基于空洞卷積的醫學圖像超分辨率重建算法
2023-09-27 06:31:58王雅婧馬巧梅
計算機應用 2023年9期
李 眾,王雅婧,馬巧梅*
(1.中北大學 軟件學院,太原 030051;2.山西省醫學影像人工智能工程技術研究中心(中北大學),太原 030051)
0 引言
隨著醫療影像技術的廣泛應用,醫學圖像已成為重要的醫學診斷輔助工具。通過超分辨率重建得到紋理細節豐富且清晰的醫學圖像既可以幫助醫生更清楚地判斷病例的早期病變,也可以避免通過增加掃描次數或掃描時間的方式取得高分辨率醫學圖像,造成成本高昂、輻射過量的問題[1]。
醫學圖像超分辨率(Super-Resolution,SR)重建指通過對低分辨率(Low Resolution,LR)醫學圖像的一系列操作,生成高分辨率(High-Resolution,HR)圖像的過程。基于插值的超分辨率重建算法[2]簡單有效、容易實現,但重建后的圖像容易存在邊緣模糊的問題。基于重構的方法[3]需要先驗信息對結果進行約束,重建的紋理邊緣比插值法更清晰,但容易出現先驗信息不足的問題。基于深度學習的方法則利用卷積神經網絡(Convolutional Neural Network,CNN)獲取LR 與HR 間的映射關系,是近幾年來學者研究的熱點。Dong 等[4]提出的基于CNN 的圖像超分辨率(Super-Resolution CNN,SRCNN)算法是在圖像超分領域運用深度學習方法的首次嘗試,使用3 個卷積層便能有效提取圖像內部的特征,并取得優于其他算法的重建效果。Kim 等[5]提出VDSR(Very Deep convolutional networks Super-Resolution)超分模型,利用殘差加速網絡收斂,提高了超分算法性能,但增加了計算的復雜度,并且可能引發梯度消失問題。Lim 等[6]提出EDSR(Enhanced Deep residual network for Super-Resolution)模型,通過堆疊大量殘差單元增加網絡深度以提升重建效果,但堆疊的殘差網絡使總參數量激增,計算成本加大。Chollet[7]提出了深度可分離卷積,利用一個深度卷積和一個點卷積代替標準卷積,實現通道空間區域的獨立運算,可有效減小參數量,提升計算效率。單一的感受野對網絡中的各層做簡單的鏈式堆疊,對特征提取不充分,無法保證神經網絡的魯棒性與泛化性。Chen 等[8]提出了空洞卷積(Dilated Convolution,DC),對普通卷積注入空洞,擴大感受野,捕獲圖像更多的信息且不給網絡增加額外的參數,可以在重建中取得較好效果。胡雪影等[9]在殘差學習的基礎上引入空洞卷積,對卷積的感受野起到了提升作用,并且提升了網絡優化速度,但對于奇數放大倍數來說表現不佳。注意力機制最早是用于解決自然語言處理問題,Woo 等[10]通過對通道信息和空間信息的融合,提出了CBAM(Convolutional Block Attention Module)增強特征中重要信息的表達,但無法捕獲不同尺度的空間信息,容易造成特征全局信息的丟失。張曄等[11]提出基于多通道注意力機制的圖像超分辨率網絡,引入多通道注意力模塊對圖像紋理進行信息提取,提升了生成圖像的質量,但未考慮到圖像不同尺度間的信息差異。
