基于EG-SSMA-DELM的數控銑床刀具RUL預測研究*
2023-09-22 07:55:00張天驍谷艷玲安文杰
機電工程 2023年9期
張天驍,谷艷玲,安文杰
(沈陽工業大學 機械工程學院,遼寧 沈陽 110870)
0 引 言
隨著工業技術的不斷發展,機械加工也逐步向高效率、高精度方向發展。對機械設備進行狀態監測,能夠在延長設備壽命、提高生產力,同時也可以避免安全事故的發生。
數控銑床刀具失效約占停機時間的20%[1],因此,刀具的狀態監測和剩余使用壽命(remaining useful life, RUL)預測得到越來越多的關注。準確地預測刀具RUL,將有效優化工作流程安排,并最大限度地利用刀具,降低生產成本,提高企業效益。
目前,RUL預測分為基于模型預測、基于數據驅動預測以及數模聯動的方法[2]。其中,基于模型的預測方法需要建立數學或物理模型;然而該方法針對每個系統構建特定的模型,易受工程經驗和主觀因素的影響;且開發這樣的模型耗時耗力,在實際工程應用中受限。隨著深度學習(deep learning, DL)“大數據”技術的發展,獲取設備運行工況的海量數據成為現實,將DL應用于實際工程領域成為目前研究的重點。
王新海等人[3]提出了一種基于集合經驗模態分解和混沌粒子群算法優化極限學習機(extreme learning machine, ELM)的車床刀具磨損故障診斷方法。LIU Xiao-fei等人[4]提出了一種新的卷積向量融合網絡,通過矢量動態加權來預測滾動軸承RUL壽命,提高了預測的精度。何彥等人[5]提出了一種長短時記憶網絡結合卷積神經網絡的刀具磨損監測模型,并采用該方法對采集的數據進行了多維度特征提取,使用線性回歸對刀具磨損值的特征進行了映射。
上述方法雖然都取得了較好的預測精度,但是基于DL的預測模型需要大量高質量的全壽命數據訓練,在實際工程中,從海量監測數據中篩選出可用數據是非常困難的。
