基于機器學習的網站漏洞預警研究
——以代購系統為例
2023-10-24 07:35:36鄧明體
裝備制造技術 2023年8期
鄧明體
(廣西水利電力職業技術學院,廣西 南寧 530023)
0 引言
當前,各家代購公司模式競爭眾多,競爭激烈,比如專注于海外直郵的公司、代購公司、代售公司等,在市場競爭中人們非常關注品牌的影響力及安全問題。對于代購系統來說,對于未來的發展,除了完善物流服務,暢通的物流鏈使客戶能及時收到貨物,提高了消費者的整體體驗,還要有技術創新,持續提升技術,建立健全的移動終端等網絡代購系統,使購物者可以直接通過手機或電腦進行海外代購,免去了傳統繁瑣的流程,而保證代購系統的健康安全運行是上述條件的基礎。由于代購系統存在漏洞,讓不法分子有機乘,可修改程序,破壞系統運行,嚴重可給公司的運行帶來了災難的打擊[1]。因此,及時的修補代購系統的安全漏洞是安全管理員的重要工作之一。漏洞預警是代購系統建設中的重要的一個步驟,越是及時收到漏洞預警信息越能夠及時進行響應。比如當阿里云漏洞庫更新了一條漏洞預警信息(圖1),安全管理員想第一時間收到通知,實現漏洞監控預警具有顯著的現實意義。

圖1 阿里云漏洞庫
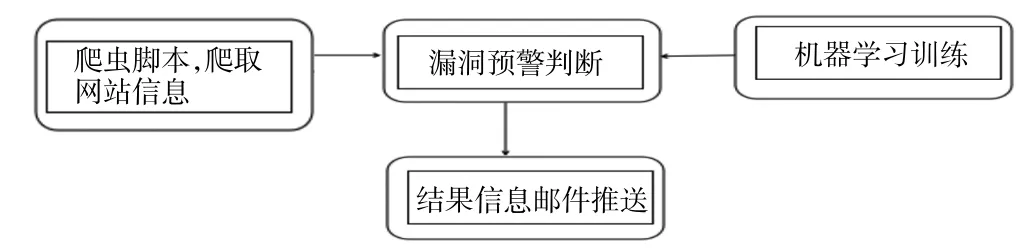
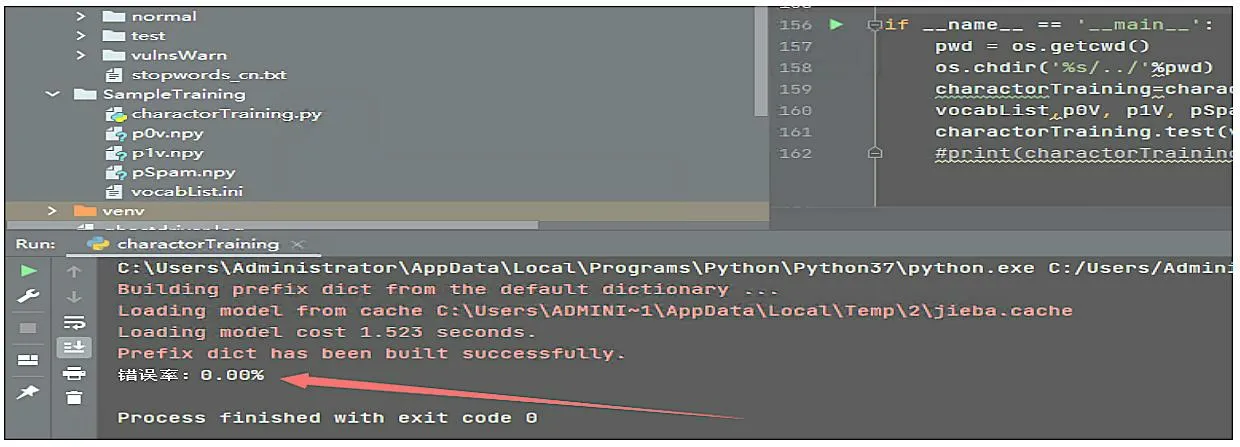
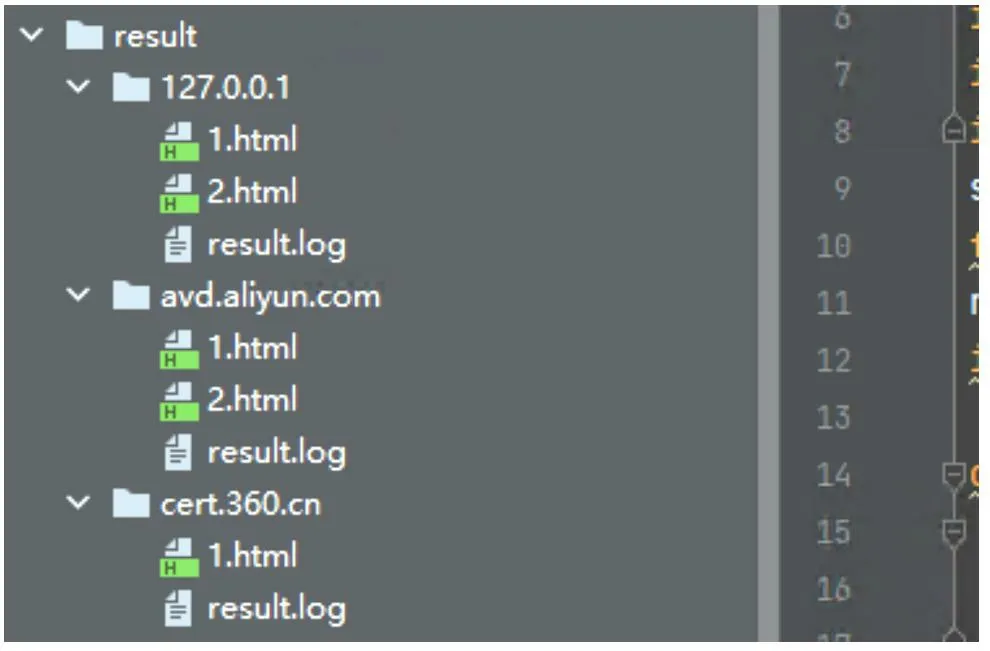
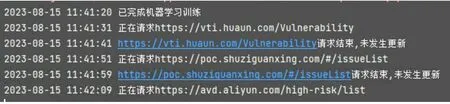
安全管理員傳統的做法是設置python 定時爬蟲,提取包含漏洞信息的對應 把監控頁面變更前后的所有文本變化信息提取出來,再使用基于機器學習識別變更內容是否是漏洞預警信息,在這里方案中使用的機器學習算法是樸素貝葉斯[2]。分類是數據分析和機器學習領域的一個基本問題,現實生活中樸素貝葉斯算法應用廣泛,如文本分類、垃圾郵件的分類、釣魚網站分類等。例如想知道哦一個人的年收入是否達到中產階級水平,可以收集樣本人群的信息,根據年齡、工作單位的性質,學歷、受教育時長、職業、家庭情況、性別、資產所得等信息來評估,這樣就可以建立分類模型來判斷個人的年收入等級。 算法分為有監督、無監督的學習算法,而樸素貝葉斯是有監督算法,它是基于貝葉斯定理與特征條件來假設的分類方法[3]。監督學習它的目的是讓模型能夠從已知的輸入和輸出之間的關系中學習,并且能夠對新的輸入做正確的預測。監督學習有很多種算法,每種算法都有自己的優缺點,適用于不同的問題和數據。比如常見的監督學習算法有線性回歸、邏輯回歸、決策樹、支持向量機、神經網絡等。不同的算法適用于不同的問題和數據,選擇合適的算法需要考慮很多因素,比如數據的特征、規模、分布、噪聲等,以及模型的復雜度、可解釋性、穩定性等。一般來說,沒有一種算法是萬能的,需要根據具體的情況進行比較和測試,才能找到最優的解決方案。在上述方案中,為什么選擇樸素貝葉斯算法,原因分析如下:使用邏輯回歸算法,缺點是不能處理非線性的關系,也不能處理回歸問題。使用決策樹算法,缺點是容易出現過擬合,也容易受到噪聲和異常值的影響。使用支持向量機,可以出來復雜的關系,但是計算效率低,選擇參數困難。綜上所述,使用樸素貝葉斯算法效率將優于其他算法。 