面向資源約束項目調度的二階段帝國競爭算法
2023-11-16 00:50:52黃起彬
計算機與生活 2023年11期
李 斌,黃起彬
1.福建理工大學 機械與汽車工程學院,福州 350118
2.福建理工大學 福建省大數據挖掘與應用技術重點實驗室,福州 350118
3.福建理工大學 交通運輸學院,福州 350118
資源約束項目調度問題(resource-constrained project scheduling problem,RCPSP)[1]研究的是如何在有限資源和優先級關系的約束下尋求最佳的活動調度計劃,以期實現項目工期的最小化。該類問題是調度領域中最為經典且最具挑戰性的組合優化問題之一,許多工程應用問題本質上都可歸結為資源約束項目調度問題,如建筑業、流水工作車間和裝配生產調度等,長久以來一直是學術界和工程應用研究的重要課題[2-3]。
精確算法、啟發式算法和元啟發式算法是當前研究和應用中最主要的三類優化方法[4]。精確算法,如分支定界法[5]、關鍵路徑法[6]和整數線性規劃[7]等,可精確地求得實例問題的最優解,但由于其較高的計算成本,僅在小規模實例上具有競爭力[8]。啟發式算法主要分為基于優先級規則的啟發式[9]和基于鄰域搜索策略的啟發式[10]兩類,其最大的優勢是能夠以較少的計算成本獲取較高質量的解決方案,但單種啟發式算法適用的問題類型較為有限[11]。元啟發式算法,如群聚智能算法[12]和進化算法[13]等,有著更為出色的優化精度和廣泛的適用性,以及強大的可拓展性,近年來更多地受到國內外專家學者們的關注[8]。本文提出的二階段演化帝國競爭算法(two-stage evolutionary imperialist competitive algorithm,TSE-ICA)正是一種能夠利用小規模種群有效求解經典RCPSP的元啟發式算法。
TSE-ICA將整個演化過程分為兩個階段,分別以種群多樣性的開發和高效的收斂為前后兩階段的搜索重點。該算法以探索階段開始,采用基于關鍵路徑法的組塊提取策略構建組塊間同化算子,對精簡后的搜索空間進行廣泛勘探;隨后的深度挖掘階段,采用一種結合相同元素保留策略的組塊間同化算子,將優化問題劃分為多個以組塊內最優為目標的子問題,實現收斂過程穩步且高效的推進。組塊提取策略同樣被用于革命機制,兩種基于子問題的鄰域搜索策略被用于增強種群的搜索效率和幫助算法跳出局部最優。同時,帝國競爭機制通過交互各帝國之間的收斂信息,自適應地為各帝國調整同化參數。最后,記憶庫[3]作為一種有效的收斂輔助工具被用于提高種群的進化速率。
為了系統性地驗證TSE-ICA對經典RCPSP的求解能力,本文選擇PSPLIB(project scheduling library)[14]中的實例集J30、J60和J120進行數值實驗。首先,采用Taguchi法[15]確定TSE-ICA面對不同實例集時的最佳參數設置。接著,基于PSPLIB提供的當前已知最優解得到的實驗結果,與3 種基于帝國競爭算法(imperialist competitive algorithm,ICA)的同源改進算法和其他3種先進的元啟發式算法對比,來驗證改進機制的有效性和運行效率。最后,基于關鍵路徑值求得的實驗數值,與11 種著名的優化算法進行對比,初步說明了TSE-ICA的適用性和優化能力。
1 問題描述
RCPSP中,單個項目是由一個活動集合J、一個代表活動執行優先級的緊前關系集合Pr和一個資源集合K構成。活動集合J中包含n+2 個活動,任一活動j(j=1,2,…,n+2)都有一個緊前活動集合Prj、工期dj和開始時間sj,以及執行過程中對第k類資源的占用量rjk(k=1,2,…,K)。第k類資源的總量上限記為Rk(k∈K)。其中,活動1和活動n+2 為虛擬活動,不消耗時間和資源,用以標記項目的開始與結束,故d1+dn+2=0,r1k=r(n+2)k=0(k=1,2,…,K)。
RCPSP的數學模型如下:
目標函數(1)是最小化項目完成時間,活動n+2的結束時間(FTn+2)即是項目完成時間;約束(2)為優先級約束,任一活動的開始時間大于或等于所有緊前活動的結束時間;約束(3)為資源限制,任一時刻的資源占用量不得超過可用資源上限,其中集合A(t)包含t時刻所有正在執行的活動;約束(4)表示任一活動的開始時間都不為負數。
項目常用一個AoN(activity-on-node)有向網絡圖G=(N,A)來表示。節點集合N對應n+2 個活動,連接集合A對應活動間的緊前關系。圖1是一個由9個活動組成的RCPSP示例,其僅涉及1類資源,該資源為可再生資源[14]且占用上限為8個資源單位。圖2為該示例的最佳調度計劃,對應的最短項目工期為13個時間單位。
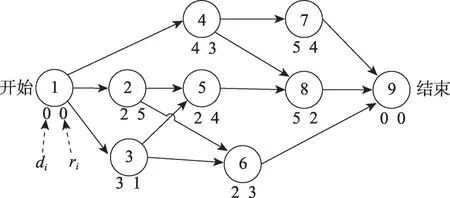
圖1 RCPSP實例Fig.1 RCPSP example
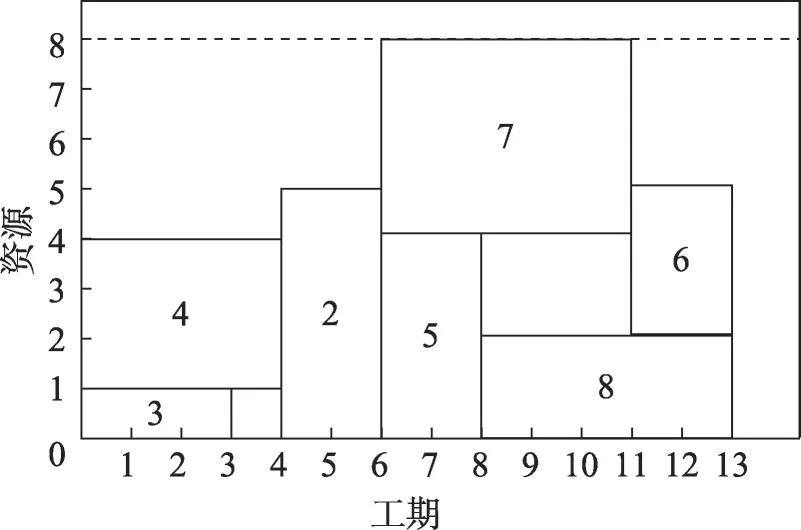
圖2 RCPSP示例的最優解決方案Fig.2 Optimal solution of RCPSP example
2 相關工作回顧
2.1 基于元啟發式的優化方法
2.1.1 概述
元啟發式算法具有優秀的探索尋優能力,但其算法設計和實現中也存在三個需要克服的困難:(1)元啟發式算法的隨機搜索特性令其難以保證求得精確解,盡管當前已有不少相關算法展現出了強大的優化能力,但它們在開放實例庫上的求解精度依然與最優解下限或理論最優解有一定差距;(2)元啟發式算法的求解精度與計算耗時往往難以兼顧,二者符合“沒有免費的午餐定律”(no-free-lunch theorem)[16];(3)元啟發式算法的參數敏感性使其面對不同規模或特性的問題時需要頻繁地調整參數來維持算法的魯棒性。
針對上述挑戰,基于元啟發式的混合型算法(hybrids)[3]框架在近二十年來獲得飛速發展。通常,一種混合型算法框架內同時包含多種算法、搜索算子或優化技術,因此構造一個混合型算法往往運用到多種方法。典型的構造方法有:(1)超啟發式,用一種高層啟發式對多種底層算法進行選擇[17-19];(2)混合算法,將多種元啟發式算法結合[20-22];(3)多重算子,為算法引入其他的啟發式或元啟發式搜索算子[23-25];(4)異構算子,改變搜索算子的演化行為[26-27];(5)異構算法,改進算法的演化框架[28-31]。這些方法使得演化種群能夠在迭代過程中采取合適的搜索方式,以滿足不同演化階段下對種群多樣性或收斂性能的需求[28]。但是,算法框架的復雜化是計算成本增加的重要原因之一。對于這一問題,不少專家學者選擇通過設置較小的種群規模來平衡算法的計算復雜度[4]。
