上市公司財務風險預警
——基于機器學習方法
2023-09-26 01:02:46張彩妮任愛珍林子達
中小企業管理與科技 2023年16期
張彩妮,任愛珍,林子達
(內蒙古農業大學,呼和浩特 010018)
1 引言
目前,我國整體經濟受到國際經濟形勢影響,面臨下行壓力,眾多公司融資困難,陷入財務困境。在此背景下,構建有效的財務危機預警模型以識別潛在財務風險,對于企業自身規避風險、投資者制定投資計劃和經濟社會健康發展具有重大意義。
當前,學者基于機器學習中的各種分類算法來構建預警模型:陳志君[1]以我國通信行業上市公司為研究對象,通過篩選財務指標,采用邏輯回歸建立財務危機預警模型,該模型的正確率達到79%。李長山[2]的研究表明,由邏輯回歸構建的預警模型能夠有效識別我國制造業公司的財務風險。連曉麗[3]以A 股上市的正常公司和ST 公司為研究樣本,發現基于隨機森林的財務危機預警模型在不同的市場行情下均有較高的準確率。孟杰[4]通過對比隨機森林與支持向量機、邏輯回歸、分類決策樹和神經網絡在我國上市公司財務失敗預警時的表現,得出隨機森林模型預測精度更高、更穩健的結論。游甜[5]選取財務指標和非財務指標,對比分析優化后的支持向量機、BP_Adaboost 和kNN 在企業財務危機預測時的表現,發現支持向量機模型具有更高的判別正確率。周廷煒[6]利用優劣解距離法和網格尋優算法優化支持向量機預測模型,提高了該模型識別上市公司退市風險的能力。薛慧[7]構建了基于LightGBM 的財務風險預警模型,并與隨機森林等常用模型進行對比分析,結果表明,參數優化后的LightGBM 模型對電力行業上市公司財務風險預測的效果更好。
在現有的研究中,加權K 近鄰法被應用于機械故障診斷[8,9]、樓宇室內定位[10,11]和圖像識別[12,13]等工業領域,取得了有效的成果。而目前加權K 近鄰法并未涉及對企業財務危機進行預警分析,因此,文章基于大數據分析方法,利用加權K 近鄰算法來構建上市公司財務預警模型,并與隨機森林和支持向量機進行對比研究,分析不同模型的性能,幫助企業及時辨識財務風險,實現企業健康發展的良性循環。
2 指標選取與數據處理
有效的危機預測機制應發揮早期預警作用,提前對危機事件發出警示。相較于公司破產和企業違約等事件,公司被列入風險警示板的時點往往更早,更適用于刻畫企業的財務危機。因此,文章以2022 年為基期,對陷入財務困境的公司定義為基期被列入風險警示板的公司,利用2019-2021 年的財務和非財務數據來預測基期公司是否陷入財務困境。在剔除披露信息不完全的公司后,文章獲取540 個有效的危機樣本,并對個別缺失的數據利用平均值進行補充。由于陷入財務困境的公司數量遠遠小于正常公司的數量,考慮到樣本的平衡性,文章隨機抽取了資產規模相似、數量相同的非ST 公司與ST 公司一一匹配。相關數據均來源于CSMAR 數據庫。
根據國內外已有的關于上市公司財務危機預警的相關研究成果,結合定性分析和定量分析,文章篩選出使用頻率較高且能夠較好地解釋企業財務風險的指標,從企業的償債能力、盈利能力、營運能力、發展能力以及治理能力這5 方面選取了19 個財務指標和非財務指標作為模型的輸入變量。表1 列示了財務指標和非財務指標的類型和定義。文章采用Z-Score 法對原始數據進行標準化處理,經過該種方法處理后的樣本數據的取值范圍為[0,1]。

