未知二進制協議的報文分割方法
2023-11-22 08:23:24李曉輝朱承才
計算機技術與發展 2023年11期
徐 魁,海 洋,李曉輝,朱承才,陶 軍,3
(1.寶雞市公安局通信處,陜西 寶雞 721014;2.東南大學 網絡空間安全學院,江蘇 南京 211189;3.計算機網絡和信息集成教育部重點實驗室(東南大學),江蘇 南京 211189)
0 引 言
隨著互聯網技術的不斷發展,保障通信網絡的安全愈發重要。二進制協議因其非侵入性的特點以及在網絡中的廣泛應用成為了當前研究的熱點。
協議逆向工程的關鍵在于對協議報文如何分段。對未知規范的通信需要通過監控網絡流量等方法對其進行逆向工程[1]。靜態流量逆向工程的應用包括僵尸網絡分析[2]、蜜罐設置[2-3]、模糊漏洞測試[4]和網絡自動建模[5]。2004年,Beddoe[6]和Rauch提出了首個解決方案:序列比對。此后ProDecoder[7]和PRISMA[2]發現自然語言處理在使用ASCII編碼關鍵字來構造消息的協議上運行良好。推斷消息格式往往需要大量消息,然而多序列比對會導致指數復雜性[8],當數據量巨大時性能變差。另一方面,長可變消息可能出現對齊偏差,從而導致字段邊界誤判。因此,為了聚類消息類型或對齊字段序列,就需要進行消息字段劃分。ScriptGen[3]、Discoverer[9]和Netzob使用序列對齊來推斷消息格式。FieldHunter[10-11]使用字段類型的特征化等方法進行格式推斷。張蔚瑤等人使用協議特征庫對未知協議進行逆向分析[12]。此外,研究人員提出了三類創新性的協議報文分段方法:基于信息論投票的報文分段、基于決策模型的報文分段[13]與基于報文內部結構的報文分段。Zhang等人[14]提出協議關鍵詞提取方法ProWord,首次將無監督專家投票算法應用于流量分析。Sun等人[15]引入統計信息,從信息論的角度提出協議報文分段算法ProSeg。IPART[16]在專家投票算法基礎上又加入語義識別,對報文分段點進行二次確認。Jiang等人[17]提出基于相鄰字節距離的報文分段算法ABInfer,采用最近鄰聚類算法迭代將相鄰字節進行合并,然后對字段進行劃分。
協議字段劃分的過程可以抽象為報文字節序列中字段邊界的決策問題。黎敏等人[18]將字段劃分過程看成馬爾可夫過程,在此基礎上使用隱半馬爾可夫模型(Hidden Semi-Markov Models,HSMM)[19]進行字段劃分。Cai等人[20]同樣使用隱半馬爾可夫模型進行求解,對黎敏的工作進行了優化。Tao等人[21]使用貝葉斯決策模型進行協議逆向分析,提出了對二進制協議進行字段劃分的方法PRE-Bin。
