增量式約簡拉氏非對稱ν型孿生支持向量回歸機
2023-11-16 00:51:00張帥鑫顧斌杰
計算機與生活 2023年11期
張帥鑫,顧斌杰,潘 豐
江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122
構建貼合樣本分布的模型是一項具有挑戰性的工作。支持向量回歸機(support vector regression,SVR)是貼合樣本分布來構建回歸模型的經典算法[1]。目前,SVR 已經在許多領域如預測電力負荷[2]、股市價格[3]、風速[4]和天氣[5]等取得了成功的應用。
為了提高SVR 的泛化性能,Sch?lkopf 等人[6]提出了ν型支持向量回歸機(ν-support vector regression,ν-SVR),在目標函數中引入比例參數ν(0≤ν≤1)來自動調整SVR 中的不敏感參數ε,實現對支持向量數量的控制。然而,ν-SVR 所考慮的上下ε區間內的樣本數量是一樣的,為了處理回歸問題中的不對稱噪聲,Huang 等人[7]用彈球損失函數代替ε不敏感損失函數,提出了一種非對稱ν型支持向量回歸機(asymmetric-ν-support vector regression,Asy-ν-SVR),位于不同位置的樣本會受到不同的懲罰,從而模型能夠獲得更好的泛化性能。
為了加快SVR的訓練速度,Peng[8]提出了孿生支持向量回歸機(twin support vector regression,TSVR),TSVR 將原來的求解單一大規模二次規劃問題轉化為求解兩個較小規模的二次規劃問題,構建兩個非平行超平面,其訓練速度大約是SVR 的4 倍,并且具有同樣出色的泛化性能。隨后涌現了大量關于TSVR的研究[9-12]。2017年,Xu等人[13]將TSVR和Asy-ν-SVR相結合,提出了一種非對稱ν型孿生支持向量回歸機(asymmetric-ν-twin support vector regression,Asy-ν-TSVR),兼顧訓練速度和泛化性能。隨后,Gupta 等人[14]對Asy-ν-TSVR 進行了改進,提出了一種基于彈球損失函數的改進正則項的拉氏非對稱ν型孿生支持向量回歸機(Lagrangian asymmetric-ν-twin support vector regression,LAsy-ν-TSVR)。首先用2-范數代替原來松弛變量的1-范數,使得最小化目標函數具有強凸性;然后在目標函數中加入正則化項,以遵循結構風險最小化原則;最后使用線性迭代收斂法改善計算性能,實驗結果表明,LAsy-ν-TSVR 能獲得比SVR、TSVR 以及Asy-ν-SVR 更出色的泛化性能。此后,為了解決核函數的半正定性問題,Gupta等人[15]提出了一種魯棒的拉氏非對稱ν型孿生支持向量回歸機,引入光滑函數改進模型的訓練速度,并提升了泛化性能。
然而,以上研究都是傳統離線學習方法,不能滿足在給定時間內處理大量數據的要求,從而導致越來越多的未處理數據累積,同時并未把新信息不斷地集成到已經構建的模型中,可能會導致過時的模型。在大數據情況下,增量算法能夠有效地解決以上問題。針對SVR 的增量形式,目前學者們取得了很多研究成果,主要分為精確求解形式和近似求解形式。