ELM是HUANG Guang-bin等人[6]針對模型在預測精度上不足等問題提出的一種新方法。目前,ELM已應用于許多領域,如風力預測、軸承故障診斷等。該方法的優點是求解速度快、精度高、參數設置簡單。然而,ELM只具備1個隱藏層,導致模型的魯棒性較差。
因此,HENRY K E等人[7]結合DL,提出了深度極限學習機(DELM)。DELM可以自動提取特征,其不僅克服了人工方式提取特征的繁瑣性和局限性,還避免了DL對數據要求高的缺點,已被廣泛應用于各類狀態識別及壽命預測問題中。
但是DELM存在輸入層權值與偏置隨機生成問題,不能反向調節,易陷入局部最優,影響RUL預測精度。
綜上所述,筆者設計一種EG-SSMA優化DELM的刀具磨損預測模型(EG-SSMA-DELM),用于對刀具的磨損狀態及剩余使用壽命進行判斷。
首先利用精英反向學習與黃金正弦算法改進黏菌的初始種群,提高種群的多樣性;然后通過改進黏菌算法的搜索方式,優化DELM中編碼器的偏置與輸入權重,使優化后的DELM模型的全局搜索能力和預測精度皆得到提升,最后采用實測數據對模型性能進行驗證。
1 理論介紹
1.1 DELM模型
深度極限學習機(DELM)泛化性好。相較于其他深度方法,DELM訓練速度更快,在提取非線性數據特征時效果顯著,因此,DELM目前被廣泛應用于解決各種領域的分類與回歸問題[8]。
DELM模型中包括三層,即輸入層、多個隱藏層和一個輸出層[9]。DELM的結構模型如圖1所示。
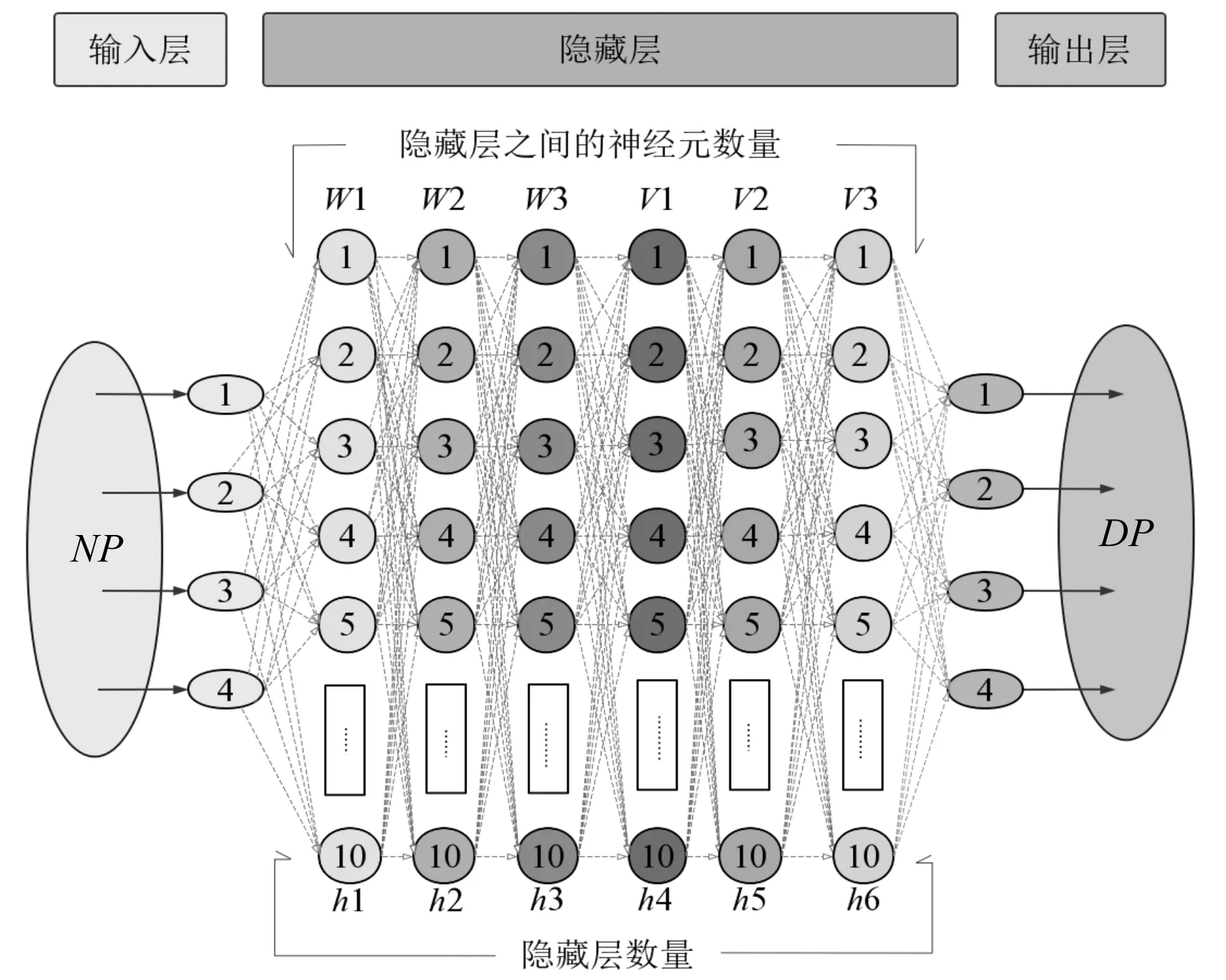
圖1 DELM的結構模型
當第K個隱藏層中的節點數等于K-1個隱藏層,可以得出激活函數g(x)保持線性的結論;否則g(x)應該是分段非線性的。
因此,第K個隱藏層的輸出表示如下:
HK=g((βK)THK-1)
(1)
式中:βK為輸出權重向量;HK為DELM輸出隱藏層的輸出矩陣(當K-1=0時,該層表示輸入層,HK為DELM的輸入)。
然而,DELM算法同樣存在缺點,即在訓練過程中,輸入層權重與偏置是隨機產生的正交隨機矩陣,同時只有輸出層權重參數會更新,而輸入層權重與偏置不進行更新,這就導致了DELM的最終效果受到影響。
