中國生成式人工智能頂層設計的倫理視界
2023-11-17 06:03:06陳萬球
倫理學研究 2023年5期
陳萬球
《麻省理工技術評論》(MIT Technology Review)將生成式人工智能(GAI)描述為過去10 年AI 領域最有前途的進步之一,高德納咨詢公司(Gardner Consulting)則把其列為最有商業前景的AI 技術[1](1)。與此同時,生成式人工智能帶來的政治安全、虛假信息、算法歧視、侵害知識產權、侵害隱私和個人信息、虛假訓練數據、數據標注錯誤等挑戰層出不窮。作為對挑戰的回應,我國政府頒布了《生成式人工智能服務管理暫行辦法》(以下簡稱《暫行辦法》)。該辦法是我國生成式人工智能的頂層設計,也是全球首部專門立法,它確立了發展與治理的原則與方法,對處理技術發展與技術治理之間的關系和推動生成式人工智能技術健康有序發展具有十分重要的意義。
一、問題提出:生成式人工智能凸顯了“科林格里奇困境”
根據《暫行辦法》的釋義,生成式人工智能是指“具有文本、圖片、音頻、視頻等內容生成能力的模型及相關技術”。“相關技術”的主體主要指技術的提供者和使用者。作為一種正在崛起的新興技術,其發展趨勢引發人們的反思和擔憂:如果一項新興技術因擔心其后果不良而過早對其實施控制,它就難以發展;反之,控制過晚則有可能走向失控。這就是技術發展中所謂的“科林格里奇困境”。
1.快與慢:技術發展的快速性與治理的滯后性之間的矛盾
世界經濟論壇創始人克勞斯·施瓦布將技術進步描述為革命,因為技術進步具有速度、范圍和系統的影響。在認識與改造自然的過程中,人類祖先積淀了豐富的經驗與知識體系。技術作為“對象化的知識力量”[2](785),其發展往往是從慢到快。在農耕文明時代,一次重大的技術革命要歷時數百年甚至更長的時間;在工業文明時代,一次重大的技術革命往往也要經歷數十年。在當代,人們常常驚嘆于科技革命日新月異,摩爾定律就是明證。當代技術發展的顯著特點是加速迭代。人工智能從20世紀50 年代誕生開始算起,發展至今已70 余年,從弱人工智能到強人工智能,呈現加速發展的趨勢。以ChatGPT 為代表的生成式人工智能為例,OpenAI 在2018 年首次開發應用生成對話模型,此后不斷開發和改進GPT 模型,5 年間完成了5 次迭代,推出的技術和產品不斷創新進化(見表1)。
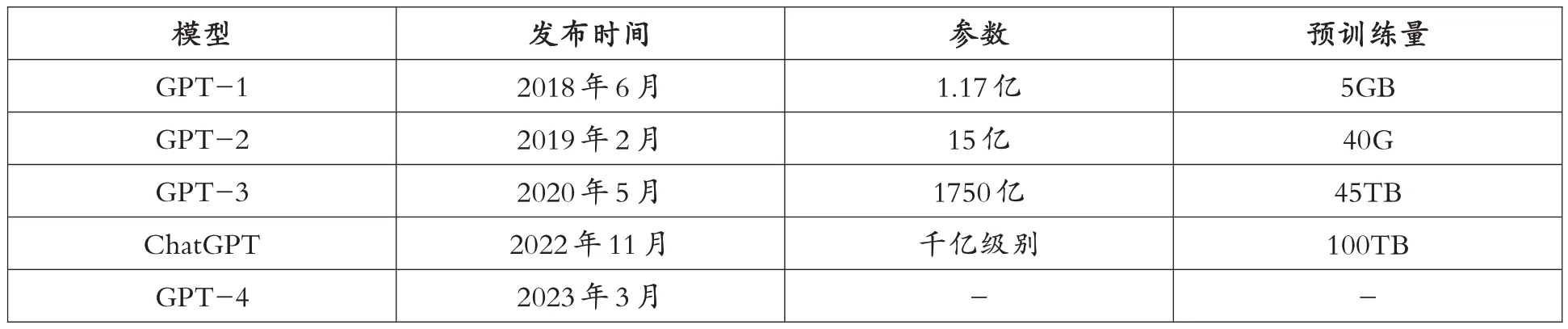
表1 GPT 的發展歷程
技術創新跑出的“加速度”讓人們始料未及,對其后果的失控警示人們暫時停下發展的腳步。2023 年3 月,包括馬斯克在內的千余名科學家和工程師,簽署一封公開信,提議暫時停止研發巨型人工智能模型6 個月,因為擔心“開發和部署更強大數字思維的競賽失控”[3]。
技術發展的“加速度”與傳統技術治理的“滯后性”形成鮮明對比。技術是呈指數級增長的,但是社會、經濟和法律系統只會緩慢增長。在以往技術治理中,治理主體面對快速迭代的技術及產生的社會問題和挑戰,往往需要審慎妥當的方法予以回應和解決,而這個過程較為漫長。尤其是生成式人工智能借助5G 互聯網技術服務應用落地提速,操作使用快捷方便,推廣應用價值廣泛。因而生成式人工智能技術的快速發展亟須治理速度與之相匹配。
