基于知識和改進深度學習的網絡主題文本快速過濾方法
2023-10-10 06:24:42劉麗娟
科學與信息化 2023年19期
劉麗娟
國家計算機網絡應急技術處理協調中心上海分中心 上海 201315
引言
網絡主題文本過濾是一個復雜的課題,目前存在手段單一、效率低下等問題。現階段研究大部分依賴人工手段,效率低下,并且鑒于不同人思維存在局限性,評判標準不同[1],導致主題文本的過濾結果有差異。此外,自動化手段不能充分利用已有的經驗知識[2],容易造成遺漏、誤判的現象。常用方法有用推薦系統[3]進行過濾,通過word2vec[4]進行內容識別,用決策樹[5]識別敏感詞變體,但上述方法適用領域有限。因此,亟須一種智能方法將“被動”查找主題文本轉變為“主動”關聯知識、經驗,提高網絡主題文本的過濾效率。
目前知識圖譜[6]理論為過濾文本主題信息提供良好方法,深度學習理論[7]為模型訓練提供了良好途徑,二者結合能智能化地實現網絡主題文本過濾。
本文提出一種基于知識和改進深度學習的網絡主題文本快速過濾方法。首先對主題文本進行理解,融合知識圖譜作為內部知識嵌入;其次聯系上下文,對待查找主題文本進行語義擴展,作為外部知識嵌入;最后用改進深度學習模型處理主題詞向量,依據目標定位主題文本。實驗表明,該方法鑒別網絡主題文本的準確率較高,縮短運算處理時間。
創新點在于:①在融合內部知識基礎上,知識圖譜使理解的角度更為全面;②嵌入上下文外部知識擴展語義,使主題過濾過程更為準確;③融合上述內、外部層次知識作為深度學習模型訓練向量,使模型識別更為高效。
1 基于知識嵌入的主題文本分析
網絡主題文本鑒別是一個反復迭代的過程,主題文本知識是一個不斷豐富完善的過程,需用知識嵌入方法解決。知識嵌入是知識產生者與知識接受者之間交互的重要手段。知識嵌入分為內部知識嵌入和外部知識嵌入。
1.1 內部知識嵌入(嵌入知識圖譜)
內部知識嵌入指知識圖譜的實體關系嵌入。傳統的主題文本識別方法難以綜合實體間關系,嵌入實體關系能完整語義表示知識單元,準確識別主題文本。
實體關系以知識圖譜形式進行嵌入。知識圖譜旨在描述真實世界存在的各種實體或概念及其關系,構成語義網絡圖,節點表示實體或概念,邊由屬性或關系構成。主題信息在知識圖譜中直觀表示為KG=<head,relation,tail>,其中head、tail分別是三元組的頭實體、尾實體,是KG的實體集合,relation={r1,r2,……,r|R|}是KG的關系集合,包含R種不同關系。使用Neo4j圖數據庫構建知識圖譜,經過規范化存儲能清晰地描述知識。
核心步驟是整合結構化數據、實體抽取和關系抽取非結構化數據,經過初步層次知識表示,將實體關系轉化為連續的向量空間,經過知識推理,發現知識,在保留知識圖譜的原有結構基礎上完整嵌入實體關系。
對文本進行分詞、詞性標注及主題實體識別,去除停用詞和無意義的單字,得到一組包含n個描述主題特征的關鍵詞。一條由n個特征詞構成的主題特征為x=[ , ,…],其中 是完整主題文本中第i個位置上的詞匯,將特征關鍵詞轉換為詞向量,映射為對應的d維表示向量
1.2 外部知識嵌入(嵌入上下文)