隨著超分辨率重建在醫學領域應用的不斷深入,基于深度學習的醫學圖像超分辨率重建算法也取得了顯著進展。Zhang 等[12]在2017 年提出了一種基于深度學習和遷移學習的單張醫學圖像超分辨率重建方法,通過對醫學圖像的不同特征進行共享,提高模型泛化能力,相較于其他醫學圖像重建算法取得了更好的重建效果。基于殘差學習的思想,Wang 等[13]于2019 年提出了一種使用三維CNN 提高計算機斷層掃描(Computed Tomography,CT)圖像分辨率的算法,在保證圖像重建質量的同時提高了計算效率。高媛等[14]提出了一種基于深度可分離卷積和寬殘差網絡的醫學圖像超分辨率重建方法,大幅降低了網絡參數量。Chen 等[15]提出了反饋自適應加權密集網絡(Feedback Adaptively Weighted Dense Network,FAWDN),利用反饋機制和自適應加權策略,使網絡專注于信息量大的特征,從而提高醫學圖像質量。2021 年Qiu 等[16]提出了一個多重改進殘差網絡(Multiple Improved Residual Network,MIRN),結合幾個不同深度的殘差塊,使模型可以專注于醫學圖像的細節恢復并且有效避免了迭代后醫學圖像過度平滑的問題,但對于含豐富病理信息的醫學圖像重建效果較差。
相較于自然圖像,醫學圖像存在大量的細小紋理且往往伴隨許多無用信息,例如由病人器官律動造成的陰影和噪聲斑點等,這要求重建算法的效果更加精確。并且醫學圖像相較于自然圖像更注重主觀視覺感受,無法單純從評價指標的角度衡量圖像質量,因此重建出符合醫生感官的醫學圖像更有助于模型的實際應用。目前已有的研究大多采用單一尺度提取圖像特征,對于醫學圖像中的細節還原度欠佳,而且在醫學圖像中邊緣部分是醫療診斷中的重要信息。為此,本文提出一種基于空洞可分離卷積(Dilation Separable Convolution,DSC)與改進的混合注意力機制的醫學圖像超分網絡,突出了醫學圖像重建細節與邊緣部分,在提升重建效果的同時盡可能降低網絡參數量。主要工作如下:
1)在深層特征提取階段將可分離卷積與不同空洞率的空洞卷積相結合,利用空洞率不同的三個并行空洞卷積,提升不同尺度特征表達,獲取不同感受野下的全局信息。
2)引入融合邊緣特征的通道注意力機制與使用大感受野的空間注意力機制,增強圖像在通道與空間維度的特征表達。
1 相關工作
1.1 殘差學習
經典的CNN 在信息傳遞時會存在信息丟失、梯度消失等問題。He 等[17]將殘差結構引入深度神經網絡,通過增加跳躍連接將梯度由淺層傳遞到深層部分,使得梯度在反向傳播時得到保留,從而使網絡的訓練更加穩定。普通網絡結構與殘差網絡結構對比如圖1 所示。
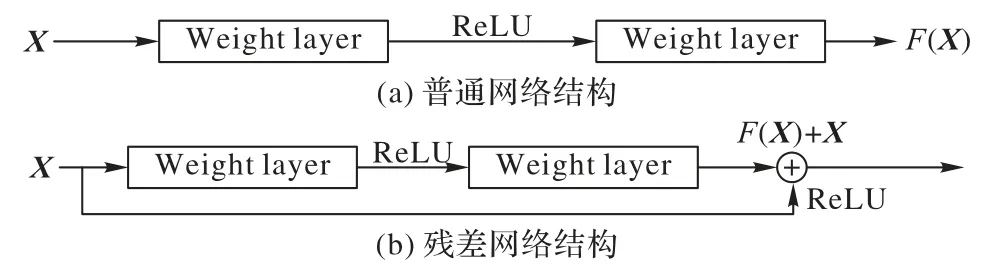
圖1 普通網絡與殘差網絡的結構對比Fig.1 Comparison of ordinary network structure and residual network structure
相較于普通網絡結構,殘差網絡結構在網絡中添加直接連接,在網絡的輸出部分直接添加輸入X的映射,學習輸入與輸出之的殘差。殘差模塊保留了輸入的原始信息,加深網絡層數,減少原始特征的流失。本文算法的網絡基礎結構基于深度殘差網絡,引入跳躍連接將所提取的不同程度的圖像信息連接起來,隨著訓練深度的增加而額外獲得增益。
