基于傳統CNN-LSTM模型和PGAN模型的用電量預測對比研究
2023-10-19 00:31:14陳露東盧嗣斌徐常
電測與儀表 2023年10期
陳露東,盧嗣斌,徐常
(貴州電網有限責任公司電網規劃研究中心配網規劃室,貴陽 550003)
0 引 言
隨著時代變遷,人工智能在半個世紀的時間內曲折前進。大量的學者認為,在計算機時代,整個世界將進入人工智能時代[1]。隨著工業和人民生活水平的提高,對電力能源的供應量和供應效率都提出了更高的要求[2-4]。“智能電網”一詞大量出現在各大期刊和出版物上,已經引起了國內外學者的廣泛關注[5-6]。并且,在全球倡導綠色低碳,可持續發展的大背景下,智能電網已經從廣大學者的想法中找到了一條可行的道路,與人工智能相結合,應對設計和建設智能電網的挑戰。未來的智能電網是將信息和通信納入發電、輸電和消費的各個方面,盡量減少對環境的污染,增強電力能源的利用效率,降低成本的同時增強可靠性[7]。在智能電網發展下,大多數的電力問題通常都源于配電系統。其組件數量龐大,運行和控制相對緩慢需,并且需要較高的資本進行維護。配電網智能化升級是智能電網發展的核心,其中用電量的預測被認為是關鍵一步[8]。目前,傳統電網是一個剛性系統,電能的傳輸、儲存和分配等都缺乏彈性[9],使得傳統電網存在著效率低,電能浪費嚴重,信息交互能力弱和自動化程度低的缺點[10-11]。
以時間序列和回歸分析法為代表的傳統方法中,利用混沌時間序列方法進行了短期內的用電量預測[12]。此外還有研究表明稀疏懲罰分位數回歸分析在短期用電量預測內有著顯著的成效[13]。雖然傳統的預測方法能達到不錯的效果,但受到多種因素的共同影響,無法獲得精確的預測。近些年來以深度學習為代表的前沿智能學習方法運用在用電量分析的過程中,其無需建立準確的數學模型,就可以抽象出時間序列的特征。其中長短時記憶神經網絡在用電量領域已經有所研究,但其仍然處于預測方法的初級階段[14]。還有學者通過改進粒子群算法,依據不同粒子慣性權重選擇小波神經網絡尋優策略進行用電量預測[15]。然而在實際用電量預測中,對于復雜對象的用電量預測,單一測算法仍存在著很大的局限性。在統籌全局的情況下,選擇合適的智能算法,并且在權衡計算資源耗費的同時,達到用電量預測的最高效化。
一晃二十年過去了,他看著易非的父親從樓上跳下來,看著易非的母親處理喪事,看著易非求學和長大。他們都沒有斷聯系。他覺得易叔就像一棵被雷劈火燒過的樹木,死了,但枝干還在,怒指蒼穹,易非從死干上長出新枝,而長得愈發的急迫和頑強。對,就是急迫,就是這種感覺,可惜田有園表達不出來。