精確求解形式的回歸模型以Ma等人[16]提出的精確在線支持向量回歸模型(accurate online support vector regression,AOSVR)為代表,保留逐個增加的每一個訓練樣本,能夠求得模型的精確解,不會降低模型的泛化性能。隨后,受AOSVR 思想的啟發,Gu等人[17]提出了增量式支持向量有序回歸學習算法,顧斌杰等人[18]提出了精確增量式在線ν型支持向量回歸機。之后,為了降低噪聲的影響,并加快訓練速度,Huang 等人[19]提出了一種在線魯棒支持向量回歸機(online robust support vector regression,ORSVR)。最近,曹杰等人[20]提出了一種精確增量式ε型孿生支持向量回歸機,實現了ε型孿生支持向量回歸機高效地增量處理線性回歸問題。
近似求解形式通過對輸入樣本的預處理或者篩選,只能求得目標函數的近似最優解。Hao等人[21]提出增量式最小二乘孿生支持向量回歸機,通過矩陣求逆引理和基于已有核矩陣僅添加新增樣本與舊樣本構成的行向量,保持解的數量不增長,使增量更新模型的速度加快。為了解決最小二乘孿生支持向量回歸機(least squares twin support vector regression,LSTSVR)存在構成的核矩陣無法很好地逼近原核矩陣的問題,曹杰等人[22]提出一種增量式約簡LSTSVR。
目前還沒有關于拉氏非對稱ν型孿生支持向量回歸機的增量學習算法。盡管Gupta 等人[15]對拉氏非對稱ν型孿生支持向量回歸機進行了光滑處理,提升了泛化性能,但其仍然是離線算法,并不適用于增量提供樣本的場景(極端情況下,每次僅提供一個新樣本),例如:時間序列預測、網絡監測、入侵檢測、數據挖掘、金融數據分析、谷氨酸發酵過程等。一方面,現有的拉氏非對稱ν型孿生支持向量回歸機無法隨著樣本的到來動態更新模型;另一方面,在歷史樣本積累到計算機內存無法承載處理的程度,應當考慮如何削減樣本集的大小,保留有效的樣本信息。為了將拉氏非對稱ν型孿生支持向量回歸機推廣到在線學習模式,并緩解增量過程中內存消耗問題,本文提出一種增量式約簡拉氏非對稱ν型孿生支持向量回歸機(incremental reduced Lagrangian asymmetric-ν-twin support vector regression,IRLAsy-ν-TSVR)。針對現有的LAsy-ν-TSVR 離線模型無法高效求解增量問題,選擇特征相異的樣本,構建能夠保留原增廣核矩陣中線性無關的列向量和行向量的增廣核矩陣,然后以約簡后的增廣核矩陣為基礎,推導增量遞推公式,構建增量式約簡拉氏非對稱ν型孿生支持向量回歸機。最后通過實驗驗證算法的可行性和有效性。
1 拉氏非對稱ν型孿生支持向量回歸機
拉氏非對稱ν型孿生支持向量回歸機的原始問題如下[15]:
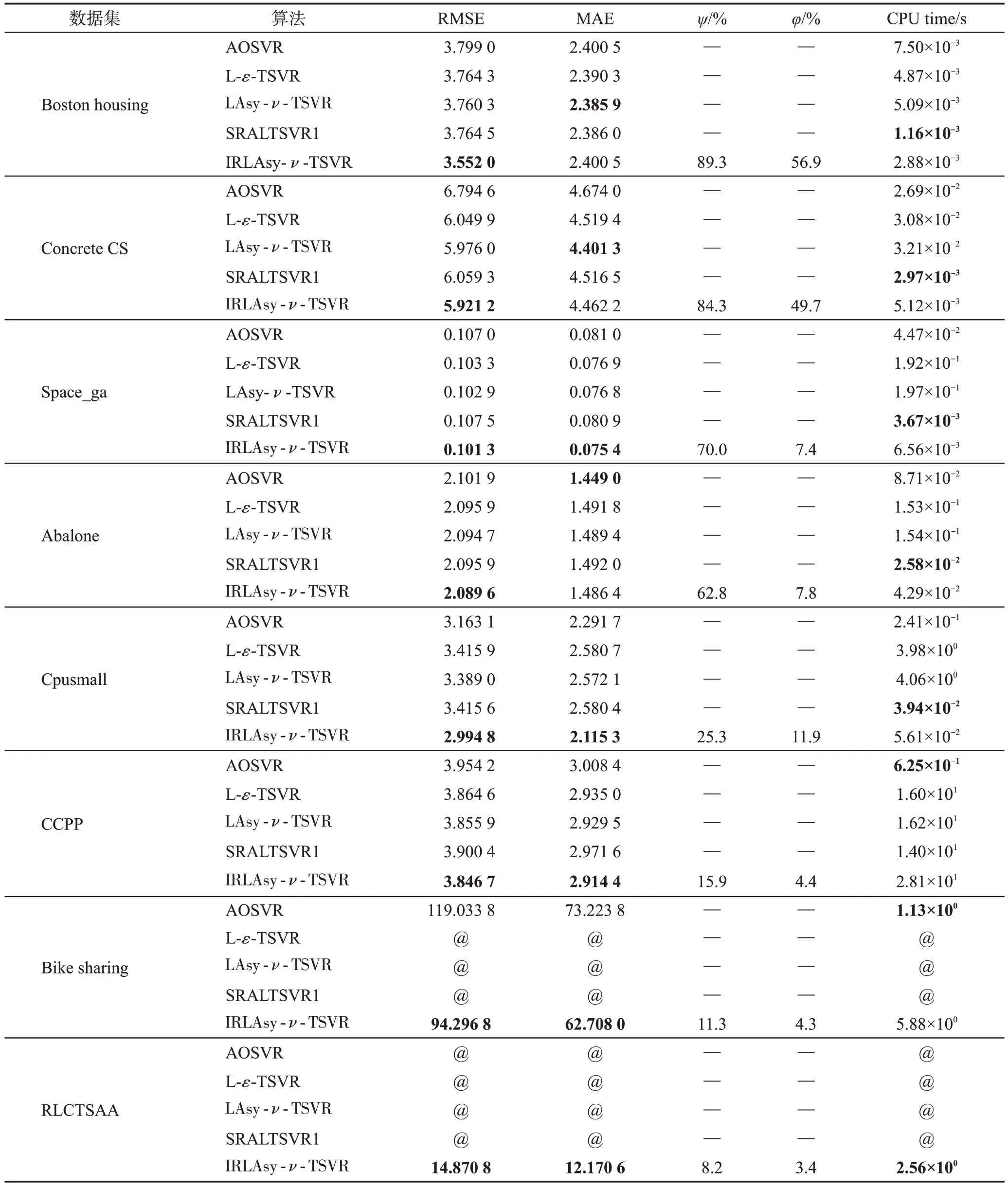
