基于改進(jìn)SSA算法優(yōu)化極限學(xué)習(xí)機(jī)模型的土壤供肥量預(yù)測*
2023-11-11 04:02:38李井竹劉秋菊王仲英
中國農(nóng)機(jī)化學(xué)報 2023年10期
關(guān)鍵詞:模型
李井竹,劉秋菊,王仲英
(1.河南牧業(yè)經(jīng)濟(jì)學(xué)院信息工程學(xué)院,鄭州市,450032; 2.鄭州工程技術(shù)學(xué)院信息工程學(xué)院,鄭州市,450032; 3.河南經(jīng)貿(mào)職業(yè)學(xué)院工程經(jīng)濟(jì)學(xué)院,鄭州市,450018;4.河南省智慧農(nóng)業(yè)遠(yuǎn)程環(huán)境監(jiān)測控制工程技術(shù)研究中心應(yīng)用技術(shù)研究院,鄭州市,450018)
0 引言
作為農(nóng)業(yè)大國,農(nóng)業(yè)現(xiàn)代化和精準(zhǔn)化一直是我國農(nóng)業(yè)領(lǐng)域的前沿發(fā)展方向。在農(nóng)業(yè)節(jié)水領(lǐng)域,鑒于淡水資源的稀有性,隨著理論研究的不斷深入和技術(shù)的提高,為了滿足現(xiàn)代農(nóng)業(yè)對節(jié)水灌溉的快捷和準(zhǔn)確性需求,農(nóng)業(yè)節(jié)水已經(jīng)逐步走向精準(zhǔn)化、智能化和信息化。土壤供肥量預(yù)測是農(nóng)業(yè)水肥氣一體化領(lǐng)域的關(guān)鍵技術(shù)環(huán)節(jié),高效精準(zhǔn)的土壤供肥量預(yù)測能夠按照農(nóng)作物生長不同階段對養(yǎng)分的需求和氣候條件進(jìn)行精準(zhǔn)補(bǔ)肥,提高農(nóng)肥利用率,確保土壤供氧,實現(xiàn)農(nóng)作物增產(chǎn)提質(zhì),并最大程度降低農(nóng)藥化肥對農(nóng)田生態(tài)環(huán)境的不利影響[1]。
目前,研究人員對農(nóng)作物土壤供肥量預(yù)測模型主要劃分為物理模型和數(shù)據(jù)驅(qū)動模型。數(shù)據(jù)驅(qū)動模型能夠根據(jù)歷史實測數(shù)據(jù)構(gòu)建土壤供肥量的數(shù)學(xué)模型,擁有比物理模型更好的操作性。而影響農(nóng)作物土壤供肥量的因素較多,作物生長機(jī)理復(fù)雜,因此,數(shù)據(jù)驅(qū)動模型通常具備比物理模型更高的預(yù)測精度。隨著機(jī)器學(xué)習(xí)的不斷發(fā)展,各研究領(lǐng)域越來越多地引入智能決策模型,這其中應(yīng)用廣泛的包括人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Network,ANN)[2]、支持向量機(jī)(Support Vector Machine,SVM)、回歸模型(Regression Model,RM)以及極限學(xué)習(xí)機(jī)模型(Extreme Learning Machine,ELM)[3]等。這些數(shù)據(jù)驅(qū)動模型對于復(fù)雜條件的非線性復(fù)雜系統(tǒng)行為能夠更好地預(yù)測,是目前的預(yù)測熱點。人工神經(jīng)網(wǎng)絡(luò)ANN具有易于得到局部最優(yōu)的不足,而支持向量機(jī)模型SVM則易受到訓(xùn)練樣本的影響,極限學(xué)習(xí)機(jī)ELM因為具備預(yù)測精度高、泛化能力強(qiáng)和學(xué)習(xí)速度快的優(yōu)點,已被應(yīng)用于諸多智能決策領(lǐng)域。但標(biāo)準(zhǔn)極限學(xué)習(xí)機(jī)的權(quán)重和偏差具有很大的隨機(jī)性,對訓(xùn)練精度和泛化能力產(chǎn)生了很大的不確定性,為此,很多學(xué)者借助于啟發(fā)式搜索機(jī)制對其進(jìn)行優(yōu)化,試圖降低隨機(jī)取值對模型預(yù)測能力的影響。如:Sheoran等[4]為提高軟件構(gòu)件質(zhì)量預(yù)測的準(zhǔn)確度和靈敏度,提出利用蟻群算法優(yōu)化極限學(xué)習(xí)機(jī),最后證明預(yù)測模型具有較好性能。Liu等[5]結(jié)合HW方法和極限學(xué)習(xí)機(jī)對住宅用電進(jìn)行預(yù)測,證明預(yù)測模型誤差更小。Hazir等[6]結(jié)合極限學(xué)習(xí)機(jī)和支持向量機(jī)對木材涂層粘接度進(jìn)行預(yù)測,在考慮不同工藝因素的情況下,提高了預(yù)測效率和精度。Suchithra等[7]利用極限學(xué)習(xí)機(jī)對農(nóng)業(yè)土壤特征參數(shù)進(jìn)行分類,在泛化能力上提高了評估的準(zhǔn)確度。由于針對極限學(xué)習(xí)機(jī)的主要參數(shù)是隨機(jī)選擇的,以上文獻(xiàn)方法的最終結(jié)果容易出現(xiàn)穩(wěn)定性差、數(shù)據(jù)過擬合的不足。而在農(nóng)業(yè)領(lǐng)域,Bz等[8]結(jié)合混合粒子群優(yōu)化極限學(xué)習(xí)機(jī),對西北干旱區(qū)氣候條件的參考蒸發(fā)蒸騰量進(jìn)行了預(yù)測和評估。