2.全局與局部:技術影響的全局性與治理的局部性之間的矛盾
技術影響的全局性有兩個維度:
從廣度上看,技術對社會影響的路徑是從局部走向全局。一項新技術的傳播范圍,受到地域、國別、文化、宗教等因素的限制,起初是在比較小的范圍內傳播。技術的發展史表明,第一次技術革命時期,從瓦特根據科學原理于1769 年發明工業用蒸汽機到1868 年中國人自主研制的第一艘蒸汽輪船“黃鵠號”下水,技術傳播花了100 年左右的時間。從1804 年英國工程師德里維斯克制造出世界上第一臺蒸汽機車到1909 年詹天佑主持修建的我國第一條鐵路京張鐵路通車,技術傳播也花了100 年左右的時間。可見,在第一次技術革命時期技術傳播速度較慢,技術對社會的影響局限在一定時空范圍之內。20 世紀以來,隨著信息技術、電子計算機的發明,特別是在互聯網技術的加持下,技術傳播以前所未有的速度推進,萬物互聯互通,技術從局部到全局,涵蓋政治、經濟、文化、生態等領域。今天,生成式人工智能技術發起了新一輪影響人類社會的革命,其全局性影響領域可能包括:國家安全與意識形態,科技、教育與文化發展,廣播電影電視產業,商業模式和產業升級,社會發展與改革等。甚至有學者稱,生成式人工智能技術“有可能成為一種影響各行業的底座型技術”[4](3)。
從深度上看,技術對社會的影響是由淺入深。技術的當代性不僅表現為技術呈指數級增長,而且其影響極為深遠。進入工業化時代以來,物理學、生物學、工程學、化學在近代得到了發展,技術應用在資本主義社會獲得了巨大推動力。《共產黨宣言》指出:“自然力的征服,機器的采用,化學在工業和農業中的應用,輪船的行駛,鐵路的通行,電報的使用,整個整個大陸的開墾,河川的通航,仿佛用法術從地下呼喚出來的大量人口——過去哪一個世紀料想到在社會勞動里蘊藏有這樣的生產力呢?”[5](405)可見,自資產階級產生以來的幾百年時間里,技術對社會和人類自身的干預程度明顯加深。“人工智能正在快速發展和廣泛應用,其強大的重塑力必然對生產方式、生活方式乃至人的自身烙下深深的印記。”[6](36)生成式人工智能的深度影響表現在:就社會而言,在一定程度上重構人類社會的政治、經濟、文化、社會、生態等;就個人而言,對人的干預從體外到體內,從身體到意識逐步加深。
生成式人工智能對社會影響的全局性客觀上要求技術治理的全球性和全方位性。如果生成式人工智能的社會治理視野不夠寬闊、領域不夠廣泛、程度不夠深入,就會導致治理的“局部性”,無法與技術發展在廣度上相匹配。
3.無序與有序:技術發展的無序與治理追求的有序之間的矛盾
