基于先驗知識的單視圖三維點云重建算法研究
2023-10-17 13:12:53陳雅麗李海生王曉川李楠
計算機應用研究 2023年10期
關鍵詞:深度學習
陳雅麗 李海生 王曉川 李楠


摘 要:單幅圖像的三維重建是一個不適定問題,由于圖像與三維模型間存在的表示模式差異,通常存在物體自遮擋、低光照、多類對象等情況,針對目前單幅圖像三維模型重建中重建模型具有歧義性的問題,提出了一種基于先驗信息指導的多幾何角度約束的三維點云模型重建方法。首先,通過預訓練三維點云自編碼器獲得先驗知識,并最小化輸入圖像特征向量與點云特征向量的差異,使得輸入圖像特征分布逼近點云特征分布;然后,利用可微投影模塊將圖像的三維點云表示形式從不同視角投影到二維平面;最后,通過最小化投影圖與數據集中真實投影圖的差異,優化初始重建點云。在ShapeNet和Pix3D數據集上與其他方法的定量定性比較結果表明了該方法的有效性。
關鍵詞:點云;三維重建;深度學習;先驗知識;可微投影模塊
中圖分類號:TP301.6 文獻標志碼:A 文章編號:1001-3695(2023)10-044-3168-05
doi:10.19734/j.issn.1001-3695.2022.12.0833
Single-view 3D point cloud reconstruction algorithm based on priori knowledge
Chen Yali1,2,3,Li Haisheng1,2,3,Wang Xiaochuan1,2,3,Li Nan1,2,3
(1.School of Computer & Engineering,Beijing Technology & Business University,Beijing 100048,China;2.Beijing Key Laboratory of Big Data Technology for Food Safety,Beijing 100048,China;3.National Engineering Laboratory for Agri-product Quality Traceability,Beijing 100048,China)
Abstract:Single-view 3D reconstruction is an ill-posed problem.Due to the different modes of representation between the image and the 3D model,there are usually self-occlusion,low illumination,and multiple objects.Aiming at the ambiguity of the reconstructed model in the current 3D model reconstruction of a single image,this paper proposed a 3D point cloud model reconstruction method based on the guidance of prior information and multi-geometric angle constraints.Firstly,it obtained prior knowledge by pre-training the 3D point cloud encoder,and minimized the difference between the input image feature vector and the point cloud feature vector,so that the input image feature distribution approximated the point cloud feature distribution.Then,it used a differentiable projection module to project the three-dimensional point cloud representation of the image from different angles to a two-dimensional plane.Finally,it optimized the initial reconstructed point cloud by minimizing the diffe-rence between the projected image and the actual projected image in the dataset.The results of quantitative and qualitative comparison with other methods on ShapeNet and Pix3D datasets verify the effectiveness of the proposed algorithm.
