基于數(shù)據(jù)挖掘和區(qū)塊鏈技術(shù)的碳排放信息定向提取模型
2023-09-28 02:08:56陳小鵬
工業(yè)加熱 2023年7期
陳小鵬
(國網(wǎng)山東省電力公司濱州供電公司,山東 濱州 256600)
碳排放信息可以為分析溫室氣體氣候變化,進而調(diào)整降低碳排放量提供幫助[1-3],研究碳排放信息定向提取具有重要意義。
許多相關(guān)學者對信息定向提取展開研究,如王一洲等[4]采用密度統(tǒng)計的方法,根據(jù)信息結(jié)構(gòu)特征對信息進行聚類,完成信息提取,但在面向大規(guī)模信息時具有局限性。如延安等[5]通過概念運算,獲取提取規(guī)則,但運算量較大且過于復(fù)雜,不具有全面性。
數(shù)據(jù)挖掘是用一種方法,從海量的數(shù)據(jù)中尋找隱藏的信息。區(qū)塊鏈技術(shù)由分布式信息存儲、傳輸、加密算法等計算機技術(shù)構(gòu)成。加密算法包括對稱和非對稱加密算法,區(qū)塊鏈中一般采用非對稱加密算法。
為此本文有效結(jié)合數(shù)據(jù)挖掘和區(qū)塊鏈技術(shù)提出一種定向提取碳排放信息的方法,在定向提取信息時,信息集屬性之間是相互獨立的,具有較高的穩(wěn)定性,可以處理多分類的信息,算法簡單,且具有普遍性,在信息有不同特征時,其性能不會出現(xiàn)大的不同。
1 碳排放信息定向提取模型
在設(shè)計碳排放信息定向提取模型時[6],主要從碳排放信息的使用、管理、安全性設(shè)計模型,在模型設(shè)計時,考慮數(shù)據(jù)傳遞、儲存,運用區(qū)塊鏈技術(shù)完成傳輸加密處理。本文采用MapReduce計算模式下樸素貝葉斯提取信息及同態(tài)加密的計算方法實現(xiàn)碳排放信息的提取和加密傳輸。碳排放信息定向提取模型結(jié)構(gòu)如圖1所示。
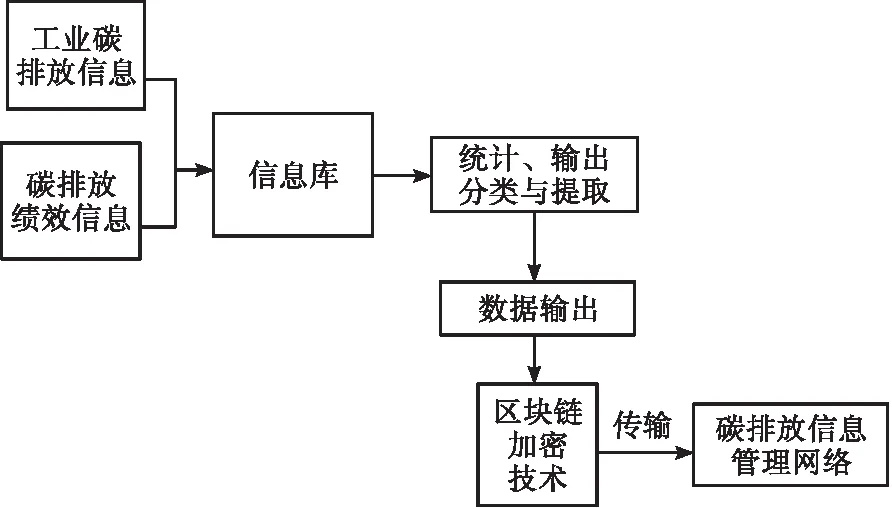
圖1 碳排放信息定向提取模型結(jié)構(gòu)
碳排放信息來源于工業(yè)碳排放及碳排放績效信息[7],構(gòu)建碳排放信息庫,通過數(shù)據(jù)挖掘技術(shù)對碳排放信息定向提取,運用區(qū)塊鏈進行加密傳輸,最終碳排放信息傳輸?shù)教寂欧判畔⒐芾砭W(wǎng)絡(luò),與管理者及用戶實現(xiàn)信息交互。