Ska等[9]為優(yōu)化能量利用率,提出結(jié)合粒子群和極限學(xué)習(xí)機(jī)的環(huán)境溫度預(yù)測模型。Vidhya等[10]為實現(xiàn)電能質(zhì)量的特征分類,設(shè)計增強(qiáng)型粒子群的極限學(xué)習(xí)機(jī)模型。李明軍等[11]則針對混凝土大壩的變形預(yù)測模型,結(jié)合智能優(yōu)化算法對極限學(xué)習(xí)機(jī)進(jìn)行優(yōu)化,以此應(yīng)對大壩安全隱患。Zkf等[12]則在水電站及水庫規(guī)律領(lǐng)域結(jié)合粒子群和極限學(xué)習(xí)機(jī)對其進(jìn)行預(yù)測,有效提升了預(yù)測準(zhǔn)確度。以上研究成果都不同程度對預(yù)測模型的效率和準(zhǔn)確度進(jìn)行了優(yōu)化,但依然存在針對復(fù)雜高維問題計算效率低、易產(chǎn)生局部收斂以及收斂精度不高等不足。
土壤供肥量預(yù)測模型是目前農(nóng)業(yè)灌溉理論領(lǐng)域的重要突破點,為提高土壤預(yù)測模型的準(zhǔn)確度,本文提出一種融合改進(jìn)麻雀搜索算法優(yōu)化極限學(xué)習(xí)機(jī)的農(nóng)業(yè)土壤供肥量預(yù)測算法。旨在利用混合多策略改進(jìn)的麻雀優(yōu)化算法MHISSA對極限學(xué)習(xí)機(jī)ELM的連接權(quán)重和偏差進(jìn)行尋優(yōu),避免隨機(jī)取值對模型擬合能力的影響,進(jìn)而建立泛化能力更優(yōu)和準(zhǔn)確性更好的極限學(xué)習(xí)機(jī)下的土壤供肥量預(yù)測模型。然后結(jié)合農(nóng)作物生長期中的天氣、土壤以及作物本身的實時信息作為優(yōu)化后的極限學(xué)習(xí)機(jī)的網(wǎng)絡(luò)輸入,為農(nóng)作物土壤肥料用量及灌溉提供更精準(zhǔn)的決策。
1 麻雀搜索算法
麻雀搜索算法(Sparrow Search Algorithm,SSA)是受自然界中麻雀覓食社會行為啟發(fā),在2020年提出的群智能優(yōu)化算法[13]。SSA算法模型簡單、可調(diào)參數(shù)少、尋優(yōu)性能極佳,已被廣泛應(yīng)用在機(jī)器學(xué)習(xí)超參調(diào)優(yōu)[14]、圖像分割[15]、頻譜分配[16]、航跡規(guī)劃[17]等。麻雀覓食過程分工明確,一部分負(fù)責(zé)搜索食物源,稱為發(fā)現(xiàn)者。發(fā)現(xiàn)者負(fù)責(zé)尋找食物,并為整個種群提供搜索方向和覓食區(qū)域;一部分則利用發(fā)現(xiàn)者捕食獵物,稱為追隨者;還有一部分麻雀作為警戒者,當(dāng)發(fā)現(xiàn)危險時,會及時向其他個體發(fā)出警報信號,以便種群立即作出反捕食行為。通常,發(fā)現(xiàn)者和追隨者麻雀比例一般分別占種群規(guī)模的10%~20%,且角色可以相互轉(zhuǎn)換,但比例維持不變。具有較優(yōu)適應(yīng)度的發(fā)現(xiàn)者搜索能力強(qiáng),獲取食物更快。追隨者則根據(jù)發(fā)現(xiàn)者的行為提高自身適應(yīng)度。
SSA算法迭代過程中,發(fā)現(xiàn)者的位置更新方式如式(1)所示。
(1)
式中:t——算法當(dāng)前的迭代次數(shù);
Tmax——最大迭代次數(shù);
xi,j(t)——第i個麻雀個體在第j維的位置信息,j=1,2,…,d;
α——隨機(jī)量,α∈(0,1];
R2——預(yù)警值,R2∈[0,1];
ST——安全值,ST∈[0.5,1];
Q——服從正態(tài)分布的隨機(jī)量;
L——1×d的矩陣,元素均為1。
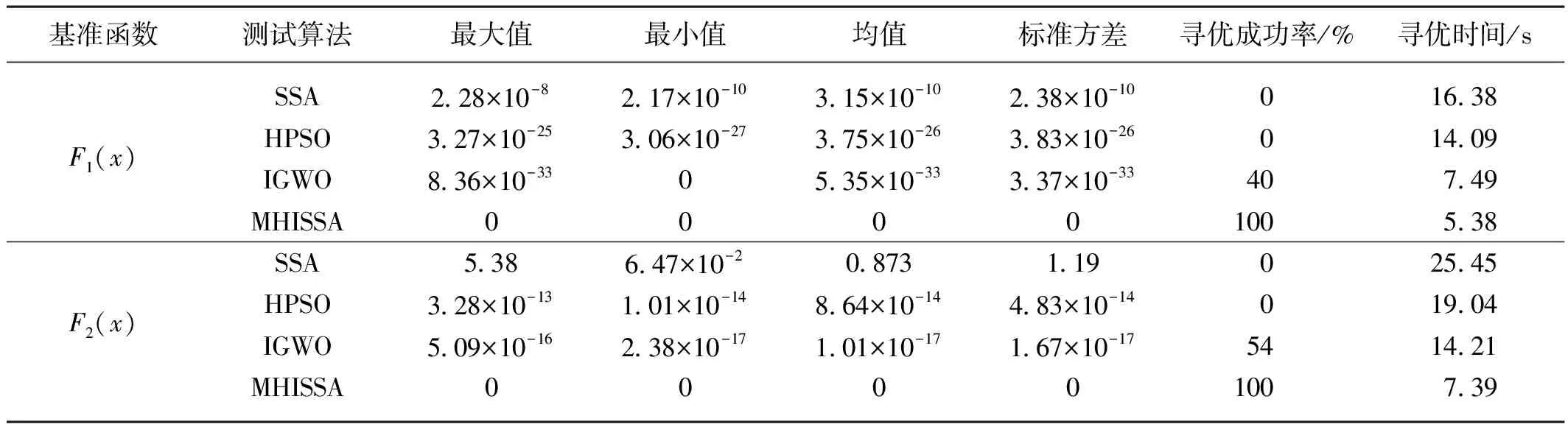
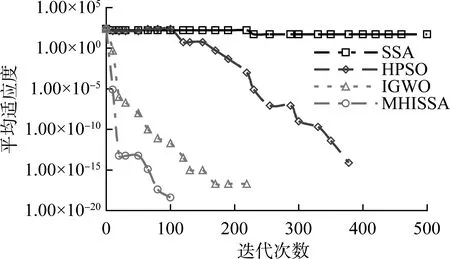
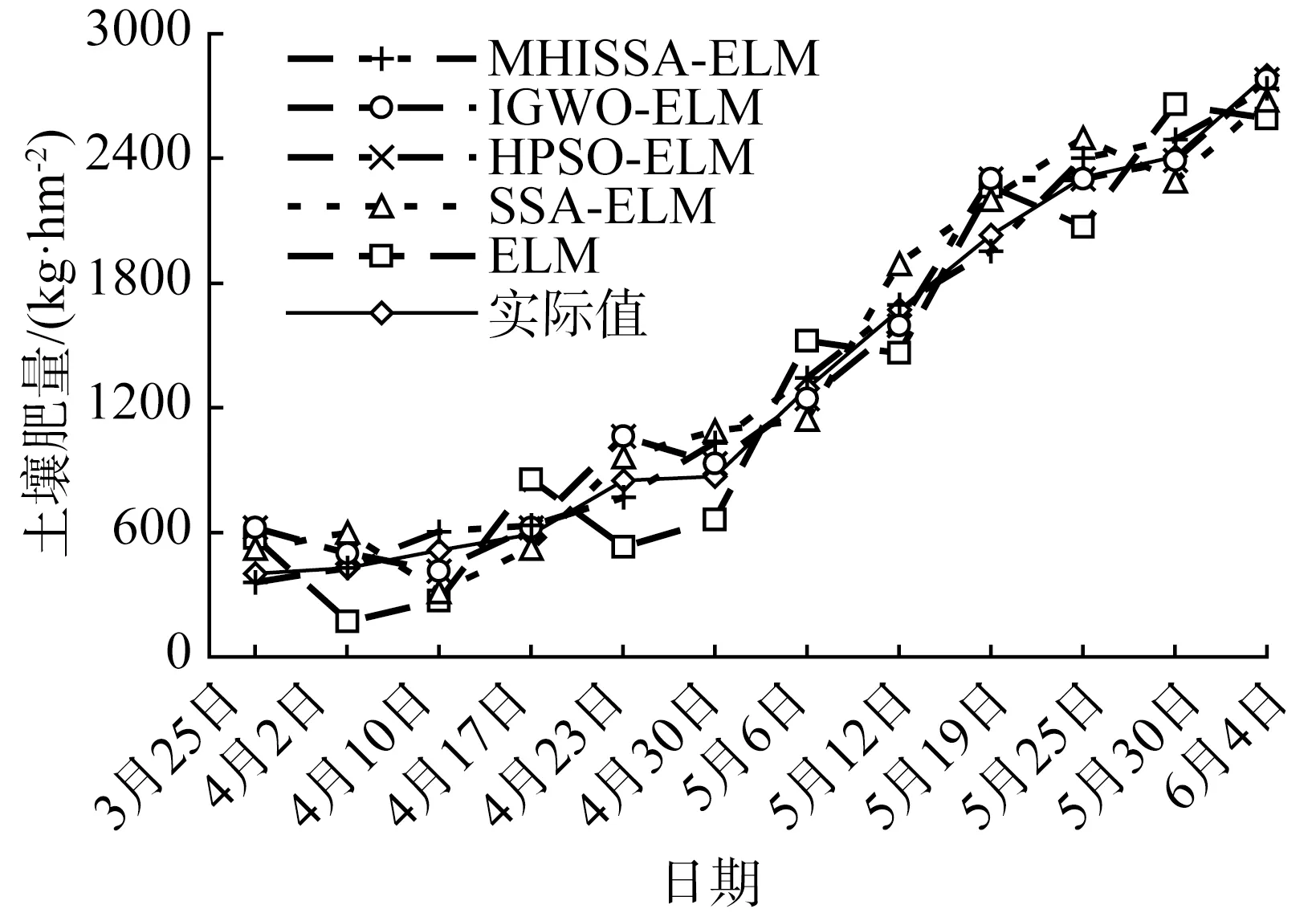
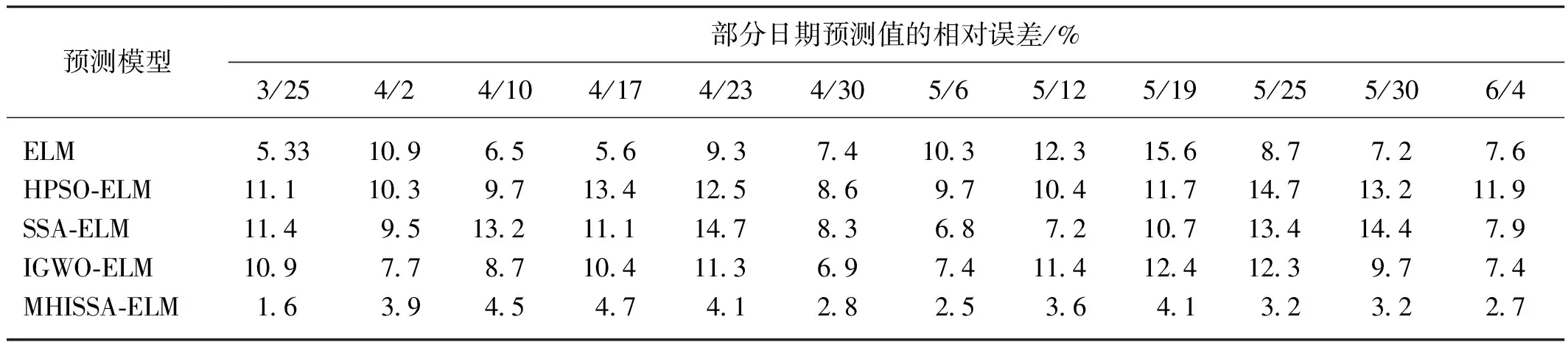
若R2 追隨者的位置更新方式如式(2)所示。 (2) 式中:xP,j(t)——當(dāng)前發(fā)現(xiàn)者占據(jù)的最佳位置; xworst,j(t)——當(dāng)前全局最差位置; A——1×d的矩陣,每個元素隨機(jī)賦值1或-1,且A+=AT(AAT)-1,表示偽逆矩陣。 若i>n/2,表明適應(yīng)度較差的追隨者個體i沒有得到食物,已發(fā)生饑餓,需飛到其他區(qū)域覓食。 警戒者位置更新方式如式(3)所示。 (3) 式中:xbest,j(t)——當(dāng)前全局最優(yōu)位置; β——步長控制因子,為服從均值為0、方差為1的正態(tài)分布隨機(jī)量; K——隨機(jī)量,K∈[-1,1],表示麻雀飛行方向,也是移動步長控制因子; fi——麻雀個體i的適應(yīng)度; fg——當(dāng)前全局最優(yōu)適應(yīng)度; fworst——當(dāng)前全局最差適應(yīng)度; ξ——極小常量,避免分母為0。 