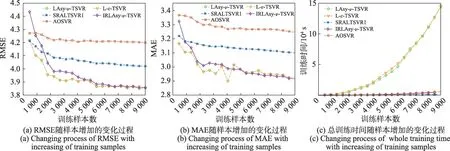
其中,ω1,ω2∈Rm為權重向量,b1,b2∈R 為偏置,C3,C4>0 為正則化常數,C1,C2>0 為線性項常數,ξ1,ξ2∈Rl是松弛向量,||?||表示2范數,e表示元素全為1的列向量,0 式(1)和式(2)的對偶問題如下[15]: 因此,對于某個測試輸入x可通過式(5)預測其輸出: 本章首先引入正號函數,將拉氏非對稱ν型孿生支持向量回歸機的有約束最優化問題轉換成無約束最優化問題,并說明為什么采用半光滑牛頓法直接在原始空間求解最優化問題;其次在增量環境下,為了節省矩陣求逆的時間開銷,討論如何利用矩陣求逆引理高效更新Hessian 逆矩陣;然后為了減少大規模數據集情況下樣本累積導致的內存消耗,采用約簡技術篩選出特征差異較大的樣本,以確保解的稀疏性;最后給出了增量式拉氏非對稱ν型孿生支持向量回歸機算法的步驟,并分析了時間復雜度。 由于在原始問題轉化為對偶問題后往往要求解一對二次規劃問題,而二次規劃的解不一定是凸優化最優解。Fung等人[23]將半光滑牛頓法運用到拉氏支持向量分類機上,直接在原始空間中求解凸優化問題,進一步加快了模型的收斂速度。受其啟發,考慮到LAsy-ν-TSVR的目標函數具有局部連續二次梯度的特性,使用半光滑牛頓法可以保證局部二次收斂,為此采用半光滑牛頓法[24-25]在原始空間直接求解最優化問題,并將目標函數修改成方便后續增量推導的形式。 首先,參照文獻[25]中的方法,引入正號函數(x+)=max{0,xi},i=1,2,…,l,將式(1)和式(2)改寫成如下無約束最優化問題: 為了更加方便直觀地處理正號函數,將式(6)和式(7)簡化為: 其中,Λ1、Λ2表示對角矩陣,以式(8)為例,當第i個輸入樣本的二次梯度不存在時,則Λ1的第i個對角元素為0,表示為。式(9)中Λ2的第i個對角元素也同樣構造。 ν型和ε型的區別在于ν型用一個比例參數ν去靈活控制管道寬度ε。因此,將ε當成一個變量,對含有雙變量的目標函數求最優解。 接著,對目標函數L1分別求關于u1和ε1的偏導數,整理得到Jacobian矩陣為: 雖然在2.1 節中用半光滑牛頓法重新對LAsy-ν-TSVR進行了求解,加快了收斂速度[15,25],但是其仍是離線算法,無法處理在線問題。為此,結合逆矩陣的增量更新公式,將拉氏非對稱ν型孿生支持向量回歸機改寫成增量形式。假設下標t表示t時刻,上標k表示第k次迭代,以此類推。假設在t+1 時刻,新增一個樣本(xl+1,yl+1),則基于增量更新公式,u1(t+1)、u2(t+1)可以由u1(t)、u2(t)快速更新求解。接下來,將分別描述初始化和迭代更新的詳細步驟。 2.2.1 初始化 初始化對角矩陣計算如下: 引理1[26]設A是l×l的可逆矩陣,b是l×1的向量,d是標量,且d-bTA-1b≠0,則有: 由引理1可得: 因此,Hessian矩陣的逆只需要通過求解W1的逆便可以求得。 