1.1 碳排放信息獲取
1.1.1 工業(yè)碳排放信息
工業(yè)碳排放信息由能源活動及生產(chǎn)的碳排放信息構(gòu)成[8],工業(yè)能源活動碳排放計算公式為
Hind-energy=∑Gi×∑HGi
(1)
(2)

工業(yè)生產(chǎn)碳排放Hco2計算公式為
(3)
1.1.2 碳排放績效信息
碳排放績效信息的獲取涉及多種指標,本文選取能源結(jié)構(gòu)、經(jīng)濟結(jié)構(gòu)等指標評估獲取碳排放績效信息。權(quán)重作為表述所有碳排放績效指標重要程度的變量[9],可表達出所有指標重要程度差異,因此為獲取碳排放績效信息,提出熵值法,通過全部碳排放績效指標傳輸?shù)焦芾碚叩男畔⒘看_認權(quán)重,信息熵是碳排放績效不確定性的度量,基于信息熵理論,熵值越小時,表示碳排放績效信息量和管理時的作用越大,其權(quán)重也越大。
設(shè)碳排放區(qū)域有n個,指標為m個,正向指標和逆向指標分別描述碳排放的綜合評價結(jié)果越好對碳排放績效的正效影響和負效影響越大,碳排放數(shù)據(jù)運用極值法標準化處理,減少指標不同單位的影響。碳排放績效指標矩陣如表1所示。
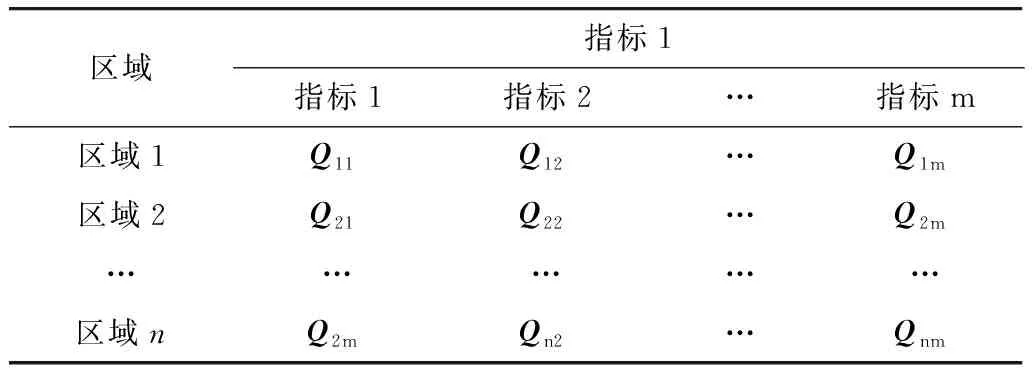
表1 碳排放績效指標矩陣
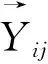
(i=1,2,…,n;j=1,2,…,,m)
(4)
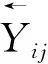
(i=1,2,…,n;j=1,2,…,m)
(5)
第j項指標在第i個區(qū)域在該指標所占的比重計算公式為
(6)
式中:Yij為碳排放績效指標;Sij為其所占比重;第j項指標的信息熵用bj表示,表達式如下:
(i=1,2,…,n;j=1,2,…,m)
(7)
運用熵值方法確定權(quán)重,權(quán)重vj計算公式為
(8)
線性加權(quán)求和公式表示為
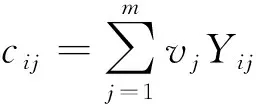
