基于詞性標注規則的馬鈴薯文獻信息抽取方法
2023-10-12 09:45:44王騰陽趙小丹胡林
科學技術與工程 2023年27期
王騰陽,趙小丹,胡林
(中國農業科學院,農業信息研究所,北京 100081)
馬鈴薯是中國第四大糧食作物,除了能夠兼做糧食、蔬菜和飼料,還有很多加工用途,產業鏈較長,有很大的潛力增產增收[1]。馬鈴薯育種研究人員育成新品種后會以論文的形式發布研究成果,內容通常包括馬鈴薯新品種的選育過程、特征特性、抗病性、品質分析等[2]。由于論文采用自然語言編寫,缺少結構化的表述信息,積累了大量的非結構化文本數據,因此大規模的育種文獻給人工整理品種數據帶來了極大的挑戰[3]。因此,亟需利用自然語言處理等技術自動分析馬鈴薯育種文獻文本,抽取文本中的品種名、親本、株高株型、抗病性等屬性。這些信息可以用來搭建馬鈴薯遺傳育種數據庫,為馬鈴薯智能育種決策提供基礎服務。
信息抽取指的是從自然語言文本中抽取指定類型的實體、屬性等信息,并形成結構化數據的文本處理技術[4]。張萌等[5]對城市軌道交通安全事件案例的自由文本制定知識元屬性、構建詞庫,并對文本進行分詞,利用正則表達式抽取事件信息,但因其抽取規則制定不完善,部分知識元抽取效果不理想。譚永濱等[6]研究提取交通微博文本信息的方法,提出基于線性參照方法構建位置表達模式庫,并將模式庫表達為Trie樹,利用有限狀態機匹配微博文本中位置表達模式,識別并提取微博文本中的位置信息,其錯誤結果主要來自未登錄地名與模式不確定性。劉時翔[7]研究半結構化金融文本信息抽取,用正則表達式抽取電話號碼等簡單項信息,利用行文格式、分隔符號等特點,用隱含馬爾柯夫模型(hidden Markov model,HMM)模型抽取復雜項信息,造成抽取結果錯誤的因素有文本塊的邊界難以劃分,大量過渡數據使文本塊數據連續性較差,合同結構隨意性較大等。Feng等[8]提出基于主題識別和命名實體識別的信息抽取方法,提取新冠疫情通報文本信息的風險區域和疫情軌跡信息。Martin[9]研究使用深度學習的方法識別企業發票的結構化文本,為企業節約人工提取成本。
雖然馬鈴薯育種文獻文本描述形式多樣,但論文作者對馬鈴薯特征特性的描述有規律可循,如“株高50 cm左右”“干物質含量15.4%”“皮色淡黃”“肉色白色”等,目標詞可以歸類為某一具體詞性,并且相對于實體間的關系,任務更專注于提取實體的屬性值,所以可使用自然語言處理的方法,將待處理文本進行分詞,對分詞結果進行詞性標注,根據語句中的詞性獲取目標詞。因此,現面向馬鈴薯種質資源領域,基于文本處理的分詞和詞性標注結果,編寫規則庫,根據規則對符合詞性的目標詞實現快速匹配,據此提出基于詞性標注和規則庫的馬鈴薯育種文獻信息抽取模型,以期實現馬鈴薯育種文獻中的種質資源信息結構化。
