用于語音檢索的三聯體深度哈希方法
2023-09-27 06:31:52張秋余溫永旺
計算機應用 2023年9期
張秋余,溫永旺
(蘭州理工大學 計算機與通信學院,蘭州 730050)
0 引言
隨著互聯網多媒體數據檢索等實際應用的爆炸式增長,迫切需要海量大數據的快速檢索方法[1]。在現有的深度神經網絡技術中,哈希方法因快速的查詢速度和較低的內存成本,已成為最流行和有效的技術之一[2]。
目前,深度哈希方法被廣泛應用于圖像檢索[3-4]、語音檢索[5-6]、語音識別[7-8]等領域。圖像領域采用三聯體標簽(錨圖像、正圖像、負圖像)[4]的深度哈希方法能生成兼具語義信息和類別信息的哈希碼,三聯體標簽提供了數據之間相對相似的概念,確保在學習的哈希碼空間中,最大化錨圖像和負圖像之間的距離,同時最小化錨圖像和正圖像之間的距離,使生成的哈希碼具有最大鑒別力。因此,要想更準確、快速地從海量語音數據中檢索到所需的語音數據,如何生成更高效緊湊的哈希碼是亟須解決的問題。
傳統語音檢索采用的語音特征有梅爾頻率倒譜系數(Mel Frequency Cepstral Coefficient,MFCC)[9]、功率歸一化倒譜系數(Power-Normalized Cepstral Coefficient,PNCC)[10]、線性預測倒譜系數(Linear Predictive Cepstral Coefficient,LPCC)[11]等。與一維特征參數不同,語譜圖[12]以二維模式攜帶時域頻域信息,是語音特征很好的表現形式。將語音轉換成語譜圖圖像的形式,從語譜圖圖像的角度研究基于深度學習的語音檢索方法,可將圖像領域中的三聯體深度哈希方法的優勢在語音檢索領域發揮出來,對于海量語音數據檢索具有重要的研究意義和應用價值。
綜上所述,為提高語音檢索效率和精度,確保生成的二值哈希碼更加高效緊湊,且具有最大鑒別力,本文引入注意力機制-殘差網絡(Attentional mechanism-Residual Network,ARN)模型,給出了一種用于語音檢索的三聯體深度哈希方法。本文的主要工作如下:
1)提出空間注意力力機制和三聯體交叉熵損失對深度網絡進行端到端訓練,同時利用三聯體標簽進行語音特征和深度哈希碼的學習,使模型在提取高級語義特征時充分利用數據集內的相似關系,學習具有最大鑒別力的深度哈希碼。
2)為了利用數據之間的相對相似性關系,采用二次特征提取方法,提取語音數據的低級語譜圖圖像特征,并從同一類中隨機選取相同語義的兩幅語譜圖圖像特征作為錨語譜圖圖像特征和一幅正語譜圖圖像特征,從不同類中隨機選取一幅負語譜圖圖像特征生成一組三聯體作為網絡的輸入。
3)為了充分提取高級語義特征,利用ARN 模型,自主聚集整個語譜圖能量顯著區域信息,提高顯著區域表示。引入一種新的三聯體交叉熵損失函數,通過同時懲罰語義相似性和分類損失來保留深度哈希碼中的分類信息。
1 相關工作
近年來,監督信息以三聯體標簽標記數據的深度哈希方法已廣泛應用于圖像檢索、人臉識別等領域。Cao 等[3]通過構建具有度量學習目標函數的三重網絡來充分提取圖像的代表性特征并構建哈希碼,可有效地檢索同一類圖像;Li等[4]提出了結合三態似然損失和線性分類損失的三重深度哈希方法,可使生成的哈希碼具有更高的查詢精度;Li 等[13]提出利用三重排序信息和鉸鏈損失函數來度量框架下的相似度信息和分類信息;Long 等[14]提出了一種結合注意力模型的深度哈希檢索算法,可充分提取有用信息,減少無用信息,并引入一種新的三聯體交叉熵損失提高模型的表達能力,生成高質量的哈希碼。Liao 等[15]提出基于三重深度相似度學習的人臉識別卷積神經網絡(Convolutional Neural Network,CNN),使學習到的哈希碼同一類之間的距離盡可能小,而不同類之間的距離盡可能增大。
