一種高效運動想象腦電信號淺層卷積解碼網絡
2023-10-29 10:06:50李文平徐光華張凱張四聰趙麗嬌李輝
西安交通大學學報 2023年10期
李文平,徐光華,2,張凱,張四聰,趙麗嬌,李輝
(1. 西安交通大學機械工程學院,710049,西安; 2. 西安交通大學機械制造系統工程國家重點實驗室,710054,西安; 3. 西安交通大學經濟與金融學院,710061,西安)
腦-機接口(brain-computer interface, BCI)是一種允許使用者使用大腦神經信號來控制如假肢、外骨骼、輪椅等外部設備的系統[1-3]。基于運動想象(motor imagery, MI)范式的腦-機接口系統,其典型過程為采集大腦在動作想象時的電信號,經過數據預處理與特征提取,再對想象任務進行識別與分類,最后形成相對應的控制指令[4]。目前用于運動想象腦-機接口系統的腦電信號有植入腦電、皮層腦電和頭皮腦電[5]等。頭皮腦電采用電極帽或將電極平貼于頭皮上記錄數據,是一種非侵入式的信號,與其他腦電信號相比,具有安全性高、易用、低成本、便攜等方面的優點,但同時也犧牲了信噪比與空間分辨率[6-7]。由于基于運動想象的腦-機接口系統的性能主要取決于信號解碼算法的性能,因此提高解碼算法的信息傳輸率對提升腦-機接口系統性能有著至關重要的作用。
共空間模式(common spatial pattern,CSP)特征提取方法,結合支持向量機(SVM)等機器學習分類算法,在二分類任務的運動想象腦電解碼方面取得了較好的效果[8-9]。之后,許多學者對初始的CSP方法進行了諸多改進研究,Ang 等[10]針對CSP方法中頻帶選擇問題,提出了濾波器組共空間模式(FBCSP)算法,使用等頻寬的濾波器組對信號進行分解,在每個頻段信號提取CSP特征,再使用互信息的特征選擇方法進行特征選擇。鑒別濾波器組CSP (DFBCSP) 算法[11]、共時空頻CSP(CTFSP)算法[12]、雙譜熵(BECSP)算法[13]等一系列優化算法被相繼提出,以期能提取更加顯著的運動想象腦電信號特征。然而,上述運動想象解碼算法均需要手動對信號進行特征提取,因此解碼的性能十分依賴于專業的相關知識與經驗。
基于人工神經網絡(ANN)的深度學習方法很大程度上緩解了人工參與特征提取的需求,例如,在計算機視覺(CV)[14]與語音識別(audio recognition)[15]領域已經實現了遠超于人工提取特征的識別效果,并獲得了最先進的性能。近年來,許多研究已經關注到深度學習算法在腦電信號處理上的應用[16]。Schirrmeister等[17]提出了一種適用于腦電信號分類的深度卷積網絡(DeepConvNet)。Lawhern等[18]提出了可以跨范式、跨被試且效果較好的腦電信號解碼網絡(EEGNet),模型具有很強的泛化能力。Liu等[19]提出時間和通道注意卷積網絡(TCACNet),實現了對腦電信號的分類。上述基于深度學習的算法,通過自適應訓練的深度網絡實現了對原始腦電信號的模式識別,在大量數據的支持下能夠取得很好的識別效果。