1 文獻信息抽取
1.1 實驗環境
本實驗編程語言使用Python 3.8。自然語言處理技術使用HanLP[10],包括中文分詞、詞性標注等。具體實驗流程如下文所述。
1.2 數據預處理
PDF文檔分為兩類,一類是文字內容可以完整讀取的正常文檔;另一類是文字讀取與預期不符的文檔。文字讀取與預期不符的情況包括但不限于數字被符號代替、段落的行順序錯亂等。雖然光學字符識別(optical character recognition,OCR)可以實現該類文檔的文本化,但由于期刊論文正文存在左右排版方式,使用OCR自上而下地識別會造成文字順序混亂。因此需要先分割文檔圖像的各個文本塊,將分割出的圖片按閱讀順序排序,通過OCR獲取圖片內的文字并進行匯總。
首先將待處理的PDF文檔頁面轉化為文字為白色、背景為黑色的反二值圖像,使用游程平滑算法將文字連通,形成連通圖。游程平滑算法[11]可以應用于文檔圖像分割處理,該算法對一行(列)上的兩個黑色像素點間的距離進行判斷,如果兩個相鄰黑色像素點間空白像素的個數小于設定的閾值時,就將這兩點之間的空白像素點全部填黑。當算法的水平閾值Thor=3、垂直閾值Tver=3時,運行效果如圖1所示。

圖1 游程平滑算法示意圖
通過開源計算機視覺庫(OpenCV)中的相關方法,檢測經過游程平滑算法處理后的圖像中各個連通圖的矩形邊框,獲得其邊緣坐標。根據得到的坐標,截取源PDF文檔頁面圖像中的對應位置,按照從左到右、從上到下的順序,依次命名保存文字圖像,作為OCR文字識別的輸入源。處理流程如圖2所示,最終得到的文本塊分割結果,用矩形邊框標注。

圖2 處理文獻過程圖
由于直接提取PDF文檔或通過OCR文字識別提取文檔均存在全角字符、語句中存在多余換行符以及文字間存在多余空格等問題,因此需要先將文本內容按順序進行如下處理:①全角字符轉化為半角字符;②去除文字之間多余空格;③刪除文字內換行符。
1.3 基于詞性標注和規則庫的信息抽取方法設計
規則庫使用Json格式保存在文件。每一對鍵值對中,鍵表示抽取項的名稱,值表示抽取項的規則。規則的設計包含下面五類:①關鍵詞;②按照詞性標注的抽取規則;③目標詞中的屏蔽詞;④抽取關鍵詞所在關鍵句中不允許出現的詞;⑤提供預設詞進行匹配(以鍵值對表示,鍵表示匹配原始文本中的詞,值表示抽取結果中展示的詞)。
