面向鋁箔車間綜合能耗預測系統的研發與應用*
2023-09-18 08:42:12陳雪斌袁逸萍財音寶音朱廣賀
制造技術與機床 2023年9期
陳雪斌 袁逸萍 財音寶音 朱廣賀
(①新疆大學智能制造現代產業學院,新疆 烏魯木齊 830046;②新疆師范大學計算機科學技術學院,新疆 烏魯木齊 830054)
鋁電解電容器是一種基本電子元件,主要作用是在電路中存儲電能、濾波和平滑直流電源。近年來,隨著新能源發展和5G 基站的快速增長,使得鋁電解電容器需求量不斷增加。電子鋁箔和電極箔屬于鋁電解電容器的上游產品,生產過程中的多次軋制或腐蝕、化成需要消耗大量能源,而傳統工業手動記錄和人工監測的方式存在著采集周期長、數據準確性低以及缺乏實時性等弊端。如何提高能源利用效率已成為高耗能企業所關心的重要問題。
隨著制造企業數字化的興起,能耗監測系統已成為解決上述問題的一種有效手段。吳曉為實現能耗在線監測,實時、準確地掌握關鍵工序的能源消耗的情況而提出建設數字化能源管控系統的明確目的[1]。張琦等設計了一套企業智慧能源管控系統,基于人工神經網絡建模的方法實現了對某鋼鐵企業的能源供需量預測[2]。鞠文杰等設計出應用于工業節能的能耗在線監測系統,該系統實現了對企業運行狀態時的能耗監測、安全預警[3]。童世華從遠程監測管理的角度設計了一種車間能耗實時監測系統,實現對車間實時能耗情況的檢測[4]。
上述研究實現了能耗監測的基本功能和需求,同時也在能耗監測方面做出了巨大貢獻,但對于所采集能耗數據缺乏重視,僅對數據采集及展示,并未采取有效的方法去處理、挖掘能耗數據中所蘊含的潛能,例如不同車間的同環比分析、趨勢分析、設備的臺賬功能等,從而造成部分資源浪費。針對上述情況,結合新疆某鋁箔車間需求,搭建了一種從能源數據采集-能源消耗實時監控-能源消耗數據統計-能源消耗數據分析預測-能源數據分析報告等全過程的能耗預測系統。
1 系統總體網絡架構設計