科技是發展的利器,也可能成為風險的源頭。“人工智能、基因編輯、大數據、納米技術、合成生物學、異種移植等科技創新發展對人類社會提出諸多倫理挑戰。”[7](7)隨著新興技術成熟曲線從“觸發期”過渡到“期望膨脹期”,新興技術蘊含的技術紅利和技術后坐力(風險)逐漸顯現。生成式人工智能可能帶來社會風險、倫理挑戰與規則沖突,造成社會的無序狀態。具體表現在:(1)偽造性。即技術生成的圖片、視頻和聲音造假。南京大學阮錦繡提出了“AI 幻覺”的新概念,認為“AI 幻覺”的危險之處在于,模型輸出看起來正確,而實質上錯誤[8](4)。《福布斯》雜志認為,生成式人工智能存在“深度造假”問題,侵蝕政治選舉,偽造的視頻、音頻令選民難辨真偽,很多人擔憂AI 會毀了2024 年美國總統選舉[9](4)。美國國會山網站報道,人工智能的發展可能會引發兩大關鍵問題,一是虛假信息傳播;二是導致歧視與偏見[10](4)。(2)個人隱私與信息侵犯。人臉是公民最敏感的生物信息和核心隱私,如果被濫用、盜用,可能會成為詐騙、網絡色情等非法活動的素材來源。2023 年5 月24 日,中國互聯網協會發文提示“AI 換臉”新騙局,利用“AI 換臉”“AI 換聲”等生成虛假音視頻圖片,進行詐騙、誹謗、色情等違法行為屢見不鮮。《科技日報》報道,有騙子通過AI 換臉和擬聲技術佯裝好友,對福州某科技公司法人代表實施詐騙,10 分鐘內騙走430 萬元[11](5)。(3)高風險性。生成式人工智能具有高風險性,有學者稱之為“AI 巨風險”[12](104)。實際上,生成式人工智能的倫理和社會風險可以歸結為以下幾類:歧視、仇恨言論和排斥、信息危害、虛假信息傷害、惡意使用、人機交互危害以及環境和經濟危害。歐盟《人工智能法案》對“高風險”進行了界定,高風險是指這種情形,它可能“對人們的健康、安全、基本權利或環境造成重大損害”[13](4)。《科技日報》報道,意大利、德國、英國、加拿大、西班牙等國對ChatGPT及其開發者展開調查,可能將ChatGPT 等生成式人工智能列入高風險人工智能清單[4](3)。高風險性和不確定性,導致AI 可能“行善”,也有可能“作惡”,“一旦被濫用或誤用,迷惑性比以往的人工智能技術更強”[4](3)。技術治理追求的目標是社會的有序性。如果生成式人工智能的社會治理針對性不強、效能不高,就不能夠很好地預防和治理風險,就會形成治理的“無序性”,導致與治理的目標相背離。
總之,生成式人工智能技術發展與治理之間的快與慢、全局與局部、無序和有序之間的矛盾,凸顯了“科林格里奇困境”,客觀上需要通過科學合理的頂層設計來破局。
二、頂層設計:《暫行辦法》的破局之道
《暫行辦法》是我國關于生成式人工智能治理的頂層設計,它確立了技術發展與治理雙輪驅動的原則與方法,嘗試在發展與治理之間尋找一種新的良方,凸顯了發展與治理如何平衡的破局之道。
1.確立發展與治理的倫理原則
生成式人工智能發展與治理的倫理原則,是立足我國新一代人工智能發展實際和客觀審視新技術的可能風險而制定的。《暫行辦法》確立了相互依存的倫理三原則。
堅持發展和安全并重,這是生成式人工智能發展與治理的首要原則。習近平總書記強調要“堅持統籌發展和安全,堅持發展和安全并重,實現高質量發展和高水平安全的良性互動”。這已成為堅持技術發展與安全的指導思想。技術的安全風險涉及國家安全、社會安全和人民群眾生命財產安全。從技術全過程看,生成式人工智能的安全風險包括全過程的風險:準備階段——“數據安全風險”、運算階段——“算法偏見風險”、生成階段——“知識產權風險”[14](30)。一方面,要通過發展生成式人工智能技術來提升安全實力和保障安全;另一方面,深入推進安全理念、機制、措施創新,營造有利于智能技術發展的安全環境,確保生成式人工智能“安全可靠可控”。
