
基于數據驅動的催化重整產品質量預測
2023-09-06 12:48:22潘艷秋張超陽李鵬飛
石油煉制與化工 2023年9期
潘艷秋,張超陽,李鵬飛,俞 路
(大連理工大學化工學院,遼寧 大連 116024)
2022年,工業和信息化部印發了《“十四五”推動石化化工行業高質量發展的指導意見》,指出石化化工行業要推動產業結構調整、加快改造提升、提高行業競爭能力[1]。煉化企業可以通過信息智能化轉型來開發提升產業競爭力的核心技術,助力煉化企業實現高效綠色化的增質提效[2-3]。
催化重整是生產石化原料和提升汽油質量的重要手段[4],全球約27%的汽油來自重整汽油、70%以上的芳烴來自重整芳烴、50%以上的煉油用氫來自重整產氫[5]。目前,針對催化重整裝置的研究以對裝置各單元進行建模和過程優化為主,如王連山等[6]針對某煉油廠連續催化重整過程提出了一種38集總組分動力學模型,并應用序列二次規劃法(SQP)進行優化求解,最終可將芳烴收率提高0.17%。宋舉業等[7]以中國石化洛陽分公司1.2 Mt/a連續催化重整裝置為背景,建立了C4/C5分離流程模型,并對塔底溫度和進料溫度進行優化,實現降本增效達450萬元/a。Askari等[8]利用Aspen HYSYS軟件對煉油廠催化重整裝置進行模擬,考察了原料組成、反應溫度、反應壓力對最終產品分布和汽油辛烷值的影響,結果表明該動力學模型準確,模擬方法有效。
由于催化重整加工過程機理十分復雜,重整裝置具有時滯性強,操作參數高非線性、強耦合性特點,因而構建與實際運行狀況高度一致的機理模型難度很大。隨著互聯網技術和大數據技術的快速發展,以神經網絡為代表的數據驅動建模技術成為化工過程機理研究的重要手段[9]。例如,王杰等[10]以某煉化企業運行數據為基礎,結合最大信息系數(MIC)法和Pearson相關系數法篩選出22個變量,基于BP神經網絡建立了汽油研究法辛烷值(RON)預測模型,并采用遺傳算法(GA)對模型參數進行優化,使重整汽油RON損失降低了25%。石翠翠等[11]針對特征變量存在高度非線性和冗余的特點,提出了一種基于偏最小二乘回歸(PLS)和互信息(MI)組合降維的改進天牛須搜索算法(RSBAS)優化的BP神經網絡模型(PLS-MI-RSBASBP),用于S Zorb裝置汽油辛烷值預測。結果表明,相較于普通BP神經網絡模型,該模型的預測性能更優秀。