根據前面的分析,我們需要實現4 個功能:(1)爬蟲腳本功能;(2)漏洞預警判斷功能;(3)機器學習訓練功能;(4)結果信息郵件推送功能。結構關系如圖2所示。 圖2 功能結構 爬蟲腳本功能:主要實現采集網站的信息,并把他轉換成文本形式保存到文檔中。機器學習訓練:主要實現選擇合適算法,導入合適的樣本數據,訓練模型。漏洞預警判斷:主要實現采集真實的安全網站信息頁面,并把漏洞信息分離出來。結果信息郵件推送:主要實現把漏洞信息通過郵件發送到安全管理員的郵箱中。 我們從國內一些漏洞預警平臺(比如:阿里云漏洞庫、360 、riskivy)收集漏洞預警樣本,基于樸素貝葉斯算法訓練程序識別漏洞預警信息特征。每十分鐘爬取一次監控頁面,對比上一次頁面信息,提取差異內容,基于機器學習訓練結果讓程序判斷差異內容是否是漏洞預警信息,如果是則通報。 (1)爬蟲腳本采集樣本 第一步,我們先使用爬蟲腳本采集安全網站上的25 份漏洞預警樣本,單獨把每一個樣本放入文件txt中。在訓練漏洞預警樣本時,去掉一些高頻詞,比如“的”“一”“在”,具體去掉的高頻詞和標點符號整理到stopwords_cn.txt。因為去掉樣本中的這些非關鍵詞,后續調用程序判斷時,可以提高分類準確率。第二步,我們再整理25 份非漏洞預警樣本,單獨把每一個樣本放入文件txt 中。 (2)機器學習訓練-基于樸素貝葉斯算法進行樣本 通過上述50 份樣本進行訓練,保存訓練結果到vocabList,p0V,p1V,pSpam 參數中。為了檢查訓練結果的準確度,我們又整理了10 份漏洞預警信息,10份普通文本信息,測試效果如圖3 所示。 圖3 測試結果 測試結果:錯誤率為0%,即正確率為100%。其結果符合預期的要求。 (3)漏洞預警判斷 大部分站點頁面內容都是基于JS 渲染出來的,簡單的requests.get 獲取不到頁面信息,因此使用phantomjs 模擬瀏覽器解析JS。phantomjs 是一個基于WebKit 的無界面的瀏覽器,可以用于自動化網頁操作和測試。它具有以下功能:網頁截圖,可以將網頁完整地截圖保存為圖片文件;頁面渲染,可以將網頁加載并渲染,獲取渲染后的頁面內容;頁面交互,可以模擬用戶的點擊、輸入等操作,與頁面進行交互;網絡監控,可以捕獲網頁中的網絡請求和響應,用于網絡性能分析和調試;自動化測試,可以用于編寫和執行自動化測試腳本,對網頁進行功能和性能測試;網絡爬蟲,可以用于抓取網頁內容,進行數據采集和分析。網頁性能分析:可以分析網頁的加載性能,包括資源加載時間、渲染時間等;腳本執行,可以執行JavaScript 腳本,操作網頁元素,修改頁面內容等。總之,PhantomJS 提供了一種無界面的瀏覽器環境,可以用于實現各種網頁操作和測試的需求。監控目標列表放在項目根目錄下的urls.txt 文件里,默認url 列表如下: https://vti.huaun.com/Vulnerability https://poc.shuziguanxing.com/#/issueList https://avd.aliyun.com/high-risk/list https://nox.qianxin.com/vulnerability https://sec.sangfor.com.cn/security-vulnerability