測驗模式效應:來源、檢測與應用*
2023-10-09 06:31:24黃穎詩
心理科學進展 2023年10期
陳 平 代 藝 黃穎詩
·研究方法(Research Method)·
測驗模式效應:來源、檢測與應用*
陳 平 代 藝 黃穎詩
(北京師范大學中國基礎教育質量監測協同創新中心, 北京 100875)
測驗模式效應(Test Mode Effect, TME)是指同一測驗采用不同測驗形式施測而產生的測驗功能差異。TME的存在會對測驗公平、選拔標準和測驗等值等產生影響, 因此對TME進行準確檢測和合理解釋具有重要意義。通過對TME的來源、檢測(包括實驗設計和檢測方法)以及研究結果進行系統梳理, 全面展示TME研究的方法論。對TME模型進行進一步解釋、對TME研究中的測驗形式進行拓展以及將TME的研究成果應用于我國的大規模教育測評項目, 都是TME領域的未來重要發展方向。
測驗模式效應, 測驗公平, 測量不變性, 計算機測驗
1 引言
隨著計算機技術的進步和網絡的普及, 計算機測驗已經在測量和評估領域得到廣泛使用。大到國際大規模測評項目, 小到課堂測試, 都越來越多地使用計算機進行施測。測驗形式正經歷著從傳統“紙筆測驗(Paper-based Testing, PBT)”向“計算機測驗(Computer-based Testing, CBT)”的轉變。與PBT相比, CBT具有很多優點, 比如: (1)采用計算機輔助測驗, 測量更加高效、公平; (2)可以呈現高生態效度和高交互性的新穎題型, 增加被試的作答興趣(Pomplun et al., 2006); (3)可以方便記錄被試的作答步驟、動作序列和作答時間等過程性信息, 從而更全面地評價被試。正因如此, CBT已在國際學生評估項目(Programme for International Student Assessment, PISA)、國際數學和科學趨勢研究(Trends in International Mathematics and Science Study, TIMSS)、美國國家教育進展評估(National Assessment of Educational Progress, NAEP)等大規模測評項目中得到廣泛應用(檀慧玲等, 2018)。
盡管大多數測驗都在朝著CBT的方向發展, 但這并非一個簡單的過程。在進行測驗形式的轉化之前, 研究者和實踐者面臨一個關鍵性問題: 當同一測驗采用不同測驗形式(比如PBT和CBT)施測時, 其測驗結果不一定相同, 因而不能盲目地對它們進行直接比較(Jerrim, 2016)。這種由測驗形式不同而帶來的測驗功能差異, 被稱為測驗模式效應(Test Mode Effect, TME; Kroehne et al., 2019; OECD, 2017)。在已有研究中, TME在絕大多數情況下特指PBT和CBT這兩種測驗形式間的差異。考慮到測驗形式從PBT向CBT轉變是大勢所趨, 因此對TME進行研究具有以下重要意義:
首先, 對TME進行研究可以促進測驗公平。測驗公平是衡量測驗質量的一個重要方面, 一直受到測驗開發者、使用者、心理測量學家和普通大眾的廣泛關注(Kline, 2013)。一個公平的測驗應該能給被試提供平等的機會, 來反映他們掌握的與測驗目的相關的知識和技能。然而, 不同測驗形式間的轉換可能會引入與測驗目的無關的變量, 比如被試操作計算機的能力可能會對其CBT的成績產生影響。因此, 研究TME有助于明確和控制無關因素的影響, 從而提高測驗的公平性。
其次, 對TME進行研究可以保障選拔結果的可比性。很多大型考試都曾出現同時使用PBT和CBT的情況。比如, TOEFL就同時存在PBT和基于互聯網的測驗(Internet-based Testing, iBT)等多種測驗形式。考慮到TME的存在, 美國教育考試服務中心在使用PBT時, 并不是將CBT中的題目直接轉移到PBT上, 而是有針對性地對PBT中的測驗內容、實施過程和評價標準等進行修改, 以保障不同測驗形式下的結果具有可比性, 從而增加選拔與評價結果的可信度。
最后, 對TME進行研究可以幫助獲得準確的等值結果。隨著CBT的廣泛使用, PISA等國際測評項目已經出現“不同測驗周期使用不同測驗形式”的情況(Feskens et al., 2019)。TME的存在會影響不同測驗周期學生分數等值結果的準確性, 使得研究者沒法合理刻畫學生的能力發展趨勢, 進而削弱教育評估項目的意義。因此, 對題庫中可能存在TME的題目進行檢測, 可進一步改善測驗和題目質量, 從而保障教育評估項目的有效性。
鑒于這一主題的重要性, 本文對TME進行系統述評, 以期為測量研究者與實踐者了解TME的來源、檢測方法和研究思路提供幫助。本文將按以下順序進行組織: 首先介紹TME的來源, 然后探討TME的檢測(包括控制TME影響的實驗設計和對TME進行檢測的方法), 接著總結TME研究的結果與不足, 最后展望TME的未來研究方向。
2 TME的來源
TME來源于測驗形式不同所帶來的差異, 這種差異可以來自4個層面: 測驗層面、題目層面、被試層面和評分者層面。接下來分別介紹這4個層面的差異如何導致TME的產生。
2.1 測驗層面
測驗層面的差異是指由于不同測驗形式具有的特征不同而導致的差異, 比如PBT與CBT在作答設備、作答過程中是否允許檢查并修改答案、測驗過程中有無監督以及測驗計時和選題方式等方面都具有不同的特征。具體來說:
(1)作答設備。在PBT中, 被試通常使用紙筆進行作答; 而在CBT中, 被試需要在顯示屏上閱讀題目, 并使用鼠標和鍵盤進行作答。屏幕大小、分辨率和刷新速度等都可能對被試在計算機上的作答產生影響。Ziefle (1998)對被試在PBT和兩種屏幕分辨率(1664×1200和832×600)下CBT的閱讀表現及感受到的疲勞程度進行比較, 結果發現: 被試在PBT中的表現顯著好于兩種分辨率下CBT的表現; 而且分辨率越高, 被試感受到的疲勞程度越輕。在屏幕大小方面, 其對TME的影響因人而異, 但總體來說, 更大的屏幕會增加文字的可讀性, 從而提高測驗表現(Bridgeman et al., 2003)。
(2)是否允許檢查并修改答案。在PBT中, 被試可以不按題目的呈現順序進行作答, 甚至可以隨時對已作答題目進行檢查并修改答案; 而有些CBT (如計算機化自適應測驗[Computerized Adaptive Testing, CAT])一般不允許被試返回檢查并修改答案, 主要是因為考試機構擔心提供修改機會會帶來兩個問題: ①“聰明”被試或“聰明”備考機構所指導的被試通過采用Wainer策略(Wainer, 1993)和Kingsbury策略(Wise et al., 1997)等作弊策略獲得虛高的分數, 從而影響測驗的公平性、公正性和準確性; ②增加測驗時間, 相應地增加測驗費用。CAT不提供修改功能也會給被試帶來兩方面的影響: ①被試在PBT中慣用的作答策略不能用于CAT, 會給他們帶來焦慮和壓力; ②若被試完全有能力答對某道題目但是鍵入或點擊失誤了, 不允許修改會導致其能力被低估; 相反, 若被試沒有能力答對某道題目但是猜對了, 不允許修改會導致其能力被高估(陳平, 丁樹良, 2008; 高旭亮等, 2016; 林喆等, 2015)。不提供修改機會的CAT可能導致TME的產生。