系統整體由感知層、傳輸層和應用層構成[10],其結構框架如圖1 所示。
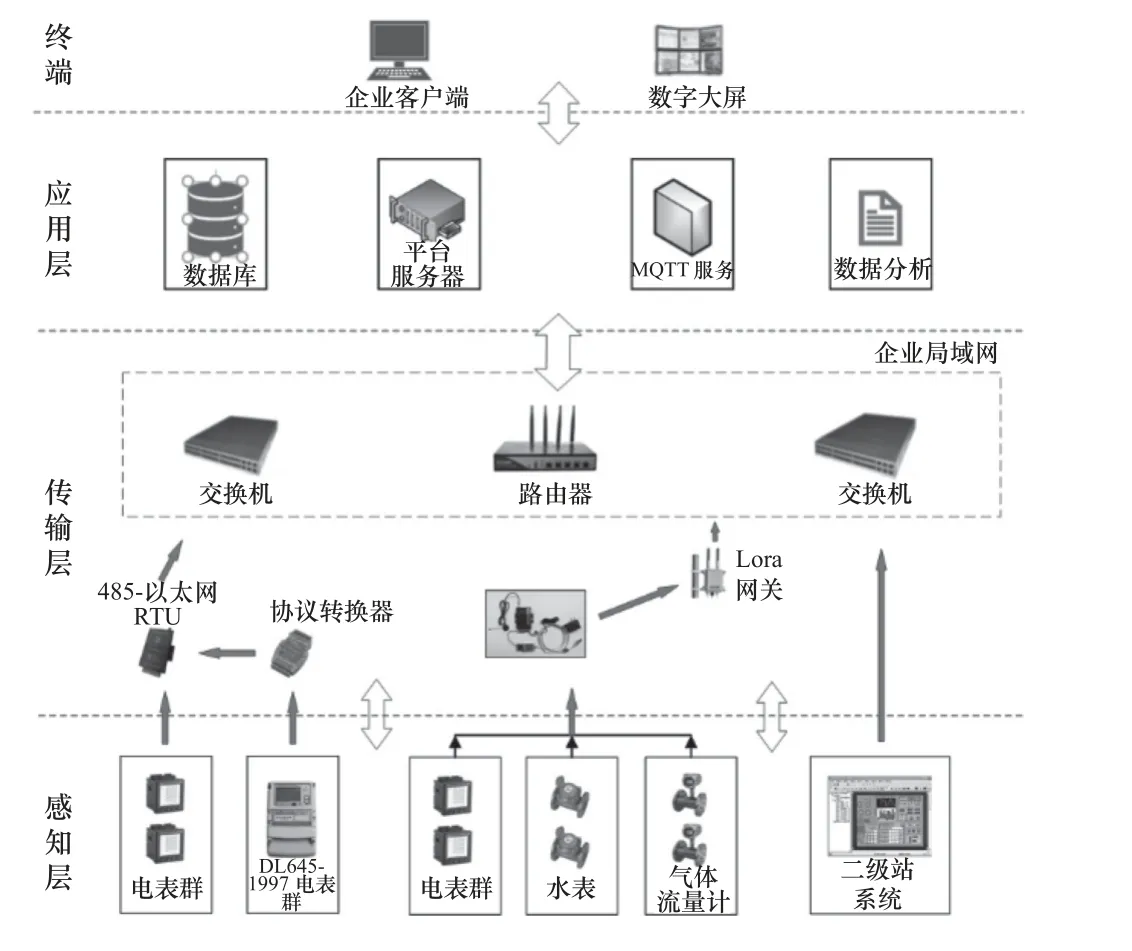
圖1 系統總體架構
1.1 感知層
感知層實現底層數據采集。由于企業內部存在部分有線方式無法接入的智能電表,系統以Lora無線的方式將數據上傳到Lora 網關中,再將數據匯總至中心服務器。除此之外的區域均采用智能電表、電子遠程水表、流量計等儀器對采集單元數據進行采集。
1.2 傳輸層
傳輸層由Lora 網關和通信網絡組成,主要對所采集的數據信息進行解析和傳輸。為保證數據傳輸過程的穩定性,系統采用以光纖傳輸為主的能源數據采集。Lora 節點使用Lora 連接到Lora 網關,Lora 網關位處于其星形網絡的核心位置,由Lora網關連接服務器進行數據的傳輸。
1.3 應用層
應用層實現對傳輸到平臺服務器的數據進行分析、處理及存儲的功能。該層中,MQTT 服務提供一對多的消息發布,實現對能耗數據信息的發布與訂閱[5]。系統數據庫采用MYSQL 搭建主從復制集群,并在此基礎上實現系統對數據庫的讀寫分離。最終通過Web 直觀地向企業人員展示不同車間的實時能源數據、能耗監測和設備掉線預警等信息。
2 系統的軟硬件設計
2.1 硬件設計
系統硬件主要由智能采集表、Lora 模塊和LoraWAN 網關組成。組網方式選取單跳網絡,采用協議為星形拓撲網絡,如圖2 所示。

圖2 星形拓撲網絡
智能采集表負責采集水、電和氣等能耗數據。
Lora 模塊的主要任務是利用Lora 網絡對智能表數據進行接收與傳輸。結構原理如圖3 所示,終端選用核心處理器為Semtech SX1276 的L8DTU Lora 模塊,模塊支持全球各地多種頻段(433/470/780/868/915 MHz),工作電壓范圍為+7~+30 V,同時提供RS232 和RS485 接口,接口內置15 kV ESD 保護且擁有WDT 看門狗設計,保證系統穩定性。