http://www.cnnvd.org.cn/web/vulnerability/querylist.tag 在crawlspider 爬蟲腳本目錄下面有以下幾個文件:monitor.py、phantomjs,上述方案中把功能實現的代碼寫在monitor.py 中,關鍵代碼如下: #先提取html 文本,再進行比較 def compareHtml(self,file1,file2): text1 = '' text2 = '' with open (file1,'r',encoding='utf-8') as f://讀取第一個網頁的文本 text1str = f.read() text1=self.filter_tags(text1str) with open (file2,'r',encoding='utf-8') as f://讀取第一個網頁的文本 text2str = f.read() text2=self.filter_tags(text2str) d = difflib.HtmlDiff() //比較兩個網頁的文本的不同 htmlContent = d.make_file(text1,text2) with open('diff.html','w',encoding='utf-8')as f: f.write(htmlContent) //把兩個網頁的文本的不同的地方寫入文件 soup = BeautifulSoup (htmlContent,'html.parser') diffContentHtml = soup.find_all ("span",class_="diff_add") diffContent = '' for dif in diffContentHtml: diffContent += HTMLParser(dif.text).text() diffContentHtml = soup.find_all ("span",class_="diff_chg") for dif in diffContentHtml: diftext = dif.text if diftext not in text1str: diffContent += HTMLParser(diftext).text()return diffContent 最后把爬取的結果保存在1.html 和2.html 中,把比較不同的信息保存在result.log 的文件中。例如在爬去取阿里云漏洞庫網站的結果如圖4 所示。 圖4 文件 (4)機器學習核心功能實現 我們使用機器學習判斷爬取的信息是否是漏洞信息,爬取的核心代碼如下: def samTest(self): .. ... for folder in folder_list: new_folder_path = os.path.join('./Sample/vulnsWarn',folder) with open(new_folder_path,'rb') as f: raws = f.readlines() for raw in raws: wordList = self.textParse(raw) docxList.append(wordList) claList.append(1) # 