接下來,本節將回顧國內外學者如何基于各類經典的元啟發式算法實現混合型算法框架的構建,以求解RCPSP及其衍生問題。
2.1.2 進化算法
Kadri等[26]提出一種能有效求解多模式RCPSP的遺傳算法(genetic algorithm,GA),通過將優先級規則與基于遺憾值的有偏取樣策略[10]結合,生成高質量的初始種群,同時采用一種改進的兩點交叉算子以更加適用RCPSP 的求解。Sallam 等[28]將整個迭代過程分為以種群多樣性與局部收斂為主要搜索目標的前后兩個階段,提出一種兩階段、多算子的差分進化算法(differential evolution,DE),該算法在每個階段設置兩種差分進化算子,并根據不同算子對多樣性和收斂的貢獻程度對搜索算子進行選擇。項前等[29]提出一種差分進化參數控制及雙向調度算法,在差分進化算法的基礎上加入自適應參數控制策略、正逆向交替調度優化(forward-backward improvement,FBI)[32]策略和一種保留精英個體的種群隨機重建策略,以盡可能滿足RCPSP對算法性能的要求。
2.1.3 群集智能算法
Dang 等[30]為了避免算法后期陷入局部最優,在粒子群優化算法(particle swarm optimization,PSO)中引入一種遷移策略,該策略能夠將收斂停滯的種群轉移至新的區域探索,以此跳出局部最優。Chen等[23]為了加快PSO算法對最優解的搜索效率,對每次迭代產生的新個體執行活動延遲鄰域搜索策略和FBI,通過提高種群對解空間的取樣數量,提高算法尋得最優解的概率。安曉亭等[24]首先對蟻群算法(ant colony optimization,ACO)進行適應性改進并求得Pareto 解集,接著利用帶邏輯約束的insert 和swap局部搜索啟發式對當前種群中的非支配解進行鄰域搜索。Ziarati 等[25]同時對蜜蜂算法(bee algorithm,BA)、人工蜂群(artificial bee colony,ABC)算法和蜂群優化(bee swarm optimization,BSO)算法拓展三種局部搜索策略,并通過實例集J30、J60、J90和J120的測試實驗證明結合了FBI 的BSO 是實驗所涉算法中優化性能最好的變種算法。
2.1.4 混合算法
Myszkowski 等[20]提出一種將差分進化算法與貪婪局部搜索(greedy local search,GLS)算法結合的混合算法,該算法通過由DE 產生子代,再由基于GLS的調度生成策略為子代個體生成最優的調度計劃。Tian等[21]采用相同思路,采用GA生成子代,然后混合一種基于多目標馬爾可夫網絡的分布估計算法(estimation of distribution algorithm,EDA),為子代建立資源分配模型,進而幫助每個子代個體獲得最優的調度計劃。Bagherinejad等[22]提出一種新型混合算法,將非支配排序蟻群優化(non-dominated sorting ACO)算法與GA 相結合,以實現對具有時間不確定性的RCPSP的魯棒調度。
2.1.5 基于元啟發式的超啟發式算法
結構較為簡單的超啟發式算法根據概率隨機選擇底層算法。Elsayed 等[4]以多算子遺傳算法和多算子差分進化算法為底層算法,構建一種通過自適應概率系數對4 種底層搜索算子進行選擇的超啟發式算法COA(consolidated optimization algorithm)。COA將迭代過程分為多個周期,每一周期開始前會重新選擇搜索算子,而每種搜索算子的被選擇概率會根據之前的收斂表現進行適用性調整。
基于強化學習的超啟發式,通過深度學習技術不斷學習底層算法在執行過程中的歷史表現,以決定每一種底層算法在下一決策點被選擇的概率。Sallam等[17]以多算子差分進化算法和禁忌搜索(cuckoo search,CS)為底層算法,提出一種基于強化學習策略的超啟發式算法DECSwRL-CC(DE and CS with reinforcement learning with chance constrained)。
還有一種常見的超啟發式設計范式,是將底層算法的選擇優先級視作優化問題,以元啟發式算法作為高層算法對其進行求解。Koulinas 等[18]提出一種基于粒子群優化算法的超啟發式算法,采用PSO對8 種啟發式搜索算子進行選擇;Chand 等[19]提出了以9種優先級規則為底層架構的遺傳規劃超啟發式,利用GA 的交叉算子和變異算子挑選適合求解當前問題的優先級規則。
2.1.6 面向RCPSP的其他典型算法改進
Wang 等[27]針對RCPSP 提出一種混合估計分布算法,采用一種新型概率模型更新機制對有挖掘潛力的搜索區域進行更好的采樣,同時還引入FBI和基于置換的局部搜索策略來增強算法的收斂能力。Bouleimen等[31]利用兩種鄰域搜索策略改進模擬退火(simulated annealing,SA)算法,新算法可用于標準RCPSP 和多模式RCPSP 的求解。但是,Wang 和Bouleimen 等提出的這兩種算法都沒能對標準實例庫PSPLIB的實例問題提出較有競爭力的解決方案。
2.2 帝國競爭算法
2.2.1 帝國競爭算法概述
ICA 是由Atashpaz-Gargari 和Lucas 于2007 年提出的一種群集智能算法[33],其計算流程如算法1 所示。首先,生成一個個體規模為NP的初始種群Pop0={Xi|i=1,2,…,NP},其中Xi為個體矢量,對應優化問題的一個可行解,Xi的成本值(即適應度)為f(Xi)。挑選Pop0中成本值最低的Nimp個解作為帝國主義國家,其余解則作為殖民地分配給各帝國主義國家,組成多個帝國。隨后,各帝國在迭代過程中循環執行同化、革命、交換和競爭四種機制。失去所有殖民地的帝國將會消亡。當種群中僅剩一個帝國或算法達到最大迭代數時,結束運行,輸出種群中的最優個體。
算法1帝國競爭算法
輸入:帝國競爭算法參數(NP,Nimp,β,γ,UR)。
輸出:種群中的最優個體Xbest。
步驟1隨機生成一個規模為NP的初始種群Pop0。
步驟2帝國劃分。Pop0中最優的Nimp個解成為帝國主義國家,計算和比較各帝國主義國家的歸一化成本值cˉ,任一帝國e可獲得的殖民地數量為Ncole(e=1,2,…,Nimp)。