1.2 深度可分離卷積
深度可分離卷積是CNN 中的一種卷積操作,相較于傳統卷積操作在所有輸入和輸出通道之間進行卷積計算導致參數量極大,深度可分離卷積能有效減小模型參數和計算量,提高網絡效率。深度可分離卷積的過程如圖2 所示,分為逐通道卷積和逐點卷積兩部分。
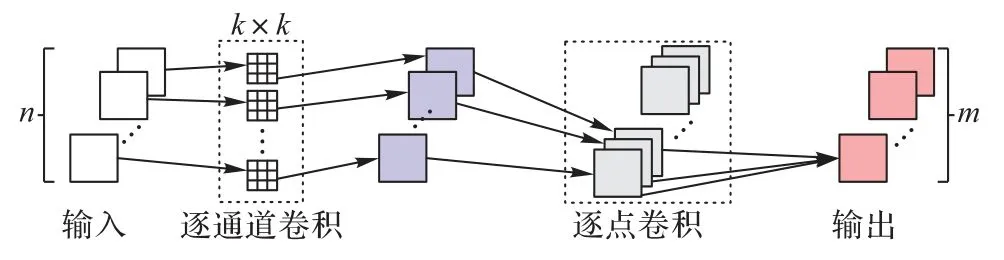
圖2 深度可分離卷積過程Fig.2 Depthwise separable convolution process
令輸入為n個通道特征圖,首先在各特征圖上分別進行k×k卷積,并將得到的n個特征圖依次輸出,再與m個1×l 的卷積核進行卷積,最終輸出m個特征圖。逐通道卷積用來提取空間的平面特征,只在通道內部進行卷積,而不對各通道間信息進行融合;逐點卷積則負責通道間的特征融合。假設輸入為N×H×W的特征,卷積核大小為k×k,輸出特征為M×H×W。令標準卷積的參數量為P1:
深度可分離卷積的參數量為P2:
因此,深度可分離卷積的參數量和標準卷積的參數量之比如式(3)所示:
由式(3)可知,深度可分離卷積的使用能大幅降低模型參數量。因此,本文使用深度可分離卷積代替標準卷積操作,在不損害模型性能的前提下降低網絡參數量。
1.3 醫學圖像基礎
醫學圖像包括CT、磁共振(Magnetic Resonance,MR)、正電子發射斷層掃描(Positron Emission Tomography,PET)圖像等多種圖像,本文主要采用CT 圖像進行實驗分析。
CT 成像是一種結合X 射線成像與計算機技術的成像技術,能獲得更詳細的斷層影像,多用于檢查頭顱、脊柱、胸腹部等部位。CT 采集的HU(HoUnfield)值為射線衰減值,根據圖像的HU 值可以區分肺、血液、骨骼和其他組織器官。
提高CT 圖像分辨率的主要方法是通過靜脈碘造影劑注射,使目標部位造影劑濃度升高,從而獲取高分辨率影像。然而,注射造影劑可能會產生一些潛在的副作用,使用超分辨率重建算法來提高醫學圖像分辨率是一種更加無創的方法,可以在提高醫生診斷能力的同時減少患者因注射造影劑帶來的潛在風險。
2 本文算法
本文構建了一種基于空洞可分離卷積的醫學圖像超分辨率重建算法,整體結構如圖3 所示。
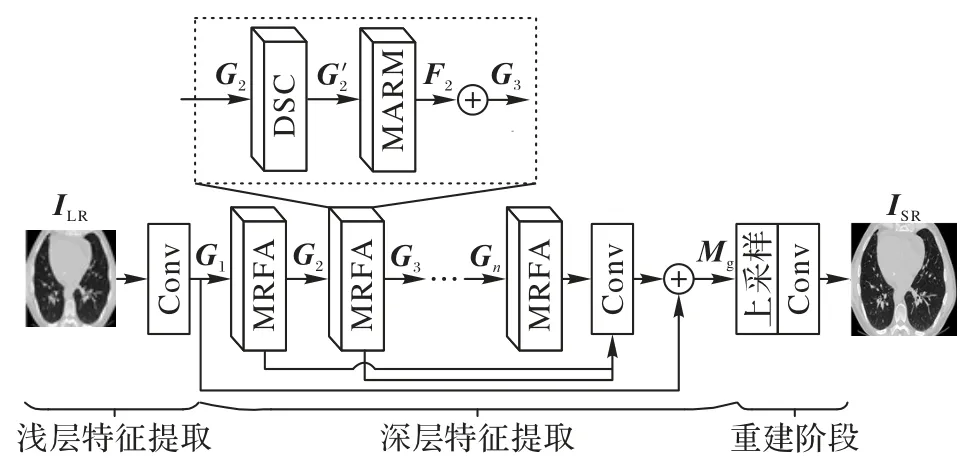
圖3 本文算法的結構Fig.3 Structure of the proposed algorithm
本文算法的網絡主要由淺層特征提取、深層特征提取、圖像重建三部分組成。淺層特征提取部分利用一層3×3 卷積對輸入的圖像進行通道變換,提取淺層特征G1,具體過程如式(4)所示:
其中:ILR為輸入的低分辨率圖像;Conv3×3為核大小為3×3 的卷積運算。
在深層特征提取階段,將淺層特征G1輸入到X個由空洞可分離卷積(DSC)模塊與混合注意力模塊(Mixed Attention Residual Module,MARM)串聯而成的多感受野注意力(Multi-Receptive Field Attention,MRFA)模塊,提取目標在不同尺度下的中間與高頻特征,并對提取的特征圖進行通道融合,生成深層特征Mg。過程如式(5)所示。