在t+1時刻的初始矩陣如下: 引理2[27]設A∈Rl×l為非奇異矩陣,u,ν∈Rl是任意向量,若1+νTA-1u≠0,則A+uνT非奇異,且其逆矩陣可表示為: 2.2.2 迭代更新 離線算法和增量算法的共性問題是:增廣核矩陣的行列數會隨著輸入樣本的增加而增加,算法的復雜度會隨著解的維數指數增長。因此,為了縮短大規模數據下的訓練時間,同時減少由于大規模數據集情況下樣本累積帶來的內存消耗,提出了一種增量式約簡拉氏非對稱ν型孿生支持向量回歸機(IRLAsy-ν-TSVR)。該算法利用約簡技術,首先通過篩選特征差異較大的輸入樣本,對應保留原增廣核矩陣中線性無關程度較大的列向量;然后篩選增量過程中位于ε管道以外的樣本,對應保留原增廣核矩陣中對模型信息貢獻較大的行向量,以此構成約簡增廣核矩陣。接下來對該IRLAsy-ν-TSVR算法的約簡部分進行描述。 2.3.1 增廣核逆矩陣列約簡 在t+1 時刻,新增一個樣本(xl+1,yl+1),假設之前l個樣本中按照列約簡技術已經篩選出線性無關程度較大的樣本,命名為基準樣本,并將基準樣本存儲在集合B中,用式(13)來判定該樣本是否為基準樣本: 然后,把式(14)代入式(13),可由式(12)求得Δ的值: 如果Δ大于或者等于預先設定的常數ρ∈(0,1),那么新增樣本被添加到集合B中;否則,不被添加到集合B中。 在處理完當前新增樣本的列歸屬之后,還要更新Φt+1,為處理下一輪新增樣本做準備。需要考慮如下兩種情況: 2.3.2 增廣核逆矩陣行約簡 在t+1 時刻,新增一個樣本(xl+1,yl+1),假設之前l個樣本中按照行約簡技術已經篩選出特征差異明顯的樣本,并將其按照輸入順序存儲在集合P中,以下用式(18)來判斷是否當前的輸入樣本應該為增廣核矩陣增加一行有效的數據行: 如果γ1大于或者等于本輪迭代更新得到的ε1(t+1),也就是間隔函數的預測值位于ε1(t+1)帶以外,則新增樣本被添加到集合P中;否則,新增樣本被丟棄。 同樣,在處理完當前新增樣本的行歸屬之后,還要更新Φt+1,根據列約簡的分屬情況,將行約簡總結為以下四種情況: 情況1如果樣本不被添加到集合B中,但被添加到集合P中,則Φt+1的更新與式(16)相同。 情況2如果樣本不被添加到集合B中,同時也不被添加到集合P中,相當于丟棄新增樣本對增廣核矩陣的更新信息,增廣核矩陣既不增加行,也不增加列,則Φt+1無需更新。 情況3如果樣本被添加到集合B中,同時被添加到集合P中,則Φt+1的更新與式(17)相同。 情況4如果樣本被添加到集合B中,但不被添加到集合P中,相當于執行增廣核矩陣的列更新而不執行行更新。則: 算法1 給出了IRLAsy-ν-TSVR 中迭代求解u1(t+1)和ε1(t+1)的過程。 u2(t+1)和ε2(t+1)可以用同樣的算法步驟求解,此處不再贅述。 針對2.3 節和2.4 節給出的增量算法,以下分析新增一個輸入樣本所需的時間復雜度,并且將其分為半光滑牛頓法尋優時間復雜度和約簡樣本時間復雜度。由于加法時間復雜度所消耗的時間遠小于乘法時間復雜度,分析時只考慮后者。 綜上,如果使用直接求解逆矩陣的方法來計算半光滑牛頓法的二階梯度,其時間復雜度將為,而結合矩陣求逆引理,可將復雜度由原先的立方階降至平方階,大大加快了算法的運算速度。