基于融合通道注意力的Uformer的CT圖像稀疏重建
2023-09-27 06:32:00陳蒙蒙喬志偉
計算機應用 2023年9期
陳蒙蒙,喬志偉
(山西大學 計算機與信息技術學院,太原 030006)
0 引言
計算機斷層成像(Computed Tomography,CT)是臨床上應用最廣泛的醫學成像模態,它是通過X 射線照射人體,將器官或組織投影至X 光片上供醫學分析與診斷的一種技術。然而,過高的X 射線會誘發人體產生癌癥等疾病。因此,為減少對病人的傷害,在稀疏角度下重建圖像非常有必要[1]。稀疏重建可以有效地減少輻射劑量,然而該方法重建出的圖像包含嚴重的條狀偽影[2],會影響對疾病的判讀。因此,高精度稀疏重建在醫學圖像領域具有重要價值。
近年來,卷積神經網絡(Convolutional Neural Network,CNN)憑借易于提取局部信息的優勢被廣泛應用。與此同時,許多用于圖像恢復的模塊被開發出來,包括編碼器-解碼器結構[3]、殘差學習[4]、注意力機制[5]、密集連接[6]、生成對抗機制[7]、多損失機制等。
將CNN 與上述模塊結合,誕生了很多新模型。Ronneberger 等[8]提出了U-Net,通過編碼器-解碼器結構,將整個網絡分為特征提取和特征融合兩部分,為醫學圖像重建領域提供了很好的借鑒作用。Jin 等[9]提出了FBPConvNet,將傳統的濾波反投影(Filtered BackProjection,FBP)[10]與殘差U-Net 結合起來,有效地抑制了條狀偽影。Chen 等[11]提出了殘差編碼-解碼卷積神經網絡(Residual Encoder-Decoder CNN,RED-CNN),借助殘差學習[12]削減了解碼過程帶來的信息丟失問題,在CT 稀疏重建任務中效果顯著。Momenta公司提出了SENet(Squeeze-and-Excitation Network)[13],通過在通道維度學習注意力分布,提升了網絡性能。Zhang 等[14]提出了DD-Net(Densenet and Deconvolution Network),充分發揮密集塊特征復用的優勢,并結合反卷積[15]操作大幅提升了CT 圖像重建網絡的性能。Wolterink 等[16]將生成對抗網絡(Generative Adversarial Network,GAN)應用于低劑量CT 圖像重建任務,取得了不錯的效果。
然而,圖像任務計算量大,且CNN 容易忽視圖像的全局信息。為了解決這一問題,受自然語言領域Transformer[17]的啟發,研究者們將它遷移至圖像任務中,提出了許多高效的算法。Dosovitskiy 等[18]提出了ViT(Vision Transformer)模型,將圖像切割成patch 序列,并直接應用Transformer 的編碼塊,在圖像分類任務中效果顯著。Huang 等[19]提出了CCNet(Criss-Cross Network),采用一種十字交叉的注意力機制降低計算量。Liu 等[20]提出了Swin Transformer,通過在不重疊的局部窗口內執行自注意力計算并采用移動窗口機制,極大地降低了計算的復雜度。Wang 等[21]提出了非局部操作算子,通過直接計算兩個空間位置的關系快速捕獲全局依賴。