促進創新和依法治理相結合,這是生成式人工智能發展與治理的第二原則。創新強則國運昌,創新弱則國運殆。科技創新離不開依法治理。良好的法律治理,是技術創新的前提;沒有法律規范治理,科技創新就失去了壓艙石。促進生成式人工智能技術創新和依法治理相結合,有一個依法治理的“合理度”問題,這種“合理度”體現在法律對技術創新的合理引導力和科學的規范力兩個方面。從前者看,《暫行辦法》中有大量的正向引導條款(見表2)。這些條款包括創新發展、創新應用、自主創新等內容,成為促進生成式人工智能創新的重要法規依據。從后者看,《暫行辦法》包含禁止和責任條款,懲治生成式人工智能可能帶來的種種亂象,對提供者違反《暫行辦法》規定的,由有關主管部門依法處罰,以此營造良好的創新軟環境和硬環境。

表2 《暫行辦法》的正向引導條款
包容審慎與分類分級監管并行,這是生成式人工智能發展與治理的第三原則。技術發展需要自由寬松的人文環境與社會環境,甚至允許出現錯誤。科學是不斷試錯的研究,解決問題需要不斷地試錯。從某種意義上說,試錯是社會進步的動力,寬容是社會進步的基石。在歷史上,核心技術需要在試錯中發展,谷歌搜索引擎就是試錯的創新產物。蘋果公司的iPod 也是基于試錯法的創新產物。當然,涉及食品安全、身體健康、基因編輯、克隆人等的技術,是不允許試錯的。包容并不意味著放任不管,包容中蘊含審慎的態度和理念。目前世界各國對推動生成式人工智能創新應用都保持著相對謹慎的態度。此外,分類分級監管是治理的一種常見方式。《暫行辦法》對生成式人工智能技術應用劃定分級監管“紅線”,將審慎容錯納入監管框架,旨在促進人工智能技術的快速發展與實際應用。
2.厘定發展與治理的倫理方法
建立健全生成式人工智能治理體系,需要創新倫理方法。《暫行辦法》創設了發展與治理的倫理三方法。
第一,明晰倫理規范。倫理規范是技術治理的重要方法。目前我國技術法律法規中都有明確的倫理規范治理條款。例如,《中華人民共和國科學技術進步法》第五十一條規定“建立和完善科研誠信、科技倫理管理制度”,第六十七條規定“在各類科學技術活動中遵守學術和倫理規范”。《中華人民共和國基本醫療衛生與健康促進法》第五十四條規定“醫療衛生人員應當遵循醫學科學規律,遵守有關臨床診療技術規范和各項操作規范以及醫學倫理規范”。《中華人民共和國生物安全法》第三十四條規定“從事生物技術研究、開發與應用活動,應當符合倫理原則”。此外,《中華人民共和國個人信息保護法》等都有明確的倫理規范治理的具體條款。《暫行辦法》明確規定了五大倫理規范:堅持社會主義核心價值觀,維護政治安全;堅持公平公正,防止產生歧視;尊重知識產權,避免不正當競爭;提倡善意使用,尊重他人合法權益;提升服務的透明度,提高生成內容的準確性和可靠性等。這些規范兼具倫理規范和法律規范兩重屬性。