雖然在更新時的時間復雜度為立方階,但考慮到與l1、l2有關,而l1、l2大小是由約簡過程中的參數ρ和中間計算的ε1、ε2進行控制。實際上,只要參數相對合理,在增量過程中會篩選掉大量線性無關的樣本,時間復雜度遠遠小于立方階,同時能夠保證精度損失不嚴重。 為了驗證所提出的IRLAsy-ν-TSVR 算法的優勢,選取AOSVR、拉氏ε型孿生支持向量回歸機(Lagrangianε-twin support vector regression,L-ε-TSVR)[28]、LAsy-ν-TSVR、光滑魯棒非對稱拉氏孿生支持向量回歸機(smooth robust asymmetric Lagrangianν-twin support vector regression,SRALTSVR1)[15]在基準測試數據集上進行對比,其中,AOSVR是增量學習算法,其余都是離線學習算法,而SRALTSVR1是指用平滑近似函數ζ1(x,τ)=x+ln(1+exp(-τx))/τ將LAsy-ν-TSVR 光滑處理的算法,其中ζ1(x,τ)是τ+的近似函數,τ為非負實數。所有實驗均在Intel i5-8400T(@1.70 GHz)處理器,8 GB 內存的PC,Matlab 2016a軟件平臺上完成。 表1 中給出了實驗所使用的8 個基準測試數據集,它們分別是Boston housing、Concrete CS(compressive strength)、Space_ga、Abalone、Cpusmall、CCPP(combined cycle power plant)、Bike sharing和RLCTSAA(relative location of CT slices on axial axis),數據集規模從506到53 500不等,且所有數據集的特征被歸一化到[0,1],然后劃分為訓練集和測試集。 表1 實驗中使用的基準測試數據集Table 1 Benchmark datasets used in experiment 在訓練集上采用5 次五折交叉驗證,共25 次實驗的平均值進行參數尋優,最終以訓練集上的最優模型在測試集上的表現來評價模型的性能。采用均方根誤差(root mean square error,RMSE)和絕對平均誤差(mean absolute error,MAE)來綜合評價回歸算法的泛化性能,并且在實驗中統計了列解稀疏率φ和行解稀疏率ψ,具體定義見式(20)~式(23)。同時記錄了訓練平均單個樣本所需的CPU時間,單位為s。 其中,表示第i個輸入樣本的預測值,yi表示第i個樣本的實際輸出值,l為當前訓練樣本的總數,lB是集合B中樣本的個數,lP是集合P中樣本的個數。 采用網格化搜索進行參數尋優,為了保證實驗條件一致性和對比公平起見,AOSVR 的參數設置為ε=0.01,C=2i在i∈[-8,8]范圍內尋優。L-ε-TSVR的參數設置為C1=C2=2i,C3=C4=2i在i∈[-8,8]范圍內尋優,ε1=ε2=0.01。