以產業園區用電量為例,分析兩種被廣泛應用的時間序列預測方法(自回歸模型和長短時記憶網絡模型),并提出了生成對抗網絡模型進行用電量預測。對比了三種智能算法在產業園區用電量預測中的效果,所得結果未來可以用于各大電網發電量、輸電量和損耗等預測。同時根據三種預測方法的效率和計算量,設計一套智能電網自動控制系統,對幾種方法進行合理高效的分配。將智能用電量預測和智能調控相結合,將大大地減少電力損耗,實現綠色可持續發展。
1 預測算法
介紹了對用電量預測的方法,其中包括自回歸模型預測,卷積神經網絡與長短時記憶網絡預測,和生成對抗網絡預測模型。這在結果章節對比這些智能算法所得結果。
1.1 自回歸方法
運用了差分整合移動平均自回歸模型(ARIMA),進行時間序列預測從而達到對用電量的預測。ARIMA是典型的時間序列模型之一,由三部分組成:自回歸模型(AR);滑動平均模型(MA)和差分階數(I)。
其中AR模型為:
yt=a0+a1yt-1+a2yt-2+…+apyt-p+εt
(1)
式中y1,y2,y3,…,yt為一個時間序列;p為自回歸階數;εt是均值為0,方差為σ2的白噪聲序列。值得注意的是,為滿足平穩性條件,要滿足|a|<1。
MA模型為:
yt=c+εt+θtεt-1
(2)
GAN用于時間序列預測問題,實質為生成器和鑒別器不停對抗的過程中,預測值不斷的逼近真實值,實現預測。生成器的輸入包括兩個方面,用電量數據的時間序列的概率分布和噪聲向量。鑒別器中輸入用電量數據和單步預測的標簽(真實觀測數據)。
自回歸移動平均模型(ARMA):
yt=c+a1yt-1+a2yt-2+…+apyt-p+εt+θ1εt-1+
θ2εt-2+…+θqεt-q
(3)
MA滑動平均過程在任何情況下都是平穩的,由于AR需滿足平穩性要求,故ARMA同樣要滿足平穩性要求:即等式的根均分布在單位圓外。如果存在有跟落在單位圓上,則此時的ARMA(p,q)過程稱為差分自回歸移動平均過程(ARIMA(p,d,q))。
在預測前,首先設計了三種簡單的方案進行初步預測,作為預測結果的對比標準,方案一為將一周前同期的用電量作為預測值,方案二為將一月前同期的用電量作為預測值,方案三為將一年前同期的用電量作為預測值。從測試集中隨機抽取一周數據,分別應用三種方案所得結果如圖4所示,根據計算均方誤差的結果可以看出,三種方案存在著明顯的差異,其中方案三的效果最好,方案一、二效果接近,這可能與季節氣候變化、節假日安排和經濟狀況有著一定的關系。方案三效果較好,但是總體均方誤差仍處于較大的水平(均方根誤差>450),只能大致預測用電量變化,難以精確預測。將這三組數據作為預測結果的比較標準,對三種不同的算法進行評估。
yt-yt-1=(a-1)yt-1+εt
(4)
Δyt=yt-yt-1=(a-1)yt-1+εt
(5)
Δ(Δyt)=2yt=(yt-yt-1)-(yt-1-yt-2)
(6)
在ARIMA模型中,差分運算的作用是使得時間序列恢復平穩。
1.2 長短時記憶網絡預測
