基于EfficientNetV2和物體上下文表示的胃癌圖像分割方法
2023-09-27 06:32:02張自力胡新榮何儒漢
計算機應用 2023年9期
周 迪,張自力*,陳 佳,胡新榮,何儒漢,張 俊
(1.武漢紡織大學 計算機與人工智能學院,武漢 430200;2.武漢紡織大學 湖北省服裝信息化工程技術研究中心,武漢 430200;3.武漢紡織大學 紡織服裝智能化湖北省工程研究中心,武漢 430200;4.武漢工程大學 計算機科學與工程學院,武漢 430205)
0 引言
癌癥是困擾全世界的疾病之一,根據世界衛生組織在2019 年的調查統計[1],胃癌的發病率和死亡率都比較高,僅在2020 年里,就增加了100 多萬新病例和76.9 萬的死亡病例,相當于每13 個死亡病例里就有1 例死于胃癌。目前推測慢性幽門桿菌傳染是造成患病的主要原因,該細菌的傳染性極強,傳染了全世界近50%的人口[2]。
病理作為醫療領域的“金標準”,在臨床診斷中有著其他診斷所無法替代的重要作用。然而,病理診斷行業存在諸多問題[3]:職業風險大、培養周期長以及職業收入低。基于以上原因,主動做病理醫生的人數少。
近年來,隨著全切片掃描技術的發展,不但使病理切片的獲取更方便,更重要的是改變了傳統的閱片方式,使得將計算機視覺技術和病理圖像診斷結合成為可能。利用計算機技術對病理圖像進行分割,讓醫生更直觀地發現圖像中的病變區域,對于幫助病理醫生更進一步地判斷胃癌的分期、分型具有重要意義。
神經網絡在短短幾年內迅速發展,如今已應用到語音識別、圖像識別、自然語言處理等諸多領域。隨著人工智能的迅速發展,卷積神經網絡(Convolutional Neural Network,CNN)越來越強大,在圖像分割領域出現了許多優秀的網絡框架,如全卷積網絡(Fully Convolutional Network,FCN)[4],它被認為是深度學習用于語義分割的開山之作,將傳統CNN中最后的全連接層換成了卷積層,這樣的設計可以使網絡適用于任意尺寸的輸入,實現了端到端的訓練。但是,它的缺點也很明顯,上采樣過程過于粗糙,只用了簡單的反卷積,使得最后分割結果不夠精細。后續也有許多研究者采用馬爾可夫隨機場[5]和條件隨機場[6]優化分割結果。比如DeepLab[7-10]系列讓深度學習在分割領域前進了一大步,通過引入空洞卷積來解決卷積越多,丟失信息越多的問題,在沒有加入參數和多余計算的情況下,擴大了感受野;同時,引入了空洞空間卷積池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)結構,在不改變特征圖大小的前提下,增大網絡的感受野,使網絡能提取多尺度信息。采用以上優秀的成果使利用計算機視覺技術分割病理圖像成為可能。
目前深度學習在胃癌病理領域的應用較少,不過在整個醫學領域中已經有了較多的研究成果。Ronneberger 等[11]提出的U-Net 模型是醫學分割中最經典的網絡模型之一,該模型及其改進方法仍然被應用在各種醫學分割任務中,并且取得了不錯的分割結果。U-Net 基于FCN 結構,將上采樣模塊設計成和下采樣類似的模塊;同時,通過跳躍連接防止細節丟失,結構簡單、效果好,在當時ISBI(International Symposium on Biomedical Imaging)比賽的神經元等多項任務中獲得冠軍,但是缺點也十分明顯,該模型的特征提取網絡太淺,導致提取的特征具有局限性。Milletari 等[12]針對臨床圖像是3D 圖像的問題,提出了V-Net 模型,將3D 卷積與UNet 進行結合來分割3D 圖像;同時,提出Dice 系數損失函數來解決數據集正負樣本不平衡的問題,在前列腺核磁共振(Magnetic Resonance Imaging,MRI)數據集中分割的Dice 評分達到了86.9%。Alom 等[13]基于傳統U-Net 提出一個全新的R2U-Net(Recurrent Residual Convolutional Neural Network based on U-Net)模型,將循環殘余卷積與U-Net 結合,有利于深層網絡的訓練,在相同參數的情況下,該模型在視網膜血管等分割任務中取得了更好的結果。Zhou 等[14]針對U-Net最佳深度未知的問題,提出了U-Net++模型,在編碼器和解碼器之間加入大量跳躍連接來提高網絡特征提取能力,該模型在六種常見數據集中皆取得了優于當時其他網絡模型的成績。Oktay 等[15]在U-Net 上采樣過程中添加注意力機制,讓網絡學會抑制不相關區域,注重有用的特征,提出了Att UNet(Attention U-Net),在電子計算機斷層掃描(Computed Tomography,CT)數據集的胰腺任務中Dice 系數達到84%。張澤中等[16]基于多尺度輸入提出了多輸入融合網絡(Multi-Input-Fusion Net,MIFNet),同時將不同尺寸的圖片作為網絡的輸入,提高網絡提取不同尺度特征的準確度,在病理切片識別AI 挑戰賽數據集上的Dice 評分達到81.87%。
一般來說,超聲、CT 和MRI 等醫學造影圖像中的數據特征相對較少,器官位置等信息相對固定,往往能花費較低的計算資源就獲得令人滿意的效果,但在具有復雜特征的病理學等數據中,獲得的結果往往不盡如人意。所以,想要提高網絡預測結果準確度,需要解決以下3 個問題:1)針對胃癌病變區域和形狀不固定的問題,如何提取更好的病變特征圖?2)針對胃癌病變區域邊緣復雜的問題,如何讓網絡上采樣過程中保留更多細節?3)如何解決數據集偏小,容易出現過擬合的問題?