Key words:point cloud;3D reconstruction;deep learning;prior knowledge;differentiable projection module
三維重建(3D reconstruction)是計算機視覺領域中的一個重要任務。其中單視圖重建[1](single-view reconstruction,SVR),從單個圖像中推斷3D模型形狀是一個不適定的問題,由于從3D到2D的投影過程會丟失3D形狀的關鍵幾何和結構信息,并且圖像與三維模型之間存在的表示模式差異,通常存在物體自遮擋等問題。隨著大規模3D數據集的公開[2,3]和深度學習技術的進步,越來越多的研究者嘗試將深度學習技術應用于三維數據的分析與理解[4]。在三維重建任務中,根據目前三維模型常用的表示形式,主要有基于點云[5,6]、基于網格[7,8]和基于體素[9,10]的三維重建方法。
1 相關工作
1.1 基于視覺幾何的三維重建方法
傳統基于視覺幾何的三維重建方法,研究時間比較久遠,技術相對成熟,已經取得巨大的成功。主要通過多視角圖像對采集數據的相機位置進行估計,再通過圖像提取特征后進行比對拼接完成二維圖像到三維模型的轉換。2005年,Isgro等人[11]將其主要分為主動式和被動式,在主動式方法[12,13]中,物體的深度信息是給定的,重建主要是利用數值近似來還原物體的3D輪廓。被動式方法[14,15]在3D重建過程中不會與被重建物體產生任何交互,主要是利用周圍環境獲取圖像,然后通過對圖像的理解來推理物體的3D結構。
1.2 基于深度學習的三維重建方法
深度學習的方法使用深度網絡從低質量圖像中自動學習三維形狀的語義特征,可以充分學習三維形狀的可見部分,通過訓練目標函數重建三維形狀的遮擋部分,彌補傳統基于視覺的三維重建的固有缺陷,提高了重建精度。
Wu等人[16]在2015年提出基于體素表示的三維重建網絡3D ShapNets。體素表示的三維形狀通過添加三維塊提高了表面精度,但是也帶來了更大的計算量。與此同時,這種體素表示方法存在信息稀疏性問題,受到空間分辨率的限制。Tatarchenko等人[17]通過一種基于八叉樹的體素表示法,八叉樹生成網絡(octree generating network,OGN)學習預測八叉樹的結構和每個單元的占用值,大大降低了生成形狀所需的空間開銷,提升了預測體素形狀的精細程度。與基于體素或基于八叉樹的CNN方法不同,Wang等人[18]提出一個自適應基于八叉樹的卷積神經網絡(Adaptive O-CNN),按照局部形狀與平面的差距自適應地生長八叉樹并在每個葉子節點中預測一個小平面作為局部的幾何形狀,充分利用了不同形狀和不同尺度局部幾何的共性,不僅減少了內存開銷,而且較現有的三維CNN方法具有更好的形狀生成能力。
網格表達不同于圖像和體素的結構,具有不一致的拓撲結構[19],能夠建模三維形狀細節,更適合于許多實際應用場景。Wang等人[20]提出了一種端到端的深度學習框架Pixel2Mesh,由粗到細基于圖卷積神經網絡直接生成彩色圖像的三角形網格。
針對上述方法存在重建精度和完整度的問題,沈偉超等人[21]將三維物體分解成多個組件,通過預測組件幾何結構和組裝組件的方式重建三維物體,從而將高分辨率三維物體的重建問題分解成一系列低分辨率組件的重建問題。Zheng等人[22]提出了一種簡單而有效的方法來重建高質量的三維模型的表面顏色和形狀。采用統一的由粗到細的策略,從輸入的單幅圖像中學習顏色和形狀。通過引入正交彩色地圖(orthographic colorful map,OCM)來表示模型的表面顏色,從而可以直接利用二維超分辨率方法獲得高分辨率的表面顏色。
1.3 基于單視圖的三維重建方法
基于單視圖的三維重建在計算機視覺領域是一個具有挑戰性的熱點問題,近幾年來,研究人員通過引入先驗知識和一些合適的約束進行三維重建。Li等人[23]提出了一種利用類信息從給定的類標簽生成三維模型的三維GAN,該網絡可以學習多類別的復雜數據分布,并且生成器的多樣性得到了很好的保證,最終從單一圖像中重建三維模型。Zhang等人[24]聯合學習2D圖像、3D形狀幾何形狀和結構的多模態特征表示,將3D形狀結構表示為零件關系,通過對視圖對齊圖像和3D形狀進行訓練,在潛在特征空間中隱式編碼視圖感知形狀信息,從而重建出三維模型。何鑫睿等人[25]通過對Pix2Vox網絡進行改進,在重建網絡中增加多尺度通道,以保留多層次的圖像信息,并融合通道注意力機制,加強對圖像特征學習,實現端到端的單視圖三維模型重建。