使用關鍵詞結合正則表達式,獲取目標抽取項所在語句,在獲取的所有語句列表中,刪除包含不允許出現的詞的語句,隨后對語句進行分詞、詞性標注,通過抽取規則定位關鍵詞位置和目標抽取項位置。對于一些表述不規律、不能使用分詞和詞性標注方法獲取的,例如,抗病性只有抗、不抗、高抗等幾種表述,但由于其表述時有多種疾病混在一起,很難通過分詞的方法來獲取,這種情況使用匹配預設詞并結合判斷目標項與預設詞的距離之間的距離的方法獲取目標項。信息抽取流程圖如圖3所示。

圖3 信息抽取流程圖
1.3.1 關鍵詞規則設計
關鍵詞用于在待抽取文本中提取目標項所在語句,根據關鍵詞的位置,在語句中使用基于詞性標注規則和預設詞的方法實現抽取目標項。用戶建立關鍵詞庫,需要根據提取項,在待提取文本中找到相關表述。用戶在人工校對提取結果時若發現抽取項的新關鍵詞,可以將其添加至關鍵詞庫,從而優化提取效果。使用正則表達式獲取關鍵詞所在語句,具體方法為從關鍵詞開始向前(后)直到達到20個文字或者遇到標點符號為止。本文使用關鍵詞定位抽取項所在文本句,對于關鍵詞規則的設計,考慮如下幾種情況:①關鍵詞之間是“或”的關系;②關鍵詞之間是“與”的關系;③關鍵詞之間是互斥的關系;④關鍵詞之間是上述幾種關系結合的關系。
關鍵詞規則如“A(BC,D,^E)/F/G”,表示提取的文本句需要符合包含A或F或G;在包含A的情況下,需要滿足同時包含B或C,以及包含D,但不能包含E。目標提取項所在句可能涉及多個不同的關鍵詞,在上述示例規則中,A、F、G稱為主關鍵詞,每一個主關鍵詞后面允許加括號,括號內的詞稱為次關鍵詞,與主關鍵詞的關系和“邏輯與”相同,表示提取語句需要同時包含主關鍵詞和所有的次關鍵詞。主關鍵詞之間以 “/”分割,次關鍵詞之間以 “”分割,與“邏輯或”相同。用“^”符號表示不允許提取語句中包含的關鍵詞。
1.3.2 分詞與詞性標注
分詞與詞性標注使用HanLP自然語言處理工具包。首先將提取的關鍵詞語句進行分詞。在進行詞性標注前,對分詞結果進行預處理有利于后續的信息抽取過程。
對分詞結果的預處理主要為合并部分分詞內容。例如,中國馬鈴薯品種的命名方式大多為“X薯X號”,在分詞時通常會將品種名中的“X薯”和“X號”分開,在進行信息抽取前將其合并會提高抽取的準確率。同理,對單引號、雙引號等內部無需分詞的內容統一進行合并,可以有效改善抽取效果。另外,需要添加關鍵詞到自定義詞典,防止關鍵詞被分詞影響后續抽取過程。
詞性標注使用CTB(chinese treebank)標注集(表1)[12],結合自定義詞庫對分詞結果進行詞性標注。
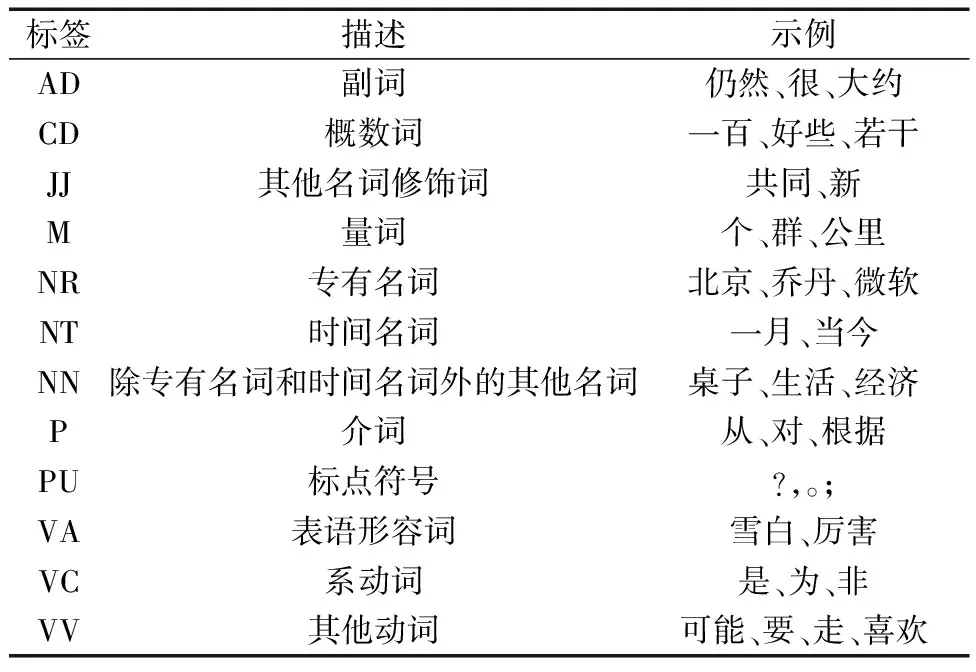
表1 部分CTB詞性標注集
1.3.3 基于詞性標注的規則庫設計