第二,推動自由探索。自由探索就是不事先設定目標,自由探究事物的本質和規律。亞里士多德認為,科學和哲學起源于驚異。黨和國家一直鼓勵自由探索式研究和非共識創新研究。在新一輪科技革命與產業變革的醞釀演變期,新一代人工智能正在重建科學研究的范式,自由探索之火被點燃。2018 年印發的《國務院關于全面加強基礎科學研究的若干意見》指出,要“尊重科學研究靈感瞬間性、方式隨意性、路徑不確定性的特點,營造有利于創新的環境和文化,鼓勵科學家自由暢想、大膽假設、認真求證”,通過激發好奇心和求知欲,引導科研聚焦未知的問題,為人們提供一個充滿探索精神的人文環境。《暫行辦法》提出,建立應用生態體系,創新應用不設立限制措施,為創新應用提供制度保障。在生成式人工智能推廣應用、算力資源的協同共享以及算力資源利用效能的提升等方面,《暫行辦法》鼓勵支持自由探索的力度很大。
第三,正確行權用權。為了預防預訓練語料庫代表性不足導致價值觀偏差,標注數據質量參差不齊引發生成毒害內容,數據集時效性偏差引發可信度危機,《暫行辦法》提出,服務者與使用者應正確行權用權,并依據上位法對開展數據服務和應用劃定“紅線”。其包括:(1)訓練數據處理活動要合規。訓練數據處理包括預訓練、優化訓練等活動,其數據和基礎模型來源要合法,不得侵害知識產權,使用個人信息應知情同意,確保訓練數據的真實性、準確性、客觀性、多樣性。(2)進行數據標注活動要合規。人工智能是大量數據教導訓練而成的,數據標注質量決定機器智能化的水平。隨著AI 基礎數據服務市場的擴大,數據標注需求量將呈井噴式增長。《暫行辦法》要求標注者應當制定清晰、具體、可操作的標注規則,積極開展數據標注質量評估(即抽樣核驗標注內容的準確性)。
3.《暫行辦法》可能存在的不足
2023 年5 月,七國集團(G7)領導人峰會呼吁制定AI 國際技術標準。為確保這項強大技術的可靠性和可管理性,美國發布了41 種生成式人工智能算法清單,清單上的算法在廣泛使用之前必須獲得許可。歐盟也制定了《人工智能法案》,為人工智能應用設置“護欄”。
作為世界上第一部規范生成式人工智能的單行法規,《暫行辦法》及時跟上新技術發展的治理步伐,對克服“科林格里奇困境”進行了有益的新探索。當然,《暫行辦法》可能存在以下不足:一是缺乏專門預防算法偏見的具體規定,因此需要結合生成式人工智能運行的現實需求進行修改;二是對生成式人工智能應用場景和使用范圍沒有作出明確的規定;三是對提供“具有輿論屬性或者社會動員能力的生成式人工智能服務”是一種概括性要求,未能作出具體的規定。技術發展既要立足現實,也要著眼于未來。所以,《暫行辦法》只是“暫行”的,必要時可以進行修改。
三、技術善治:生成式人工智能發展與治理的實踐邏輯
生成式人工智能的成長與應用具有獨特規律,沒有現成的經驗可以借鑒,探索更加有效、務實的新一代人工智能治理路徑成為時代之需。生成式人工智能具有新穎性、連貫性、不確定性、模糊性與增長快速、影響重大等特點。我們認為,當前構建生成式人工智能技術治理的實踐邏輯,要解決好“以社會主義核心價值觀為引領”“質量度統一”“敏捷治理”等突出問題。
1.治理目標要更加突出“以社會主義核心價值觀為引領”