點云作為三維數據的重要表示形式,具有可伸縮的數據表示、緊湊的形狀信息編碼和可選的嵌入紋理的特點,受到越來越多的關注。針對在單視圖三維點云重建問題,Mandikal等人[1]提出3D-LMNet框架,從單一圖像進行精確多樣的三維點云重建的潛在嵌入匹配,通過訓練三維點云自編碼器,學習一個從二維點云到相對應潛在嵌入空間的映射。 Chen等人[26]使用設計的圖像編碼器和注意力機制來提取圖像特征并輸出簡單的點云。Wen等人[27]提出了3DAttriFlow網絡,通過對輸入圖像中不同的語義層次分離和提取語義屬性,將其集成到三維形狀重建過程中,對三維形狀上特定屬性的重建提供明確的指導,從而重建更精確的3D形狀。上述方法僅僅依靠對三維信息的監控,誘導網絡生成合理、準確的三維模型是不夠的。另外,生成的點云視覺誤差隨姿態的不同而變化,在圖像不可見部分容易產生多個微小形狀的三維模型結果,且模型的細節容易丟失。比如對椅子重建中,椅子腿是辨別椅子的重要特征,但使用整體損失函數時由于椅子腿部點數過少,使得腿部部分不易重建,從而失去重要特征。
目前大多數點云重建方法在訓練過程中直接使用二維圖像特征或三維模型作為監督值,這種方法雖然簡單,但同時帶來了兩個主要的問題:一方面由于單張圖片提供的物體信息有限,僅僅約束單張圖片重建出來的模型,很難重建出高質量并與輸入圖像保持一致的三維模型,也就是重建出的點云易產生多個可能的形狀;另一方面由于圖像數據集遠遠超過三維數據,所以標注大量與輸入圖像匹配的三維模型帶來昂貴的時間和人力成本。利用點云進行單視圖三維重建仍存在一些亟待解決的問題。從單視圖圖像中恢復三維結構也是一個不適定問題,重建的點云缺乏細節曲面。
2 本文方法
本文針對目前單幅圖像三維模型重建中重建模型具有歧義性的問題,提出了一種改進的3D-LMNet方法,基于先驗信息指導的多幾何角度約束的三維點云模型重建方法。點云模型重建網絡框架如圖1所示。
具體來說,首先使用圖像編碼器與3D點云自編碼器分別獲取輸入圖像特征Ei與點云數據分布先驗Ep,為減少重建過程中不確定點云的生成,通過結合多個二維投影圖Ml監督的方法,在不同視角進行幾何外觀約束,從而使得重建模型具有與輸入一致的外觀輪廓細節,使得三維模型重建更具有廣泛性。聯合優化投影圖損失Lmask 和特征向量損失L1,更新圖像編碼器參數Eθ,最終獲得重建點云。在合成和真實數據集上對該重建方法進行了廣泛的定量和定性評估,實驗結果表明本文算法顯著優于3D-LMNet的重建方法。
2.1 3D點云自編碼器
為學習3D點云數據集中的先驗知識,本文訓練了一個編解碼器網絡(Ep,Dp) 。通過設計適當的損失函數訓練,調整編碼器和解碼器的參數,能夠充分學習輸入特征,引入點云自編碼器來充當數據集中點云特征提取器,通過訓練學習輸入點云數據的分布特征,從而獲取數據分布先驗。
采用基于PointNet的編碼器Ep 結構,其中包括五個一維卷積層。應用maxpool symmetry函數特征向量Zp上全連接層構成,產生重建點云X⌒p。具體來說,輸入點云為B×N×3,其中B為batchsize,N為點云點的數量,每個卷積輸出B×N×64,B×N×128,B×N×256,B×N×256,B×N×512,為激活函數。在解碼器中,通過三個全連接層輸出,分別為B×256,B×256,B×2048×3。
2.2 匹配重建
通過2.1節3D點云自編碼器訓練后,得到一個特征向量,其可以理解為一個向量空間,即目標域,而圖像編碼器部分獲取的圖像特征是為了與點云數據空間進行逼近,使得兩者分布匹配,最小化向量空間分布差異后得到的圖像特征可以視做是融合了該類別三維特征信息,從而可以有效地恢復出三維模型。
在此階段,旨在將3D點云中學習的先驗知識有效地轉移到2D圖像中。因此訓練一個圖像編碼器Ei,該圖像編碼器輸入一個二維圖像I,并輸出一個圖像特征向量Zi。
在匹配重建階段,通過最小化圖像特征向量Zi與點云特征向量Zp的差異,使得圖像潛在數據空間逼近于真實點云數據分布,重建出可能的點云模型。對潛在損失函數使用最小絕對偏差LAD進行計算,公式如下:
2.3 可微投影
從多個角度獲取多張二維投影圖來表達該模型,在不同角度約束重建的三維模型外觀輪廓。即若重建模型與真實模型接近,則其各角度投影必定相似,反過來說若在不同角度投影圖和真實投影圖差距很小,則可以認為其表達的模型與真實模型相似。基于這一思想,考慮到從特征空間中重建的初始點云具有不確定性,因此本節引入可微點云投影模塊,將初始點云進行投影,增加多角度幾何約束,從而確保重建點云與輸入圖像在幾何外觀上保持一致。