因此,筆者采用改進的黏菌搜索算法來對其進行優化。
1.2 黏菌優化算法模型
黏菌算法(SMA)是一種根據黏菌營養生長過程提出的全新元啟發式群智能仿生算法,由LI Shi-min等人[10]于2020年提出,其具有收斂速度快、尋優能力強的特點。
黏菌的覓食行為及覓食時的可能位置如圖2所示。
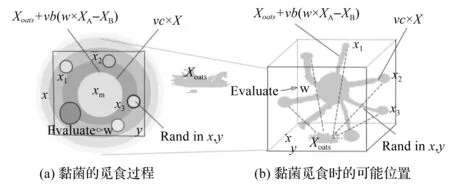
圖2 黏菌的覓食行為及覓食時的可能位置
SMA捕食的三個階段為:接近食物[11]、包圍食物和抓取食物。SMA轉化為數學模型表示如下:
1)接近食物
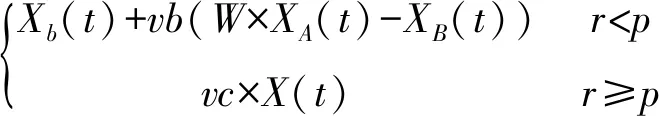
(2)
式中:X(t+1)和X(t)為第t+1次、第t次迭代時的黏菌位置;Xb(t)為瞬時最優個體位置;vb為[-a,a]范圍內的參數;W為黏菌重量;XA(t)和XB(t)為隨機的兩個黏菌位置;t為當前迭代;vc取值[0,1]。
p的表達公式如下:
p=tanh(|S(i)-DF|)
(3)
式中:S(i)為第i個黏菌個體的適應度值,i取值為1,2,…,N;DF為最佳適應度值。
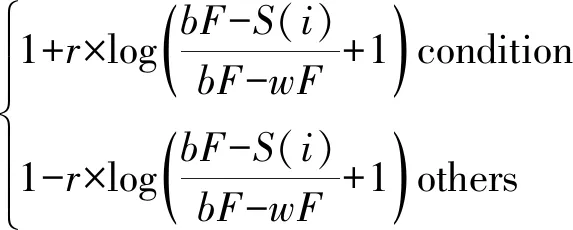
(4)
SortIndex=sort(S)
(5)
式中:SortIndex為排序后的適應度值序列;r為隨機數,取值[0,1]區間內;群體前半部分個體適應度值用condition表示;bF和wF分別為當前迭代中最佳和最差適應度值;
2)包圍食物
(6)
式中:rand與r為[0,1]中的隨機值;z為固定參數,用于開發與搜索階段,其值設為0.05。
其中:搜索空間在[lb,ub]內;
3)抓取食物
μb的值在[-a,a]范圍內隨機波動,隨著迭代次數的增加,它逐漸趨于0;μc的值在[-1,1]之間波動,最后,它也接近于0。
2 改進的黏菌優化算法
2.1 精英反向學習策略