協議報文的部分研究以比特為粒度,挖掘比特間的表征關系。Kleber等人[22]研究協議報文的內部結構,提出了一種新穎的報文分段方法NEMESYS。Marchetti等人[23]通過幅度序列和位翻轉頻率尋找報文分段點,提出汽車通信數據幀分段方法READ。
基于上述情況,該文提出了一種用于未知二進制協議逆向工程的協議字段劃分方案HV。主要工作如下所述:
首先,提出字節翻轉率的概念并將其應用到消息分析。從垂直分析的角度,通過對比相鄰消息的結構,找到該二進制協議在消息結構上的共性。其次,從水平分析的角度探究單條消息的內部結構。基于第一數字定律等方法初步找到消息邊界;使用路徑搜索等算法找到更多候選邊界點,從而優化消息字段劃分的結果。接著,創新性地聯合水平以及垂直分析進行消息字段的劃分,設計用于未知二進制協議字段劃分方案HV。對從上述得到的消息分段點進行評估、投票等決策,得到最終結果。最后,引入格式匹配分數(Format Match Score,FMS)用于量化特定消息的格式推斷質量。
1 算法思路
1.1 基于垂直分析的報文分段
此階段探究的是消息之間所呈現出的結構信息。對相鄰的消息進行比較,得出相關的統計信息。
1.1.1 字節翻轉率與位翻轉率
一般工業協議粒度為字節,將消息載荷以字節形式展開,使用字節翻轉率進行評估。字節翻轉率定義如下:
(1)
其中,BFi表示第i個字節的翻轉率,M是所有消息集合,mj是M集合中第j條消息,mj(i)是第j條消息的第i個字節。⊕是異或操作。|M|是消息集合中的消息數量。這一步得到一個含有n個元素的數組,每個元素代表某一字節處的翻轉率,n是消息載荷字節的長度。字節翻轉率獨立于同一消息中鄰近的字節,只與鄰近的消息有關。過程如算法1所描述。
同理,可以將消息載荷以比特形式展開,得到位翻轉率。定義如下:
(2)
位翻轉率處理的粒度是比特位。
1.1.2 字段劃分
對消息進行翻轉率的計算后可以得到字節翻轉率數組BF以及位翻轉率數組bF。接著進行字段劃分。首先遍歷字節翻轉率數組,查找符合如下條件之一的字節位置:
(1)該位置字節的翻轉率為局部極值點,即滿足:BFi≥BFi-1and BFi≥BFi+1。
(2)該位置字節與相鄰的位置字節都具有一個較高的翻轉率,即滿足:
BFi≥Φ and (BFi-1≥Φ or BFi+1≥Φ)。