若fi>fg,表明此時麻雀正處于群體邊界位置,未受到警戒保護(hù),很容易被捕食者攻擊;若fi=fg,則表明處于種群中間位置的麻雀已意識到危險,需要相互靠攏以降低被捕食風(fēng)險。xbest,j(t)為種群的中心位置,也是安全區(qū)域。 對于SSA算法,麻雀通過信息共享與交互方式搜索食物源。尋優(yōu)過程中,雖然發(fā)現(xiàn)者具有指引功能,但整個種群的跟隨者還是具有較大盲目性,表現(xiàn)為:個體之間交互頻率低,可能聚集在局部最優(yōu)解的方向上,得到局部極值。針對這種盲目飛行現(xiàn)象,改進(jìn)算法將充分利用當(dāng)前麻雀和最優(yōu)麻雀的尋優(yōu)方向,計算兩者的適應(yīng)度,以此確定個體的飛行模式。具體地,若當(dāng)前個體適應(yīng)度小于最優(yōu)解時,種群受當(dāng)前個體引領(lǐng)較多;若當(dāng)前個體適應(yīng)度大于最優(yōu)解時,種群受最優(yōu)解引領(lǐng)較多。該飛行引領(lǐng)方式定義如式(4)和式(5)所示。 (4) (5) 式中:xi(t)——第i個麻雀個體的位置信息; xbest——當(dāng)前最優(yōu)解的信息; f[xi(t)]——個體i對應(yīng)的適應(yīng)度值; f(xbest)——最優(yōu)解對應(yīng)的適應(yīng)度值; b1——引領(lǐng)因子,且b1∈[-2,1],用于約束種群的引領(lǐng)方向; θ——矯正因子,為隨機(jī)量,且θ∈[0,1]。 根據(jù)式(1)可知,若預(yù)警值R2小于安全值ST,則表明發(fā)現(xiàn)者麻雀種群個體可以在安全值區(qū)域內(nèi)進(jìn)行廣泛搜索。但在算法迭代過程中,發(fā)現(xiàn)者的每個搜索維度都在變小,搜索空間逐漸收窄,逐步失去種群多樣性,從而增加了算法陷入局部最優(yōu)的可能。針對這一不足,為了提升發(fā)現(xiàn)者的全局搜索能力,對發(fā)現(xiàn)者位置更新方式進(jìn)行改進(jìn)。MHISSA算法引入一種基于分段權(quán)重的正余弦優(yōu)化方法對發(fā)現(xiàn)者位置進(jìn)行更新,利用正余弦函數(shù)表現(xiàn)出的震蕩尋優(yōu)特性和分段權(quán)重的結(jié)合,確保發(fā)現(xiàn)者麻雀在種群空間內(nèi)進(jìn)行廣泛搜索,維持個體多樣性。 正余弦算法SCA是一種新型啟發(fā)式搜索算法[18],它可以根據(jù)正弦函數(shù)和余弦函數(shù)的數(shù)學(xué)特征和變化實現(xiàn)個體更新和目標(biāo)尋優(yōu),其全局尋優(yōu)能力較強(qiáng),其粒子位置的更新方式如式(6)、式(7)所示。 (6) 式中:r1——振幅調(diào)節(jié)系數(shù); r2、r3、r4——均勻分布隨機(jī)量,r2∈[0,2π]、r3∈[-2,2]、r4∈[0,1]。 (7) 式中:a——常量,一般取值1。 對于SSA算法而言,在搜索前半段,麻雀種群個體需要更強(qiáng)的全局搜索能力,以保持空間的搜索廣泛性。此時,個體應(yīng)該被賦予較大且穩(wěn)定的權(quán)重,確保廣泛的全局尋優(yōu)。改進(jìn)算法將引入一種對數(shù)與指數(shù)結(jié)合的權(quán)重方式以保證權(quán)重值的穩(wěn)定變化,并以自適應(yīng)調(diào)整的方式增強(qiáng)算法跳離局部極值的能力。因此,前半段權(quán)重公式設(shè)計如式(8)、式(9)所示。 w1(t)=2+γ+logat+lnt (8) γ=e(t/Tmax)-10 (9) 式中:w(t)——分段權(quán)重,a=1/2; γ——調(diào)節(jié)因子,且γ∈(0,1]。 在搜索后半段,麻雀種群個體需要更強(qiáng)的局部開發(fā)能力,才能確保種群在局部范圍內(nèi)的集中開采。此時,個體應(yīng)該被賦予較小且穩(wěn)定的權(quán)重,確保種群進(jìn)行深度挖掘。改進(jìn)算法將引入一種指數(shù)型權(quán)重方式,以自適應(yīng)方式調(diào)小權(quán)重值,實現(xiàn)穩(wěn)定地深度挖掘。因此,后半段權(quán)重公式設(shè)計如式(10)所示。 (10) 搜索前半段,w1(t)∈(0,1),搜索后半段,w2(t)∈[-1,1)。 結(jié)合分段權(quán)重的定義,MHISSA算法進(jìn)行發(fā)現(xiàn)者位置更新的方式如式(11)所示。 (11) 在警戒者位置更新公式(3)中,兩個控制因子β和K決定了個體的飛行步長,即均衡算法在全局搜索和局部開發(fā)間的過渡。但由于標(biāo)準(zhǔn)SSA算法中的β和K是隨機(jī)取值,無法滿足算法對解空間的搜索靈活需求,進(jìn)而導(dǎo)致局部最優(yōu)。由于較大的步長因子有利于全局搜索,較小的步長因子有利于局部開發(fā),改進(jìn)算法MHISSA將使用非線性方式對控制因子β和K進(jìn)行更新,公式如式(12)、式(13)所示。 (12) K=Kmax-(Kmax-Kmin)· (13) 式中:βmax——β的最大值; βmin——β的最小值; Kmax——K的最大值; Kmin——K的最小值。 