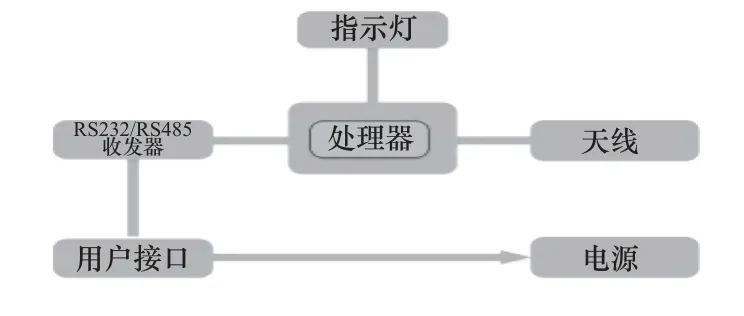
圖3 L8DTU 結構框圖
LoraWAN 網關的主要任務是將節點的數據信息收集,再通過網絡發送到平臺服務器。網關選用RAK7249 WisGate Edge Max,其模塊化和自定義選項允許在部署解決方案時具有靈活性。軟件上內置Lora 服務器,在MQTTv3.1 橋接時進行TLS 加密,最重要的是在NS 中斷時該網關會緩沖Lora 幀,其優勢在于不會丟失數據。數據傳輸流程如圖4 所示。

圖4 數據傳輸流程圖
2.2 軟件設計
系統的功能模塊構成如下:基礎信息管理模塊、實時數據模塊、累計數據模塊、尖峰平谷數據模塊、能源分析模塊、能耗預測模塊、能源預警模塊、臺賬模塊、報表參數錄入、能源點位管理、數據庫表管理模塊和能源可視化大屏模塊。
2.2.1 設計基礎信息管理模塊
系統的基礎信息管理模塊包括用戶管理功能、菜單管理功能和部門管理功能。
用戶管理功能劃分普通用戶、普通管理員和超級管理員3 種角色,普通管理員用于日常為廠區不同車間員工、不同部門的上下級領導操作、查看權限的配置,不同角色權限配置見表1。
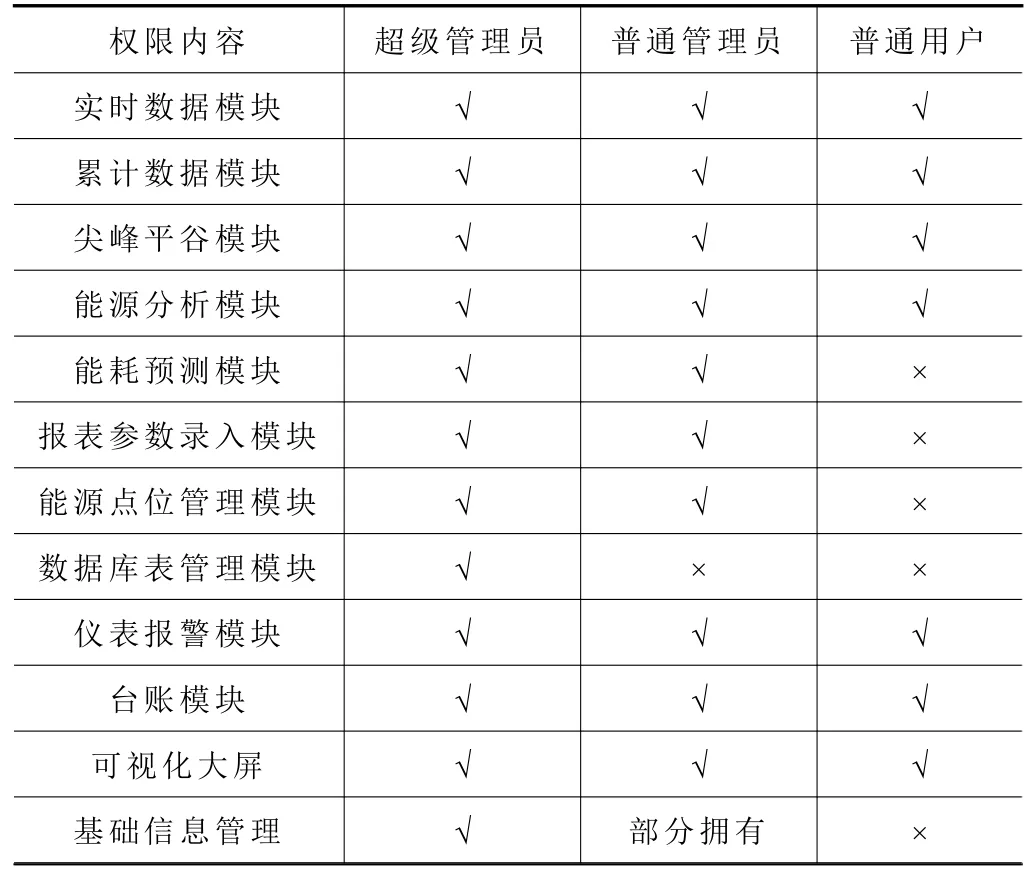
表1 角色權限配置表
2.2.2 實時數據模塊
從具體場景出發,該模塊對壓延、精整、熔鑄、水站和風機房等車間的實時數據進行展示。數據采集間隔15 s,保證對頁面數據的實時性,同時采用“樹-枝”結構進行菜單分區,圖5 所示為冷軋區實時監測界面。

圖5 冷軋區實時監測
2.2.3 設計警報模塊
能源警報模塊的設計包含兩部分,儀表模塊掉線警報和能耗預測異常警報,設計流程如圖6 所示。在底層硬件設計中,單塊Lora 模塊負責若干智能表數據的接收與發送,故對儀表模塊設計了掉線警報功能。當真實數據與預測數據出入較大時,觸發預測異常警報。

圖6 警報功能流程圖
2.2.4 設計能耗預測模塊