但是,深度學習在腦電信號識別領域仍存在以下問題。首先,運動想象作為一種內源性的腦-機接口范式,神經電信號來源于特定區域、特定時間以及個體差異性的節律,特征呈現出較強的時間-空間-頻率耦合特性[12, 20-21],加之頭皮腦電對神經信號質量的折損,如何自適應地提取到這些強耦合的特征是需要研究的重點[22];其次,深度網絡的訓練參數隨網絡深度與廣度的增加而增加,隨之帶來的是更多的訓練數據樣本需求[23],為算法的實際應用造成阻礙;最后,在腦-機接口的實際應用場景中,要想普及更多的設備使用場景,就要追求比較高的信號解碼準確率,還需要更快的神經網絡訓練速度與更低的計算資源占用[24]。
針對上述問題,本文在EEGNet網絡模型的基礎上,提出了一種改進的運動想象腦電信號淺層卷積解碼網絡(Faster-EEGNet)。通過新的神經網絡結構,增強了對運動想象時間-空間-頻率耦合特征的提取能力。該網絡可訓練參數只有104量級,對訓練樣本數要求較低;最后通過結構優化,明顯提升了網絡卷積運算速度,使得實驗中的訓練用時減少了44.8%。
1 基于深度學習的運動想象解碼算法
1.1 EEGNet網絡結構
EEGNet是Lawhern等[18]受到FBCSP算法啟發構建的一個緊湊式的、可以用于運動想象腦電信號識別的可訓練神經網絡,其網絡結構如圖1所示。

圖1 EEGNet網絡結構Fig.1 Structure of EEGNet network
網絡輸入層輸入的腦電信號數據為通道數×采樣數;緊接著為中間層,其第1層是二維卷積層,卷積核尺寸與腦電數據采樣率有關,設L=0.5fs(fs為腦電數據采樣頻率),則卷積核尺寸為L×1。該卷積層的卷積操作是對腦電信號開展逐行卷積運算,其作用為逐通道濾波,再經過激勵函數實現特征圖的輸出,其過程的數學表達式如下
yj=f((X*wj)+bj)
(1)
式中:yj表示第j個特征圖;X表示該層的輸入信號;wj表示第j個卷積核的權重矩陣;bj表示第j個卷積的偏差值;f表示激活函數。
中間層的第2層是深度卷積層,卷積核尺寸為通道數×1。該深度卷積層與第1層的區別在于:在深度為1時,進行卷積操作時1個特征圖輸入對應1個卷積核[25],而普通卷積層的每個卷積核會與每個輸入的特征圖進行卷積操作。深度卷積的計算公式為
(2)