現有基于內容的語音檢索方法有基于感知哈希、基于生物哈希、基于深度哈希等方法。如Zhao 等[16]提出一種利用語音信號的分形特征和分段聚合逼近技術生成感知哈希序列的檢索算法;He 等[17]提出一種基于音節感知哈希的語音檢索方法;Huang 等[18]提出一種基于譜圖的多格式語音生物哈希算法;Zhang 等[6]提出一種基于CNN 和深度哈希的語音檢索方法。現有基于內容的語音檢索算法采用的深度哈希方法存在一定的局限性,都是通過單標簽標記數據來學習哈希碼,并只考慮一種監督損失,導致監督信息利用不足,不能生成緊湊和區別化的哈希碼,影響語音檢索的效率及精度。
隨著深度學習技術的發展,用語譜圖圖像特征來表示語音信號的方法被廣泛應用于語音識別。語譜圖生成原理采用快速傅里葉變換(Fast Fourier Transform,FFT)[8]、離散傅里葉變換(Discrete Fourier Transform,DFT)[12]、短時傅里葉變換(Short-Time Fourier Transform,STFT)[19]等方法。Fan 等[8]提出以語譜圖作為網絡輸入,充分利用CNN 對圖像識別的優勢提取語譜圖特征,提高說話人識別性能。基于仿生學的思想,Jia 等[12]提出一種基于語譜圖圖像特征和自適應聚類自組織特征映射(Self-Organizing feature Map,SOM)的快速說話人識別方法。Wang 等[19]提出兩種新穎的深度CNN——稀疏編碼卷積神經網絡和多卷積通道網絡,以語譜圖作為輸入,分層進行特征學習。
2 本文方法
2.1 三聯體深度哈希系統模型
圖1 為利用ARN 模型設計的三聯體深度哈希的系統模型。主要由三個部分組成:1)語譜圖圖像特征深度語義學習;2)哈希碼學習;3)交叉熵損失函數。該模型旨在從具有給定的三聯體標簽的原始語譜圖圖像特征中學習緊湊的哈希碼。哈希碼應該滿足以下要求:1)錨語譜圖圖像特征應該在哈希空間中靠近正語譜圖圖像特征,遠離負語譜圖圖像特征;2)基于空間注意力力機制和交叉熵損失函數,對ARN模型進行端到端訓練,可同時利用三聯體標簽進行語譜圖圖像特征學習和哈希碼學習。

圖1 三聯體深度哈希系統模型Fig.1 Model of triplet deep hashing system
本文提出的三聯體深度哈希方法,實質上是將語音數據處理成語譜圖圖像特征,以語譜圖圖像特征作為訓練數據和測試數據;然后利用圖像領域發展成熟的三聯體深度哈希方法訓練網絡,提取語譜圖圖像特征的深度語義特征;并通過哈希構造將高維向量轉換成低維的二進制哈希碼,減少檢索的計算時間,提升檢索效率,并在殘差網絡(Residual Network,ResNet)的基礎上嵌入空間注意力模塊,充分提取語譜圖圖像特征的能量顯著區域。因此,本文提出的三聯體深度哈希方法完全適用于訓練語音數據。
本文的網絡體系結構主要分為三個模塊和三個全連接(Fully Connected,FC)層,包括:1 個net1 模塊、1 個空間注意力模塊、1 個net2 模塊和3 個FC 層。net1 模塊包含1 個殘差塊和1 個最大池化層,后面是1 個空間注意力(Spatial Attention,SA)模塊(SA 模塊用于生成1 個與輸入特征圖相乘的注意力圖)。net2 模塊包含1 個殘差塊和1 個平均池化層,之后連接1 個FC 層,用于將提取的特征扁平;FC 層之后是哈希層,哈希層的節點數即目標哈希碼的長度,目的是生成語音數據的哈希碼;在哈希層之后設置一個節點數為語音數據片段類別數的輸出層,可在模型訓練時調節哈希層的神經元活動,幫助哈希層生成包含類別語義信息和語義內容信息的哈希碼。模型參數的具體設置如表1 所示。
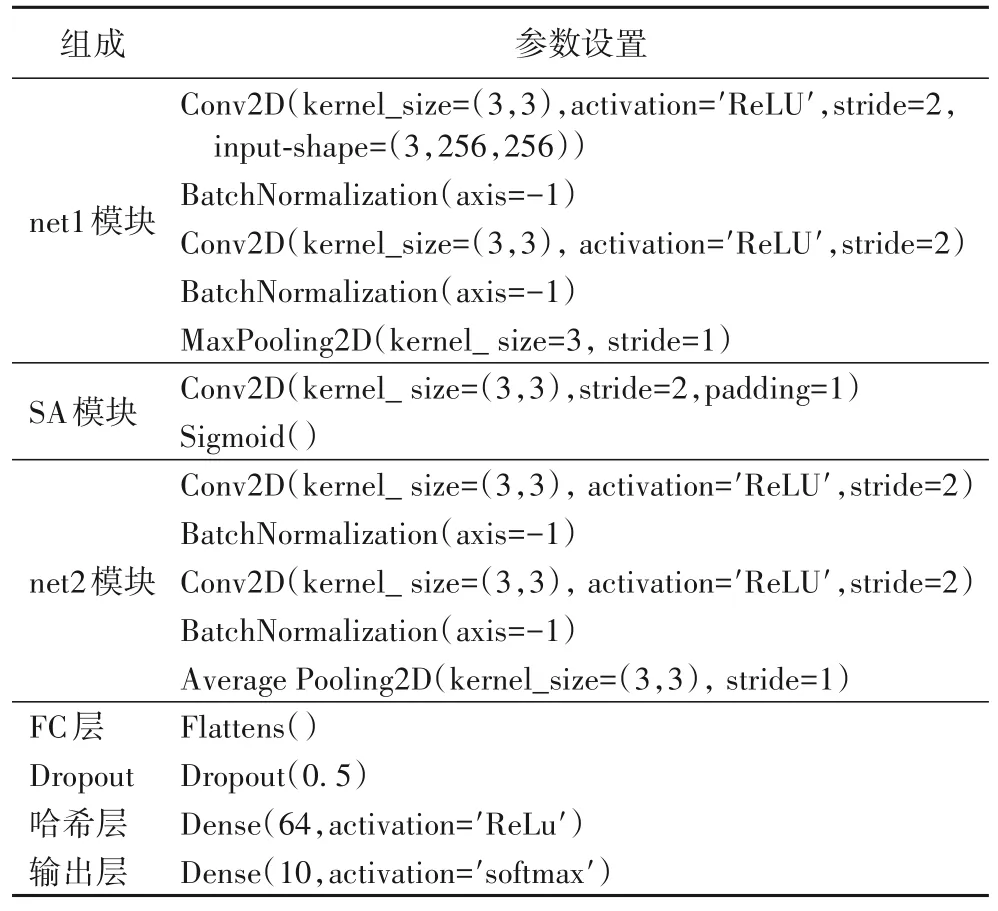
表1 深度哈希編碼模型的參數設置Tab.1 Parameter setting of deep hash encoding model
所有的卷積和池化層使用3×3 的過濾器,卷積層、池化層步幅分別設置為2 和1。除輸出層與空間注意力模塊分別采用softmax 與Sigmoid 激化函數外,所有卷積層和FC 層都配備了修正線性函數(Rectified Linear Unit,ReLU)激活功能。