反向學習方法(opposition-based learning, OBL)是TIZHOOSH H R[12]在2015年提出的,其優點為增加了算法的種群多樣性,擴大了最優解的選取范圍,從當前解與反向解中共同選取最優解,最后用于個體位置的更新。
精英反向學習方法(EOBL)由此得出。
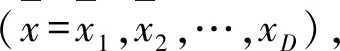
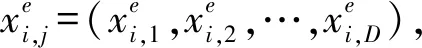
(7)
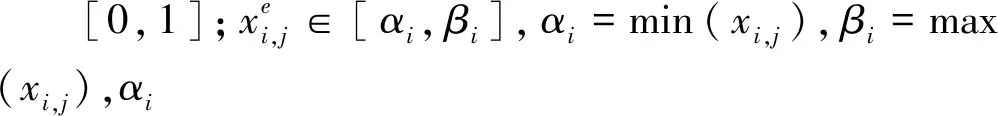
因固定邊界難以保存搜索經驗,而精英反向解則可以在狹小的空間中搜索定位,從而使算法收斂速度更快。
2.2 黃金正弦算法
黃金正弦算法(GSA)是TANYILDIZI E[14]于2017年提出的,其由數學中的正弦函數推演而來。因GSA通過不斷縮小搜索空間來找尋全局最優解,具有收斂速度快、計算復雜度低、易于實現與調節等優點。
黃金正弦算法原理圖如圖3所示。
GSA算法的核心是通過隨機產生的S個個體位置[15]搜索空間中,每個解對應個體的位置為Xti=(Xi,1,Xi,2,…,Xi,D),其中D維個體空間中第t次迭代中第i(i=1,2,3,…,n)個個體的空間位置用Xti表示,PtiPti=(Pi1,Pi2,…,PiD)表示第t代個體i的最優位置,t+1次迭代時的位置更新公式如下:
(8)
式中:R1和R2分別為[0,2π]與[0,π]的隨機數;R1為下一次的更新迭代方向;R2為個體的更新迭代位置與移動距離。
為使個體收斂到最優解,引入黃金分割系數x1和x2,其表達式如下:
x1=a×(1-τ)+b×τ
(9)
x2=a×τ+b×(1-τ)
(10)
(11)
式中:a,b的初始值為-π和π;τ為黃金分割數。
綜上所述,EG-SSMA算法的流程如圖4所示。
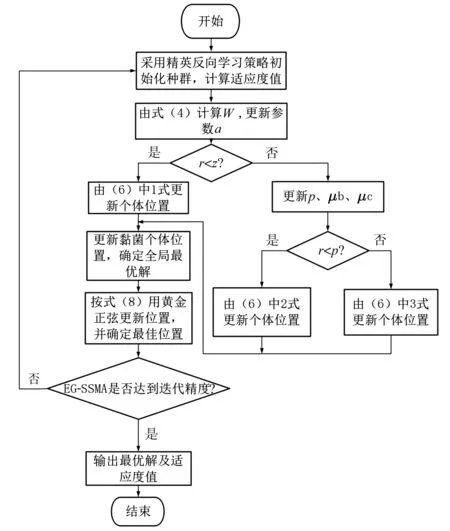
圖4 EG-SSMA算法的流程圖
2.3 基于EG-SSMA-DELM刀具RUL研究