(3)測驗過程有無監督。一般情況下, PBT的實施過程中往往有主試在場監督; 而對于部分CBT (比如通過網絡進行的在線測驗)很有可能會在無人監督的情況下開展, 這也有可能導致TME的產生。Goldberg和Pedulla(2002)比較被試在PBT、有監督CBT和無監督CBT的GRE分數, 結果表明: 被試在PBT和有監督CBT中的表現顯著好于無監督CBT。測驗過程有無監督可能會對被試的作答動機產生影響, 從而影響其在測驗中的表現。
(4)測驗計時與選題方式。在CBT中, 計算機為更精細的考試流程設計提供了可能: ①測驗開發者可以將測驗的計時設計為“以單道題目為單位”、“以測驗模塊為單位”或“以整個測驗為單位”; ②測驗的組卷不再拘泥于固定試題, 而允許被試作答與自身能力匹配的題目(即CAT)。雖然沒有研究直接表明不同的測驗計時設計會引起TME, 但是相比于以單道題為單位的計時, 目前主流的大型CBT (如PISA和NAEP)通常以一個測驗模塊為單位進行計時, 且部分CBT (如GRE)允許被試選擇偏好的時間呈現方式(即顯示或不顯示倒計時)。另外, 相比于可能包含簡單題的PBT, CAT中高能力水平被試的測驗過程可能更“吃力”, 因為總是作答與自身能力水平匹配的難題。為探究CAT匹配被試能力的選題策略是否會增加被試的測驗焦慮程度進而引起TME, Powers (1999)基于GRE的PBT和CBT樣本進行回歸分析, 發現被試在兩種測驗形式下的焦慮與GRE分數之間的關系并無顯著差異, 而且自適應的選題策略并未加劇被試的測驗焦慮。Fritts和Marszalek (2010)分析中學生的學業進度測驗(measures of academic progress)結果后發現: 在控制被試對考試的基線焦慮水平和對電腦使用的焦慮后, 相比于CAT, 被試在PBT上表現出更高的焦慮水平。
2.2 題目層面
題目層面的差異來源于題目本身的屬性, 這些屬性可能在不同測驗形式下的表現不同, 從而導致TME的產生。具體包括:
(1)題目呈現方式。呈現方式包括題目的字體、字號、粗細和顏色(Bernard et al., 2002; Bernard & Mills, 2000)、每一行的文字長度(Chaparro et al., 2002)、每一頁中呈現的題目數量和行數(Duchnicky & Kolers, 1983)以及每一頁中空白部分的面積大小(McMullin et al., 2002)等。由于CBT的形式多樣且多借助現成軟件或平臺進行施測, 很難保證所有題目都以相同方式呈現給被試, 從而導致TME的產生。
(2)題目類型。題目類型可能會影響被試和題目間的交互方式, 從而影響被試的作答表現(Kr?hne & Martens, 2011)。題目類型主要包括兩大類: 選擇題與建構題。對于選擇題, 特別是當題目較短時, 不同測驗形式的差異較小, 較少檢測出TME (Buerger et al., 2016; Lynch, 2022)。而對于建構題, 考生在PBT上的表現傾向于比CBT更好(Bennett et al., 2008)。這可能源于題目交互方式的復雜程度的變化, 交互方式較復雜的題目更容易影響被試在CBT上的成績(Kingston, 2008)。例如, 當題目包含較長的文本或作答過程涉及使用鼠標、滾輪和下拉菜單等, 題目的作答難度會增加(Poggio et al., 2005)。另外, Liu等人(2016)對美國基礎教育評價系統(PARCC)的數學建構題進行分析后發現: 相對于PBT被試群體, CBT被試群體在低年級(3~8年級)題目上的表現更好; 而對于高年級的建構題, 結論則相反。這意味著題型在不同測驗形式上的差異還可能源于題目所涉及的認知過程不同。Johnson和Green (2006)通過觀察和訪談小學生后發現, 約1/3的被試在作答不同測驗形式下的題目時會采用不同的作答策略。而對于作文任務, 研究認為被試在CBT上的表現優于PBT, 或兩者沒有顯著差異(Lee, 2002; Lynch, 2022; Zhi & Huang, 2021)。Li (2006)讓被試在作答學術英語任務(English for academic purposes)時進行出聲思維, 發現被試在CBT上展現出更高階的思維能力, 并且比PBT做出更多的修改。相比于關注單詞水平的修改, 被試在CBT上更多地進行句子和段落層次的完善和組織(Chan et al., 2018)。
2.3 被試層面
被試層面的差異來源于被試本身的屬性, 這些屬性并非測驗想要測量的特質, 但是它們在不同測驗形式上的差異可能會導致TME的產生。具體包括:
(1)人口學變量。性別、年齡、種族和社會經濟地位等人口學變量并不直接導致TME, 而是通過影響與測驗目的相關的被試能力等來間接導致TME。比如, 老年人可能由于使用計算機的熟練程度不如年輕人, 因而在CBT上的表現更差(Chua et al., 1999); 但也有研究表明, 年齡帶來的差異并不像研究者預期的那樣顯著(Weigold et al., 2016)。Fouladi等人(2002)發現不同測驗形式間的結果存在較大差異, 但在控制性別和種族的影響后, 不同測驗形式間的結果差異顯著減小。
(2)計算機的熟練程度。對計算機使用越熟練, 在CBT中的表現就越好(Jerrim et al., 2018; Pomplun, 2007)。一方面, 對計算機越熟練, 在作答時的操作就越快捷; 另一方面, 被試的學習過程和測試過程的形式相匹配時, 他們的作答分數會更高, 即存在一定的遷移適用加工過程(transfer appropriate processing; Clariana & Wallace, 2002)。但也有研究發現, 使用計算機的熟練程度不會對被試在CBT上的結果產生影響(Jeong, 2012)。
(3)作答動機。與低利害測驗相比, 參加高利害測驗的被試具有更高的作答動機, 從而在PBT和CBT上有更相近的表現(Rowan, 2010)。有意思的是, 也有研究發現: 與PBT相比, 被試對CBT普遍有更好的體驗、更高的作答動機和自我效能感, 但在CBT上的得分卻更低(Chua, 2012)。
2.4 評分者層面
評分者層面的差異本質上源于評分者內在認知加工的不同, 認知加工的不同可能使得評分者在不同測驗形式下的評分結果有所差異, 從而導致TME的產生。也即, 評分者效應(rater effect; 韓建濤等, 2019)也可能是TME的來源之一。測驗中的客觀題由于評分標準明確、客觀, 所以其評分結果不易被評分者效應影響; 而對于主觀題, 其評分結果則容易受到評分者主觀因素的影響, 從而導致其在PBT和CBT中的評分結果存在差異。具體來說, 評分者在評定不同測驗形式下的被試作答時, 主要受到被試作答呈現方式的影響(Hunsu, 2015), 其中手寫版(handwritten)和打字版(typed or word-processed)的差異是研究關注的重點。Arnold等人(1990)發現, 評分者傾向于對手寫版作答采用更寬松的標準, 而對打字版更苛刻。這可能是因為手寫作答在一定程度上具有更長的感知視覺效果, 并保留被試的修改痕跡, 而且有評分者認為手寫版比打字版更有“力量” (Powers et al., 1994; Russell & Tao, 2004a)。另外, 為探討不同測驗形式給評分者帶來的感知長度差異對測驗結果的影響, 研究者對比單倍行距與雙倍行距的作文評分, 發現長度的變化并沒有消除CBT與PBT的得分差異(Russell & Tao, 2004b)。