2.2 網絡體系結構設計
ResNet 是He 等[20]提出的殘差模塊結構,如圖2 所示。即增加一個恒等映射,將原始的函數H(X)轉換為F(X)+X,兩種表達的效果相同,但是F(X)的優化要比H(X)簡單得多,可以加快模型的訓練、提高訓練效率,并且當模型層數增加時,可非常有效地解決網絡退化問題。
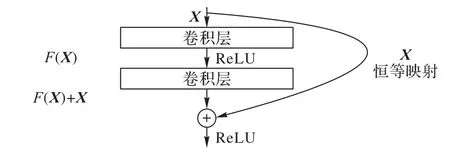
圖2 殘差模塊結構Fig.2 Residual module structure
另外,本文方法使用的空間注意力模塊是對卷積塊注意力模塊(Convolutional Block Attention Module,CBAM)[21]改進后的變體,即在沒有通道注意力模塊的情況下,生成一個有效的特征描述符,以增強語譜圖圖像特征能量顯著區域的特征,如圖3 所示。
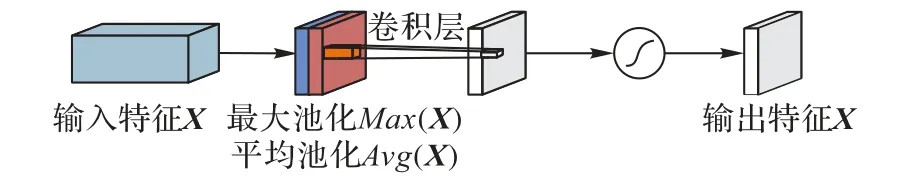
圖3 空間注意力模塊Fig.3 Spatial attention module
設X∈RC×H×W是從卷積層提取的特征映射,其中H、W、C分別表示每個特征映射的高度、寬度以及該層中特征映射(或通道)的數量。空間注意力模塊利用最大池化Max(X)和平均池化Avg(X)操作沿通道軸線聯合聚合特征映射X的空間信息。兩種操作分別取特征映射X的局部最大值和平均值,然后使用Max(X)和Avg(X)按元素相乘,進一步加權局部突出區域,最后通過一個卷積層減少特征映射的數量。加權運算的輸出是Sigmoid 函數,然后乘以特征映射X。改進后的空間注意力模塊定義為式(1):
其中:Max(X)和Avg(X)為H×W×1 維;?表示Sigmoid 函數。
2.3 深度哈希碼構造
深度哈希碼構造的實質是通過訓練圖1 的ARN 學習一個哈希函數H(?),將模型提取的高維向量βi壓縮映射成一段二進制哈希碼,hi,k=H(βi),hi,k∈{0,1}k,k代表哈希序列的長度。哈希函數H(?)必須滿足原相似或不相似的高維特征在哈希映射之后的相似性不變。深度二進制哈希碼構造的實現原理如下:
步驟1 提取初級語譜圖圖像特征。提取訓練集中原始語音文件S={s1,s2,…,sn}的語譜圖圖像特征I,即I={I1,I2,…,In}。設置FFT 點數為512,采用頻率為44 100,幀疊點數為384,窗函數采用漢明窗,具體提取流程如下:
1)分幀加窗。對重采樣格式轉換后的語音數據進行分幀加窗,并根據式(2)進行加窗處理:
其中:w(n)表示窗函數;si(n)表示加窗處理后的第i幀語音信號為幅值歸一化處理后的語音信號;T表示移動幀長;N是時間長度。
2)FFT。對分幀加窗后的語音信號進行FFT,根據式(3)實現時-頻域的轉換:
其中:X(g)表示FFT 后得到的頻域信號;g表示點序號。
3)取功率譜。根據式(4)可將語音信號的頻譜取模的平方,得到語音信號的功率譜。
其中:X(g)是輸入的頻域信號;S(g)是得到的功率譜。
4)取對數。對功率譜進行對數運算,得到語譜圖圖像特征。
步驟2 生成三聯體語譜圖圖像對。隨機將訓練數據I分成一些組,然后為每一對錨-正語譜圖圖像特征隨機選擇一個負語譜圖圖像特征,根據式(5)選取三聯體。
其中:W,b分別表示哈希層的權重矩陣與偏置向量;μARN表示殘差網絡模型中的卷積層、池化層、空間注意力機制的參數向量,f(Ii,μARN)表示輸入數據Ii在經過卷積、池化、空間注意力機制后所提取的特征向量;βi表示所提取到的深度語義特征向量。Wa、Wp、Wn分別表示從哈希層中提取的三聯體深度語義特征向量Wi=(w1,k,w2,k,…,wm,k) (i∈{a,p,n})。其中,k代表哈希層的節點數。
步驟4 構造深度哈希序列。將提取的深度語義特征Wa、Wp、Wn進行哈希構造,生成哈希序列Hi=h1,k,h2,k,…,hm,k(i∈{ a,p,n})。