(1)“安全偏好”的價值引領。社會主義核心價值觀在國家層面上首要強調“富強”。國家安全是國家富強的根基。生成式人工智能是影響和塑造國家安全的核心變量,它一方面給我們帶來巨大福利,另一方面也可能給國家安全帶來極大風險,有效預防其風險是確保安全的關鍵。鑒于國外技術治理經驗教訓,尤其是當前大國之間博弈加劇,生成式人工智能技術治理應當從一開始就要受到高度重視。“安全”,尤其是從國家安全與公共安全角度而言,應該成為生成式人工智能發展與治理的首要關切。
(2)公平公正的價值訴求。社會主義核心價值觀在社會層面提出了“平等”和“公正”的要求。從實踐層面看,人工智能所生成的內容可能帶有歧視性,如果不加以規范治理,將會導致其生成的歧視性內容大范圍擴散。AI 內容上的偏見與歧視,在本質上是訓練數據的缺陷,即用來訓練人工智能的數據本身存在偏見,導致產生偏見與歧視的結果,這就意味著必須對數據和算法加以規范。《暫行辦法》針對生成式人工智能服務的全過程,包括訓練數據的選擇、模型的生成和優化,規定了防止產生歧視性的內容,體現了社會主義核心價值觀“平等”和“公正”理念的引領作用。
(3)誠實信用的價值導向。社會主義核心價值觀在公民價值取向層面提出了“誠信”要求。生成式AI 對“誠信”價值觀提出新挑戰。生成式人工智能的技術基礎缺乏透明度,生成的內容缺乏對數據的引用,容易造成剽竊和知識產權糾紛;技術的非誠信使用,可能導致研發人員把生成的內容簡單地當作自己的研究成果,抑制了技術創新;生成的內容無法產生創造性內容,其真實性和可靠性使人質疑;生成的數據、文本、圖像、代碼、視頻極易引發論文代寫、洗稿等學術不端行為。要加強誠信價值觀建設,一方面,以識別和鑒定“AI生成內容”為抓手和依據,鼓勵研發“AI生成內容”的檢測工具進行真偽識別,如斯坦福大學開發了“DetectGPT”的論文檢測工具,普林斯頓大學研發了專門針對ChatGPT 生成內容的檢測工具——“GPT 歸零”(GPTZero)。更為簡便的方法是給AI 內容加水印。另一方面,以自律為根本,引導服務者和使用者合理使用“AI 生成內容”。加強服務者和使用者的自律意識是根本。
2.治理架構要更加凸顯“質量度統一”
質與量的統一就是度。技術治理的質體現了一定的量,治理的量體現了一定的質。推進新一代人工智能的發展,走向技術善治,建立合理治理架構,必須實現技術治理過程中質量度的高度統一。
深入把握技術治理的質。判斷技術治理好壞的標準有生產力標準和倫理標準。從前者看,科學技術是第一生產力,判斷技術治理的質,要看技術治理是否真正引導和推動技術本身的健康發展,是否推進了社會的進步。如果是“正向”推進,這種技術治理就是善的。如果一種技術治理措施阻礙了技術進步與生產力發展,這種治理是得不到倫理上的辯護的,就是技術“惡治”。從后者看,如果一種技術治理符合社會公認的道德倫理價值準則,堅持科技以人為本,并兼顧了國家歷史文化、傳統習慣,那么這種技術治理就是善的,否則也是技術“惡治”。人工智能的極度復雜性和高度的不確定性客觀上要求優化匹配的治理工具體系,以便提升治理的針對性和有效性。人工智能的治理工具有程序性工具、主體性工具、規則性工具三類。人工智能發展應用的特殊規律,客觀上需要融合上述三種治理工具加以有效應對。