
針對集群攻擊的飛行器智能協同攔截策略
2023-10-17 04:01:26高樹一林德福鄭多胡馨予
航空學報 2023年18期
高樹一,林德福,鄭多,*,胡馨予
1.北京理工大學 宇航學院,北京 100081
2.北京理工大學 徐特立學院,北京 100081
隨著現代作戰理念向體系轉變,單體武器裝備發揮的作戰效能正變得愈加有限,未來智能化戰爭將是多智能體間的協同作戰,群體間的博弈對抗將貫穿戰爭始末。針對復雜作戰環境中的集群目標攔截問題,需要考慮集群目標可能的突防手段,研究立體化多層次的智能協同攔截策略,以提升攔截成功率和任務效能。
集群目標的協同攔截可以分為2個子問題:一是多目標攔截的目標分配問題;二是攔截方集群協同打擊問題。針對以上2個問題,國內外相關研究人員已開展了一定的研究工作。多目標攔截的目標分配問題屬于任務分配問題,文獻[1]利用脫靶距離和視線角速率構造了適合于多對多作戰的攔截概率函數,提出了一種具有固定和自適應分組約束的任務分配方法,簡化分配過程進而提升了作戰效能。文獻[2]通過攻防雙方作戰態勢設計評估模型,進而結合強化學習算法提出了一種智能任務分配方法,合理的評估模型搭配強化學習智能算法不僅簡化了分配問題,同時賦予分配算法智能屬性。文獻[3]提出了一種協作的滾動優化控制器,所提出的控制器通過在規劃范圍內估計可收集的獎勵來順序地解決優化問題,并對行動范圍執行控制,從而實現攔截任務分配。文獻[4]提出了一種預測規劃攔截的方法,該方法允許在檢測到目標軌跡變化時重新規劃攔截路徑,可以高效的解決協同攔截問題。文獻[5]提出了一種基于動態態勢評估的多目標任務分配方法,該方法綜合考慮攔截集群的協作能力,并采用遺傳算法對攔截目標分配策略進行優化,通過仿真驗證了算法的有效性。文獻[6]結合路徑長度成本以及集群機動成本提出了一種目標分配方案,并通過創建Delaunay加權樹并在樹中搜索最優路徑,實現了基于航路點的作戰路徑規劃,該文獻將目標分配問題表述為基于多約束問題的路徑搜索問題,進而優化目標分配策略。上述文獻在群目標任務分配方面具有較好的實踐意義,在協同攔截作戰中預先制定的目標分配策略雖然能夠簡化攔截問題,但是所消耗的時間于戰爭是不利的,未來戰場迫切需要將分配方法融合在協同打擊中,進而提高作戰效率。
在協同攔截機動策略方面,目前開展的研究主要包括打擊時間協同、角度約束協同和智能協同3種攔截方式。關于基于打擊時間協同的集群攔截策略,國內外相關學者進行了大量的研究。文獻[7]通過分析多飛行器指定時間和預估飛行時間的誤差作為反饋,提出了系數隨時間變化的多飛行器協同攔截方法,該方法具有一定的自適應性,能夠結合制導控制的不同階段實時調整系數,進而提升攔截精度。文獻[8]基于協同控制理論,設計了一種結合空間協同和時間協同的攔截制導律模型,實現多飛行器間視線角在規定時間內收斂到期望值,該方法綜合考慮時間空間約束,在此基礎上設計相應的策略模型。文獻[9]基于超螺旋控制方法提出了攻擊時間控制協同攔截制導方法,該方法基于滑膜控制設計攔截策略,在考慮攻擊時間約束的前提下提升制導精度,具有較強的工程實用性。文獻[10]提出了一種能夠依據當前作戰態勢實時調節攻擊時間的協同攔截策略,并且通過仿真實驗驗證了算法有效性。有關時間協同的方法是協同作戰的研究重點,但區別于不同的戰場情況,與角度有關的協同方法有時更為重要。關于基于角度約束協同的集群攔截策略,相關研究人員開展了一定的研究。文獻[11]基于最優控制的方法設計了帶有角度約束的協同制導策略,通過為飛行器預先設定攔截角度進而控制集群以指定的角度構型攔截目標,該方法綜合考慮角度約束和制導精度,具有一定的工程實用性。文獻[12]將前置角和彈目距離綜合考慮,設計出一種領從式協同攔截方法,該方法依據前置角變化設計制導率,同時融合領從式協同策略,對攔截效能有較為積極的作用。文獻[13]在考慮落角約束的基礎上設計了自適應的協同攔截制導方法,該方法能夠結合作戰場景的變化調節協同制導策略,進而實現飽和攻擊。文獻[14]提出了一種將視線角速率與二階滑模技術相結合的角度約束協同制導方法,具有較強的工程實用性。