與CNN 適合捕獲局部信息的性能不同,Transformer 更適合捕獲數據的遠程依賴關系。為進一步耦合二者的特性,Wang 等[22]提出了Uformer(U-shaped Transformer),通過卷積操作構建局部增強的Transformer 塊提升了網絡的局部依賴性。Peng 等[23]提出了特征耦合單元,通過設計CNN 與Transformer 雙分支結構,并以交互的方式來融合局部和全局特征。Yuan 等[24]提出了一種卷積增強圖像Transformer,在空間維度促進相鄰圖像塊之間的相關性,且模型達到收斂時并不需要大量的訓練數據和迭代次數。
因此,本文提出一種融合通道注意力的U 型Transformer(Channel Attention U-shaped Transformer,CA-Uformer)。該網絡具有以下幾個關鍵設計:1)U 型網絡框架。使用編碼器-解碼器結構學習多尺度上下文信息,并加入跳躍連接,輔助圖像特征融合。2)雙注意力結合。將通道注意力與Transformer 中的空間自注意力結合,通過對圖像每個部位賦予不同的權重,進一步細化傳入的特征。3)卷積替換Transformer 中的前向反饋層。CNN 在圖像任務中具有局部連接、權值共享、參數量少等優點。卷積操作能使網絡更好地捕獲局部上下文信息,與Transformer 易于捕獲全局信息的能力互補。
1 本文方法
本章首先介紹了CA-Uformer 的整體結構;之后,詳細說明了網絡中每個模塊的具體設計,包括通道注意力塊和Transformer 塊。
1.1 整體網絡結構
如圖1 所示,本文設計了一個編碼器-解碼器層次結構的U 型網絡,將整個網絡結構分為特征提取與特征融合兩個階段。在特征提取階段,首先將經過FBP 稀疏重建后帶條狀偽影的CT 圖像X∈R256×256×1作為輸入,通過3×3 卷積、批歸一化、帶泄露線性整流函數(Leaky Rectified Liner Unit,LeakyReLU)激活函數,提取淺層特征X0∈R256×256×32;隨后,X0被輸入到通道注意力層,從而學習到不同通道的權重信息;操作結果X~隨后被輸入到Transformer 編碼塊中。自注意力計算和卷積是本文Transformer 塊的關鍵操作。與一般方法不同,本文對獲得了通道權重的特征圖再進行空間自注意力計算,將通道與空間兩種維度相結合,能有效地提取到圖像更多的細節特征。執行通道注意力及Transformer 編碼塊操作前后不改變特征圖大小和通道數。
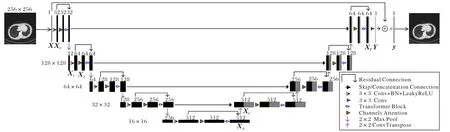