(3)該位置字節的翻轉率為0,即BFi=0。
將符合條件的字節位置標記為字段邊界可疑點。經過上述處理得到一個邊界列表b。將字節翻轉率為0的字節位標記為邊界。根據翻轉率的定義,經常變化的字段翻轉率會偏大,反之則偏小。
位翻轉率數組是一個輔助數組。對于計數字段,翻轉率會較大。計數字段低位的字節翻轉率為1,相應的最低比特位翻轉率也為1。并且計數字段從最低位到最高位翻轉率應是遞減的,每一位的翻轉率是下一位的兩倍。當字節翻轉率為1后可利用位翻轉率數組進行確認。當認定某一字節為計數字段時,需要查看該字節的后一字節以及前一字節。這一過程如算法2所描述。

算法2:字段劃分階段二1:function divide2(BF, bF, b) :2: BLen len(BF);3: bLen len(bF);4: For i In range(0, BLen) :5: IF BFi = 1 :6: IF detectLeftMatch(bF, i) :7: b.append((i-2, BFi-2));8: b.erase(i-1);9: ELIF detectRightMatch(bF, i) :10: b.append((i+1, BFi+1));11: b.erase(i);12: return b;
通過算法2可以得到垂直分析的邊界列表b。該階段是在尋找同一種協議的所有消息中共有部分的統計特性。在進行消息分段時需要取一個固定的長度進行消息間比對。具體如何取值下文有所說明。
1.2 基于水平分析的報文分段
協議字段劃分的過程可以抽象為報文字節序列中字段邊界的決策問題。因此可以使用路徑搜索算法從水平分析的角度對消息的內部結構進行分段。在此之前需要進行分支度量以及約束條件的定義。
1.2.1 分支度量的定義及第一數字定律擴展
第一數字定律,指所有自然隨機變量只要樣本空間足夠大,每一樣本首位數字為1至9,各數字的概率在一定范圍內具有穩定性。以1為首位數字的數的出現概率約為總數的三成。總結而言,越大的數以它為首幾位的數出現的概率就越低。
在十進制中,以n開頭的數出現的幾率為:
(3)
然而二進制協議中對以“0”開頭的字節也會保留,因此可以擴展為:
(4)
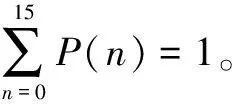
分支度量在定義時主要基于第一數字定律,邊界評估指標如式(5)所示:
(5)
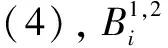
1.2.2 約束條件