步長因子β、K分別以指數(shù)函數(shù)和正切函數(shù)形式實現(xiàn)非線性轉(zhuǎn)換,使步長因子在迭代早期遞增較快,迭代晚期快速降低,使得早期可以在更廣闊的空間進(jìn)行全局搜索,保持較好的種群多樣性;后期以更快的局部開發(fā),加速算法收斂,從而平衡算法在全局搜索與局部開發(fā)間的過渡,提高算法的尋優(yōu)精度。 對于標(biāo)準(zhǔn)SSA算法而言,麻雀個體的位置更新取決于算法迭代后的位置更新,并通過個體適應(yīng)度的優(yōu)劣變化,以擇優(yōu)方式選擇下一代的個體。但這個過程中并沒有對個體進(jìn)行變異干擾,導(dǎo)致迭代晚期種群多樣性匱乏,容易得到局部極值。改進(jìn)算法將結(jié)合遺傳算法中變異的思想,在MHISSA算法中引入對立學(xué)習(xí)策略對麻雀位置進(jìn)行變異,提升多樣性。 對立學(xué)習(xí)OBL是一種通過評估問題的可行解及其對立解,并擇優(yōu)保留至下一代種群的優(yōu)化方法。令x=(x1,x2,…,xn)為問題的一個可行解(即位置坐標(biāo)),且xi∈[ai,bi],則解x的對立點坐標(biāo)求解方式為xi′=ai+bi-xi,i=1,2,…,n。MHISSA算法將對立學(xué)習(xí)機(jī)制與變異概率結(jié)合起來,具體公式如式(14)所示。 (14) 式中:r——隨機(jī)量,且r∈(0,1); [lbi,ubi]——個體的搜索空間邊界; pr——變異概率; b2——隨機(jī)量,b2∈(0,1); xnew_i——個體i通過對立學(xué)習(xí)變異后的新位置。 式(14)表明,若b2≤pr,表明個體i可以通過隨機(jī)式對立學(xué)習(xí)擴(kuò)大搜索范圍;否則,則通過一般對立學(xué)習(xí)擴(kuò)大搜索范圍。 為確保經(jīng)過對立學(xué)習(xí)后的變異操作算法具備跳離局部最優(yōu)的能力,改進(jìn)算法將通過貪婪擇優(yōu)保存策略保留適應(yīng)度較優(yōu)的個體到下一代種群中。其數(shù)學(xué)模型為 (15) MHISSA算法的執(zhí)行流程如圖1所示。 圖1 MHISSA算法流程圖 MHISSA算法一共采用四種改進(jìn)手段對標(biāo)準(zhǔn)SSA算法進(jìn)行改進(jìn),包括在算法第一階段以飛行引領(lǐng)更新個體位置,降低個體飛行搜索的盲目性;在算法第二階段以分段權(quán)重正余弦優(yōu)化和非線性步長因子分別對發(fā)現(xiàn)者和警戒者個體進(jìn)行位置更新的改進(jìn),提升搜索個體的尋優(yōu)能力;在算法的第三階段以對立學(xué)習(xí)變異對搜索位置進(jìn)行擾動,降低得到局部最優(yōu)解的概率。流程圖中以虛線框?qū)Ω倪M(jìn)策略的實施位置進(jìn)行了特別標(biāo)注。 極限學(xué)習(xí)機(jī)ELM是一種基于單隱層前饋神經(jīng)網(wǎng)絡(luò)構(gòu)建的機(jī)器學(xué)習(xí)算法[19-20]。該算法通過人工設(shè)定或隨機(jī)選擇輸入層權(quán)重和隱含層偏差,根據(jù)Moore-Penrose廣義逆矩陣?yán)碚撚嬎爿敵鰧訖?quán)重。ELM相比支持向量機(jī)SVM、反向傳播BP單層感知器等神經(jīng)網(wǎng)絡(luò)模型,訓(xùn)練參數(shù)少、學(xué)習(xí)速率快,泛化能力也更有優(yōu)勢。令ELM模型有s個輸入層神經(jīng)元節(jié)點,I個隱含層神經(jīng)元節(jié)點和M個輸出層神經(jīng)元節(jié)點。令模型輸入樣本為(xi,yi),1≤i≤Q,樣本數(shù)量為K。xi=(xi1,xi2,…,xis)T∈Rs,表示輸入層第i個輸入樣本,維度為s,yi=(yi1,yi2,…,yiM)T∈RM表示輸出層第i個輸出樣本,維度為M。ELM模型的輸出 (16) 式中:wi∈Rs——輸入層至隱含層神經(jīng)元i的輸入權(quán)重,wi=(wi1,wi2,…,wis)T; g(x)——ELM隱含層的激勵函數(shù); βi——隱含層神經(jīng)元i與輸出層的輸出權(quán)重; bi——隱含層神經(jīng)元i的偏差。 ELM網(wǎng)絡(luò)的訓(xùn)練目標(biāo)是將輸出誤差最小化,即存在wi、βi和bi,如式(17)所示。 (17) 等同于 (18) 式(18)可簡化的矩陣表達(dá)式如式(19)所示。 Hβ=Y (19) 式中:H——隱含層輸出矩陣。 (20) 網(wǎng)絡(luò)訓(xùn)練過程中,若g(x)為無限可微,在隨機(jī)給定輸入權(quán)重和偏差的情況下,隱含層輸出矩陣H不變,則ELM網(wǎng)絡(luò)的訓(xùn)練過程可以利用最小二乘法求解式Hβ=Y來決定輸出權(quán)重β,如式(21)所示。 β′=H+Y (21) 式中:H+——H的Moore-Penrose廣義逆矩陣; β′——輸出權(quán)重矩陣。 由于在傳統(tǒng)ELM模型中,輸入層權(quán)重與隱含層偏差的設(shè)置具有很大的隨機(jī)性,導(dǎo)致ELM的訓(xùn)練精度和泛化能力出現(xiàn)下降,模型具有初值敏感的不足。針對這一問題,本文將采用改進(jìn)麻雀搜索算法MHISSA優(yōu)化ELM的初始權(quán)重和偏差,提升模型的泛化能力。 