深度二進制哈希碼具體構造過程如下:
為了創建二進制哈希碼,首先通過式(7)線性縮放的方法將三聯體深度語義特向量βi映射到[0,1]區間,即:
其中,umin和umax代表每個語譜圖圖像特征的深度語義特征向量值(u)中的最小值和最大值。然后利用哈希函數H(?)進行哈希映射,并根據式(8)將[0,1]區間的深度語義特征向量T映射成為k比特的二進制哈希碼。
再通過式(9)進行深度哈希序列構造:
其中,Smeadian表示[0,1]區間每個語譜圖圖像特征深度語義特征向量值中的中值。
2.4 交叉熵損失函數
ARN 模型學習從輸入三聯體語譜圖圖像特征到三元哈希碼的映射Hi=h1,k,h2,k,…,hm,k(i∈{a,p,n}),Ha到HP的距離應小于Ha到Hn的距離。為了使生成的哈希碼具有最大類的可分性和最大哈希碼可鑒別性,在模型訓練過程中采用三聯體交叉熵損失來訓練網絡,目的是在模型訓練過程中,同時保留相似度和分類信息。
在模型的訓練過程中,ARN 模型使用三聯體標簽和標注標簽進行訓練,以同時執行哈希碼學習和分類似然學習。三聯體標簽T對應的標注標簽可以表示為Y=并且表示訓練標簽)。為了懲罰三聯體標簽的相似性損失,將輸入映射到目標空間,使用歐氏距離比較目標空間中的相似性,并確保錨語譜圖圖像特征與正語譜圖圖像特征的哈希碼盡量接近,錨語譜圖圖像特征與負語譜圖圖像特征的哈希碼應盡量遠離。基于這一目標設計了鉸鏈排序損失形式,使相似語譜圖圖像特征對之間的距離最小,不相似語譜圖圖像特征對之間的距離最大。三元組標簽的損失定義如下:
其中:Dis(t,)為度量哈希碼輸出之間距離的L2 范數;k為哈希碼的長度;r∈[0,1]為控制不同語譜圖圖像特征區分度懲罰強度的權重參數,r=0.5。為了懲罰標注標簽下的分類損失,通過聯合考慮輸入的三聯體語譜圖圖像特征來定義交叉熵損失,如式(11)所示:
其中:CE(,)為常見的交叉熵損失形式為預測類。對于相似損失ξ(T)和分類損失ξ(T,Y),通過反向傳播兩者的和來更新模型的權值。理論上,交叉熵損失有利于保留哈希碼中的分類信息,三重態損失函數也可以通過鼓勵哈希碼最小化類內相似度、最大化類間相似度來提高分類性能。
3 實驗與結果分析
3.1 實驗環境及主要參數設置
為評估三聯體深度哈希方法的性能,本文從理論和實驗兩方面進行分析。采用CSLT 發布的漢語語音數據庫THCHS-30[22]作為數據集,總時長約30 h,采樣頻率為16 kHz,采樣精度為16 B 單通道wav 格式語音段,每個語音片段的時長大約為10 s。實驗中隨機選取了內容不同的10類語音,并進行MP3 壓縮、重采樣(8-16 Kb/s)、重量化1(16-8-16 Kb/s)、重量化2(16-32-16 Kb/s)等4 種內容保持操作(Content Preserving Operation,CPO)后,得到共計3 060 條語音片段。在實驗分析階段,隨機選取1 000 條THCHS-30 語音庫中的語音片段進行評估。
在硬件平臺為Intel Core i5-2450M CPU 2.50 GHz,內存16 GB;軟件環境為Windows 10,PyCharm 2021.1.1、PyTorch-CPU 2.1.x+Python3.6 的環境下進行實驗對比。
3.2 深度哈希編碼模型性能分析
在語音檢索系統中,語音數據的深度語義特征提取和高質量哈希碼的生成對語音檢索的精度至關重要,其中哈希層的維度實際上為哈希碼的長度。當哈希層的維度不同時,模型的準確率會呈現一定的變化。因此,本文采用語譜圖圖像特征[8,12,19]與Log-Mel 譜圖圖像特征[23]作為網絡模型的輸入,來評估不同哈希碼長度下模型的準確率。圖4 為使用本文方法的語譜圖圖像特征和Log-Mel 譜圖圖像特征模型在不同哈希編碼長度下的測試準確率曲線。
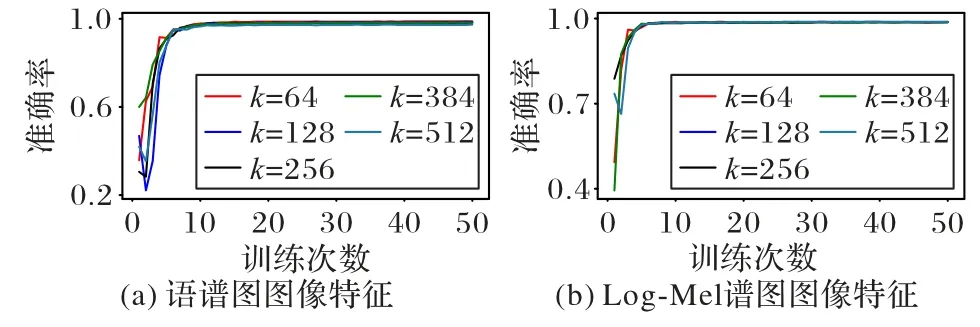