文獻[15]基于非奇異終端滑模控制理論設計出一種能夠以期望撞擊角攔截機動目標的協同制導方法,該方法作為滑膜控制的變體,較好的適用于協同作戰中,具有良好的工程實用性。文獻[16]研究了具有無向通信拓撲結構的協同制導問題,提出了一種分布式協同制導策略,以實現具有碰撞角約束的協同打擊。文獻[17]基于非線性問題轉化為線性二次微分的方法,提出了一種考慮碰撞角和時間約束的次優制導方法,仿真結果表明該方法適用于導彈齊射發射作戰場景。上述角度協同方法考慮落角約束、視線角約束等限制,對制導控制方法進行了理論推導。綜合分析時間和角度協同2種方法,由于復雜戰場中狀態空間維數的上升,傳統的基于最優控制、非線性控制等的制導方法將難以適應。
近年來人工智能技術發展迅速,部分學者針對基于智能算法的協同攔截策略設計問題展開相關研究。文獻[18]將飛行器對抗任務離散化后,提出了一種能夠應對復雜環境的智能對抗策略,該方法采用分層強化學習的方法,有效的提升了模型訓練的收斂速度,解決了群體對抗中的稀疏獎勵問題。文獻[19]基于多智能體強化學習理論設計了一種多飛行器攻防對抗自主決策算法,在無人飛行器集群協同對抗環境中進行了仿真驗證。文獻[20]利用粒子群算法,基于協同博弈理論求解了多飛行器博弈過程的納什均衡,該方法在不使用任何線性化近似的情況下,使問題的基本收益最大化,從而顯著提升導彈性能。文獻[21]基于強化學習算法提出了一種適應于多智能體博弈的狼群優化算法,該方法中學習率可以根據環境變化自主調整,通過仿真實驗表明狼群優化算法在多智能體隨機博弈中的合理性。文獻[22]基于啟發式蟻群算法提出了一種多飛行器的協同攔截過程中的路徑規劃方法,該算法通過求解友機對目標的最優分配來確定機動策略,仿真實驗表明該方法優于普通的蟻群算法,是一種適用于協同作戰的高效算法。文獻[23]基于深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法設計了一種飛行器的制導控制一體化方法,該方法綜合考慮飛行器的運動學和動力學特性,將強化學習算法與制導控制原理相結合,提升機動策略的作戰效能。文獻[24]結合協同進化算法和模型預測控制方法設計了一種飛行器軌跡規劃方法,該方法用于處理飛行器編隊控制問題,相比于傳統的模型預測控制方法提升了算法漸進穩定性。文獻[25]研究了一種基于障礙維數的連續粒子群優化算法來優化攔截入侵者的防御路徑,相比于傳統的粒子群算法,該方法更適應于攔截作戰中狀態空間維數大的仿真場景。文獻[26]采用深度確定性策略梯度算法建立了飛行器模型,并利用多飛行器的協同參數構造獎勵函數,從而引導飛行器進行協同作戰。
隨著來襲飛行器性能和突防策略的多元化發展,未來戰場中飛行器間的攻防對抗將以集群博弈的方式出現。現有的協同攔截方法雖然具備一定的攔截能力,但較難適用于動態博弈條件下的群目標攔截任務。因此將智能理論與攔截策略相結合賦予攔截器協同博弈能力是未來打贏高對抗戰爭的迫切需求。
本文面向未來集群目標協同攔截的任務需求,基于強化學習原理研究提出了一種多飛行器攔截博弈對抗策略自學習智能方法。針對傳統方法中難以應對高維連續狀態動作空間的問題,將傳統的多智能體強化學習方法與近端策略優化思想相結合,采用集中式評判-分布式執行的算法架構,提出了一種適用于飛行器集群目標攔截作戰環境的智能對抗算法。研究提出的智能攔截博弈對抗算法具有以下優勢:
1)將近端策略優化方法融入到多智能體環境中,有效解決了強化學習訓練中步長難以確定的問題。
2)基于集中-分布式算法框架,將廣義優勢函數結合到價值函數設計中,引入梯度更新限幅機制,一定程度上提升了算法的收斂性。
3)將攔截目標分配過程與協同攔截策略一體化設計,研究提出了具有自主進化能力的多目標智能協同攔截策略,提高群目標攔截效能。
1 集群飛行器攔截博弈對抗
1.1 問題描述