LAsy-ν-TSVR和SRALTSVR1的參數設置為v1=v2=j×0.1,r=k×0.1,在j,k∈[1,9]范圍內尋優,C1~C4的設置與L-ε-TSVR 相同。IRLAsy-ν-TSVR 使用與對應離線算法相同最優參數,最大迭代次數設置為k=100,半光滑牛頓法迭代停止精度設置為σ=10-5,列線性無關常數ρ=10-3。 為了便于比較,統一選取高斯徑向基核函數作為核函數K(xi,xj)=exp(-||xi-xj||2/2σ2),其中核參數σ=2i在i∈[-5,5]范圍內尋優。 表2 所示為選取的五種算法在基準測試數據集上的實驗結果,“—”表示該處指標無意義,“@”表示內存不足無法運算。為了清楚起見,最優指標加粗表示。 表2 五種算法在基準數據集上的實驗結果Table 2 Experimental results of five algorithms on benchmark datasets 從表2 可以看出,相對其他四種算法,本文算法的RMSE更小,也就是泛化性能要優于AOSVR、L-ε-TSVR、SRALTSVR1 和其對應的離線算法LAsy-ν-TSVR,即繼承了LAsy-ν-TSVR 的泛化性能,這與文獻[14]中的結論一致,一方面參數ν和非對稱參數q的引入讓模型靈活地去貼合樣本,另一方面在約簡過程中,剔除相似特征的列向量和約簡對預測性能貢獻較小的行向量,使得處理過后的核矩陣比只篩選列向量更加逼近原核矩陣,獲得和離線算法相當甚至更優的泛化性能,而其他算法的增廣核矩陣由于沒有行列信息篩選的步驟,并不能反映原核矩陣的有效信息。同時,在單步增量的半光滑牛頓迭代中,設置合適的迭代停止精度也會讓模型的RMSE更小。 從行列稀疏率指標上看,只有本文算法對核矩陣的行具有約簡過程,其稀疏率隨著樣本的增加而減小,說明其有效地剔除了核矩陣中的無效行,使增廣核矩陣逼近原核矩陣。 對于單個樣本的增量時間,本文提出的IRLAsyν-TSVR與L-ε-TSVR和LAsy-ν-TSVR相比有著相當大的優勢,通過2.5 節的時間復雜度分析,IRLAsy-ν-TSVR 的平方階復雜度優于離線算法的立方階的時間復雜度,但對比SRALTSVR1 算法,其訓練速度較差,主要原因在于本文算法添加了對增廣核矩陣的列向量和行向量的約簡,如2.5節中四種行約簡情況所分析部分,具體的時間復雜度取決于樣本的歸屬情況,同時在增量過程中,更新初始解和更新Hessian矩陣的過程中,也會增加平方階的時間復雜度,從而導致增量過程中平均一次更新時間稍大。但是從數量級上來看,兩者在大規模數據集CCPP上平均單個樣本的增量時間數量級相當,時間相差不大,詳見2.5節中的時間復雜度分析。 對于更大規模的數據集Bike sharing和RLCTSAA,由于三種離線算法均因為超過內存無法運算,表2中僅列出在線算法的實驗結果。在數據集Bike sharing上,雖然本文提出的IRLAsy-ν-TSVR 訓練速度不及AOSVR,但RMSE 和MAE 更小。而在數據集RLCTSAA上,只有本文提出的IRLAsy-ν-TSVR能夠訓練,這也體現其解決大規模數據集的在線學習問題的優勢。 