圖1 CA-Uformer的網絡結構Fig.1 Network structure of CA-Uformer
之后,本文將卷積操作得到的結果X0與Transformer 編碼塊的結果進行殘差連接,以充分利用圖像的原始細節信息。在這一層的最后,將殘差的結果輸入到下采樣,使用2×2 的最大池化使圖像大小減半,得到X1∈R128×128×32。X1再通過3 個相同的層,每個層都包含3×3 卷積、批歸一化、LeakyReLU、通道注意力塊、Transformer 編碼塊、殘差連接以及下采樣操作。在每一層,利用卷積操作改變圖像的通道數,如X1∈R128×128×32經過卷積之后得到X2∈R128×128×64。
在U 型結構底端,再次執行3×3 卷積、批歸一化、LeakyReLU、通道注意力塊、Transformer 編碼塊以及殘差操作,圖像大小變為16×16,更小的圖像尺度利于編碼塊捕獲到更長程的依賴關系。
在特征融合階段,首先進行卷積核大小為2×2,步長為2的反卷積操作來實現上采樣,作用是將特征通道數減半并將特征圖大小翻倍。此時特征圖XA∈R16×16×512經上采樣變為XB∈R32×32×256。之后,XB與編碼塊經殘差操作后對應的特征圖進行拼接得到XC∈R32×32×512。此處不再進行卷積操作改變圖像通道數,而是直接對拼接后的結果XC執行通道注意力和Transformer 解碼兩步操作,目的是復用更多的圖像信息。隨后,本文將拼接得到的結果XC與Transformer 解碼塊的結果進行殘差連接。類似地,特征圖再通過3 個相同的層,每層都包含上采樣、特征圖拼接、通道注意力塊、Transformer 解碼塊及殘差連接操作。在最后一層,本文使用3×3 的卷積將特征圖XP∈R256×256×64變為Y∈R256×256×1。再將Y與原始圖像X進行殘差連接,從而得到高精度輸出圖像y=X+Y。
實驗中,采用均方根誤差(Root Mean Square Error,RMSE)損失函數訓練CA-Uformer。
1.2 通道注意力塊結構
如圖2 所示,本文中通道注意力塊的操作主要分為壓縮與恢復兩部分。壓縮部分通過全局平均池化實現,將特征圖X0∈RH×W×C壓縮為X01∈R1×1×C,此時空間的信息都被壓縮到每個通道維度中。恢復部分包括全連接、線性整流函數(Rectified Linear Unit,ReLU)、全連接、Sigmoid。其中第一個全連接層通過縮小X01的通道數來降低維度,操作后的特征圖可表示為;第二個全連接層再恢復它的通道數與X01一致,本文采用r=16。最終將得到的權重矩陣與特征圖X0相乘,得到了具有各通道權重信息的通道特征圖
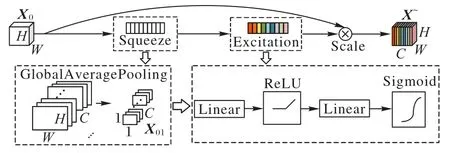
圖2 通道注意力塊結構Fig.2 Structure of channel attention block
1.3 Transformer塊結構