結(jié)合改進(jìn)麻雀搜索算法MHISSA優(yōu)化極限學(xué)習(xí)機(jī)的主要思想是:將ELM的輸入層權(quán)重和隱含層偏差值映射為MHISSA算法中麻雀的個體位置,根據(jù)定義的適應(yīng)度函數(shù),將MHISSA-ELM模型優(yōu)化問題轉(zhuǎn)化為求解適應(yīng)度最優(yōu)時MHISSA算法得到的最優(yōu)解,即最優(yōu)麻雀個體的位置。利用MHISSA算法對ELM的輸入層權(quán)重和隱含層偏差尋優(yōu),構(gòu)建最優(yōu)ELM預(yù)測模型,并對土壤供肥量進(jìn)行預(yù)測。具體過程如下。 step1:確定影響土壤供肥量變化的相關(guān)因素,并以此確定極限學(xué)習(xí)機(jī)的網(wǎng)絡(luò)輸入量。 step2:初始化MHISSA算法的相關(guān)參數(shù),包括:種群規(guī)模n、最大迭代次數(shù)Tmax、控制因子β和K的最小值和最大值、變異概率pr。構(gòu)建極限學(xué)習(xí)機(jī)模型,設(shè)置激活函數(shù)、隱含層神經(jīng)元數(shù)以及輸入層權(quán)重和隱含層偏差的搜索范圍。 step3:將樣本數(shù)據(jù)劃分為訓(xùn)練樣本和測試樣本,并利用max-min方法對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理。 step4:根據(jù)ELM模型的結(jié)構(gòu)對麻雀個體位置進(jìn)行編碼。以均方誤差函數(shù)MSE定義評估個體位置優(yōu)劣的適應(yīng)度函數(shù)如式(22)所示。 (22) 式中:S——數(shù)據(jù)總量; yi′——ELM模型的土壤供肥量預(yù)測值; yi——土壤供肥量實際值。 step5:初始化麻雀種群xi,i=1,2,…,n,將麻雀個體位置編碼為(w,b)。 step6:根據(jù)式(22)計算種群個體適應(yīng)度,確定適應(yīng)度最優(yōu)個體和最差個體。 step7:通過式(4)的飛行引領(lǐng)策略更新種群個體位置。 step8:確定發(fā)現(xiàn)者個體,利用式(8)、式(10)、式(11)的分段權(quán)重正余弦優(yōu)化機(jī)制更新發(fā)現(xiàn)者位置。 step9:確定追隨者個體,通過式(2)更新追隨者位置。 step10:利用式(12)、式(13)非線性更新警戒者步長因子;再根據(jù)式(3)更新警戒者位置。 step11:通過式(14)、式(15)的對立學(xué)習(xí)變異機(jī)制實施位置擾動。 step12:判斷個體位置是否超過(w,b)的邊界,若越界,則以相應(yīng)位置上下限修正個體位置。 step13:若t step14:以x*=(w*,b*)對ELM模型初始化,并利用訓(xùn)練樣本和測試樣本檢測預(yù)測精度,得到土壤供肥量的預(yù)測值。 基于MHISSA-ELM的農(nóng)作物土壤供肥量預(yù)測模型如圖2所示。 圖2 基于MHISSA-ELM的土壤供肥量預(yù)測模型 根據(jù)MHISSA-ELM模型進(jìn)行土壤供肥量預(yù)測,首先需要確定MHISSA-ELM網(wǎng)絡(luò)的輸入樣本。由于影響農(nóng)作物的土壤供肥量的客觀因素比較多,而很多因素并不能實現(xiàn)在線精確測量,因此,本文將選擇影響權(quán)重最大且易于測量的6個影響因素輸入網(wǎng)絡(luò)進(jìn)行訓(xùn)練,包括:土壤濕度、蒸發(fā)量、土壤肥量、平均氣溫、光照時間和農(nóng)作物生育期[21-22]。同時需要對輸入樣本數(shù)據(jù)進(jìn)行歸一化預(yù)處理,即在算法正式訓(xùn)練之前,利用max-min映射函數(shù)將所有樣本數(shù)據(jù)映射到區(qū)間[-1,1]內(nèi),同時為了提高模型的尋優(yōu)速度,使網(wǎng)絡(luò)訓(xùn)練中避免出現(xiàn)神經(jīng)元的飽和,將具體歸一化方式定義如式(23)所示。 (23) 式中:x′——預(yù)測因子的歸一化標(biāo)準(zhǔn)值; x——預(yù)測因子原始數(shù)值; xavg——原始樣本數(shù)據(jù)預(yù)測因子的均值; xmin——原始樣本數(shù)據(jù)中預(yù)測因子序列中不同時間的最小值; xmax——相應(yīng)預(yù)測因子的最大值。 該部分利用兩個經(jīng)典基準(zhǔn)函數(shù)測試MHISSA算法求解函數(shù)值的有效性。基準(zhǔn)函數(shù)種類較多,相同試驗也可以擴(kuò)展到其他基準(zhǔn)函數(shù)上進(jìn)行測試。算法參數(shù)設(shè)置為:種群規(guī)模n=30、最大迭代次數(shù)Tmax=500。試驗環(huán)境為Intel(R) Core i5 CPU 2.4G,內(nèi)存8 GB,64位微軟操作系統(tǒng)WIN7,實驗平臺為Matlab。實驗過程為:設(shè)置算法的初始參數(shù),并隨機(jī)生成初始種群分布,根據(jù)定義的基準(zhǔn)函數(shù)計算所有個體的適應(yīng)度值,確定其中的最優(yōu)解和最差解。