然而,針對催化重整裝置的數據驅動建模研究目前仍鮮有報道。基于此,本課題以國內某煉油廠催化重整裝置實際運行數據為基礎,通過設置數據篩選和處理規則構建BP神經網絡數據驅動模型,用以預測重整裝置苯產品中甲苯和非芳烴含量;進而通過實際應用效果對該模型進行評價,為后續全裝置實時優化與平臺模型集成提供技術支撐。
1 數據采集與處理
以某煉油廠連續催化重整裝置為對象,按每1 h采集1次數據的頻率,連續采集了其運行45 d的實時數據,共計1 000組數據。每組數據均包括流股流量、系統溫度、流股組成共3類60個變量參數。其中部分關鍵數據如表1所示。由于通過實時監測系統獲取的裝置操作數據經常存在隨機誤差、儀表故障、記錄錯誤等問題,而且部分變量間存在高度相關性,不能直接用于數據建模,因此需要進行數據處理以提高數據質量。
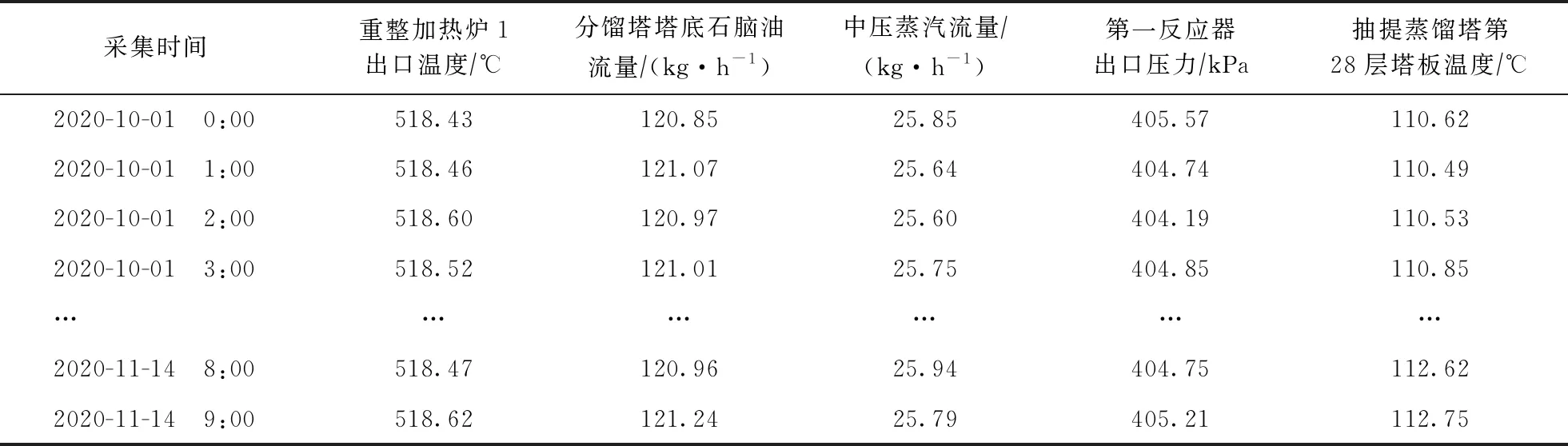
表1 部分變量數據采集結果
1.1 數據預處理
(1)數據初篩:①剔除恒為零的數據;②保留能夠代表裝置運行狀況的變量。初篩后每組數據由60個變量減少為30個變量。
(2)顯著誤差校正:由于裝置實時運行數據樣本為正態分布或近似正態分布,故依據拉依達準則[12]進行數據顯著誤差檢測和校正。
1.2 數據無量綱化處理
數據樣本中不同變量的量綱和數據量級不同,無法直接用于建模分析,故采用線性無量綱法[13]中的極值法對數據樣本進行無量綱化處理,在盡可能縮小各變量數據間數量級差異的同時保持變異系數盡量不變[14]。數據無量綱標準化處理方法見式(1)。
(1)
式中:x為原數據;x′為標準化后的數據;xmax與xmin分別為原數據的最大值與最小值。
1.3 變量相關性分析