圖3 展示了Transformer 塊的總體結構。若給定Xl-1表示輸入,則Transformer 塊的大體操作可以表示為以下公式:

圖3 Transformer塊總體結構Fig.3 Overall structure of Transformer block
其中,Xa和Xl分別表示W/SW-MSA 層和Conv 層進行殘差操作后的輸出結果。
標準的Transformer 往往通過全局自注意力得到不同位置子空間的信息。而對于醫學圖像去偽影任務,在高分辨率特征圖上采用全局自注意力會大大增加計算復雜度。因此,本文采用劃分窗口的方法將自注意力計算限制在不重疊的窗口內,本質是在空間維度計算注意力,主要操作如圖3 虛線框內所示。首先進行劃分窗口操作,其次通過應用全連接層生成查詢Q(Query)、鍵K(Key)和值V(Value)三個矩陣,并引入了相對位置編碼。計算公式如下:
其中:d表示的維度;B表示相對位置編碼。此外,引入Dropout 層來提高模型的魯棒性。最后,對切割的窗口進行合并操作并加入移位窗口機制以增強窗口間的信息流動。
本文采用卷積替代標準Transformer 塊中的前向反饋操作來捕獲更多的圖像局部信息。如圖4 所示,本文設計了局部特征增強(Local Feature Enhancement,LFE)塊,首先應用3×3 卷積與GELU(Gaussian Error Linear Unit)將圖像的通道數擴大為原來的4 倍;之后,在擴大的通道維度上進行深度可分離卷積與GELU 激活函數操作,捕獲更多的圖像局部信息。其中,深度可分離卷積操作包括逐層卷積和逐點卷積兩部分,將輸入圖的每個通道分別應用一個3×3 卷積,然后再通過1×1 卷積融合各通道的信息;最后,再應用一個3×3 卷積將圖像通道數復原至與輸入通道相同。相比常規的卷積操作,深度可分離卷積可以降低參數量和運算成本,還可以把網絡訓練得更深,捕捉更多的細節信息。
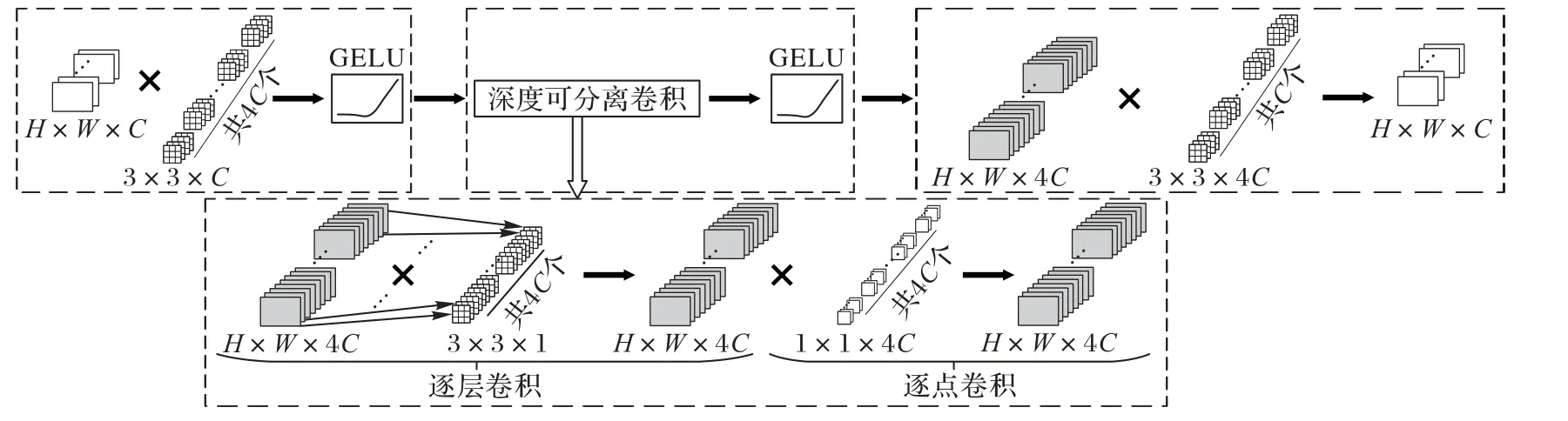
圖4 卷積實現的LFE塊的結構Fig.4 Structure of convolutional implemented LFE block
2 實驗與結果分析
本章首先介紹了數據集的構建以及實驗參數設置;之后通過對比不同算法以及不同稀疏角度數下網絡的性能,驗證了本文網絡在圖像去偽影任務中的有效性;最后,本文還進行了網絡結構內部規律的探索,在缺少某一模塊、模塊位置不同及LFE 塊不同實現方式的情況下進行實驗對比。
2.1 數據集的構建
本文的數據集下載自TCIA 數據集(https://www.cancerimagingarchive.net),從中選取了5 600 張包含頭部、胸部和腹部的高精度圖像。首先對高精度圖像進行radon 變換得到對應的稀疏投影圖像,再經過FBP 稀疏重建最終得到含條狀偽影圖像。本文將得到的含條狀偽影圖像作為輸入,將高精度圖像作為對應的標簽來訓練網絡。默認情況下均取60 個稀疏角度下的圖像對進行實驗。