在飛行器攔截博弈對抗中,對抗雙方可分別描述為進攻飛行器群體與攔截飛行器群體。進攻飛行器群體需要打擊高價值目標區域,飛行方向指向目標區域位置,并保證一定的精度。防御飛行器群體則需要實現對高價值目標區域的防御,攔截進攻飛行器。本文重點研究攻防雙方對抗過程中防御方集群的協同攔截策略,提升防御方集群博弈對抗能力,立足于集群作戰中的多目標協同攔截,從而實現防御方集群對進攻方集群飛行器的飽和攻擊,進而實現對高價值目標區域的防御作戰目的。飛行器在飛行過程中通過機載設備,可以感知作戰信息。在博弈對抗中,防御飛行器相對于入侵飛行器的態勢關系主要從博弈雙方關于相對運動關系的態勢進行描述,作戰博弈對抗必須同時滿足位置要求和角度要求。如圖1所示,環境中包括目標區域、進攻飛行器、防御飛行器,其中,(xi,yi)|i=1,2,…n為飛行器的位置坐標。
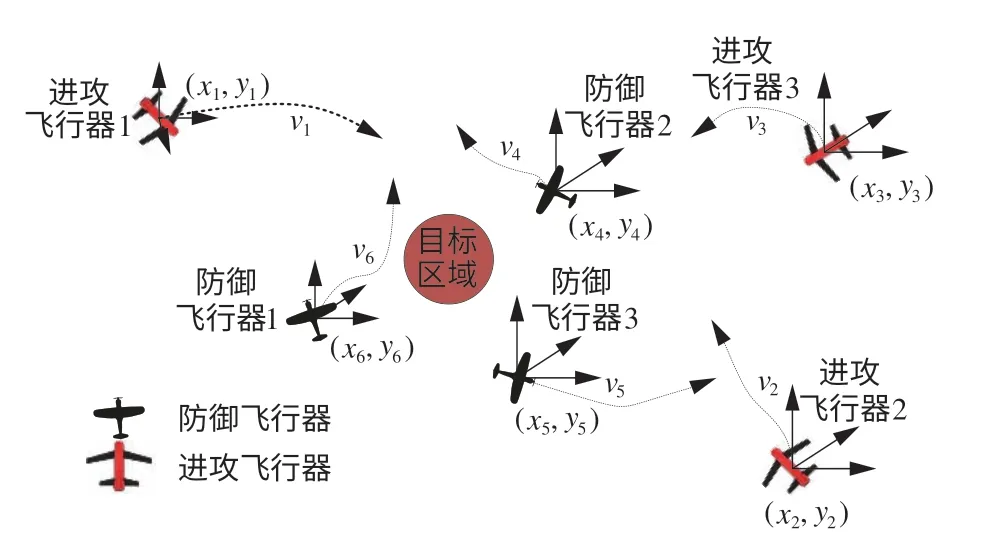
圖1 多飛行器攔截博弈問題Fig.1 Multi-aircraft interception game problem
1.2 飛行器運動學模型
本文以某固定翼飛行器為研究對象,考慮一個二維平面協同攔截場景,如圖2所示。其中,下標M和T分別表示防御方飛行器和進攻方飛行器;x,y為二維空間中飛行器的位置坐標;q和r分別表示飛行器間的視線角和相對距離;γ為飛行器速度方向與x軸的夾角,即航向角;V和a分別表示飛行器的速度大小和側向加速度大小。
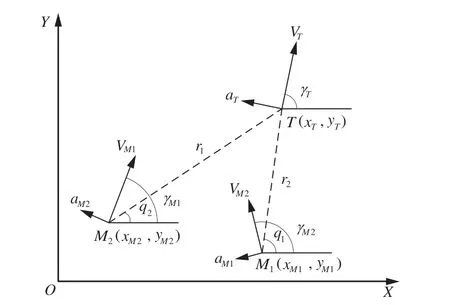
圖2 二維平面協同攔截場景Fig.2 2D plane collaborative interception scenario
某單體飛行器的二維空間運動學模型可以簡化描述為
執行攔截任務過程中,描述攻防雙方飛行器的相對運動關系方程可以表示為
式中:r為二維空間中飛行器之間的距離;q為飛行器之間的視線角大小;VT為進攻飛行器的速度大小;VM為進攻飛行器的速度大小;γT為進攻飛行器的速度航向角;γM為攔截飛行器的速度航向角;定義沿著視線和垂直視線方向的相對速度分別為Vr=˙,Vq=˙。
對Vr和Vq求導可得
式 中:aTr=aTsin(q-γT),aTq=aTcos(q-γT)為進攻方飛行器沿視線方向和垂直于視線方向的 加 速 度 ;aMr=aMsin(q-γM),aMq=aMcos(q-γM)為防御方飛行器沿著視線和垂直于視線方向的加速度。
飛行器速度航向角和過載之間存在著以下關系:
式中:nM為防御飛行器的法向過載指令;nT是進攻飛行器的法向過載指令;g為重力加速度。
本文考慮了實際飛行中飛行器能力限制,設定飛行器的最大飛行速度Vmax和過載的范圍限制,攻防雙方飛行器最大速度為Vmax=45 m/s,最大過載為nmax=1。
2 多飛行器攔截博弈對抗智能機動決策
針對群體目標智能化攔截問題,本節基于多智能體深度強化學習算法提出了一種多飛行器群體攔截博弈對抗的智能決策方法,通過感知到的作戰環境和敵我態勢信息,自主學習攔截策略,體現智能系統的自學習和自進化屬性。
2.1 近端策略優化算法模型
在面對多飛行器作戰環境時,傳統的策略梯度算法會出現訓練過程中策略更新步長難以確定的問題。因此本文采取了近端策略優化算法,在面對復雜的多飛行器攔截博弈對抗作戰環境中提出了新的目標函數,可以在算法訓練的過程中實現小批量更新,避免訓練結果發散。
不同于傳統強化學習算法中使用所執行動作的對數概率梯度,近端策略優化算法依據新舊策略之間的比率進而提出新目標,即
式中:πθ(a|s)當前策略函數;πθold(a|s)為更新前的策略函數;A為優勢函數。
本文將近端策略優化算法與廣義優勢函數估計方法相結合,同時融合clip算法以限制策略更新幅度。定義評估飛行器行為策略的目標函數:
式中:clip算法的作用是將新舊策略之間的比率限制在[1-ε,1+ε]之內,根據廣義優勢估計函數At的不同取值,clip算法可以分為2種情況,如圖3所示。圖中紅線表示Jclipθ的取值,從而防止訓練過程中策略的大幅更新,估計形式為式(7)所示。
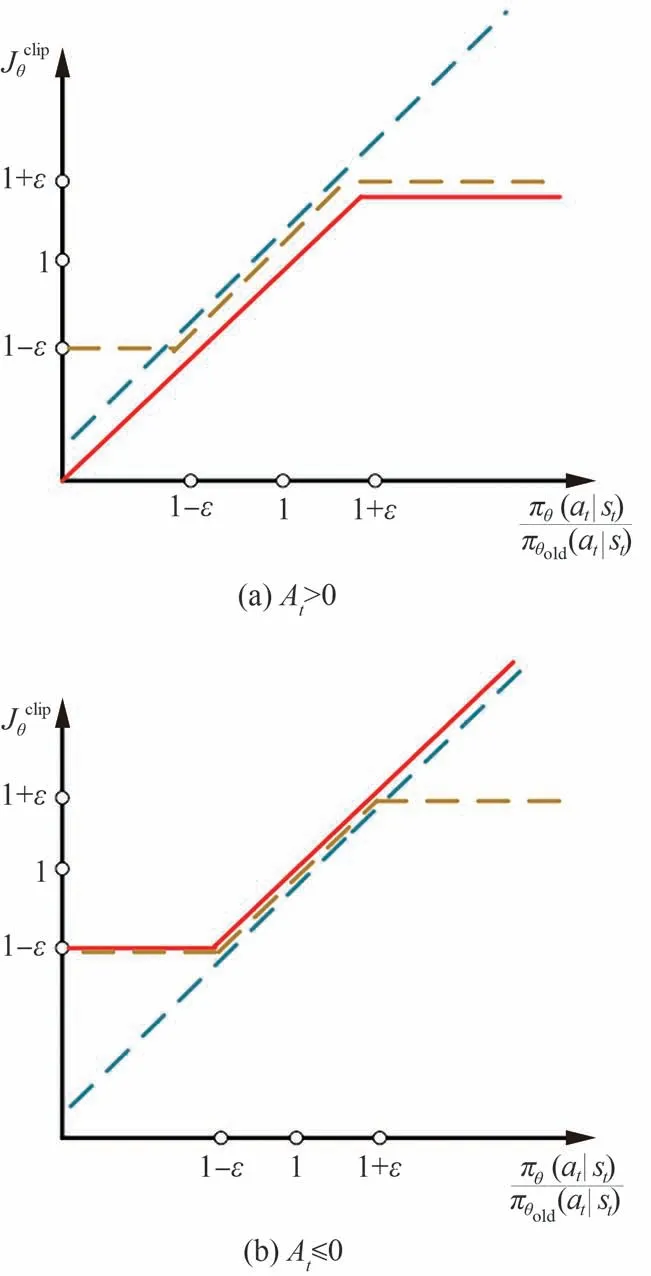
圖3 clip算法模型Fig.3 clip algorithm model
式 中:σt=rt+γV(st+1)-V(st);r為 獎 勵 值;γ為衰減因子;V(st)為此時刻的價值函數。
2.2 多智能體強化學習策略優化算法