約束條件控制節點之間是否可達。構造約束條件時:首先字段長度是有限的,一般不超過4個字節,個別字段會達到8字節,多數情況下為偶數或“1”。其次,字段是單向的,即字段是從左往右,不存在從右往左的。評估指標如式(6)(7)所示:
(6)
(7)
式(6)中,di,j表示第i個候選邊界和第j個候選邊界之間的距離。根據最短路徑搜索的思想,為使最佳路徑的路徑權值和最小,該式使用score的倒數作為分支度量。式(7)中,wk是一個距離權重,其中k是整數,表示兩個候選邊界之間相隔的字節數。當k=1,2,4時,表示j>i并且字段長度合理,使用平方增量;當k≤0(從右往左)或者k=3(3個字節長度的字段一般不常見)或者k>4(字段長度太長)時,權重為負無窮,即不可達。
1.2.3 最佳路徑搜索算法
根據分支度量和約束條件生成候選邊界有向圖,利用最佳路徑搜索算法從有向圖中找到與真實格式關鍵詞邊界最接近的一條路徑作為最終格式關鍵詞的邊界推斷結果。目標函數如式(8)所示:
(8)
其中,Trace是所有可能的路徑集合,tracek是集合的第k條路徑。
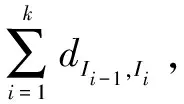
最佳路徑搜索算法應用于關鍵詞邊界選擇,最終目標是尋找一條從第一個候選邊界點到最后一個候選邊界點權值之和最小或最大的路徑。
1.3 聯合垂直分析和水平分析的消息分段
1.3.1 劃分方案
消息的水平分析通過消息內部所蘊含的信息對字段進行了劃分。消息的垂直分析通過消息序列之間所蘊含的信息對字段進行了劃分。這兩種方案各自的特點如表1所示。

表1 水平與垂直分析優缺點
該文將這兩種方式進行結合,設計了一種創新性的消息字段劃分方案HV。
對于水平分析,分析的是單條消息;結合垂直分析時要將分析對象由單條消息轉為消息集合。
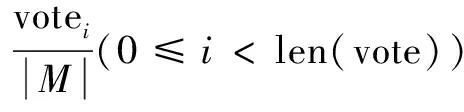
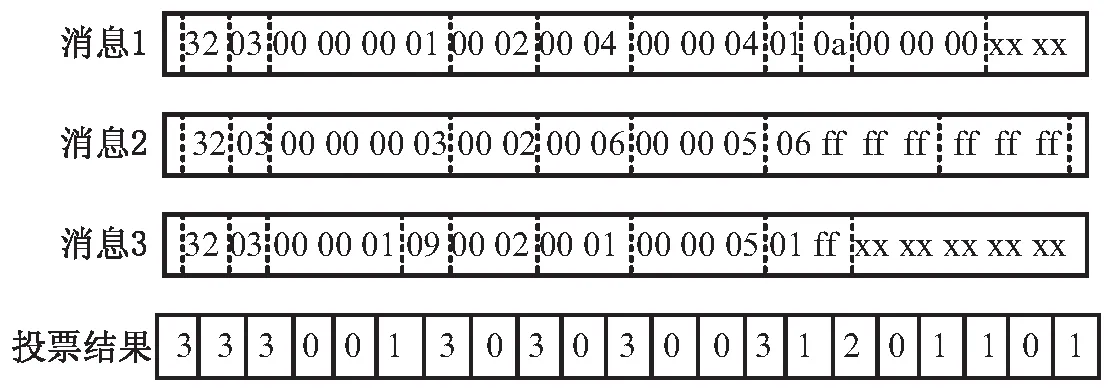
圖1 投票機制執行過程
接下來,結合垂直分析與水平分析的結果。設水平分析的字段邊界劃分結果為Ih={ih,1,ih,2,…},垂直分析的字段邊界劃分結果為Iv={iv,1,iv,2,…},最終的結果取兩者的并集,即I=Ih∪Iv。
1.3.2 方案優化
為避免在data字段進行消息字段劃分對結果產生干擾,需要對消息進行截尾處理。這里使用平均類內距離作為評估指標,如式(9)所示:
(9)
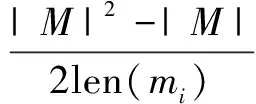