為了使算法對比更加直觀,圖1 給出了在CCPP數據集上,RMSE、MAE、總訓練時間隨著訓練樣本個數的增加的變化過程。從圖1(a)和圖1(b)中可以看出,在大規模數據集上,本文算法在RMSE和MAE的下降趨勢方面都要優于SRALTSVR1。 圖1 CCPP數據集上不同算法的性能對比Fig.1 Performance comparison of different algorithms on CCPP dataset 從圖1(c)中可以看出,IRLAsy-ν-TSVR 算法的總訓練時間要小于LAsy-ν-TSVR算法,與AOSVR算法類似,訓練總時間大致呈線性增長。IRLAsy-ν-TSVR 的時間增長趨勢要優于AOSVR,這是由于AOSVR 算法屬于精確增量算法,在其每次增加樣本時,所有歷史樣本的信息都要整合到核矩陣中,稀疏率會遠大于本文算法,增加后續增量過程中的計算量。但相較于SRALTSVR1,本文算法的訓練時間較長,是因為本文算法一方面增加了對列向量和行向量的約簡處理,另一方面,本文算法增加了增量過程和半光滑牛頓法中Hessian 矩陣初始化和迭代更新,因此本文算法的時間復雜度要稍大于SRALTSVR1算法。本文算法的時間復雜度由l1、l2決定,參與模型更新的樣本減少,即l1、l2減小,總的訓練時間也相應減少。 此外,為了體現本文算法在迭代更新時模型的收斂情況,圖2統計了在CCPP數據集上,每次新增一個樣本時,IRLAsy-ν-TSVR 算法中半光滑牛頓法的迭代次數。從圖2中可以看出,大多數情況下僅需要兩次迭代就可以收斂到設定的迭代停止精度,少數情況下只需要一次。一方面,增廣權重向量在梯度方向上的維度是累加的,增量過程使得在每次添加解的維度時只需要對新增維度進行梯度下降糾正,加快了收斂速度;另一方面,在列舉的四種約簡情況中,有的情況對模型有較小更新,甚至無需更新,這也會縮短算法的訓練時間。 圖2 CCPP數據集上每次新增一個樣本時IRLAsy-ν-TSVR的迭代次數Fig.2 Iterations of adding a new sample for IRLAsy-ν-TSVR on CCPP dataset 本文將約簡技術運用到拉氏非對稱ν型孿生支持向量回歸機上,提出了一種增量式約簡拉氏非對稱ν型孿生支持向量回歸算法。在增量過程中,該算法結合矩陣求逆引理,通過對增廣核矩陣的行列約簡以逼近原增廣核矩陣,避免了半光滑牛頓法中Hessian 矩陣的直接求逆,獲得約簡拉氏非對稱ν型孿生支持向量回歸機模型,在保證最優解的高效更新的同時,實現了解的稀疏化與解的增量連續性,而且繼承了原離線算法的泛化性能。實驗結果表明,本文算法獲得的模型和離線模型具有相近的回歸精度,并且能夠獲得稀疏解,與利用光滑函數優化的離線算法SRALTSVR1 相比,泛化性能更加出色,因此更加適合解決大規模數據集的在線學習問題。2 增量式約簡拉氏非對稱ν型孿生支持向量回歸機
2.1 半光滑牛頓法
2.2 高效更新逆矩陣和對角矩陣
2.3 約簡技術
2.4 算法步驟
2.5 時間復雜度分析
3 數值實驗與分析
3.1 實驗設計和參數設置

3.2 實驗結果分析

4 結論