針對上述問題,本文改進U-Net 并結合EfficientNetV2 和物體上下文表示(Object-Contextual Representation,OCR)的優點,提出一種基于改進U-Net 的自動分割胃癌病理圖像模型EOU-Net。本文使用公開的2021“SEED”第二屆江蘇大數據開發與應用大賽(華錄杯)醫療衛生賽道提供的胃癌病理切片圖像數據集(后文簡寫為SEED 數據集)(https://www.marsbigdata.com/competition/details?id=21078355578880)、2017 中國大數據人工智能創新創業大賽系列之“病理切片識別AI 挑戰賽”提供的胃癌病理切片數據集(后文簡寫為BOT 數據集)(http://www.datadreams.org/#/newraceintro_detail?id=225)和經典分割數據集PASCAL VOC 2012(http://host.robots.ox.ac.uk/pascal/VOC/voc2012/)進行實驗。
1 本文方法
1.1 網絡框架
針對引言提出的3 個問題,本文對傳統U-Net 作出了3點修改:首先,為了讓網絡能應對病理圖像復雜特征,引入優秀的分類網絡EfficientNetV2[17]作為U-Net 的編碼器(Encoder)來提高網絡的特征提取能力;然后,為防止網絡在上采樣階段丟失病理圖片復雜的邊緣信息,加入了本文改進的OCR 模塊,通過細胞上下文特征信息判斷某個像素是否與周圍像素屬于同一類,從而提高網絡分割的邊緣精度;最后,為了應對醫學數據集普遍偏小,訓練過程容易出現過擬合的問題,加入了驗證階段增強(Test Time Augmentation,TTA)后處理模塊,對同一張圖片進行多次變化,分別預測,并將不同預測結果通過特征融合的方式得到網絡最后的分割結果。具體網絡模型如圖1 所示,主要分為三個部分:1)由MBConv 和Fused-MBConv 組成的編碼器,用于提取圖像中不同感受野的胃癌區域特征;2)加入了改進后的OCR 解碼器模塊(Decoder),將不同感受野提取的特征圖進行融合,然后上采樣恢復到原圖大小,并通過探索圖像中像素間關系來解決上采樣帶來的細節丟失問題,優化模型輸出的邊緣細節;3)TTA 后處理模塊,通過對輸入圖片進行多次變換,并融合多次變換的預測結果,得到最終的網絡輸出結果。
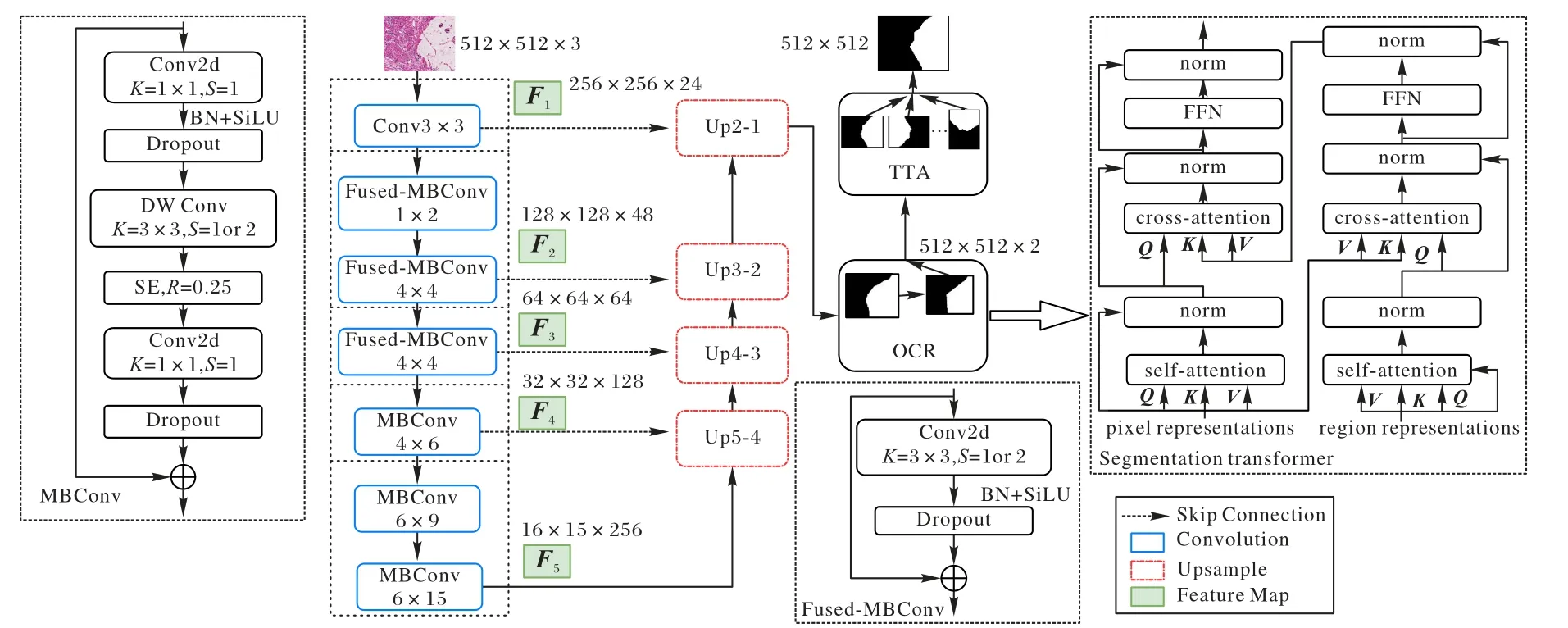
圖1 EOU-Net網絡模型結構Fig.1 Network model structure of EOU-Net
在數據處理階段,本文首先對胃癌數據集進行預處理,將圖像統一縮放到512×512,在編碼階段通過EfficientNetV2主干網絡提取特征,得到5 個感受野不同的特征圖:F1、F2、F3、F4和F5,其中:K為卷積核大小;S為卷積步距,R表示SE(Squeeze-and-Excitation)注意力模塊節點舍棄的比例,MBConvM×N表示中間層通道數擴大M倍,該模塊重復N次。特征提取后,依次對特征圖進行上采樣,接著將Up2-1上采樣之后的結果,通過改進后的OCR 模塊,這樣就完成了一次預測。接著,通過TTA 后處理模塊對輸入圖像多次預測,就能得到網絡最后的預測結果。
1.2 EfficientNetV2特征提取模塊
