基于深度學習的PM2.5 濃度預報
2023-09-21 08:17:10呂秋明莫欣岳
科學技術創新 2023年22期
呂秋明,莫欣岳*,李 歡
(海南大學 網絡空間安全學院(密碼學院),海南 海口)
引言
空氣污染是全球性的環境問題,尤其在城市地區。隨著工業和交通運輸業的迅速發展,城市空氣污染問題愈發突出。作為空氣污染的重要成分之一,PM2.5對環境和人類健康的影響已引起廣泛重視。隨著人們對環境和生活質量需求的提高,對空氣質量的關注也越來越高。因此政府部門不斷加強對空氣質量的管控,對以PM2.5為首的空氣污染物開展預報預警,有助于采取及時有效的防控措施,保障生態環境和公眾健康[1]。
近年來,機器學習特別是深度學習技術的成功應用也為空氣污染預報提供了新的思路和方法。深度學習是一種基于人工神經網絡的模型算法,具有很強的特征提取和自適應學習能力,可以對復雜的非線性關系進行學習和模擬。針對空氣污染預報問題,已有學者嘗試基于深度學習的方法開展研究[2]。例如Tao等[3]結合卷積神經網絡(CNN)與雙向門控循環單元網絡(BiGRU)提出一種深度學習模型(CBGRU),該模型通過CNN 對數據下采樣減少數據的復雜性,并使用BiGRU挖掘時間信息特征。
不同深度學習算法具有不同特點,例如卷積神經網絡(CNN)具有較好的特征提取能力,而長短期記憶網絡(LSTM)擅長時間序列分析。本研究引入多種深度學習算法,不僅融合了CNN和雙向長短期記憶網絡(BiLSTM)的特性,而且加入先進的注意力機制(Attention),建立了深度學習組合模型CNN-BiLSTM-Attention。基于深度學習組合模型開展PM2.5濃度預報,并對模型的預報效果進行了量化分析和評價。本研究旨在通過深度學習方法實現PM2.5濃度的有效預報,為公眾的健康防護和政府的空氣污染防控提供支持,同時助力于深度學習技術應用和發展。
1 研究數據
1.1 研究區域 北京市位于中國華北地區,是中國的首都,也是政治中心、文化中心和科技創新中心。隨著城市化進程的加速,伴隨而來的環境問題也日益凸顯。北京也是空氣污染較嚴重的城市之一,PM2.5污染形勢始終不容樂觀。為了改善空氣質量,北京市政府采取了一系列管控措施,如加強空氣質量的監測和預警、推廣清潔能源、機動車限行等。
1.2 數據集與預處理 本研究使用了北京市常規空氣污染物濃度監測數據(http://zx.bjmemc.com.cn/getAqiList.shtml?timestamp=1689873072321),具 體 包 括PM2.5、PM10、SO2、NO2、CO、O3。數據時間跨度為2013 年3 月1日至2017 年2 月28 日,數據粒度為小時級別。其中,訓練集、驗證集和測試集的比例分別為80%、10%和10%。鑒于預報量PM2.5濃度序列的時間規律和與其它污染物復雜的相互作用,使用6 種常規空氣污染物歷史濃度數據作為預報因子。為消除不同污染物量級的影響,使用Min-Max歸一化算法對原始數據進行歸一化。然后通過滑動時間窗口算法將原始時間序列轉化為監督學習任務。
2 深度學習算法
2.1 卷積神經網絡 卷積神經網絡(Convolutional Neural Network,CNN)是一種廣泛應用于計算機視覺領域的深度學習模型[4]。CNN 的主要思想是通過卷積運算和池化操作提取圖像特征,然后通過全連接層進行分類或回歸等任務。CNN的卷積層通過卷積核在輸入數據上進行卷積運算,提取局部特征,并且具有平移不變性。池化層則通過對卷積層輸出的特征圖進行下采樣操作,減少特征的維度和數量,從而進一步提高計算效率和泛化能力。