步驟3同化。所有帝國內,殖民地根據β和γ向其隸屬的帝國主義國家所在區域移動。
步驟4革命。為帝國內的每一個殖民地生成一個0到1之間的隨機數ri,ri小于UR的殖民地將被重新隨機生成(i=1,2,…,Ncole)。
步驟5交換。帝國中成本值最低的國家成為該帝國的帝國主義國家。
步驟6競爭。歸一化總成本值最小的帝國將其最弱的殖民地供給其余帝國爭奪,計算其余帝國的勢力POWe=[-re],勢力最大的帝國獲得該殖民地。
步驟7算法達到終止條件前重復執行步驟3至步驟6。
ICA中,帝國所代表的子種群之間屬于平行合作[3]關系。帝國內部通過同化、革命和交換三個機制進行演化,帝國間的交互由競爭機制完成。同化機制中,殖民地根據同化系數β和同化偏移角γ向其隸屬的帝國主義國家移動,以通過對帝國主義國家鄰域的大量采樣實現搜索區域的快速收斂。根據革命概率UR,革命機制會重置部分殖民地的個體編碼,幫助種群保持多樣性。交換機制確保每輪迭代開始時帝國主義國家是帝國內部成本值最低的個體。競爭機制根據各帝國的總成本值TC(total cost),通過將弱勢帝國的最弱殖民地轉移給演化效益更高的帝國,來強化種群對關鍵區域的收斂效率。更詳細的算法流程和參數說明請查閱文獻[34]。
2.2.2 帝國競爭算法在調度問題中的應用
目前,ICA 還鮮有被用于RCPSP 及其衍生問題的求解,但大量的文獻資料顯示,ICA 有著較強的搜索性能和魯棒性[35],且在調度優化領域有著良好的應用潛力,如:Li 等[36]開發出一種具有動態反饋能力的ICA,為考慮運輸與時序的流水車間調度問題提供了一種有效的解決方案;Akbari等[37]成功利用ICA實現VVER-1000 反應堆堆芯在循環期間的最佳燃料布置;Behjati 等[38]采用一種分組式帝國競爭算法,處理大規模碼頭岸橋分配和內集卡調度問題,在對實例的計算中取得了良好效果;Shokouhandeh等[39]利用一種改進ICA,面向電動汽車停車場與采用分布式發電單元供能的充電樁,實現兩種應用場景下的24 h 能源優化調度。總的來說,ICA在調度領域有著廣泛的應用前景,且還有很多細分領域未曾涉獵。基于此,本文嘗試提出一種TSE-ICA用于RCPSP的求解。
3 二階段演化帝國競爭算法
TSE-ICA是一種針對RCPSP所提出的具有多個搜索算子和優化策略的混合型優化算法。如前所述,該算法將優化過程分為勘探與挖掘兩個階段,通過在不同階段選擇合適的搜索算子,實現種群多樣性與收斂性能的靈活側重。本文創新性地提出兩種新型同化算子用于二階段演化框架的構建。同時,采用記憶庫技術異構化ICA的種群演化模式。
TSE-ICA的優化流程如圖3所示。首先,采用隨機數排序法[29]和編碼修正策略(算法2)生成初始種群,利用串行調度生成策略[40]計算個體成本值,并為初始種群劃分帝國。接著,建立一個與初始種群規模相當的記憶庫M,將初始種群存于其中。至此種群開始迭代,并根據預設的迭代數將演化過程分為兩個階段:階段1,采用組塊間同化算子開發種群多樣性;階段2,在組塊間同化算子中融入相同元素保留策略以加速收斂。同時,基于組塊的改進革命機制能夠有效地對殖民地進行鄰域搜索。而改進后的帝國競爭機制可以交互各帝國的收斂信息,自適應地調整各帝國的同化系數。同化機制和革命機制產生的高質量子代會取代M中的較差解。在每一輪迭代結束前,使用M更新現有種群,并重新劃分帝國。算法達到終止條件(當前迭代數g大于預設的最大迭代數G)時結束運行,輸出種群中的最優解。
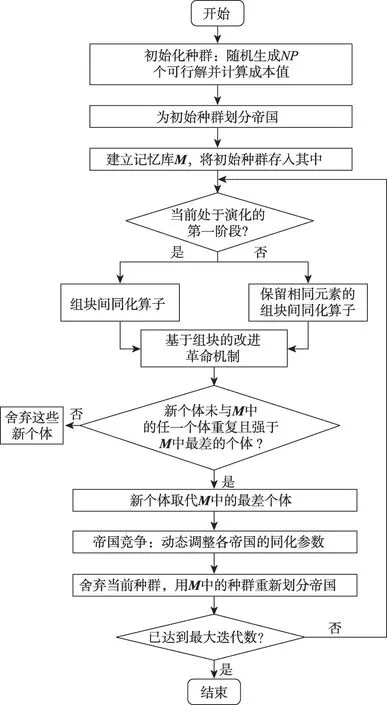
圖3 TSE-ICA的流程圖Fig.3 Flowchart of TSE-ICA
3.1 個體編碼與初始種群
TSE-ICA 的Pop0中,個體的編碼形式是滿足優先級約束的活動列表Xi=(x1,x2,…,xn+2)。初始個體皆由隨機數排序法生成:首先,為每一個活動生成一個0 至1 內的隨機數,而活動1 和活動n+2 固定對應數值0和1;接著,對所有隨機數進行升序排列得到隨機數數列,進而生成對應的活動列表;最后,對生成的活動列表采取編碼修正策略,得到滿足優先級約束的可行活動列表。圖4為一個可行解的生成過程。
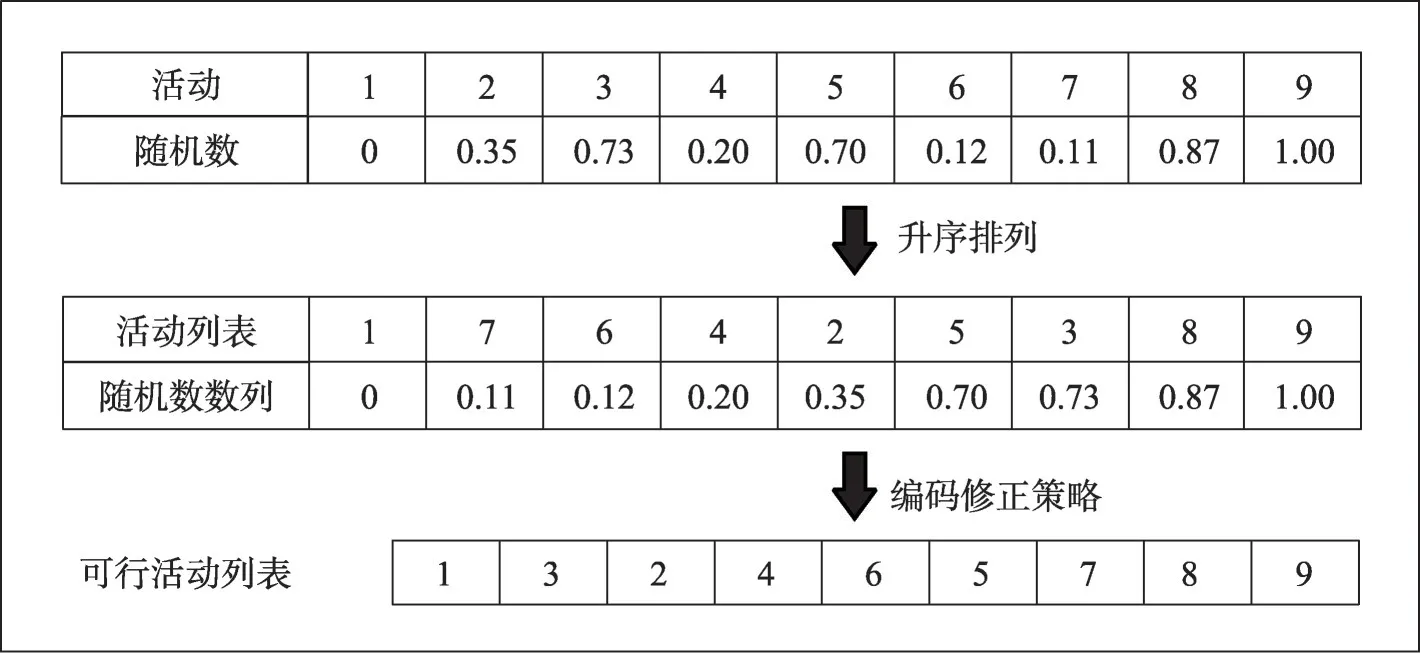
圖4 可行活動列表的生成過程Fig.4 Process of generating feasible activity list
算法2 為非可行解的編碼修正策略。整個修正過程分為n+2個階段,每一個階段針對一個編碼位置進行修正。若當前位置的活動不符合優先級約束,便在活動列表中找出該活動的所有緊前活動,然后將該活動與編碼位置最靠后的緊前活動調換位置,重復該過程直至當前位置的活動滿足優先級約束,便進入下一階段對下一個編碼進行修正。
算法2編碼修正策略
初始種群建立后,需要將每個個體編碼轉換為調度計劃方可計算成本值(即項目完成時間)。串行調度生成策略(serial schedule generation scheme,SSGS)和并行調度生成策略(parallel schedule generation scheme,PSGS)是最常用的兩種轉換方法[40]。基于活動列表中的排序,SSGS能夠給予每一個活動盡可能早的開始時間,令每個活動被安排在允許其執行的時間窗內的最佳時刻,因此SSGS生成的調度計劃被稱為活躍的調度計劃(active schedule);PSGS能夠在任一時刻t盡可能多地執行活動,在該策略下延遲任一活動的開始時間都會導致項目完成時間被延遲,因此PSGS 生成的調度計劃被稱為不可延遲的調度計劃(non-delay schedule)。不可延遲的調度計劃是活躍的調度計劃的一個子集,最優解決方案一定存在于活躍的調度計劃中。因此,本文選用SSGS計算個體的成本值。
隨機生成個體的計算復雜度為O(nNP),編碼修正策略和SSGS 的計算復雜度同為O(n2NP),因此初始化種群的計算復雜度為O(2n2NP+nNP)。
3.2 記憶庫
在基于種群的元啟發式算法中,記憶庫是一項常用的收斂輔助工具,更是GA 與DE 及其變種算法的核心組成部分[3]。記憶庫能夠存儲搜索過程中產生的精英解,并利用該信息引導種群進化,進而起到提高種群收斂速度的作用[41]。