需要注意的是, 來自評分者的影響通常與題型相互交織, 評分者對CBT與PBT的評分差異大多出現于建構題上。為區分兩者的影響, 研究者將手寫版的作答輸入計算機, 讓評分者對混合之后的打字版作答進行評分, 發現被試在CBT上的得分更高(Jin & Yan, 2017; Russell & Haney, 1997)。但也有對學術英語測試的研究發現, 控制評分者的嚴格程度和信度之后, 被試在CBT與PBT下的整體測驗得分差異較小, 評分者僅在詞匯量測試題中呈現出對手寫版的偏好(Chan et al., 2018)。
表1對TME的來源進行總結, 并對TME的產生進行說明。
在實踐中, 研究者往往需要在排除無關變量的影響后, 再探究測驗形式對測驗結果的影響。因此, 對TME的來源進行梳理有助于研究者在實驗設計階段對無關變量進行嚴格控制, 以減少無關變量的影響。比如, 在測驗層面保證被試都能檢查并修改答案, 且作答過程都在有人監督的情況下進行; 在題目層面保證所有題目在PBT和CBT上有相同的呈現效果; 在被試層面保證在兩種測驗形式上作答的被試的年齡和性別等方面一致。
3 TME的檢測
3.1 TME的實驗設計
TME研究一般采用兩類實驗設計控制被試特征: 組間設計和組內設計(Buerger et al., 2016)。在TME的研究背景下, 組間設計中每名被試只接受PBT或者CBT, 而在組內設計中每名被試先后接受這兩種測驗形式。TME組間設計和組內設計如圖1所示(共名被試和道題)。根據被試是否能夠自由選擇測驗形式, 組間設計又被分為兩類: (1)自由選擇。即被試可以自由選擇測驗形式(Puhan et al., 2007); (2)隨機分配。即研究者將被試隨機分配給某種測驗形式(Gu et al., 2021; Schwarz et al., 2003)。根據被試作答順序是否固定, 組內設計也可以被分為兩類: (1)固定順序。即所有被試接受兩種形式測驗的順序固定且一致(Jeong, 2012); (2)平衡順序。即先將被試隨機分成兩組, 一組先接受測驗形式A (如PBT), 一段時間后再接受測驗形式B (如CBT), 另一組則與之相反, 即所謂的“AB-BA設計” (Bodmann & Robinson, 2004; Kim et al., 2018; Seifert & Paleczek, 2022)。
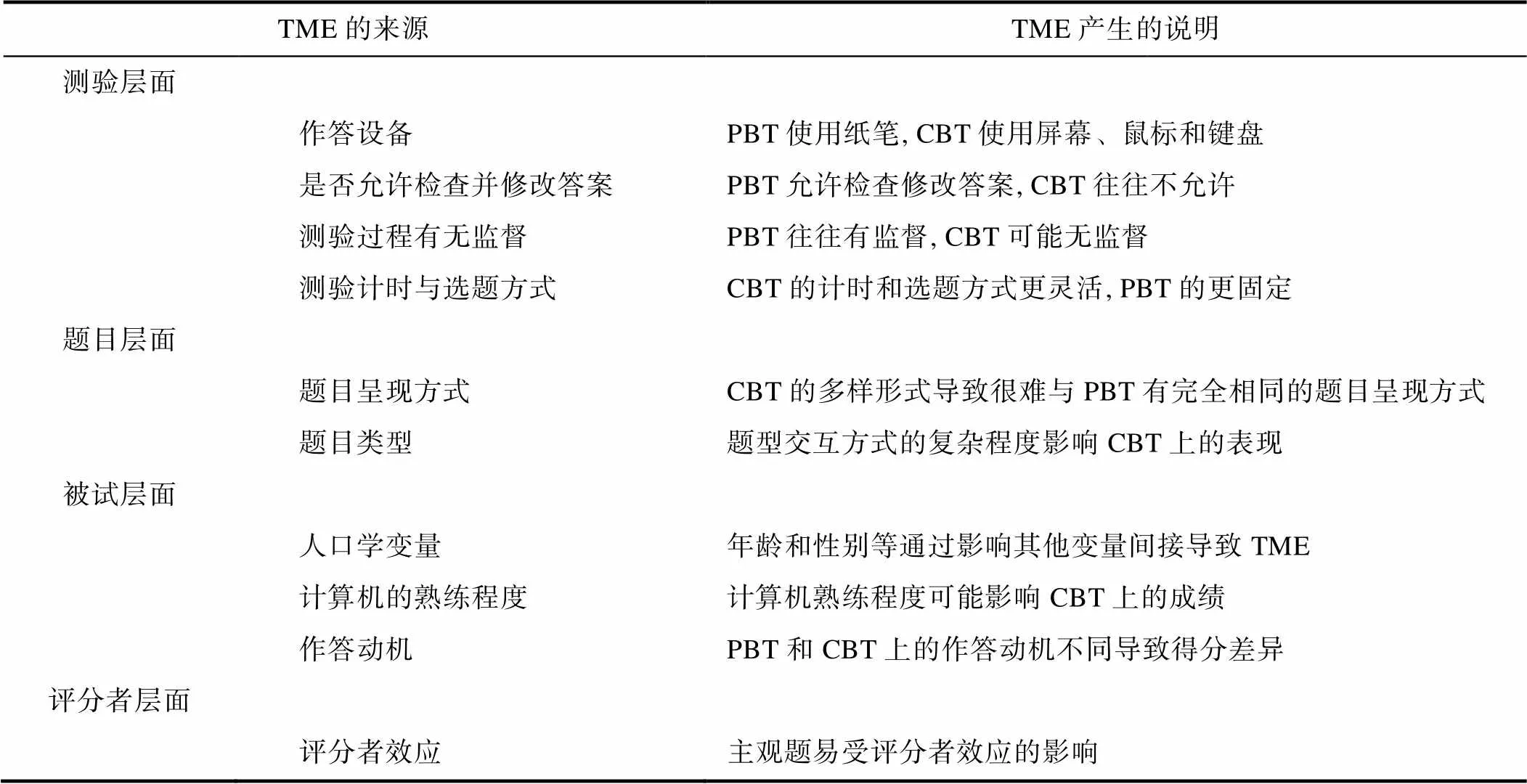
表1 TME的來源和對TME產生的說明
組間設計和組內設計各有其適用范圍。與前者比, 后者能有效避免由組間個體差異帶來的無關變量干擾, 但也容易受到疲勞效應和練習效應的影響, 因此適用于樣本量和題量都較少的情況, 更適用于練習效應較小的人格測驗。而在組間設計中, 雖然組間個體差異難以避免、容易引入無關變量, 但是由于每名被試只接受一種測驗形式, 實施起來更方便、快捷, 因而適用于樣本量和題量都較多的情境, 更適用于能力測驗。
為改進這兩種設計的不足, 研究者將它們結合形成平衡不完全區組(Balanced Incomplete Block, BIB; Brunfaut et al., 2018)設計, 如表2所示。在BIB設計中, 原測驗被分成多個平行題本, 相應地被試也被隨機分成多個組, 這多個被試組理論上可被看作是相互平行的。表2中的“Test 1”和“Test 2”代表被試的作答順序。每組被試作答兩個題本, 并在題本序號和作答順序上進行平衡, 從而減輕被試的疲勞效應。由于題本A和B理論上平行, 比較每組中兩個題本間的作答就可以估計TME。通過設計組1和組4以及組2和組3可以控制順序效應、疲勞效應和學習效應。BIB設計結合兩種設計的優點, 因而在樣本量大、題目較多的測評項目(如PISA)中已經得到較為成熟的運用(OECD, 2014)。
通過實驗設計, 可以有效控制組間被試特征的影響。但是即使控制組間差異, BIB設計依舊無法完全避免組內個體差異(如年齡、計算機的使用和作答動機)的影響, 此時可以在測驗過程中估計由個體特征造成的TME。接下來介紹TME的檢測方法。
3.2 TME的檢測方法
對TME進行檢測就是對被試在PBT和CBT上的作答表現進行比較, 作答表現的比較可以分為兩個層面: 觀測變量層面和潛變量層面。在觀測變量層面, 一般采用方差分析(Analysis of Variance, ANOVA)法進行比較。在潛變量層面, 一般通過檢驗測量不變性或參數不變性來檢測TME。在結構方程模型框架下, 測量不變性是指在測量被試的目標特質時, 觀測變量和潛在特質間以及潛在特質之間的關系在待比較的各組之間或在不同情境下等同(白新文, 陳毅文, 2004); 而在項目反應理論(Item Response Theory, IRT)框架下, 參數不變性體現在題目參數和能力參數的不變性上(聶旭剛等, 2018)。目前, 潛變量層面的TME檢測方法主要包括多組驗證性因子分析(Multigroup Confirmatory Factor Analysis, MCFA)法、題目功能差異(Differential Item Functioning, DIF)法和模式效應模型(Mode Effect Model, MEM)法。下面對這4種方法進行述評。
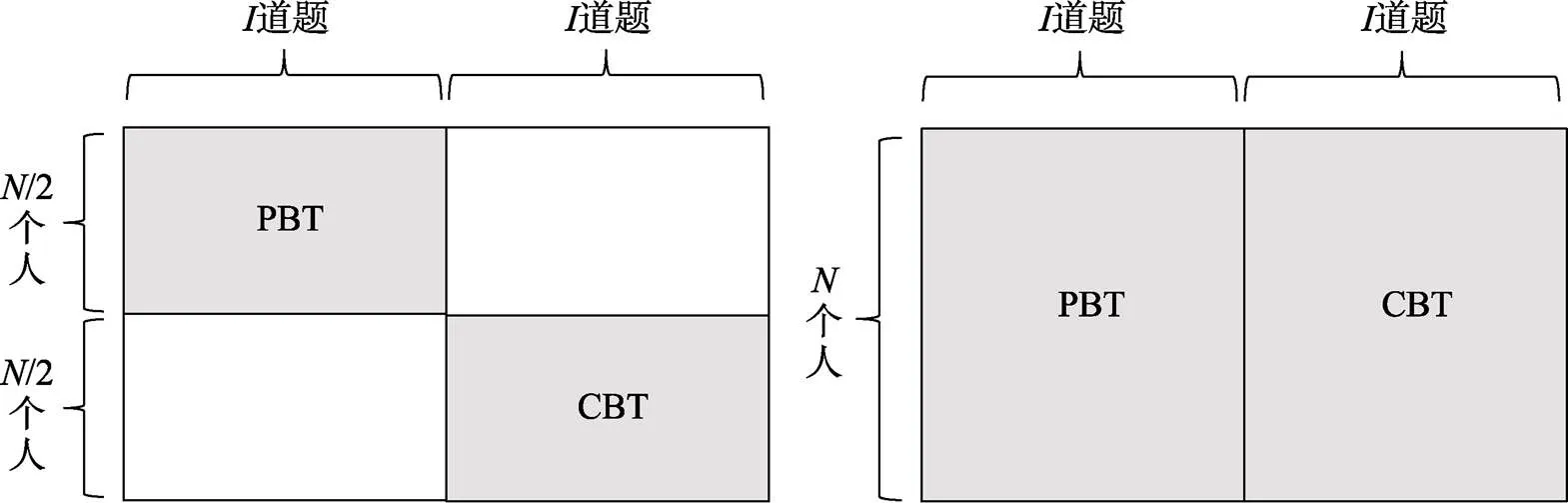
圖1 TME組間設計(左)和組內設計(右)示意圖
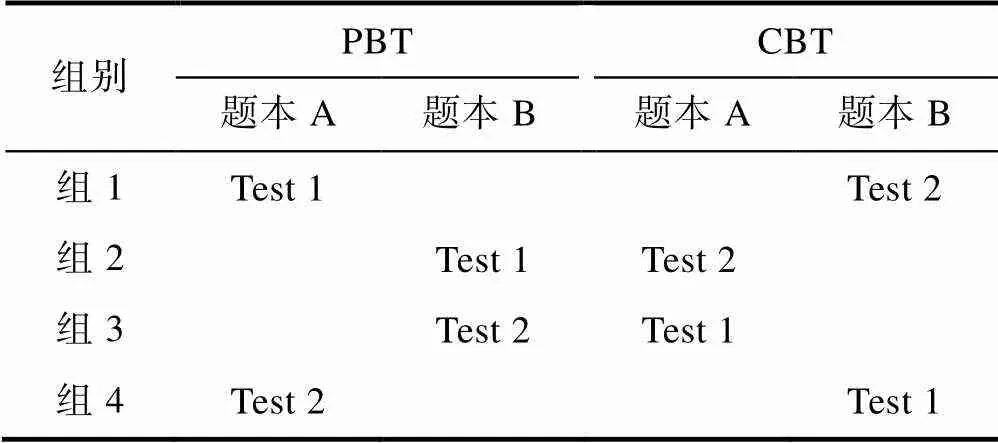
表2 TME研究中的BIB設計
3.2.1 ANOVA法
ANOVA法首先計算兩種測驗形式下的作答指標(包括測驗層面的總分以及題目層面的平均分、正確率和空缺率等), 然后根據實驗設計是組內或組間設計, 采用被試內或被試間的ANOVA對這些作答指標進行比較。如果這些指標間存在顯著差異, 則說明存在TME并且TME會對測驗結果產生影響(Bodmann & Robinson, 2004; Goldberg et al., 2003; Khoshsima et al., 2017)。ANOVA法可通過SPSS或R中的TAM包(Robitzsch et al., 2022)實現。
3.2.2 MCFA法
MCFA法采用多組比較的思想, 對兩種測驗形式下的結果進行測量不變性檢驗(Kim & Huynh, 2008)。測量不變性檢驗是通過比較一系列嵌套模型來實現, 具體表現在依次對以下不變性進行檢驗: (1)結構不變性(configural invariance)檢驗。即檢驗不同組之間的因子結構(即觀測變量和潛變量間的關系)是否相同; (2)弱不變性(weak invariance)檢驗。若結構不變性得到滿足, 則進一步檢驗不同組之間的因子載荷是否相等; (3)強不變性(strong invariance)檢驗。若弱不變性得到滿足, 則進一步檢驗不同組之間的截距(潛變量預測觀測變量時的截距)是否相同; (4)嚴格不變性(strict invariance)檢驗。若強不變性得到滿足, 則檢驗不同組之間的殘差方差是否相同。這4種檢驗對應的測量不變性水平具有層級嵌套關系, 只有低一級的不變性得到證實后, 進行高一級的不變性檢驗才有意義(蔡華儉等, 2008)。如果測驗在某一級水平的測量不變性上出現違反, 則說明該測驗在對應水平上存在TME, 通過這種方式可以對測驗層面的TME進行檢驗。