2.2 長短期記憶網絡 長短期記憶網絡(Long Short Term Memory, LSTM)是一種循環神經網絡(RNN)的改進模型,主要用來解決時間序列的長期依賴問題[5]。相較于傳統的RNN,LSTM包含三個門控單元(輸入門,遺忘門,輸出門)。LSTM結構見圖1,在每個時間步,LSTM會根據當前輸入和前一時刻的狀態,通過三個門控單元進行計算,從而控制信息的流入和流出。
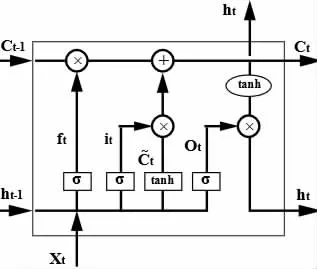
圖1 LSTM 結構
雙向長短期記憶網絡(Bidirectional Long Short Term Memory Network, BiLSTM)由兩個單向的LSTM組成,每個時刻的輸入會同時提供給前向和后向的LSTM,兩個隱含層獨立計算狀態和輸出,BiLSTM的最終輸出由兩個LSTM的輸出共同決定。
式中:W 和b 是相應的權重和偏置向量;h,x,C? 和C 分別是輸出,輸入,候選記憶和記憶單元;f,i 和o 分別是遺忘門,輸入門,輸出門單元。
2.3 注意力機制 注意力機制(Attention)是一種用于加強神經網絡對輸入序列中重要部分關注度的機制。在序列數據的處理中,往往需要對每個時間步的輸入進行加權求和,以得到一個整體的表示。Attention 機制通過根據當前狀態動態地計算權重向量,使得模型能夠更加靈活地對輸入序列進行建模,從而提高模型的性能[6]。
2.4 建立CNN-BiLSTM-Attention 模型 本研究基于上述深度學習算法建立了CNN-BiLSTM-Attention 的串聯組合模型,模型的主要架構和功能如下:(1) 輸入層,輸入的數據是一個二維張量,該層的shape 參數為(window,input_size);(2) 卷積層,使用Conv1D 函數創建一個卷積層,激活函數為ReLU;(3) 池化層,使用MaxPooling1D 函數創建一個池化層;(4) Dropout 層,使用Dropout 函數創建一個Dropout 層;(5) BiLSTM層,使用Bidirectional 和LSTM函數創建一個BiLSTM層,包含一個正向和一個反向的LSTM層,激活函數為tanh;(6) Dense 層,全連接層,該層用于將BiLSTM層的輸出傳遞給Attention 層,激活函數為sigmoid;(7)Attention 層,使用Dense 函數創建一個全連接層,激活函數為sigmoid;(8) 乘法層,使用Multiply 函數將Attention 層的輸出與BiLSTM層的輸出按元素相乘,以加權計算LSTM層的輸出;(9) Flatten 層,該層用于將數據展平,以傳遞給Dense;(10) 輸出層,使用Dense函數創建一個全連接層,該層有1 個神經元,激活函數為tanh,用來得到模型的最終輸出值。
3 模型評估
模型評估是在測試集上對模型進行性能評估的過程。對于時間序列預測任務,通常使用以下統計指標評估模型的性能[7]:平均絕對誤差(Mean Absolute Error,MAE),均方誤差(Mean Squared Error,MSE)和決定系數(R2)。
MAE 是預測值與真實值之間的平均絕對誤差,它表示模型預測值與真實值之間的平均距離。MAE 計算公式如下:
MSE 是預測值與真實值之間的平均平方誤差,它表示模型預測值與真實值之間的平均偏差的平方。MSE 計算公式如下:
R2分數是用于評估回歸模型擬合程度的指標,取值范圍在0 到1 之間,其中1 表示回歸模型完美擬合所有數據,0 表示回歸模型無法解釋目標變量的方差。R2計算公式如下:

4 實驗結果與分析