式中:h表示深度卷積的深度;yj,h表示第j個卷積核對應的深度為h的輸出;Xj表示第j個輸入的特征圖;wj,h表示第j個深度為h的卷積核;bj,h表示第j個深度為h的偏差值。
深度卷積的意義為對輸入的每個特征圖進行單獨操作,實現了特征圖的獨立特征提取[25]。同時相比于普通卷積,深度卷積的運算量、可訓練參數量也會大大減少。深度卷積層的卷積計算類似于CSP算法中的空間濾波計算,是對各通道信號的加權濾波,因此該層的輸出變為一維信號。
中間層的最后一層為深度分離卷積[25],此卷積過程是深度卷積與點卷積的組合,因此有兩層的卷積過程。點卷積的卷積核大小為1×1,因此卷積不會改變特征圖的大小,但也能將特征降維以及增加模型的非線性表達能力。
由深度分離卷積層輸出的特征圖,首先經過深度卷積過程進一步提取時域特征,再經歷如下所示的點卷積過程
(3)
式中:yj表示第j個特征圖輸出;Xi表示第i個特征圖輸入;wj表示第j個點卷積核;bj表示卷積偏置。
可以看出,點卷積核會與每一個輸入的特征圖進行卷積,求和之后得到特征圖輸出。因此,深度分離卷積過程增加了網絡對腦電信號時空耦合特征提取的學習能力。
最后在輸出層進行全連接與分類結果輸出,實現腦電信號解碼。
1.2 Faster-EEGNet網絡結構
本文的研究工作主要是基于EEGNet網絡模型開展優化,提出如圖2所示的適用于運動想象腦電信號解碼的Faster-EEGNet緊湊式深度學習網絡。網絡的輸入數據導聯數為C,數據長度為T,F1與D表示網絡的一組可調整超參數,網絡的最終結構可由F1與D確定。
本文提出的網絡模型,重點是對EEGNet網絡中間層的第1層與第2層結構進行改造,在網絡構建過程中選用一維卷積核加快卷積速度,對于單通道信號的不同頻段、不同通道信號以及信號時域信息,有著更強的耦合特征學習能力,能夠實現更快的網絡訓練速度以及具有更強的特征提取能力。
表1詳細列出了Faster-EEGNet網絡的結構與參數。可以看到,輸入層對于采集到的原始腦電信號,需要進行適當的預處理,如通道選擇、去線性趨勢、帶通濾波等,輸入數據為采樣點數×通道數(T×C)。中間層的第1層是大小為32的F1個一

圖2 Faster-EEGNet的網絡結構Fig.2 Structure of Faster-EEGNet

表1 Faster-EEGNet的網絡結構與參數
維卷積濾波器,能夠對多通道的腦電信號進行時域特征提取,計算公式如下
(4)