為保證種群整體質量的穩定提高,TSE-ICA引入一個記憶庫M,用于存儲當前質量最高的NP個可行解,并在每一輪迭代結束前用其更新當前種群。迭代開始前,M會對整個初始種群進行備份,且M的存儲規模不再發生變化。每一輪迭代中,經由同化機制(3.3節)與革命機制(3.4節)產生的新個體,若不與M中的任一個體重復(即所有活動的開始時間一致)且優于M中的最差解,便取代M中的最差解,反之舍棄這些新個體。最后,在每一輪迭代結束前,現有種群會被M中的種群替代,并重新進行帝國劃分。利用記憶庫更新種群的計算復雜度為O(NPG)。
需要說明的是,因為本文算法會在每一輪迭代中重置種群并重新劃分帝國,所以無需執行標準ICA中的交換機制。
3.3 二階段同化機制
以探索階段開始、挖掘階段結束的二階段演化框架目前已被運用于多種混合型元啟發式算法中,且都取得了較好的實驗成果[28,42]。經典的二階段演化過程常常將尋優過程按照迭代次數分為兩個階段,然后在前后兩階段使用不同特性的搜索算子。同化是ICA最主要的搜索算子。因此,本文提出兩種專門用于RCPSP 的改進同化算子,分別負責第一階段對搜索空間的廣泛勘探和第二階段對最優解的快速收斂。比例系數St控制著兩個階段的轉換:當g>St×G時,演化進程由階段1進入階段2。
3.3.1 組塊間同化算子
TSE-ICA在階段1,采用組塊間同化算子開發種群多樣性,即殖民地向其宗主國趨同的過程中,個體的編碼分量以組塊為單位進行變動來產生新個體。
通過關鍵路徑法[6],可以得到實例網絡圖G=(N,A)的關鍵路徑和每一個活動對應的最早開始時間EST(earliest start time)和最晚結束時間LFT(latest finish time)。處于關鍵路徑上的活動被稱為關鍵活動,延遲關鍵活動的完成時間會對項目工期造成直接影響[8]。以關鍵活動為界,一個活動列表可提取出若干個組塊,構成一個組塊集合B。圖1中的關鍵活動為1、2、6和9。基于圖1,一個組塊提取示例如圖5所示。在任一可行活動列表內部,關鍵活動間的前后順序始終是固定的。因此,將關鍵活動作為組塊的首個元素能夠起到標記組塊位置的作用,并作為組塊的索引號使用。同化雙方具有相同索引號的兩個組塊在本文中被稱為對位組塊。
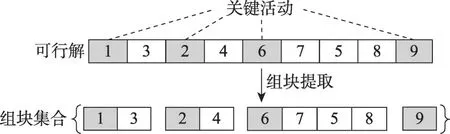
圖5 組塊提取示例Fig.5 Example of block extraction
上述的組塊提取策略能夠幫助算法實現特征選擇[43],用以較好地去除搜索空間中的冗余部分。關鍵路徑之外的活動被稱為非關鍵活動,由于優先級關系的約束,每一個非關鍵活動只能進入固定且數量有限的組塊中。比對非關鍵活動與關鍵活動的EST和LFT,便可得到每一個非關鍵活動允許進入的組塊集合(集合內包含的是組塊索引號),如算法3 所示。通過將組塊信息與隨機搜索過程結合,每一個編碼分量的變動范圍被限制在符合條件的組塊內,即隨機搜索行為被限制在可行解所在的子空間內,以此提高算法對解空間的搜索效率。
算法3獲取非關鍵元素的可進入組塊集合
基于組塊提取策略構建的組塊間同化算子,可以利用一個同化概率UA∈[0,1]控制子代的多樣性。組塊間同化的運算流程如算法4 所示。通過采用0至1 內的隨機數與UA進行對比,殖民地個體的每一個非關鍵活動編碼都有三種可能的變動形式:當隨機數rj,1>UA時(j∈Jnc,Jnc為非關鍵活動集合),將待同化的活動從當前所在組塊隨機移入一個允許其進入的組塊的末尾;若rj,1
3.3.2 保留相同元素的組塊間同化算子
TSE-ICA的階段2,采用保留相同元素的組塊間同化算子以加速收斂。
隨著種群的演化,一些有助生存的基因片段會越來越普遍地存在于個體編碼中。對于RCPSP,這些基因片段可表征為多個特定活動有序組成的特定活動塊。這些活動塊能夠高效利用資源、有效壓縮工期。但很多傳統的優化方法不具備分辨和保護特定活動塊的能力,在搜索過程中對其造成破壞,從而產生大量的低質量解[8]。針對這一問題,文獻[8]選擇將父代雙方編碼中的相同活動塊保留至子代,來改善子代的整體質量。本文受此啟發,為組塊間同化算子引入相同元素保留策略。
組塊本質上就是由若干活動組成的活動塊,故優化問題可被拆解為多個子問題:各組塊的最優構成。相同元素保留策略通過不變動同化雙方在對位組塊中的相同元素,并以其在帝國主義國家(種群中的較優解)中的編碼順序傳承至子代,實現組塊內特定活動塊的識別和保留。隨著迭代的進行,組塊內的特定構成元素會不斷地積累和完善,進而實現優化子問題的逐個收斂。因此,相同元素保留策略的加入,能夠將父代的優秀特征繼承至下一代,保證子代的整體質量。并且,子代在基因上與父代的帝國主義國家更加接近,有助于各帝國更快速地完成鄰域空間的收斂工作。
保留相同元素的組塊間同化算子的工作流程如算法4 所示。與階段1 相比,階段2 的同化算子在執行過程中僅有兩處不同:(1)繼承至子代個體的特定活動在排序上同帝國主義國家一致(算法4 的步驟2);(2)對位組塊中的相同元素不執行同化操作(算法4 的步驟3.1)。此外,算法4 的步驟3.3 中,將活動插入組塊末尾同樣是為了不破壞已有的特定活動塊。并且,由算法4 可得,二階段同化算子的最大時間復雜度為O[(n2+n+1)NPG]。
算法4二階段同化機制
3.4 基于組塊的改進革命機制
TSE-ICA 的革命機制包含插入和亂序兩種領域搜索策略,主要功能是強化算法的搜索速率和避免陷入局部最優。插入策略[3,10,24,28]指將一個活動移動至任意一個允許其進入的組塊內的隨機一個位置;亂序策略指對組塊內的非關鍵活動進行一次亂序。
階段1 時,算法需要對搜索空間進行廣泛勘探,插入策略和亂序策略能有效提高算法對解空間采樣次數。階段2時,一些基因片段會在演化過程中受到保護和傳承。假若這些固定的編碼片段尚未擁有最優的元素構成且一直沒有被完善,便會在同化機制的趨同作用下普及至每一個帝國成員,進而陷入局部最優。因此,采用插入策略適當地調整組塊內的元素構成,及采用亂序策略幫助組塊內的元素嘗試不同的排序方案,有機率幫助帝國成員跳出局部最優。
改進后的革命機制依舊根據革命概率UR挑選部分殖民地進行變異,具體流程如下:
首先,設置一個變異概率UM,并在殖民地個體對應的組塊集合Bcol中隨機挑選一個組塊,該組塊至少包含一個非關鍵活動。接著,生成一個隨機數rcol,若rcol
相比插入策略,亂序策略會同時對更多活動造成影響。而隨著演化過程的推進,組塊內的元素構成趨于成熟,再對其進行頻繁的亂序易造成子代個體的質量低下。因此,受文獻[44]啟發,UM將隨著迭代數的增大而增大,其值由下式確定:
式中,UM,max為變異概率的最大取值。
由以上描述可知,改進革命機制的時間復雜度為O(URNPG)。
3.5 改進帝國競爭機制