利用式(4)的飛行引領(lǐng)方式更新個體位置,利用式(11)計算發(fā)現(xiàn)者個體的位置更新,利用式(2)計算追隨者個體的位置更新。利用式(12)和式(13)更新步長因子,并利用式(3)計算警戒者個體的位置更新。最后利用式(14)和式(15)對個體位置進(jìn)行變異。算法迭代運行500次之后,輸出種群中的最優(yōu)解。 基準(zhǔn)函數(shù)F1(x)表達(dá)式如式(24)所示。 (24) 該函數(shù)名稱為Schwefel1.2,為單峰函數(shù),維度為30,搜索范圍為[-100,100],理論極值點fmin=0。 基準(zhǔn)函數(shù)F2(x)表達(dá)式如式(25)所示。 (25) 該函數(shù)名稱為Ackley,為多峰函數(shù),維度為30,搜索范圍為[-32,32],理論極值點fmin=0。該函數(shù)各變量間無明顯關(guān)聯(lián),拐點較多,是一種具有明顯局部波峰特征的多模態(tài)函數(shù)。 單峰函數(shù)F1(x)可以測試算法的尋優(yōu)精度和收斂能力,而多峰值函數(shù)F2(x)更加側(cè)重于測試算法是否具備跳離局部最優(yōu)點的能力。由于對于連續(xù)多峰值函數(shù),隨著函數(shù)維度遞增,其局部極值點會呈現(xiàn)指數(shù)級增長。選擇文獻(xiàn)綜述部分提及的增強(qiáng)型粒子群優(yōu)化算法HPSO[10]、改進(jìn)灰狼優(yōu)化算法IGWO[11]以及標(biāo)準(zhǔn)麻雀搜索算法SSA[13]進(jìn)行性能對比。 四種算法在目標(biāo)函數(shù)最大值、最小值、均值、標(biāo)準(zhǔn)方差值、尋優(yōu)成功率以及尋優(yōu)時間上的試驗結(jié)果如表1所示,算法在不同基準(zhǔn)函數(shù)上的尋優(yōu)收斂曲線如圖3和圖4所示。觀察試驗結(jié)果可知,在兩個基準(zhǔn)函數(shù)F1(x)和F2(x)上,本文的MHISSA算法都求解到了最優(yōu)解,其求解精度是最高的。而最小的標(biāo)準(zhǔn)方差值也說明算法尋優(yōu)具有更好的穩(wěn)定性,可以穩(wěn)定地求解到最優(yōu)解。對比標(biāo)準(zhǔn)SSA算法,MHISSA算法在原基礎(chǔ)上提高了二十個數(shù)量級以上的尋優(yōu)精度,證明改進(jìn)策略的有效性。而對比另外兩種智能算法的改進(jìn)策略也均有不同程度的性能提升。在算法收斂曲線方面,MHISSA算法明顯下墜趨勢更加明顯,能夠更快地接近最優(yōu)解。SSA算法曲線平緩,說明尋優(yōu)精度較差,尋優(yōu)能力有待改進(jìn)。HPSO和IGWO算法也在經(jīng)過若干次迭代之后無法進(jìn)一步提高尋優(yōu)精度,陷入了局部最優(yōu)解。將尋優(yōu)成功率SR定義ξ=10-10,若尋優(yōu)結(jié)果小于ξ值,則視為算法尋優(yōu)成功;否則,算法尋優(yōu)失敗。可以看到,MHISSA算法在兩個不同類型的基準(zhǔn)函數(shù)上都可以得到100%的尋優(yōu)成功率,表明在20次獨立試驗過程中均可以求解到預(yù)定義的精度。SSA算法和HPSO算法的尋優(yōu)成功率為0,表明算法尋優(yōu)能力還有待提升。從尋優(yōu)時間上看,MHISSA算法可以以更少的時間求得最優(yōu)解,表明算法不僅尋優(yōu)精度更高,而且尋優(yōu)效率也可以得到保證。 表1 算法的尋優(yōu)結(jié)果 圖3 基準(zhǔn)函數(shù)F1(x) 圖4 基準(zhǔn)函數(shù)F2(x) Wilcoxon秩和檢驗是一種非參數(shù)統(tǒng)計檢驗方法,可以用于判斷改進(jìn)算法MHISSA與對比算法之間是否具有顯著性差別。MHISSA算法的Wilcoxon秩和檢驗結(jié)果如表2所示。p值為Wilcoxon秩和檢驗值結(jié)果,S表示是否具備顯著性判定結(jié)果。若滿足條件p<0.05而S為“+”,則表明MHISSA算法優(yōu)于對比算法具有強(qiáng)顯著性結(jié)果;若滿足條件p>0.05而S為“-”,則表明MHISSA算法優(yōu)于對比算法具有弱顯著性結(jié)果;若p=NaN,則表明MHISSA算法與對比算法之間的顯著性結(jié)果無法判斷。將四種算法獨立運行20次取其均值做Wilcoxon秩和檢驗。根據(jù)表2的結(jié)果可知,MHISSA算法在兩個基準(zhǔn)函數(shù)測試上都具有顯著性結(jié)果,無論是單峰函數(shù)還是多峰函數(shù),MHISSA算法的Wilcoxon秩和檢驗p值均小于0.05,且S為“+”,表明MHISSA算法對比SSA、HPSO和IGWO算法在尋優(yōu)性能上具有顯著性優(yōu)勢。 表2 Wilcoxon秩和檢驗 令麻雀種群規(guī)模為n,算法的最大迭代次數(shù)為Tmax,個體空間搜索維度為d。根據(jù)MHISSA算法的實施步驟,種群初始化階段的時間復(fù)雜度為O(n×d),飛行引領(lǐng)階段對個體位置進(jìn)行更新的時間復(fù)雜度為O(n×d),發(fā)現(xiàn)者、追隨者和警戒者的位置僅在更新方式上進(jìn)行了改變,并未增加更新流程,所以該階段的時間復(fù)雜度為O(n×d),對立學(xué)習(xí)變異階段由于是按概率對個體位置進(jìn)行變異,所以其最差時間復(fù)雜度也僅為O(n×d)。