為進一步尋找違反測量不變性的成因, 可以根據輸出結果確定當前測量不變性水平下對模型擬合違反較大的題目。在放松該題目上的檢驗限制后, 若模型擬合顯著變好, 則說明該題目的存在會對測量不變性產生影響, 可認為存在TME。這樣依次對所有題目進行檢測, 即可找出所有具有TME的題目。此時, 測驗滿足部分(partial)弱不變性、部分強不變性或部分嚴格不變性。
已有研究幾乎都得到結構不變性的結果, 這可能是因為一個用于施測的成熟測驗往往具有較好的信效度, 所以在測驗形式發生變化后因子結構并沒有發生變化。大多數測驗具有完全或部分弱不變性, 還有一些測驗具有完全或部分強不變性, 但是極少有測驗能夠達到嚴格不變性(比如, Hox et al., 2015)。一般來說, 只要達到弱不變性或部分強不變性, 就說明不同測驗形式下的結果可比。MCFA法可通過R中的lavaan包(Rosseel, 2012)實現。
3.2.3 DIF法
TME和DIF都反映“由于某種因素的影響, 導致能力相同的被試在同一題目上具有不同的正確作答概率”, 在DIF中這種因素是指被試來自不同群體, 而在TME中這種因素是指不同的測驗形式。鑒于兩者的相似性, 不少研究者將檢測DIF的方法用于對TME的檢測(Chan et al., 2004; Keng et al., 2008; Puhan et al., 2007; Schwarz et al., 2003), 此時作答CBT的被試組可看作是目標組(focus group), 作答PBT的被試組可看作是參照組(reference group)。
常見的DIF檢測方法主要有兩類: 一類是基于IRT的方法(即將潛在特質作為匹配變量), 包括IRT似然比檢驗法(IRT Likelihood Ratio, IRT-LR)、測驗與題目功能差異法(Differential Functioning of Items and Test, DFIT)以及同時題目偏差檢驗法(Simultaneous Item Bias Test, SIBTEST; Shealy & Stout, 1993)等; 另一類是非IRT的方法(即直接將測驗總分作為匹配變量), 包括Mantel- Haenszel法、標準化法(Standardization, STND)和邏輯斯蒂克回歸法(Logistic Regression, LRDIF)等。其中, Mantel-Haenszel、SIBTEST、IRT-LR和DFIT法都已被用于檢測TME(Claudia et al., 1999; Puhan et al., 2007; Terluin et al., 2018)。值得注意的是, 只有DFIT法可以同時對測驗和題目層面的DIF進行檢測, 其他方法只能對單個題目的DIF進行檢測(Raju et al., 1995)。
以SIBTEST法為例, 簡要介紹檢測TME的步驟: (1)將所有題目分為匹配子測驗和待測子測驗。匹配子測驗由不存在TME的題目組成, 因此可將被試在匹配子測驗上的分數作為其能力估計值; (2)對目標組和參照組在匹配子測驗和待測子測驗中的作答結果進行評價, 并基于匹配子測驗上的分數將能力相同但組別不同的被試進行匹配。SIBTEST假定在匹配子測驗中分數相同的被試具有相同能力, 所以組別不同的匹配被試在待測子測驗上的分數差異就是TME的值; (3)對TME的值進行顯著性檢驗, 從而確定題目是否有TME(蔡曉芬, 2014; 湯楚, 2016)。DIF法可通過R中的mirt包(Chalmers, 2012)實現。
3.2.4 MEM法
von Davier等人(2019)提出可以通過在兩參數邏輯斯蒂克模型(Two-Parameter Logistic Model, 2PLM)中加入量化的TME參數從而形成MEM, 然后在估計題目參數和能力參數的同時也對TME參數進行估計。MEM包含三個子模型, 每個子模型都有不同的模型假設。
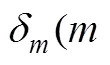
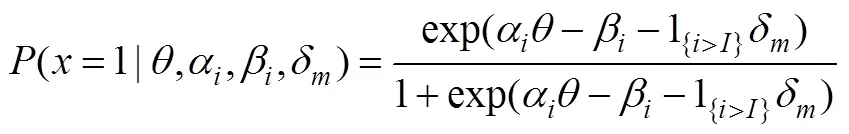
MEM中的模型2假設測驗形式和題目之間存在交互作用, 也即在測驗形式發生變化后, 測驗中有的題目可能會變得更難, 有的題目會變得更簡單。因此, 模型2也被稱為題目特異性的MEM (item-specific MEM), 公式如下:
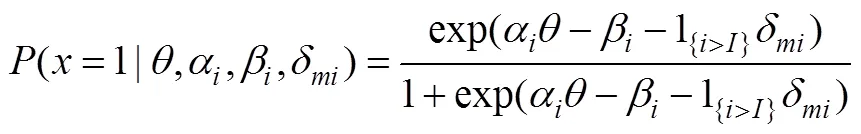
MEM中的模型3假設測驗形式和被試之間存在交互作用, 即在測驗形式轉化后, 對于有的被試來說題目變得更難, 對于有的被試來說題目變得更簡單。模型3也被稱為個體特異性的MEM (person-specific MEM), 公式如下:

MEM法的以上三個子模型分別假設三種不同的情況。在使用這種方法檢測TME時, 通常的做法是使用AIC和BIC等模型擬合指標比較三個模型和數據的擬合程度, 擬合越好說明數據更接近對應模型的假設, 從而可以探究TME是具有一般性、題目特異性還是個體特異性(von Davier et al., 2019)。模型擬合的同時也對題目參數、能力參數和TME參數進行估計, 進而找出具有TME的題目并對其進行調整。另外, 模型1和2具有嵌套關系, 模型3與模型1和2沒有嵌套關系。如果簡單模型和復雜模型的擬合不存在顯著差異, 則選擇性價比更高的簡單模型。MEM法可通過mdltm軟件(von Davier, 2005)實現。
MEM法的三個子模型還可以從TME來源的角度進行理解。模型1假設TME只與測驗形式有關, 說明此時TME的來源只包括測驗層面的差異, 如計算機的硬件設施和是否允許檢查并修改答案等。模型2假設TME具有題目特異性, 說明此時TME會受到題目層面差異的影響, 如題目類型和題目的呈現方式等。這種情況在能力測驗中較為常見, 特別是包含多種題型的考試中, 不同題目受到測驗形式的影響也不同, 從而導致題目特異性的TME。模型3假設TME具有個體特異性, 說明此時TME會受到被試層面差異的影響, 如年齡、性別、計算機的熟練程度和作答動機等。這種情況可能出現在個體差異較大的時候, 即使通過實驗設計進行控制, 也沒法完全避免個體差異的影響, 從而導致個體特異性的TME。
為促進TME檢測方法的應用, 本文在附錄部分呈現能實現ANOVA、MCFA和DIF方法的R代碼示例, 并以組間設計為例給出檢驗題目層面TME的簡要流程。
3.2.5 TME檢測方法的比較
表3對上述4種TME檢測方法的優缺點、適用范圍和實現方法進行了總結。
ANOVA法通過“計算PBT和CBT上的作答指標, 再比較兩者間的差異”來檢測TME, 優點在于方便快捷、計算簡單, 適合對測驗層面的TME進行初步檢測; 不足在于檢驗力較低, 而且只能對觀測指標進行比較。MCFA法通過驗證測量不變性來對TME進行檢測。與ANOVA法類似, MCFA法更適合對測驗層面的TME進行檢測, 可以探究觀測變量與潛在特質間以及潛在特質間的關系; 不足在于對題目層面TME進行檢測的過程繁瑣、不易操作。
DIF法利用DIF和TME在概念和檢測方法上的共通性, 采用DIF檢測方法對TME進行檢測。DIF法的優點體現在兩方面: 一是能對測驗中具有TME的題目進行準確識別; 二是包含的方法非常多樣, 在實踐中可以靈活選擇。MEM法通過建立包含TME參數的IRT模型, 直接對TME的值進行估計。與前三種方法相比, MEM法具有兩方面的優點: 一是能對TME的大小進行直接估計; 二是能在一定程度上探究TME的來源, 從而更好地對TME進行解釋和控制; 缺點是模型較為復雜(特別是模型3), 可能會面臨模型識別和參數估計等方面的挑戰。