本文將多飛行器攔截博弈對抗作戰場景描述為一個合作的多智能體強化學習問題,采用集中式評判分布式執行算法架構,該方法模型如圖4所示,仿真環境中多智能體圍繞共同目標進行分工與協作,涌現群體智能。
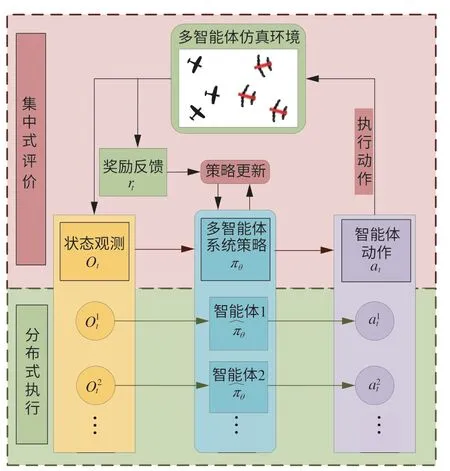
圖4 集中式評價分布式執行算法框架Fig.4 Centralized evaluation distributed execution algorithm framework
為適應多飛行器對抗作戰場景,本文將近端策略優化算法和集中式評價分布式執行框架相結合,提出了一種適用于集群對抗的多智能體強化學習算法。為應對復雜作戰環境下值函數以及策略梯度計算復雜的問題,引入深度學習中的神經網絡去擬合強化學習中的評判函數以及策略函數。多智能體深度強化學習算法模型如圖5所示。
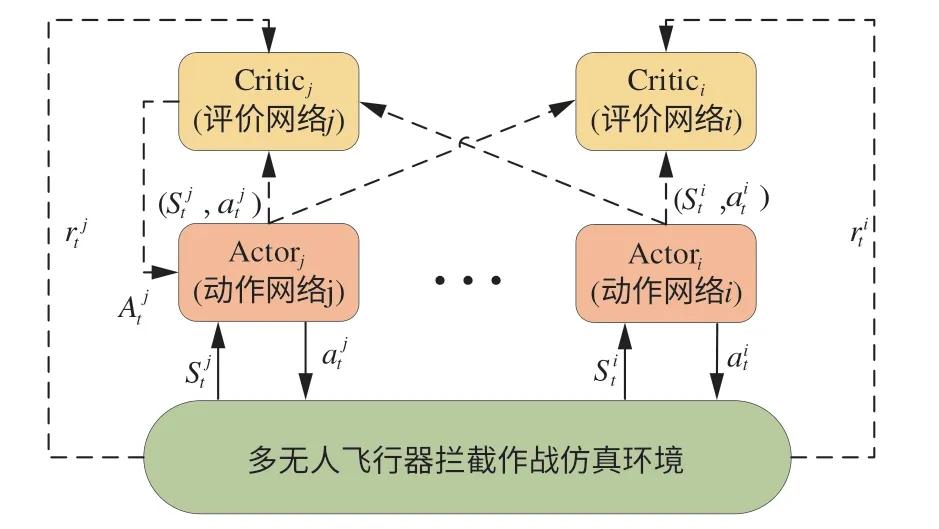
圖5 多智能體深度強化學習算法模型Fig.5 Multi-agent deep reinforcement learning algorithm model
飛行器攔截策略訓練過程分為評判和執行2個部分,單體飛行器同時具有攻防對抗策略π和策略的評判模塊Q,本文用神經網絡擬合評判函數以及策略函數,如圖6所示。并引入經驗回放機制,使訓練數據通過經驗回放機制中的重要性采樣獲得,從而在一定程度上改善了算法的收斂性。
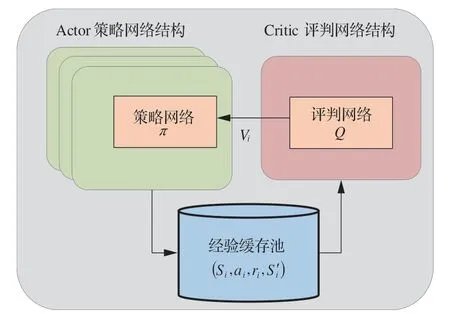
圖6 算法架構Fig.6 Algorithm architecture
1)評判模塊
神經網絡具有替代非線性函數的能力,因此本文使用多層循環神經網絡(Recurrent Neural Network,RNN)來近似評價策略的值函數。相比于傳統的全連接網絡,RNN增加了前后時序的關系,在訓練過程中將前序信息應用于當前輸出的計算中,提升神經網絡訓練的收斂性能。
評判模塊通過計算狀態價值函數V(st)和Vtarget(st)更新神經網絡參數ω,Critic評判網絡優化的損失函數如式(8)所示:
用于擬合值函數的神經網絡結構如圖7所示,基于時間差分算法優化損失函數進而更新神經網絡參數。
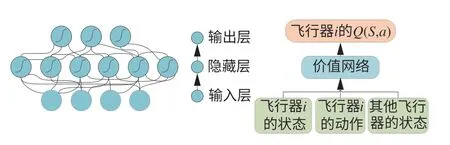
圖7 值函數神經網絡Fig.7 Value function neural network
2)執行模塊
在集中式訓練和分布式執行的框架下,策略神經網絡在執行時只利用飛行器自身的觀測狀態生成飛行器的機動策略。本文使用神經網絡擬合策略函數,如圖8所示。定義每架單體飛行器的參數化機動策略為πθi,θ是機動策略的參數,同時為Actor執行模塊定義一個策略優化目標函數:
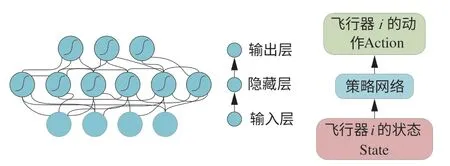
圖8 策略神經網絡Fig.8 Strategic neural network
式中:θ為策略網絡參數;At為評判網絡估計的優勢函數;πθold(at|st)代表收集經驗的原始網絡,πθ(at|st)為利用更新后的策略;clip函數將概率比限制在一個合理的范圍;ε為一個超參數。以At作為優化目標,At>0時增加πθ(at∣St)的概率,反之At≤0則減小πθ(at∣St)的概率。
2.3 飛行器博弈智能對抗算法建模
將飛行器間的對抗作戰任務建模為部分可觀馬爾科夫決策過程,如圖9所示。將飛行器群體構成一個整體智能無人系統,對智能無人系統中的相關變量定義如下:i=1,2,…,n表示各個飛行器的編號,n為飛行器的總數量;所有飛行器的聯合動作空間為A;所有飛行器的聯合動作為at;所有飛行器下一時刻的聯合動作為at+1;飛行器的聯合狀態空間為S,聯合狀態為st;每架飛行器的感知信息為oti∈st;各個飛行器的獎勵為rti。
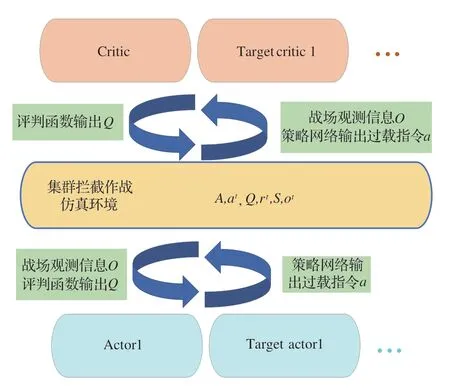
圖9 作戰場景馬爾可夫建模Fig.9 Markov modeling of operational scenario