與EEGNet網絡中間層的第1層相比,Faster-EEGNet網絡的第1層卷積對所有通道采用不同的卷積權重,在濾波之后進行疊加,雖然大大增加了該層的可訓練參數,但也增強了對時空耦合特征的學習能力。在卷積核大小的選擇上,采用了更小的32,以增加時間分辨率。不僅如此,由于采用的卷積在運算過程中是對所有通道同時進行,因此相比于EEGNet網絡,計算速度提升較大,達到了在參數增多的情況下仍能加快計算速度的目的。之后的批次標準化計算起到了正則化的作用,能夠減小數據的分布變化。第2層是大小為16的深度卷積層,深度卷積的特點就是卷積核不與上一層所有的特征圖連接,其作用一方面是減少該層的參數量,另一方面是單獨對上一層輸出的時空特征圖進行時域特征學習。在激活函數的選擇上,沒有依照EEGNet網絡使用指數線性單元(elu), 而是選擇了整流線性單元(Relu)函數,其數學表達式為
(5)
式中:y表示激活函數的輸出;x表示激活函數的輸入。
由于Relu會將輸入為負的激勵輸出為0,因此起到了特征選擇的作用。同時,將部分神經元輸出置零,也加快了網絡計算的速度。
深度卷積之后使用大小為4的平均池化,將250 Hz的信號采樣頻率降到64 Hz,可大大降低特征圖的大小,因而減少了計算量。緊隨的神經元丟棄(dropout)操作使部分神經元失活,起到了防止過擬合的作用,失活率可以根據訓練過程中的過擬合情況選擇0.25或者0.5。中間層的最后一層是深度分離卷積,與EEGNet網絡一樣借鑒了CSP算法的思想,進一步提取時間-空間域上的特征,輸出的特征圖經歷批次標準化、 Relu激活、平均池化、神經元丟棄等一系列操作后,生成該層輸出。尺寸為8的平均池化進一步降低了特征圖大小,減少了后續計算量。最后經過全連接展平,將所有的特征與輸出層連接。
Faster-EEGNet網絡將第1層二維平面串行卷積變為所有通道同時進行的串行卷積,完成了各通道信號的時域濾波、空間濾波,中間深度卷積層對空間模式提取信號進行時域卷積特征提取,最后由深度分離卷積再次提取信號時間-空間耦合特征。整個過程中,雖然可訓練參數量有所增加,但是計算速度與特征學習能力得到了增強。
2 實驗材料與設計
2.1 數據集介紹
本文使用2022年世界機器人錦標賽-BCI腦控機器人大賽公開的運動想象RankB賽題數據作為驗證數據集,采用博瑞康64導腦電采集設備采集實驗數據,含一個事件信息(trigger)通道,信號采樣頻率為250 Hz。一次實驗內容包括2 s任務提示、4 s運動想象和2 s休息,每組共計30次。任務類型包括左手運動、右手運動、雙腳運動的想象,每種任務隨機出現10次。數據集采集了5名被試者的運動想象數據,每名被試者參與3組實驗共計90個試次。為了模擬真實的在線識別場景,本文腦電解碼實驗使用的訓練集與測試集數據均來自不同的實驗組,以減少訓練集與測試集的相似性。
2.2 模型訓練與驗證實驗設計