4 測驗模式效應的研究結果
在過去30多年里, 已經有超過300項研究對PBT和CBT的測驗結果(包括成就測驗、人格與態度測驗和職業興趣測驗等領域的結果)進行比較(Duchnicky & Kolers, 1983; Kulik et al., 1980), 但并沒有得到一致的結論。很多研究者發現, 同一測驗在CBT上的難度要普遍高于PBT, 導致被試在PBT上的表現顯著好于在CBT上的表現(比如, Backes & Cowan, 2019; Beatty et al., 2022; Lee et al., 1986; Jeong, 2012)。然而也有一些研究得出相反的結論, 即被試在CBT上的表現要好于在PBT上的表現(比如, Brunfaut et al., 2018; Russell & Plati, 2002)。還有不少研究發現, 被試在不同測驗形式上的作答結果沒有顯著差異(Blumenthal & Blumenthal, 2020; Hamhuis et al., 2020; Khoshsima & Toroujeni, 2017; Paleczek et al., 2021; Porion et al., 2016; Prisacari & Danielson, 2017a, 2017b)。
出現這樣的結果可能與研究發表的年代有關。隨著研究發表年代的遞進, 被試在PBT和CBT上的作答表現也發生變化。在21世紀之前, 計算機還沒有得到普及, 相應地人們對計算機的使用不太熟練, 因此會出現PBT得分顯著高于CBT的結果。隨著計算機的逐漸普及, 人們使用計算機的能力也得到提高, 再加上對計算機有著較強的興趣和作答動機, 因此出現更多在CBT上得分更高的情況。
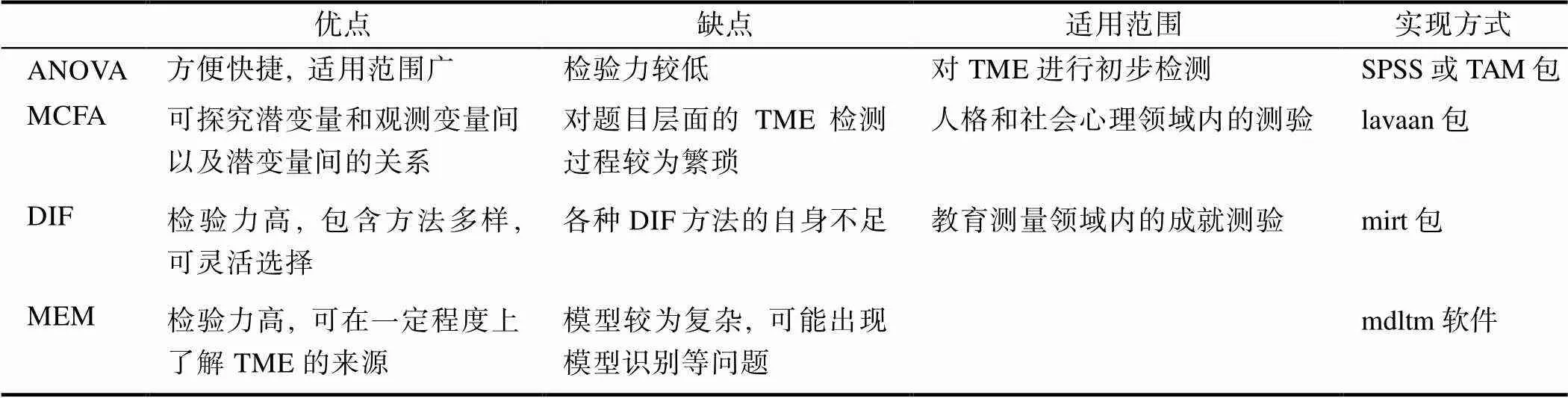
表3 四種TME檢測方法的總結
對于沒有檢測出TME的研究, 則可能有以下幾點原因: (1)部分測驗題目(如多選題)的穩定性較好, 不易產生TME; (2)隨著題型越來越多樣化, 可能會出現“在同一測驗中, 部分題目對PBT更有利, 而另一些題目對CBT更有利”的情況。如果只對測驗層面的TME進行檢測, 則可能出現效應上的抵消; (3)在“測驗本身結構較好、實驗設計較完善且對TME來源控制較好”的前提下, 測驗層面不存在較大的TME。若研究者采用檢驗力較低的ANOVA和MCFA法, 則容易出現TME檢測不顯著的情況。
因此, 很多研究在對測驗層面的TME進行檢測后, 還會對題目層面的TME進行檢測(Keng et al., 2008; Puhan et al., 2007; OECD, 2017)。通過綜合測驗和題目層面的檢測結果, 可以為測驗在PBT和CBT上的可比性提供依據, 也可以更細致地探究TME的來源, 從而為題目的修訂提出建議。
5 討論與展望
目前隨著計算機和網絡的廣泛運用, TME已經成為大型測驗電子化進程中不容忽視的問題。PISA、NAEP和TIMSS等大規模測評項目都在經歷著從PBT到CBT的變化。在進行測驗形式的轉變之前, 采用嚴密的實驗設計和精確的檢測方法對測驗中可能存在的TME進行檢測, 是保證PBT和CBT上作答結果具有可比性的重要途徑, 也是對測驗公平的保障。
通過前面的梳理, 可以看到盡管TME的研究已經較為成熟, 但是也還存在一些問題: 首先, TME的來源比較復雜, 使得影響TME的因素繁多。而且對于同一因素, 還可能會在不同人群中出現巨大差異。比如CBT中的交互方式, 年輕人會適應鍵盤和鼠標的輸入方式, 而中老年人可能會非常不適應。這使得研究者幾乎無法預測和控制影響因素, 不利于對TME進行深入的分析與解釋。其次, 缺少對TME檢測方法的系統比較。盡管4種TME檢測方法各有優勢, 有時也可以同時使用以達到更好的效果, 但是還沒有研究對它們的檢測效果進行全面比較。最后, 不同TME研究中的結果難以進行比較。如前所述, TME的研究結果受TME的來源、實驗設計和檢測方法等多方面的影響, 因此有研究者使用元分析方法對TME研究的影響因素進行探究, 然而結果不盡相同(Wang et al., 2007, 2008)。這可能是因為元分析本身存在“蘋果與桔子之爭”問題, 即很多研究者認為方法不同的研究不能進行直接比較。
綜上, TME今后的研究方向包括但不限于以下幾個方面:
5.1 提升MEM方法的解釋性與適用性
第三部分提到, 可以從TME來源的角度理解MEM。但是, MEM只能在一定程度上幫助研究者鎖定TME的來源范圍, 無法對TME的來源做出解釋。因此, 可以借助“IRT模型能夠增減參數”的優勢, 在現有MEM中加入與TME來源相關的因素, 從而直接在模型中對TME進行解釋。比如, 模型1假設TME只與測驗形式有關, TME的來源可能是作答過程有無監督等測驗層面的特征。為進一步對這些因素進行解釋, 可以建立關于TME參數和測驗層面特征的回歸方程, 以探究不同特征的權重以及不同特征對TME產生的貢獻大小。在模型2和3中, 也可以建立類似的回歸方程對TME的來源進行解釋。
另外, 還可以使用廣義模型對TME進行解釋。陳冠宇和陳平(2019)基于廣義線性混合模型和非線性混合模型的視角全面探討解釋性IRT模型(Explanatory IRT Model, EIRTM)。EIRTM是一個綜合性的解釋框架, 它通過在IRT模型中加入預測變量來對被試和題目間的關系進行刻畫, 進而解釋相關變量的影響。具體地講, 他們在EIRTM的框架下, 從固定效應和隨機效應的角度對TME進行解釋。未來研究也可以在EIRTM這一更加靈活、更加廣義的框架下對混合MEM進行進一步界定。
再者, 已有的MEM方法主要基于IRT模型(即2PLM)。而認知診斷測驗(Cognitive Diagnostic Testing, CDT)由于能夠反饋學生對特定知識屬性的掌握情況、能夠剖析心理量表的潛在結構(de La Torre & Douglas, 2004), 正日益受到測量研究者和實踐者的青睞。未來研究可進一步開發適用于CDT的MEM方法, 比如借助廣義多策略認知診斷模型(Ma & Guo, 2019)分析CBT與PBT下的被試作答策略差異, 以了解不同測驗形式下的認知加工過程變化。
5.2 拓展TME研究中測驗形式的范圍
目前大多數TME研究都聚焦于PBT和CBT之間的比較, 然而TME還可能出現在PBT和其他測驗形式之間, 包括手機測驗(mobile-based assessment)和電話或面對面訪談(phone or face-to-face interview)等測驗形式(Chan et al., 2004; Magnus et al., 2016)。Kim和Walker (2021)還研究在考試中心參加測驗和使用遠程監考在家參加測驗之間的TME。隨著測驗形式的不斷發展, 更多新型測驗形式不斷涌現, 比如基于游戲的測驗(game-based assessment)、基于虛擬現實(virtual reality)和增強現實(augmented reality)等智能穿戴設備的測驗等。對這些形式的測驗進行TME研究也值得未來研究者重視。
5.3 將TME研究成果應用于我國大規模教育測評項目