表1 財務指標和非財務指標
3 模型設定
3.1 加權K 近鄰
K 近鄰是一種經典的監督學習算法。其基本思路為:在特征空間中,如果有K 個樣本與待測類別的樣本最相似(距離最近),且這K 個樣本大多數屬于某一個類別,那么待測樣本也屬于這個類別。在K近鄰算法中,所選擇的鄰居都是已經正確分類的對象。該算法需確定的參數為K,即選擇多少個與待測樣本距離最近的樣本進行預測。
采用K 近鄰算法預測時,默認K 個近鄰(K 個觀測)對待測樣本的影響力度是相同的。而事實上,距待測樣本近的觀測樣本對預測結果的貢獻應當大于距離較遠的觀測樣本。為解決這個問題,Hechenbichler 和Schliep[14]提出了加權K 近鄰法,其核心思想為:將相似性定義為各觀測樣本與需要預測的新觀測樣本距離的某種非線性函數,且距離越近,相似性越強,權重越高,預測時的貢獻越大。
3.2 隨機森林
隨機森林算法依賴袋裝算法,即從原始數據集中進行有放回抽樣來產生新樣本集。每個新產生的樣本集都可生長出一棵決策樹。假設總共有M 個輸入變量,每棵樹在生長時,會從全體輸入變量中隨機選取m 個(m<M)輸入變量,根據不純度最小的準則選取最優變量進行決策樹節點的分割,使每棵樹都充分生成。將所有決策樹匯總到一起形成隨機森林,隨機森林的預測分類結果是由每棵樹的預測分類結果進行少數服從多數的投票確定。
3.3 支持向量機
支持向量機是以統計學習理論為基礎的一種監督學習方法。該方法在處理二分類問題時,是通過在高維特征空間找到一個超平面來將兩類樣本有效分開。根據樣本是否線性可分,支持向量機的分類問題分為兩種情況:對于線性可分的樣本,可通過求解凸二次型規劃問題來直接確定分類超平面,進而對不同類別的樣本進行分類;對于非線性可分的樣本,需要先將原低維空間中的樣本映射到高維空間中,這一映射過程可通過選取適當的核函數來實現,然后在高維空間中尋找分類超平面,實現對觀測樣本的分類。
3.4 模型性能評估
為清晰有效地對比不同分類模型的泛化能力,文章基于混淆矩陣,選用ROC 曲線和AUC 值來評估模型的整體分類能力。ROC 曲線是二維平面空間中的一條曲線,AUC 則為曲線下方面積,是具體的數值。ROC 曲線的橫軸為假正例率即FPR(“正例”指ST 樣本),縱軸為真正例率即TPR,二者分別表示為:
式中,TP為分類模型正確預測了ST 樣本的個數;FP 為將非ST 樣本預測為ST 樣本的個數;TN 為正確預測了非ST樣本的個數;FN 為將ST 樣本預測為非ST 樣本的個數。在二分類問題中,ROC 曲線越偏離45°對角線,即AUC 值越接近1,表示模型的分類性能越好。
此外,文章選用在分類任務中常用的指標來評估模型性能,這些評價指標分別為準確率、F1得分、召回率和精確度,其計算公式如下:
4 實證結果與分析
文章針對上市公司的財務預警問題,從財務指標和非財務指標中充分挖掘相關特征,分別利用加權K 近鄰算法、隨機森林算法和支持向量機算法來構建預測模型,并利用R 軟件進行實證分析。文章共選取135 家ST 公司,將2019-2021年的810 個觀測值作為模型的訓練樣本,再將2022 年的270個觀測值作為模型的測試集,用于驗證不同模型的預測性能。
表2 為加權K 近鄰模型在測試集上的混淆矩陣。從表2可以看出,加權K 近鄰模型識別測試集中樣本的整體正確率為87.04%,可分別將82.96%的ST 公司和91.11%的非ST 公司正確識別。因此,若提前3 年對被預測為ST 的企業預警,這些企業通過采取調整企業經營戰略、優化企業債務結構和規劃合理的現金流量等應對措施,那么其中將有82.96%的企業可以避免被證監會列入風險警示板。