接著對消息作截尾處理,取不同長度的消息計算平均類內距離,取平均類內距離驟增時的消息長度lenavg作為截尾點候選點。同時考慮所有消息中最短的消息長度lenmin。將lenavg的初始值設為所有消息的長度最小值,再設一個下限lenlow,在該文中設為10。最終的截尾長度lenfinal取值如下:
lenfinal=min{lenmin,max{lenavg,lenlow}}
(10)
1.4 格式匹配分數FMS
引入格式匹配分數FMS作為字段劃分質量的度量。該測度主要考慮三個方面:(1)正確識別字段的比率;(2)區分移位字段邊界和完全錯誤字段;(3)量化不同字段邊界推斷的遞減效用。
FMS為消息的每一個真實邊界rk定義了范圍,一個邊界的范圍起始點為前一個邊界rk-1和前一邊界rk的中間點,范圍結束點為當前邊界rk和后一邊界rk+1的中間點。消息開始處r0和消息結束處r|R|不分配邊界范圍。因此,當推斷邊界il滿足式(11)時,就表明il屬于rk的范圍。
(11)
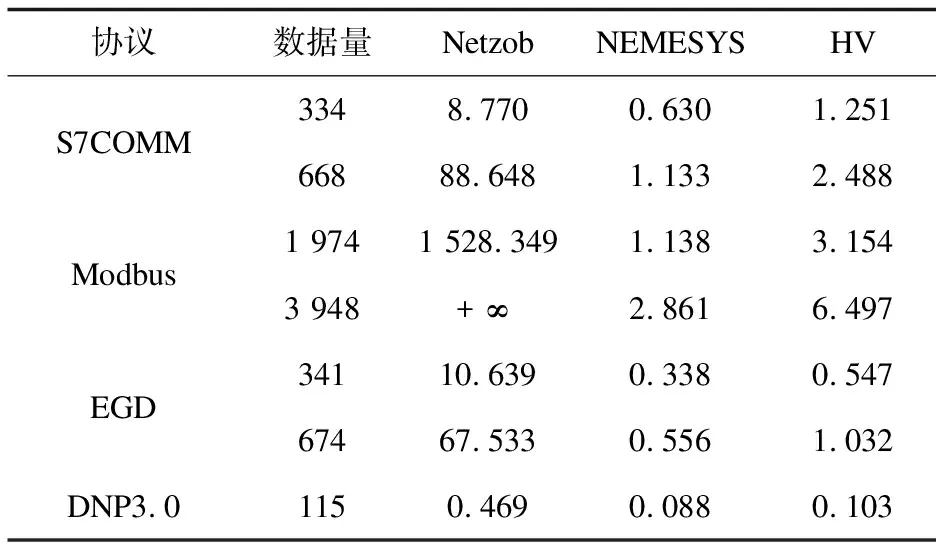
式中,il表示第l個推斷的字段邊界的下標索引,0 δr=argmin{|i-r|}-r (12) 將空集上的min運算符定義為minφ=-∞。可知δr有四種情況:①δr=-∞:對于真實邊界r,沒有與之匹配的推斷結果。②δr=0:推斷邊界與真實邊界完全吻合。③-∞<δr<0:推斷邊界在真實邊界的左邊,偏移量為δr字節。④δr>0:推斷邊界在真實邊界的右邊,偏移量為δr字節。 模式匹配分數的定義如式(13)所示。 (13) 最后,對整個式子進行標準化,使得FMS的值在0到1之間。推斷質量越高,FMS越大。 實驗樣本為668條S7COMM協議數據、115條DNP3.0協議數據、3 948條Modbus協議數據和674條EGD協議數據。S7COMM協議使用TPKT和COPT封裝PDU,DNP3.0協議較復雜,Modbus協議較簡單,EGD協議含有時間戳等字段。 由于實驗無需對不同協議的字段劃分結果進行橫向比較,因此并未保持協議數據的數據量一致。實驗中投票時的Θ設置為0.8,FMS的γ設置為2,使用tshark對消息解析出的信息作為基準。 圖2展示了四種協議截尾后的投票結果。可見劃分結果的有效字段較多,側面印證截尾的必要性。 該階段對字段邊界的推導初具成效,尤其是EGD協議。這是因為EGD協議主要由IP地址和時間戳字段等常見字段組成。