能耗預測模塊中的預測模型使用Python 進行實現,考慮到使用Java 第三方庫中的Python 解釋器加載模型可能會出現解釋器運行速度較慢的情況,設計將訓練預測模型包裝在REST API 中,以調用API 的形式獲取模型的預測結果。在系統實時數據的采集傳輸中實現對未來短期能耗趨勢的預測。將預測結果通過前端開源組件Echarts 將實時數據與預測數據以趨勢圖的形式呈現。
3 基于APSO-LSTM 算法的預測模型
對時間序列預測常采用的方法有ARIMA 模型(自回歸移動平均模型)、ES 模型(指數平滑模型)、RW 模型(隨機游走模型)和神經網絡等。ARIMA 模型和ES 模型擅長對具有季節性的時間序列數據進行捕捉,RW 模型是基于假設時間序列中的下一個值加上一個隨機誤差項,該模型擅長對具有較長時間趨勢的時間序列進行預測[7-9]。基于本研究數據集具有的非線性特征,研究選擇具有較強泛化能力的神經網絡(long short-term memory,LSTM)進行預測模型構建。
LSTM 本質上是一種特定形式的循環神經網絡(recurrent neural network,RNN)[6]。在模型的選擇時使用LSTM 模型而不是RNN 模型的原因是,對RNN 模型的訓練,實際上就是借助計算機強大的計算能力對wx、ws、wo、b1、b2求偏導并不斷地進行調整,使損失函數L3盡可能地達到最小。在這個過程中,隨著神經網絡的層數加深對wx、ws會因為時間序列的拉長而產生梯度消失和梯度爆炸。LSTM 通過增加門機制大幅度地減少了這種情況的發生。
LSTM 模型整體由輸入層、隱藏層和輸出層組成。如圖7 所示,LSTM 的隱藏層由一系列結構相同的LSTM 單元組成,每個LSTM 單元的結構包括3 個主要部分:輸入門、遺忘門、輸出門以及一個狀態變量。以下是LSTM 神經網絡在t時刻的更新過程。

圖7 LSTM 原理圖
