基于類間相似性的聚類集成方法
2023-11-22 08:23:28張棟超蔡江輝楊海峰鄭愛宇
計算機技術與發展 2023年11期
關鍵詞:方法
張棟超,蔡江輝,楊海峰,鄭愛宇
(太原科技大學 計算機科學與技術學院,山西 太原 030024)
0 引 言
聚類是統計多元分析、數據挖掘和機器學習中的一個重要問題。聚類的目標是將一組對象分組成簇,以便同一簇中的對象與其他簇中的對象高度相似但顯著不同。在過去幾十年中,已經開發了大量聚類算法,包括分區[1]、分層[2]、基于密度[3]和基于網格[4]的聚類等。但沒有一種算法能夠處理實踐中遇到的所有聚類問題,即無法發現具有不同大小、形狀和噪聲水平的所有聚類。給定一個數據集,不同的算法通常返回不同的結果。事實上,由具有不同初始化和參數的相同算法返回的聚類結果通常是不同的。因此,用戶可能會困惑于選擇最合適的方法來解決他們的問題。集成聚類方法已成為克服這一問題的有力工具。
集成聚類是聚類的一個重要分支。聚類集成根據多個聚類結果找到一個最終的數據劃分,該劃分最大程度地共享了所有基聚類的信息。目前已經開發了幾種類型的聚類集成方法,其中基于相似性的聚類集成方法受到很多研究者的青睞。很多學者通過尋找初始對象之間的相似性來構建共協矩陣[5],然后通過該矩陣獲得最終聚類劃分。
在矩陣元素的相似性計算過程中,大部分研究者將基聚類信息看的同等重要,而原始對象中往往會有一些噪聲,導致基聚類結果變差,并影響了最終聚類結果,而且傳統的共協矩陣空間復雜度往往是O(n2),在數據量較大時內存占用極大。因此,該文提出了一個基于簇間相似性的聚類集成方法。首先,設計了一種基于證據積累模型的相似度計算方法,將相似度大的樣本點暫時劃分為小簇;然后,提出一種新的相似度計算方法,將劃分好的小簇作為相似矩陣的構成對象,構建相似矩陣;最后,通過對相似矩陣的切圖,形成最終的聚類劃分。
主要貢獻如下:
(1)設計了一種基于證據積累模型的相似性計算方法,有效地將初始對象形成初始簇劃分。
(2)提出一種簇間相似性計算方法,用簇來構建相似矩陣,該方法相比直接使用原始對象構建共協矩陣,大大節省了空間復雜度。
1 相關知識
目前,聚類集成有兩個重要任務:
(1)如何生成不同的基聚類并保證其多樣性;
(2)如何將多個不同的基聚類融合生成最終一致聚類。
第一個任務已經提出了幾種不同的方法,大致可以分為以下3類:
(1)使用相同的方法(參數不同)來生成基聚類。比如用k-means作為基聚類器用不同的聚類數來生成聚類集[5];隨機選擇不同的聚類中心使用k-means[6];使用不同的核參數運行譜聚類算法[7]等;