這些字段在投票前已經被事先定義的字段識別方法識別了。 圖2 投票結果 在垂直分析時需要計算位翻轉率,圖3展示了這四種協議的位翻轉率。可見字段邊界左邊的比特位的翻轉率普遍偏高,所以翻轉率高的位置附近或者翻轉率驟降點可以判定為字段邊界。 圖3 位翻轉率 實驗使用Netzob以及NEMESYS作為對比方法,如圖4所示。(a)描述的是S7COMM協議的字段劃分的質量,可見隨著數據量的增加三者的質量變化都較小。(b)描述的是Modbus字段劃分的質量,其中Netzob推測的質量最高。(c)描述的是DNP3.0字段劃分的質量。可見Netzob的質量較差。因為實驗中DNP3.0協議的數據量太少,Netzob可挖掘的統計信息太少。且NEMESYS和HV都有較大起伏,這是因為NEMESYS只考慮單條消息,依賴于每條消息的取值,所以不受樣本數增加的影響;但是HV在考慮單條消息的同時也會考慮多條消息之間的比較,因此隨著相似樣本的增加會提高推測質量。(d)描述的是EGD字段的劃分質量,清晰地觀察到HV的推導質量極高且穩定,達到了0.725,這是因為EGD協議中有幾個字段的語義被HV事先定義了。 圖4 FMS測度下的字段劃分質量 圖5展示了HV與Netzob和NEMESYS在所有消息上的推導質量的分布情況。從圖中可以看出HV除了在Modbus協議上的推測質量不如Netzob,其余情況下的推測質量均高于Netzob和NEMESYS,而且較為穩定。HV整體上是優于Netzob以及NEMESYS的。 圖5 FMS分布情況 表2列出了三種方法的運行時間。其中+∞表示在30分鐘內無法求解。可以看出,三種方法中Netzob的運行時間最長,甚至當數據集到達一定數量時,可能無法求解。這是由于Netzob和大多數協議逆向算法相同,使用了全局序列比對算法,導致具有指數級別的時間復雜度。當對最大長度為l的k條消息進行比對時,復雜度為O(lk)。從中還可以看出,NEMESYS運行時間最短,這是因為NEMESYS不需要將數據集中的消息進行任何比較,它只與消息的長度以及數量相關,導致它具有極低的線性復雜度。同樣,HV運行時間也較短,并且運行時間也幾乎是線性的。以Modbus為例,在分析1 974條消息時,NEMESYS與HV都是在幾秒內完成,而Netzob使用的時間是HV的500倍。 表2 執行時間 s 圖5說明邊界推斷的質量只有在Modbus協議上是Netzob>HV>NEMESYS;而S7COMM,DNP3.0和EGD協議上均為HV>NEMESYS>Netzob。