LSTM 是一種常用的神經網絡模型,在序列數據預測任務中表現良好。其中,LSTM 中的部分參數無法通過訓練數據自動學習而獲得,需要人為手動輸入且這部分參數會直接影響到模型的預測精準度、訓練速度等。目前,LSTM 超參數的選擇通常過分依賴于研究人員的個人經驗和對專業知識的理解度,耗時久且容易受到主觀因素的影響。因此,文章設計一種基于粒子群算法優化LSTM 神經網絡的能耗預測模型,利用改進的粒子群算法對LSTM模型的輸入序列長度和隱藏層單元數進行優化,從而提高預測模型的準確性和魯棒性。
APSO 算法是一種基于粒子群算法的改進算法,通過動態的調整慣性權重,使得粒子在搜索過程中可以更快地找到全局最優解,與LSTM 模型結合具有較強的魯棒性。APSO-LSTM 神經網絡算法步驟如下:
(1)采用最大最小值歸一化對數據預處理,將數據劃分為訓練集和測試集。
(2)將LSTM 模型的輸入序列長度和隱藏層單元數設置為APSO 算法的粒子,通過不斷調整學習因子和慣性權重而不斷調整超參數的值。
(3)定義LSTM 模型和訓練函數,設置優化器和損失函數。
(4)定義目標函數,將輸入序列長度和隱藏單元數作為該函數的輸入,并返回訓練LSTM 模型的損失函數作為性能評估指標
(5)初始化粒子群,包括粒子的速度vi和位置xi設定迭代次數以及學習因子c1、c2。
(6)通過統計對初始種粒子群的適應度,分別記錄粒子群的個體極值和全局極值。
(7)根據更新粒子的速度vi和位置xi分別對粒子群的個體極值和全局極值。
(8)如果滿足結束條件或達到迭代次數,則順延到步驟(9);否則,返回步驟(6)。
(9)輸出最優超參數,并將構建LSTM 模型。
將模型通過訓練集進行訓練,測試集進行預測,輸出預測結果。公式更新為
式中:wmax為慣性權重最大值,wmin為慣性權重最小值,f表示粒子當前目標函數。設定最大慣性權重為1.5,最小慣性權重為0.6,通過不斷增加迭代次數,慣性權重隨著進化狀態而變化,平衡全局和局部的搜索能力,達到全局搜索最優。