基于重整裝置運行過程的復雜性,裝置實時變量數據之間存在高度非線性關系和強相關性。為避免冗余變量加大模型的計算量及模型臃腫性,需要篩選出與目標變量具有強相關性的變量作為模型輸入變量。由于輸入變量之間也存在強相關性,所以需要去除輸入變量之間具有強相關性的變量,保證數據的高質量。常見的變量相關性分析方法有Pearson,Spearman,Kendall,MIC等[15],其中MIC方法適用范圍更廣、計算復雜度較低、魯棒性較高[16-18],更適用于催化重整裝置的變量相關性分析。MIC方法基于隨機變量的n個觀測值來計算,見式(2)。
(2)
式中:a、b分別是網格劃分數量;B為最大網格數,式中B=n0.6[18];X,Y為基于網格的兩個離散變量;I(X,Y)為互信息。其中,0≤MIC≤1;當MIC(X,Y)=0時,說明兩個變量相互獨立;當MIC(X,Y)=1時,說明兩個變量線性相關。
1.3.1輸入變量與目標輸出變量間相關性分析
采用MIC法計算初步篩選后28個輸入變量與2個目標變量間的相關性,結果如表2所示。其中MIC1和MIC2為各輸入變量分別與目標輸出變量1、2的MIC分析結果。
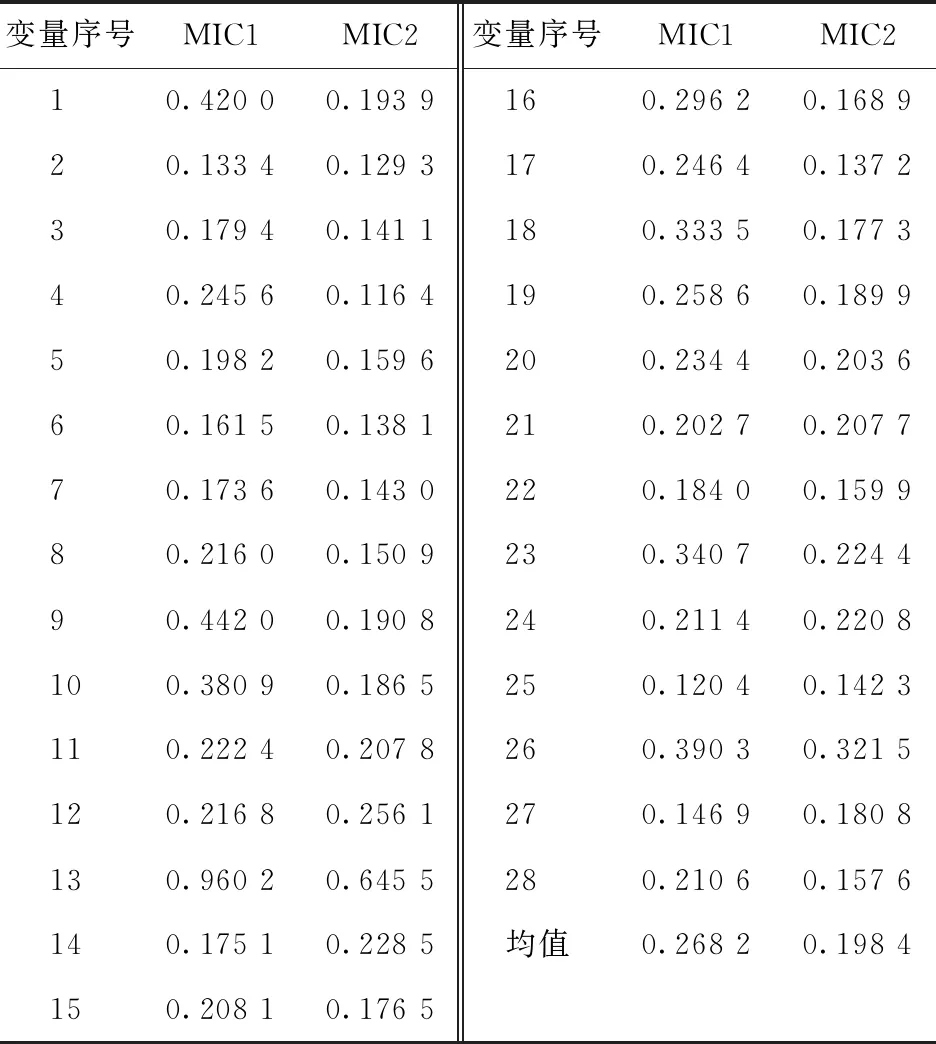
表2 輸入變量與目標變量的相關性
為了盡可能地保留關鍵變量,以所有MIC計算結果的平均值作為分界線對變量進行取舍。由表2可知,輸入變量與輸出變量1、2的相關性均值分別為0.238 2和0.198 4,而對兩個輸出變量的平均均值為0.233 3。因此,舍去相關性小于0.233 3的15個輸入變量[15,19],保留高于平均均值的13個變量,進行變量間相關性計算。
1.3.2輸入變量間相關性分析
同樣,采用MIC方法對上述13個輸入變量進行相關性分析,結果見圖1。
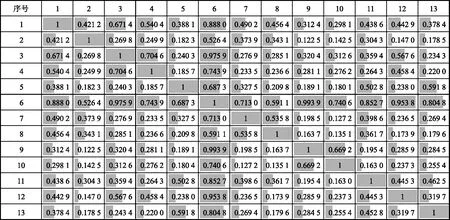
圖1 輸入變量間相關性分析結果
由圖1可知,變量6(裝置產氫流量)與多個變量間相關性系數較大(≥0.8),說明其相關性較高,故舍去變量6[20-21]。最終,共保留12個輸入變量用于建模,見表3。