規則基于分詞和詞性標注結果制定,在規則中,每一個匹配項使用CTB詞性標注集中的標簽代替。每一條規則都要包含作為提取依據的關鍵詞和需要提取的目標詞。關鍵詞使用“KEYWORD”代替,目標詞使用“TARGET”代替,用“ANY”代替兩個標簽間任意數量、任意詞性的標簽。抽取規則允許在同一位置有多種詞性標簽,標簽間用“/”分割,因為目標詞有可能被分詞,采用的解決方法是在規則中使用多個“TARGET”標簽,在抽取完成后將抽取的多個“TARGET”進行合并得到抽取結果。“TARGET”標簽設計為可以指定特定的詞性標簽或不允許為某個特定詞性標簽。語法同關鍵詞的設計類似,指定特定的標簽間用“/”分割;在標簽前加“^”符號表示不允許抽取某個特定標簽。
抽取過程如下:①定位在規則中關鍵詞和目標詞的所在位置;②定位關鍵詞在分詞結果中的位置;③迭代檢查詞性標注結果是否符合規則;④合并、返回抽取結果。
設關鍵詞在分詞結果的位置為Pt,在規則中的位置為Pr,以規則中包含的元素個數N作為迭代次數,用i表示,即i=0,1,2,…,N-1。
詞性標注結果中迭代索引映射為
Index=Pt-Pr+i
(1)
每次迭代都要判斷詞性標注結果是否符合規則,具體的判斷依據有:①索引是否位于有效范圍內;②詞性標注結果是否在規則內;③索引是否為特殊情況(例如:索引為關鍵詞位置時,不要求②成立)。當不滿足上述條件時,跳出迭代并返回空字符串。抽取數據文本樣式如圖4所示(關鍵詞以加粗斜體表示)。
部分抽取語句示例如表2所示,在“原語句”列中,關鍵詞為加粗字體。
1.3.4 基于預設詞的抽取規則設計
在馬鈴薯育種文獻中,對于如抗病性的表述方法比較多樣,使用詞性標注的抽取方法不能滿足需求,但需要提取的目標詞的表述較為統一。例如“抗晚疫病、PVX、PVY”,單純使用詞性標注的方法雖然可以獲得該品種對晚疫病的抗性結果,但對PVX和PVY的抗性難以制定規則獲得相關表述;又如“植株抗晚疫病、感輕花葉和重花葉病毒病”和“晚疫病:高抗”兩種表述中,若只根據第二種表述制定規則“關鍵詞(KEYWORD),標點符號(PU),目標詞(TARGET)”,則在第一句明顯會匹配錯誤的結果,對于此類使用詞性標注規則方法難以提取,且需要提取的目標詞表述較為統一的語句,使用基于預設詞的抽取方法。
預設詞使用鍵值對保存,鍵用于保存關鍵詞語句中的匹配詞,值用于保存給用戶輸出結果的詞。
抽取過程如下:①獲取關鍵詞、預設詞在句中位置;②在語句中所有的預設詞里,尋找距離關鍵詞最近的一個,添加進結果集。
1.3.5 抽取結果的匯總與清洗