(2)運行不同類型的聚類算法以生成基本聚類。比如使用多個層次聚類和k-均值生成聚類集[8];將具有不同目標函數的多個聚類算法作為基本聚類,并將聚類集成問題轉化為多目標優化問題[9];Yu等人研究了如何整合多種類型的模糊聚類[10]等;
(3)在數據集中的不同子空間或子樣本上運行一個或多個聚類算法。比如應用bootstrap方法獲得了多個數據子集[11];使用隨機映射的方法獲得多個特征子空間[12];使用不同的核函數來描述數據[13];結合boosting和bagging的優點,提出一種新的簇集合混合采樣方法[14]等。
第二個任務開發了幾種類型的聚類集成方法,大致可以分為以下4類:
(1)成對相似性方法。利用所有數據對象兩兩之間的相似關系來聚合多個聚類。比如Fred和Jain[5]提出了一種基于證據積累的集成算法,并構造了一個相似度矩陣;Iam On等人定義了一個基于鏈接的相似度矩陣,該矩陣充分考慮了集群之間的相似度[15];Huang等人提出了一種增強的共協矩陣[16],該矩陣能夠同時捕獲聚類中的對象共現關系以及多尺度集群關系。薛紅艷等人[17]以及邵長龍等人[18]用信息熵對共協矩陣加權以達到更好的聚類效果。
(2)基于圖的方法。將基礎聚類信息表達為一個無向圖,通過圖劃分得到集合聚類。比如Strehl和Ghosh提出了3種超圖集成算法[19]:基于聚類的相似性劃分算法(CSPA)、超圖劃分算法(HGPA)和元聚類算法(MCLA)。CSPA創建一個相似圖(對象視為頂點,相似度做邊)。HGPA構建了一個超圖,其中頂點代表對象,而相同的加權超邊代表簇。MCLA生成一個圖,其中頂點代表聚類,而邊的權重反映聚類之間的相似性。Bai等人[20]提出了從基聚類中提取可信度標簽,通過聚類的關系構建形成圖,最后通過歸一化譜聚類獲得最終聚類結果。
(3)基于重標記的方法。將基本聚類信息表示為標簽向量,然后通過標簽對齊聚類。其代表性方法有硬標簽對齊和軟標簽對齊。比如將重標記問題轉化為最小成本的一對一分配問題[21];使用交替優化策略來解決軟標簽對齊問題[22];Rathore等人提出了一個有效的模糊集合框架[23],該框架使用累積一致方案來聚集模糊聚類。
(4)基于特征的聚類方法,將聚類集成問題作為分類數據的聚類。比如整合信息論和遺傳算法來尋找最一致的聚類[24];Topchyet 等人提出了一個概率框架[25],并使用EM算法來尋找共識聚類等。
除了以上4種,近年來也有部分學者提出使用加權的方法。與現有的方法不同,筆者研究的對象被指定用k-means算法做基聚類器。首先,對原始對象進行相似度計算,形成多個小簇;然后,用另一種方法計算簇與簇之間的相似度;最后,通過NCUT[26]切圖的方式得到最終聚類劃分,來實現多弱等于強的目的。