傳統U-Net 的特征提取網絡有一個致命的局限性,即模塊細節是人為決定,那么很容易讓人產生懷疑:如果網絡更深、更寬,輸入圖像更大,那么網絡的特征提取能力是否會更好。然而,隨著卷積神經網絡(CNN)的發展,已經出現了許多更優秀的卷積、激活函數、注意力等模塊,這些模塊的搭配方案非常多,想要人為窮舉找出最好的特征提取網絡并不現實。所以,如果能借助某種方法找出這些優秀模塊的最佳組合方案,能有效提高特征提取網絡的特征提取能力。
目前,主要從網絡的深度、寬度和圖像分辨率來提升CNN 的特征提取能力。然而,這三個參數并不是增加得越多,網絡的特征提取能力越好,隨意修改參數,往往會出現反效果;同時,參數選擇過多,人工調參優化工作也會過于繁重。Tan 等[18]研究這三個參數的最佳搭配關系,并提出了EfficientNet,通過NAS(Neural Architecture Search)技術[19]以準確度和運算量為優化目標來平衡網絡深度、寬度和圖像分辨率,最后得到EfficientNet-B0,在ImageNet 分類任務上有84.3%的準確度,需要的參數也遠少于其他網絡。
EfficientNetV2[17]是繼EfficientNet 之后提出的全新網絡。針對EfficientNet 訓練圖像過大時,有可能出現內存不夠以及在淺層網絡使用DW(DepthWise)[20]卷積訓練速度過慢的問題,提出了Fused-MBConv 模塊,并且使用NAS 技術探索Fused-MBConv 和MBConv 模塊的最佳組合方式,最后提出了全新的EfficientNetV2,在ImageNet 分類數據集上,不僅有87.3%的準確度,訓練速度也更快。本文將EfficientNetV2 引入圖像分割領域,提出一種使用EfficientNetV2 提取特征的方法,使U-Net 的編碼器有更優秀的特征提取能力,EfficientNetV2 的基本模塊如表1 所示。其中:MBConvM的M表示中間層通道數擴大倍率;k 表示卷積核大小;SE 表示注意力模塊節點舍棄比例。本文的輸入圖像大小統一縮放為512×512。首先,通過Stage0 的stem 模塊得到256×256 的特征圖F1;其次,通過Stage1、Stage2 的Fused-MBConv 模塊得到128×128 的特征圖F2;然后,通過Stage3 的Fused-MBConv模塊得到64×64 的特征圖F3;接著,通過Stage4 的MBConv 模塊得到32×32 的特征圖F4;最后,通過Stage5、Stage6 的MBConv 模塊得到16×16 的特征圖F5。至此,得到5 個不同感受野的特征圖,將用于后續的上采樣和特征融合。

表1 EfficientNetV2基本模塊Tab.1 Basic modules of EfficientNetV2
1.3 改進后的OCR解碼器模塊