完成通過基于詞性標注和基于預設詞的兩種抽取方法后,將兩種抽取結果添加進一個集合中進行匯總。通過詞性標注的抽取方法可能將不相關的詞也統計入抽取結果,因此需要將匯總后的抽取結果匹配規則庫中的違禁詞進行篩選,從而得到更加準確的抽取結果。
2 實驗結果及分析
2.1 數據來源與評價標準
測試集為馬鈴薯育種文獻115篇,文獻為PDF格式,通過人工標注抽取項和正確的抽取結果,針對每篇文獻內容包含的馬鈴薯品種名稱、親本、株型株高、皮色肉色、抗病性等共20個數據項進行信息抽取實驗。由于部分文獻中不包含全部抽取項,因此抽取項數目總計1 490項。由于文獻來自不同的年代,作者對馬鈴薯性狀描述的側重點不同,大部分文獻不包含全部的20個抽取項。測試集文獻的抽取項數目分布如圖5所示。
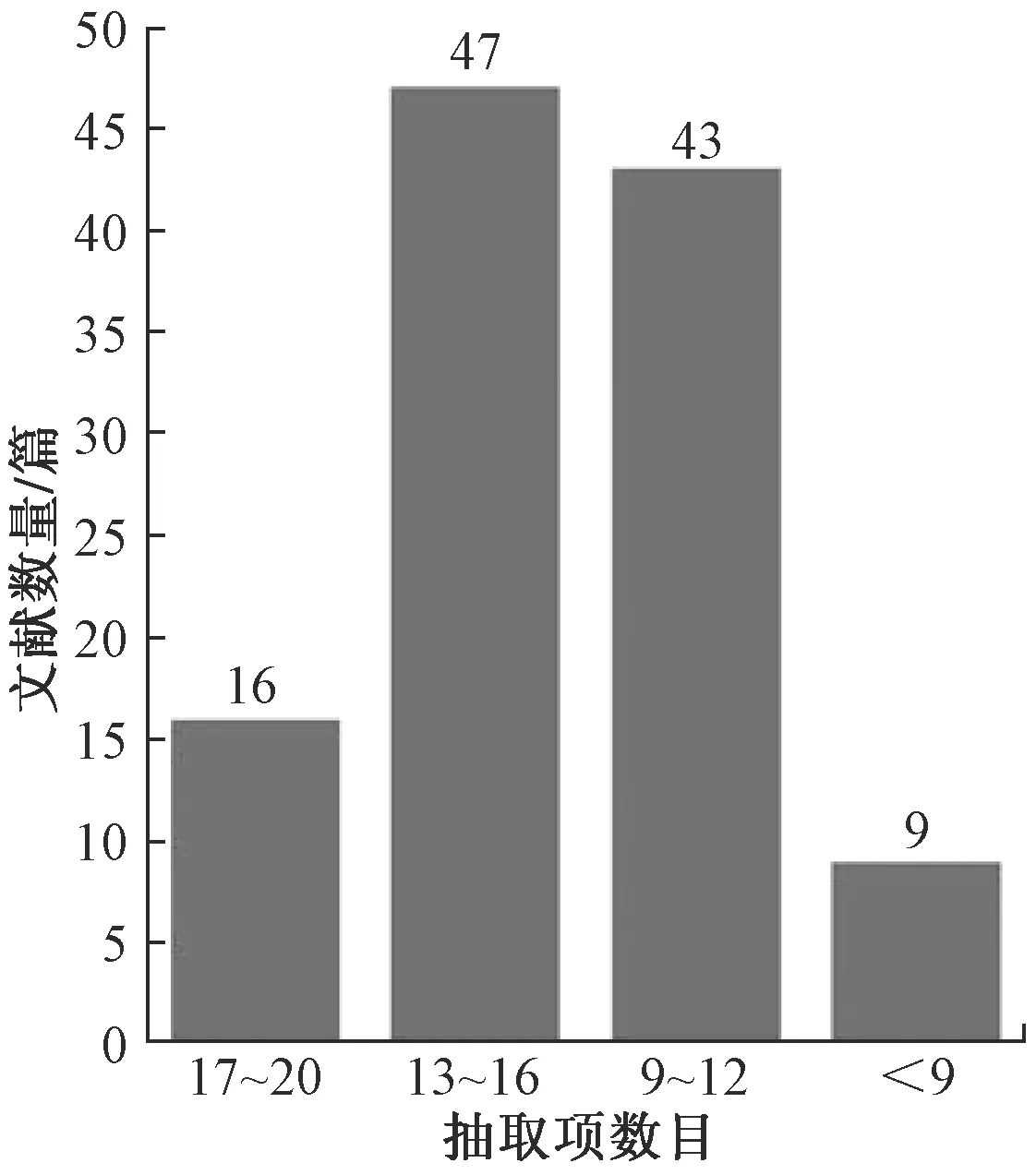
圖5 測試集抽取項數目分布
文本信息抽取總共分為四種情況:TP表示文本中有數據,并且成功抽取到數據;FP表示文本中缺失數據,但抽取到了數據;TN表示文本中缺失數據,也沒有抽取到數據;FN表示文本中有數據,但沒有抽取到數據。以精確率P、召回率R和F作為性能評價標準,計算公式[13]為
(2)
(3)
(4)
2.2 方法結果對比
為了進一步驗證本文方法的有效性,使用了傳統信息抽取方法作為對比。作為對比的基于普通規則的傳統信息抽取方法與本文基于詞性標注和預設詞信息抽取方法的文本預處理、關鍵詞與規則庫的處理方式相同,主要區別在于信息抽取部分。傳統信息抽取方法使用正則表達式定位關鍵詞,以某個指定字符作為邊界,截取關鍵詞到指定字符范圍之間的內容作為抽取結果。各方法的抽取結果統計見表3。

表3 抽取結果統計
在普通規則方法中,抽取成功的比率達87.38%,能夠有效抽取信息,但其準確率僅為53.89%,表明該方法提取有近一半不需要的干擾信息。基于詞性標注規則中,抽取成功的。普通規則的抽取方法使用正則表達式提取目標信息,該方法的局限性在于注重于語句的字數、結構是否合規,缺少對文本內容的判斷,導致提取到過多的無效信息。本文使用的基于詞性標注規則彌補了普通規則的缺陷,使用詞性標注判斷文本內容是否有效,達到去除無效信息的效果。
本文抽取結果評價如圖6所示,由圖6可知,不論是基于詞性標注規則還是基于預設詞的抽取方法,召回率接近甚至達到100%,但準確率在基于詞性標注規則中為82%,在基于預設詞中為84%,本文所使用的基于詞性標注規則的方法能夠有效提取馬鈴薯育種文獻中所需信息,但提取出不需要的結果的數量遠遠超過提取失敗結果的數量。

圖6 信息抽取結果評價
通過分析提取結果得知,提取失敗的原因主要有以下幾種。