4 能耗預測實驗與系統實現
4.1 APSO-LSTM 能耗預測模型實驗
以本系統的應用對象(某鋁箔公司)作為測試數據的來源,廠區內的主體耗能為水、電、氣(天然氣、氬氣等)。在此,以冷軋車間的電量預測作為驗證實驗。取系統2022 年7 月1 日至2022 年10月8 日中的2 400 條數據作為數據集,訓練集與測試集以比率為4∶1 進行劃分。
首先,使用PyTorch 庫構建一個LstmMode 作為LSTM 模型,LstmMode 包含一個lstm 層和一個線性層,以(time_step,batch,input_size)三維張量為輸入,經過lstm 層計算輸出張量x1(time_step,batch,output_size)。將x1展開成二維張量去通過線性層計算,得到一個標量輸出。然后標量輸出被重新展開為三維張量,并返回作為輸出。
其次,選擇tanh 函數為激活函數,PyTorch 庫中的MSE 函數作為損失函數,優化器選擇Adam算法。定義createDataSet 函數,使用滑動窗口法將原始時間序列數據轉換為可供LSTM 模型訓練的輸入和輸出。定義splitData 函數用于劃分訓練集(rate∶0.8)。加載數據集(使用Pandas 庫中的read_csv 函數讀取數據),對數據集進行最大最小歸一化處理。調用createDataSet 函數將處理后的數據進行轉化,調用splitData 函數將轉換后的數據集按照給定rate 進行劃分訓練集和測試集。
接著,定義訓練函數(train_loop)接收nEpoch(訓練總輪數)、model(模型)、optimizer(優化器)、lossFn(損失函數)、trainData(訓練集)五個參數,參數nEpochs 取500,設置初試學習率為0.001,在400 輪訓練后采用乘以因子0.5 來降低學習率,返回訓練好的模型。該LSTM 模型的輸入序列長度為3,隱藏層單元數為6。