其中:Hg(*)為MRFA 模塊的特征提取過程;concat 為特征融合操作。
重建階段首先通過亞像素卷積對融合后的特征圖進行上采樣,再使用3×3 卷積得到最終重建圖像,如式(6)所示:
其中:Hu(*)表示圖像重建操作;ISR為超分辨率重建圖像。
2.1 DSC模塊
醫學圖像細節更豐富,紋理更復雜,往往包含了許多不同尺度的細節信息。常見的圖像超分辨率網絡往往只關注單一尺度的圖像信息而忽視了不同尺度間的信息融合。針對上述問題,本文提出了DSC 模塊,結合不同空洞率下的空洞卷積與深度可分離卷積,獲取圖像局部和全局特征信息,如圖4 所示,其中:D表示空洞率,C表示輸入通道數。
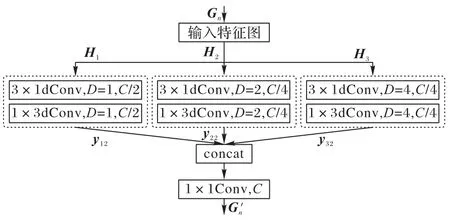
圖4 空洞可分離卷積模塊的結構Fig.4 Structure of dilation separable convolution module
在空洞卷積中,鄰近像素是通過對相互獨立的子集卷積得到的,相互之間缺少相關性;因此使用單一空洞率的空洞卷積容易導致圖像局部信息的丟失,造成網格效應。不同的空洞率有利于提取不同層次的圖像特征,為此本文采用多尺度空洞率融合的方法提升網絡的特征表達性能。
首先,將輸入的特征圖Gn分為三個分支Hl(l=1,2,3),為保證圖像特征信息的完整性,緩解因空洞卷積操作引起的網格效應,使用3×3 大小的深度可分離卷積對第一個分支的通道特征進行提取,另外兩分支使用不同空洞率的空洞可分離卷積代替3×3 的可分離卷積,為網絡提供不同的感受野大小,幫助網絡更好地提取圖像特征。整個過程如式(7)所示:
最后,采用concat 和一個1×1 卷積對所提取特征進行融合與降維,輸出結果如式(8)所示:
2.2 MARM
圖像經過淺層特征提取后,各個部分往往表達不同特征,但這些特征都保持著相同權重,而沒有考慮不同特征之間重要程度的區別,不利于突出目標的特征信息。神經網絡中添加注意力機制可以使模型注重于感興趣的區域,聚焦重要特征的提取。在使用注意力機制進行特征提取過程中需要關注以下2 個問題:1)圖像的每個通道都含有大量的低頻與高頻信息分量,高頻分量往往含有許多邊緣信息,因此在對高低頻信息進行區分與整合過程中需要額外關注邊緣信息的重要程度。2)注意力機制中的濾波器往往只能接收局部信息。為了使模塊能夠關注到特征圖全局信息,需要提高模塊對于不同尺度特征的關注程度。
針對上述問題,本文改進的混合注意力模塊的結構如圖5 所示。

圖5 改進的混合注意力模塊的結構Fig.5 Structure of improved mixed attention residual module
針對本文1.1 節獲得的特征圖像,使用改進的MARM,選擇性地獲取圖像低頻與高頻信息。MARM 利用跳躍連接降低網絡優化難度,緩解梯度消失問題,將提出的邊緣通道注意力模塊(Edge Channel Attention Module,ECAM)與改進的空間注意力模塊(Improved Spatial Attention Module,ISAM)串聯,進一步提取圖像特征。計算過程如式(9)所示:
2.2.1 ECAM