標記漏洞信息,1 表示是漏洞預警信息 folder_list = os.listdir('./Sample/normal') for folder in folder_list:# 遍歷文件夾 new_folder_path = os.path.join('./Sample/normal',folder) with open(new_folder_path,'rb') as f: raws = f.readlines ()# 讀取文件 for raw in raws: wordList = self.textParse(raw) docxList.append(wordList) claList.append (0) # 標記非漏洞樣本,0 表示不是漏洞預警信息 vocabList = self.createVocabList (docxList)# 建立分詞列表 trainMat = []# 訓練集矩陣 trainClasses = []# 訓練集類別向量 for docIndex in range (len (docxList)):# 遍歷訓練集 trainMat.append(self.setOfWords2Vec(vocabList,docxList[docIndex])) trainClasses.append(claList[docIndex]) p0V,p1V,pSpam = self.trainNB0(np.array(trainMat),np.array(trainClasses)) # 訓練模型 return vocabList,p0V, p1V, pSpam# 返回結果 該程序十分鐘爬取一次,將爬蟲結果保存下來,1.html 是上一次爬蟲結果,2.html 為最新爬蟲結果。對比前后十分鐘結果,提取新增內容的文本信息,根據機器學習效果判斷是否是漏洞預警信息,在result.log里可以看到每次對比信息。其實本身一個站點只監控一個頁面,訪問頻率可以適度加大也沒有問題。檢測效果如圖5 所示。 圖5 運行效果 為了提高分類的準確率,方案設計時要從以下幾方面去入手。擴大數據集,有實驗證明,良好的樣本的數據能打敗更好的算法。如果想要提高機器學習的分類準確率,首先想到的就是擴大數據集。樣本數據足夠多,只要機器學習花費的時間在可以接受的范圍內,數據集就可以繼續擴大,它可以使方案設計時獲得更優秀的分類準確率。主要在這幾方面改進:(1)訓練階段改進;(2)算法改進。 方案通過分析網頁漏洞信息的特征,采用了基于貝葉斯算法的網頁漏洞信息的檢測,給出了利用該模型進行網頁漏洞信息預警推送的設計方案。實驗測試數據分析,該方案可以檢測出網頁漏洞信息,為了提高判定數據的準確率,我們可以增加樣本數據。綜上所述,代購行業正在經歷飛速發展,其增長的空間還是很大的,但要想實現長足發展,還需要繼續加強行業的技術創新,優化行業服務,完善有關政策,以推動行業的可持續發展。1 樸素貝葉斯算法
2 功能結構設計
3 關鍵技術具體實現
4 實驗測試
5 基于機器學習的網站漏洞預警的建議
6 結語
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