由于每一輪迭代都會對帝國勢力進行重新劃分,帝國間的強弱關系不再適用于引導子種群間的計算資源流動。為了更好地利用不同子種群間的平行合作關系,TSE-ICA的帝國競爭機制通過交互各帝國的收斂信息,自適應地為各帝國設置更適合的同化概率UA。
首先,在初始種群劃分帝國后,根據式(6)為每一個帝國設置不同取值的初始UA。
式中,UA,i,1為第i個帝國在第一輪迭代中使用的同化系數;UA,min為初始UA中的最小值。
在演化過程中,各帝國會向上一輪迭代中收斂效益最高的帝國進行學習,自適應地調整UA值;但是,若所有帝國在上一輪迭代中都未能讓同化后的殖民地得到提升,各帝國在當前迭代的UA值會逐漸向各自的初始值靠近,以通過更廣泛的同化搜索范圍幫助種群挖掘出更具潛力的搜索區域。帝國競爭的操作流程如下:
(1)計算各帝國在同化過程中的收斂效益Cb,計算公式如下:
式中,下標g和g-1 用于表示迭代數的前后關系,后同;表示第e個帝國的第i個殖民地;βe,i為同化后降低的成本值,如果殖民地未獲得提升,其對應的βe,i=0。
(2)記收斂效益最高的帝國的收斂效益為Cbbest,g、同化概率為UA,best,g。若Cbbest,g>0,收斂效益最高的帝國在下一輪迭代繼續使用該UA值,其余帝國則通過式(9)更新UA值;若Cbbest,g=0,表示所有殖民地都未能在被同化后獲得提升,此時各帝國用式(10)更新UA值。
式中,N為高斯分布函數。需要注意的是,當UA,i,g+1<0 時,令其值等于0;當UA,i,g+1>1 時,令其值等于1。
由上,可得帝國競爭的時間復雜度為O(NPG)。
3.6 時間復雜度分析
將各組成部分的時間復雜度相加,TSE-ICA的時間復雜度為O{[(2n2+n)+(n2+n+3+UR)G]NP},若只關注主體部分,可將其表示為O(n2NPG)。
表1 為3 種先進的RCPSP 元啟發式優化算法與TSE-ICA 的時間復雜度對比。通過如表1 所示的對比結果,可以發現TSE-ICA 有著較為合理的計算成本,這意味著TSE-ICA 對RCPSP 有著較好的應用潛力。同時,經典的ICA源于對連續優化問題的求解,在以往工作中實現過3 種能夠較好求解連續優化問題的改進ICA,其與本文所提TSE-ICA的時間復雜度對比如表2 所示。用于組合優化問題的TSE-ICA 相對于以往提出的ICA改進算法,在時間復雜度上有一定的增加,但仍表現出較好的特性(隨后的計算實驗中得到進一步證明)。

表1 算法時間復雜度橫向對比Table 1 Lateral comparison of time complexity
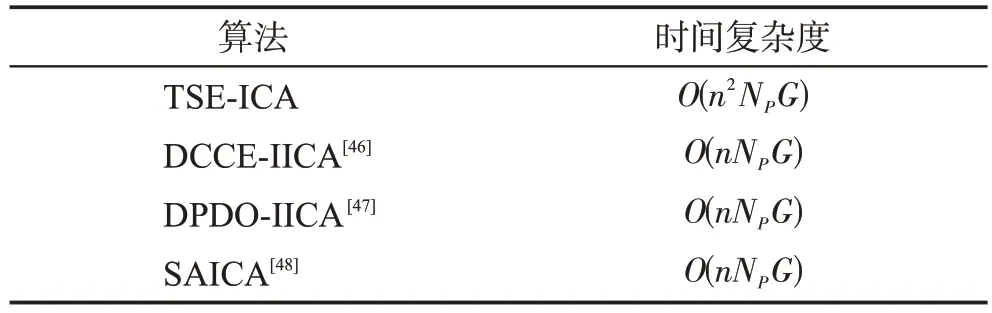
表2 算法時間復雜度縱向對比Table 2 Vertical comparison of time complexity
4 仿真實驗與結果分析
4.1 實驗設置
本文實驗是基于CPU為2.20 GHz i7-10870H、內存16 GB、64位Windows 10操作系統的計算機完成,編程平臺為Python3.7。為了檢驗本文算法的性能特點,仿真實驗部分選用標準實例庫PSPLIB(http://www.om-db.wi.tum.de/psplib)的3 個實例集J30、J60和J120,共1 560 個實例,其中J30 和J60 皆包含480個實例,J120 包含600 個實例。這些實例的生成與3個參數密切相關[14]:
(1)網絡復雜度(network complexity,NC)為每個活動的平均緊前活動數量。
(2)資源因子(resource factor,RF)為每個活動的資源需求量與資源總量的平均百分比。其值越大,活動對資源的平均需求量越大,反之則越小。
(3)資源強度(resource strength,RS)為資源的稀缺程度。其值越大可供調配的資源總量越多,反之資源受限越嚴重。
J30和J60的參數設置為NC∈{1.5,1.8,2.1},RF∈{0.25,0.50,0.75,1.00}和RS∈{0.2,0.5,0.7,1.0}。而J120除了RS∈{0.1,0.2,0.3,0.4,0.5}外,其余參數與其他兩個實例集相同。
為了更好與其他同類型研究進行對比,需要測試最大調度次數Schedules為1 000、5 000和50 000時的實驗結果(最大迭代數G=Schedules/NP)。單個實例的獨立運行次數為10。實驗的評估指標是平均偏差率AD(average deviation),即算法所求最優解與最優下界的偏差。J30 的最優下界為精確最優解。J60和J120 中部分實例的精確最優解未知,針對這兩個實例集目前有兩種評判標準:
(1)以當前已知最優解作為最優下界求取平均偏差率ADBK:
(2)在國際上更為通用的以關鍵路徑值為最優下界求取平均偏差率ADCP:
式(11)、式(12)中,P為當前實例集包含的實例個數;Fbest,p為算法對實例p多次獨立運行后取得的最優解;LBp為實例p的最優下界;下標BK 和CP 用于區分當前已知最優解和關鍵路徑值。關鍵路徑值為不考慮資源約束時的項目最短完成時間。
4.2 參數分析
TSE-ICA中影響算法有效性的參數有:種群規模NP、帝國個數Nimp、最小同化概率UA,min、革命概率UR、最大變異概率UM和階段轉換比例系數St。因為采用小規模種群有效求解經典RCPSP是本次研究的主要目標之一,所以在參照大量相關文獻后[4,8],將本次實驗中的種群規模NP設為50。
本文采用Taguchi 法的實驗設計方法(design-ofexperiment,DOE)[15]確定最佳的參數值。分別從J30、J60 和J120 中隨機選取48、48 和60 個實例計算ADBK,實驗的最大調度次數為5 000。
表3 為各參數值對應的等級。表4 為參數等級正交表和25種參數組合下TSE-ICA的實驗結果。圖6是由實驗結果得到的參數等級變化趨勢,圖中ADBK值最低的等級對應著最佳的參數取值。根據圖6,TSE-ICA 針對不同實例集的最佳參數組合如表5 所示。表6 統計了面對不同實例集時各參數對TSEICA的影響程度。由表6可知,對于J30,對TSE-ICA的優化性能影響最大的參數是Nimp,最小的是St;對于J60,UR是最有可能影響TSE-ICA 算法性能的參數,其次是UA,min,影響最小的則是St;求解J120 時,TSE-ICA 對UA,min的敏感性最高,對Nimp的敏感性最低。
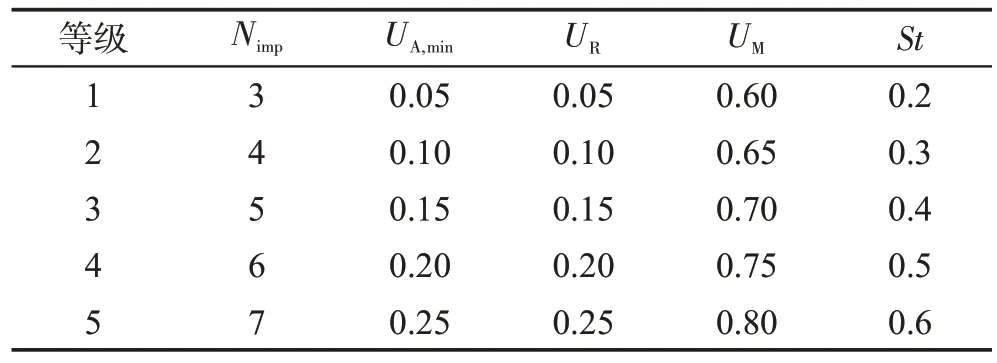