下載的圖像中5 000 張作為訓練集,300 張作為驗證集,300 張作為測試集。輸入圖像大小為256 像素×256 像素。
2.2 網絡超參數設置
實驗中,窗口大小為8×8,訓練輪數為100,學習率為0.000 3,batch_size 為3。所有的對比實驗都采用同一組參數。實驗配置CPU:Inter Xeon CPU E5-2620 v4@2.10 GHz;GPU:NVIDIA Geforce GTX1080 Ti,基于PyTorch1.8.0 框架編寫,Python3.7.0 語言實現。
2.3 評價指標
本文采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、結構相似性(Structural SIMilarity,SSIM)及均方根誤差(RMSE)三個指標來評價網絡性能,計算公式如下:
其中:MAX表示圖像的最大灰度值;x表示網絡訓練得到的預測圖像;y表示標準的高精度圖像;μx表示x的均值;μy表示y的均值;表示x的方差表示y的方差;σxy表示xy的協方差;C1和C2是常數。
此外,為衡量算法復雜度,本文增加了參數量、浮點運算量以及重建時間3 個指標。最后,為了使數據結果更具有說服力,本文實驗部分的PSNR、SSIM、RMSE 以及重建時間都取測試集所得結果的均值,而參數量和浮點運算量則是針對模型本身。
2.4 實驗結果及分析
2.4.1 不同算法對比分析
為了驗證CA-Uformer 在圖像去偽影任務中的性能,本文選取了4 種利用CNN 的經典算法DnCNN[25]、RED-CNN[11]、U-Net[8]和FBPConvNet[9],以及一種結合Transformer 的新型算法Uformer[22]作為對比實驗,并對實驗結果進行分析。
在測試集中隨機選取一張腹部圖片,在不同算法下的重建結果如圖5 所示。將圖5(a)、(b)作為參考,可以發現:DnCNN 的重建圖帶有明顯偽影;RED-CNN 的重建圖中偽影有所減少,但仍然可以通過肉眼觀察到偽影的存在;U-Net 的重建圖已無法直接觀察到偽影,但是重建出的圖像過于平滑,圖像結構不明顯;在FBPConvNet 的重建圖與Uformer 的重建圖中,偽影明顯減少,并且圖像局部信息保留得更多,圖像的平滑現象有所緩和;在CA-Uformer 的重建圖中,圖像的結構信息與高精度圖已經非常接近,而且每一個局部組織之間界限分明。觀察圖5(h)中箭頭所指,CA-Uformer 重建出了非常細小的結構組織,而其他算法的重建結果都達不到如此精細。

圖5 不同算法的腹部重建結果Fig.5 Abdominal reconstruction results of different algorithms