為驗證本文所提出的Faster-EEGNet網絡性能,在所選公開數據集上設計了與EEGNet網絡運動想象解碼性能的對比實驗。模型訓練的過程如圖3 所示。
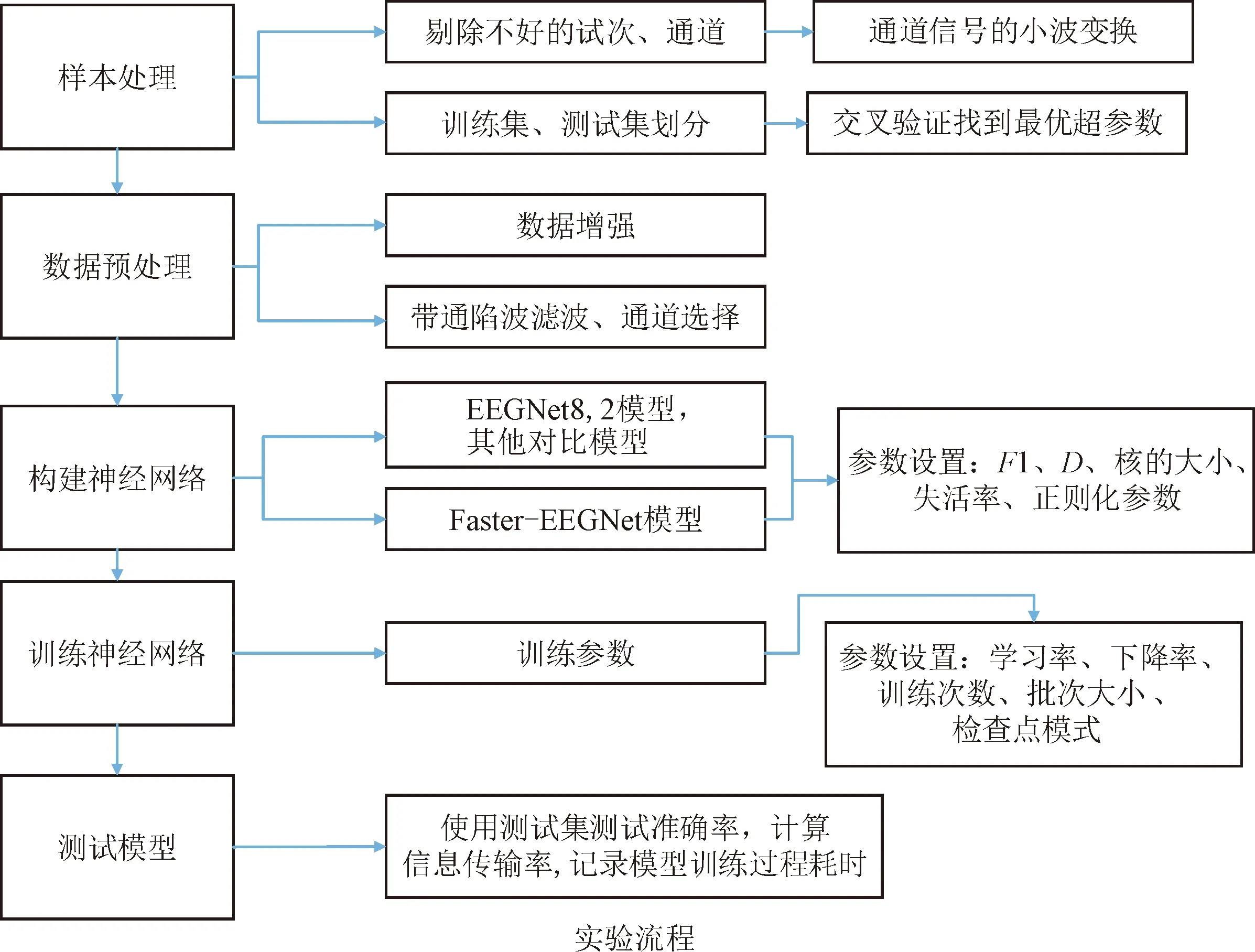
圖3 模型訓練與實驗過程Fig.3 Model training and experiment process
實驗采用python語言平臺,計算機配置為12核intel Core i7-8700,編程環境為Windows10 + python3.10。不使用GPU的原因是由于在前期實驗過程中發現,在數據量與神經網絡都很小的情況下,GPU訓練的速度很大程度上取決于CPU處理與載入數據的速度,所以導致訓練耗時差異很小,因此使用CPU進行訓練可以更好地對比神經網絡訓練速度的差異。
樣本的處理步驟為:實驗中,對每名被試者所有通道每個試次的數據進行小波變換,繪制試次信號的時頻圖,然后根據經驗去掉噪聲比較大的腦電信號通道與試次樣本。本實驗的通道號選擇如表2所示。

表2 不同被試者腦電通道號的選取
被試訓練集與測試集的劃分過程為:為消除訓練數據與測試數據相似度對測試結果的影響,先使用第1個實驗組的數據作為測試集,第2、3組的數據作為訓練集得到測試集準確率,然后再依次使用第2組、第3組數據作為測試集,即采用三折交叉驗證的方法,選取3組測試集準確率的平均值作為模型的分類識別準確率。
數據預處理步驟為:由于數據集中每名被試者的數據樣本只有90個試次,訓練集樣本只有60個試次,因此本文采用移動剪裁的方法進行數據增強,即使用長度為120的窗,移動間隔為30的裁剪方法對4 s的運動想象數據進行裁剪,可以將數據樣本擴大30倍,之后對增強后的樣本再進行去線性趨勢以及8~30 Hz濾波。
按照Lawhern[18]所述的網絡參數構建EEGNet8,2網絡,按照表1的參數對Faster-EEGNet網絡進行設置,其中F1設置為16,D設置為2,F2設置為32,第1個神經元的丟棄概率設置為0.5,第2個神經元的丟棄概率設置為0.25。
模型訓練的批次大小設置為32,EEGNet8,2網絡的學習率設置為0.01,Faster-EEGNet網絡的學習率設置為0.000 1,學習率設置按梯度衰減,以防止訓練前期收斂太慢與訓練后期過擬合。為了發揮2種網絡的最佳性能,學習率與批次大小的設置選取訓練調參過程中的一個較優參數。
2.3 性能評價方法
2.3.1 模型準確率
為驗證本文所提出模型的先進性,使用2.2節中的模型訓練方法,分別訓練EEGNet8,2與Faster-EEGNet網絡。EEGNet8,2網絡的訓練次數設置為200,并使用Lawhern[19]中所述的檢查點模式方法,選擇驗證集上損失函數最小的模型作為輸出模型。本文提出的Faster-EEGNet網絡不使用檢查點模式方法,而是在訓練200次后以最后一次訓練得到的模型作為輸出模型。采用三折交叉驗證方法計算模型的識別準確率,每個被試者均重復20次,記錄下每次實驗的交叉驗證準確率。