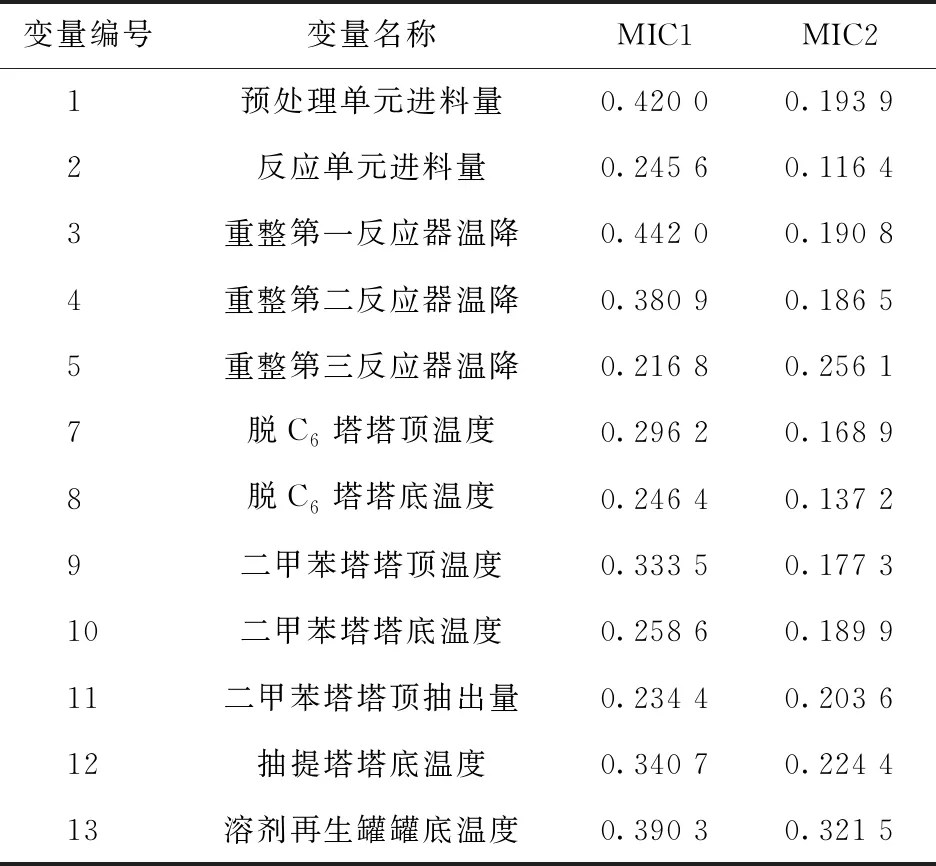
表3 相關性分析后優選的輸入變量
2 模型構建與計算結果
BP神經網絡具有很強的非線性擬合能力,對具有復雜運行狀況和數據強非線性特點的連續催化重整裝置建模尤為適用[22]。采用性能優異的B-R訓練算法[23],將上述預處理好的數據樣本按照70%,15%,15%的比例隨機劃分為訓練集、驗證集、測試集3組,訓練集和驗證集數據樣本用于模型參數的訓練,測試集數據樣本用于驗證模型的泛化能力。
2.1 模型結構的確定
2.1.1隱含層數的確定
在隱含層數分別為1~5、每層神經元數分別設置為6,8,10的情況下[23],選擇回歸系數R和均方根誤差RMSE作為評價指標,回歸系數R越大,說明模型的預測值越接近真實值,表示模型越精確;均方根誤差RMSE越小,表明計算值與真實值誤差越小,采用多次計算、對結果求平均值的方法評價不同模型結構對神經網絡模型預測精度的影響,結果如圖2所示。
由圖2(a)可知:對于目標變量苯產品中非芳烴組分含量,當隱含層神經元數為6、隱含層數為3時,獲得最大的R和最小的RMSE;當隱含層神經元數為8或10、隱含層數為3時,獲得較大的R和較小的RMSE(效果僅次于隱含層數為4時)。由圖2(b)可知:當隱含層數為3,隱含層神經元數分別取6,8,10時,均獲得最大的R和最小的RMSE。綜合考慮隱含層數對兩個目標變量的影響,神經網絡模型隱含層數選擇3為宜。
2.1.2神經元數的確定
依次使用公式經驗法和反復試驗法來確定模型隱含層的神經元數和最佳神經網絡結構[24]。隱含層神經元數由式(3)計算。
(3)
式中:Nhid為隱含層神經元數;Nin為輸入層神經元數;Nout為輸出層神經元數。
輸入變量數為12、輸出目標變量數為2,由式(3)可初步確定Nhid=6。在此基礎上,將每層神經元數范圍擴展為4~8個,探討神經元數不同對模擬結果的影響。在優化隱含層數為3條件下計算共獲得125種組合結構模型的模擬結果,每種組合計算200次,其均值如表4所示。由表4可知,3層隱含層的神經元數分別為8,6,8時(第115組計算結果),模型回歸效果最好。最終,優化得到的BP網絡模型結構為(12,8×6×8,2)。