針對刀具失效造成工件報廢和關鍵部件損壞等問題[16],筆者采用DELM進行回歸預測研究。但其初始參數隨機性較大,嚴重影響了最終的預測結果。
因此,筆者對黏菌個體的位置更新公式進行改進,引入精英反向學習與黃金正弦算法,然后采用改進后的黏菌算法對初始值進行尋優,進而提出基于EG-SSMA-DELM的刀具磨損預測模型。
EG-SSMA算法優化DELM的問題可以轉化為對適應度函數求極值的問題,使用EG-SSMA優化DELM的基本思想是,求出適應度值最好的一組黏菌位置,在跳出迭代時,把該位置作為DELM最優初始權值和閾值,從而建立刀具磨損的預測模型。
EG-SSMA-DELM模型流程圖如圖5所示。
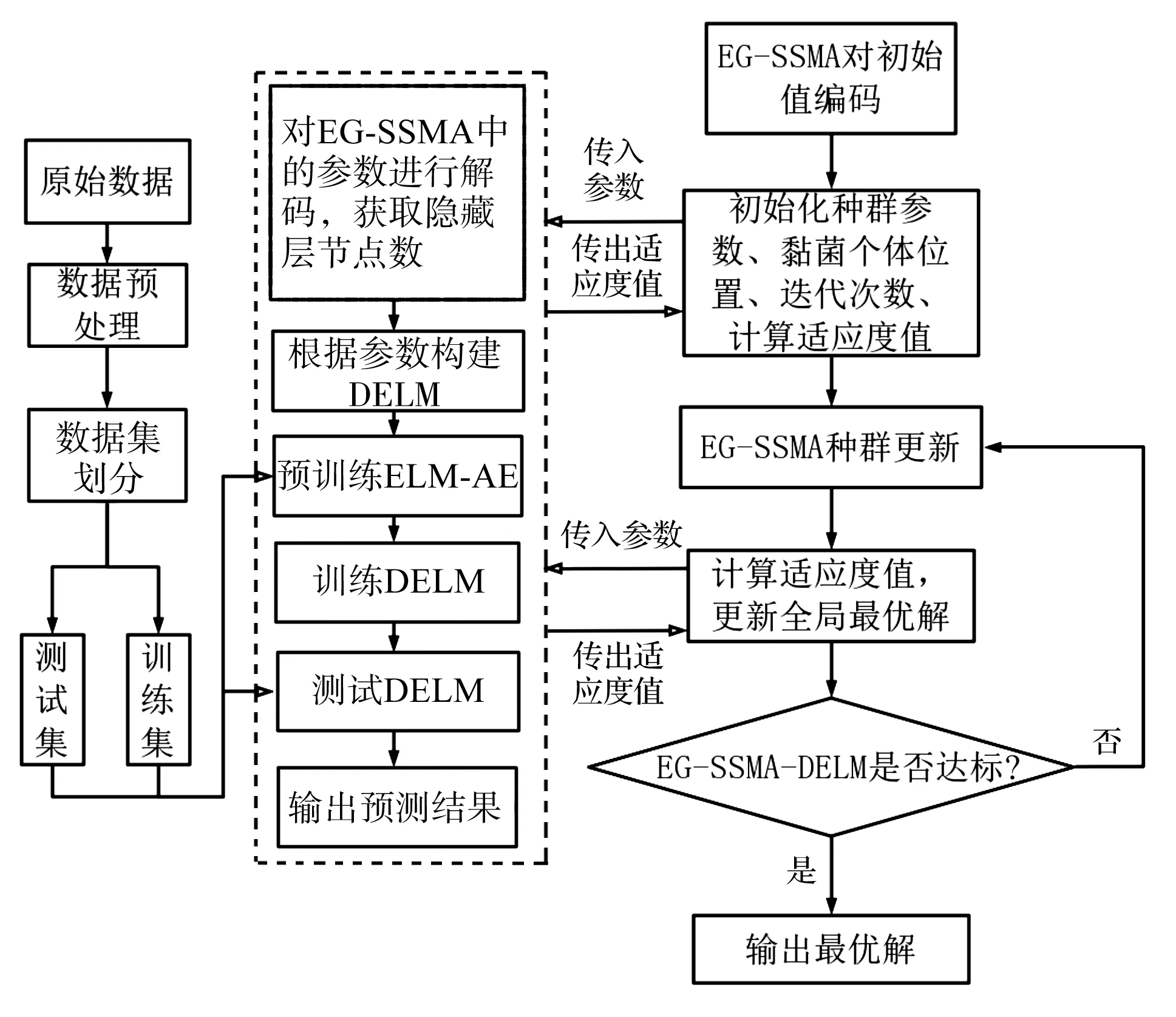
圖5 EG-SSMA-DELM模型流程圖
同時,筆者采用適應度函數來計算深度極限學習機的期望輸出與實際輸出之間的最小誤差,即找到一組網絡超參數,使EG-SSMA-DELM在所使用的數據集上誤差最小。其數學表達式為:
(12)
式中:RULpi和RULpi分別為實際輸出結果和預測輸出結果;N為樣本數量。
3 試驗驗證及方法對比
筆者將EG-SSMA-DELM刀具磨損預測模型應用于實測數據集中,以驗證該方法在刀具磨損壽命預測中的有效性;并將其與其他方法進行比較,以驗證其性能的優劣。
3.1 刀具磨損數據集介紹
為了測試EG-SSMA-DELM模型的性能,筆者采用實測刀具磨損全壽命數據進行驗證試驗。此處筆者采用的是VDM850E型立式加工中心數據,其參數如表1所示。
筆者使用安德時VA5Pro數據采集器,采集每一次銑削過程中的振動信號,采樣頻率為12 800 Hz,每分鐘采集一次數據,每次保存1.28 s,即每次采樣振動數據為16 384個樣本點。
實驗工況數據同表1。筆者采集了4把刀具的銑削操作(C1、C2、C3、C4),刀具磨損試驗及傳感器安裝位置如圖6所示。

圖6 刀具磨損試驗及傳感器安裝位置