4.1 模型訓練Epoch 的選定 Epoch 指使用訓練集的全部樣本對模型訓練一次的過程。采用控制變量法逐步調整Epoch 次數,測試Epoch 取值對模型預報效果的影響。以MAE 為標準,實驗結果顯示,MAE 隨著Epoch 次數的增加先減少后增加,當Epoch 取20 時MAE 達到極小值,其它指標也顯示出了類似的規律。因此,基于模型預報效果和計算成本的考慮,本次試驗選擇20 作為模型最終的Epoch 參數。詳見表1。

表1 Epoch 次數對預報效果的影響
4.2 時間窗口的選定 較長的時間窗口可以捕捉到更長期的時間依賴關系,但也會增加模型的復雜度和計算成本;而較短的時間窗口可能會限制模型的數據挖掘能力。不同類型的數據也具有不同的規律,例如周期性,故時間窗口的大小對不同類型數據的預測效果影響也不同。通過調整時間窗口的大小,來觀察模型性能的變化,進而選定最合適的時間窗口。表2 顯示,隨著時間窗口的變大,模型的預報準確性呈現先上升后下降的規律,在窗口大小取12 時模型的MAE,MSE 和R2達到極值分別為0.015 44,0.000 78 和0.935 33。

表2 時間窗口大小對模型的影響
4.3 模型預報性能 為驗證本研究提出的深度學習組合模型CNN-BiLSTM-Attention 的預報性能,在測試集上對照PM2.5濃度的監測值,對其預報效果進行評估。圖2 顯示,組合模型可以準確地學習污染物濃度的變化規律并做出預測,預測結果不僅能反映污染物的變化趨勢,而且對極值的預報也較為準確,僅在個別極值點上預報值略低于實際值。
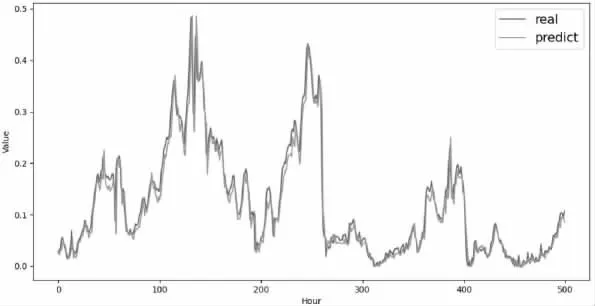
圖2 CNN-BiLSTM-Attention 預報結果
此外, 在測試集上將提出的組合模型CNN-BiLSTM-Attention 與基準模型LSTM進行了詳細的對比,以驗證模型的性能變化。表3 顯示,相比于LSTM,使用BiLSTM并結合CNN,以及引入Attention 機制建立組合模型可以有效提升模型預報性能。通過對測試集上預報結果MAE,MSE 和R2的比較,LSTM的三種統計指標分別為0.091 49,0.017 33 和0.952 74,CNNBiLSTM-Attention 的三種指標分別為0.017 93,0.001 00 和0.955 35,后者比前者各項均有提升,分別提升了80%,94%和0.3%。

表3 LSTM與CNN-BiLSTM-Attention 預報效果對比
5 結論
本研究引入多種深度學習方法,包括卷積神經網絡(CNN),雙向長短期記憶網絡(BiLSTM)和注意力機制(Attention), 建 立 了 深 度 學 習 組 合 模 型CNN-BiLSTM-Attention。針對北京市PM2.5小時濃度開展了預報,并基于三種統計指標和基準模型對實驗結果進行了分析,進而評估模型的預報性能。
實驗結果表明:對于深度學習模型Epoch、時間窗口等超參數的調節可以有效提高模型性能;提出的深度學習組合模型CNN-BiLSTM-Attention,結合了CNN 特征提取和緩解模型過擬合問題的優勢、BiLSTM準確捕捉長時間序列信息中隱含特征的優點以及Attention 機制可以根據輸入序列中不同位置重要性而賦予不同權重的能力,能夠對PM2.5的濃度變化進行準確預測;相對于基準模型LSTM,CNN-BiLSTM-Attention 在MAE、MSE和R2指標上有顯著提升,分別為80%、94%和0.3%。
在今后的工作中,將針對基于深度學習的污染預測問題,開展進一步研究。例如:不斷引入更多先進的深度學習算法,通過對比實驗驗證不同深度學習算法的效果和適用性;開展集合預報,同時建立多個不同預報模型并對預報結果進行融合,進一步提高預報結果的準確性和穩定性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