此外,MHISSA算法需要迭代Tmax次才能結(jié)束,所以除了種群初始化階段之外,其他過程均需要進(jìn)行Tmax次。所以,MHISSA算法的最差整體時間復(fù)雜度為O(n×d×Tmax),這個與標(biāo)準(zhǔn)SSA算法的時間復(fù)雜度是一致的,表明改進(jìn)算法在試圖優(yōu)化算法尋優(yōu)性能的同時并未額外增加計算代價。 以一種春季瓜類蔬菜“甬甜5號”在2020年3—8月的觀測數(shù)據(jù)作為訓(xùn)練樣本數(shù)據(jù),2021年3—8月的觀測數(shù)據(jù)作為測試樣本數(shù)據(jù)。對于這種瓜類蔬菜的主要施肥及生長期是:移苗施基肥于3月19日,移栽定植于3月20日,伸蔓期追肥于4月19日,膨瓜初期追肥于5月10日,成熟期為6月5日。該品種甜瓜在其整個生育期的磷氮鉀(分別對應(yīng)過磷酸鈣、尿素和硫酸鉀)三種肥料的用量比例為2∶4∶4。施基肥后,磷肥用量為70%,氮肥用量為40%,鉀肥用量為40%。剩余肥料用量則通過滴灌系統(tǒng)自動播撒,同時保持作物土壤持水七層為灌水底限。 預(yù)測實驗的過程為:設(shè)置MHISSA算法初始參數(shù),構(gòu)建極限學(xué)習(xí)機(jī)模型,輸入模型網(wǎng)絡(luò)輸入量。劃分訓(xùn)練樣本和測試樣本,并對樣本作標(biāo)準(zhǔn)化處理。設(shè)置極限學(xué)習(xí)機(jī)模型訓(xùn)練的適應(yīng)度函數(shù),并計算種群個體適應(yīng)度,確定種群最優(yōu)解和最差解。按MHISSA算法迭代搜索最優(yōu)解,輸出極限學(xué)習(xí)機(jī)最優(yōu)權(quán)重值和偏差值,并構(gòu)建最優(yōu)預(yù)測模型。最后輸入測試樣本至最優(yōu)預(yù)測模型,對土壤供肥量進(jìn)行預(yù)測。選取四種預(yù)測模型與本文的MHISSA-ELM模型進(jìn)行對比,包括:混合增強(qiáng)粒子群優(yōu)化ELM的預(yù)測模型HPSO-ELM、標(biāo)準(zhǔn)麻雀搜索算法優(yōu)化ELM的預(yù)測模型SSA-ELM、改進(jìn)灰狼算法優(yōu)化ELM的預(yù)測模型IGWO-ELM以及未進(jìn)行連接權(quán)重與偏差參數(shù)優(yōu)化的標(biāo)準(zhǔn)ELM預(yù)測模型。為了提高預(yù)測模型的可靠性,四種模型均針對作物從苗期施基肥到成熟期采摘一共80天內(nèi)的土壤供肥量進(jìn)行預(yù)測。 為了評估模型的預(yù)測質(zhì)量,選擇平均絕對誤差MAE、平均相對誤差RMSE以及擬合度因子R2三個指標(biāo)對預(yù)測結(jié)構(gòu)進(jìn)行全面評估。MAE可以反映預(yù)測值誤差的實際情況,其值越小,精度越高;RMSE可以反映預(yù)測可信度,其值越小,精度更高;R2值越接近1,表明預(yù)測值與實際值具有更高的擬合度。指標(biāo)相關(guān)定義如式(26)~式(28)所示。 (26) (27) (28) 式中:n——選擇的樣本數(shù)量; yi——樣本實際值; yi′——土壤供肥量預(yù)測值; yavg——實際值均值; yi,avg′——預(yù)測值均值。 MAE、RMSE和R2三個評價指標(biāo)對比如表3所示。在MAE和RMSE兩個指標(biāo)上,本文的MHISSA-ELM模型不同程度地小于另外四種對比模型。在R2指標(biāo)上,ELM模型擬合度是最小的,即R2值最小,其他四種基于智能群體算法對ELM改進(jìn)后的預(yù)測模型都不同程度地提高了R2值,說明對極限學(xué)習(xí)機(jī)的連接權(quán)重和偏差的優(yōu)化是能夠提升ELM模型預(yù)測精度的。同時,本文的MHISSA-ELM模型的R2與1最為接近,預(yù)測精度最高,這些結(jié)論均有效證明本文所采用的改進(jìn)策略的有效性,能夠通過改進(jìn)麻雀搜索算法對極限學(xué)習(xí)機(jī)ELM在預(yù)測精度和模型泛化能力方面實現(xiàn)有效改進(jìn)。 利用2020年3—8月的觀測數(shù)據(jù)作為預(yù)測模型的訓(xùn)練樣本集,下一年2021年3—8月的同時段觀測數(shù)據(jù)作為模型的測試樣本集。此外,將土壤濕度、蒸發(fā)量、土壤肥量、平均氣溫、光照時間和作物生育期六個因素考慮為影響土壤供肥量預(yù)測模型的網(wǎng)絡(luò)輸入量,通過預(yù)測模型計算該甜瓜在生育期的土壤供肥量預(yù)測值,五種模型的預(yù)測值與實際土壤供肥量值的對比圖如圖5所示。從預(yù)測值與實際值對比結(jié)果來看,五種預(yù)測模型得到的預(yù)測值與實際值間的變化趨勢是基本一致的,可見結(jié)合極限學(xué)習(xí)機(jī)ELM模型的預(yù)測機(jī)制在農(nóng)業(yè)土壤供肥量上具有一定的預(yù)測能力。但從預(yù)測值與實際值曲線是的擬合程度來說,不同模型的差別還是比較明顯。