通道注意力可使網絡在訓練中對含有不同豐富度信息的通道賦予不同的關注度,將資源盡可能地分配在信息更豐富的通道,提升網絡性能[18]。而對于醫學圖像,圖像邊緣有助于區分器官結構邊界,是輔助醫生診斷的重要因素之一。因此,利用特征圖邊緣信息的豐富程度對各通道所占權重進行分配,可使特征圖中的紋理細節在通道層面被充分利用。圖6 為邊緣通道注意力模塊。
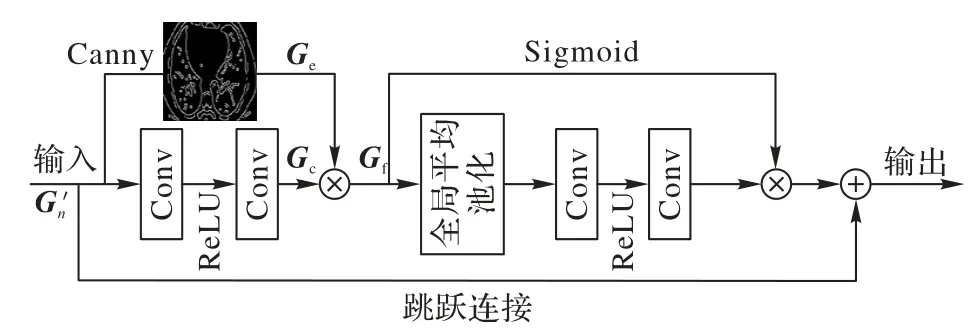
圖6 邊緣通道注意力模塊的結構Fig.6 Structure of edge channel attention module
使用Canny 邊緣檢測算法[19]對輸入特征圖進行邊緣提取,與經過卷積操作的特征圖Gc進行乘法聚合操作,得到邊緣增強后的特征圖Gf。整個過程可如式(10)所示。
其中,Canny(*)表示Canny 邊緣檢測算子。Gf經全局平均池化獲得整體特征信息,Sigmoid 函數分配各通道權重,從而使最終特征在通道上增強對邊緣信息的關注。通過跳躍連接將輸入的初始特征圖與網絡底層連接進行殘差學習,以降低網絡訓練難度。
2.2.2 ISAM
空間注意力是指在計算卷積特征圖時,根據輸入的特征圖的不同位置賦予不同權重的技術。相較于通道注意力,空間注意力側重于提取空間位置信息。通過對特征圖進行空間維度的信息提取,加強網絡對圖像細節部分的學習,從而對通道注意力模塊忽略的信息進行補充。改進的空間注意力模塊如圖7 所示。
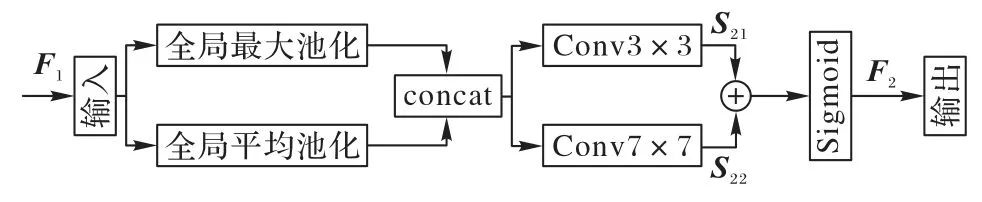
圖7 改進的空間注意力模塊的結構Fig.7 Structure of improved spatial attention module
將前一階段的輸出作為本模塊的輸入,利用平均池化和最大池化得到兩個不同信息表示的特征圖,并對兩個特征圖進行拼接。空間注意力機制中,更大的感受野可以增強全局信息提取能力,因此,改進的空間注意力機制設置3×3、7×7,步長為1 的兩種不同的卷積核,對特征圖信息進行捕捉,通過對應位置相加的方式將生成的兩種特征圖S21、S22進行融合,之后使用Sigmoid 激活函數生成最終的空間注意力特征圖。整個過程如式(11)所示:
其中:σ為Sigmoid 激活函數;⊕表示加和操作;f3×3、f7×7表示卷積核為3×3、7×7 的卷積操作。
2.3 損失函數
2.3.1 像素損失
大多數基于深度學習的超分算法使用像素損失作為模型的損失函數,主要包括L1、L2 損失函數[20-21]。L1 損失衡量的是預測結果和真實結果差的絕對值之和,而L2 損失則衡量的是預測結果和真實結果的平方差之和。相較于L2 損失,L1 損失函數對離群值更加敏感,因此會使得重建圖像的紋理和細節更加清晰且L1 損失的梯度相對于L2 損失更加穩定,這意味著L1 損失更容易收斂,訓練過程更加穩定,不容易陷入局部最優解。L1 損失函數定義如式(12)所示:
其中:θ表示模型的參數集;n表示訓練輸入的圖像塊數量;(f*)表示本章提出的超分辨率網絡表示第i個低分辨率醫學圖像與對應的高分辨率圖像。
2.3.2 感知損失
感知損失在網絡中針對特征圖細節進行計算,比像素損失更符合人體視覺感知[22]。感知損失函數分別將重建圖像y'與真實高分辨率圖像y輸入到預先訓練好的圖像分類網絡,提取一組盡可能相似的特征計算歐氏距離,借助VGG-16[23]結構,用全連接層前最后一個卷積層的輸出作為特征。定義φ(?)表示特征提取操作。損失函數Le如式(13)所示:
2.3.3 整體損失函數
為提高重建圖像的清晰度,降低模糊圖像對模型性能的影響,本文將L1 損失與感知損失結合,作為整個網絡的損失函數,可表示為:
其中,α、1 -α為兩項損失的平衡權值。為比較α的取值對實驗結果的影響,使用L2R2022 醫學圖像配準比賽中的肺部圖像數據集L2R2022-CT(https://learn2reg.grand-challenge.org/learn2reg-2022/)進行2 倍放大對比實驗。
首先使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)作為客觀評價指標,對結果進行評估,如圖8 所示。
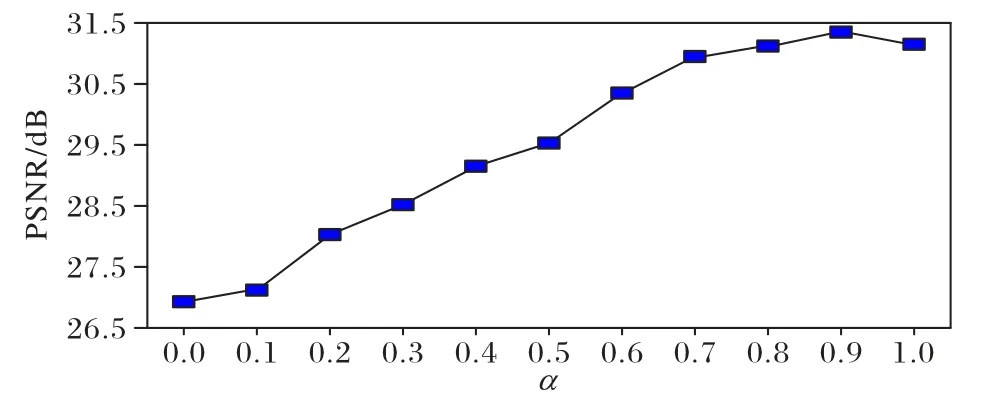
圖8 不同α 下的PSNR對比Fig.8 Comparison of PSNR under different α
由圖8 可知,當α=0 時整體損失函數完全由感知函數組成,即L=Le,此時重建圖像的PSNR 值為最低。當α處于[0,0.9]內評價指標PSNR 值遞增,并在α=0.9 時達到最高值31.35 dB。而當α=1 時L=L(θ),整體損失將由L1 損失得出,此時PSNR 相較于之前有所下降。
為進一步探討α取值對圖像重建效果的影響,本文分別對α=0,0.9,1 時的重建圖像進行直觀對比,結果如圖9所示。

圖9 不同權值重建圖像的直觀對比Fig.9 Visual comparison of reconstructed images with different weights
通過對比可以看出:α=0 時重建圖像最模糊;而α=0.9時重建圖像效果最佳,且相較于α=1 時的重建圖像擁有更加清晰的邊緣與完整的結構。這符合圖8 所示的PSNR 變化趨勢,綜合PSNR 與主觀圖像對比分析,當α=0.9 時模型重建效果最佳,因此本文設置平衡權值α為0.9 進行下述實驗。
3 實驗與結果分析
3.1 實驗設置
本文實驗數據采用L2R2022 醫學圖像配準比賽中的肺部CT 圖像數據集以及癌癥基因組圖譜(The Cancer Genome Atlas,TCGA)(https://www.cancer.gov/ccg/research/genomesequencing/tcga)中的腹部CT 圖像。各取2 400、1 100 張細節紋理豐富、清晰度高的圖像按照4∶1 的比例劃分為訓練集A、B 與測試集A、B。準備階段使用下采樣方式由原始圖像生成低分辨率圖像,并將它一一配對用于后續實驗。圖10展示了其中的兩組圖像對,分別表示原始高分辨率(HR)圖像與低分辨率(LR)圖像。
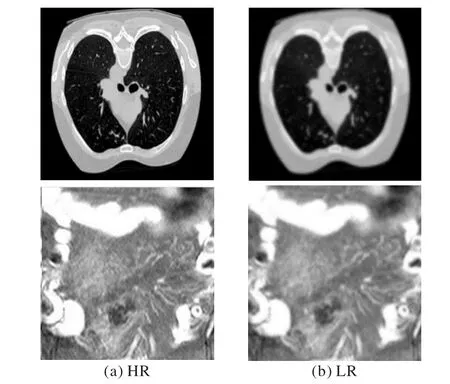
圖10 原始數據樣本Fig.10 Raw data samples
實驗環境如下:Intel Core i7-8750H CPU @ 2.20 GHz,GPU 為NVIDIA Quadro RTX,內存24 GB,Python 3.8.3,深度學習框架為PyTorch 1.4.0,CUDA 版本為10.1。batch size 為16。采用Adam 算法進行優化,相關參數β1=0.9,β2=0.999,?=10-8,初始學習率為0.000 1,每訓練200 個epoch 學習率減半。采用PSNR 和結構相似性(Structural Similarity Index Measure,SSIM)作為客觀評價指標。PSNR 反映圖像失真水平,數值越高表示重建質量越好。SSIM 主要評估圖像之間的相似性,數值越接近1 則重建的圖像越接近原始圖像。