表1 為測試集中的實驗結果對比。通過對比這些數值可以看出,Uformer 在對比算法中性能最好。與Uformer 相比,CA-Uformer 的PSNR、SSIM 提高了0.76 dB、0.31%,RMSE降低了8.33%;與經典的U-Net 相比,CA-Uformer 的PSNR、SSIM 提高了3.27 dB、3.14%,RMSE 降低了35.29%。此外,隨著算法模型的增大,參數量和浮點運算量也會增大,對比重建時間可以發現,前4 種算法相近,后2 種算法相近。實驗結果表明,雖然本文的CA-Uformer 模型比較大,但是性能最好、重建精度也最高,而本文的目的正是為了壓制條狀偽影,從而得到高精度圖像,因此這是有意義的。
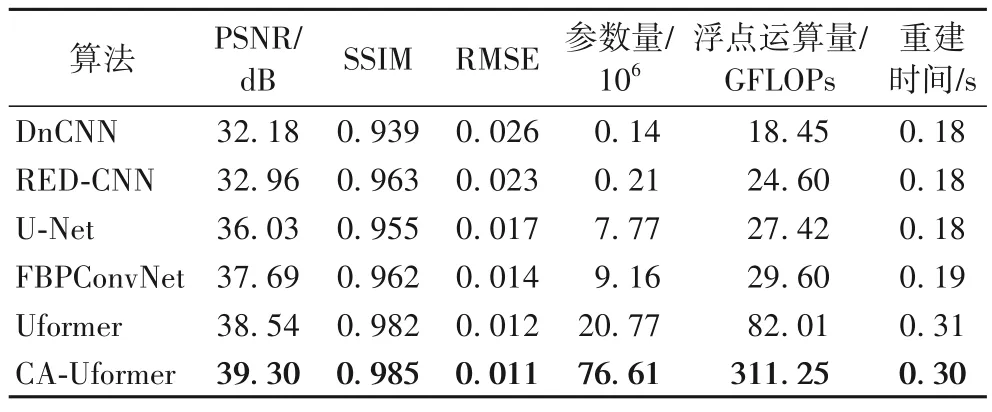
表1 不同算法在測試集上的實驗結果Tab.1 Experimental results of different algorithms on test set
2.4.2 不同稀疏角度個數對比分析
為了探索CA-Uformer 在不同稀疏角度下的性能,本文分別在15、30、60 和90 個稀疏角度下對高精度圖像經過radon變換及FBP 算法得到對應的含條狀偽影圖,并依次輸入到網絡中進行訓練,最后對重建結果進行分析。
本文在測試集中隨機選取了一張頭部圖片在不同稀疏角度數下的重建結果作為展示,如圖6 所示。可以發現,在15 個稀疏角度下的含條狀偽影圖(圖6(b))質量很差,最后重建出的結果(圖6(f))也丟失了很多的細節信息;在30 個稀疏角度時,圖6(g)保留了部分細節信息;在60 個稀疏角度時,觀察圖6(h)發現保留的細節信息明顯增多;在90 個稀疏角度時,圖6(i)中紋理及細節信息大部分被保留下來,圖像結構也更明顯。
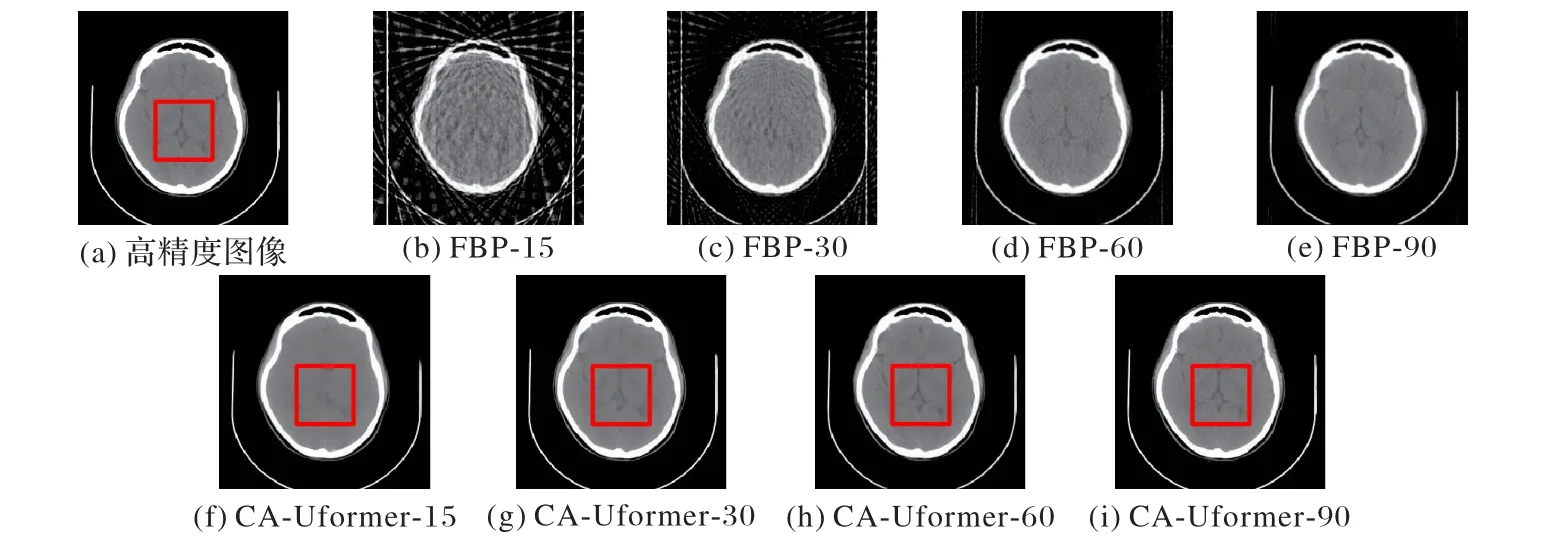
圖6 不同稀疏角度下頭部的重建結果圖Fig.6 Head reconstruction results under different sparse angles
定量的重建結果如表2 所示,表中數據均為測試結果的均值。由于該部分采用的算法均相同,因此不再將參數量、浮點運算量和重建時間作為評價指標。可以發現,90 個稀疏角度下重建出的圖像效果最好,PSNR、SSIM 和RMSE 都取得了最優的結果。實驗結果表明,稀疏角度數越少越不易于網絡的訓練;稀疏角度數越多則網絡訓練越容易。也就是說,隨著稀疏角度個數的增加,網絡去偽影能力越來越強。
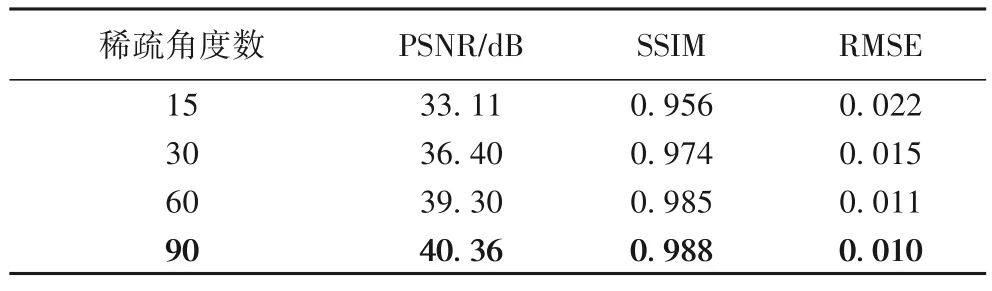
表2 不同稀疏角度數時測試集的實驗結果Tab.2 Experimental results on test set with different sparse angles
2.4.3 網絡結構內部規律探索
1)不同模塊對重建結果的影響。
為了充分說明網絡的內部機制對實驗性能的影響,本文分別在無通道注意力機制及無殘差機制下進行實驗,并與CA-Uformer 進行對比。