2.3.2 信息傳輸率
信息傳輸率是反映數據傳輸系統性能的重要參數,是描述腦-機接口性能的指標之一,其計算公式為
(6)
式中:RIT表示信息傳輸率;N表示目標數;P表示識別準確率;L表示平均試次時長。
實驗中使用的腦電數據長度為0.48 s,但考慮到實際使用場景,加上了模擬的0.5 s休息時長,因此計算過程中L取0.98 s。
2.3.3 模型訓練速度
使用S04被試者的數據,從訓練10個輪次開始,每次增加10個輪次,一直增加到100個輪次。將此實驗過程重復20次,記錄下每次訓練耗時數據。
2.3.4 模型推理速度
模型的推理速度受測試數據的長度以及腦電數據通道數的影響。為評價測試數據的長度對模型推理速度的影響程度,首先使用S04被試者的數據,選擇第1組與第2組共60個試次的59通道腦電數據,按照2.2節中所述方法對樣本進行預處理,測試長度分別為0.5、1.0、1.5、2.0、2.5和3 s,采用Faster-EEGNet網絡與EEGNet8,2網絡進行訓練,次數設置為200。對于EEGNet8,2網絡,采用檢查點模式方法選擇輸出模型,測試集按照2.2節中所述方法增強到360個樣本,每個長度樣本對應的實驗重復3次,記錄2種模型對測試集所有樣本進行推理所消耗的時間。
2.3.5 結果的假設檢驗
將上述性能評價指標實驗結果,視作同一組數據的不同處理或測量結果的均值差異,可采用雙樣本t檢驗(pairedt-test)方法來比較均值大小,其表達式可寫為
(7)
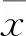
采用式(7)的t檢驗統計量對2組樣本的均值進行檢驗,其自由度的數目由 Satterthwaite 逼近給出。若均值相等則檢驗通過,表明結果無明顯差異,否則需進行單側檢驗比較均值大小。
3 實驗結果與討論
3.1 網絡可訓練參數
表3給出了Faster-EEGNet、EEGNet8,2、DeepConvNet以及ShallowConvNet 4種網絡可訓練參數量的對比結果。

表3 4種運動想象解碼網絡的可訓練參數量對比
由表3可知,DeepConvNet網絡的可訓練參數量最大,達到了105數量級,ShallowConvNet與Faster-EEGNet網絡的數量級都在104,EEGNet8,2網絡的可訓練參數最少。總體而言,Faster-EEGNet網絡的可訓練參數量相對較少,因此在小樣本訓練場景也能獲得較好的模型擬合效果。對于EEGNet8,2網絡,雖然第1層的卷積層為每個通道都分配了單獨的卷積核,導致參數量增加,但同時換來了更強的耦合特征提取學習能力。