表4 不同神經元組合計算結果
2.2 計算結果分析
基于上述優化的BP網絡模型結構進行訓練,由測試集數據樣本得到模型性能結果,見表5。由表5可知:①對于產品苯中非芳烴含量與甲苯含量,模型預測結果的回歸系數分別為0.872 1和0.901 2,說明模型預測值與真實值一致性較好,該模型能夠很好地預測裝置運行的波動性;②二者的均方根誤差分別為0.012 4和0.046 3,表明預測值與真實值偏差較小;③二者平均相對誤差(MRE)分別為1.036%和3.312%,表明所建模型預測結果的準確性良好,能夠滿足化工裝置控制精度要求。
圖3為采集數據裝置運行的真實值與所建神經網絡模型預測值的對比結果。由圖3可以看出,隨著裝置運行時間的增加,預測模擬值與裝置真實值的變化趨勢相同且吻合良好,表明所建模型的預測結果具有較高的準確性,達到了利用該模型預測裝置產品中非芳烴含量和甲苯含量的目的,可以用于后續優化工作。

圖3 苯產品中非芳烴和甲苯含量模擬值與真實值變化趨勢對比
3 裝置操作參數優化
結合現場裝置參數調節難度和操作參數對產品質量(苯產品中非芳烴和甲苯含量)影響程度的大小,選取易于調控、對產品質量影響程度較大的5個參數進行優化分析,并確定參數優化合理區間,見表6。除待優化輸入變量外,其他輸入變量采用2.1節預處理后變量數據的平均值。
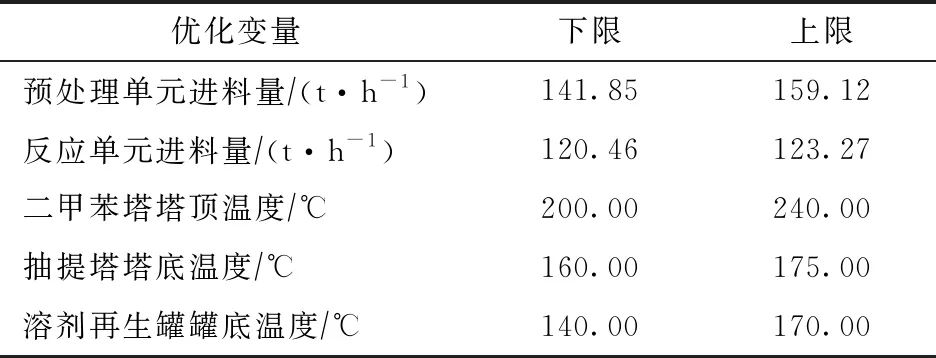
表6 優化參數及其變化范圍
采用帶精英策略的遺傳算法NSGA-Ⅱ對上述變量參數進行優化求解,求解器參數設置:最優個體系數為0.3,種群規模為200,最大進化代數為500,停止代數為200,適應度函數偏差為1×10-4,其他參數設置為函數默認值。輸入變量參數的變化范圍介于變量變化下限與上限之間,優化目標為苯產品中非芳烴質量分數(y1)和/或甲苯質量分數(y2)最小。變量優化結果見圖4,圖中點N代表催化重整裝置正常操作點,點A、點B、點C分別為優化后的操作點。優化后的輸入變量和目標函數如表7所示。