條件生成對抗網絡(CGAN)是GAN的一個擴展,它使模型限定在一些額外的信息y上,y可以是任何類型的輔助信息。因此設置的新值函數為:
在時間序列處理的研究中,LSTM網絡是一種十分常用的時間遞歸神經網絡(如圖1所示)。其通過引入記憶單元對傳統的遞歸神經網絡(RNN)進行了升級。其內部主要包含三個步驟,首先是忘記步驟,通過忘記門σf對上一時刻的輸入狀態ct-1進行控制,過濾不重要的信息。其次是選擇階段,通過選擇門的控制信號σi來記錄有用信息。兩個步驟所得結果為當前狀態ct。最后一步為輸出,通過控制信號σo對輸出門進行控制,得到最終輸出ht。其中,tanh為激活函數對狀態量和輸入量進行放縮,X為輸入的時間序列。
各地湖泊管理單位根據自身情況建立了相應的高郵湖湖泊巡查網絡,完善巡查制度,湖泊巡查工作有序開展,為維護湖泊良好的水事秩序,對控制涉湖違法水事案件的發生起到了積極顯著的作用。

圖1 長短時記憶網絡(LSTM)框架圖
1.3 生成對抗網絡預測
近年來,生成對抗網絡(GAN)被應用于序列數據領域的各種問題,并取得了顯著的效果。目前GAN多用于生成聽覺,圖像和文字數據,但由于這些研究不涉及預測,其結果是可以被評估的[16]。 在預測中應用GAN是具有十分大的挑戰,因為目前沒有一個統一的評估標準。
GAN是一類從數據概率分布中給定一組樣本模擬概率分布的算法,其結構如表1所示。

表1 生成對抗網絡的結構
一個GAN由兩個神經網絡組成,即發生器G和鑒別器D,這兩個神經網絡在對抗過程中同時被訓練。首先,從已知概率分布Pnoise(z)(通常為高斯分布)中采樣噪聲向量z。G以噪聲矢量z為輸入,訓練生成一個分布服從Pdata的樣本。另一方面,對D進行優化,以區分生成的數據和真實的數據。D和G用值函數進行以下兩人極小極大對策:
V(G,D)
(7)
(8)
CNN是一種包含輸入層、卷積層、池化層、全連接層和輸出層的一種前饋神經網絡,CNN網絡的目的是對目標進行特征提取,通過對數據的卷積和池化處理,可以提取出隱藏在數據背后的特征關系。
Ez~Pz(z)[log(1-D(G(z|y))]
(9)
比如,當教師在講解課文《我們愛你啊,祖國》時,便可以通過以下方式開展教學:首先,教師可以通過信息技術在網絡平臺上下載與教學內容相關的素材,加深學生的感受,營造合適的教學氛圍。其次,教師可以為學生展示巍峨聳立的泰山、莊嚴肅穆的故宮以及宏偉壯麗的布達拉宮。在一幅幅動態或靜態的畫面中,學生能夠感受到中國的偉大,同時也能夠加深對祖國的熱愛之情,形成一定的知識記憶。
從表2可以看出,攀枝花優質鈦精礦經流態化氧化→流態化還原→常壓一段流態化浸出及過濾、洗滌、干燥煅燒后,鈦精礦中TiO2品位可從47%左右提高至約90%,CaO+MgO總含量從7.5%左右降至約1.5%,其中CaO含量在0.75%左右,SiO2含量5%左右,不滿足大型沸騰氯化法生產鈦白粉對原料的要求。為了進一步降低產品中雜質元素含量,對人造金紅石產品進行了磁選試驗。經磁選后人造金紅石TiO2含量≥92%,CaO+MgO總含量約0.6%,其中CaO含量在0.3%以上,SiO2含量4%左右,仍高于氯化鈦白原料對CaO和SiO2的指標要求。