3.2 實驗與結果分析
3.2.1 MRFA模塊數量分析
本文使用MRFA 模塊進行深層特征提取,當MRFA 模塊數量X發生改變時,重建出的圖像質量也會隨之改變。為探討網絡中MRFA 模塊數量對重建圖像峰值信噪比的影響,本節基于測試集A 在2 倍放大下對重建效果進行分析。圖11為不同MRFA 模塊數下的性能對比。
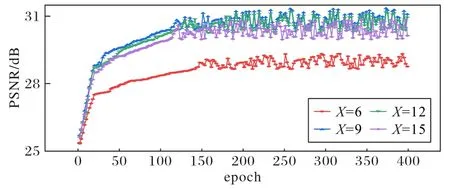
圖11 不同MRFA模塊數的PSNR對比Fig.11 Comparison of PSNR with different MRFA module numbers
由圖11 可知,MRFA 模塊數量X的取值不同,重建圖像的PSNR 指標也有所區別。當X=9 時,重建圖像的PSNR 值最高,因此本文取MRFA 模塊為9 進行下述實驗。
3.2.2 消融實驗
為驗證本文算法中各模塊性能,對DSC 模塊、ECAM、普通通道注意力(Channel Attention,CA)模塊、傳統的空間注意力模塊(SAM)、ISAM 在測試集A 中進行2 倍放大的消融實驗。首先僅使用DSC 模塊進行深層特征提取,之后在此基礎上引入ECAM 對不同通道間信息進行增強,通過對DSC+SAM 模塊與DSC+ISAM 模塊的重建性能對比,探討特征的空間位置信息,最后將三個模塊級聯,對比分析各模塊對圖像超分重建性能的作用。實驗結果如表1 所示。
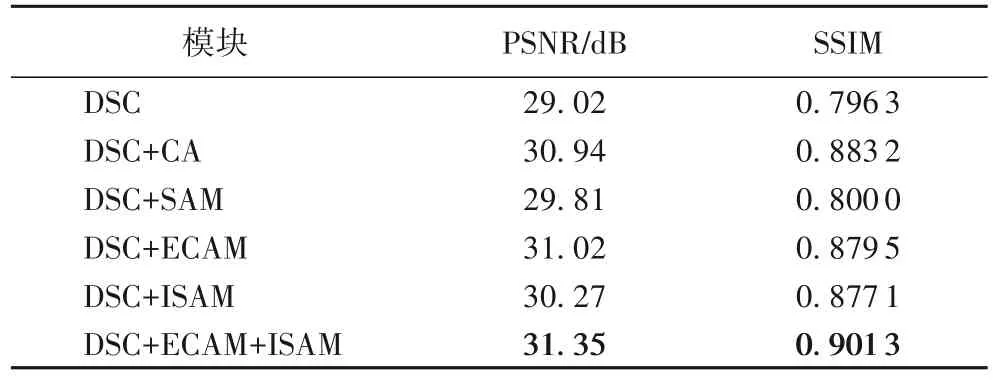
表1 不同模塊的重建性能比較Tab.1 Comparison of reconstruction performance of different modules
由表1 可知,結合DSC 模塊與ECAM 的圖像重建效果優于DSC 模塊與CA 相結合的結果。而相較于其他組合方式,DSC、ECAM 與改進的混合注意力模塊(ISAM)可以獲得更大的感受野與圖像通道與空間信息,使算法擁有更好的重建性能。
3.2.3 對比實驗分析
將本文算法與經典的超分辨算法Bicubic[24]、SRCNN[4]、FSRCNN(Fast SRCNN)[25]、VDSR[5]、基于殘差通道注意力的超分網絡RCAN[26]以及基于多尺度注意力殘差的重建網絡[27]、FAWDN[15]與MIRN[16]等具有代表性的超分辨率重建網絡分別在測試集上進行測試。結果如表2 所示。
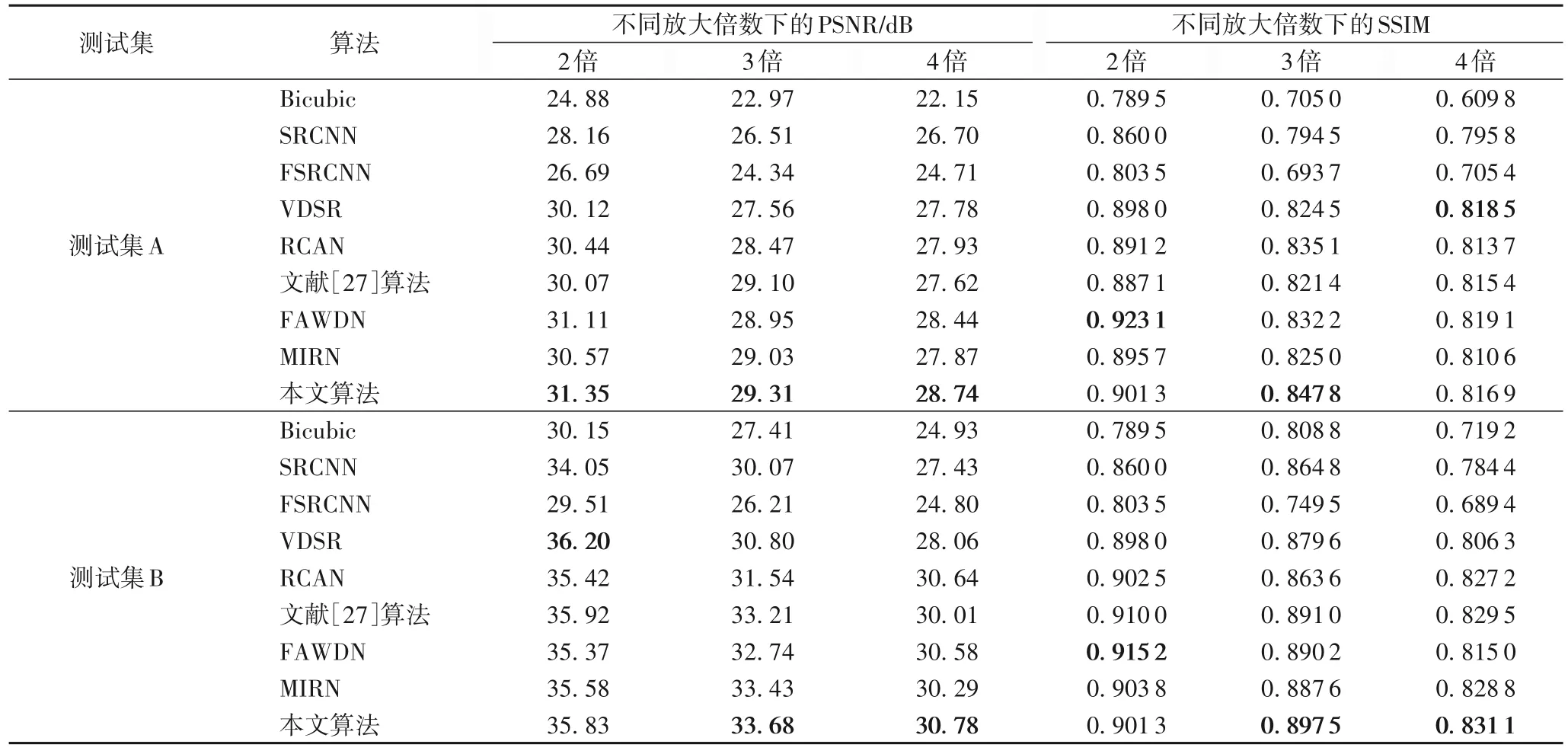
表2 不同算法的PSNR/SSIM值比較Tab.2 Comparison of PSNR/SSIM values of different algorithms