程序性工具需要事前對人工智能產品的性質與功能提出準入性要求,對應用場景作出“負面清單”式要求;事中對人工智能產品正常功能運作、潛在風險的識別消除、人為干涉或終止措施等做好應對與處理;事后圍繞責任界定、侵權行為、違規處置、救濟機制等展開。主體性工具需要明確界定政府、第三方機構、企業以及社會等四類主體的治理權限與責任。就當前而言,中央政府需要承擔頂層設計、試點安排、監督指導以及國際對話等職責,而地方政府則更多承擔屬地監管、系統備案等操作性職責。規則性工具需要以數據、算法、應用環境為切入點并提出相應治理要求。新一代人工智能技術需要從數據生命周期視角,對數據采集與存儲、傳輸與使用、跨境流動等各個環節都提出監管要求,需要對算法目標、算法備案、算法應用限制、應急處理等方面的挑戰進行應對。就人工智能產品應用環境而言,需要為人工智能產品設置適宜的硬件要求(如自動駕駛汽車行駛的道路環境),對系統使用者資質能力的合理要求,以及對應用軟件、網聯通信等配套保障的現實要求等。
精準把握技術治理的量。技術治理過程中存在量的問題。技術治理的對象、手段與方法都是一個變量。從治理對象上看,新一代人工智能技術本身是發展變化的。隨著大數據、算法、算力等的迭代,人工智能的發展呈螺旋式上升,新興技術逐漸應用到各個領域。因而,人工智能治理要以全數據治理理念促進全范圍、全領域的治理,做到“一個都不能少”,大力拓展人工智能治理的范圍、領域等,使人工智能治理從關注部分對象轉變為關注全體對象。比如將人工智能技術涉獵范圍內所有主體、所有相關對象、所有社會事務均納入治理視野之中,依托大數據技術進行統籌、整合、調配,實現全域的有效治理。從治理手段方法上看,主要依靠政策、法律法規、倫理規范、行業標準等進行治理。迄今為止有關新一代人工智能技術的治理規范(法律法規、政策)數量眾多(見表3)。目前地方性的關于新一代人工智能技術的規范已經出臺或正在制定之中。
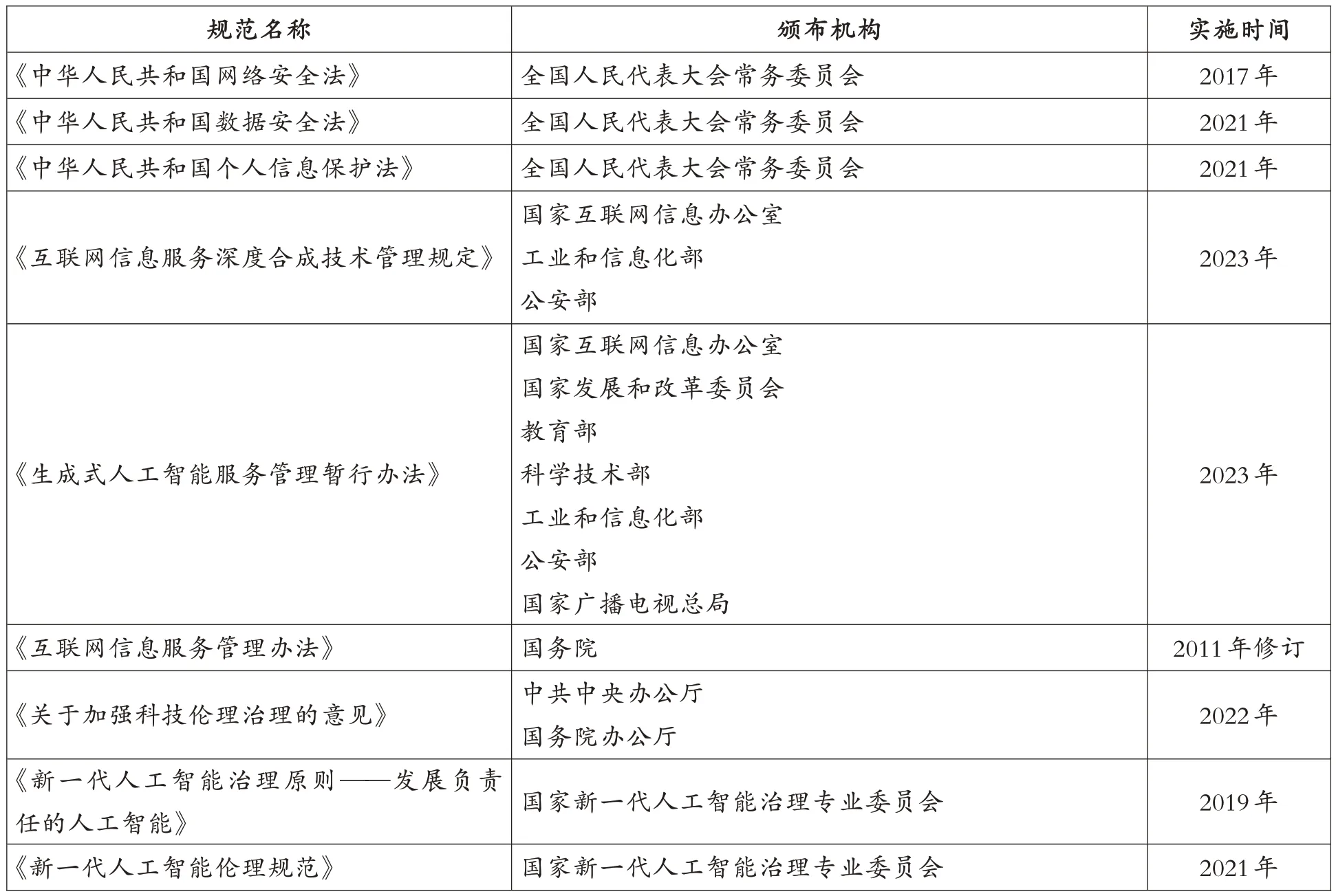
表3 新一代人工智能技術的治理規范
實現技術治理質量度的統一。技術治理的關鍵是在不確定性中尋找“合理限度”的確定性。這種“合理限度”確定性一方面表現在:有關人工智能的具體法律法規、政策規定體現并服務于技術治理。如網絡安全法、數據安全法、個人信息保護法是全國人大常委會制定的,對人工智能治理而言是宏觀層面的一般性治理約束,缺乏有效的針對性。這就需要深度合成技術管理規定、互聯網信息服務管理辦法、新一代人工智能治理原則與倫理規范等來設定具體的治理標準,精準施策,對癥下藥。人工智能法律法規的一般性規定與特殊性約束相互配合,共同實現人工智能治理的質量度的統一。另一方面,“合理限度”確定性還表現在合理的治理原則上,它是統籌質和量的關鍵,比如:(1)適度原則。政策與立法要適度,即政策與立法要注重質,不是數量越多越好,越嚴越好,而是管用就行。(2)均衡原則。即治理過程要保持技術發展與技術治理的均衡,人工智能現有的法律法規、政策、標準等規范,以及規范之間的相互協調配合,既要有利于技術的健康發展,又要給技術創新適宜的空間,而不至于制約技術進步。(3)適當超前。將國家中長期計劃,尤其是建設科技強國遠景規劃作為制定法律法規與政策的依據,立足現實、服務長遠,推進新一代人工智能服務國家戰略。