筆者將C1、C2、C3作為模型的訓練集,C4作為測試集以驗證EG-SSMA-DELM模型的性能。C1前期運行比較平穩,幅值相對穩定;但是在運行后期急速退化,幅值在較短時間內劇烈增大。
C1刀具的磨損過程時域波形圖如圖7所示。
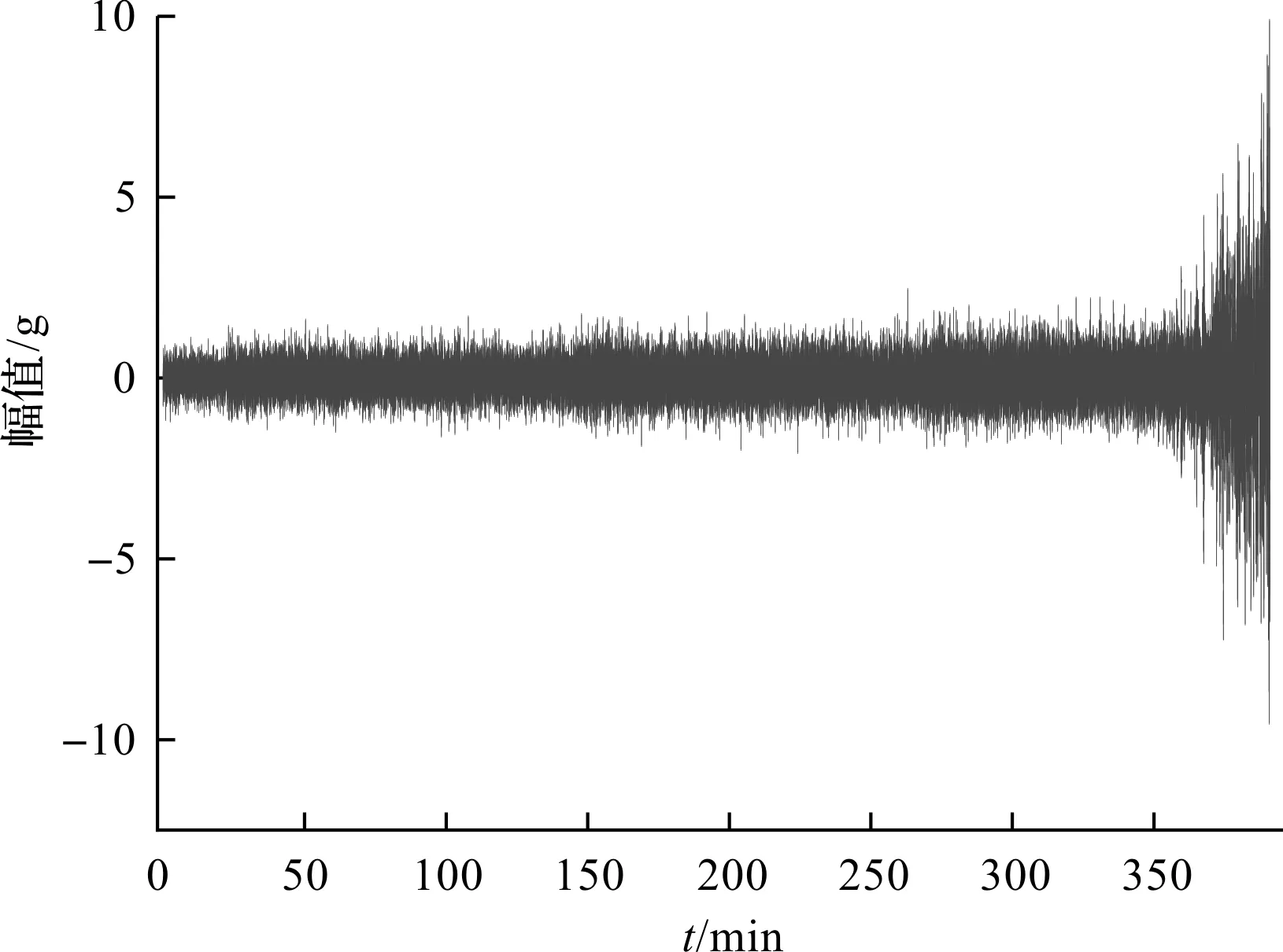
圖7 C1刀具的磨損過程時域波形圖
C4刀具振動信號的振幅隨時間緩慢增長,C4刀具的磨損過程時域波形圖如圖8所示。
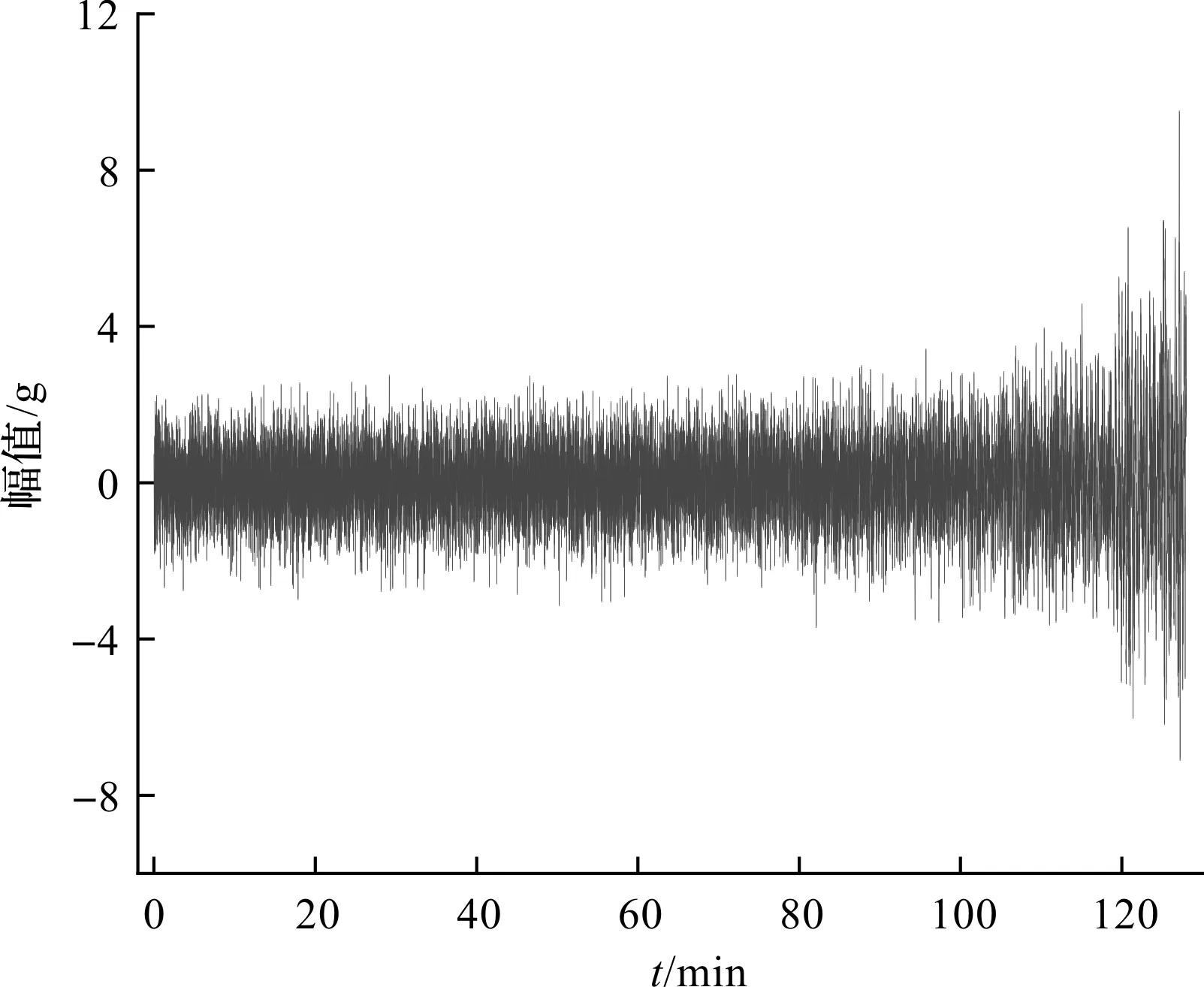
圖8 C4刀具的磨損過程時域波形圖
4組刀具磨損過程的均方根(root mean square, RMS)曲線如圖9所示。
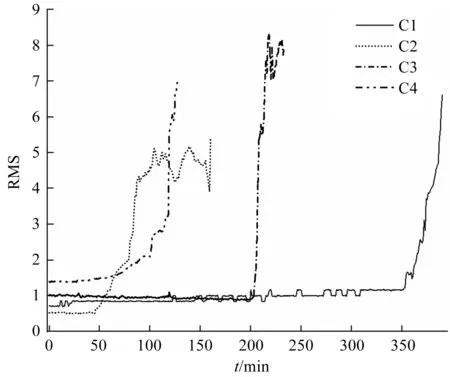
圖9 4組刀具的磨損過程RMS
雖然刀具是在相同的工況下運行,但是其退化狀態并不相同。因此,刀具的退化模式并不唯一,很可能出現退化漸變式和突然退化兩種模式。不同的退化模式無疑為刀具的壽命預測增加了很大難度,因此,預測模型的魯棒性強弱至關重要。
刀具的4種磨損狀態如圖10所示。

圖10 刀具磨損狀態
3.2 試驗結果分析
為了驗證基于EG-SSMA-DELM的預測模型具有更好的預測精度、更強的魯棒性和泛化性能,筆者在提出的EG-SSMA-DELM模型中采用隱含層結構,激活函數選擇ReLU函數。
訓練過程中,DELM每個自編碼結構包含一個隱藏層,以重構損失作為損失函數,依次訓練完成后進行堆疊,以此提取刀具振動信號退化的深層特征;EG-SSMA-DELM以原始1D信號作為模型輸入,以健康指標RMS作為模型輸出,設置失效閾值RMS=5 g,并根據RMS的值推斷刀具的剩余使用壽命[17]。
為了驗證EG-SSMA-DELM模型的預測效果,筆者采用均方根誤差(RMSE)來對其進行測試。
為驗證EG-SSMA-DELM模型的通用性,同時采用平均絕對誤差(mean absolute error,MAE)、平均絕對百分比誤差(mean absolute percentage error,MAPE)與確定系數(r-square,R2)共同作為評估標準:
(13)
(14)
(15)
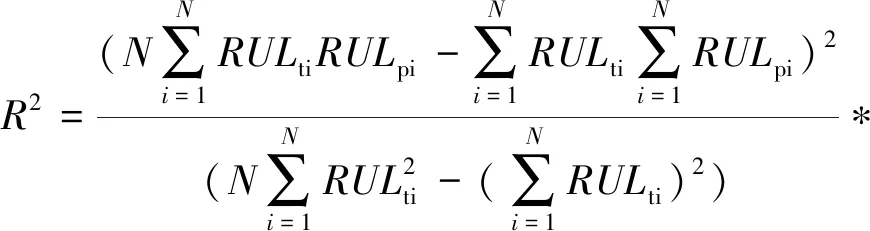
(16)
式中:N為樣本的數量;RULpi和RULti分別為模型的實際值和預測結果;RULmean為輸入變量的平均值。
其中:R2越接近1,模型性能越好。
筆者使用三倍交叉驗證法對訓練集的三組刀具全壽命數據進行交叉訓練,即從訓練集中選取兩組全壽命數據用于模型的訓練,剩余一組作為驗證集對模型進行驗證,如此反復三次試驗。
以該方法訓練好的EG-SSMA-DELM預測模型在C4刀具上的預測結果如圖11所示。
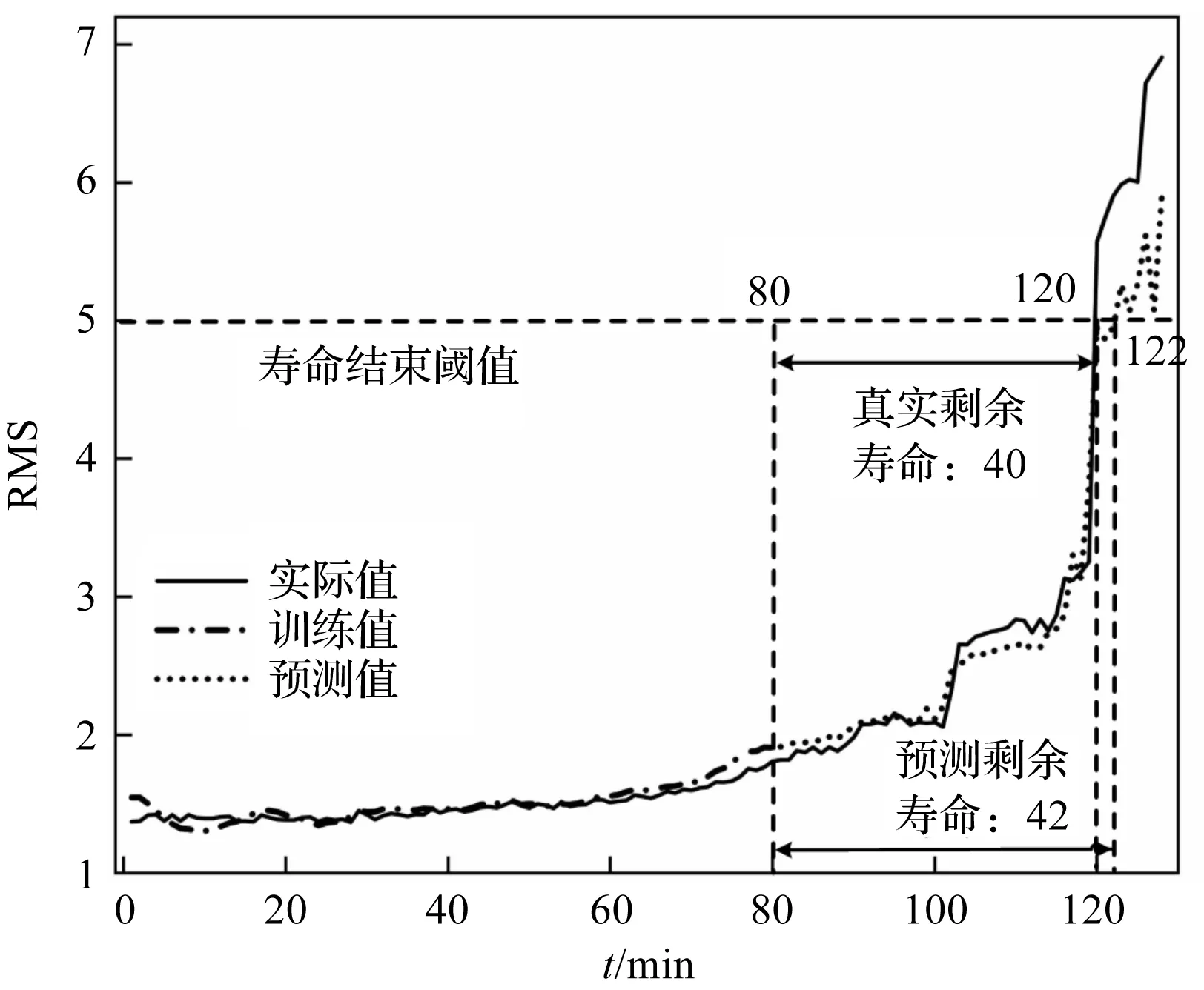
圖11 基于EG-SSMA-DELM預測模型結果
3.3 方法對比分析
為了進一步驗證EG-SSMA-DELM模型的性能,筆者引入了反向傳播神經網絡(back propagation neural network,BPNN)模型、ELM模型、DELM模型、SMA-DELM模型、麻雀搜索算法(sparrow search algorithm,SSA)-DELM模型進行對比實驗[18]。
其中,BPNN的隱藏層節點設置為5,具有1個隱藏層;ELM、DELM、SMA-DELM、SSA-DELM的隱藏層結點也都設置為5,各具有10個隱藏層結構。
不同模型的性能預測結果如表2所示。
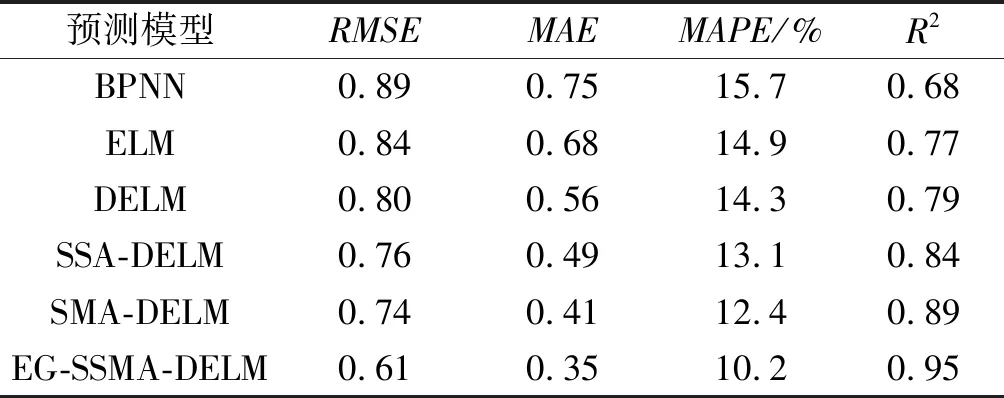
表2 不同模型的預測性能
不同模型的預測性能對比柱狀圖如圖12所示。
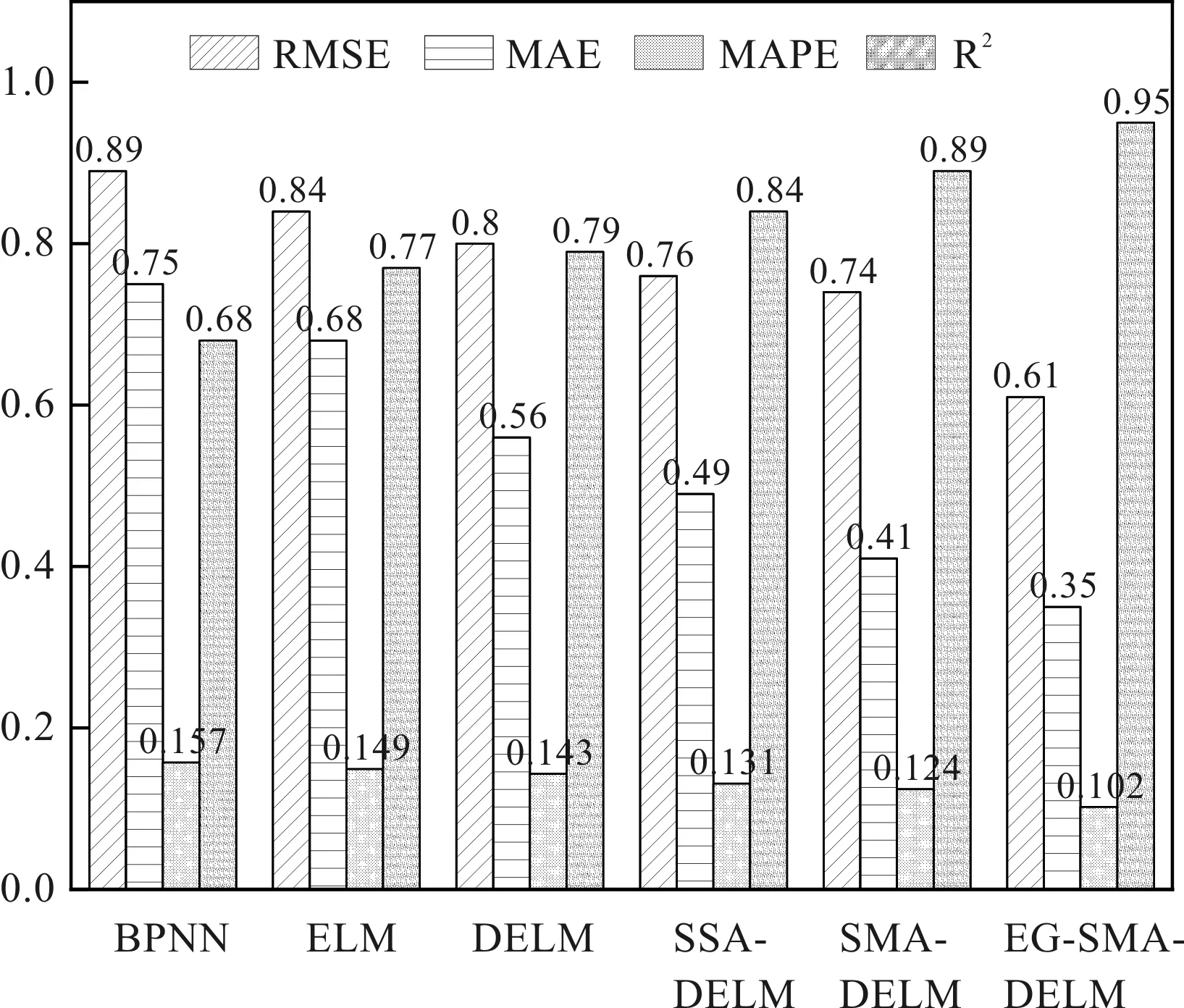
圖12 不同模型的預測性能對比柱狀圖
由12可知:從RMSE、MAE、MAPE和R2得出的統計結果顯示,與ELM和BPNN等傳統模型相比,DELM表現出更好的預測性能,RMSE=0.80,MAE=0.56,MAPE=14.3%,R2=0.79。