構建體育教師教育專業化框架,首先要分析專業發展的所屬范疇。專業化框架歸根到底是實施主體作用機制下制度、層級、模式及相互關系的建設。構成體育教師教育專業化框架要遵循專業發展發展的基本運行機制,制度層面的設置基于體育專業標準及體育教學課程標準的教育培訓制度和資格認證制度;層級層面體現出體育教師教育培訓和資格認證的等級性和終身性;模式層面設置體育教師的教育培訓模式和資格認證模式等。基于專業社會學的理論,可以整合出兩個維度來分析體育教師的專業化框架構建的問題,且這兩個維度在一定程度上包含了以上各個層面所涉及的內容。
以貴州產業園區用電量的歷史數據為基礎,進一步建立超前值xt+1的概率分布模型:
對發電機整體在安裝彈性支撐為10kN/mm的彈性支撐時進行模態仿真分析,彈性支撐主要參數如表4和表5所示,前9階振動頻率如表6所示,其中前9階靜態剛度時振型如圖3所示(由于前9階振型一致只是頻率不一致,動態剛度振型圖在此省略)。
c={x0,…,xt}
(10)
P(xt+1)
(11)
使用CGAN進行模擬:
P(xt+1|c)
(12)
如圖2所示,建立預測生成對抗網絡模型(PGAN),歷史數據作為條件提供給發生器和鑒別器。發生器從平均值為0和標準偏差為1的高斯分布中抽取噪聲向量,并根據條件窗口c預測xt+1。鑒別器獲取xt+1并檢查它是否是跟蹤c的有效值。因此,進一步更新函數為:
突然響起一波噓聲,我抬起頭,看見電視屏幕上出現了首相,她的頭發甚至比平日更加灰白。她站在唐寧街首相官邸外面,一身穿著和她離開前往外星人母艦時一模一樣。
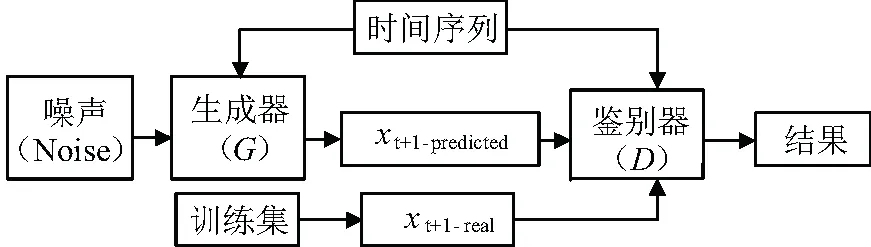
圖2 預測型生成對抗網絡框架圖
Ez~Pz(z)[log(1-D(G(z|c))]
(13)
通過訓練該模型,最優生成器對給定條件下xt+1的全概率分布進行建模。掌握了完整的概率分布后,可以通過抽樣來提取關于任何可能結果及其發生概率的信息。
通常,預測模型是通過優化某一個點的狀態誤差作為損失函數來訓練的,而GAN采用對抗性訓練來訓練神經網絡實現預測目的。將均方根誤差(RMSE)優化為損失函數來訓練該模型,并將其結果與另外兩種常用的預測模型的結果進行了比較。
在訓練GAN時,生成器G學習將已知的概率分布Pz轉換為與Pdata相似的生成器分布PG。
2 用電量預測結果分析
在智能電網覆蓋城市的大背景下,對用電量進行預測,并且進行自動化調控,檢測工廠、發電站和第三產業用電等。文中選取了中國貴州某產業園區3年以來的用電情況作為例子,來研究數據采集準備方法,和不同方法架構之間的比較。