在算法訓練過程中,飛行器接受環境觀測信息產生機動策略,通過值函數對策略進行評估優化,直到訓練生成最優值函數Q*(s,ai)和最優策略π*。算法中局部觀測信息和全局觀測信息交匯融合提升了多智能體群體博弈的對抗性能。作戰過程中算法流程如圖10所示,其中TD表示時序差分方法(Temporal Difference,TD)。
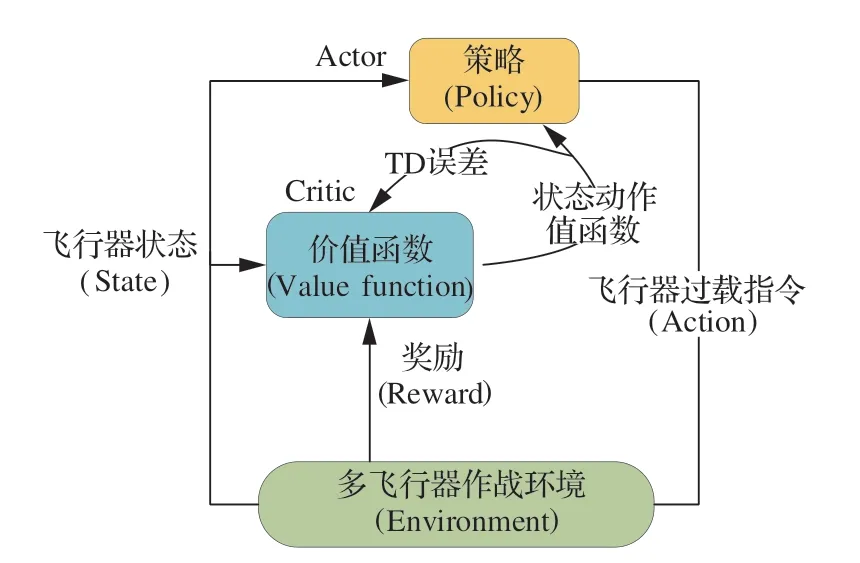
圖10 強化學習過程Fig.10 Reinforcement learning process
3 強化學習算法建模設計
第2節基于深度強化學習方法,建立了多飛行器智能攔截博弈對抗作戰模型,本節對模型中的觀測空間和獎勵函數進行設計。
3.1 觀測空間設計
多智能體深度強化學習模型訓練過程中,單個智能體的局部觀測值以及輸入給評價網絡的整體觀測值都對模型訓練具有較大影響。強化學習算法的核心在于與環境交互,每個智能體觀測到的信息都對策略的學習有著較大影響。本文中單個飛行器與環境交互過程中觀測的環境信息包括3部分,可表述為
在式(10)中,與視線角速率相關的觀測信息為
式中:V為攔截飛行器的速度;λ˙為攔截飛行器i與環境中其他入侵飛行器的視線角速率。
在式(10)中,表示距離的觀測信息為
式中:進攻飛行器和防御飛行器的相對距離使用(pt,pm)=‖pt-pm‖來表示,其中,pt為進攻飛行器的位置,pm為防御飛行器的位置。
在式(10)中,表示速度矢量前置角的觀測信息為
式中:γm為攔截飛行器的速度航向角;是攔截飛行器和入侵飛行器的視線角。
3.2 獎勵函數設計
在多飛行器攔截博弈對抗作戰場景中,防御方飛行器的作戰目標是以較小耗能逼近進攻飛行器,從而實現攔截打擊。深度強化學習理論中獎勵函數設計對博弈策略的學習尤為重要,針對多飛行器攔截博弈對抗任務場景,如果僅使用終端攔截回報會使獎勵函數設計稀疏,從而導致策略學習過程缺乏反饋引導,導致飛行器博弈策略訓練緩慢。本文結合作戰任務場景攔截過程中飛行器間的距離關系和角度關系設計獎勵函數,下面對己方攔截飛行器的獎勵函數進行描述。
攔截飛行器的獎勵函數包括4部分。分別是基于飛行器間相對距離的獎勵、基于飛行器間前置角的獎勵,攔截成功的單體獎勵和集群終端獎勵,可描述為
單體飛行器攔截終端獎勵S表示為
式中:Z為攔截飛行器的集合;fm為布爾變量,當攔截飛行器成功攔截入侵飛行器時為1,否則為0;經過仿真驗證設置超參數為K1=800。
集群攔截終端獎勵P1表示為
式中:fB為布爾變量,當進攻集群全部被攔截時為1,否則為0;經過仿真驗證設置超參數為K2=4×103。
基于飛行器相對距離獎勵P2表示為
式中:U為進攻飛行器的集合;經過仿真驗證設置超參數K3=0.5。
基于飛行器間前置角的獎勵P3表示為
式中:經過仿真驗證設置超參數為K4=0.65,K5=0.3。
4 仿真結果及分析
為驗證算法在多飛行器智能攔截場景中的有效性,本文設計了多飛行器攔截博弈對抗仿真環境,基于不同的任務類型以及飛行器的分布情況設置了作戰仿真實例進行仿真實驗。
4.1 仿真參數
在仿真實驗中,程序運行的服務器采用Ubuntu18.04系統,搭載Intel Core i7 9700F處理器,顯卡型號為Nvidia GeForce GTX 3090。模型訓練采用并行計算方法,設定進程數為64,仿真環境步長為0.06 s。
4.2 算法訓練
使用5架飛行器構成防御集群進行訓練,仿真程序實現流程如圖11所示。
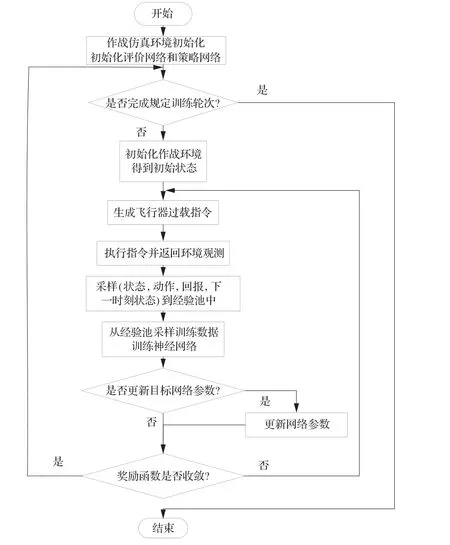
圖11 算法訓練流程圖Fig.11 Algorithm training flow chart
多飛行器智能攔截博弈對抗作戰環境中防御方飛行器策略訓練算法使用的訓練參數如表1所示。
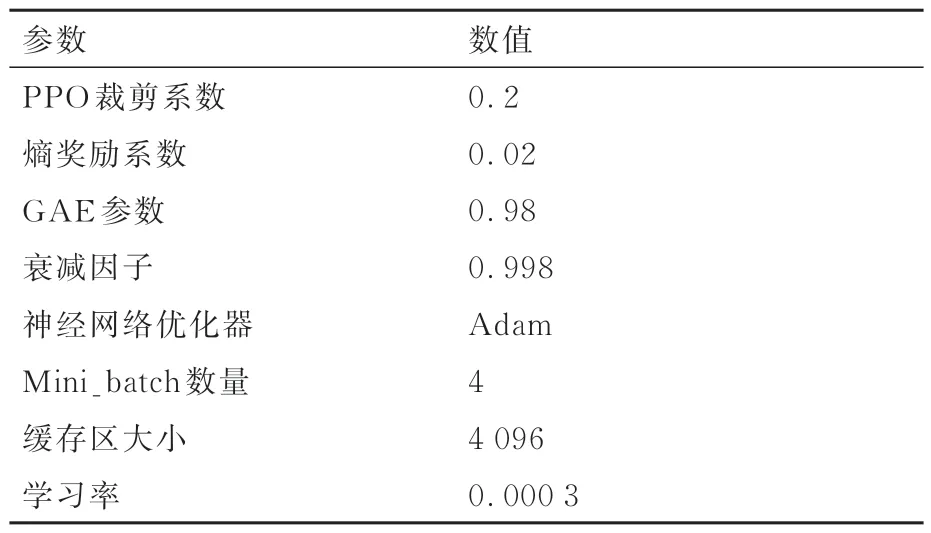
表1 算法訓練參數設置Table 1 Setting of algorithm training parameters
為了便于觀察算法訓練狀態,防止訓練過程中出現梯度消失等現象,對算法獎勵值的收斂性能進行了監測。以3架飛行器協同攻擊目標作戰場景為例,算法訓練過程獎勵曲線如圖12所示;在相同條件下使用多智能體深度確定性策略梯度下降算法(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)進行策略訓練時,得到獎勵曲線如圖13所示。