外部知識嵌入指嵌入上下文。由于文本在不同語境下含義不同,故需研究上下文,以便更準確地定位主題信息。結合主題文本過濾的范圍、對象,借助關聯關系,嵌入上下文進行語義擴展。主要過程是,定義主題文本上下文實體e,對上下文進行數據預處理,包括分詞處理、去停用詞、詞頻統計等,加入約束條件,獲得提取主題特征結果的上下文向量。實體e的上下文向量context(e) ={ei|<e,r,ei>∈TopicInfoKG},是主題知識圖譜TopicInfoKG相鄰一跳的結點集合,實體關系r為上下文實體提供補充知識,擴展主題語義,提升主題的識別效率。
2 改進深度學習網絡主題文本過濾模型
在知識嵌入基礎上,建立改進深度學習網絡主題文本過濾模型,如圖1,共有四階段,第一階段是數據預處理,主要生成神經元網絡輸入數據和嵌入矩陣;第二階段是神經元網絡訓練;第三階段是特征組合;第四階段用多重過濾機Multilayer Perceptron(MLP)實現分類。

圖1 模型處理階段
網絡輸出層用Sigmoid函數進行二分類,定義域為0到1開區間,根據0.5進行分界,若結果大于等于0.5,說明為正樣本,否則為負樣本,從而實現分類,過濾主題文本信息。計算公式如下:
知識操作具體過程是,從知識提取中得到每個詞語 對應的實體向量∈、實體上下文向量∈,k是實體嵌入的維數。對主題描述文本輸入包括主題特征向量詞語-實體對齊后的實體向量,實體上下文向量詞語-實體對齊轉換函數g(e)=tanh(Me+b),通過上述操作,將特征連接在一起,輸入到詞向量空間,保持原有空間關系。主題文本x用e(x)表示。Softmax分類器輸入是主題描述文本e(x),經過歸一化得到主題文本在第k種主題的輸出概率,不斷訓練直到模型符合擬合要求為止。
3 實驗分析
用準確度Accuracy、精度Precision、召回率Recall和F1值指標分別評價主題文本檢測方法性能,比較關鍵詞法、互信息法、深度學習法、基于知識嵌入的改進深度學習方法。TP表示正確分類下正樣本數,TN表示正確分類下負樣本數,FP表示負樣本誤分類為正樣本數量,FN表示正樣本誤分類為負樣本數量,公式分別如下:
針對“進口博覽會”主題,對比上述方法,比較F1值,可知本文的知識嵌入改進深度學習法的F1值最佳,如圖2。
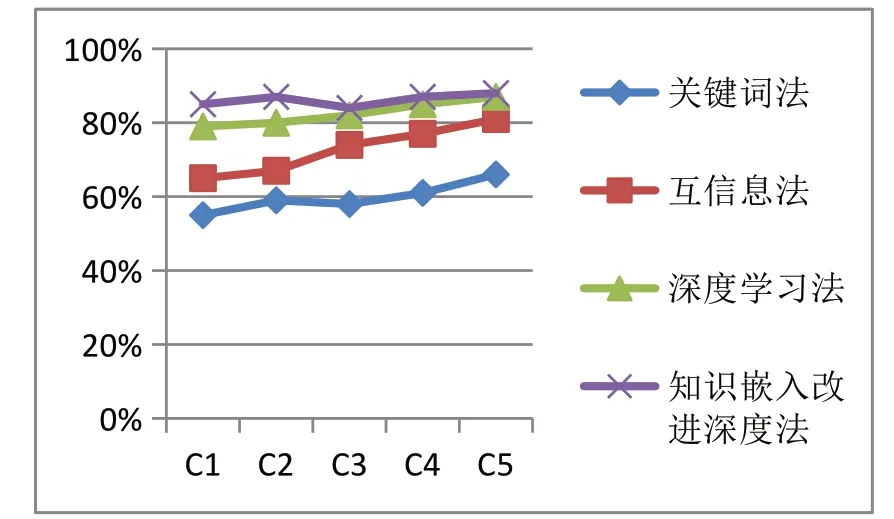
圖2 不同方法的F1值比較
以響應耗時為檢驗指標,比較用不同方法處理100個、200個、400個……個節點的應用性能,如圖3所示。可看出隨著主題信息節點數量不斷增加,不同算法響應耗時不斷減少。關鍵詞法、互信息法、深度學習法三種算法響應耗時均在2s以上。而知識嵌入改進深度學習法的處理耗時始終在1s內,平均處理耗時在0.9s左右。綜上可看出,本文提出的方法能節省運算處理時間,實現網絡主題文本準確、快速過濾。
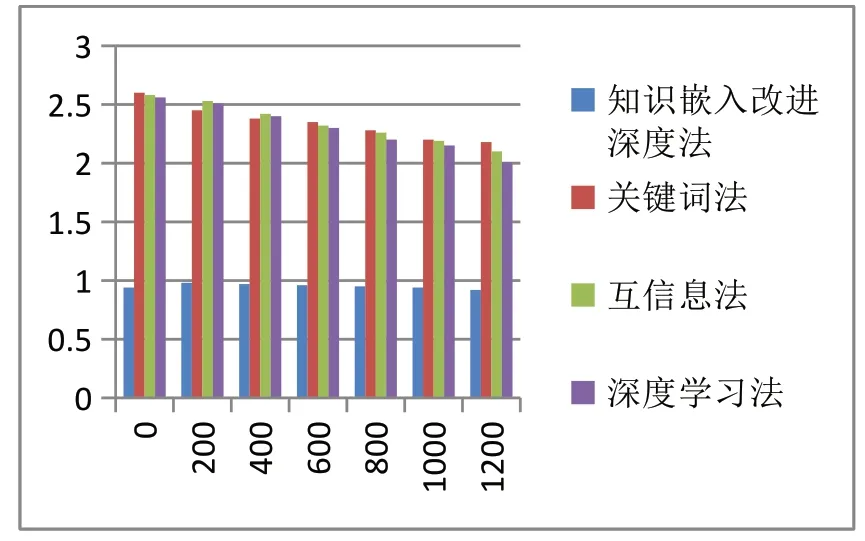
圖3 不同方法的耗時響應時間
4 結語
本文提出一種基于知識和改進深度學習的網絡主題文本快速過濾方法。貢獻有:①利用圖譜嵌入實體關系,獲得主題內部知識;②通過嵌入上下文外部知識,豐富并擴展語義范圍;③一個智能的改進深度學習網絡主題文本快速過濾模型。
下一步工作重點將關注知識圖譜嵌入的效率,重點考慮如何使知識描述更為豐富完整,并在此基礎上加強擴展能力,增強處理能力。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