2.1 數據預處理
數據集包含日期、時間信息,有功功率,無功功率,平均電壓,平均電流這6個變量。對于用電量預測實驗來說,數據集中的數據是不完整的,并且得到的數據集中包含了大量的異常值。兩種方法可以去替換異常值:(1)利用異常值前一天和后一天同時間值的平均值代替。(2)利用一年前同時間的值代替。由于季節和節假日等因素影響,方案2的效果更加理想。每種屬性以時間序列記錄,其采樣周期為1分鐘如圖3(a)。由于預測不需要做到分鐘的精度,這樣不僅耗費資源,浪費時間,也沒有實際意義。對每段時間序列進行了降采樣,以天為單位如圖3(b),這樣可以大大提升用電量預測的效率和實際意義。數據集中包含3年的數據,用前2年的數據作為訓練集,最后1年的數據作為測試集,定義RMSE為衡量預測結果好壞的標準,RMSE值越小,說明模型預測結果越好,均方根誤差值越大,說明模型預測結果越大。并且從測試集中隨機抽取一周數據,來展示預測效果。
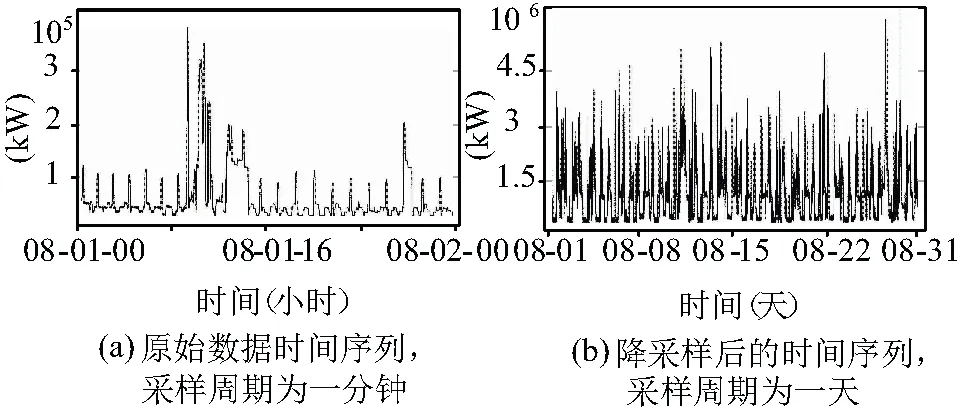
圖3 數據集中的時間序列圖例
2.2 建立基礎預測標準
差分運算表達式:
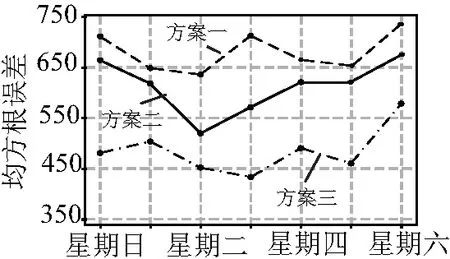
圖4 簡單模型方案下一周用電預測結果
2.3 ARIMA模型預測結果
使用循環神經網絡(RNN)作為產生器和鑒別器的主要組成部分。圖7中,生成器獲取條件用電量時間序列并通過RNN層傳遞條件來構造其表示。然后,將條件表示與噪聲向量連接起來,通過兩個密集層,得到預測的t+1時概率模型(xt+1)。如圖8所示,鑒別器從產生器或數據集中沿著相應的條件用電量時間序列獲取xt+1,并在條件用電量時間序列的末尾連接xt+1以獲得{x0,…,xt+1}。并檢查時間序列的有效性。結果如圖9所示,相比基礎預測標準的均方根誤差出現了顯著的下降,如圖10。GAN預測的結果優于CNN與CNN-LSTM預測結果,并且預測時間也較其有所縮短。對兩類模型的均方根誤差進行t檢驗,自回歸模型的均方根誤差顯著低于基礎預測標準(P< 0.05)。
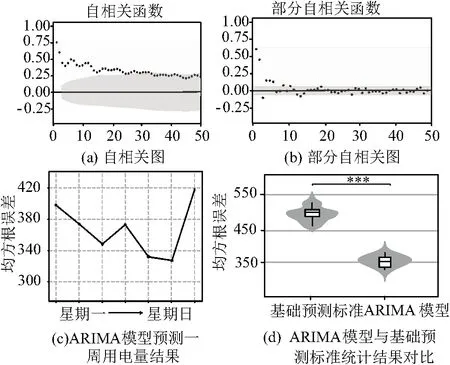
圖5 ARIMA模型以及預測結果
結果如圖5(c)所示,均方根誤差出現了明顯的下降,與基礎預測標準相同的是,星期天與星期六的用電量預測值仍然誤差較大。但整體的準確性得到了大幅提高,即預測天數的平均均方誤差得到了顯著的降低(簡單模型平均均方誤差約為 514,自相關函數模型平均均方根誤差約為369)。如圖5(d),對兩類模型的均方根誤差進行t檢驗,自回歸模型的均方根誤差顯著低于基礎預測標準(P< 0.001)。
2.4 CNN與CNN-LSTM預測結果