具體來說,在獲得預測點云X⌒i后,利用相機參數對模型進行投影。通過視角變換并將變換后的點云投影到平面上,將點云中所有點的高斯映射合并,得到與真值匹配的投影圖,相比于以往的投影方式,采用可微函數的方法使得投影圖更具平滑性。對獲得任意視角v的不同投影,使用相應的真實投影計算損失。令M⌒VI,J為在第v視角點云投影模塊在(i,j)坐標處的像素值,其獲得方法如下:
2.4 損失函數
通常使用二元交叉熵損失來實現投影值和真實值之間的一致性,定義投影圖損失如下:
其中:MV和M⌒V別是第v個視角真實二值輪廊圖和點云投影輪廊圖;i,j分別是投影圖像中像素值。使用多個不同角度的投影圖像約束訓練,得到的重建點云投影生成模型具有更精細的輪廓,更貼近真實三維物體。優化過程中的最終損失函數是二元交叉熵和仿射變換損失函數的組合:
3 實驗與結果
3.1 數據集
本文實驗訓練采用ShapeNet數據集中的數據,其中包括視圖、Mask圖、相機視點信息,在網格表面采樣得到相應的點云(數量為2 048),同時隨機選擇20個視角對每個模型進行渲染獲得圖像,得到圖像和點云的數據對。包括13個不同類別的模型,按照80%、20%的比例劃分為訓練集與測試集。訓練后在ShapeNet數據集[2]和Pix3D數據集[3]進行了測試,其中Pix3D中的圖像在形狀和背景方面較為復雜。
3.2 實驗參數
本文實驗訓練過程分為兩個階段,在第一個階段即點云自編碼器過程,采用預訓練的方式,第二個階段使用Adam優化器對重建網絡訓練進行聯調。其中批處理大小為2,初始學習率為1×10-5。式(7)中α的設置值為10,輸入圖像尺寸為64×64×3,最終重建點云的數量為1 024、2 048,點云編碼器、重建網絡訓練迭代次數分別為500、10,選擇四個角度進行投影。
3.3 評估指標
本文采用以下定量評估指標進行評估:
a)CD(Chamfer distance):用于衡量兩個點云之間的距離,也叫倒角距離,具體為一個點云S中的每一個點p,都找到另一個點云S⌒ 中與之最近鄰的一個點q,然后對點云所有點距離求和。
3.4 實驗結果與分析
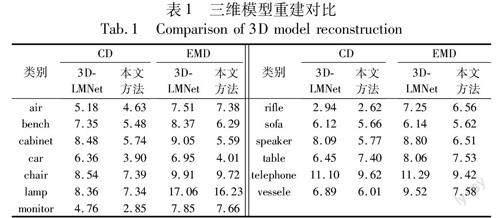
如表1可以看出,本文方法在bench、cabinet、car、monitor、speaker類別上CD距離比3D-LMNet[1]低近2.5,同時在air、chair、lamp、rifle、sofa、telephone、vessele類別也低于3D-LMNet[1]。在 EMD度量上,本文方法同樣具有競爭力,其中在bench、cabinet、car、speaker類別上也低近2.0,在其他大部分類別上也是有更低的數值。
對部分重建結果進行可視化展示,圖2展示了本文方法在ShapeNet測試子集上的部分重建結果(1 024點),從可視化結果可以看出,本文方法在重建模型為1 024數量點時仍有較好的效果,模型具有較強的魯棒性。圖3、4分別展示了本文算法與3D-LMNet在ShapeNet測試子集與Pix3D上的重建結果對比(2 048點)。從可視化結果可以看出,基于先驗指導的單圖重建結果有著較為完整的輪廓外觀,如圖3、4中table中間的隔層、椅子腿部等,另外本文方法在針對目前單幅圖像三維模型重建中重建模型具有歧義性的問題有較好的效果,而3D-LMNet方法對某些類別針對輸入圖像本身可能存在噪聲、遮擋情況的重建效果不佳的問題,如圖3bench類別樣例2中無法重建出模型輪廓,而本文方法通過引入可微投影模塊進一步添加了約束條件,使得重建效果更佳。
4 結束語
本文提出了一個基于先驗知識的單視圖三維點云重建算法,引入點云自編碼器獲取數據先驗,減少重建過程中不確定點云的生成,在此基礎上,結合可微投影模塊設計新穎的三維模型重建網絡,實現重建點云具有與輸入圖像一致的外觀輪廓細節,得到了較好的重建結果,通過實驗與其他方法進行了對比驗證了所提算法的有效性。此外,本文結合數據先驗,減少解碼過程中不確定點云的生成,提高重建結果的準確率,使得三維點云重建更具有廣泛性。未來將考慮利用圖卷積提取帶有法向信息的點云特征,結合對抗網絡試圖取得更好的重建效果。
致謝 此項工作是在國家超級計算天津中心的天河新一代超級計算機上完成,感謝天河的大力支持。
參考文獻:
[1]Mandikal P,Navaneet K L,Agarwal M,et al.3D-LMNet:latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image[C]//Proc of British Machine Vision Confe-rence.2018:55.
[2]Mo Kaichun,Zhu Shilin,Angel X C,et al.PartNet:a large-scale benchmark for fine-grained and hierarchical part-level 3D object understanding[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:909-918.