感受野對于語義分割任務來說非常重要,能直接影響網絡分割物體的大小。而CNN 使用的卷積不論是3 × 3 還是7 × 7,始終有大小限制。所以,CNN 通過堆疊卷積獲取的感受野也必然有局限性。早些年,為了擴大網絡的感受野往往會采用金字塔場景解析網絡(Pyramid Scene Parsing Network,PSPNet)[21],或者ASPP[8]結構。隨著Non-local[22]提出后,許多研究[23-25]嘗試從self-attention 的角度解決該問題。受到OCRNet[26]的啟發,本文對OCR 模塊作出了兩點改進:1)沒有將像素特征(Pixel Representations)與細目標區域(Fine Object Regions)進行拼接;2)將Fine Object Regions 和軟目標區域(Soft Object Regions)按照相加的方式進行特征融合,因為考慮到人工設置權重往往很難找到最合適的值,不如直接交給卷積去完成這個任務,這樣就能在保證效果的同時,減少模塊的參數和計算量,具體結構如圖2 所示。

圖2 改進后的OCR模塊結構Fig.2 Structure of improved OCR module
在解碼階段,本文使用線性插值的上采樣方法,該方法相較于轉置卷積需要的計算量更小,其實際效果與轉置卷積效果相差不大,而且轉置卷積如果參數選擇得不合適很容易出現棋盤效應[27]。基于以上原因,本文選擇線性插值方法,實際結構如圖3 所示。
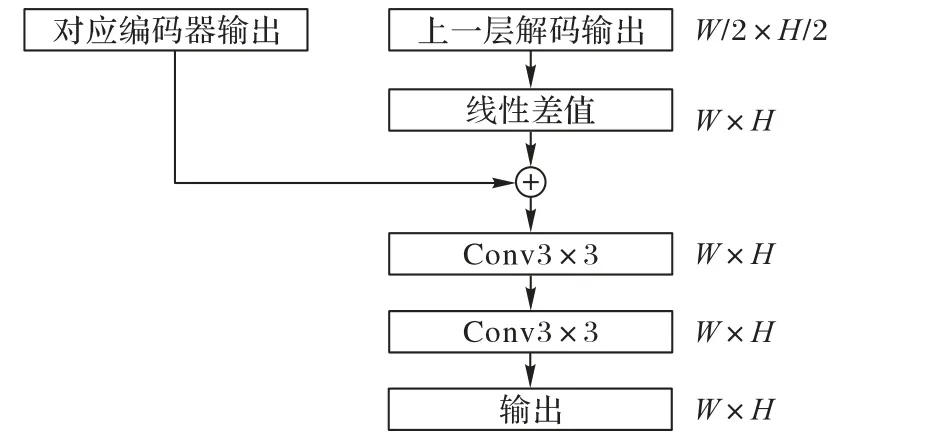
圖3 上采樣的結構Fig.3 Structure of upsampling
首先,將上一層上采樣得到的特征圖通過線性差值的方式放大一倍;然后,將它與骨干特征提取網絡得到的同一大小特征圖按相加的方式進行特征融合;最后,通過兩個3 × 3的卷積便能得到這一層上采樣輸出,重復這個過程直至上采樣到原圖大小1/2 時,為了避免感受野帶來的局限性,通過改進后的OCR 模塊來探索像素與像素之間的關系。OCR 本質就是一種由粗到細的分割,設輸入圖片為I∈RH×W×C,對應的輸出結果為Y∈RH×W。其中,H、W、C表示輸入圖片的行、列和通道數。在本文中,H=W=512,C=3。首先,通過骨干特征網絡以及上采樣操作得到輸入特征圖;然后,再依次通過變換函數得到每個像素特征(Pixel Representations)和2 個軟目標區域(Soft Object Regions)分別對應病變區域和健康區域,如式(1)~(3)所示:
其中:θ(·)表示做4 次圖3 所示操作,得到原圖大小1/2 的特征圖fB,將它作為改進后OCR 模塊的輸入;?1(·)和?2(·)是變換函數,由3×3 卷積、批歸一化(Batch Normalization,BN)、線性整流函數(Rectified Linear Unit,ReLU)實現;fS代表軟目標區域,通道數為2,將它作為粗分割,用于最后的特征融合;fP代表每個像素的語義信息和特征,通道數為256。
根據每個像素的語義信息和特征得到每個類別區域特征(Object Region Representations):
其中:Xi表示第i個像素的特征向量;Mki表示第i個像素是k類的概率,本文分為病變區域和健康區域兩類,所以,k=2。隨后,使用self-attention 計算每個像素與各個區域的關系,具體見式(5)~(6):
其中:κ(·)、γ(·)、δ(·)均為變換函數,由1×1 卷積、BN、ReLU 激活函數實現;Q、K、V為3 個向量;dK是K的維度,fR是像素與各個區域的關系。然后計算物體上下文特征fO:
最后,通過卷積將上下文特征通道數轉換到分割類別數,然后和粗分割采用相加的方式進行特征融合,就能得到最終改進后OCR 模塊的輸出,具體見式(8):