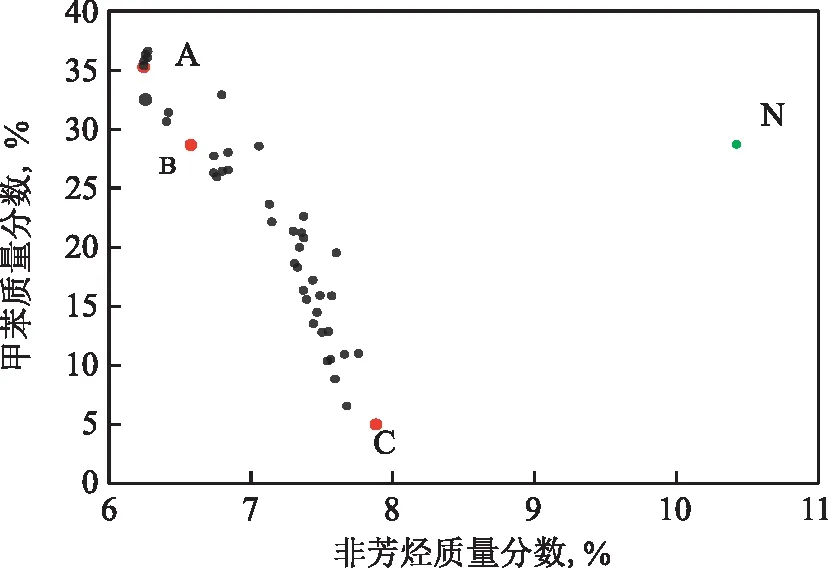
圖4 多目標優化最優解集

表7 最優解優化變量及目標函數
由圖4可以看出,對催化重整裝置苯產品質量優化的方案有3種:①為最大程度降低產品中非芳烴含量,則選擇操作點A工況,此時產品中非芳烴質量分數降低40.12%,但甲苯含量有所增加;②為保持甲苯含量不增加的同時降低非芳烴含量,則選擇操作點B工況,此時產品中非芳烴質量分數降低36.85%;③為同時降低苯產品中非芳烴和甲苯的含量,則選擇最佳操作點C工況,此時苯產品中非芳烴和甲苯的質量分數分別降低24.38%和82.58%。從以上分析可知,可通過改變相關操作參數實現提高苯產品質量的目的,方案③對應的操作點C工況對提高苯產品質量的效果最佳。
4 結 論
(1)基于催化重整裝置的實時數據,建立了實時數據處理規則,將采集到的60個變量簡化至14個,在保證數據完整性和準確性的同時,降低了數據的維度,為后續建模提供了簡約的數據集。
(2)基于處理后的數據集,建立了苯產品質量的預測模型,當模型輸入變量為12個,輸出變量為2個,隱含層為3層,3層隱含層的神經元數分別為8,6,8時模型的預測結果最優,因此優化的模型結構為(12,8×6×8,2)。
(3)經過模型訓練和驗證,對于苯產品中的非芳烴含量與甲苯含量,模型預測結果的回歸系數(R)分別為0.872 1和0.901 2;二者的均方根誤差分別為0.012 4和0.046 3,平均相對誤差(MRE)分別為1.036%和3.312%,表明所建模型預測值與真實值一致性較好,預測精度較高。
(4)采用帶精英策略的遺傳算法NSGA-Ⅱ對影響產品質量較大的5個操作變量進行優化,優化后的工況下,苯產品中非芳烴和甲苯質量分數分別可降低24.38%和82.58%,說明所建模型可用于裝置的產品質量預測和調控,有利于現代工廠智能化建設。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