(9)
綜上可知計算權(quán)重流程如圖2所示。
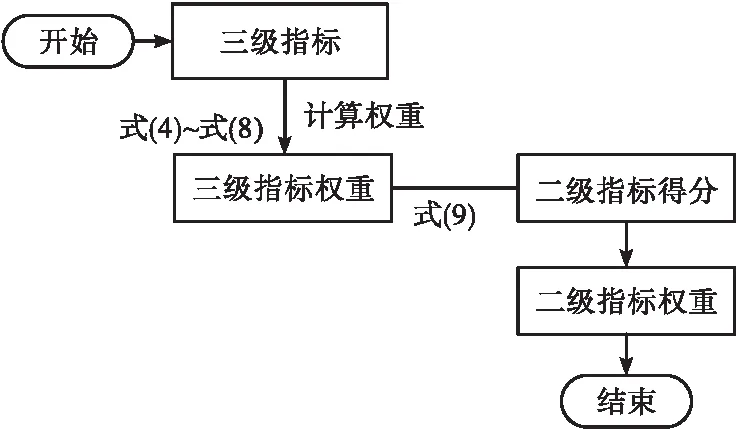
圖2 權(quán)重計算流程圖
1.2 碳排放信息的定向提取
根據(jù)工業(yè)碳排放信息和碳排放績效信息構(gòu)建的碳排放信息庫,提出樸素貝葉斯定向提取的方法[10-11],獲取碳排放信息待分類定向數(shù)據(jù)及其分配概率,實現(xiàn)碳排放信息的定向提取。對碳排放定向信息到最大分類概率的類別進行劃分,完成碳排放信息定向提取。
設(shè)碳排放信息類別F1,F2,…,Fm,類別的數(shù)量用m表示,所有碳排放信息相應(yīng)屬性數(shù)量用n表示,定向碳排放信息可用n+1維碳排放信息屬性向量R表達,定向碳排放信息R表達式為
R={r1,r2,…,rm,F}
(10)
待分類定向碳排放信息R′從屬于類別Fi的結(jié)果,滿足條件表述為
W(Fi|R′)|>W(Fj|R′),1≤j≤m,j≠i
(11)
對W(Fi|R′)進行最大化處理,令R′屬于Fi的概率比其余類別高,處理公式表示為
(12)
式中:W(R′)為常數(shù);W(Fi)推算公式為
(13)
W(R′|Fi)推算公式為
W(R′|Fi)=W(r′1|Fi)×W(r′2|Fi)×…×
W(r′n|Fi)
(14)
式中:數(shù)據(jù)庫A里的類別為Fi的訓練元組數(shù)用|Fi,A|表示。
如W(r′k|Fi)為計算目標,對其屬性ηk進行判定,在ηk處于離散狀態(tài)時,W(r′k|Fi)為屬性取在r′k的Fi類別元祖數(shù)量和全部定向碳排放信息Fi的元組數(shù)量的百分比,在ηk是連續(xù)狀態(tài)下,遵循高斯分布,其均值和標準差分別用λ及γ表示,W(r′k|Fi)界定表達公式為
(15)
式中:e為指數(shù)函數(shù),依據(jù)以上求解的最大概率類別,完成碳排放信息的定向分類及提取。
Map和Reduce函數(shù)并行推算下進行樸素貝葉斯定向提取,Main和Reduce函數(shù)描述如下:
Map函數(shù):定向信息id號和傳輸內(nèi)容分別是key和walue,熟知信息集里的定向信息及其屬性,如屬性屬于離散型,把定向碳排放信息類別的屬性取值數(shù)量求和,若屬于連續(xù)型,求解屬性取值總和及平方和,當前分片經(jīng)過遍歷、統(tǒng)計,將所得的定向提取信息結(jié)果進行輸出。
Reduce函數(shù):獲取Mapper的臨時提取信息,對離散型統(tǒng)計結(jié)果進行整理,得到概率,對于O個定向信息的連續(xù)屬性,如為平方和,利用以下公式求加屬性均值和標準差,計算公式分別為
(16)
(17)
對項目進行統(tǒng)計,對MapReduce程序輸出最終碳排放信息定向提取結(jié)果。
1.3 區(qū)塊鏈同態(tài)加密傳輸
根據(jù)1.2的提取到的碳排放信息,在信息傳輸過程中加入?yún)^(qū)塊鏈技術(shù),區(qū)塊鏈技術(shù)是一種利用分布式的數(shù)據(jù)儲存方法來進行信息的處理[12],并通過點到點傳輸、共識機制、加密算法等方法來完成信息的處理與運用。在本文的設(shè)計中,使用區(qū)塊鏈實現(xiàn)一個分布式的、沒有人管理的信息庫,其使用與傳統(tǒng)的管理員信息管理方法有很大的不同;將此技術(shù)用于定向提取碳排放信息的傳輸,節(jié)約大量的人力、物力。在區(qū)塊鏈技術(shù)中,引入一種加密算法,完成碳排放信息的加密和解密,如圖3所示。
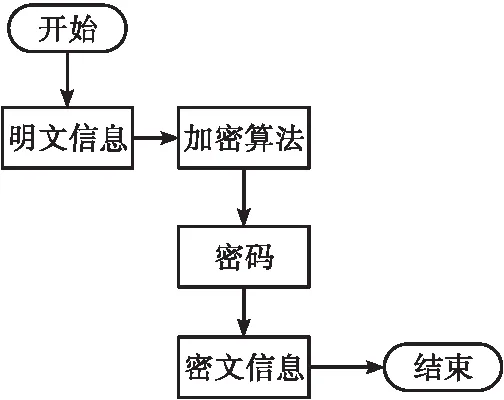
圖3 區(qū)塊鏈加密流程圖
利用同態(tài)加密算法實現(xiàn)碳排放信息加密[13-14],加密信息是以文字與數(shù)字構(gòu)成的記憶詞,使用者只有透過固定的記憶詞,方可獲得登錄密碼的數(shù)據(jù)。在加密時,利用解密進行運算,得到密碼信息。碳排放信息加密與解密處理時,對碳排放信息釋放進行設(shè)置,將釋放的信息置于內(nèi)存空間中;在實際使用時,它是以malloc功能為基礎(chǔ),隨著內(nèi)存的增大,碳排放信息被釋放,在釋放時,malloc調(diào)用時,獲取空閑空間,按照使用者的要求進行下一階段的輸出。它所能提供的信息的數(shù)量與所能提供的存儲空間是一樣的,所以它能有選擇地加密信息。