其中:Y為改進后OCR 模塊的最終輸出;ρ(·)和σ(·)為3×3卷積。OCR 模塊能很好地優化胃癌病理圖像的病變細胞和正常細胞的復雜的邊緣區域,使預測圖更接近實際情況。
1.4 TTA后處理模塊
通過1.3 節的方法能得到預測圖,但該預測圖很可能存在因網絡過擬合而導致分割錯誤的地方,所以需要后處理方法來解決這個問題。圖像增強技術目前被廣泛應用在訓練階段,常常通過對原數據集進行一系列變換來達到擴充數據集的目的,從而增加數據集的多樣性,常見的變換有翻轉、裁剪、旋轉和縮放等。許多研究表明,通過后處理方式能進一步提高網絡的精確度,DeepLabV2[8]使用稠密條件隨機場(Dense Conditional Random Field,DenseCRF)優化分割的邊緣細節,從而提高網絡分割結果;然而,該算法要求分割區域與其他區域存在一定差異才會有比較好的效果,具有一定局限性。Wachinger 等[28]使用3D DenseCRF 提高國際醫學圖像計算和計算機輔助干預協會(Medical Image Computing and Computer Assisted Intervention society,MICCAI)數據集的邊緣分割效果;石志良等[29]利用腐蝕圖替代人工輸入初始化圖割模型,實現相鄰骨組織的自動分離。TTA 也是其中一種后處理方法,在驗證階段對輸入圖片進行增強。本文使用TTA后處理進一步提高預測精確度,常見的流程是在驗證階段將輸入圖像進行多次旋轉、縮放、翻轉,然后依次預測,最后將預測結果進行特征融合得到最終的預測結果。對于比較小的醫學數據集,該方法很有效。本文對增強方法選擇翻轉加旋轉,因為胃癌病理圖像具有位置、形狀不固定的特點,通過翻轉和旋轉能大幅增加數據集的多樣性,解決容易過擬合的問題。特征融合方式選擇取平均。具體操作如圖4 所示。
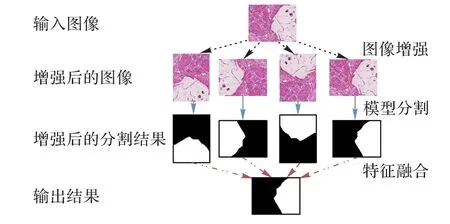
圖4 TTA后處理過程Fig.4 Procedure of TTA post-processing
2 實驗與結果分析
本文實驗的硬件環境:CPU 為Intel Xeon Gold 5218 CPU@ 2.30 GHz,GPU 為NVIDIA Tesla V100。實驗使用的PyTorch 版本為1.8.1,CUDA 版本為10.1。
2.1 數據集與預處理
SEED 數據集包含正常、管狀腺癌、黏液腺癌3 種類型共1 770 張樣本;BOT 數據集包含正常和病變兩種類型共700 張樣本。每一張圖像都有對應的分割蒙版,其中:0 代表正常區域;255 代表病變區域。PASCAL VOC 2012 有2 913 張語義分割圖片,訓練集和驗證集分別有1 464、1 449 張圖片,共有背景、人、飛機等21 類。
胃癌病理細胞一般具備以下特征:1)癌細胞的細胞核體積比較大,通常是正常細胞的5~10 倍;2)癌細胞的外形一般不規則;3)癌細胞細胞質減小,細胞核與細胞質面積之比增大。它們是判斷胃癌病理圖像中有無病變區域的重要因素。