在PISA 2014年的現場實驗研究(field trial study)中, 研究者在參與測試的學校中隨機選取學生參加PBT和CBT, 并通過多種方法對TME進行檢測, 證實數學、閱讀和科學等認知測驗在PBT和CBT上的結果具有可比性, 從而為測驗形式的轉變提供理論依據(OECD, 2016)。隨后在2015年的正式測驗中, 全球參與測試的74個國家(地區)中的58個國家(地區)全面使用CBT進行測驗(OECD, 2017)。
而在我國的一些大規模教育測評項目中, 學科測驗仍采用PBT的形式。這主要是因為我國各地的信息化水平程度不同、計算機或網絡機房的配備程度不同, 導致少部分地區尚無條件使用CBT。通過對TME進行深入研究, 可在一定程度上解決這一問題: (1)若測驗中不存在顯著影響測驗結果的TME, 則說明該測驗在PBT和CBT上的結果具有測量等價性, 即可以在不同地區使用不同測驗形式; (2)若測驗中存在具有TME的題目, 則可以對其進行修訂和改進, 增強它們在不同情境中的穩定性。
需要注意的是: 對于部分需要人工評分的建構題, 仍需盡量避免評分者對被試作答呈現方式感知差異所帶來的影響。比如: (1)考慮將手寫作答輸入計算機, 能較有效地控制來自評分者層面的影響; (2)通過改良對評分者的訓練規則來降低手寫版和打字版的評分差異(Powers et al., 1994)。另外, 隨著自動評分技術的發展(Ramesh & Sanampudi, 2022 ; Zhang et al., 2020), 測驗或將迎來全計算機化模式, 屆時評分者對TME的影響將主要集中在機器評分的算法層面。
白新文, 陳毅文. (2004). 測量等價性的概念及其判定條件.(2), 231?239.
蔡華儉, 林永佳, 伍秋萍, 嚴樂, 黃玄鳳. (2008). 網絡測驗和紙筆測驗的測量不變性研究——以生活滿意度量表為例.(2), 228?239.
蔡曉芬. (2014).(碩士學位論文). 江西師范大學, 南昌.
陳冠宇, 陳平. (2019). 解釋性項目反應理論模型: 理論與應用.(5), 937?950.
陳平, 丁樹良. (2008). 允許檢查并修改答案的計算機化自適應測驗.(6), 737?747.
高旭亮, 涂冬波, 王芳, 張龍, 李雪瑩. (2016). 可修改答案的計算機化自適應測驗的方法.(4), 654?664.
韓建濤, 劉文令, 龐維國. (2019). 創造力測評中的評分者效應.(1), 171?180.
林喆, 陳平, 辛濤. (2015). 允許CAT題目檢查的區塊題目袋方法.(9), 1188?1198.
聶旭剛, 陳平, 張纓斌, 何引紅. (2018). 題目位置效應的概念及檢測.(2), 368?380.
檀慧玲, 李文燕, 萬興睿. (2018). 國際教育評價項目合作問題解決能力測評: 指標框架、評價標準及技術分析.(9), 123?128.
湯楚. (2016).(碩士學位論文). 江西師范大學, 南昌.
Arnold, V., Legas, J., Obler, S., Pacheco, M. A., Russell, C., & Umbdenstock, L. (1990).. Retrieved March 7,2023, from https://files.eric.ed.gov/fulltext/ED345818.pdf.
Backes, B., & Cowan, J. (2019). Is the pen mightier than the keyboard? The effect of online testing on measured studentachievement., 89?103.
Beatty, A. E., Esco, A., Curtiss, A. B. C., & Ballen, C. J. (2022). Students who prefer face-to-face tests outperform their online peers in organic chemistry., 464?474.
Bennett, R. E., Braswell, J., Oranje, A., Sandene, B., Kaplan, B., & Yan, F. (2008). Does it matter if I take my mathematics test on computer? A second empirical study of mode effects in NAEP.(9), 1?39.
Bernard, M., Fernandez, M., Hull, S., & Chaparro, B. S. (2003). The effects of line length on children and adults’ perceived and actual online reading performance.(11), 1375?1379.
Bernard, M., Lida, B., Riley, S., Hackler, T., & Janzen, K. (2002). A comparison of popular online fonts: Which size and type is best.(1), 1?8.
Bernard, M., & Mills, M. (2000). So, what size and type of font should I use on my website?(2), 1?5.
Blumenthal, S., & Blumenthal, Y. (2020). Tablet or paper and pen? Examining mode effects on German elementary school students’ computation skills with curriculum-based measurements.(4), 669?680.
Bodmann, S. M., & Robinson, D. H. (2004). Speed and performance differences among computer-based and paper-pencil tests.(1), 51?60.
Bridgeman, B., Lennon, M. L., & Jackenthal, A. (2003). Effects of screen size, screen resolution, and display rate on computer-based test performance.(3), 191?205.
Brunfaut, T., Harding, L., & Batty, A. O. (2018). Going online: The effect of mode of delivery on performances and perceptions on an English L2 writing test suite., 3?18.
Buerger, S., Kroehne, U., & Goldhammer, F. (2016). The transition to computer-based testing in large-scale assessments: Investigating (partial) measurement invariance between modes., 597?616.