然后,利用APSO 算法對LSTM 模型的輸入序列長度和隱藏層單元數超參數進行尋優。第一,定義目標函數,以輸入序列長度和隱藏層單元數作為函數的輸入并返回訓練LSTM 模型的損失函數作為模型的性能評估指標。第二,定義超參數的搜索空間,使用numpy 庫中的linspace 函數來生成一組均勻分布的輸入序列長度和隱藏層單元數值。第三,使用隨機數生成器在超參數搜索空間內隨機選擇一組粒子,每個粒子代表一組超參數并為每個粒子分配一個初試速度,此處對應APSO-LSTM 神經網絡算法的步驟(5),余下步驟與APSO-LSTM 神經網絡算法步驟(6)~(8)一致,直至將最優參數組合輸出。
最后,以輸出最優參數對LSTM 模型進行訓練,重復上述LSTM 訓練過程。
訓練集用于APSO-LSTM 模型訓練,測試集用于驗證模型的預測準確度。使用測試集中的均方根誤差來衡量模型性能,如圖8 所示。公式定義如下:
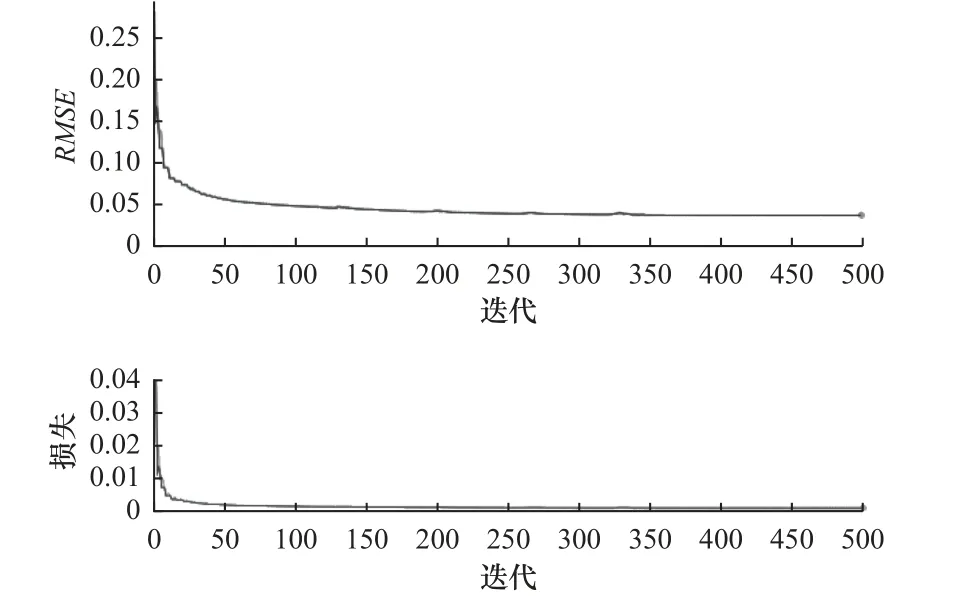
圖8 誤差曲線
式中:N為測試集總數據量;為預測值;yi為實際值。
圖9 為基于APSO 算法找尋最優超參數構建的LSTM 模型預測值與真實值擬合效果圖。APSOLSTM 模型預測值與實際值的擬合度較高,這表明模型經過APSO 優化具有良好的預測效果,對企業的生產計劃和資源配置等提供一定意義的指導參考。
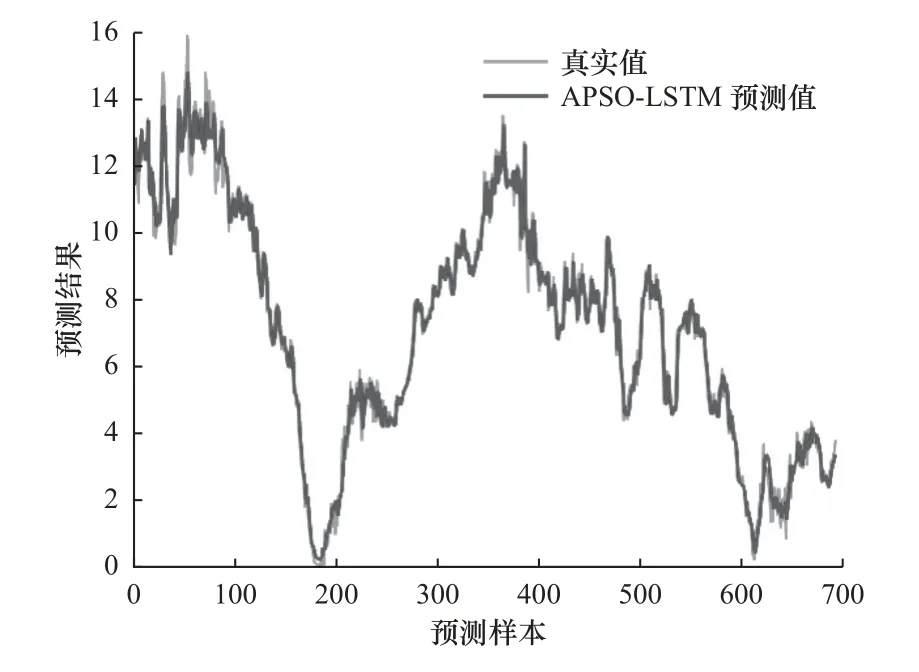
圖9 預測結果對比
4.2 系統實現
上述軟件設計中已列出系統模塊,這里僅展示其中的部分內容。
實時表數據為壓延車間、精整車間、熔鑄車間、水站、機床、風機房的實時能源數據。如圖10 所示,以風機房為例,每個設備包含參數有瞬時流量、表頭累計流量、壓力、溫度、對應時間戳,且界面設有數據導出功能。
圖10 實時數據-風機房