表2 加權K 近鄰模型混淆矩陣
表3 和表4 分別為隨機森林和支持向量機模型在測試集上的混淆矩陣。從表3 可以看出,隨機森林預警模型在測試集上的正確率為86.67%,識別ST 公司和非ST 公司的命中率分別為87.41%和85.93%。支持向量機預警模型在測試集上的正確率可由表4 得出,為86.30%。其識別ST 公司的命中率為89.63%,識別非ST 公司的命中率為82.96%。根據實驗結果,若利用隨機森林和支持向量機預測模型提前3 年對被預測為ST 的企業預警,及時采取正確應對措施的企業中將分別有87.41%和89.63%可避免被證監會列入風險警示板。

表3 隨機森林模型混淆矩陣

表4 支持向量機模型混淆矩陣
圖1~圖3 展示了加權K 近鄰模型、隨機森林模型和支持向量機模型的ROC 曲線,從圖中可以看到,3 種模型的ROC 曲線均較對角線有著明顯的偏離,說明這3 個模型均有較好的性能;隨機森林模型的ROC 曲線較對角線的偏離程度最大,AUC 值為0.942 2,這表明隨機森林模型具有更好的整體分類效力,對ST 公司和非ST 公司的識別均較為準確。

圖3 基于支持向量機模型的ROC 曲線
此外,表5 列示了評估預測模型性能的各項指標值。可以看到,3 種模型均具有較高的準確率,均在86%以上,其中加權K 近鄰模型準確率最高。不同模型的精確度和召回率有較大差異,支持向量機模型的召回率最高,為89.63%,而精確度最低,為84.03%,這說明該模型更側重于將測試集中所有的ST 公司識別出來,甚至犧牲了一些對非ST 公司判別的準確率。加權K 近鄰模型的召回率最低,為82.96%,但其精確度高達90.32%,這表明該模型注重在每次識別時能夠更準確地識別ST 公司,即在判定該公司是否會被ST 處理時趨于保守。就F1得分和AUC 值而言,隨機森林模型的表現更為出色,這說明該模型兼顧了ST 和非ST公司識別的準確率。
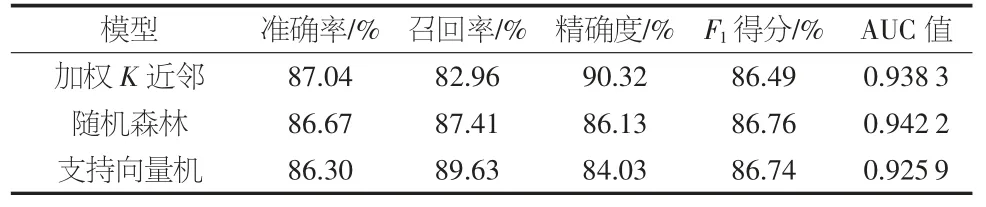
表5 各模型預測性能評價指標
5 結論
在復雜多變的宏觀經濟背景下,企業不可避免地面臨著財務風險。財務預警模型通過對企業當前和歷史的財務信息進行挖掘分析,能夠有效預測企業未來經營狀況,是財務危機管理的事前預防手段,在理論研究和實際應用中具有重要意義。文章選取2019-2022 年我國A 股上市公司的數據共計1 080 個樣本作為實證研究對象,運用加權K 近鄰、隨機森林和支持向量機算法構建了預測模型,選取資產負債率、投入資本回報率、總資產周轉率等財務指標和管理層持股比例、股權集中度等非財務指標作為模型輸入變量,對上市公司進行財務預警研究。通過對實證結果的分析,發現3 種模型均能有效地識別企業財務風險,且各有所長。
文章在3 個方面仍待完善:首先,對于模型輸入變量的選取以前人的研究結果與經驗為基礎,可能存在遺漏對企業財務危機有影響的變量的情況;其次,僅選擇加權K 近鄰、隨機森林和支持向量機3 種方法來構建預警模型,在未來的研究中應選擇更多、更前沿的算法來進行對比分析;最后,文章的數據均源自現有的數據庫,可能存在企業財務信息未充分披露、數據失真等情況。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代企業(2021年2期)2021-07-20 07:57:18
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代經濟信息(2020年34期)2020-06-08 06:02:40
數學物理學報(2020年2期)2020-06-02 11:29:24
意林·全彩Color(2019年9期)2019-10-17 02:25:48
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