(1)分詞結果不準確;在分詞時,有時會存在目標詞被分詞和不被分詞兩種情況,在制定規則時會針對兩種情況分別制定,例如,在處理品種名“晉薯1號”時,會將其分詞為“晉”“薯”和“1號”三個部分;但在處理“威芋3號”時,會將其分為“威芋”和“3號”兩個部分,導致在規則的制定和分詞結果的預處理上難以進行處理從而無法準確提取品種名。
(2)文獻中涉及的品種不止一個,還涉及對其親本的描述;在有些文獻中提到其親本信息,例如在“天薯13號[14]”的描述文獻中,不僅有對“天薯13號”的特征描述,還存在對其母本和父本的株型、高度、淀粉含量和皮色肉色等特征的描述,模型會將其特征描述全部提取作為結果,對正確的結果造成干擾,因此造成召回率不變,準確率降低。
(3)部分文獻所屬的期刊在排版中,存在有其他文章的頁面,導致提取到其他文章中的內容。
(4)部分年代較為久遠的育種文獻,文檔信息化程度較差,不論是直接提取PDF文檔文字,還是使用OCR對其內容進行文字識別,文字提取效果均不理想,造成文獻信息提取效果較差。
3 結論
以馬鈴薯育種文獻為對象,提出一種基于詞性標注和規則庫的信息抽取模型,結果表明,總體正確率達82.97%,召回率達99.73%,F值為90.58%,因為抽取結果需要人工進行校對再輸入進育種數據庫,所以希望模型在具有較高的準確率的同時,擁有更高的召回率,從而能減輕人工錄入的工作量,因此本文使用的抽取模型能夠有效提取文獻內信息。該模型的重點在于分析分詞與詞性標注結果,因此該抽取模型具有通用性,只需編寫所需規則庫,就能應用到其他領域的抽取任務。該模型不僅能完成文本內容的信息抽取,而且還實現了文本圖片的文本塊分割,根據頁面閱讀順序進行排序,使用OCR文本識別提取文字內容完成信息抽取。通過分析抽取結果,得出造成抽取錯誤的原因主要有以下幾種。
(1)分詞結果不準確。
(2)論文中涉及的品種不止一個,作者也對其親本品種有所描述,造成抽取結果中有其他品種的屬性信息。
(3)期刊將其他文章與待抽取文章排版到同一頁面,抽取到其他文章的信息。
(4)提取PDF文件內文字與預期不符等。
未來將實現通過識別抽取屬性與主體間的關系,抽取論文內所有主體的屬性信息,提高抽取準確率的同時,獲得更多品種的種質資源數據;針對農業領域訓練或微調分詞和詞性標注模型,改善語句分詞效果,進而提高信息抽取的準確性。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2017年11期)2018-01-03 20:59:57
中華手工(2017年2期)2017-06-06 23:00:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