Chalmers, R. P. (2012). mirt: A multidimensional item response theory package for the R environment.(6), 1?29.
Chan, K. S., Orlando, M., Ghosh-Dastidar, B., Duan, N., & Sherbourne, C. D. (2004). The interview mode effect on the Center for Epidemiological Studies Depression (CES-D) scale: An item response theory analysis.(3), 281?289.
Chan, S., Bax, S., & Weir, C. (2018). Researching the comparability of paper-based and computer-based delivery in a high-stakes writing test., 32?48.
Chua, S. L., Chen, D.-T., & Wong, A. F. L. (1999). Computer anxiety and its correlates: A meta-analysis.(5), 609?623.
Chua, Y. P. (2012). Effects of computer-based testing on test performance and testing motivation.(5), 1580?1586.
Clariana, R., & Wallace, P. (2002). Paper-based versus computer-based assessment: Key factors associated with the test mode effect.(5), 593?602.
Claudia, P. F., Oshima, T. C., & Nambury, S. R. (1999). A description and demonstration of the polytomous-DFIT framework.(4), 309?326.
de La Torre, J., & Douglas, J. A. (2004). Higher-order latent traitmodels for cognitive diagnosis., 333?353.
Duchnicky, R. L., & Kolers, P. A. (1983). Readability of text scrolled on visual display terminals as a function of window size.(6), 683?692.
Feskens, R., Fox, J.-P., & Zwitser, R. (2019). Differential item functioning in PISA due to mode effects. In B. Veldkamp & C. Sluijter (Eds.),(pp. 231?247). Cham, Switzerland: Springer.
Fouladi, R. T., McCarthy, C. J., & Moller, N. (2002). Paper-and-pencil or online? Evaluating mode effects on measures of emotional functioning and attachment.(2), 204?215.
Fritts, B. E., & Marszalek, J. M. (2010). Computerized adaptive testing, anxiety levels, and gender differences., 441?458.
Goldberg, A., Russell, M. & Cook, A. (2003). The effect of computers on student writing: A meta-analysis of studies from 1992 to 2002.(1), 1?52.
Goldberg, A. L., & Pedulla, J. J. (2002). Performance differences according to test mode and computer familiarity on a practice graduate record exam.(6), 1053?1067.
Gu, L., Ling, G. M., Liu, O. L., Yang, Z. T., Li, G. R., Kardanova, E., & Loyalka, P. (2021). Examining mode effects for an adapted Chinese critical thinking assessment.(6), 879?893.
Hamhuis, E., Glas, C., & Meelissen, M. (2020). Tablet assessment in primary education: Are there performance differences between TIMSS’ paper-and-pencil test and tablet test among Dutch grade-four students?(6), 2340?2358.
Hox, J. J., De Leeuw, E. D., & Zijlmans, E. A. O. (2015). Measurement equivalence in mixed mode surveys, Article 87.
Hunsu, N. J. (2015). Issues in transitioning from the traditional blue-book to computer-based writing assessment., 41?51.
Jeong, H. (2012). A comparative study of scores on computer-based tests and paper-based tests.,(4), 410?422.
Jerrim, J. (2016). PISA 2012: How do results for the paper and computer tests compare?(4), 495?518.
Jerrim, J., Micklewright, J., Heine, J.-H., Salzer, C., & McKeown, C. (2018). PISA 2015: How big is the ‘mode effect’ and what has been done about it?(4), 476?493.
Jin, Y., & Yan, M. (2017). Computer literacy and the constructvalidity of a high-stakes computer-based writing assessment.(2), 101?119.
Johnson, M., & Green, S. (2006). On-Line mathematics assessment: The impact of mode on performance and question answering strategies.(5), 1?35.
Keng, L., McClarty, K. L., & Davis, L. L. (2008). Item-level comparative analysis of online and paper administrations of the Texas Assessment of Knowledge and Skills.(3), 207?226.
Khoshsima, H., Hosseini, M., & Toroujeni, S. M. H. (2017). Cross-mode comparability of computer-based testing (CBT) versus paper-pencil based testing (PPT): An investigation of testing administration mode among Iranian intermediate EFL learners.(2), 23?32.
Khoshsima, H., & Toroujeni, S. M. H. (2017). Comparability of computer-based testing and paper-based testing: Testing mode effect, testing mode order, computer attitudes and testing mode preference., 80?99.
Kim, D., & Huynh, H. (2008). Computer-based and paper- and-pencil administration mode effects on a statewide end-of-course English test.(4), 554?570.
Kim, S., & Walker, M. (2021).(ETS Research Reprot Series, No. 21-10). New Jersey, NJ: Educational Testing Service.
Kim, Y. J., Dykema, J., Stevenson, J., Black, P., & Moberg, D. P. (2018). Straightlining: Overview of measurement, comparison of indicators, and effects in mail-web mixed-mode surveys.(2), 214?233.
Kingston, N. M. (2008). Comparability of computer-and paper- administered multiple-choice tests for K-12 populations: A synthesis.(1), 22?37.
Kline, R. (2013). Assessing statistical aspects of test fairness with structural equation modelling.(2-3), 204?222.
Kroehne, U., Gnambs, T., & Goldhammer, F. (2019). Disentangling setting and mode effects for online competence assessment. In H. P. Blossfeld & H. G. Roβbach (2ndEds.),(pp. 171?193). Wiesbaden, Germany: Springer VS.
Kr?hne, U., & Martens, T. (2011). 11 Computer-based competence tests in the national educational panel study: The challenge of mode effects., 169?186.
Kulik, J. A., Kulik, C.-L. C., & Cohen, P. A. (1980). Effectiveness of computer-based college teaching: A meta-analysis of findings.(4), 525?544.
Lee, J. A., Moreno, K. E., & Sympson, J. B. (1986). The effects of mode of test administration on test performance.(2), 467?474.
Lee, Y.-J. (2002). A comparison of composing processes and written products in timed-essay tests across paper-and- pencil and computer modes., 135?157.
Li, J. (2006). The mediation of technology in ESL writing and its implications for writing assessment.(1), 5?21.
Liu, J., Brown, T., Chen, J., Ali, U., Hou, L., & Costanzo, K. (2016).. Retrieved March 6, 2023, from https://files.eric.ed.gov/fulltext/ED599049.pdf.
Lynch, S. (2022). Adapting paper-based tests for computer administration: Lessons learned from 30 years of mode effects studies in education., Article 22.
Ma, W., & Guo, W. (2019). Cognitive diagnosis models for multiple strategies.(2), 370?392.
Magnus, B. E., Liu, Y., He, J., Quinn, H., Thissen, D., Gross, H. E., & Reeve, B. B. (2016). Mode effects between computer self-administration and telephone interviewer- administration of the PROMIS(?) pediatric measures, self-and proxy report.(7), 1655?1665.
McMullin, J., Varnhagen, C., Heng, P., & Apedoe, X. (2002). Effects of surrounding information and line length on text comprehension from the web., 19?29.
OECD. (2014).. PISA, OECD Publishing, Paris.
OECD. (2016).. PISA, OECD Publishing, Paris.
OECD. (2017).PISA, OECD Publishing, Paris.
Paleczek, L., Seifert, S., & Sch?fl, M. (2021). Comparing digital to print assessment of receptive vocabulary with GraWo-KiGa in Austrian kindergarten.(6), 2145?2161.
Poggio, J., Glasnapp, D. R., Yang, X., & Poggio, A. J. (2005). A comparative evaluation of score results from computerized and paper & pencil mathematics testing in a large scale state assessment program.(6), 1?31.
Pomplun, M. (2007). A bifactor analysis for a mode-of- administration effect., 137?152.
Pomplun, M., Ritchie, T., & Custer, M. (2006). Factors in paper-and-pencil and computer reading score differences atthe primary grades.(2), 127?143.
Porion, A., Aparicio, X., Megalakaki, O., Robert, A., & Baccino, T. (2016). The impact of paper-based versus computerized presentation on text comprehension and memorization., 569?576.
Powers, D. E. (1999).(ETS Research Report Series, No. 99-15). Princeton, NJ: Educational Testing Service.
Powers, D. E., Fowles, M. E., Farnum, M., & Ramsey, P. (1994). They think less of my handwritten essay if others word process theirs? Effects on essay scores of intermingling handwritten and word-processed essays.(3), 220?233.
Prisacari, A. A., & Danielson, J. (2017a). Rethinking testing mode: Should I offer my next chemistry test on paper or computer?, 1?12.
Prisacari, A. A., & Danielson, J. (2017b). Computer-based versus paper-based testing: Investigating testing mode with cognitive load and scratch paper use., 1?10.
Puhan, G., Boughton, K., & Kim, S. (2007). Examining differences in examinee performance in paper and pencil and computerized testing.(3), 1?21.