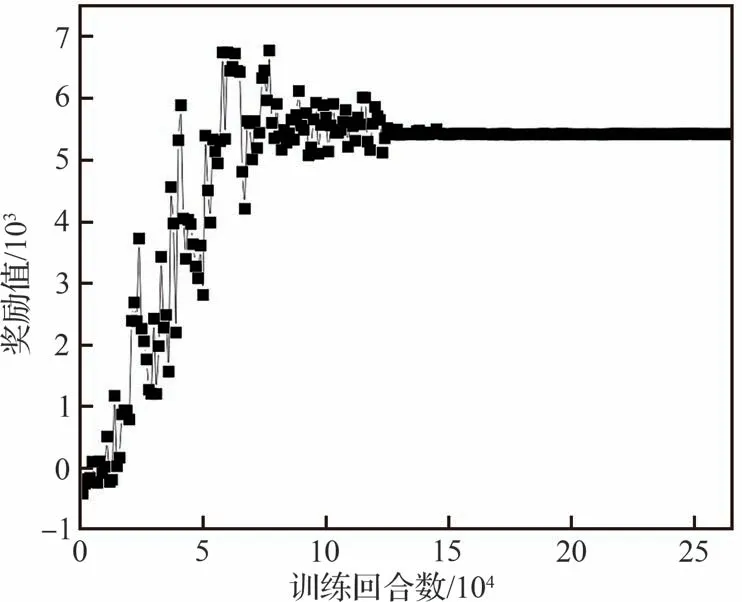
圖12 本文算法獎勵函數曲線Fig.12 Reward function curve of our algorithm
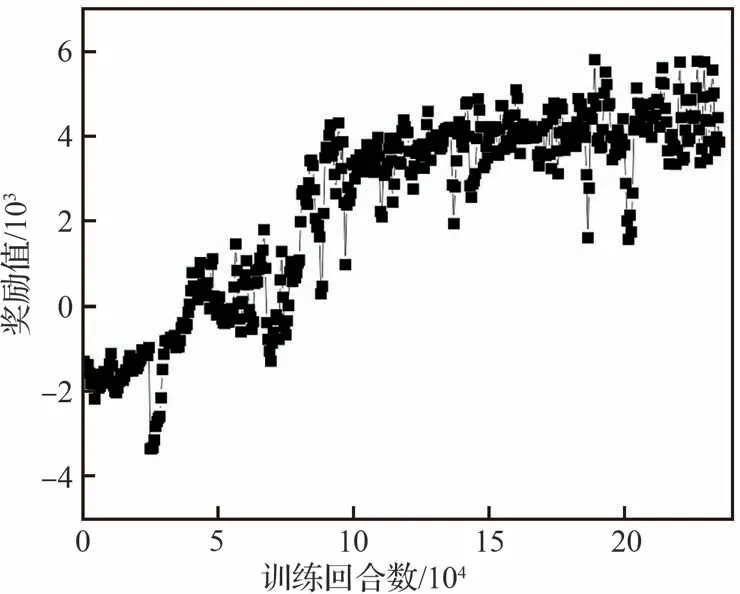
圖13 MADDPG獎勵函數曲線Fig.13 Reward function curve of MADDPG
根據獎勵函數曲線(圖12)可知,在算法訓練過程中,飛行器集群的行為獎勵收益值保持比較平穩的狀態緩慢增加,在訓練回合數到達12.5×104次之后獎勵函數曲線逐漸收斂;根據獎勵函數曲線(圖13)分析可知,MADDPG算法訓練回合數到達17.5×104后才開始收斂。相比于傳統算法而言,本文所提智能算法收斂所需的回合數更少,收斂更加穩定。仿真結果表明,在集群攔截任務中智能對抗算法收斂較快,獎勵曲線較為光滑。
4.3 驗證與分析
為了驗證研究提出的飛行器智能對抗博弈算法,本文根據進攻飛行器的數量不同設定了4種典型作戰場景,針對不同場景分別訓練飛行器集群攔截作戰策略模型。4種典型作戰場景情況如表2所示,攻防雙方初始化階段隨機性條件設置如下,防御集群生成的初始位置與目標區域的距離RM0∈[0,100] m,防御集群的初始速度VM0∈[15,25] m/s,初始速度方向隨機。進攻集群隨機生成的初始位置與目標區域的距離RT0∈[500,600] m,進 攻 集 群 的 初 始 速 度VT0∈[15,45] m/s,初始速度方向與彈目連線的夾角<30°。

表2 作戰場景設置Table 2 Operational scenario setting
本文針對訓練得到的4種場景下的機動策略模型分別進行仿真測試,驗證算法的有效性。仿真場景中,防護目標被隨機設置在固定位置,5架防御飛行器在防護目標區域附近隨機地部署。進攻飛行器的位置在一定的限制范圍內隨機生成,每個飛行器的能力約束包括飛行速度限制、過載能力限制等。設定作戰場景中攔截成功的判定方法為脫靶量<5 m。4種典型作戰場景的初始參數如表3所示。

表3 仿真環境參數Table 3 Simulation environment parameters
1)5架防御vs 1架進攻
針對1架進攻飛行器攻擊防護目標的情況,仿真環境初始參數如表3所示,其中進攻方采取的機動策略為比例導引法,則飛行器集群攔截任務的仿真結果如圖14所示,其中,D-UAV表示防御飛行器,A-UAV表示進攻飛行器。由位置曲線(圖14(a))分析可知,基于近端策略優化的多智能體強化學習算法訓練得到的機動策略模型能夠對1架進攻飛行器來襲實施成功攔截。由法向過載曲線(圖14(b))可知,機動策略模型輸出的法向過載指令在限制范圍內,指令變化平滑,航向角變化平穩,適于飛行器跟蹤控制。軸向過載曲線(圖14(c))表明,為了快速實現攔截任務,神經網絡輸出相應的軸向過載指令,提升飛行器的速度,使得防御方飛行器群體更加高效快速的實現攔截任務。
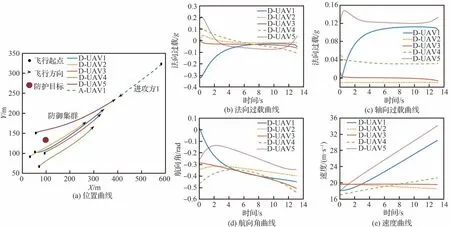
圖14 5架防御vs1架進攻協同攔截仿真結果Fig.14 5 defense vs 1 attack cooperative intercept countermeasure simulation results
從位置曲線(圖13(a))可以看出,防御方飛行器各自采取較為平滑的飛行路線去攔截進攻方,在保證成功率的同時縮短攔截路程,減少作戰耗能。
仿真結果表明,采用本文所提的智能協同策略可以對單體進攻飛行器進行有效攔截,實現高精準度打擊。針對多對一攔截問題,相比于按照自身能力約束分別對目標進行攔截的方法,智能協同策略能夠利用飛行器間的協作機制執行任務,具有一定的實際應用價值。
2)5架防御vs2架進攻