圖4 不同哈希碼長度k的測試準確率曲線Fig.4 Test accuracy curves of different hash code lengths k
從圖4 可以看出,在不同哈希碼長度k下,本文模型在輸入語譜圖圖像特征/Log-Mel 譜圖圖像特征時,模型的測試準確率曲線幾乎都快逼近1,性能表現卓越。哈希碼長度為64時,兩種特征下的模型測試準確率曲線都已達到最高,這是因為本文方法借鑒了圖像領域發展成熟的三聯體深度哈希方法,在生成哈希碼的過程中,提供了數據相對相似的關系,以及網絡模型中嵌入的注意力機制能夠自主聚集整個語譜圖圖像特征/Log-Mel 譜圖圖像特征的能量顯著區域,提高了顯著區域表示,充分提取了深度語義信息。另外,當本文模型輸入語譜圖圖像特征/Log-Mel 譜圖圖像特征時,在不同哈希層節點下,在訓練批次15 或10 時,測試準確率曲線已基本趨于穩定,并取得了很好的效果,不再有任何變化,這說明模型沒有過擬合和欠擬合現象,對輸入數據的擬合程度表現良好。兩種特征下,模型的收斂程度不同是由于語譜圖圖像特征頻率范圍跨度大,語義信息量更豐富,計算量更大。當哈希碼長度為64 時,模型的測試準確率最高,這說明哈希碼節點數為64 時可以滿足檢索系統的基本要求,而過長的哈希碼會導致語音檢索系統的檢索效率下降,過短的哈希碼會對語音數據的語義信息表達不全面,造成哈希碼之間區分性的降低。因此,本文三聯體深度哈希方法的哈希碼長度為64時的模型架構表現最好,可用來生成更緊湊的哈希碼。
3.3 精度分析
為了評價本文方法的性能,使用平均精度均值(mean Average Precision,mAP)進一步衡量在不同哈希碼長度下網絡模型的性能表現。同時,為了測試語譜圖圖像特征和Log-Mel 譜圖圖像特征在作為模型的輸入時,模型所生成的哈希碼的魯棒性,在實驗之前,先對語音數據進行MP3 壓縮、重采樣(8-16 Kb/s)、重量化1(16-8-16 Kb/s)、重量化2(16-32-16 Kb/s)等4 種CPO,共得到4 000 條語音數據。
本拓撲中網端提供單相交流高壓電,輸入級采用多個不控整流模塊串聯級聯的方式,同時為保證網端能接近單位功率因數運行,需要在整流環節加裝有源功率因數校正單元。
采用CPO 后的語音數據生成的哈希碼進行測試,先采用三聯體標簽/單標簽的方法,利用ARN 模型對各種CPO 后的語音數據所生成的語譜圖圖像特征/Log-Mel 譜圖圖像特征計算它們的平均精度(Average Precision,AP),然后再根據AP 值計算mAP。同理,利用深度平衡離散哈希(Deep Balanced Discrete Hashing,DBDH)[24]、改進的深度哈希(Improved Deep Hashing Method,IDHM)[25]對CPO 后的語譜圖圖像特征/Log-Mel 譜圖圖像特征計算mAP,并與文獻[6,26]中的方法進行對比。給定一個錨語譜圖圖像特征xq,使用式(12)計算它的平均精度:
其中:Rk為相關語音片段數目;p(k)為返回列表中截止點k處的精度;Δr(k)為指示函數,如果第k個位置上的返回語音片段與xq相關,則該指示函數等于1;否則Δr(k)為0。給定Q次查詢,mAP 為已排序的所有查詢結果的AP。mAP 計算如式(13)所示:
表2 為不同哈希碼長度下,利用本文三聯體標簽/單標簽的方式將語譜圖圖像特征和Log-Mel 譜圖圖像特征分別送入ARN 模型的mAP 對比結果。
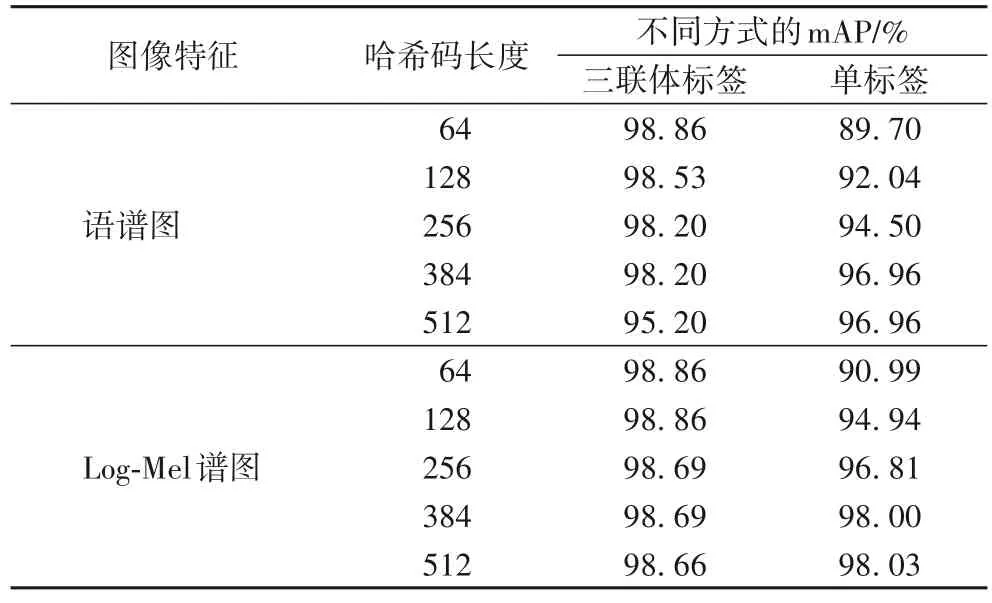
表2 不同哈希碼長度下同一編碼模型的mAPTab.2 mAP values of same encoding model under different hash code lengths