表3 參數取值等級Table 3 Level of parameter values
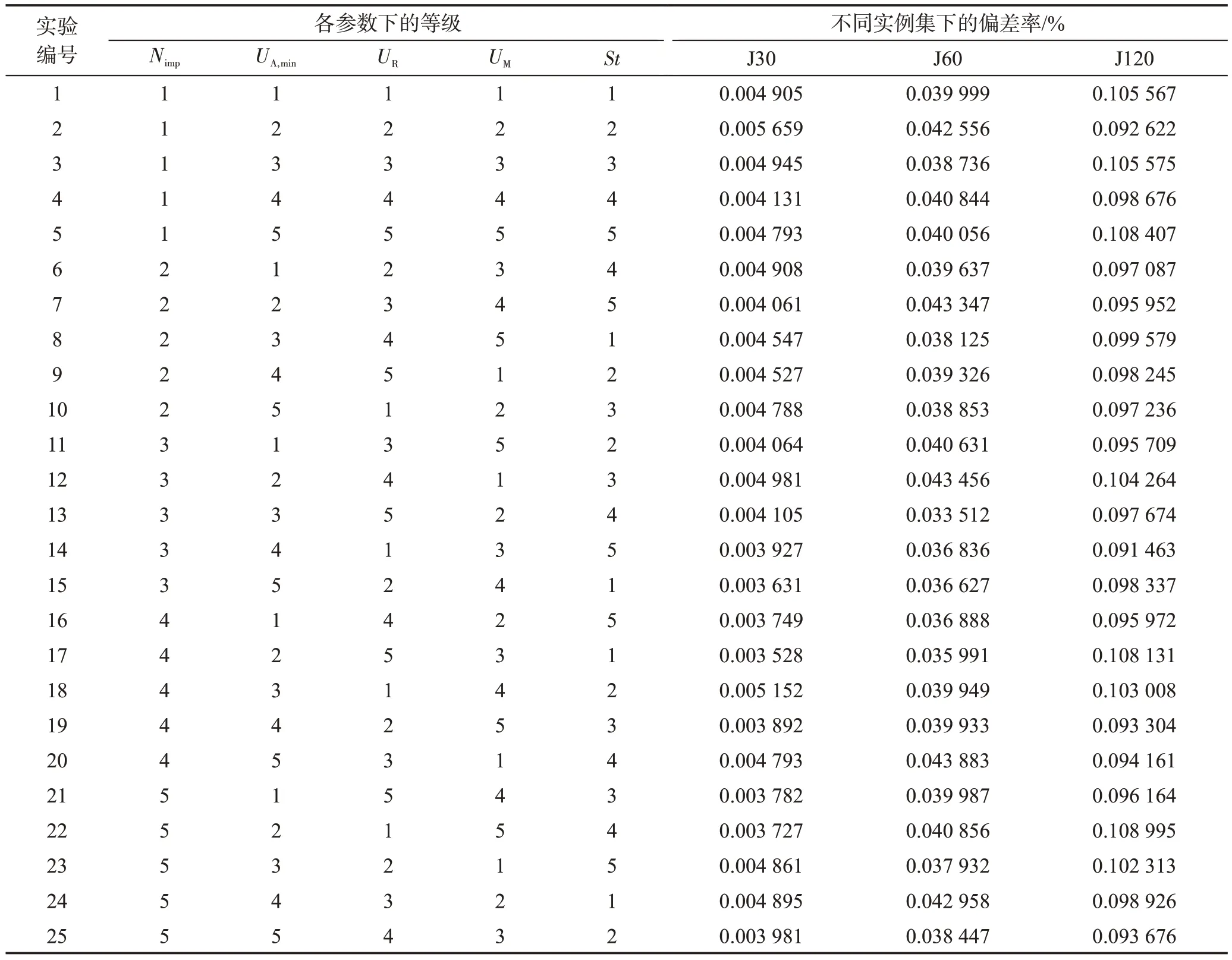
表4 正交表和TSE-ICA求解J30、J60和J120的平均偏差率ADBKTable 4 Orthogonal table and average deviation ADBK of TSE-ICA for J30,J60 and J120
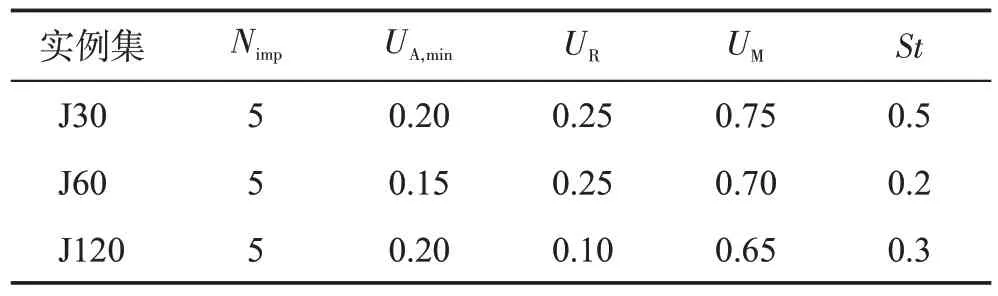
表5 最佳參數組合Table 5 The best combination of parameter values
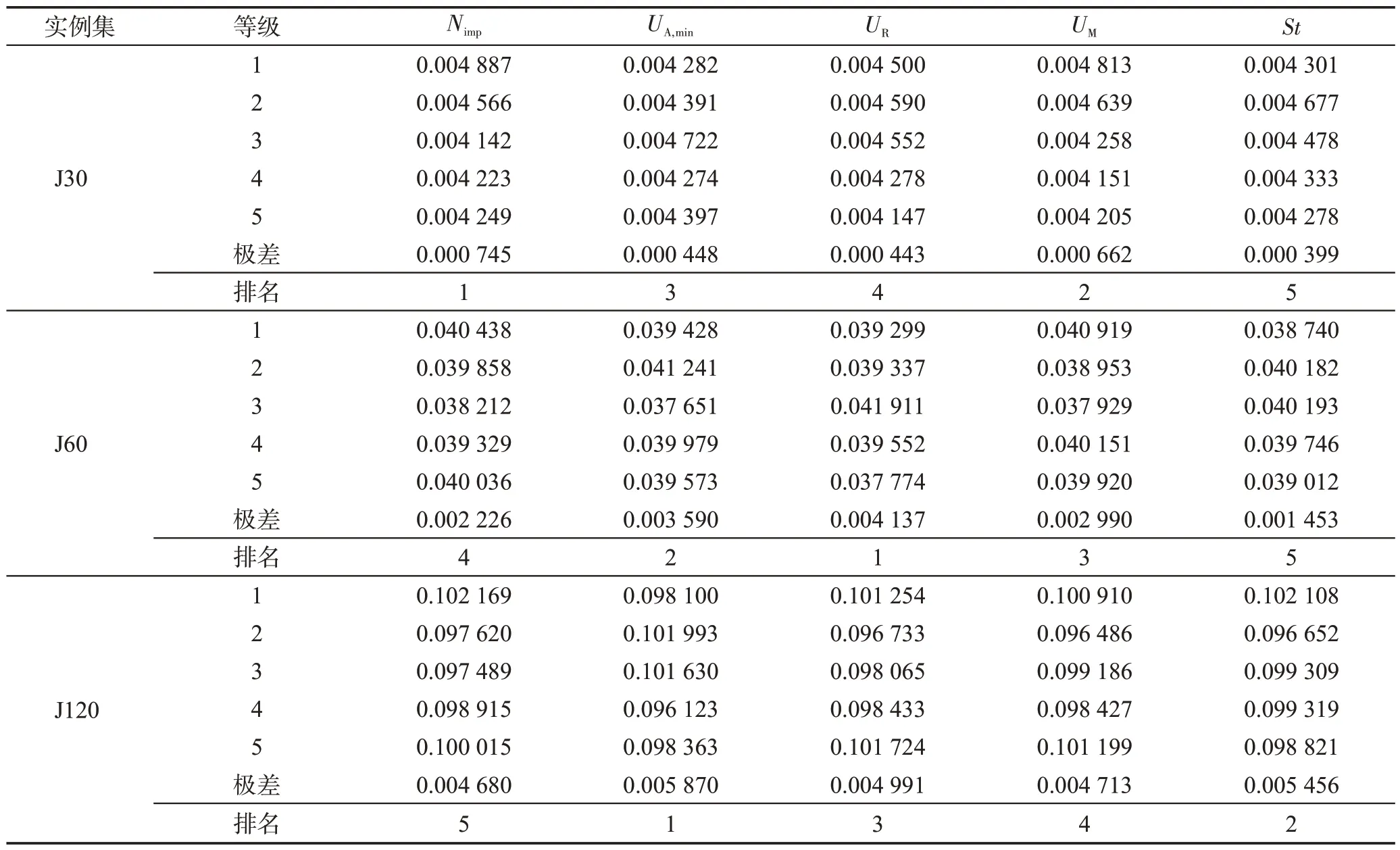
表6 均值響應表Table 6 Response table for means
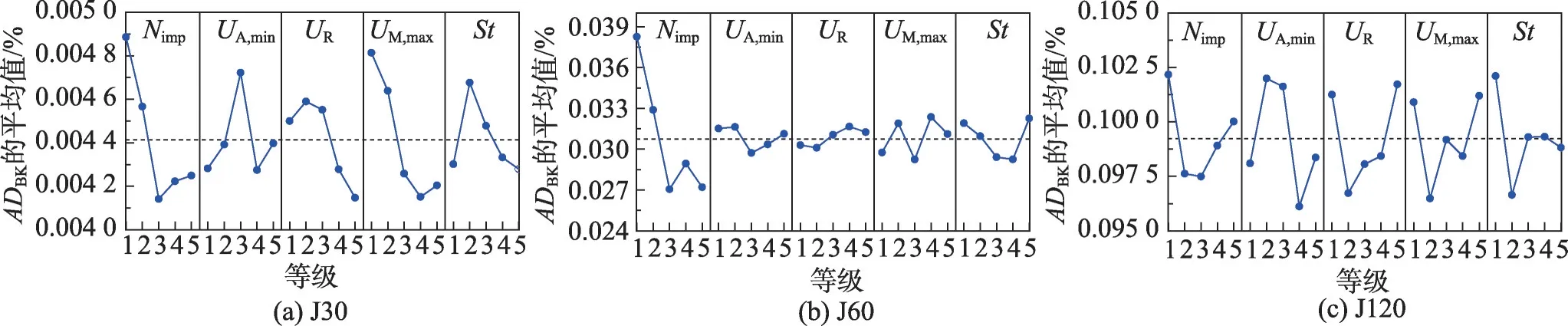
圖6 TSE-ICA的參數等級變化趨勢Fig.6 Factor level change trend of TSE-ICA
4.3 實驗結果
表7為TSE-ICA求解3個實例集的實驗結果,其中CT指每個實例的平均計算時間。圖7 展示了TSE-ICA對每個實例的所求最優解的ADBK。
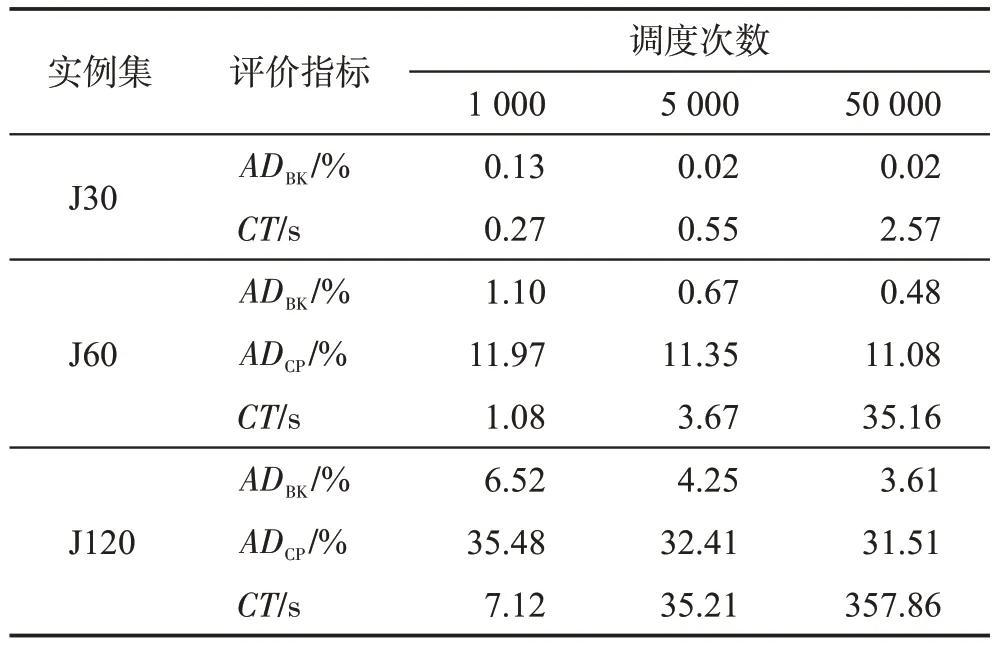
表7 TSE-ICA的實驗結果Table 7 Experimental results of TSE-ICA

圖7 TSE-ICA求解每個實例的平均偏差率ADBKFig.7 Average deviation ADBK for TSE-ICA solving each instance
如圖7(a)所示,對于J30,TSE-ICA 分別能夠在1 000、5 000 和50 000 次調度次數時求得444、473 和475個實例的理論最優解。其中,未能求得最優解的5個實例分別是13-6、29-1、29-5、29-8和40-1,其共同特點是RS=0.2。
根據圖7(b),對于J60,TSE-ICA在3種調度次數下分別有353、367 和383 個實例的計算結果與已知最優解一致。可以發現,存在偏差的實例數量及其偏差率會隨著RF的增大而增大。對于有著最小RS和最大RF的實例,算法的偏差率最大。
面對難度最大的J120,3種調度次數下TSE-ICA能夠求得已知最優解的實例數分別為153、173 和181。從圖7(c)中可以很明顯地看出,TSE-ICA 對RF大于0.25的實例的偏差率大幅高于RF等于0.25的實例。同時,偏差率與RS呈明顯的負相關。
總的來說,NC對本文所提算法的求解表現沒有顯著的影響。但是,實例的RF越高或RS越低,TSEICA越難對其求解。并且,隨著實例所含活動數的增多,RF與RS對算法求解精度的影響越顯著。
4.4 與多種先進算法的對比分析
實驗結果對比共分兩部分:(1)基于實驗所得的ADBK和CT,TSE-ICA 與3 種同類型算法、1 種GA 改進算法和2 種DE 變種進行數值比較和分析,以驗證本文算法的改進有效性和收斂效率;(2)基于國際通用標準ADCP,TSE-ICA 與11 種著名算法進行比較,進一步證明本文算法的優化性能和問題適應性。
本節列出了17 種對比算法,這些算法皆是采用或先進、或經典的優化技術構建的混合型算法。ICAS(imperialist competitive algorithm with spilt mechanism)[49]、DCCE-IICA(decimal-binary conversion and clonal evolution oriented improved imperialist competitive algorithm)[46]和ICA-DE(hybrid algorithm of differential evolution algorithm and imperialist competitive algorithm)[50]對各自應用的組合優化問題有著優異表現,IGA(improved genetic algorithm)[26]、IDE(improved differential evolution algorithm)[51]和ADDEBS(improved differential evolution parameter control and bidirectional scheduling algorithm)[29]能夠較好地求解RCPSP 及其衍生問題。此6 種算法被用于第一部分的對比。其他11種算法皆遵循國際通用標準完成J30、J60和J120的測試實驗,是TSE-ICA在第二部分的比較對象,這11 種算法在實驗結果上都有著較強的競爭力,尤其是Search-tree+GA、ALNP 和MAOA,對J60和J120的優化效果十分出色。
4.4.1 基于當前已知最優解的算法對比分析
本小節的對比算法分別是:ICAS、DCCE-IICA、ICA-DE、ADDE-BS、IGA 和IDE。表8 統計了TSEICA 與6 種對比算法基于當前已知最優解的實驗結果;表9 為TSE-ICA 與4 種對比算法(不包括ADDEBS 和IDE)的平均計算時間。ADDE-BS 和IDE 的實驗數據取自現有文獻。其余4 種對比算法的實驗平臺與數據來源同本文算法一致。
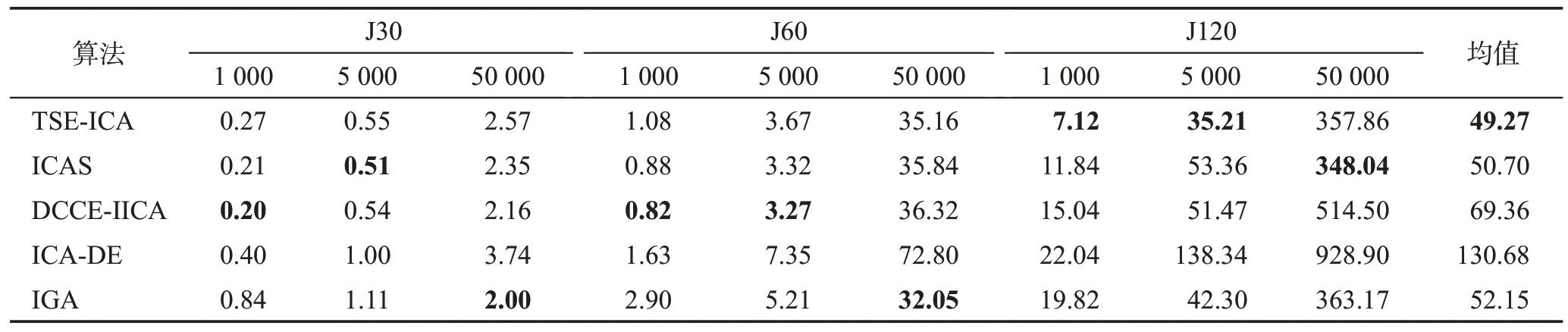
表9 5種算法求解J30、J60和J120的平均計算時間Table 9 Average computational time of 5 algorithms for solving J30,J60 and J120 單位:s
如表8所示,對于J30,IDE有著一眾對比算法中最好的收斂表現,而TSE-ICA 與除IDE 之外的對比算法相比,有著很強的競爭力。并且,在4 種基于ICA 的混合型算法中,TSE-ICA 有著最好的收斂精度;對于J60和J120,TSE-ICA在最大調度次數為1 000和5 000 時的優化性能強于所有對比算法,在50 000次調度時的求解精度僅次于IGA,這意味著本文算法能夠利用較少的迭代數尋得較高質量的解決方案,但隨著迭代數的增多,TSE-ICA的收斂效益會逐漸不如IGA。