針對2架進攻飛行器攻擊防護目標的情況,仿真環境初始參數如表3所示,其中進攻方采取的機動策略為比例導引法,防御方采取智能機動策略,作戰仿真情況如圖15所示。由位置曲線(圖15(a))分析可知,強化學習方法訓練得到的智能機動策略能夠實現智能打擊任務分配,在面對兩架進攻飛行器時,機動策略模型綜合考慮防御飛行器和進攻飛行器的距離優勢和角度優勢進行智能分配,提升了攔截效率。
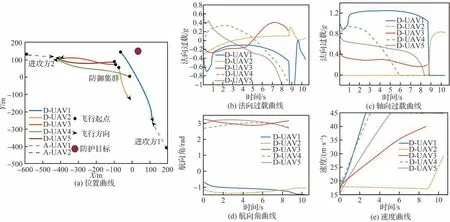
圖15 5架防御vs 2架進攻協同攔截仿真結果Fig.15 5 defense vs 2 attack cooperative intercept countermeasure simulation results
由法向過載曲線(圖15(b))可知,防御方飛行器過載變化較為平滑,并且保持在過載約束范圍內。由軸向過載曲線(圖15(c))可知,在飛行器發動機推力作用下,攔截方飛行器加速飛行,提升攔截方速度優勢,縮短攔截時間提升攔截效率。在攔截進攻飛行器2時,防御集群通過多個打擊角度攔截進攻飛行器,在攔截進攻飛行器1時,防御飛行器1作為主要攔截器迎擊進攻飛行器,防御飛行器2作為防御飛行器1的補充打擊確保攔截成功。
仿真結果表明,集群協同條件下防御方可以更好發揮動態博弈優勢,提高攔截成功率,最大化對抗收益。多對多攔截體現了本文所提的智能機動策略具有良好的任務分配能力,通過與環境的不斷交互,神經網絡可以根據不同的作戰場景訓練得到對應的協同打擊策略。
3)5架防御vs 3架進攻
針對3架進攻飛行器攻擊防護目標的情況,仿真環境初始參數如表3所示,其中進攻方采取的機動策略為比例導引法,防御方采取智能機動策略,仿真結果如圖16所示。由位置曲線(圖16(a))分析可知,強化學習智能機動策略不僅可以引導飛行器精準打擊目標,同時可以根據進攻飛行器的飛行狀態實現合理的攔截任務分配,機動策略模型產生的智能任務分配如表4所示,以使得防御集群以合理的方式完成攔截任務,精準打擊目標。由過載曲線(圖16(b)和圖16(c))分析可知,防御方飛行器集群采用的智能策略綜合考慮攔截耗能和過載限制等因素,提升了多飛行器攔截效能。由航向角曲線(圖16(d))分析可知,攔截過程中飛行器航向角變化平穩,適用飛行器控制。由速度曲線(圖16(e))分析可知,攔截過程中飛行器均勻加速至約束限制,提升攔截速率。
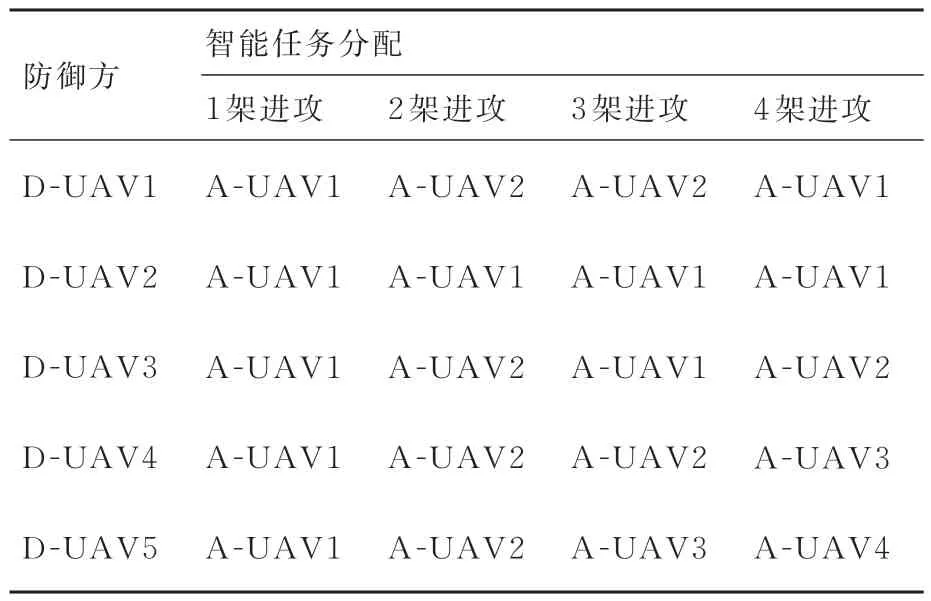
表4 任務分配情況Table 4 Task allocation
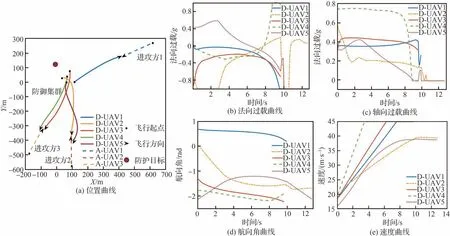
圖16 5架防御vs 3架進攻協同攔截仿真結果Fig.16 5 defense vs 3 attack cooperative intercept countermeasure simulation results
由于各飛行器初始位置及指向均隨機,為了能夠更好的攔截進攻飛行器,防御方在初始階段采取較大過載將飛行方向偏向進攻飛行器,從而減少攔截時間。具有相同攔截目標的飛行器之間具有一定的合作效能,防御飛行器2和5從2個方向逼近進攻飛行器2,保證攔截成功的同時縮短打擊時間。
仿真結果表明,通過在進攻方飛行器兩側構建合適的圍捕態勢,使得目標難以逃逸,同時也能保證攔截方飛行軌跡平滑,防止機動指令過大。在集群對抗過程中,本文所提機動策略模型可以對進攻飛行器集群進行有效攔截,隨著目標數量的增多,機動策略生成的任務分配方案使整體攔截效能顯著提升。
4)5架防御vs 4架進攻
針對4架進攻飛行器攻擊防護目標情況,仿真環境初始參數如表3所示,其中進攻方采取的機動策略為比例導引法,防御方采取智能機動策略,仿真結果如圖17所示。隨著進攻方飛行器數量的增多,智能機動策略模型生成的目標分配策略展現出較強的優勢,分配結果如表4所示,在保證充分攔截的前提下合理的分配火力,提升攔截效率,更加精準全面地完成攔截任務。
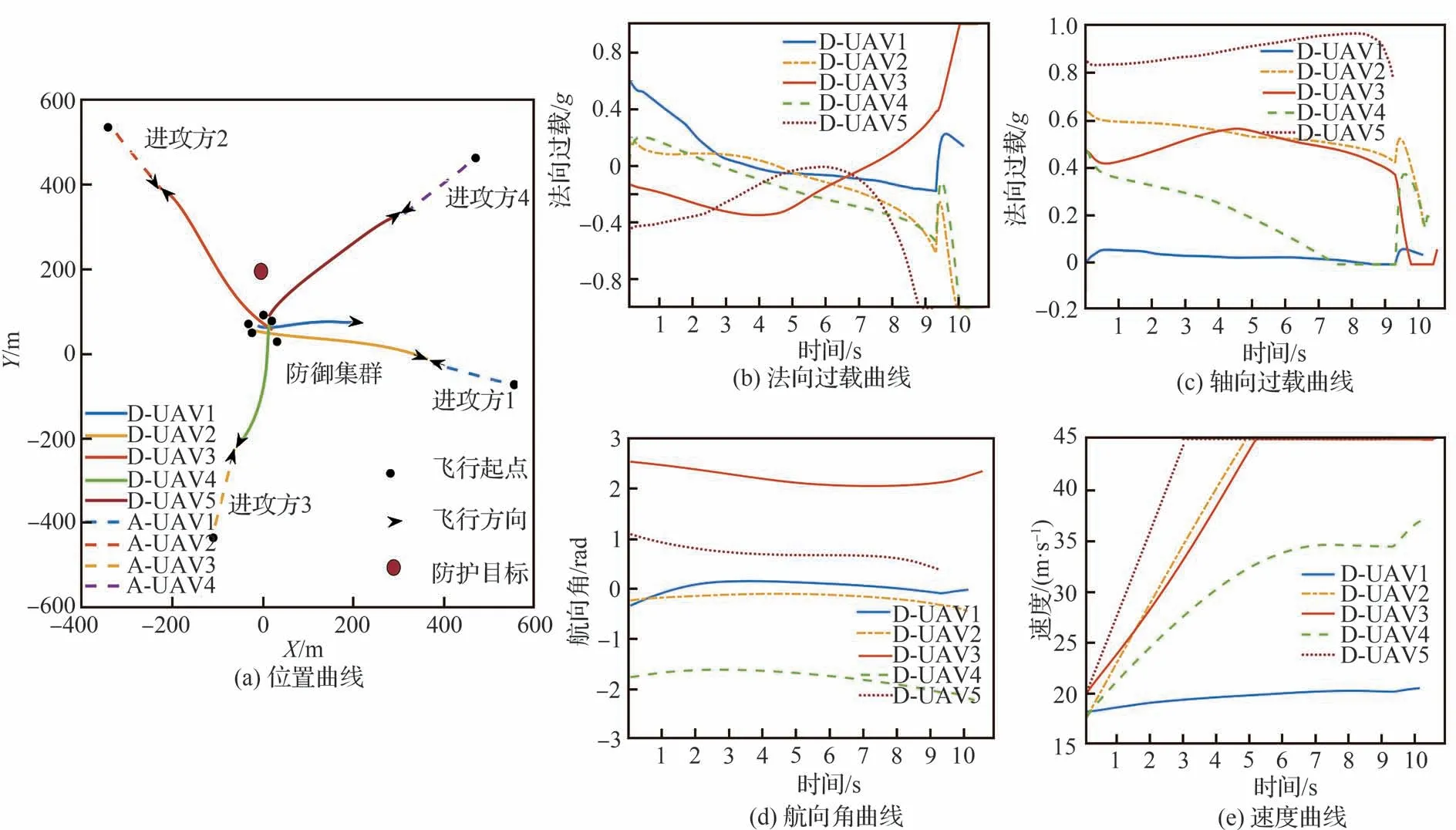
圖17 5架防御vs 4架進攻協同攔截仿真結果Fig.17 5 Defense vs 4 attack cooperative intercept countermeasure simulation resultsTask allocation