3.2 運動想象腦電信號解碼準確率與信息傳輸率
圖4展示了EEGNet8,2與Faster-EEGNet網絡在世界機器人錦標賽上運動想象B榜三分類數據集上的識別準確率結果,所有的數據樣本長度均為0.48 s。由圖可見,在S04與S05被試者的表現上,Faster-EEGNet與EEGNet8,2網絡的識別準確率分別為82.12%與27.57%,前者明顯優于后者(在p<0.001的顯著水平上)。對于S03被試者,則是EEGNet8,2網絡取得了更好的識別準確率。2種算法在S01與S02被試者上無顯著差異,Faster-EEGNet比EEGNet8,2網絡的平均準確率提升了0.46%。識別結果表明,不同被試者間運動想象信號的質量差異較大。
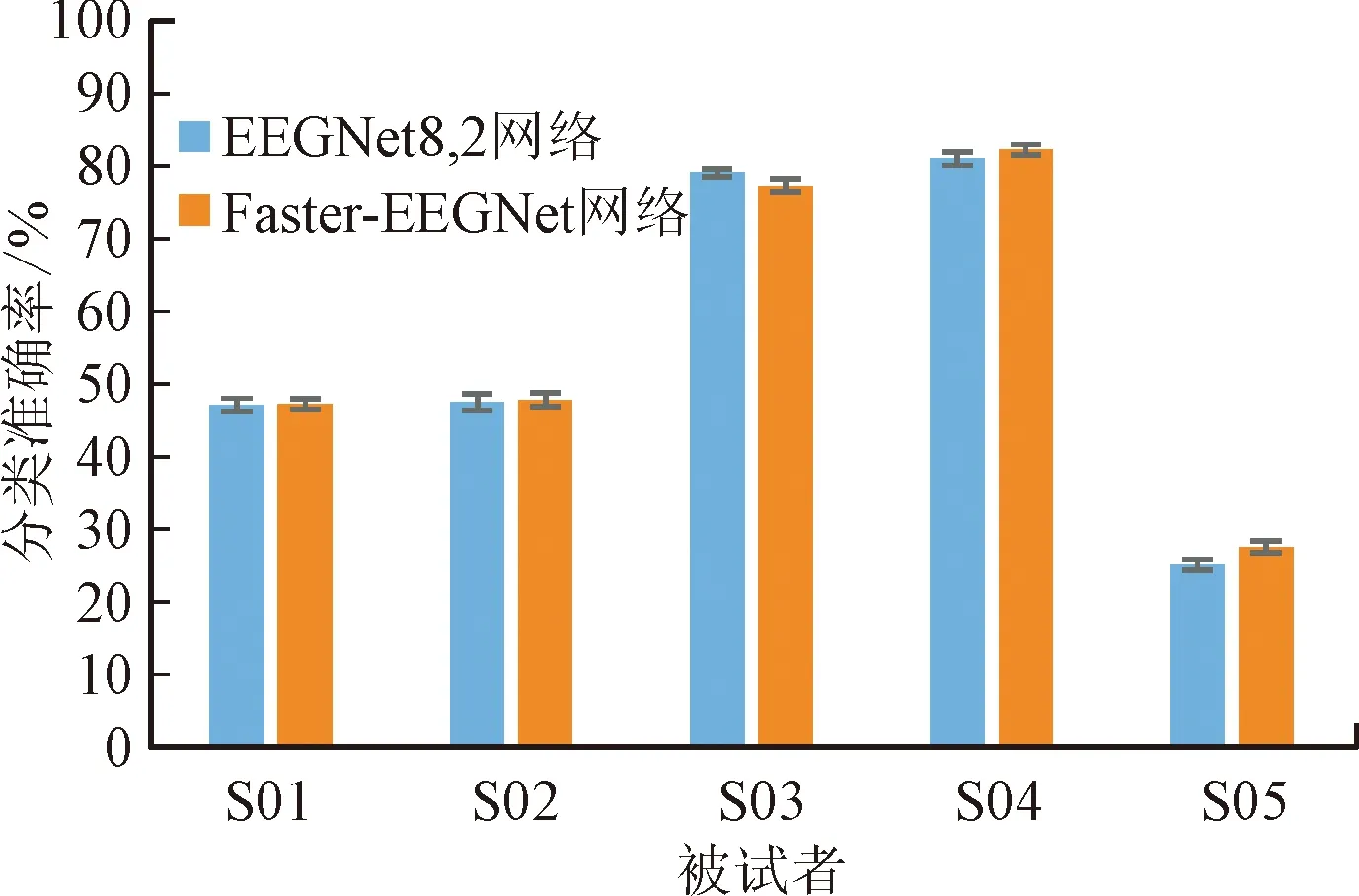
圖4 2種網絡模型的分類準確率對比Fig.4 Comparison of classification accuracy of EEGNet8,2 and Faster-EEGNet models
表4給出了EEGNet8,2與Faster-EEGNet網絡在實驗中運動想象解碼信息傳輸率RIT的結果。由于被試者S05的三分類準確率低于1/3,因此信息傳輸率都為0。Faster-EEGNet網絡在S04被試者上的信息傳輸率結果更優(在p<0.001的顯著水平上),而對于S01與S02被試者,兩種算法并無明顯差異。

表4 2種網絡模型的信息傳輸率
3.3 神經網絡訓練速度對比結果
圖5給出了兩種神經網絡在S04被試者上的訓練耗時。由圖可見,在訓練數為10~100的所有實驗中,本文提出的Faster-EEGNet網絡模型的訓練耗時均明顯低于EEGNet8,2(在p<0.001的顯著水平上),能夠減少44.8%的訓練耗時,訓練速度得到明顯提升。模型訓練速度加快的原因在于:Faster-EEGNet網絡將第1層二維平面串行卷積變為所有通道同時進行的串行卷積,使用較小的卷積核完成了各通道信號的時域濾波、空間濾波;而EEGNet網絡的第1層為所有通道分配一個卷積濾波器,在卷積計算時使用比較大的卷積核逐次串行對所有通道進行卷積,因而第1層只完成了時域濾波過程,輸出特征圖也比較大,提升了后續計算的復雜度。
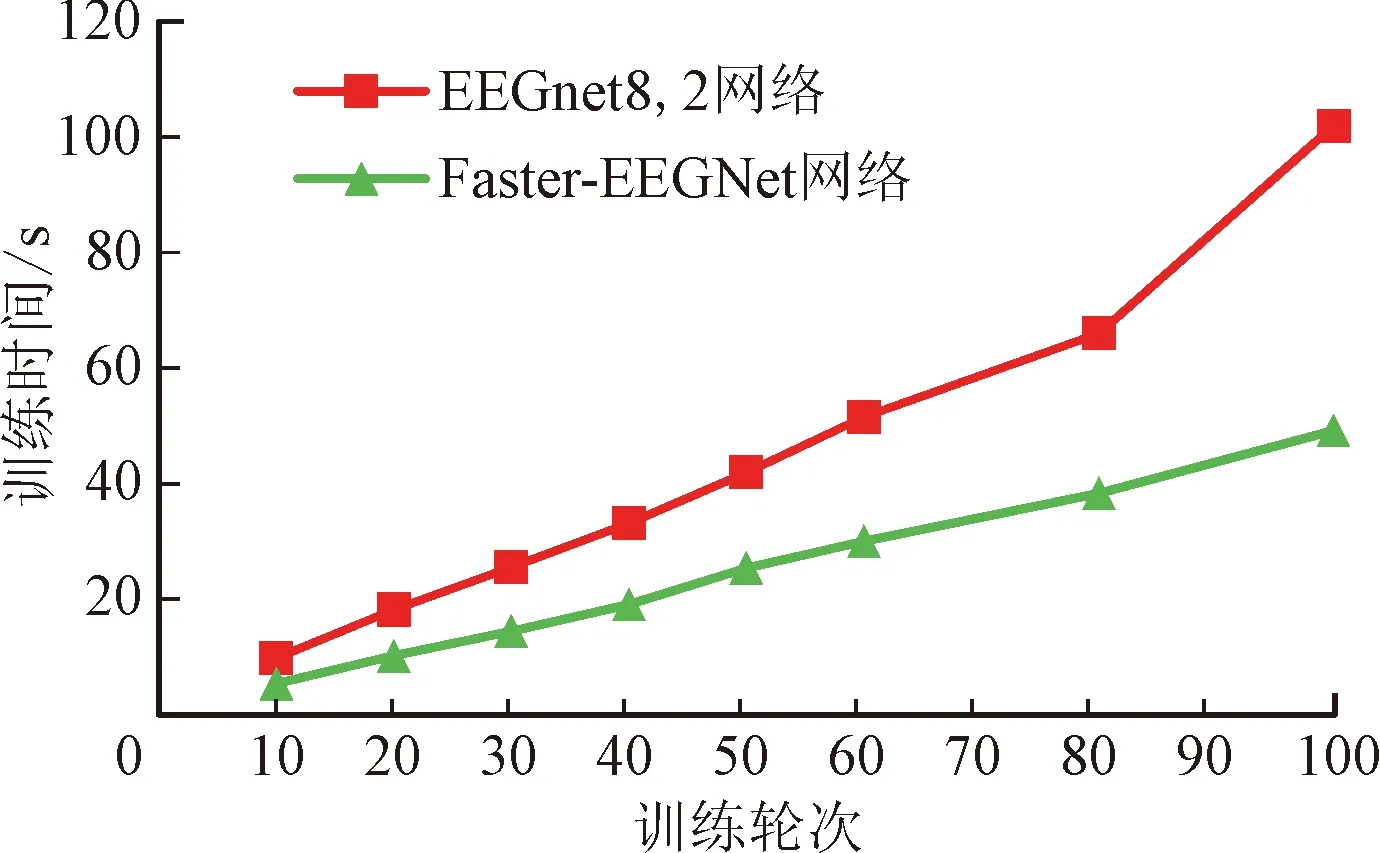
圖5 2種網絡模型的訓練耗時對比(S04被試者)Fig.5 Comparisons of time spent on two net models(S04 training model)