3.治理實踐要更加重視“敏捷治理”
生成式人工智能具有顛覆性和革命性,留給決策者和治理者理解其潛在用途和影響的時間大為縮短。傳統治理方式是一種外在的事后規范性治理,無法解決人工智能的不確定性[15](38)。科學已造成的新的不確定性,我們根本無法借鑒以往的經驗來解決。因此,對生成式人工智能的治理,必須轉變觀念,采取更加“敏捷”的治理方法。
敏捷治理是治理的基本途徑[16](49)。它具有區別于傳統治理的全面性、適應性、靈活性和包容性特征,能夠更好地避免傳統治理的“相對片面性”“弱適應性”“滯后性”“弱包容性”的弱點(見表4),能有效彌合技術創新發展與治理能力提升之間的空隙。敏捷治理提供了一種更靈活、適應性更強的方法來進行實時學習,將原則和政策結合,可以在特定情況下有效解決問題,而不會破壞潛在的創新。

表4 敏捷治理與傳統治理的區別
2018 年世界經濟論壇白皮書提出了“敏捷治理”概念。目前,我國新一代人工智能敏捷治理已經從理論走進現實。2019 年我國《新一代人工智能治理原則——發展負責任的人工智能》把“敏捷治理”確立為治理的八大原則之一。2021 年《新一代人工智能倫理規范》提出“推動敏捷治理”。2022 年《關于加強科技倫理治理的意見》提出了“敏捷治理”的治理要求。當前,生成式人工智能的治理,要秉持“敏捷治理”的要求,突出對生成式人工智能的風險預警與跟蹤研判,及時動態調整治理方式和治理規范,快速靈活應對倫理挑戰。在基本理念上,生成式人工智能技術治理應避免一刀切式的、一蹴而就的治理方式,按照“急用先立、成熟先立”的原則,遵循包容審慎、敏捷靈活、鼓勵創新等治理理念,兼顧不同應用場景可能存在的負面影響,大力采用敏捷治理方案。結合敏捷治理的四個特性,構建我國生成式人工智能治理路徑,具體而言包括:基于敏捷治理的全面性,構建“基礎模型—專業模型—服務應用”的全面性治理格局;基于敏捷治理的適應性,構建事前預防與事后應對相結合的適應性治理機制;基于敏捷治理的靈活性,構建“技術—法律”相結合的靈活性治理工具[17](141);基于敏捷治理的包容性,構建“審慎—彈性”相結合的倫理治理工具。唯有如此,才能更好推動新一代人工智能向善向上發展。
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中國核電(2021年3期)2021-08-13 08:56:36
家庭影院技術(2018年11期)2019-01-21 02:20:52
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
華人時刊(2017年21期)2018-01-31 02:24:01
小康(2017年16期)2017-06-07 09:00:59
北方交通(2016年12期)2017-01-15 13:52:53
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