由仿真結果中的位置曲線(圖17(a))以及過載曲線(圖17(b)和圖17(c))分析可知,攔截過程中防御集群綜合考慮戰場因素,不僅將過載限定在規定范圍內,同時減少作戰耗能,便于實現精準打擊。由位置曲線(圖17(a))可以看出在攔截初始階段智能模型對作戰任務進行了合理分配,防御飛行器1和防御飛行器2協同攔截進攻飛行器1,其余的3架防御飛行器分別攔截剩余目標。在面對4架進攻飛行器時,防御方飛行器基于各自的位置速度進行目標的最優分配,在相互通訊的基礎之上,防御方群體能夠以較為平滑的軌跡運動,同時實現自主協同全面攔截。
本仿真示例中進攻飛行器數量較多,防御方集群采用本文所設計的智能策略能夠以高成功率完成攔截任務,驗證了研究提出的協同智能攔截策略的有效性。
通過上述仿真的分析可知,基于近端策略優化的多智能體深度強化學習算法訓練得到的機動策略模型在攔截任務中有較好的表現。為了驗證算法效能,針對4種作戰情況,采用訓練得到的強化學習策略模型進行1 000次仿真測試實驗,統計仿真結果如表5所示。

表5 1 000次作戰仿真結果統計Table 5 1 000 battle simulation results statistics
上述仿真結果表明,基于5架飛行器訓練得到的智能協同攔截模型可以很好的應用于多架進攻飛行器的攔截任務中,基于近端策略優化的多智能體深度強化學習算法對飛行器集群的行為決策具有良好的適應能力和泛化能力。由1架進攻飛行器的仿真結果可以看出,對于數量較少的來襲目標,飛行器集群可以很好的完成預定的攔截任務。其他作戰情況中,來襲的進攻飛行器數量增多,強化學習模型輸出的智能攔截策略能夠實現智能任務分配,同時保證作戰過程中的全面打擊。在多架來襲進攻飛行器的作戰情況分析中,5架飛行器在飛行過程中依據強化學習策略模型智能生成任務分配模型,實現了多飛行器集群的智能攔截。
綜上所述,深度強化學習為飛行器集群去中心化、自主化和自治化提供一種智能化解決途徑,將強化學習算法應用在飛行器集群攔截作戰任務中可以在一定程度上提升裝備的智能水平和能力,具有一定的現實意義。
5 結 論
在集群作戰環境中給飛行器賦予智能,從而實現作戰過程中的智能決策,是一個非常有挑戰性的任務。本文針對來襲群體目標的智能協同攔截機動策略問題,研究了多智能體深度強化學習在飛行器攻防對抗中的創新應用,提出了基于近端策略優化算法的智能協同攔截機動策略,仿真結果表明本文研究提出的智能協同攔截可以提升群體目標攔截的效能和智能化水平。主要結論如下所示。
1)研究提出的智能協同攔截算法可以有效實現飛行器以合理的打擊分配策略攔截進攻集群。通過強化學習訓練過程中的高效探索和自學習進化,提升了攔截任務分配的效率和智能化水平,節省了前期任務分配時間,增加攔截效能。
2))與現有執行攔截任務需獲提供大量額外復雜的戰場環境信息不同,提出的協同攔截策略通過對作戰場景針對性的分析,可以僅用可感知的部分作戰環境信息制定高效協同攔截策略,減少對群里目標攔截中態勢信息數量和維度的感知要求,降低信息感知難度。
3)提出的基于近端策略優化算法的多智能體深度強化學習算法提出應用了小批量更新、集中式訓練-分布式執行等方法提升算法訓練效率,同時提升了算法的適應性,降低了訓練的數據需求,減少了時間成本,提升智能協同攔截算法的訓練效率。
4)提出的多飛行器智能攔截博弈對抗策略采取集中式訓練-分布式執行的方法,既提升了訓練效率,又在執行中采取分布式架構,降低了對群體協同信息交互的要求,對實際工程應用具有一定的參考價值。
5)提出的智能協同攔截策略既借鑒了現有解析制導律來進行觀測空間的設計,又利用強化學習賦予了協同攔截策略自學習、自優化的屬性,提升收斂性的同時又增加了自學習智能屬性,對群體博弈對抗作戰場景具有一定的實際和借鑒意義。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學大世界(2018年1期)2018-04-12 05:39:14
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