Raju, N. S., van der Linden, W., & Fleer, P. (1995). IRT-based internal measures of differential functioning of items and tests.(4), 353?368.
Ramesh, D., & Sanampudi, S. K. (2022). An automated essay scoring systems: A systematic literature review.(3), 2495?2527.
Robitzsch, A., Kiefer, T., & Wu, M. (2022).(TAM). R package. Retrieved April 26, 2023, from https://cran.r-project.org/web/packages/TAM/TAM.pdf.
Rosseel, Y. (2012). lavaan: An R package for structural equation modeling.(2), 1?36.
Rowan, B. (2010).(Unpublished doctorial dissertation). James Madison University, Harrisonburg.
Russell, M., & Haney, W. (1997). Testing writing on computers: An experiment comparing student performance on tests conducted via computer and via paper-and-pencil.(3), 1?20.
Russell, M., & Plati, T. (2002). Does it matter with what I write? Comparing performance on paper, computer and portable writing devices.(4), 1?15.
Russell, M, & Tao, W. (2004a). Effects of handwriting and computer-print on composition scores: A follow-up to Powers, Fowles, Farnum, & Ramsey., Article 1.
Russell, M., & Tao, W. (2004b). The influence of computer-print on rater scores., Article 10.
Schwarz, R. D., Rich, C., & Podrabsky, T. (2003, April).. Paper presented at the Annual Meeting of the National Council on Measurement in Education, Chicago, IL.
Seifert, S., & Paleczek, L. (2022). Comparing tablet and print mode of a German reading comprehension test in grade 3: Influence of test order, gender and language., 1?13.
Shealy, R., & Stout, W. (1993). A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DTF as well as item bias/DIF.(2), 159?194.
Terluin, B., Brouwers, E. P. M., Marchand, M. A. G., & de Vet, H. C. W. (2018). Assessing the equivalence of web-based and paper-and-pencil questionnaires using differential item and test functioning (DIF and DTF) analysis: A case of the Four-Dimensional Symptom Questionnaire (4DSQ).,(5), 1191?1200.
von Davier, M. (2005).(ETS Research Report Series, No. 05-16). Princeton, NJ: Educational Testing Service.
von Davier, M., Khorramdel, L., He, Q. W., Shin, H. J., & Chen, H. W. (2019). Developments in psychometric population models for technology-based large-scale assessments: An overview of challenges and opportunities.(6), 671?705.
Wainer, H. (1993). Some practical considerations when converting a linearly administered test to an adaptive format., 15?20.
Wang, S., Jiao, H., Young, M. J., Brooks, T., & Olson, J. (2007). A meta-analysis of testing mode effects in grade K-12 mathematics tests.(2), 219?238.
Wang, S., Jiao, H., Young, M. J., Brooks, T., & Olson, J. (2008). Comparability of computer-based and paper-and- pencil testing in K-12 reading assessments: A meta-analysis of testing mode effects.(1), 5?24.
Weigold, A., Weigold, I. K., Drakeford, N. M., Dykema, S. A., & Smith, C. A. (2016). Equivalence of paper-and- pencil and computerized self-report surveys in older adults., 407?413.
Wise, S. L., Freeman, S. A., Finney, S. J., Enders, C. K., & Severance, D. D. (1997, March).. Paper presented at the annual meeting of the National Council on Measurement in Education. Chicago, IL.
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020).. arXiv preprint arXiv:1904.09675.
Zhi, M., & Huang, B. (2021). Investigating the authenticity of computer-and paper-based ESL writing tests., Article 100548.
Ziefle, M. (1998). Effects of display resolution on visual performance.(4), 554?568.
為促進TME檢測方法的應用, 以下呈現能實現ANOVA、MCFA和DIF方法的R代碼示例。由于實現MEM方法的mdltm軟件不是開源軟件且研究者在技術報告中并未提供詳細的參數估計方法, 因此未囊括在本例中。接下來以組間設計為例, 給出檢驗題目層面TME的簡要流程。
附表1 基于R軟件的ANOVA、MCFA和DIF方法代碼示例

檢驗方法代碼示例 ANOVA目的: 比較每一題在PBT和CBT上的平均分# 加載所需程序包 -------library(TAM)# 數據準備 ----------------# 1 = PBT, 0 = CBT# nperson 為被試量(即圖1中N)# nitem 為題目數(即圖1中I)# response_raw 包含兩種測驗形式下的所有作答, 是一個[nperson, nitem]的矩陣# TMEbetween 用于儲存每道題在不同測驗形式下的顯著性結果# 創建數據框, 包含測驗模式標簽“mode”與相應的作答數據response_b <- data.frame(mode = c(rep(1, nperson/2), rep(0, nperson/2)),response_raw)# 數據分析 ----------------# 創建空矩陣用于結果存儲TMEbetween <- matrix(data = NA, nrow = nitem, ncol = 1)for (j in 1:nitem){# 對每一題比較兩種測驗模式下的得分差異(第一列是標簽, 因此從j+1開始)anova_item <- aov(response_b[, j+1] ~ mode, data = response_b)# 將結果儲存于矩陣相應位置TMEbetween[j, 1] <- summary(anova_item)[[1]]$`Pr(>F)`[1]}
續表

檢驗方法代碼示例 MCFA目的: 檢驗PBT與CBT下結果的測量不變性# 加載所需程序包 -------library(lavaan)# 模型檢驗 ----------------# (本示例限定所有題目都屬于同一個潛在特質)# 1. 檢驗形態等價(即結構不變性)# 2. 檢驗載荷等價(即弱不變性)# 3. 檢驗截距等價(即強不變性)# 4. 依次放松每道題目的載荷限制, 并將結果儲存于cfa_itemmodel <- 'trait =~ item1 + item2 + … + itemN' # 建立模型fit1 <- cfa(model, data = response_b, group = "mode") # 形態等價fit2 <- cfa(model, data = response_b, group = "mode", group.equal = "loadings") # 載荷等價fit3 <- cfa(model, data = response_b, group = "mode",group.equal = c("loadings", "intercepts")) # 截距等價cfa_item <- matrix(data = NA, nrow = nitem, ncol = 1) # 創建空矩陣for (j in 1:nitem){# 依次對每一題放松限制fit4 <- cfa(model, data = response_b, group = "mode",group.equal = c("loadings", "intercepts"),group.partial = paste("item", j, "~1", sep = ""))# 將結果儲存于矩陣相應位置cfa_item[j, 1] <- anova(fit3, fit4)$`Pr(>Chisq)`[2]} DIF (SIBTEST)目的: 分析參照組和目標組的結果差異# 加載所需程序包 -------library(mirt)# DIF檢驗 -----------------# beta_statistic用于儲存檢驗統計量的結果, 并且: # 表示不存在DIF# 表示存在中等程度DIF# 大于0.1表示存在較嚴重DIF (Puhan et al., 2007)# suspect為可能存在TME的題目集合# anchor為不存在TME的錨題集合#(當不指定錨題時, 可令除待檢題目外的所有題作為錨題集)anchor <- c(1, 2, 3) # 設置錨題為第1、2和3題suspect <- c(1:nitem)[-anchor] # 除去錨題, 即得到可能存在DIF的題目集合beta_statistic <- matrix(data = NA, nrow = length(suspect), ncol = 1) # 創建空矩陣for (j in 1:length(suspect)){# 對每一題進行DIF檢驗dif_item <- SIBTEST(response_b[, -1], response_b$mode,match_set = anchor, suspect_set = suspect[j])# 將結果儲存于矩陣相應位置beta_statistic[j, 1] <- dif_item$beta[1]}
Test mode effect: Sources, detection, and applications
CHEN Ping, DAI Yi, HUANG Yingshi
(Collaborative Innovation Center of Assessment for Basic Education Quality, Beijing Normal University, Beijing 100875, China)
Test mode effect (TME) refers to the difference in test function caused by the administration of the same test in different test modes. The existence of TME will have an impact on test fairness, selection criteria and test equating, so it is of great significance to accurately detect and interpret TME. By systematically sorting out the source, detection (including the experimental design and detection methods) and research results of TME, the methodology of TME research is comprehensively demonstrated. Further interpretation of the TME model, expansion of the test modes in TME research, and application of TME research results to large-scale educational assessment programs in China, are important future development directions in the field of TME.
test mode effect, test fairness, measurement invariance, computer-based testing
B841
2023-01-10
* 國家自然科學基金面上項目(32071092)、北京師范大學中國基礎教育質量監測協同創新中心自主課題(2022-01-082-BZK01)資助。
陳平, E-mail: pchen@bnu.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂探索(2022年2期)2022-05-30 21:01:37
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
光學精密工程(2016年6期)2016-11-07 09:07:19