由表2 可知,同在ARN 編碼模型下,將語譜圖圖像特征/Log-Mel 譜圖圖像特征以三聯體標簽的方式送入編碼模型,它的編碼模型的mAP 值與哈希碼長度成反比,這是因為三聯體標簽信息會編碼數據集內的相似關系,以及ARN 編碼模型利用三聯體交叉熵損失函數并實現了最大的類可分性和最大的哈希碼可分性,當哈希碼長度為64 時,mAP 就已達到最高。而利用單標簽方法將語譜圖圖像特征/Log-Mel 譜圖圖像特征送入編碼模型,它的編碼模型的mAP 值與哈希碼長度成正比,這是因為單標簽對監督信息利用不足以及ARN 編碼模型只考慮了一種損失,所以越長的哈希碼對語音數據的語義信息表達越全面。由表2 可知,同在ARN 編碼模型下,采用三聯體標簽的方法和單標簽方法,設置哈希層不同的節點數,編碼模型的mAP 基本都保持在90%以上,說明ARN 編碼模型具有很好的魯棒性。
表3 為不同哈希碼長度下不同編碼模型的mAP 的對比結果。其中,文獻[24-25]中的實驗數據是對語譜圖圖像特征/Log-Mel 譜圖圖像特征的運行結果。本文利用語譜圖圖像特征/Log-Mel 譜圖圖像特征,采用三聯體標簽的方法,將數據送入ARN 編碼模型進行訓練,生成哈希碼。由表3 可知,相較于文獻[6,24-26],當哈希碼長度k為64、128、256、384 時,ARN 模型的mAP 最高,這說明ARN 模型的魯棒性最優。當哈希碼長度k為512 且模型輸入特征為語譜圖圖像特征時,文獻[6,26]方法的mAP 值略高于本文方法。主要有兩個原因:1)本文方法采用的三聯體標簽本身比成對標簽、單標簽包含更豐富的語義信息,因為每個三聯體標簽可以自然地分解為兩個成對的標簽,明顯地提供了數據之間相對相似的概念;2)本文方法同時利用注意力機制和三元交叉熵損失函數訓練網絡,充分提取語義信息并將類別信息嵌入到所學習的哈希碼中,所以ARN 模型在哈希碼長度為64 時,mAP值已最高,過長的哈希碼太過冗余,反而影響mAP 值。文獻[24-25]方法是成對標簽,包含的語義信息和類別信息欠缺,且所采用的深度卷積神經網絡模型需要150 次以上的迭代mAP 才能達到高精度,當迭代次數與本文方法一樣,同為50 次的時候,模型的mAP 值精度不高,這是因為文獻[24]方法采用的是平衡離散哈希方法,通過離散梯度傳播和直通估計器優化哈希碼,雖避免了傳統連續松弛法帶來的量化誤差,但是增加了復雜度;文獻[25]中引入了基于標準化語義標簽的兩兩量化相似度計算方法以及采用量化損失來控制哈希碼的質量,增加了算法復雜度;文獻[6,26]中采用單標簽方法且只考慮一種損失,造成監督信息利用不足,所以只有當哈希碼長度為512 時,編碼模型的mAP 值才能達到高精度。因此,本文方法采用的哈希編碼模型具有良好的性能。
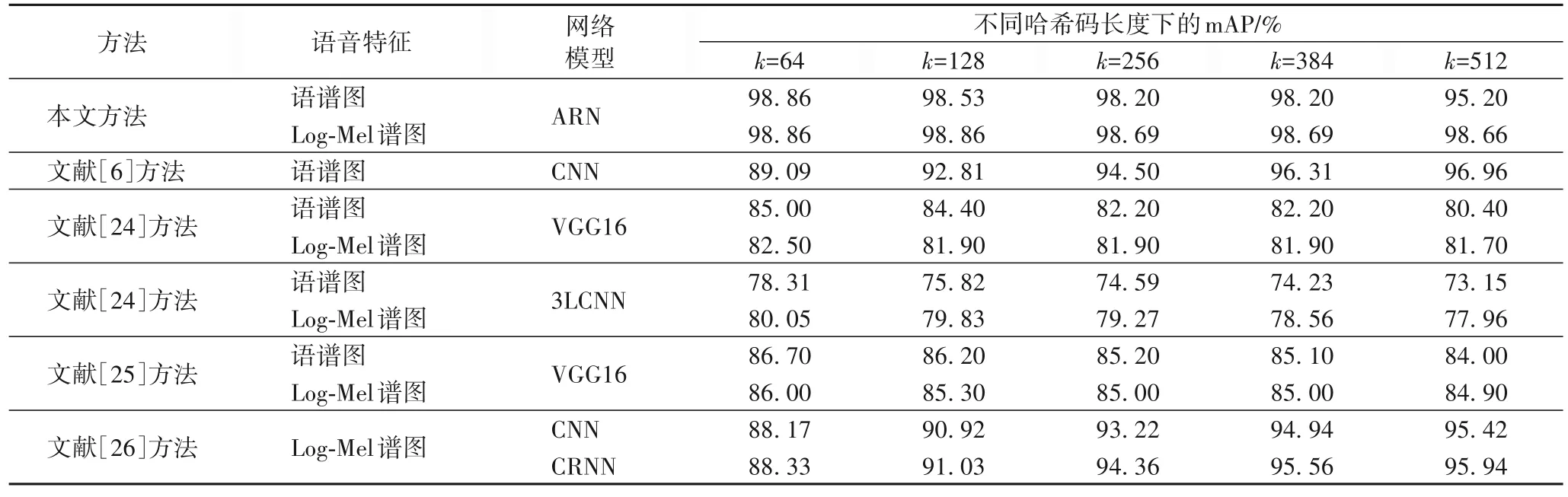
表3 不同哈希碼長度下不同編碼模型的mAP值Tab.3 mAP values of different encoding models under different hash code lengths
由表3 可知,通過對兩種特征的mAP 值的權衡考慮,后續實驗評估采用哈希碼長度為64 的ARN 編碼模型。
3.4 檢索性能評估
查全率R又稱作召回率,表示檢索返回的列表中,查詢出來的語音片段與查詢相關的語音片段所占的比例。計算公式如(14)所示:
其中:TP、FN分別表示檢索到的與查詢相關的語音片段的數目,以及未檢索到與查詢相關的語音片段數目;TP和FN的和為語音數據庫中與查詢相關的語音片段的總數。
查準率P為檢索精度,表示返回的列表中,查詢為真的語音片段所占的比例,計算公式如(15)所示:
其中:FP表示檢索到與查詢無關的語音片段的總量,TP和FP的和為返回的語音片段的總量。
因為查全率和查準率是反依賴的關系,所以用F1 分數作為測試指標。F1 分數越大,說明檢索性能越好。計算公式如(16)所示:
圖5 為不同標簽方法下不同特征的P-R曲線。實驗分別利用三聯體標簽/單標簽方式將語譜圖圖像特征和Log-Mel譜圖圖像特征送入ARN 模型中,來測試兩種標簽方式下兩種特征的查全率和查準率。