考慮到降采樣后,訓練集的數據較少。故在進行深度學習預測前,更改采樣周期,放棄標準周的限定,而是對每7天的數據進行一次采樣,對已有訓練集進行擴充。將數據集擴大7倍。對卷積神經網絡進行訓練并且得出預測結果(見圖6),發現CNN所得結果的確較基礎預測標準有了明顯提高,但是與ARIMA模型所得結果差距不大,并且訓練所花費的時間也遠遠大于ARIMA模型所花費的時間,所以認為CNN不適合應用在用電量預測方面。相較CNN,增加了LSTM結構后,大大的增加了神經網絡的預測準確率,并且兩者組合的模型更加穩定,預測誤差效果更加理想。卷積神經網絡去提取特征,長短時記憶網絡去解釋這些特征。預測結果如圖6所示,準確率大大提高,平均均方根誤差降低到了350以下。在用電量方面有了質的飛躍。
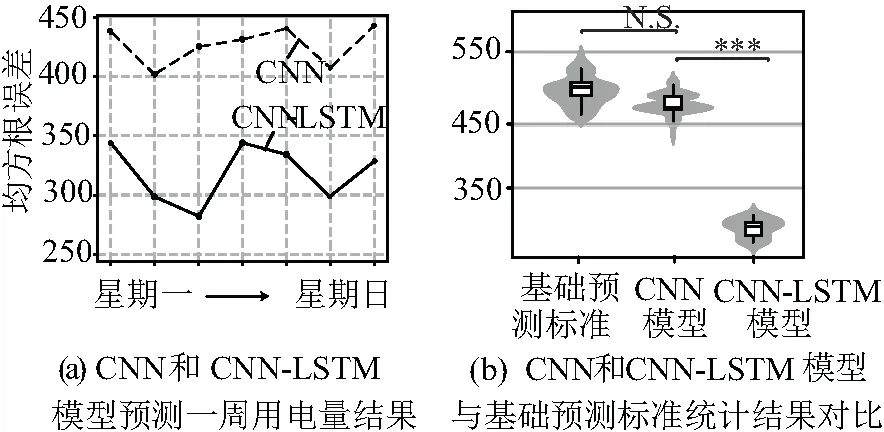
圖6 利用CNN和CNN-LSTM模型預測用電量結果
2.5 PGAN預測結果
式中c表示常數項;θ表示系數。
作品以行刺秦王為題材,意在展現一群仁人志士當燕國國勢迫急之際而展現出來的為信義而輕生死的精神力量,這種精神力量在與強秦以欺詐和暴虐吞并列國的行為對比中,在“勢”與“道”之爭中,建起了另一座價值豐碑。
首先畫出自相關函數圖和部分自相關函數圖,來確定開始模型的滯后觀測值設置,如圖5(a)所示,自相關圖中,發現了較為顯著的滯后觀測量,并且隨著滯后的增加相關性逐漸減小。圖5(b)中,自相關系數呈現出拖尾特征,逐漸減小,部分自相關系數的前6階不在置信區間內,并且關注到在第7個分量處出現了明顯的不同,因此選取6階附近的幾個階數作為AR模型的階數,然后對結果進行比較,最終選擇模型為AR(7),此時均方根誤差為最低。

圖7 生成器結構圖
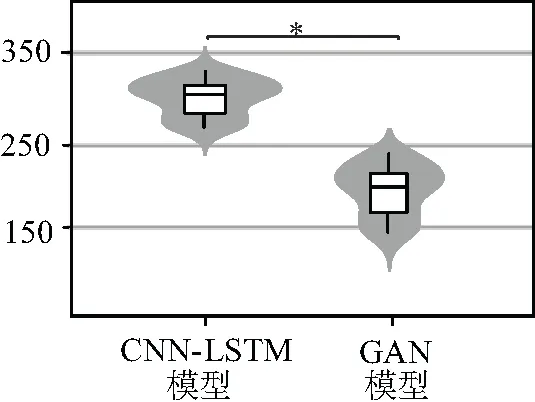
圖8 鑒別器結構圖
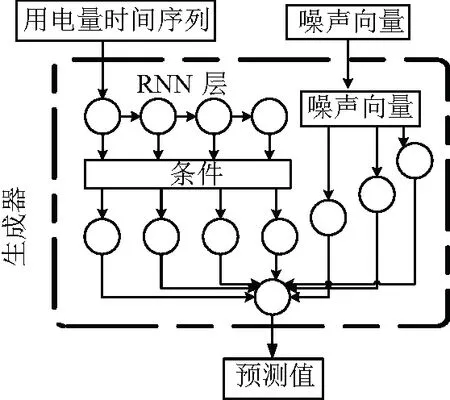
圖9 GAN模型預測一周用電量結果
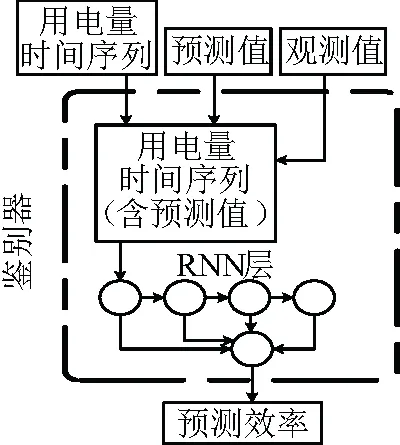
圖10 CNN和CNN-LSTM模型與GAN模型統計結果對比
2.6 智能預測用電量網絡設計
如表2所示,三種算法在用電量預測方面的應用各有優劣,面對的用電量預測這一個實際問題,要考慮許多現實因素。CNN-LSTM模型計算精度高,但是計算時間長,占用資源大,不適宜廣泛應用于各類用電量預測。ARIMA模型精度較低,但是計算時間短,可以高效地預測大規模的用電量。GAN網絡較好的綜合了兩者優點,訓練時間較短并且預測正確率較高。
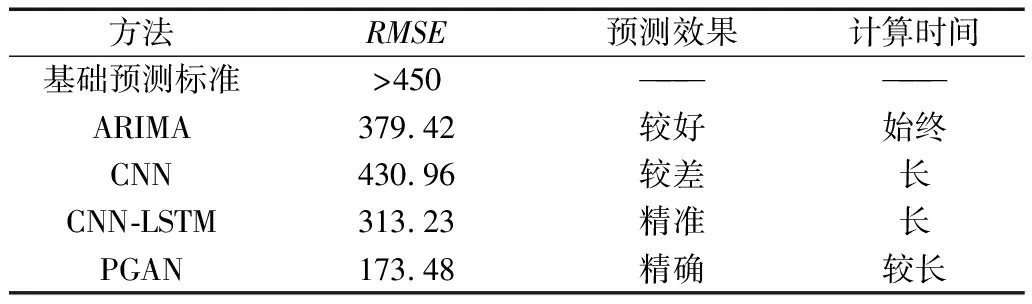
表2 用電量預測RMSE平均值結果比較