從表2可知,Netzob的執行時間遠遠大于HV以及NEMESYS。而后兩者的執行時間相差無幾。因此,綜合字段劃分質量和劃分時間,HV總體上是優于Netzob以及NEMESYS的,它有著較穩定的推斷質量。HV的執行時間幾乎是線性的,當數據量較大時也能快速處理,而Netzob中的序列比對的復雜度是指數級別,當數據到達一定量就無法求解。 推斷二進制協議的格式結構對于二進制協議分析十分重要。目前的協議逆向分析對于文本協議的研究較深,針對二進制協議進行逆向分析仍存在難點。字段劃分是協議逆向過程中的前置步驟,協議逆向的準確度很大程度依賴于字段劃分的質量。為解決上述問題,該文提出了一種新穎的較簡單的未知二進制協議字段劃分方法HV。HV首先單獨分析每一條消息的內部結構;接著通過計算相鄰消息之間的字節以及位翻轉率進行字段劃分;最后結合兩次分段得到最終的字段劃分結果。其他需要成對比較消息的方法復雜度在指數級別,HV幾乎只需要線性復雜度。并且與其它方案相比,此方案在推斷字段邊界的質量上也有著不錯的表現。該文還定義了格式匹配分數來衡量字段劃分的質量,相比傳統的衡量指標,格式匹配分數更加適用于字段劃分。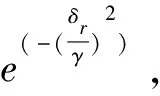
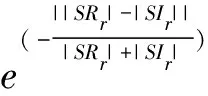
2 實 驗
2.1 實驗設置
2.2 實驗結果及性能分析
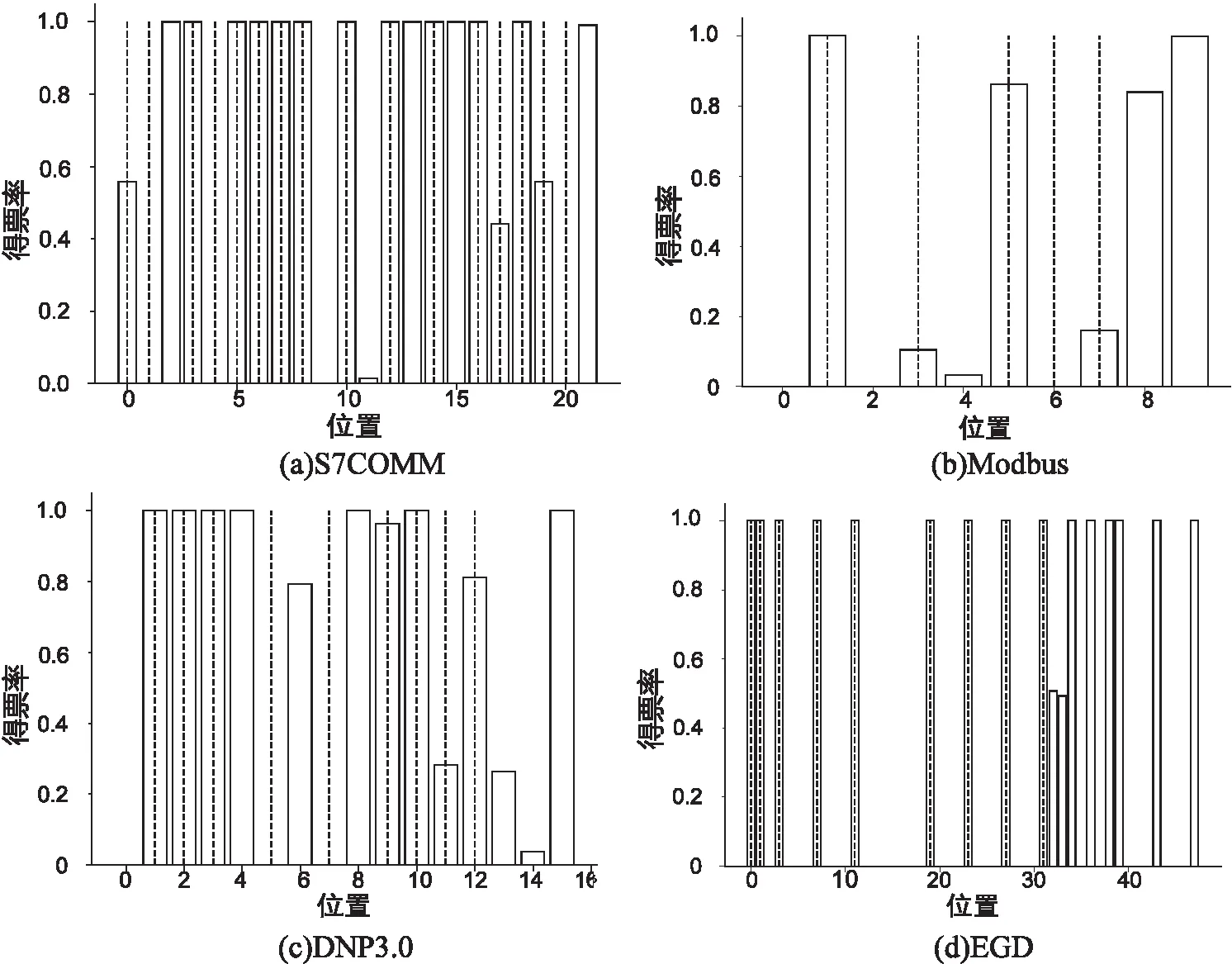
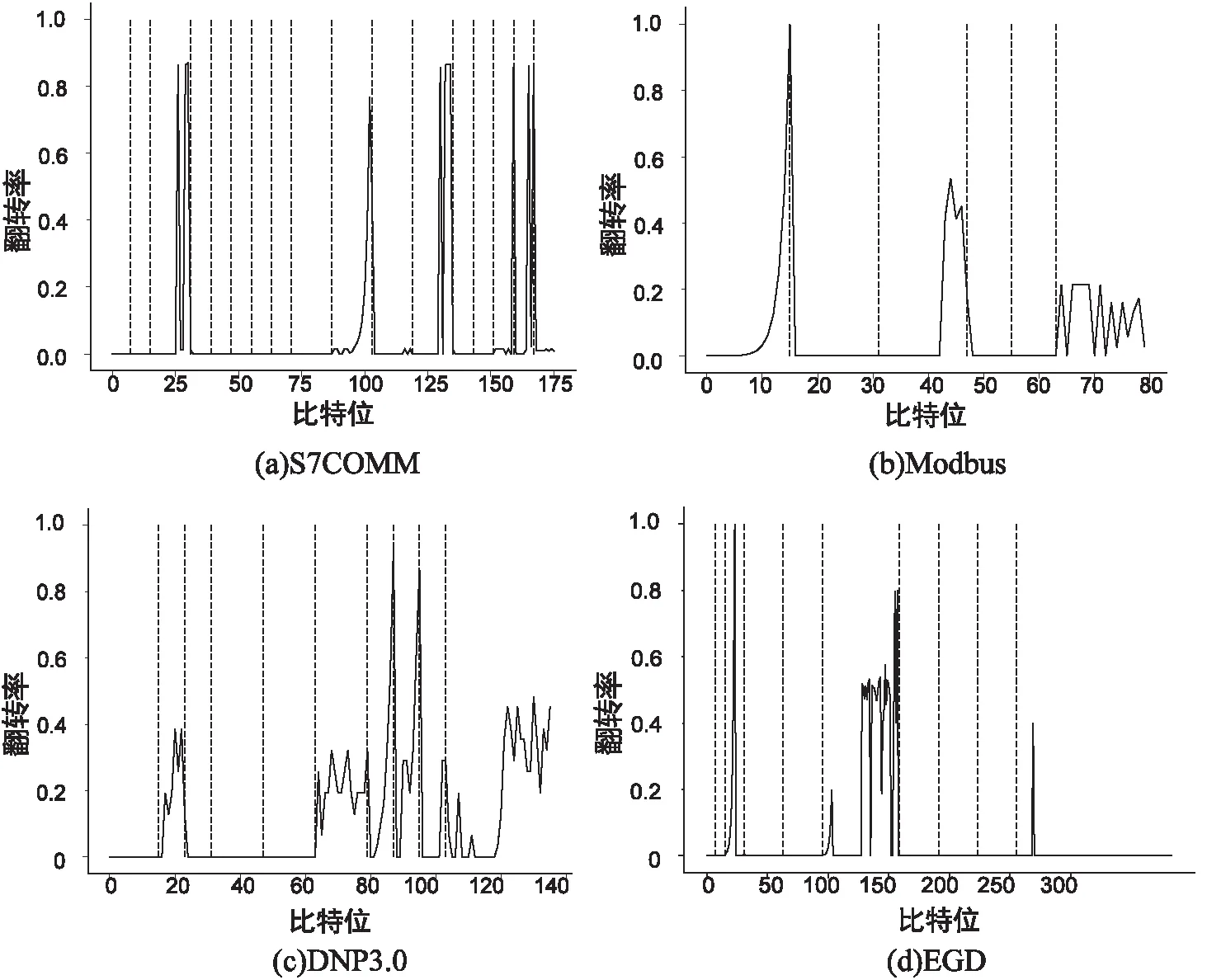
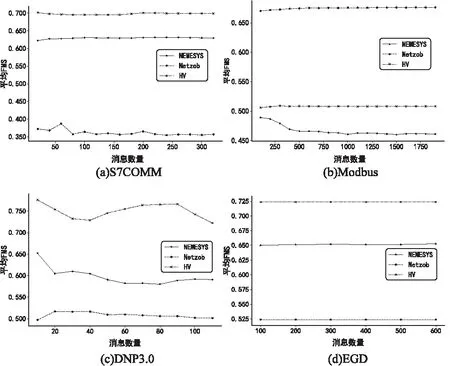
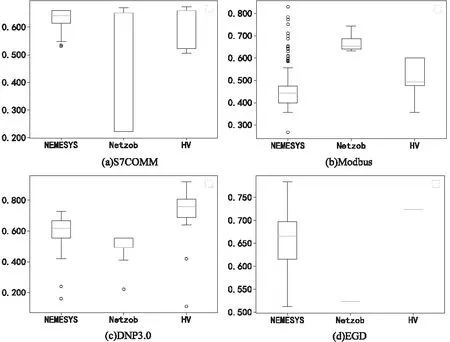
3 結束語
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
電子制作(2018年18期)2018-11-14 01:48:24
產品可靠性報告(2017年7期)2017-09-05 09:49:12
山東工業技術(2016年15期)2016-12-01 05:31:22
汽車觀察(2016年3期)2016-02-28 13:16:26
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
中國質量與標準導報(2014年1期)2014-02-28 22:21:28