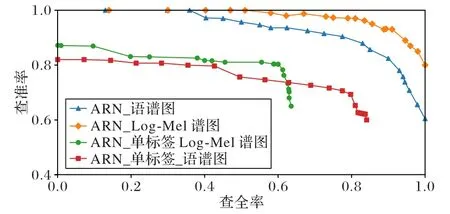
圖5 不同標簽方法下不同特征的P-R曲線Fig.5 P-R curves of different features under different labeling manners
從圖5 可知,在哈希碼長度均為64 的時候,本文方法三聯體標簽比單標簽方式下的查全率、查準率更高,說明在同等哈希碼長度下,三聯體標簽方式能生成更高效緊湊的哈希碼,這是因為三聯體深度哈希編碼模型在生成哈希碼的過程中,會充分利用三聯體之間的相似關系、三聯體交叉熵損失函數,而單標簽方式相比三聯體標簽方式,監督信息不足。
為評估本文方法的檢索性能,采用哈希編碼長度為64的ARN 模型來測試查全率、查準率和F1 分數,與現有方法[19,26-28]的檢索性能進行了對比,對比結果如表4 所示。
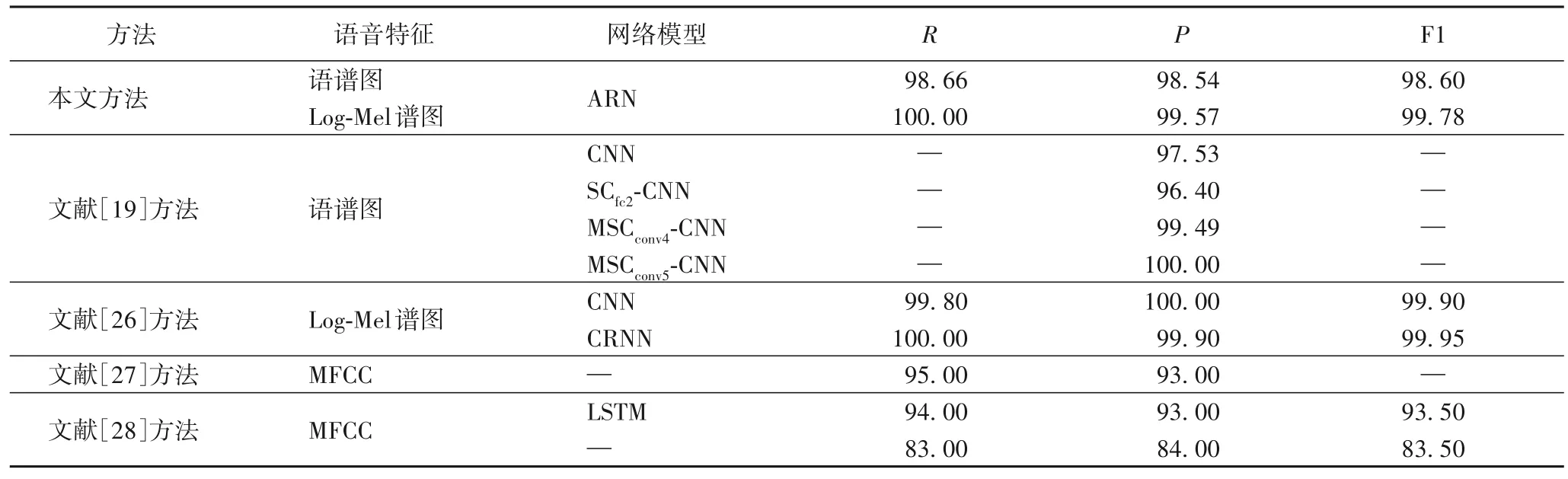
表4 不同方法的檢索性能對比 單位:%Tab.4 Retrieval performance comparison of different methods unit:%
從表4 可知,相較于文獻[19,27-28]中的方法,本文方法基本取得了最優結果,唯獨查準率P略低于文獻[19]中的MSCconv5-CNN(Multichannel Sparse Coding Convolutional Neural Network)模型,說明本文方法的檢索性能較好。文獻[26]中的方法的檢索性能略高于本文方法,是因為文獻[26]中的方法在檢索過程中,采用了兩級分類檢索策略,先根據類別哈希碼篩選出與查詢語音同一類的候選集合,再在候選集合中檢索匹配,且檢索過程中采用了384 長度的哈希碼。
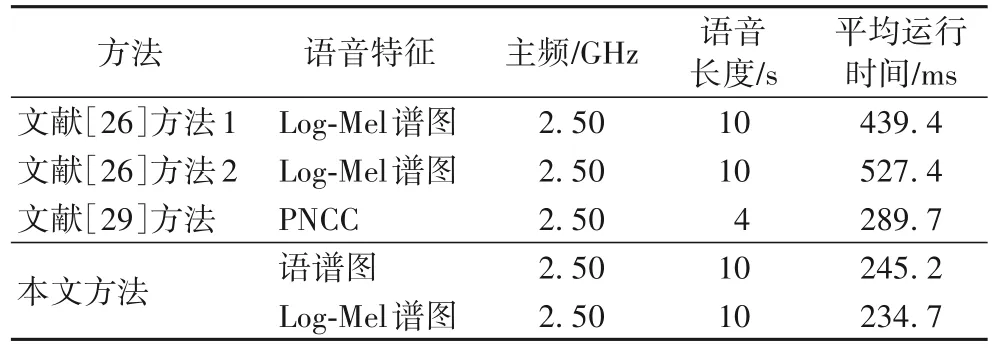
為了評估ARN 模型的分類性能,對語譜圖圖像特征和Log-Mel 譜圖圖像特征的受試者工作特征(Receiver Operating Characteristic,ROC)曲線和曲線下面積的(Area Under Curve,AUC)進行了對比。ROC 曲線與x-y軸圍成的區域面積被定義為AUC 值。y=x這條直線為判斷模型分類性能好壞的一個閾值,它的值為0.5,若0.5 圖6 不同特征的ROC曲線和AUC值Fig.6 ROC curves and AUC values for different features 從圖6 可以看出,本文方法在兩種不同特征的ROC 曲線中取得的AUC 值分別為0.85 和0.96。AUC 值的區間范圍均在0.5 另外,為了測試本文方法生成的哈希碼的魯棒性,將CPO 后的語音數據生成的語譜圖圖像特征/Log-Mel 譜圖圖像特征作為ARN 模型的輸入,并利用模型生成的哈希碼進行評估分析,查全率和查準率如表5 所示。其中,文獻[26]方法1 和文獻[26]方法2 分別代表骨干網絡為CNN 和CRNN 的方法。 表5 不同內容保持操作下的查全率和查準率對比結果 單位:%Tab.5 Comparison results of recall and precision under different content preserving operations unit:% 從表5 可看出,本文方法以四種CPO 后的語音數據所生成的語譜圖圖像特征和Log-Mel 譜圖圖像特征作為模型的輸入時,本文方法所生成的哈希碼仍然具有較高的查全率和查準率。相較于文獻[26,29]方法,語音數據在MP3 壓縮和重量化2(Requantization 2,R2)操作后,本文方法在兩種特征下查全率和查準率均達到了100%。這是因為MP3 壓縮的特點是使低頻信號不失真,高頻信號減弱;R2 操作的特點是使音頻波形精度增高,而不影響音頻的質量。相比之下,語音數據在重采樣(Resampling,R)操作后,本文方法在采用語譜圖圖像特征下的查全率和查準率略低于文獻[26,29]方法。