在智能電網的大背景下建立用電用戶自動篩選系統,在該系統中集成ARIMA模型,CNN-LSTM模型和GAN模型,利用ARIMA對智能電網下各類用電量進行初步預測,根據用電用戶重要性和優先級選擇用電量預測方法。并且建立反饋通路,將預測的結果與實際的比較結果作為校正值反饋給模型,如果遇到誤差持續過大的情況,可以利用更高級的模型進行計算,并且對其進行校正,這樣大大提高了用電量檢測的效率。圖11中的流程圖,是根據對方法的研究,設計的多算法融合用電量預測系統。根據算法的復雜程度將預測的模型分為初級模型,中級模型和高級模型。從智能電網數據庫中讀取各類用電量數據,并與安裝在終端的智能傳感器采集的環境數據結合,生成用電量歷史數據集,對用電用戶進行評估,分別用三種模型進行預測,對于一些不間斷用電的用電用戶,可以直接給出預測值。預測值發送到智能配電網和智能發電廠進行電力資源的調配。同時,設計一個反饋系統,從智能電表上采集實時用電量,與預測值進行比較,反饋誤差來對系統進行自動調控。
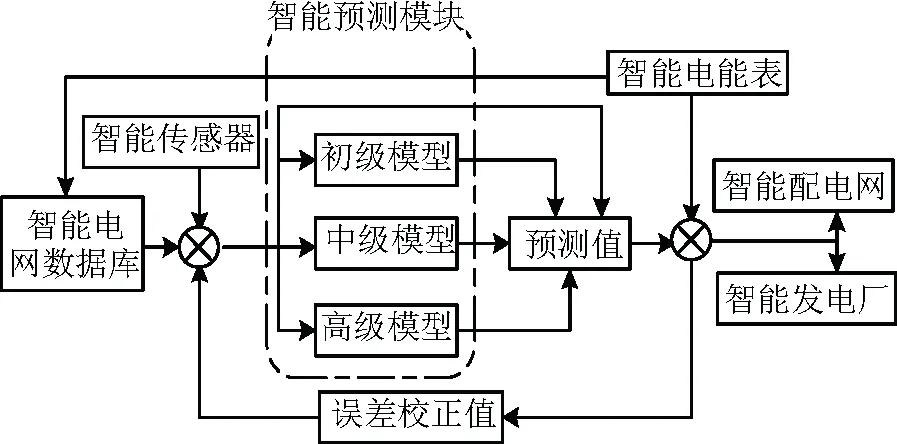
圖11 智能電網中預測用電量流程圖
從現有數據集中選擇產業園區連續6個月的用電量,并且按照不同類型(工業用電,生活用電和基礎設施用電)的用電量分為三組,分別模擬國家依據可靠性要求分為三類符合用戶對象:一類用戶(突然中斷供電將會造成人身傷亡或會引起周圍環境嚴重污染的,將會造成經濟上的巨大損失的,將會造成社會秩序嚴重混亂或在政治上產生嚴重影響的用戶)、二類用戶(突然中斷供電會造成經濟上較大損失的,將會造成社會秩序混亂或政治上產生較大影響的用戶)、三類用戶(不屬于上述一類和二類負荷的其他用戶)。以第1個月的數據作為數據集,后5個月為測試集。對提出的智能預測用電量網絡測試。按照用電量的等級,選擇相對應的預測方法,并且對結果進行評估。提出一個效率評價指標E,它等于均方根誤差與時間的乘積的倒數。在實際試驗中,隨著數據量的增加,平衡時間與準確性,智能用電量預測模型的效率評價指標越高,并且顯著的高于使用單一預測方法的效率評價指標。故所提出的智能預測用電量網絡為未來智能電網下的用電量規劃提供了一種新的思路
基于無公害中藥選肥原則:選用國家生產綠色食品的肥料使用準則中允許使用的肥料種類,所有的肥料應以對環境和作物不產生不良后果的方法使用。黃芩施肥應堅持以基肥為主、追肥為輔和有機肥為主、化肥為輔的原則。有機肥包括高溫腐熟、殺菌處理后的堆肥、廄肥、沼肥、綠肥、作物秸稈、泥肥、餅肥等;生物菌肥包括腐殖酸類肥料、根瘤菌肥料、磷細菌肥料、復合微生物肥料等;微量元素肥料即以銅、鐵、硼、鋅、錳、鉬等微量元素及有益元素為主。
3 討論
當下,很多研究者對智能電網展開研究。結合物聯網、大數據和智能算法等,已經做出了十分多的用電量預測方案[17]。有研究者提出基于多表融合的方法對用戶短期用電量進行預測,將水、電、氣三表數據合一,利用機器學習算法對用戶用電量做出了預測,得到十分理想的效果[16,18-19]。