觀察圖7 中的重建結果及對應的放大圖,可以發現,無通道注意力(No-CA)的結果中仍存在部分偽影,且細節信息較為模糊;在圖7(c)與(d)中,各部位間的結構輪廓均不夠明顯,而在本文方法的重建結果中,能明顯觀察到各部位間的結構信息。
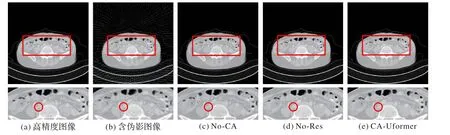
圖7 不同模塊的腹部重建結果Fig.7 Abdominal reconstruction results with different modules
表3 為測試集中的實驗結果。可以看出,三者的重建時間都相同。無通道注意力(No-CA)模塊會相應地減少參數量和浮點運算量,而無殘差機制(No-Res)幾乎不影響。與本文方法CA-Uformer 相比,無通道注意力的PSNR、SSIM 降低了2.86 dB、0.01,RMSE 增加了0.004;無殘差的PSNR、SSIM降低了0.47 dB、0.001,RMSE 增加了0.001。即無通道注意力的效果最差,無殘差的結果次之,本文方法最好。這表明通道注意力機制對實驗結果的影響最大,而殘差機制的影響較小。
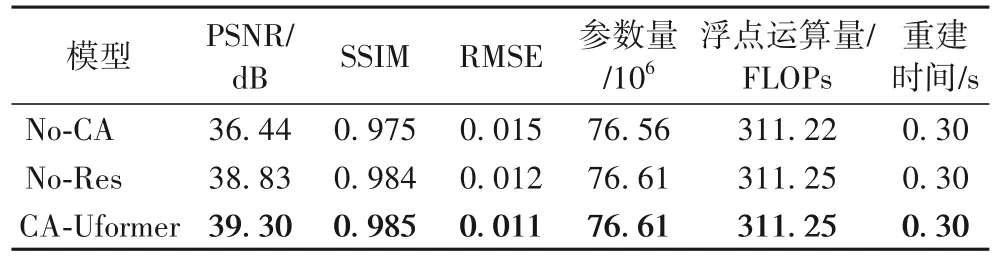
表3 不同模塊在測試集上的結果Tab.3 Results on test set with different modules
2)模塊位置不同對實驗的影響。
為了進一步探索通道注意力塊的擺放位置對實驗性能的影響,本文設計了3 種不同方式,如圖8 所示。CA-Identity表示同時執行Transformer 與通道注意力,并將二者操作的結果進行殘差連接;Transformer-CA 表示先執行Transformer 再執行通道注意力,之后在輸入與輸出之間加入殘差連接;圖8(c)是CA-Uformer 采用的方法,先執行通道注意力再執行Transformer,最后在輸入與輸出之間加入殘差連接。
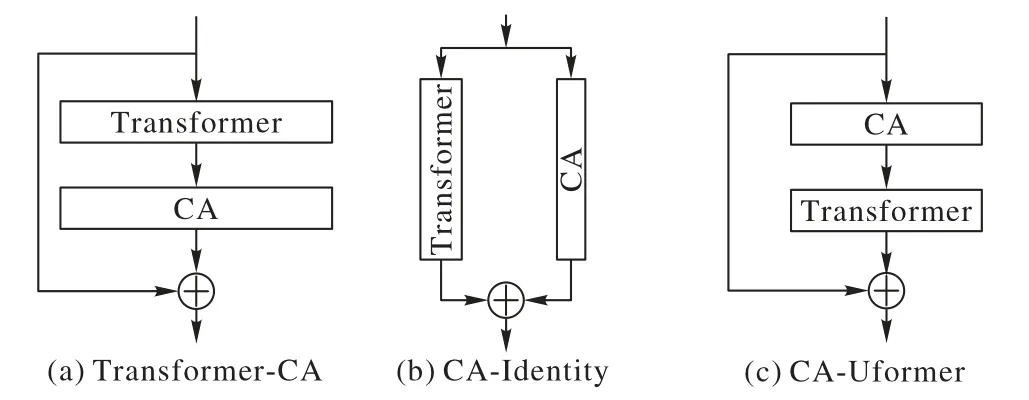
圖8 通道注意力塊的不同擺放位置示意圖Fig.8 Schematic diagram of different positions of channel attention blocks
圖9 為測試集中隨機選取一張肺部的重建結果。可以發現,3 種方式的去偽影性能相當,但是重建出的肺泡細節依次變多。
表4 為測試集中的實驗結果。由于只改變模塊位置,并未影響算法,因此參數量、浮點運算量和重建時間都相同。可以發現,與本文方法相比,CA-Identity 的PSNR、SSIM 降低了1.26 dB、0.001,RMSE 增加了0.002;Transformer-CA 的PSNR、SSIM 降低了0.73 dB、0.002,RMSE 提高了0.001。結果表明,本文先執行通道注意力提取通道維度的信息,再進行后續處理的方法有效提升了網絡性能,優先提取通道維信息更利于網絡學習到較多的圖像特征。