同時,因SSA與SMA優化算法的引入,其預測性能又高于傳統的DELM。筆者對SMA進行了改進,將改進后的SMA用于優化DELM,由于EOBL與GSA的加入,EG-SSMA-DELM模型的預測精度達到了最佳,相比于經典的DELM方法,其RMSE平均下降了19.60%,預測精度提高了16.00%。
綜上所述,EG-SSMA-DELM預測模型在所使用的對比模型中獲得了較高的預測精度性能,這為刀具RUL預測提供了良好的參考,具有極高的實用價值。
4 結束語
針對刀具的磨損狀態及RUL預測研究問題,筆者以振動信號為切入點,提出了一種基于EG-SSMA-DELM的刀具磨損預測模型方法,實現了對刀具磨損的RUL預測目的。
研究結論如下:
1)基于初始的SMA算法,采用EOBL與GSA算法對其進行改進,增加了SMA的種群多樣性,擴大了最優解的選取范圍,從而使該算法收斂速度更快,尋優能力更強;
2)針對DELM算法模型參數設置的隨機性,將EG-SSMA算法應用于DELM參數的優化,并轉化為對適應度函數求極值的問題。使用EG-SSMA優化DELM的基本思想是求出適應度值最好的1組黏菌位置,在跳出迭代時把該位置作為DELM的最優初始的權值和閾值,從而建立刀具磨損預測模型;通過對預測值與真實值作對比,證明了該預測模型的卓越性;
3)為探究預測模型的精度,采用BPNN、ELM、DELM、SMA-DELM、SSA-DELM作為對比模型,實驗結果表明,相比于經典的DELM方法,EG-SSMA-DELM方法的均方根誤差平均下降了19.60%,預測精度提高了16.00%;EG-SSMA-DELM預測模型的4種性能指標(RMSE、MAE、MAPE、R2)均優于其他預測模型,該方法在各項指標上效果顯著。顯然,EG-SSMA-DELM模型可以獲得更好的預測性能,對刀具磨損預測技術具有一定的應用價值。
在后續的研究中,筆者將繼續采用該模型對更多種類的刀具進行RUL預測研究,以得到更為有效的刀具預測模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