數據集中有的圖像分辨率非常大,對比Patch 預測的結果與直接縮放到統一大小預測之后的結果,發現直接縮放的效果會好很多,所以在實驗過程中會將所有圖像統一縮放到512×512 大小。同時,因為CNN 對環境因素非常敏感,數據采集設備、光照、標注質量等都會影響最后的分割結果。為避免網絡模型出現訓練過擬合問題,在訓練前對數據進行增強,提高訓練集多樣性,從而提高網絡的魯棒性。在獲取圖像數據前,使用albumentations 庫對圖像進行隨機翻轉、隨機改變亮度、隨機改變對比度、隨機改變飽和度等操作,實際效果如圖5 所示。圖5(a)分別為原始圖與它對應的分割蒙版;圖5(b)分別為進行縮放和圖像增強后的訓練數據與它對應的分割蒙版,這樣訓練數據的多樣性將會大大增加,可以有效防止數據過少或者單一導致的過擬合問題。
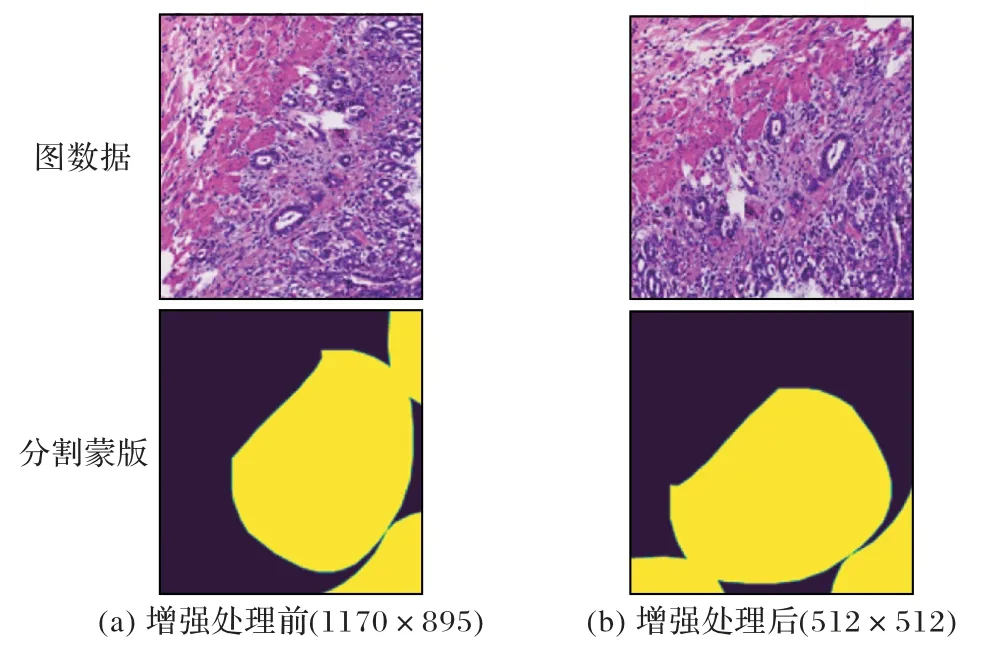
圖5 增強處理前后的對比Fig.5 Comparison before and after enhancement processing
2.2 實驗設置
平均交并比(Mean Intersection over Union,MIoU)是真實值和預測值兩個集合的交并比,能客觀地反映網絡分割結果的好壞。MIoU 的計算公式見式(9):
其中:pij表示真實值為i,被預測為j的像素數量;k是類別個數;pii是預測正確的數量。MIoU 一般都根據類來計算,將每一類的交并比(Intersection over Union,IoU)計算出來后累加,最后再除以類別數,就能得到全局的預測評價。MIoU 越高,分割圖像與分割蒙版重疊性越高,即分割效果越好。
本文首先通過消融實驗驗證每個模塊的有效性,接著使用DeepLabV3+[8]、U-Net[11]、U-Net++[14]等經典醫學分割模型與本文提出的EOU-Net 進行比較。
將數據集按8∶2 劃分為訓練集和驗證集,設定隨機種子為0 來保證數據集的一致性。在訓練過程中,訓練集的batch size 為12,驗證集的batch size 為1,損失函數為二值交叉熵損失函數,優化器為Adam 優化器,初始學習率為10-4,學習率的調整策略為每30 個epoch 之后將學習率減半,總共訓練250 個epoch,因為網絡使用EfficientNetV2 的ImageNet21k 的訓練權重進行遷移學習,所以初始學習率比較小,只需要根據新數據集進行微調便能達到很好的效果。訓練集和驗證集的MIoU 變化如圖6 所示。
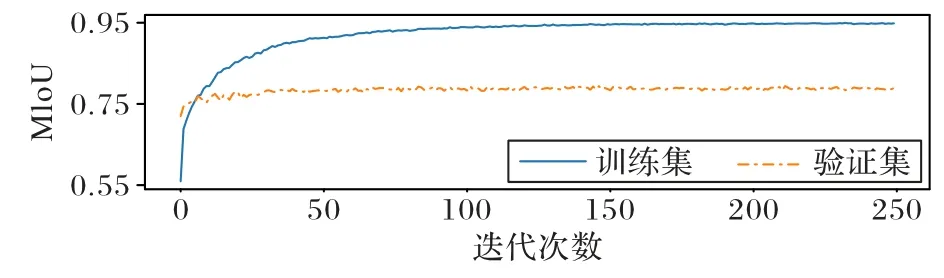
圖6 訓練集和驗證集的MIoU曲線Fig.6 MIoU curves for training and validation sets
2.3 實驗結果分析
2.3.1 消融實驗
為了驗證EOU-Net 各模塊的有效性,分別對各模塊進行消融實驗,具體結果如表2 所示。基線模型為使用了ImageNet 預訓練權重的EfficientNet 作為編碼器的U-Net。首先,將編碼器替換為使用了ImageNet 預訓練權重的EfficientNetV2 之后,MIoU 比U-Net 提高了0.50%;在解碼器上添加改進后的OCR 模塊后,MIoU 比U-Net 提高了0.87%;使用TTA 后處理,MIoU 比U-Net 提高了1.62%。由此可見,本文提出的模塊均能有效提升分割精度。
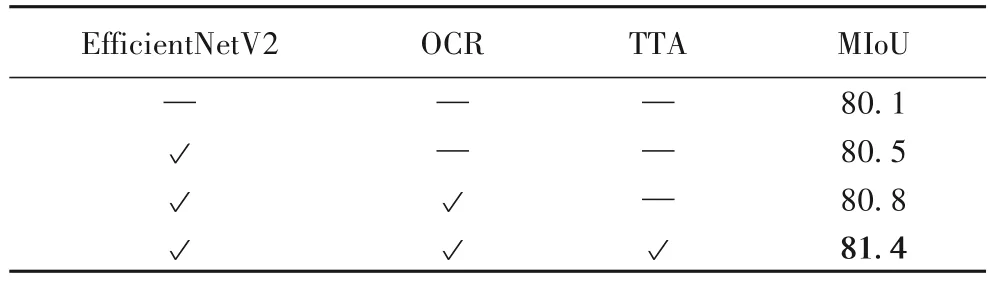