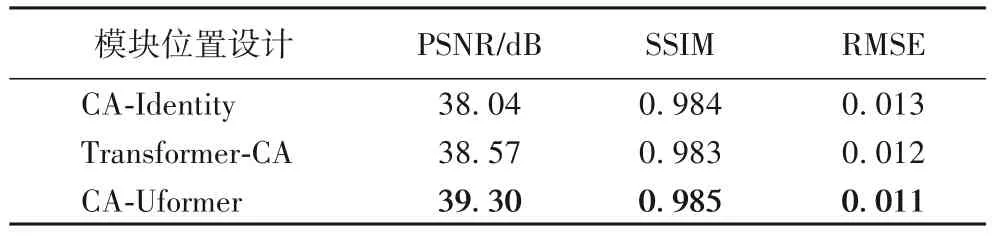
表4 模塊位置不同在測試集上的結果Tab.4 Results of different module positions on test set
3)LFE 塊的不同實現方式對實驗的影響。
為了更多地捕獲數據的局部特征,本文探索了LFE 塊不同的設計方式,包括多層感知機(Multi-Layer Perception,MLP),3×3 卷積、批歸一化、GELU(簡稱3×3Conv+BN+GELU),Uformer 中采用的局部增強的前向反饋網絡(Locallyenhanced Feed-Forward network,LeFF)以及本文采用的Conv,并對實驗結果進行分析。
如圖10 所示,MLP 的重建圖和3×3Conv+BN+GELU 的重建圖中仍存在部分偽影,LeFF 的重建圖中細節性有所增強。觀察箭頭所指以及紅色圓圈內圖像,可以發現本文方法的重建圖中細節信息更多。
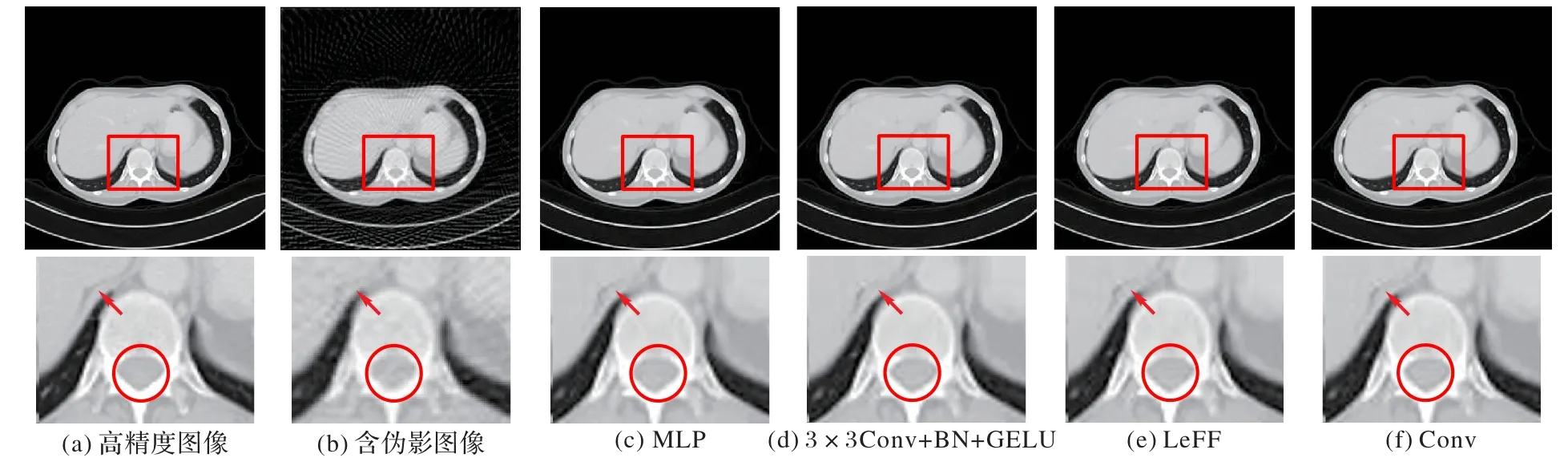
圖10 不同LFE塊的肺部重建結果及放大圖Fig.10 Lung reconstruction results and magnification with different LFE blocks
從表5 可以看出:LeFF 方法的PSNR 和RMSE 較好,MLP方法的SSIM 值較高;而本文采用的Conv 的PSNR、SSIM 及RMSE 取得了最優值,即本文方法的重建精度最高。比較參數量和浮點運算量可以發現,本文方法的指標最高,而重建時間相近。結果表明,本文利用卷積替代前向反饋層的方法能捕捉到更多的圖像細節信息。

表5 不同LFE塊在測試集上的結果Tab.5 Results of different LFE blocks on test set
3 結語
本文通過引入通道注意力機制,采用U 型架構,并利用CNN 與Transformer 的不同特性,提出了用于圖像去偽影任務的CA-Uformer 方法。CA-Uformer 在通道與空間兩種維度上進行注意力計算,進一步強調了有用信息;采用U 型架構融合了多尺度圖像信息;利用卷積操作捕獲更多的圖像局部信息,與Transformer 易于提取全局特征的能力進行耦合。這幾種機制的有效結合大幅提升了網絡的性能。
此外,通過不同方法的對比及對網絡結構內部規律的探索分析,驗證得出CA-Uformer 的網絡性能最優,它重建出的圖像不僅包含偽影最少,而且保留的圖像細節和結構信息更多,圖像精度也更高。
本文方法在圖像去偽影任務中表現出了強大的能力,未來將進一步探索其他模塊對性能的影響并考慮將它們應用到更多場景中。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