綜合表8 的總體情況進行分析,可以發現4 種ICA變種算法對小規模實例集J30的整體優化表現不如GA 和DE 的改進算法,但面對更大規模的J60 和J120 時,4 種基于ICA 的變種算法與其他3 種對比算法相比有著不俗的優化性能。而TSE-ICA 是4 種同類型對比算法中優化精度最好的算法,這證明了本文所提改進機制的有效性。并且,對于中大規模實例集J60和J120,TSE-ICA能夠在較少調度次數的約束下尋得相對最優的解決方案,初步證明本文算法有著高效的迭代尋優速率。
此外,算法運行速率是另一項重要評估指標,用于評價算法對優化問題的適用性。正如表9所示,針對實驗中的3個實例集,TSE-ICA的整體計算時間最短,其次是ICAS和IGA。具體來看,對于J30和J60,除最耗時的ICA-DE外,其余所有算法的平均計算時間都較為相近;而面對J120 時,TSE-ICA 在1 000 和5 000 次調度次數時的計算耗時大幅短于其他算法,在50 000次最大調度次數的計算時間也僅與第一名的ICAS 保持著很小的差距。這證明了本文所提算法有著較好的運行速率。
為了更加確鑿地證明TSE-ICA在收斂精度上的優勢,本小節首先采用Friedman檢驗[52]對7種算法的優化表現進行排名。
表10 為置信度α為0.05 的Friedman 檢驗結果。基于實驗得到的平均偏差率數據,表中統計了各算法相互對比得到的秩均值。因為本文的實驗背景是求解最小值問題,故表現越出色的算法秩均值越小。SR是整合3 個數據集的實驗結果得到的秩均值,對其升序排列可得到7 種算法的優化性能排名[53]。從表10中可以看出,對于J30,IDE和ADDE-BS這兩個DE的變種算法優勢最大,而本文所提TSE-ICA位于第三名;對于J60和J120,TSE-ICA的秩均值最小;SR的排名結果顯示,TSE-ICA對3個標準實例集的整體表現優于所有對比算法。
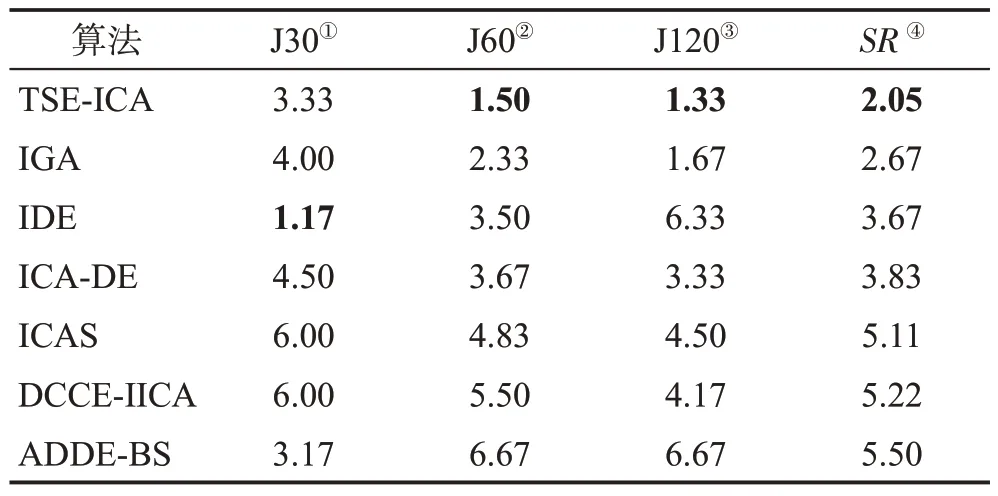
表10 7種算法的Friedman檢驗結果(α=0.05)Table 10 Results of Friedman test for 7 algorithms (α=0.05)
Friedman 檢驗能夠基于實驗結果確定多個對比算法之間是否存在顯著性差異,但忽略了對比算法兩兩之間的差異性。而post hoc Iman-Davenport檢驗[54]能夠很好地解決該問題。首先根據式(13)計算差異臨界值CD(critical difference),然后將對比算法兩兩間的SR之差與CD進行對比,若差值大于CD,說明二者間的性能確實存在顯著差異。
式中,qα是以((κ-1),(κ-1)(η-1))為自由度從F 分布統計量表得到的臨界值;κ和η分別表示算法個數和實例數。
圖8 為7 種算法的post hoc Iman-Davenport 檢驗結果。根據式(13)計算得到CD=0.162。顯然,圖8中TSE-ICA 與所有對比算法的SR之差皆小于CD,故可得出TSE-ICA與任意一種對比算法都有著顯著的性能優勢,證實了Friedman檢驗得出的結果。
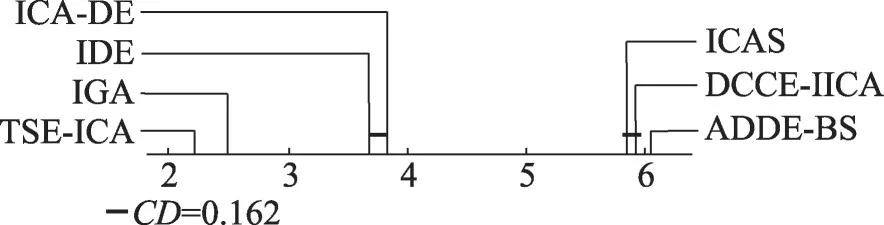
圖8 7種算法的post hoc Iman-Davenport檢驗結果Fig.8 Results of post hoc Iman-Davenport test for 7 algorithms
4.4.2 基于關鍵路徑值的算法對比分析
本小節與TSE-ICA對比的算法有11種,分別是:QICA(quantum-inspired genetic algorithm)[45]、EA(FBI)(a population based stochastic algorithm with forwardbackward improvement)[55]、Search-tree+GA(Searchtrees combined with genetic algorithm)[56]、ALNP(activity-list based nested partitions algorithm)[57]、MAOA(multi-agent optimization algorithm)[58]、DSA(differential search algorithm)[59]、MJPSO(multiple justification particle swarm optimization)[60]、PSO(FBI)(pseudo particle swarm optimization with forwardbackward improvement)[61]、GRASP(SS-FBI)(greedy randomized adaptive search procedure combining scatter search and forward-backward improvement)[62]、BA(FBI)(bee algorithms with forward-backward improvement)[63]和JPSO(justification particle swarm optimization)[64]。本小節所有算法的實驗數據皆取自已公開發表的文獻。
表11統計了12種算法基于關鍵路徑值的平均偏差率。從表11 中可以很明顯地看到:對于J30,TSEICA在調度次數較少的情況下有著最好收斂精度,但在50 000次調度時略差于MAOA、PSO(FBI)和Searchtree+GA;對于J60,本文算法的優化表現并不出色;對于J120,TSE-ICA 在1 000 次調度情況下的收斂精度相對較低,但在5 000和50 000次調度時有著最低的平均偏差率。
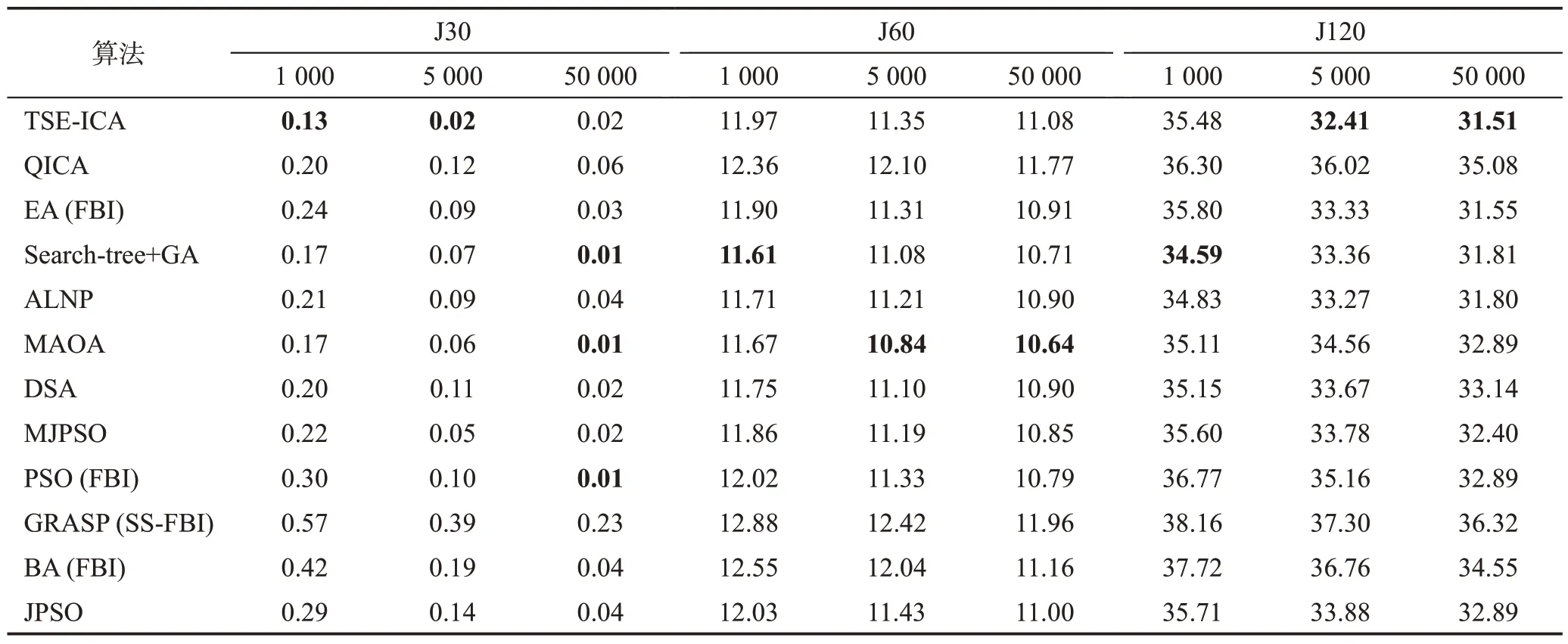
表11 12種算法基于關鍵路徑值的平均偏差率Table 11 Average deviation of 12 algorithms based on critical-path values 單位:%
此處同樣用到Friedman 檢驗和post hoc Iman-Davenport 檢驗對實驗數據作進一步的分析,其檢驗過程同前一小節一致。表12為本小節的Friedman檢驗結果;圖9為post hoc Iman-Davenport檢驗結果(根據式(13)計算得到此時CD=0.418)。
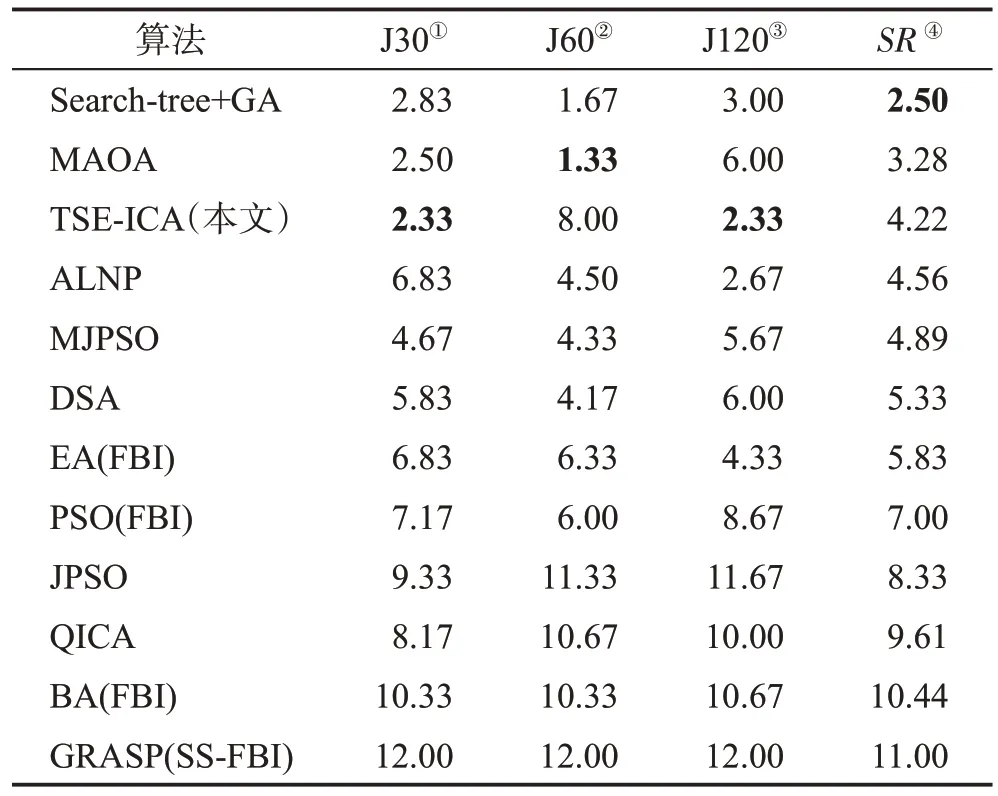