[3]Sun Xingyuan,Wu Jiajun,Zhang Xiuming,et al.Pix3D,single RGB image,3D shape modeling,3D reconstruction,shape retrieval,3D pose estimation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:2974-2983.
[4]李海生,武玉娟,鄭艷萍,等.基于深度學習的三維數據分析理解方法研究綜述[J].計算機學報,2020,43(1):41-63.(Li Hai-sheng,Wu Yujuan,Zheng Yanping,et al.A survey of 3D data analysis and understanding based on deep learning[J].Chinese Journal of Computers,2020,43(1):41-63.)
[5]Li Yangyan,Bu Rui,Sun Mingchao,et al.PointCNN:convolution on χ-transformed points[C]//Proc of the 32nd International Conference on Neural Information Processing Systems.[S.l.]:Curran Associates Inc.,2018:828-838.
[6]Fan Haoqiang,Su Hao,Guibas L,et al.A point set generation network for 3D object reconstruction from a single image[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2017:2463-2471.
[7]Gao Lin,Yang Jie,Wu Tong,et al.SDM-Net:deep generative network for structured deformable mesh[J].ACM Trans on Graphics,2019,38(6):1-15.
[8]Mao Aihua,Dai Canglan,Gao Lin,et al.STD-Net:structure-preserving and topology-adaptive deformation network for 3D reconstruction from a single image[J].IEEE Trans on Visualization and Computer Graphics,2020,29(3):1785-1798.
[9]Choy C B,Xu Danfei,Gwak J,et al.3D-R2N2:a unified approach for single and multi-view 3D object reconstruction[C]//Proc of European Conference on Computer Vision.Cham:Springer,2016:628-644.
[10]Xie Haozhe,Yao Hongxun,Zhang Shengping,et al.Pix2Vox+:multi-scale context-aware 3D object reconstruction from single and multiple images[J].International Journal of Computer Vision,2020,128(12):2919-2935.
[11]Isgro F,Odone F,Verri A.An open system for 3D data acquisition from multiple sensor[C]//Proc of the 7th International Workshop on Computer Architecture for Machine Perception.Piscataway,NJ:IEEE Press,2005:52-57.
[12]Park J,Kim H,Tai Y W,et al.High quality depth map upsampling for 3D-TOF cameras[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2011:1623-1630.