R操作是將采樣頻率先降低到8 kHz,然后增加到16 kHz,雖提高了音頻質量,但也無形中增加了音頻體積,增大了計算量,致使語譜圖圖像特征損耗更大,部分信息丟失。相比其他語音內容保持操作,語音數據在重量化1(Requantization 1,R1)操作后,本文方法在兩種特征下的查全率和查準率都低于文獻[29]方法,這是因為語音信號在16-8 Kb/s 量化操作時,語音波形幅度精度降低,所以R1 操作影響了音頻質量;而R1 操作下文獻[29]方法的查全率和查準率更高,因為哈希碼長度498 大于本文方法的哈希碼長度64,所以在音頻質量破壞的情況下,哈希碼長度越長,所包含的語義信息更全面。 為了驗證本文方法對語音檢索的準確度,實驗隨機選取了1 000 條測試語音中的第756 條查詢語音進行了匹配檢索,分別利用語譜圖圖像特征和Log-Mel 譜圖圖像特征作為模型的輸入所生成的深度哈希碼與深度哈希索引表中的哈希碼(數據庫中每個語音數據所對應的哈希碼)進行匹配檢索,匹配檢索結果如圖7 所示。 圖7 不同語音特征的匹配檢索結果Fig.7 Matching retrieval results for different speech features 從圖7 可知,只有查詢語音的比特誤碼率(Bit Error Ratio,BER)小于設置的閾值0.20,其余999 條語音的BER 均大于0.20,匹配失敗。因此,本文方法具有較好的檢索效果。 檢索效率是驗證算法好壞的一種重要方法。實驗隨機選取THCHS-30 語音庫中的10 000 條語音片段,并對它們經過MP3 壓縮內容保持操作后作為查詢語音進行評估。計算本文方法的平均檢索時間,并與文獻[26,29]方法進行對比分析,結果如表6 所示。 表6 本文方法與現有方法的檢索效率對比結果Tab.6 Comparison results of retrieval efficiency of proposed method and existing methods 從表6 可知,使用Log-Mel 譜圖作為特征的本文方法的平均運行時間相較于文獻[26,29]方法縮短了19.0%~55.5%,說明本文方法檢索效率良好。本文方法采用的三聯體標簽可以明顯地提供數據之間相對相似的概念,同時利用注意力機制和三元交叉熵損失函數訓練網絡,生成更高效緊湊的哈希碼,縮短了匹配長度,節省了檢索時間。文獻[26,29]中分別采用了384、498 長度的哈希碼進行了匹配檢索,相比本文方法采用的64 長度的哈希碼,增加了匹配長度,影響了檢索效率;文獻[29]方法的檢索平均運行時間低于文獻[26]方法,是因為在生成哈希碼的過程中,文獻[29]中采用了降維速度更快的主成分分析算法。因此,本文方法非常適合語音檢索任務。 本文利用注意力機制-殘差網絡(ARN)模型,提出了一種用于語音檢索的三聯體深度哈希方法。與現有的語音檢索方法中采用的基于單標簽的深度哈希方法相比,可利用三聯體標簽信息編碼數據集內的相似關系生成高效緊湊的哈希碼。另外,結合殘差網絡和注意力機制來提取語譜圖圖像特征的深度語義特征,并引入三聯體交叉熵損失,不僅可以使模型充分提取語譜圖圖像特征的語義信息,而且還可將語譜圖圖像特征的所屬類別信息嵌入到所學習的哈希碼中,從而提高語音檢索的檢索精度和效率。實驗結果表明,與現有語音檢索方案相比,本文方法能夠生成高效緊湊的哈希碼,確保了語音檢索系統具有良好的識別率、魯棒性、查全率和查準率,對較長的語音具有良好的檢索效率和準確性。 不足之處是本文方法不能構造更緊湊的深度哈希二值碼來完成語音高效的檢索。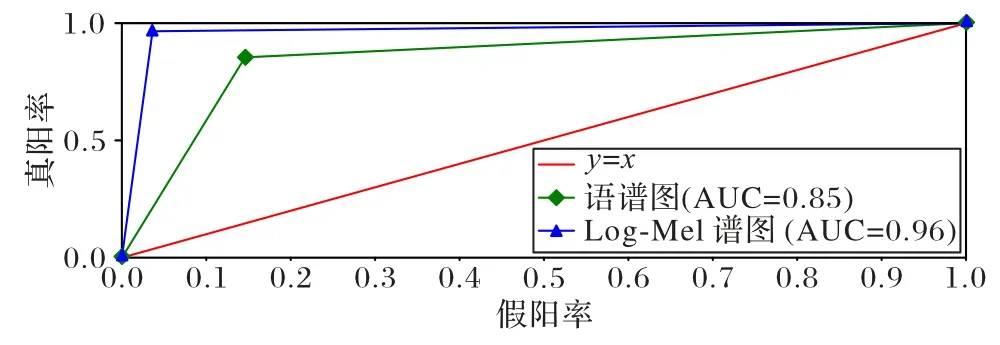

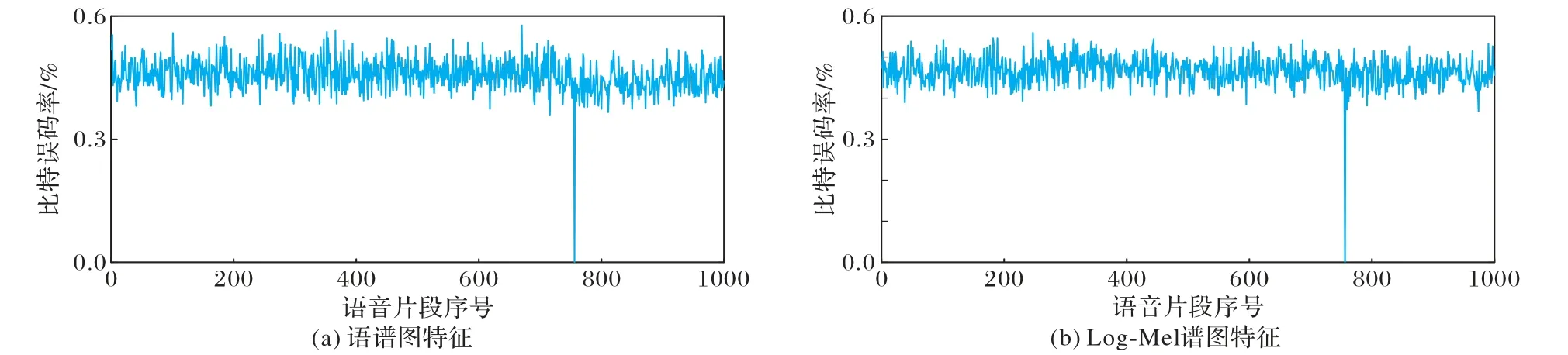
3.5 檢索效率分析
4 結語
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56