表2 EOU-Net消融實驗結果 單位:%Tab.2 Ablation experimental results of EOU-Net unit:%
為了更直觀地觀察各模塊的提升效果,隨機從驗證集中選出1 張圖片,并依次使用不同的網絡模型分割,具體結果如圖7 所示,Label 為人工標注結果。從圖7 中能更直觀地看出各模塊的有效性,將骨干特征提取網絡換成EfficientNetV2后,找到的病變區域更準確,說明網絡的特征提取能力確實有所提高;再加入改進后的OCR 模塊之后,也能明顯觀察到分割邊緣細節得到了優化;最后,TTA 后處理也能讓EOUNet 在面對不同的環境因素時,表現差異不會過大。
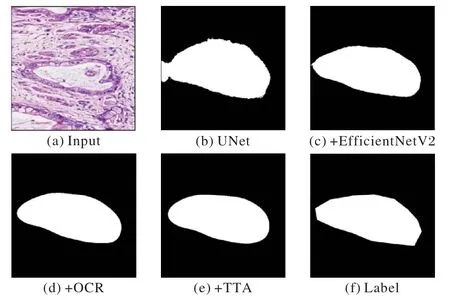
圖7 消融實驗可視化Fig.7 Visualization of ablation experiment
2.3.2 后處理方法對比實驗
本文以未添加TTA 后處理的EOU-Net 作為基礎模型,通過比較不同圖像增強和特征融合的TTA 模塊來找到最好的圖像增強方式和特征融合方式。圖像增強方法包括:水平垂直翻轉、水平翻轉、垂直翻轉以及水平垂直翻轉加旋轉。特征融合方式包括:平均、相加和幾何平均。同時,為了驗證本文的后處理方法在胃癌數據集中的有效性,將它與經典的DenseCRF-n(n代表算法迭代的次數)后處理方法進行比較,具體結果見表3。
由表3 可以看出,選擇水平垂直翻轉加旋轉的圖像增強方式效果最好;同時,平均和相加的特征融合方式效果相當,MIoU 基本沒有差別。實驗中效果最好的TTA 模塊與DeepLab 中的DenseCRF 后處理相比,MIoU 提升了1.10%。因為DenseCRF 算法要求分割區域的邊緣與周圍像素具有一定差異,所以并不適合特征復雜的醫學圖像,由此可見,本文的TTA 后處理優于經典后處理方法。
2.3.3 不同方法對比實驗
1)SEED 數據集對比實驗。
在SEED 數據集上將EOU-Net 與Att U-Net[15]、U-Net[11]、U-Net++[14]等經典網絡進行了比較,具體結果如表4 所示。Att R2U-Net[13]和Att U-Net 沒有使用ImageNet 預訓練的權重,因此,將未使用ImageNet 預訓練權重的EOU-Net 與這兩個模型進行比較。可以看出,OCRNet 的表現一般,MIoU 比EOU-Net 小1.8 個百分點,說明對于醫學分割還是U 型結構更通用。通過MIoU 和不同種類的IoU 結果可以發現,EOUNet 無論是正常區域還是病變區域分割結果都優于目前經典網絡模型。
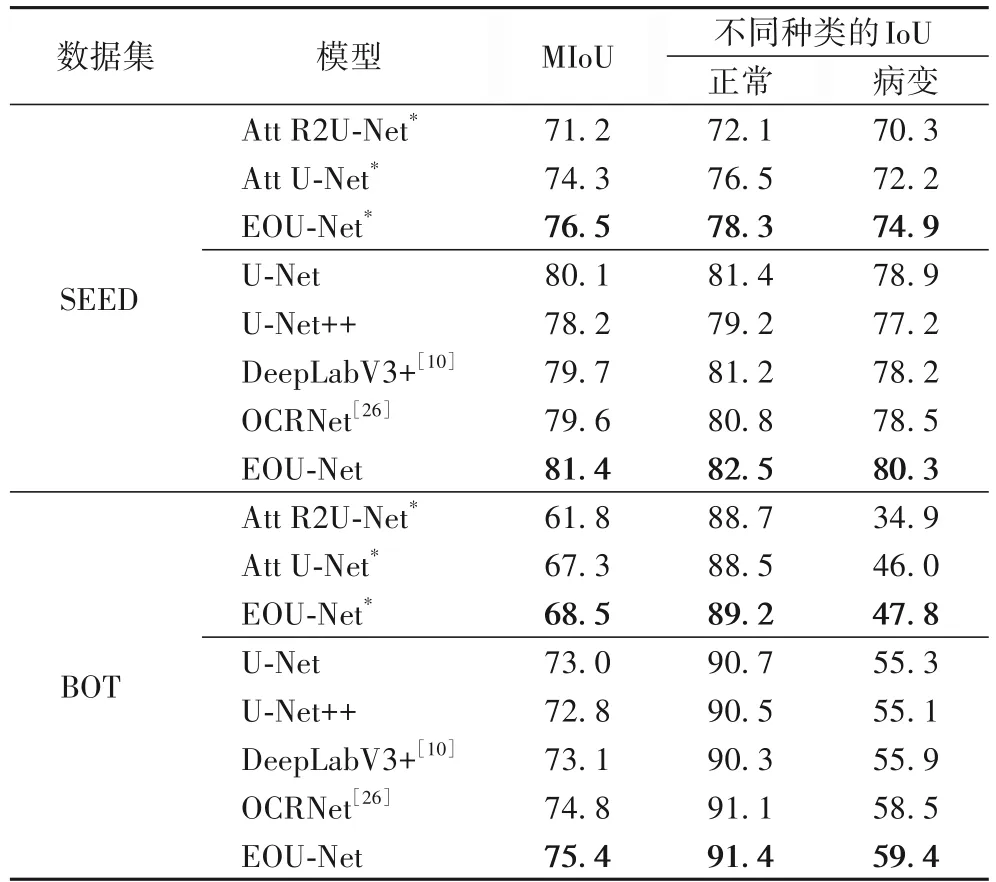
表4 SEED和BOT數據集上的對比實驗結果 單位:%Tab.4 Comparison experimental results on SEED and BOT datasets unit:%
2)BOT 數據集對比實驗。
為進一步驗證EOU-Net 的有效性,在BOT 數據集上進行實驗,結果見表4。實驗設置和SEED 數據集一致,因為BOT數據集的較多樣本病變區域占整張圖像比例較小,所以病變區域的IoU 普遍不高。但是,從MIoU 和不同種類的IoU 結果可以看出,EOU-Net 能有效提高胃癌病理圖片的分割結果,MIoU 比OCRNet 提高了0.6 個百分點。