ELM模型、SSA-ELM模型、HPSO-ELM模型和IGWO-ELM模型的預(yù)測值與實際值都存在不同程度的偏差,ELM模型的偏差最多,說明標(biāo)準(zhǔn)極限學(xué)習(xí)機(jī)模型在預(yù)測穩(wěn)定性和泛化能力上還有較大提升空間。SSA-ELM模型優(yōu)于ELM模型,但依然不穩(wěn)定,說明標(biāo)準(zhǔn)麻雀搜索算法在尋優(yōu)精精度上還存在不足。HPSO-ELM和IGWO-ELM模型在部分日期上的土壤供肥量預(yù)測值與實際值較為貼近,穩(wěn)定性和擬合程度要優(yōu)于SSA-ELM和ELM模型。而本文的MHISSA-ELM模型則得到了所有模型中最好的穩(wěn)定性和最高的數(shù)據(jù)擬合程度,部分日期甚至準(zhǔn)確率達(dá)到100%,說明改進(jìn)后的麻雀搜索算法通過提升的尋優(yōu)精度和收斂速度能夠增強(qiáng)極限學(xué)習(xí)機(jī)的預(yù)測精度和泛化能力。 圖5 五種模型的預(yù)測值與實際值對比 引入平均絕對百分比誤差MAPE進(jìn)一步分析預(yù)測模型的預(yù)測精度和穩(wěn)定性,定義如式(29)所示。 (29) 式中:|yi-yi′|——預(yù)測誤差。 引入MAPE后的預(yù)測誤差如圖6所示。 圖6 引入MAPE后的預(yù)測誤差 從表4及圖6可知,ELM模型的預(yù)測誤差在[-100,100]kg/hm2之間,最大相對誤差為15.9%,MAPE達(dá)7.3%,說明標(biāo)準(zhǔn)極限學(xué)習(xí)機(jī)在常量化的連接權(quán)重和偏差下預(yù)測模型的泛化能力較弱。另外四種基于智能群體優(yōu)化算法下改進(jìn)的ELM模型的預(yù)測精度都有不同程度提升。SSA-ELM模型的預(yù)測誤差在[-90,95]kg/hm2之間,最大相對誤差為14.3%,MAPE為6.9%,比ELM預(yù)測能力更強(qiáng),弱于HPSO-ELM和IGWO-ELM模型。本文的MHISSA-ELM模型的預(yù)測誤差基本可以控制在[-10,15]kg/hm2之間,最大相對誤差為4.8%,MAPE為1.7%,說明算法出現(xiàn)的誤差波動范圍最小,對于土壤供肥量的預(yù)測精度得到了大幅提高。 表4 引入MAPE后的相對誤差值 綜合以上模型得到的預(yù)測值與樣本提供的土壤供肥量實際值之間的擬合程度,并對比模型的相關(guān)預(yù)測誤差結(jié)果可知,本文的MHISSA-ELM模型具有更強(qiáng)的學(xué)習(xí)能力,模型不僅擁有更高的收斂速度,而且在預(yù)測精度和性能穩(wěn)定性方面均優(yōu)于四種對比模型,在農(nóng)業(yè)智能灌溉領(lǐng)域具有一定應(yīng)用可行性。 1) 農(nóng)業(yè)灌溉系統(tǒng)的土壤供肥量受多個因素的綜合影響,為提高農(nóng)作物土壤供肥量的預(yù)測精度,提出一種基于改進(jìn)麻雀搜索算法優(yōu)化極限學(xué)習(xí)機(jī)的農(nóng)業(yè)土壤供肥量預(yù)測模型MHISSA-ELM。首先,分別利用飛行引領(lǐng)、分段權(quán)重正余弦優(yōu)化、警戒者步長因子非線性更新和變異對立學(xué)習(xí)機(jī)制對傳統(tǒng)SSA算法的全局搜索能力進(jìn)行改進(jìn);然后,利用改進(jìn)麻雀搜索算法對極限學(xué)習(xí)機(jī)的網(wǎng)絡(luò)連接權(quán)重和隱含層偏差迭代尋優(yōu),建立預(yù)測精度更高和泛化能力更優(yōu)的改進(jìn)預(yù)測模型MHISSA-ELM。利用MHISSA-ELM模型研究農(nóng)業(yè)土壤供肥量預(yù)測問題。 2) MHISSA-ELM模型的預(yù)測誤差基本可以控制在[-10,15]kg/hm2之間,最大相對誤差為4.8%,MAPE為1.7%。MHISSA-ELM模型得到了所有模型中最好的穩(wěn)定性和最高的數(shù)據(jù)擬合程度,部分日期甚至準(zhǔn)確率達(dá)到100%,說明通過提升尋優(yōu)精度和收斂速度,改進(jìn)后的麻雀搜索算法能夠增強(qiáng)極限學(xué)習(xí)機(jī)的預(yù)測精度和泛化能力。該模型能夠結(jié)合作物生育期的影響因素對土壤供肥量作出精準(zhǔn)預(yù)測,在農(nóng)業(yè)智能灌溉領(lǐng)域具有應(yīng)用前景。2 一種多策略混合改進(jìn)麻雀搜索算法MHISSA
2.1 飛行引領(lǐng)策略
2.2 分段權(quán)重正余弦優(yōu)化發(fā)現(xiàn)者更新機(jī)制
2.3 警戒者步長因子非線性更新
2.4 變異對立學(xué)習(xí)
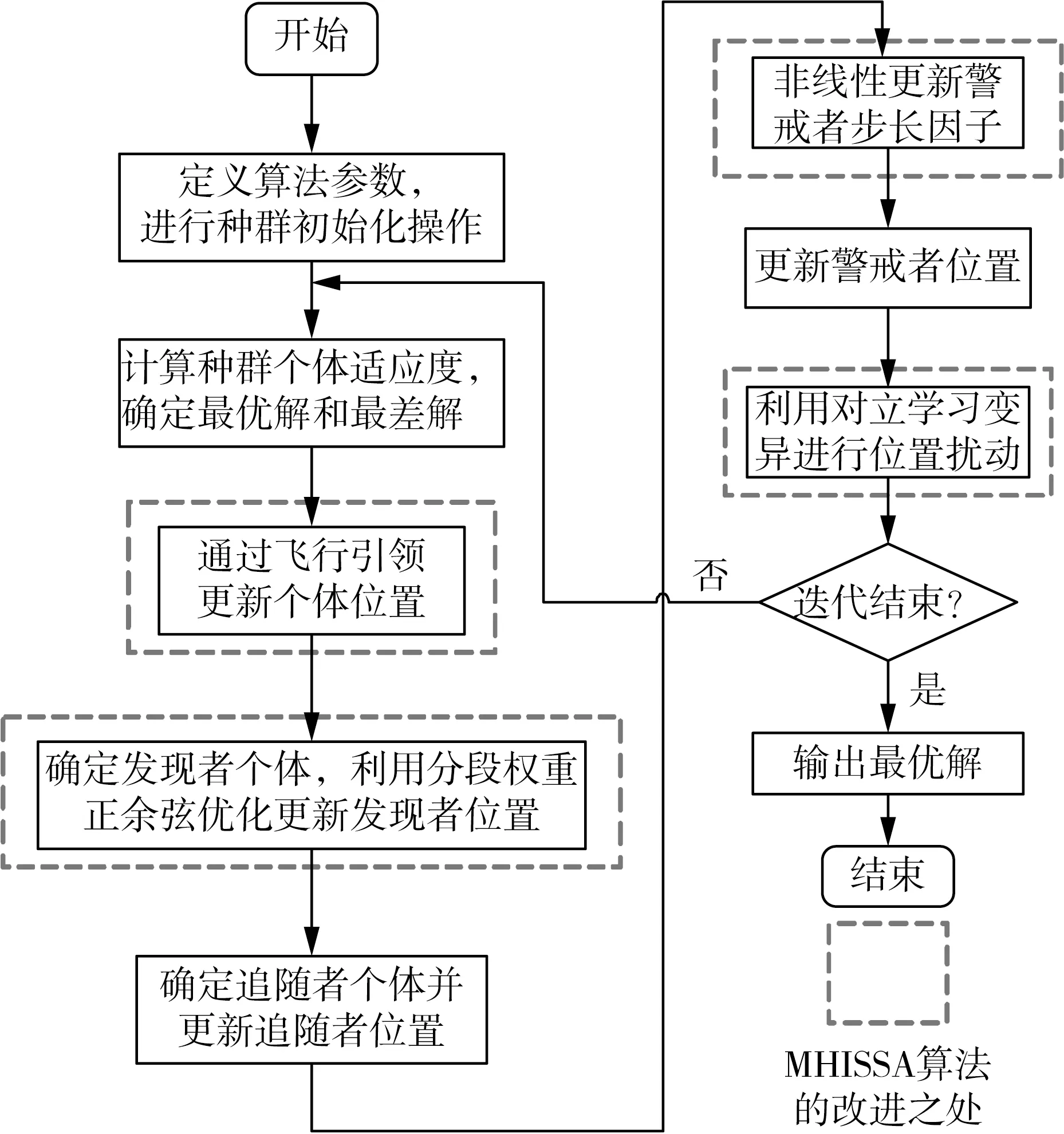
3 基于MHISSA算法優(yōu)化極限學(xué)習(xí)機(jī)ELM模型
3.1 極限學(xué)習(xí)機(jī)模型
3.2 MHISSA-ELM模型設(shè)計
3.3 基于MHISSA-ELM模型的土壤供肥量預(yù)測

4 試驗分析
4.1 MHISSA算法的基準(zhǔn)函數(shù)測試及分析


4.2 農(nóng)作物土壤供肥量預(yù)測試驗

5 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