從表2 可以看出,本文算法在不同放大倍數下,在各數據集上均有良好表現。當放大倍數為3 時,與SRCNN、VDSR相比,本文算法的PSNR 平均提高了11.29%與7.85%;SSIM平均提高了5.25%和2.44%。可以看出,在各放大倍數下,本文算法均有一定提升,但是在放大倍數較大時PSNR 與SSIM 比放大倍數較小時更低,因此在今后的研究中將著力于解決放大倍數較高時的圖像重建問題。
圖12 展示了各算法在實驗所用數據集下的4 倍放大的重建效果。圖12(a)主要對各算法對圖像的整體還原能力進行對比。可以看出,不同算法對圖像還原程度不一,其中:文獻[27]算法相較于其他算法對LR 圖像質量有了一定提升,但在邊緣部分存在模糊現象;而本文算法則還原出了更加清晰的圖像邊緣,且擁有更加豐富的紋理信息。圖12(b)主要對比了細節放大下各算法的重建效果,對比發現,SRCNN、FSRCNN、VDSR 等對比算法均出現了不同程度的噪聲干擾,而本文算法還原的圖像最貼近于原始圖像,對于細節還原更加清晰。整體來說本文所提網絡訓練的圖像更加接近原始圖像,對比其他網絡,本文算法對圖像整體結構的復原更加完整,對邊緣紋理的還原度也更高;但相較于原始圖像,重建的清晰度仍有不足。
3.2.4 模型運行時間比較
重建模型的計算時間往往和網絡參數量與算法復雜度呈正相關,因此本文通過對各模型重建圖像的平均用時的比較來衡量算法復雜度。表3 為通過對50 組測試圖像的重建測試得到的不同重建算法重建圖像的平均用時。
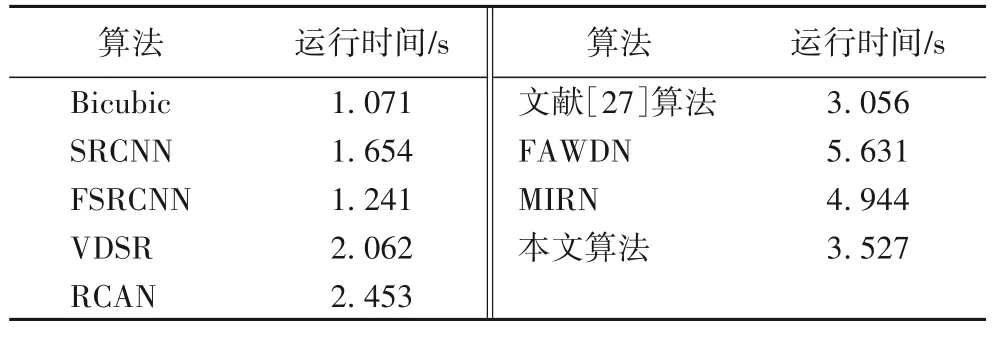
表3 不同算法重建圖像的平均用時Tab.3 Average time spent to reconstruct images by different algorithms
由表3 可知,網絡設計較為復雜的模型往往重建時間較長,且重建效果更佳的網絡往往也有著更長的重建用時。對重建時長較長的文獻[27]算法、FAWDN、MIRN 以及本文算法的重建效果進行對比得出,本文算法在不損失圖像重建精度的同時可以盡可能地縮短重建用時,且能在較復雜的結構設計下保持較高的重建效率。
4 結語
本文提出了一種基于空洞可分離卷積與改進的混合注意力機制的圖像超分辨率重建算法,解決了傳統超分辨率網絡對于圖像特征提取尺度單一、容易丟失邊緣及高頻細節的問題。使用空洞可分離卷積對圖像進行不同尺度特征提取,同時盡可能減少網絡參數量;使用改進的邊緣通道注意力結構,融合特征圖像的邊緣信息,將資源分配到信息更加豐富的部位;對于空間注意力機制,更大的卷積核可以擁有更強的全局信息提取能力,因此使用兩種不同大小卷積核,提取特征,生成最終空間注意力特征圖。同時結合像素損失與感知損失,設置一種更加適于人體視覺評價的復合損失函數作為整體損失函數,保證網絡收斂效果的同時使重建圖像更加符合視覺標準。通過對常用的幾種超分辨率重建算法與本文所提算法的對比分析驗證,本文算法在客觀評價指標方面有顯著提升,且可以獲得細節紋理更加清晰的重建圖像,驗證了本文算法在醫學圖像超分領域的準確性與實用性。本文算法在3、4 倍放大倍數下均可以獲得視覺效果更佳的重建圖像,然而目前臨床診斷越來越需要更大尺寸的醫學圖像進行輔助,因此在后期工作中會更加關注較大倍數下圖像還原能力,以及時間與資源的消耗問題,著重于構建細節紋理還原度更高且還原更加快速的超分網絡。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
