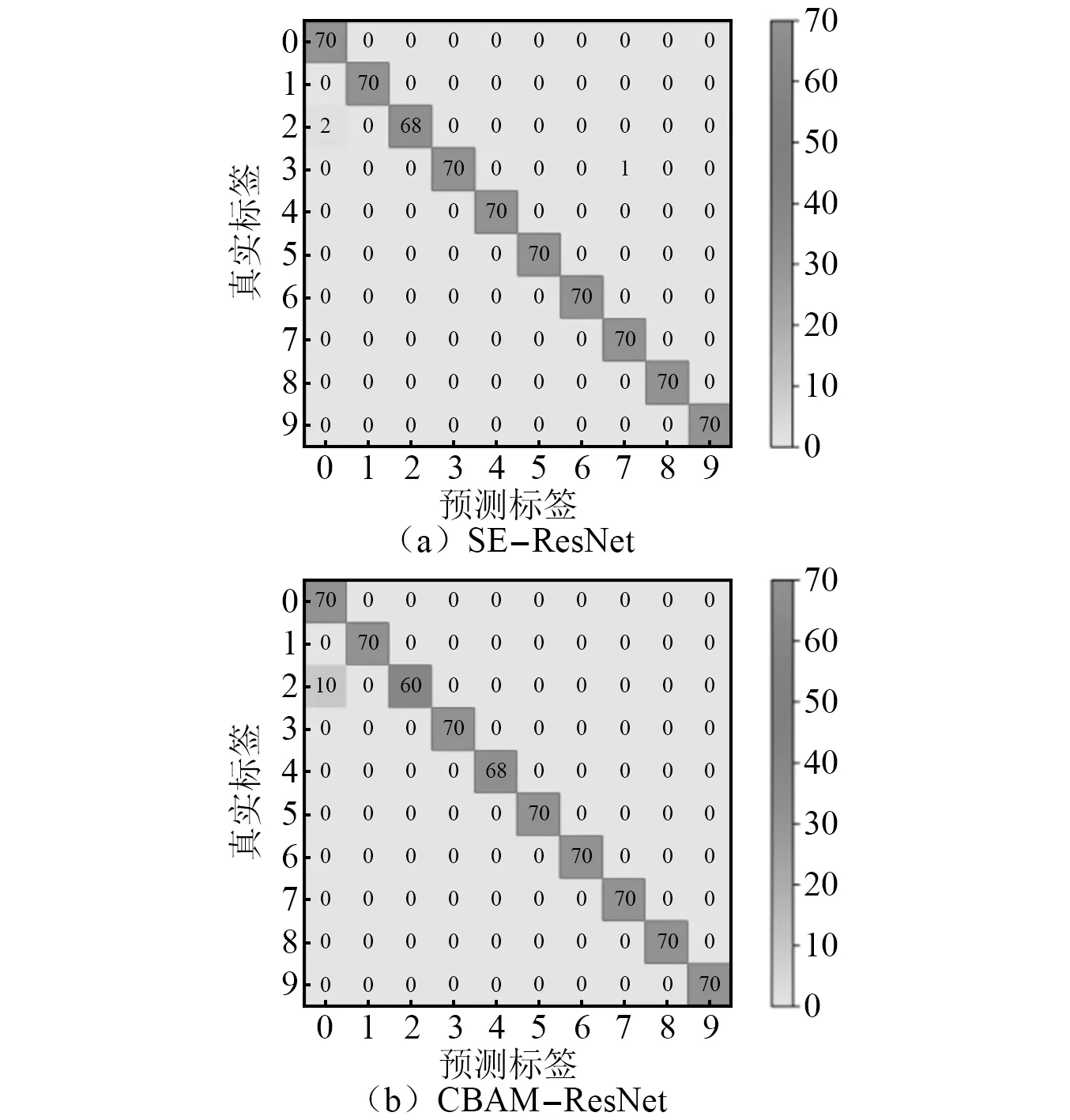
圖17 0→1 470 W混淆矩陣圖Fig.17 0→1 470 W confusion matrix

圖18 0→2 205 W混淆矩陣圖Fig.18 0→2 205 W confusion matrix
由混淆矩陣圖可以看出,在由工況0向其他3種工況遷移過程中,SE-ResNet模型和CBAM-ResNet模型出現標簽識別錯誤的次數很低。在測試速度(如圖19所示),本文提出的兩種模型的測試速度在9~10 s,相比較于ResNet模型相差不大,說明兩種模型雖然加深了網絡,但是整體沒有影響模型的運算速度。在測試精度上(如圖20所示),SE-ResNet模型和CBAM-ResNet模型在向其他3種工況遷移的準確率都高于ResNet模型遷移的準確率,SE-ResNet模型和CBAM-ResNet模型測試準確率分別高達99.71%和98.86%,都高于ResNet模型在同工況有訓練集97.28%的準確率,表現出比ResNet模型更高的準確率和泛化性,起到了模型優化的目的。
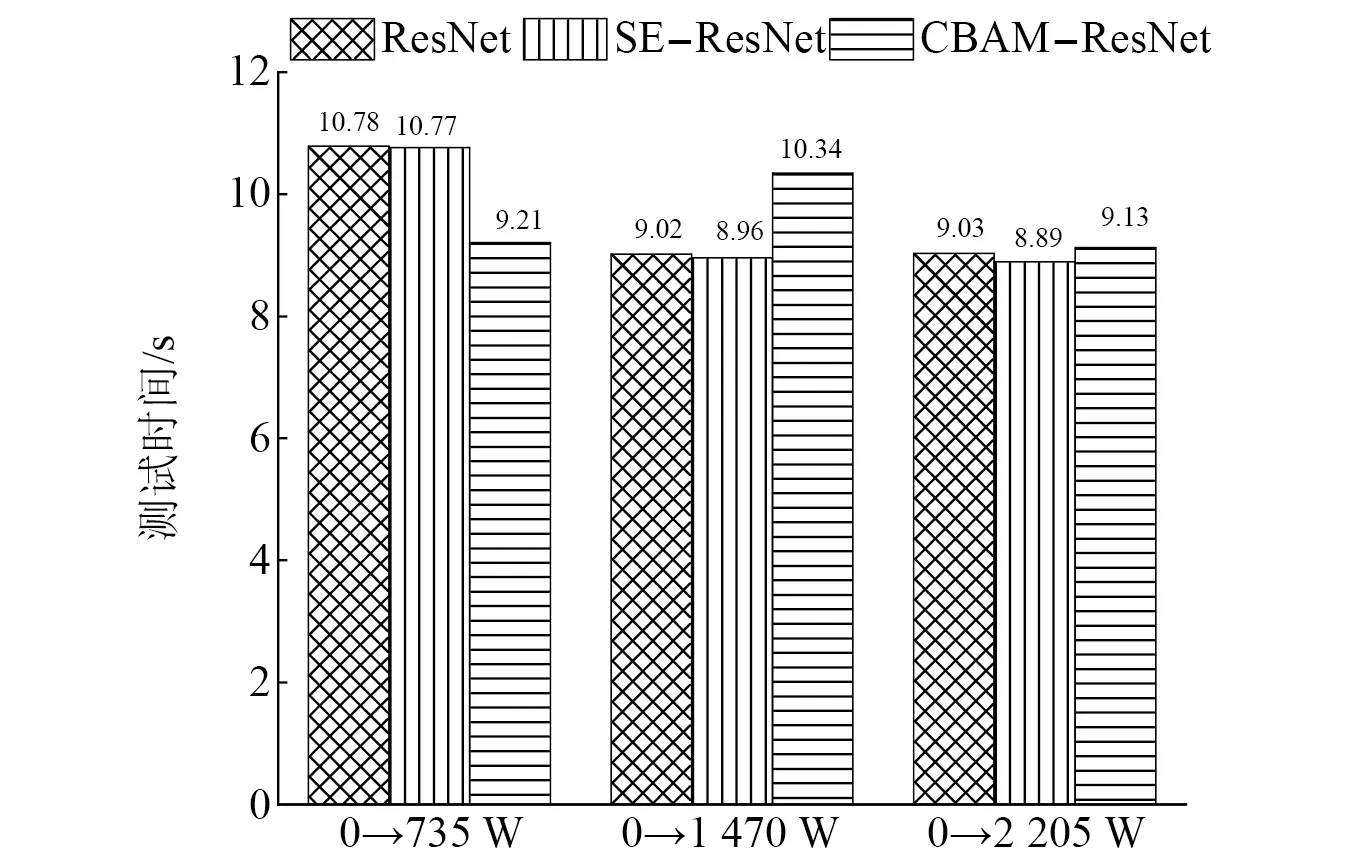
圖19 模型測試時間對比圖Fig.19 Model test time comparison diagram
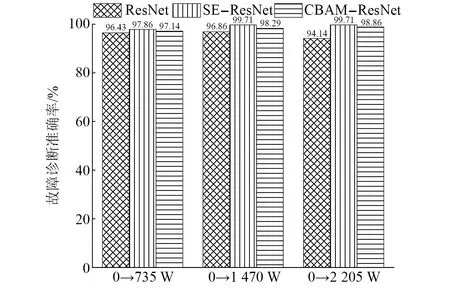
圖20 模型優化效果對比圖Fig.20 Comparison diagram of model optimization effect
4 結 論
針對滾動軸承在不同工況環境中故障診斷訓練時間長、準確率低和泛化性能能弱的問題,提出了一種基于注意力機制改進殘差神經網絡的軸承故障診斷方法。得出的結論如下:
(1) 提出的ResNet比ResNet18模型具有更快的收斂速度。與其他3種常用的深度學習模型(LeNet,CNN和BiLSTM)相比無論是在同工況還是不同工況之間的模型遷移,ResNet模型的測試精度遠遠高于其他幾種深度學習模型。
(2) 對于模型的優化,SE-ResNet模型和CBAM-ResNet模型雖然加深了網絡,但測試速度相比較于ResNet模型變化不大。在測試的準確率上,SE-ResNet模型在不同工況遷移的準確率達到97.86%~99.71%,CBAM-ResNet模型在不同工況遷移的準確率僅為97.14%~98.86%,高于ResNet模型在不同工況遷移的準確率,而且大部分測試高于同工況有訓練集的準確率,表現出比ResNet模型更強的準確率和泛化性,起到了模型優化的目的。
(3) 基于注意力機制改進殘差神經網絡的算法實現了不同工況間的直接遷移,注意力機制的本身特點就是注意到有用的信息,拋棄無用的信息,雖然加深了網絡,但不會減慢模型的運算速度,而且在測試的準確率上高于其他常用的深度學習算法不同工況的直接遷移和同工況有訓練集的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
裝備制造技術(2020年3期)2020-12-25 05:22:30
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
核科學與工程(2015年4期)2015-09-26 11:59:03
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