區(qū)塊鏈技術(shù)將定向提取的碳排放信息利用同態(tài)加密方法傳輸給管理網(wǎng)絡(luò)[15],保證傳輸信息的準確性,在Map函數(shù)分布計算中,不能將Mapper信息交互,用最終生成的中間結(jié)果,保證信息定向提取的獨立性,將定向提取的碳排放信息運用同態(tài)加密進行推算,利用代數(shù)推算,在相同的明文情況下操作信息代數(shù),完成加密碳排放定量提取的信息。把同態(tài)加密全過程設(shè)置成JK,加密過程通過生產(chǎn)密鑰、加密、解密及信息評估共4個環(huán)節(jié)構(gòu)成,4個環(huán)節(jié)分別表示為:KG、Enc、Decc及Eval,加密過程為
JK=(KG,Enc,Dec,Eval)
(18)
若AK和BK私鑰相互作用產(chǎn)生信息安全參數(shù),私鑰分別應(yīng)用加密及解密密文。設(shè)置明文U∈Sn,n表示整數(shù),Sn表示整數(shù)的集合。把明文U的同態(tài)加密用Xod(ι)表示,推算公式為
Xod(ι1+ι2)=Xod(ι1)⊕Xod(ι2)
(19)
式中:ι1、ι2為碳排放信息。
以上公式為碳排放信息的加密傳輸,傳輸完成后開展信息解密,利用私鑰解密密文υ,解密結(jié)果σ表示為
σ=Dec(υ,AK)
(20)
最終,評估解密結(jié)果完成碳排放定向提取信息的加密傳輸。若評估函數(shù)為ψ,密文設(shè)置為υ,評估密鑰用φ表示,評估算法運用φ的評估函數(shù)ψ開展評估,形成評估密文L,評估密文公式表示為
L=Eval(φ,ψ,υ)
(21)
基于以上公式,完成碳排放信息的同態(tài)加密傳輸,實現(xiàn)信息安全傳輸及保證信息的精準傳輸。
利用以上過程對碳排放信息加密處理,確保定向提取碳排放信息的正常傳輸,在信息傳輸過程中,加入IoT設(shè)備,運用不對稱加密的公鑰,把公鑰信息設(shè)置為129字節(jié)的加密信息。利用同態(tài)加密的路徑傳輸?shù)絉aft集群中,且對公鑰信息進行保存,利用私鑰解密,獲得ID號,連接信息防止緩存中及本文區(qū)塊鏈,完成信息傳輸。
2 實驗分析