為了更直觀地比較預測結果,隨機從驗證集中挑出4 張病理圖像,采用不同算法進行處理并顯示分割效果,如圖8所示。可以直觀地發現,面對特征比較復雜的胃癌病理圖像,EOU-Net 確實能更好地提取圖片中的病變區域以及處理邊緣信息,從而達到更好的分割結果。
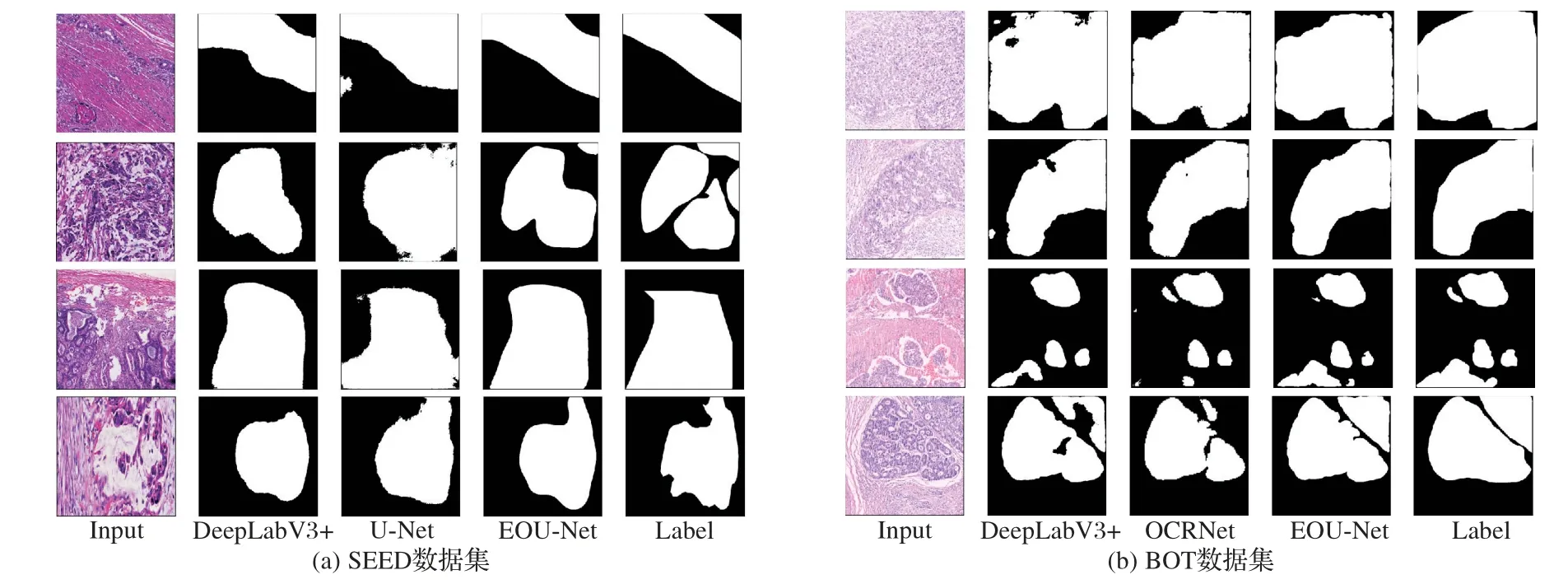
圖8 對比實驗可視化Fig.8 Visualization of comparison experiments
3)PASCAL VOC 2012 數據集對比實驗。
在PASCAL VOC 2012 數據集上驗證EOU-Net 在其他類型數據集上的表現,實驗結果見表5。可以看出,EOU-Net 在非醫學的數據集中的性能相較于經典網絡也有所提高。當種類數變多時,U-Net 的MIoU 很低;而EOU-Net 不僅沒有受太大影響,同時相較于OCRNet 有所提升,MIoU 提高了4.5個百分點。
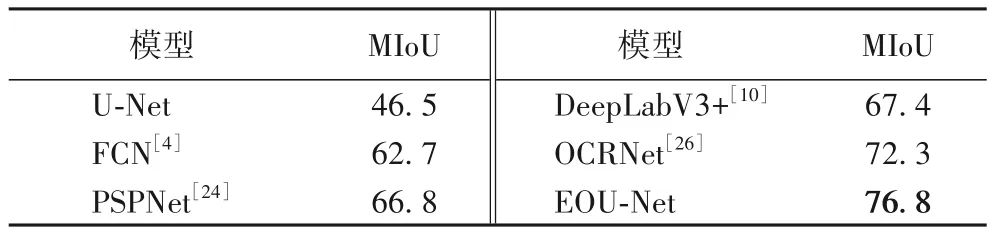
表5 PASCAL VOC 2012數據集上的對比結果 單位:%Tab.5 Comparison results on PASCAL VOC 2012 dataset unit:%
將EOU-Net、OCRNet 和DeepLabV3+進行可視化分割結果比較,如圖9 所示。從圖9 中也能更直觀地發現EOU-Net確實能通過提高邊緣分割精度從而提升網絡分割準確度。
3 結語
本文針對胃癌病理圖像特點,改進U-Net 模型的基本結構,提出了一種新的EOU-Net 模型。利用EfficientNetV2 的特征提取能力,使編碼器部分能更好地提取胃癌病理圖像復雜的病變特征;接著,通過改進后的OCR 模塊,讓網絡在上采樣階段基于物體上下文特征探索像素間的關系,從而得到更好的邊緣分割結果;最后,使用TTA 后處理方法,從多個旋轉角度分別對輸入圖像進行分割,解決了醫學圖像數據集普遍偏小、容易出現過擬合的問題。在SEED 病理圖像數據集、BOT 病理圖像數據集以及PASCAL VOC 2012 數據集上的結果表明,本文的EOU-Net 能夠有效提高網絡分割效果,MIoU分別達到了81.4%、75.4%和76.8%,能為醫生診斷提供輔助。然而,病理圖像之間分辨率的差距非常大,本文在訓練過程中將圖像尺寸統一縮放到512×512,導致很多特征沒有被充分利用,所以,未來準備在如何充分利用這些特征上作進一步研究。
猜你喜歡
今日農業(2020年20期)2020-12-15 15:53:19
電子制作(2019年15期)2019-08-27 01:12:00
能源(2018年10期)2018-12-08 08:02:48
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
能源(2016年10期)2016-02-28 11:33:30
中國衛生標準管理(2015年3期)2016-01-14 03:41:46
醫學研究雜志(2015年9期)2015-07-01 17:28:27
中國當代醫藥(2015年20期)2015-03-01 02:04:29
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:52