表12 12種算法的Friedman檢驗結果(α=0.05)Table 12 Results of Friedman test for 12 algorithms (α=0.05)
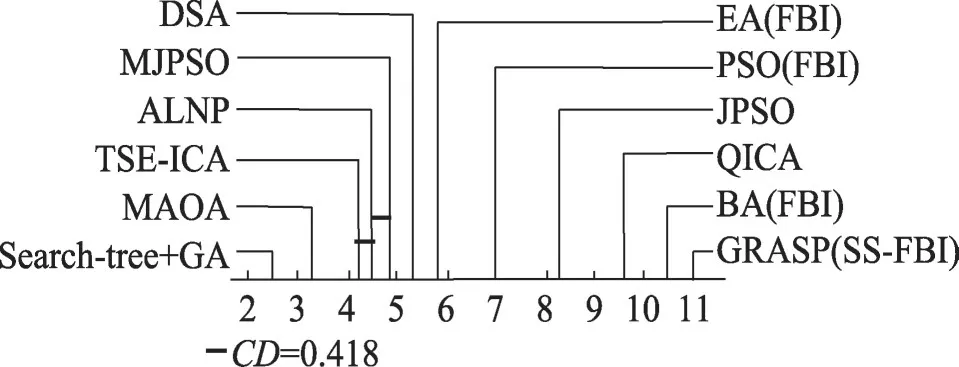
圖9 12種算法的post hoc Iman-Davenport檢驗結果Fig.9 Results of post hoc Iman-Davenport test for 12 algorithms
如表12所示,根據Friedman檢驗結果,TSE-ICA對實例集J30和J120的優化表現排在了第一位,但對J60的求解能力排在了第8名。通過對SR值排序,得出本文所提TSE-ICA在眾多優化算法中的性能表現排名為第3,落后于Search-tree+GA 和MAOA。從圖9 可以看出,TSE-ICA 與ALNP 和MAOA 的SR之差小于CD,說明TSE-ICA與除ALNP和MAOA之外的其他算法之間確實存在顯著差異,可以證明Friedman檢驗的結果存在合理性。
綜上,可以確定本文算法與國際上的知名算法相比,在小規模數據集J30和大規模數據集J120上有著出色的優化性能和較好的適用性。對于中等規模數據集J60,TSE-ICA 雖然差于部分先進的混合型算法,但仍具有較強的競爭力。
4.5 收斂速率分析
為進一步分析本文所提TSE-ICA 的收斂速率,本文分別從3個測試集中挑選2個較難求解的實例,于圖10繪制TSE-ICA與3種ICA變種(ICAS、DCCEIICA、ICA-DE)對這些實例在5 000 次調度下的收斂曲線。J30-13-5表示J30中的13-5,余同。
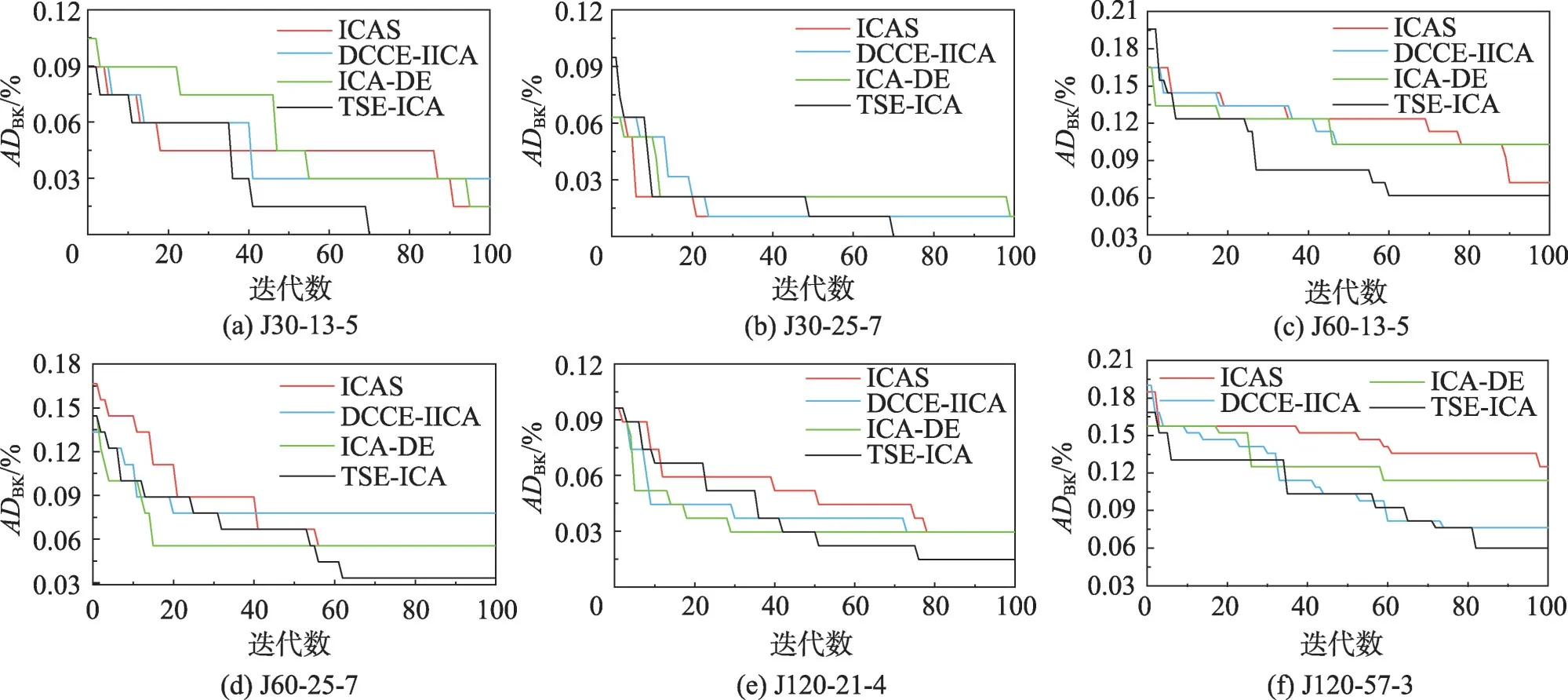
圖10 4種改進ICA對6個實例的收斂曲線Fig.10 Convergence curves of 4 improved ICA for 6 instances
如圖10(a)和圖10(b)所示,對于J30-13-5和J30-25-7,ICAS與TSE-ICA有著最快的前期收斂速率,但僅有TSE-ICA的收斂曲線能夠在中后期保持著穩定且快速的下降速率,并在最大迭代次數結束前尋得理論最優解。根據圖10(c)和圖10(d),TSE-ICA 對J60-13-5 有著眾算法中最快的收斂速度,但在對J60-25-7 的收斂速率上慢于DCCE-IICA。在圖10(e)和圖10(f)中,面對J120-21-4,TSE-ICA 雖有著最好的收斂精度,但在收斂速度上不如DCCE-IICA和ICA-DE;對于J120-57-3,TSE-ICA 在前期的收斂速度優于其他算法,在中后期的收斂速率與DCCEIICA相近。
綜合圖10 中的所有信息,可以發現四種同類型算法都能夠在演化前期有一個較快的收斂速率,但只有TSE-ICA的收斂曲線能夠在中后期依舊保持穩定的下降趨勢,極少發生收斂早熟的現象。這說明二階段演化框架及其對應的搜索算子,能有效滿足演化種群在不同時期的搜索性能需求,幫助算法維持穩定且高效的收斂速率。
4.6 改進策略的有效性分析
為了進一步驗證組塊提取策略和相同元素保留策略的改進有效性,本節對以下4 種算法進行對比:(1)采用傳統同化算子的ICA1;(2)僅采用組塊間同化算子的ICA2;(3)僅采用保留相同元素的組塊間同化算子的ICA3;(4)采用二階段同化算子的TSEICA。除同化算子外,這四種ICA的其余部分完全一致。圖11 為4 種算法對J30-13-5、J60-25-7 和J120-57-3的收斂曲線,調度次數為5 000。從圖11中可以很清晰地得出如下結論:
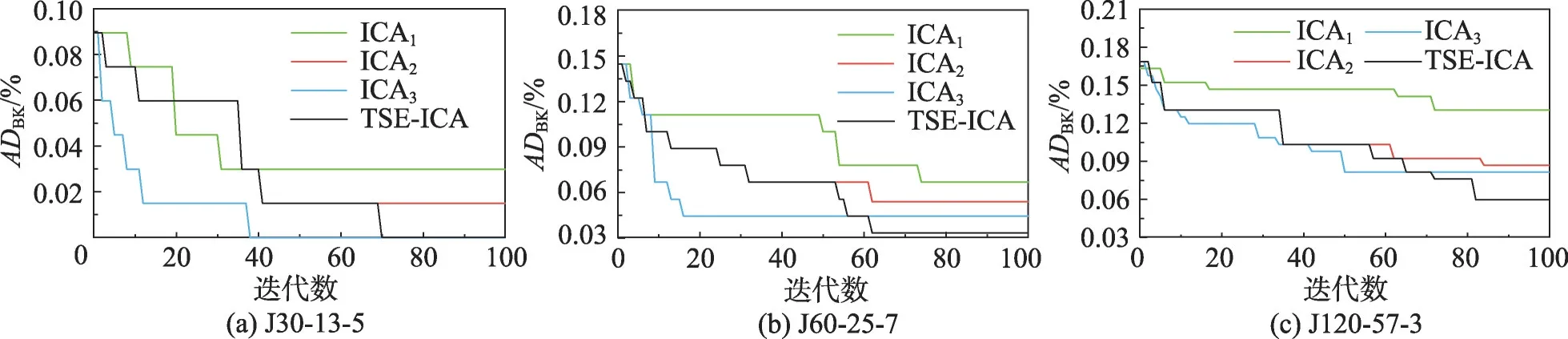
圖11 4種同化算子下ICA對3個實例的收斂曲線Fig.11 Convergence curves of ICA for 3 instances with 4 different assimilation operators
(1)ICA2對3個實例的收斂精度和收斂速度明顯強于ICA1,證明了利用組塊提取策略改進過的同化算子具有更好的搜索效率。
(2)ICA3對3個實例的求解速率明顯優于其他對比算法。并且,ICA3能夠輕松求得J30-13-5的理論最優解,對其余兩個實例的收斂精度僅弱于TSE-ICA。但是,除去難度最低的J30-13-5,ICA3對J60-25-7 和J120-57-3的收斂過程存在早熟的現象。這說明相同元素保留策略確實能夠為組塊間同化算子帶來高效的收斂性能,但僅采用該種同化算子會增加算法陷入局部最優的風險。
(3)在搜索過程的前半段,ICA2與TSE-ICA的收斂曲線是重合的。但到了后半部分,TSE-ICA開始采用保留相同元素的組塊間同化算子后,其收斂曲線的下降速率明顯快于ICA2,且在收斂精度上超過ICA3。一方面,這進一步印證了相同元素保留策略對收斂性能的貢獻;另一方面,也說明種群在第一階段對基因多樣性的積累確實有助于第二階段的收斂,驗證了二階段演化框架的有效性。
5 結束語
本文提出了一種能夠有效求解經典資源約束項目調度問題的二階段演化帝國競爭算法。該算法基于種群多樣性和收斂性能提出兩種同化算子,通過二者的交替使用實現算法在不同階段下的功能側重。兩種基于組塊的鄰域搜索策略用于革命機制中,加快算法收斂的同時幫助算法逃出局部最優。改進帝國競爭機制為算法提供自適應的參數決策。同時,一個記憶庫不斷存儲迭代過程中產生的精英解,并利用其更新現有種群,保證種群的進化效率。基于標準實例集J30、J60和J120的仿真實驗結果,本文算法通過與17種先進的元啟發式算法進行實驗結果對比,證明了本文所提改進策略的有效性、算法良好的優化性能和問題適用性。
下一步,至少還有兩個需要深入討論的研究方向:首先,本文所用的二階段算法演化框架是一種能夠平衡廣度探索與深度挖掘能力的改進策略,其有望應用于其他元啟發式算法的改進中;其次,實際的資源約束項目調度問題可能存在多模式、多技能、多緩沖和不確定性強等特點,如何基于帝國競爭算法或二階段演化框架設計出有效的優化方法,是近期需要展開的下一步工作。
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
房地產導刊(2022年5期)2022-06-01 06:20:14
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
海峽姐妹(2018年3期)2018-05-09 08:20:40