用電量預測已經成為智能電網規劃中重要的一環,其發展關系到智能電網的建設以及城市的發展。本文利用了ARIMA模型、CNN-LSTM模型和PGAN模型對用戶用電量進行預測,并對其在用電量預測中的效果進行了評估,結合各類方法的特點,提出智能電網中用電量預測具體的實現模型。并且對未來的智能電網的部分系統結合用電量預測模塊設計出控制圖,具有很理想的實際意義。
4 結束語
文章主要研究生成對抗網絡等模型在用電量預測方面的應用。綜合各類算法的優劣,設計了用電量預測系統,并將該系統運用在智能電網系統中。為智能電網動態規劃和優化提供了新的思路和方法。對產業園區用電數據進行預測,得出結論:
總體而言,對人的主體性關切已經成為學界闡釋馬克思實踐觀的核心入路,在這一基礎上,研究者們從不同的視域進行了各具特色的詮釋。以上所述關于實踐的本體論、價值論、人類學等不同視域對馬克思實踐范疇的理解和闡釋充分說明了馬克思實踐觀在馬克思哲學體系中的核心地位,就此而言,對馬克思實踐范疇的理解從根本上影響著研究者對整個馬克思哲學的認識和把握。
(1)創新性的將生成對抗網絡運用在用電量預測中,并且在用電量預測中有著很好的效果。
所謂防風固沙林,是指以通過降低風速,防止或者減緩風蝕、固定沙地,保護耕地、果園、牧場等以及農作物免受風沙侵襲為主要目的,而營造的喬木林和灌木林。如:油松、樟子松、楊樹、檉柳、橡櫟、山杏、白蠟、紫穗槐、沙棘、荊條、梭梭、胡枝子等等。
但考慮到訓練時間和對計算資源的占用,這種算法并不適合運用在全面的用電量預測中;
2017年省級黨委和政府扶貧開發工作成效考核反饋廣西的問題清單中,關于扶貧資金使用管理的問題共有12項,直接點名的有馬山、田東、寧明等10個縣(市)。上述各縣(市)對整改工作責無旁貸;其他市、縣也要擺正心態,根據中央和自治區檢查反饋的問題,主動對號入座,對本地區脫貧攻堅工作開展全面自查自糾,形成問題清單。各市、縣要以問題清單為線索,深入分析導致問題的主觀原因、制度原因、作風原因,真正把問題找全、把根源找準,做到精準整改,重點突破,確保問題全面整改到位。
(2)針對未來智能電網中用電用戶的復雜程度、規模旁大和優先級順序等特點,設計智能用電量預測系統,對不同的用電用戶加以區別,分別采用不同種類的預測方法,使得實驗效率最優化。
文中不僅將生成對抗網絡應用在用電量預測中,更在智能電網的規范發展上提出了一種高效精準的用電量預測方案,可以結合環境、政策和經濟等因素變化,實現良好的自我調節。并且對于用電量的預測從側面也可以很好地把握國家的宏觀經濟調控和走勢,使得國家可以及時對發展戰略進行調整,掌握產業發展特點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
光學精密工程(2016年6期)2016-11-07 09:07:19