以某地區(qū)碳排放管理中心為實驗對象,其中包含abalone、covtype、Data1和Data2四種碳排放信息集,采用本文方法在不同信息集下定向提取碳排放信息。碳排放信息集數(shù)據(jù)見表2。
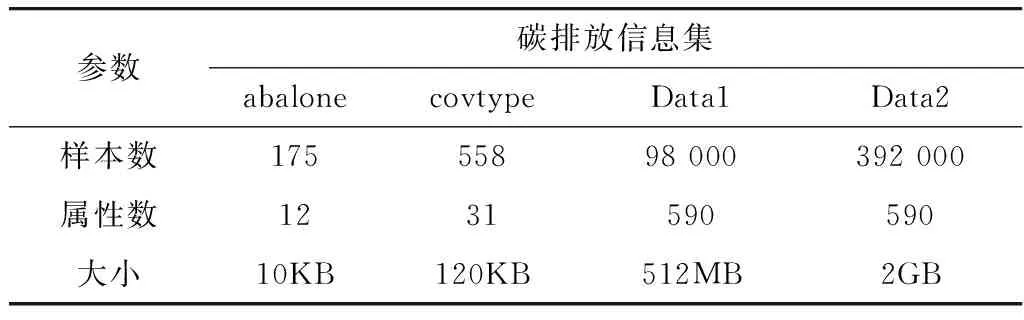
表2 實驗數(shù)據(jù)
設(shè)置集群節(jié)點數(shù)分別為2、6、10、16個,在不同集群節(jié)點數(shù)量下,測試本文方法的從不同碳排放信息集中定向提取碳排放信息的速度,測試結(jié)果如圖4所示。
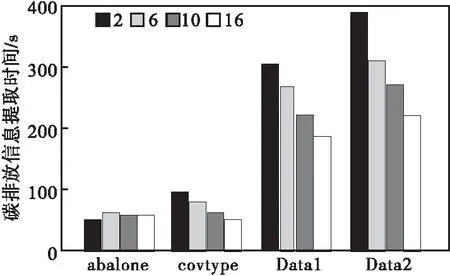
圖4 碳排放提取時間變化圖
由圖4可知,集群節(jié)點數(shù)量不同情況下,碳排放信息集abalone、covtype的定向提取時間整體變化波動不大,整體表現(xiàn)為平穩(wěn)趨勢,原因在于這兩個碳排放信息集數(shù)據(jù)量較小,信息定向提取效率受集群節(jié)點數(shù)量影響較小;碳排放信息集Data1和Data2的定向提取出時間受集群節(jié)點數(shù)量影響較大,集群節(jié)點數(shù)量越多提取效率越快。實驗證明本文模型在大規(guī)模的碳排放信息定向提取效率方面具有明顯優(yōu)勢。
為驗證本文模型定向提取碳排放信息的加密效果,以從Data2碳排放信息集中提取的包含的A、B、C、D、E及F區(qū)域的定向碳排放信息為實驗對象,6個區(qū)定向提取的原始信息如表3所示,用本文模型同態(tài)加密結(jié)果如表4所示。
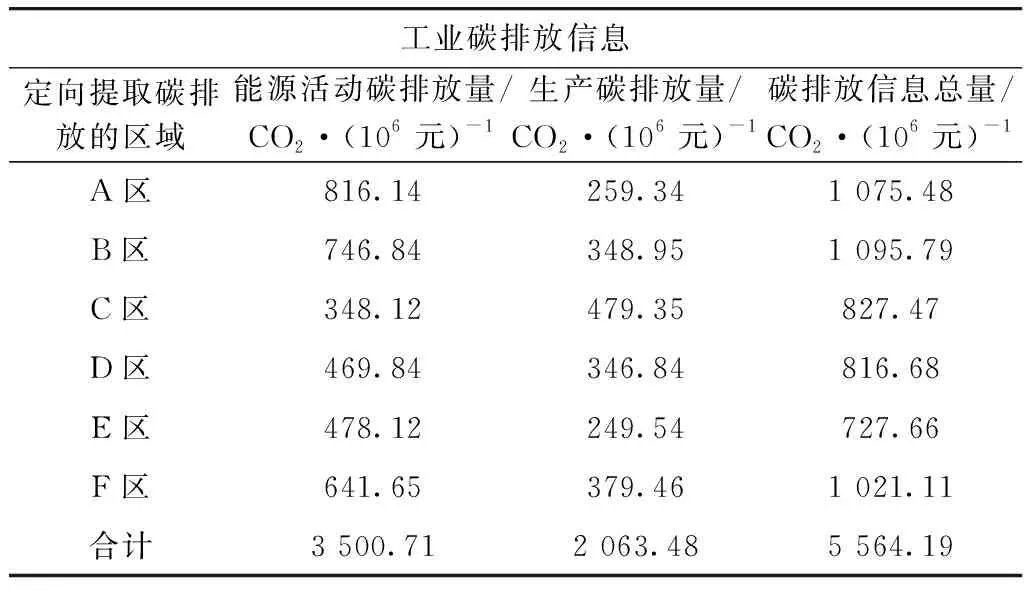
表3 6個區(qū)定向提取碳排放信息的原始數(shù)據(jù)
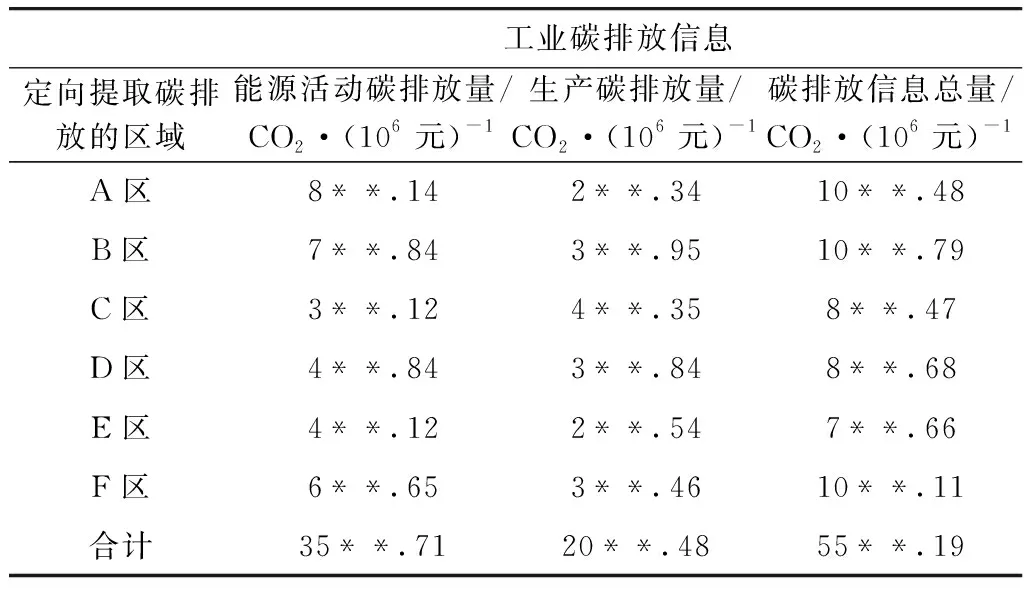
表4 6個區(qū)定向提取碳排放信息加密結(jié)果
由表3和表4可知,本文模型應(yīng)用后,可實現(xiàn)6個地區(qū)的碳排放信息數(shù)據(jù)的加密處理,6個區(qū)所有碳排放量數(shù)值中間兩位顯示為*,未出現(xiàn)定向提取碳排放信息的加密遺漏現(xiàn)象,可有效保障定向碳排放信息輸出安全性。實驗結(jié)果表明,本文模型對碳排放信息的加密效果好,可保護碳排放信息的安全傳輸,避免出現(xiàn)在傳輸過程中碳排放信息泄露的現(xiàn)象。