[13]Rocchini C,Cignoni P,Montani C,et al.A low cost 3D scanner based on structured light[J].Computer Graphics Forum,2001,20(3):299-308.
[14]Morris N J W,Kutulakos K N.Dynamic refraction stereo[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2011,33(8):1518-1531.
[15]Warren P A,Mamassian P.Recovery of surface pose from texture orien-tation statistics under perspective projection[J].Biological Cyberne-tics,2010,103(3):199-212.
[16]Wu Zhirong,Song Shuran,Khosla A,et al.3D ShapeNets:a deep representation for volumetric shapes[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2015:1912-1920.
[17]Tatarchenko M,Dosovitskiy A,Brox T.Octree generating networks:efficient convolutional architectures for high-resolution 3D outputs[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:2107-2115.
[18]Wang Pengshuai,Sun Chunyu,Liu Yang,et al.Adaptive O-CNN:a patch-based deep representation of 3D shapes[J].ACM Trans on Graphics,2018,37(6):1-11.
[19]李海生,曹國梁,魏陽,等.三角網格曲面共形參數化研究綜述[J].圖學學報,2021,42(4):535-545.(Li Haisheng,Cao Guoliang,Wei Yang,et al.Survey on triangular mesh surface conformal parameterization[J].Journal of Graphics,2021,42(4):535-545.
[20]Wang Nanyang,Zhang Yinda,Li Zhuwen,et al.Pixel2Mesh:generating 3D mesh models from single RGB images[C]//Proc of European Conference on Computer Vision.Cham:Springer,2016:628-644.
[21]沈偉超,馬天朔,武玉偉,等.組件感知的高分辨率三維物體重建方法[J].計算機輔助設計與圖形學學報,2021,33(12):1887-1898.(Shen Weichao,Ma Tianshuo,Wu Yuwei,et al.Component-aware high-resolution 3D object reconstruction[J].Journal of Computer Aided Design & Computer Graphics,2021,33(12):1887-1898.)
[22]Zheng Yanping,Zeng Guang,Li Haisheng,et al.Colorful 3D reconstruction at high resolution using multi-view representation[J].Journal of Visual Communication and Image Representation,2022,85:103486.
[23]Li Haisheng,Zheng Yanping,Wu Xiaoqun,et al.3D model generation and reconstruction using conditional generative adversarial network[J].International Journal of Computational Intelligence Systems,2019,12(2):697-705.
[24]Zhang Xuancheng,Ma Rui,Zou Changqing,et al.View-aware geometry-structure joint learning for single-view 3D shape reconstruction[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2022,44(10):6546-6561.
[25]何鑫睿,李秀梅,孫軍梅,等.基于改進Pix2Vox的單圖像三維重建網絡[J].計算機輔助設計與圖形學學報,2022,34(3):364-372.(He Xinrui,Li Xiumei,Sun Junmei,et al.Improved Pix2Vox based 3D reconstruction network from single image[J].Journal of Computer-Aided Design & Computer Graphic,2022,34(3):364-372.)
[26]Chen Hui,Zuo Yipeng.3D-ARNet:an accurate 3D point cloud reconstruction network from a single-image[J].Multimedia Tools and Applications,2022,81:12127-12140.
[27]Wen Xin,Zhou Junsheng,Liu Yushen,et al.3D shape reconstruction from 2D images with disentangled attribute flow[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2022:3793-3803.
收稿日期:2022-12-15;修回日期:2023-02-09基金項目:國家自然科學基金資助項目(62277001);北京市自然科學基金—小米創新聯合基金項目(L233026);北京市教委—市自然基金委聯合資助項目(KZ202110011017)
作者簡介:陳雅麗(1998-),女,四川宜賓人,碩士研究生,主要研究方向為計算機圖形學、三維重建;李海生(1974-),男(通信作者),山東德州人,教授,博導,博士,主要研究方向為計算機圖形學、三維重建(lihsh@btbu.edu.cn);王曉川(1987-),男,陜西咸陽人,講師,博士,主要研究方向為計算機圖形學、圖像處理與質量度量、虛擬現實;李楠(1979-),男,北京人,教授,博士,主要研究方向為設計方法學、服務化設計與制造、智能工程.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