累積表數據分有3 個子菜單,分別為統計表數據、月累積數據和尖峰平谷數據。其中統計表數據由分鐘累積表數據、小時累積表數據、當天累積表數據組成。圖11 所示為日累計界面。

圖11 累計表數據一日累計
能耗分析總開發有6 個子菜單,分別為能源趨勢分析、能耗環比分析、萬元產值能耗分析、單位產品能源成本分析等。圖12 所示為能耗趨勢預測界面,企業管理人員以預測能耗趨勢為參考主動做出生產調整,進而指導生產,降低能源消耗。

圖12 能耗趨勢預測
4.3 預測應用實例成果
新疆某鋁箔企業在2022 年9 月中下旬將系統正式投入使用。在實際生產中,對不同月份的同一車間、同一產品規格以及相同進線的能源消耗進行統計,見表2。
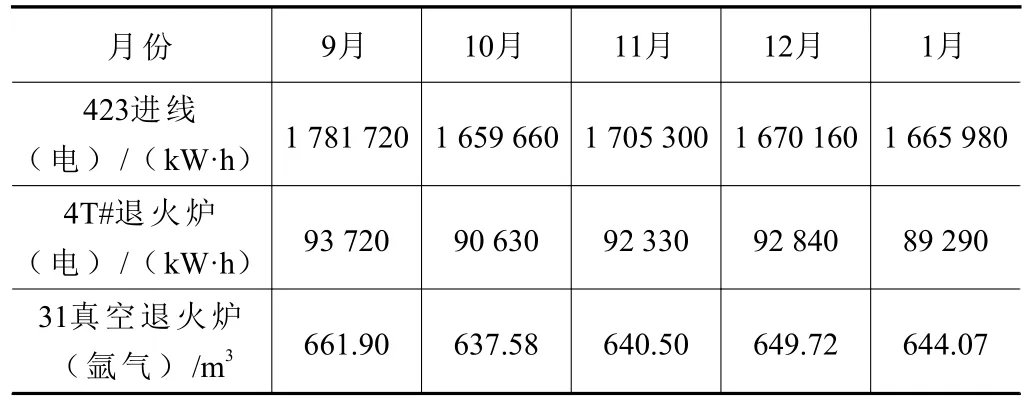
表2 精整車間能耗對照明細
綜上所述,應用本系統后,定義9 月份能耗為百分百,在該企業精整車間系統應用前、后兩個月能耗對比中,423 進線(電)的能耗下降了6.85%,4T#退火爐(電)能耗下降了3.29%,31 真空退火爐(氬氣)能耗下降了3.67%,達成了計劃之初的完成指標,為企業降本增能提供了有力支撐,如圖13 所示。
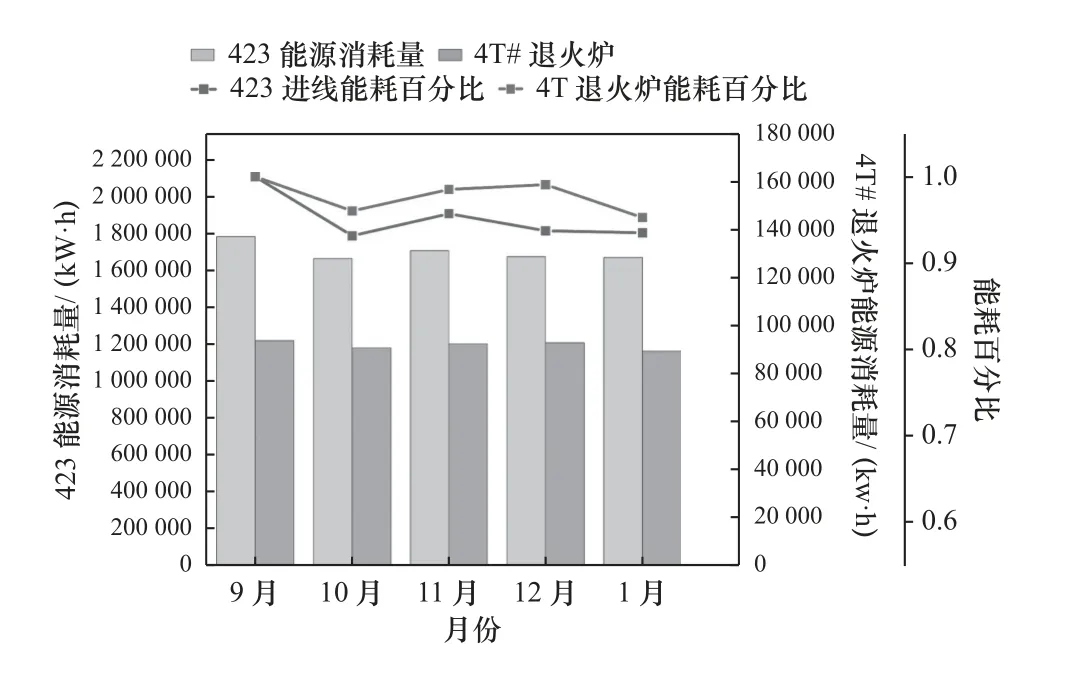
圖13 能源消耗趨勢
5 結語
本文設計了一種基于Lora 無線通信網絡的企業能耗監測與預測系統,以及一種基于APSO-LSTM算法的能耗預測模型。經過若干次系統版本的迭代,目前系統已在新疆某鋁箔企業實施應用。設計的APSO-LSTM 預測模型能夠較為準確地預測未來的能耗情況,且避免了手動調參。經實際應用證明,該系統有助于企業監測和管理能耗信息,并使管理人員以預測能耗趨勢為參考主動做出生產調整,從而指導生產,達到降低能耗、綠色生產的目的,具備一定的實際應用價值和推廣前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