3.4 模型推理速度對比結果
圖6展示了大小為360的測試樣本上,Faster-EEGNet與EEGNet8,2網絡模型的預測推理消耗時間對比結果。由圖可見,兩種算法的推理時間都隨著樣本長度的增加而呈近似線性增加,但Faster-EEGNet網絡模型的推理時間在所有測試樣本長度時均小于EEGNet8,2網絡模型(在p<0.001的顯著性水平上),如樣本長度為0.5 s時推理時間減少了43.6%,樣本長度為3 s時推理時間減少了73.0%;從單樣本推理時間來看,樣本長度為3 s時最長,Faster-EEGNet8,2網絡模型推理需耗時0.73 ms,而EEGNet網絡模型推理耗時則需要2.66 ms,結果表明相較于EEGNet8,2網絡模型,Faster-EEGNet網絡模型的推理速度有了較大的提升。
4 結 論
本文針對現有深度學習方法在運動想象腦電信號識別領域面臨的挑戰展開研究,旨在解決基于運動想象的腦-機接口在實際應用中對于快速模型訓練、想象任務準確識別、小樣本訓練的需求問題,在EEGNet網絡結構的基礎上,提出了緊湊型的Faster-EEGNet網絡,并給出了其結構參數設置以及訓練方法。與其他學者提出的神經網絡相比,Faster-EEGNet網絡參數量較少,對于小樣本的訓練場景也能夠獲得較好的模型擬合效果。所選三分類運動想象數據集上的分類結果表明,Faster-EEGNet神經網絡平均識別準確率與信息傳輸率均高于EEGNet網絡,部分被試者結果顯著高于EEGNet網絡,顯示出較好的解碼性能。在模型訓練速度方面,Faster-EEGNet網絡有著較為顯著的優勢,實驗中所有試次的平均訓練速度提升了44.8%。在基于運動想象的腦機接口系統中,Faster-EEGNet網絡能夠在保證較好解碼性能的前提下顯著減少解碼模型的訓練耗時,提升了運動想象腦機接口系統的便利性。此外,與EEGNet網絡模型相比,Faster-EEGNet網絡模型推理速度的提升量超過43.6%,大大提高了腦機接口系統的快速響應能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·學霸日記(2021年4期)2021-09-05 04:28:51
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小學生作文(低年級適用)(2019年12期)2020-01-18 07:50:36
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中國化妝品(2018年6期)2018-07-09 03:12:42