在企業(yè)碳排放信息管理系統(tǒng)中,用本文模型定向提取某地區(qū)企業(yè)每年的碳排放申報信息,如圖5所示。
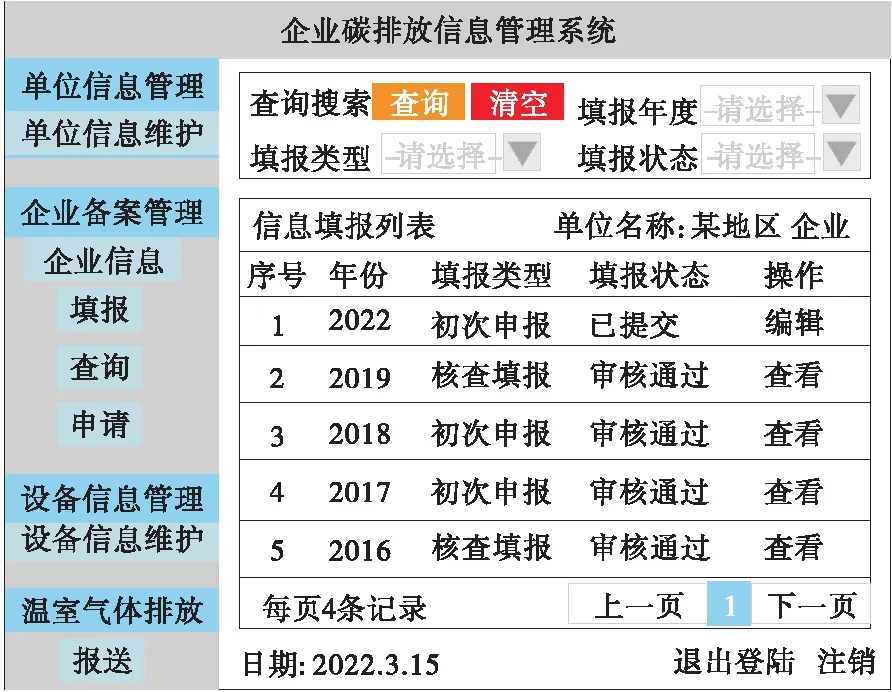
圖5 企業(yè)碳排放信息提取結(jié)果展示
由圖5可知,提取某地企業(yè)從2016年—2022年碳排放申報信息。填報類型分為初次填報和核查申報,2016年—2019年的填報狀態(tài)均已審核通過,2022年的已填交狀態(tài),可編輯操作。
將文獻[4]方法、文獻[5]方法作為本文方法的對比方法,測試三種方法在數(shù)據(jù)量不同的情況下,進行數(shù)據(jù)挖掘時所需的時間,分析結(jié)果如圖6所示。
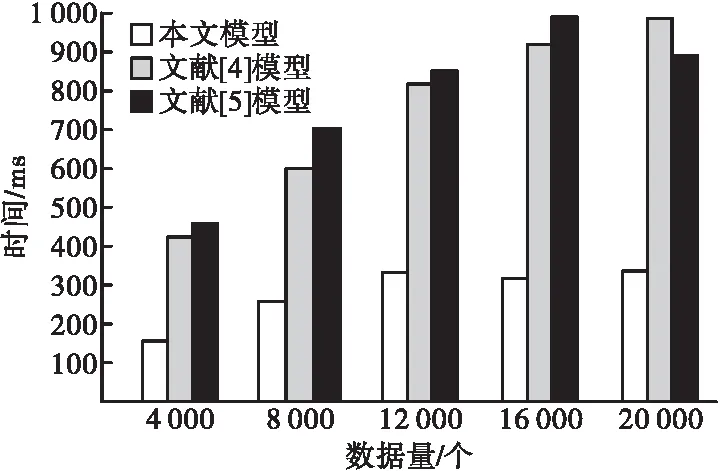
圖6 三種方法的對比結(jié)果
由圖6可知,隨著數(shù)據(jù)量的增加,三種方法完成挖掘所需時間隨之增加,但本文模型數(shù)據(jù)挖掘過程的所需時間始終小于兩種對比方法,當數(shù)據(jù)量數(shù)量達到20 000個時,本文方法的挖掘時間僅為330 ms,數(shù)據(jù)挖掘效率高。
3 結(jié) 論
本文研究數(shù)據(jù)挖掘和區(qū)塊鏈技術(shù)的碳排放信息定向提取模型,設(shè)計碳排放信息定向提取框架,依據(jù)采集到的工業(yè)碳排放及碳排放績效信息,構(gòu)建碳排放信息庫,利用大數(shù)據(jù)技術(shù)中的樸素貝葉斯的方法對信息庫的信息進行定向提取,在提取傳輸信息時,利用同態(tài)加密方法保護碳排放信息傳輸?shù)陌踩?定向提取速度快,適用于大規(guī)模的碳排放信息提取。在區(qū)塊鏈中利用同態(tài)加密算法進行傳輸數(shù)據(jù)加密,可有效確保碳排放信息安全傳輸。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
電子設(shè)計工程(2014年18期)2014-02-27 12:00:13
祝您健康(1987年3期)1987-12-30 09:52:32