2 文中算法
2.1 相關定義
設X={X1,X2,…,Xn}是對象的集合,其中,
xi={xi1,xi2,…,xid}
d為維度,n為數據對象的個數。聚類集成方法首先要在數據集X上產生M個聚類結果,即:
∏={π1,π2,…,πM}
其中,
πh={Ch1,Ch2,…,Chl}
是第h個基聚類,Chl表示第h個基聚類的第l個簇。該文主要使用的符號如表1所示。

表1 常用符號
2.2 聚類集成方法
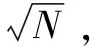
(1)
其中,vhl表示第h個基分區中第l個簇的中心點,d(xi,vhl)是目標點(xi)到聚類中心點(vhl)的歐氏距離。
基于證據積累模型,該文提出一個相似度計算方法,用來將相似度高的一些對象預先劃分為簇,隨后將剩余的相似度較低等異常點進行歸并處理。
(2)
相似度量方法如公式(2)所示,其中,
部分對象的基聚類結果如圖1所示。
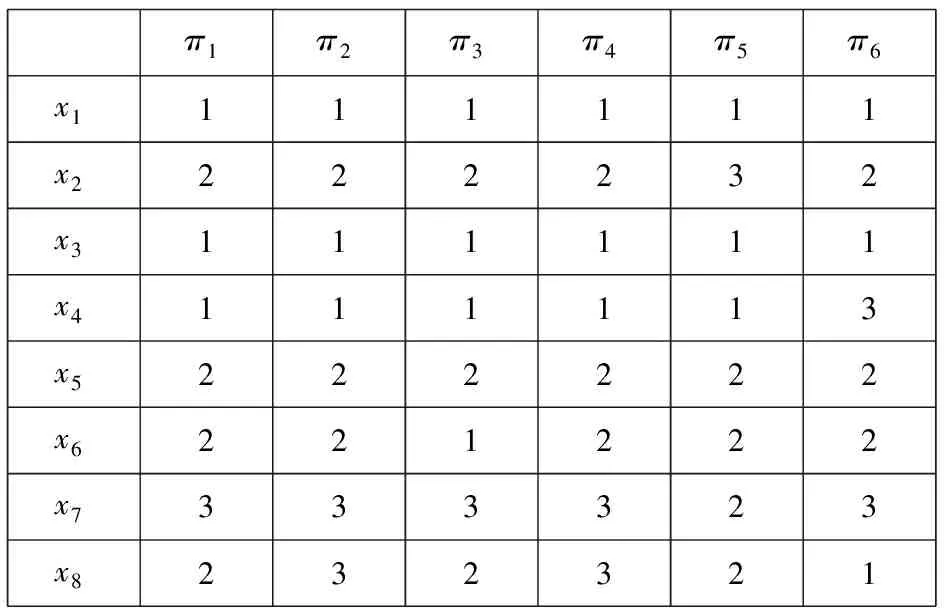
π1π2π3π4π5π6x1111111x2222232x3111111x4111113x5222222x6221222x7333323x8232321
圖1中,x1~x8是數據集中的8個對象,π1~π6是6次基聚類結果,表中元素代表x屬于第幾類。以圖1中的對象為例,通過公式(2)計算相似度得知x1與x3的相似度為1,x1與x4相似度為5/6,因此S1={x1,x3,x4}將3個對象劃分為1個簇;同理S2={x2,x5,x6},x7,x82個對象與其他對象間相似度較小,因此暫設為異常點S3={x7},S4={x8}。該過程每個對象只經過1次運算,其時間復雜度為O(N)。使用數據集(S)設置得到以下相似矩陣,如圖2所示。
2)激勵機制缺乏。雖然我國已對綠色建筑提出了各類政策,但建設單位對綠色建筑的落實的積極性不高,難以推動綠色建筑的發展。例如,政府雖然制定了鼓勵綠色建筑發展的各項策略,但是由于成本及運營維護等方面的經濟與技術問題的制約,導致其激勵作用難以發揮,使建設單位及施工方的積極性不高[2]。
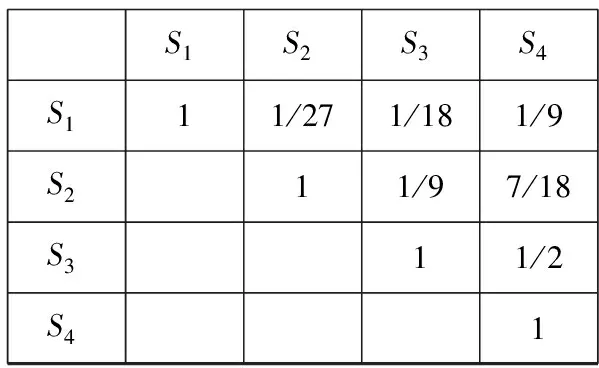
S1S2S3S4S111/271/181/9S211/97/18S311/2S41
簇間相似度計算如公式(3)所示,其中p,q為簇(S)中對象的個數。
(3)
其中,
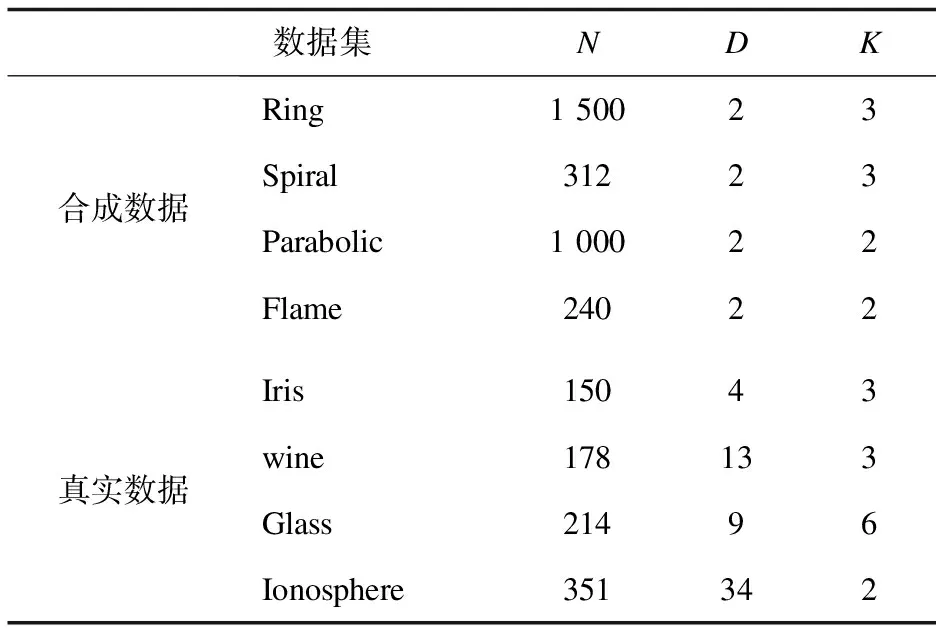
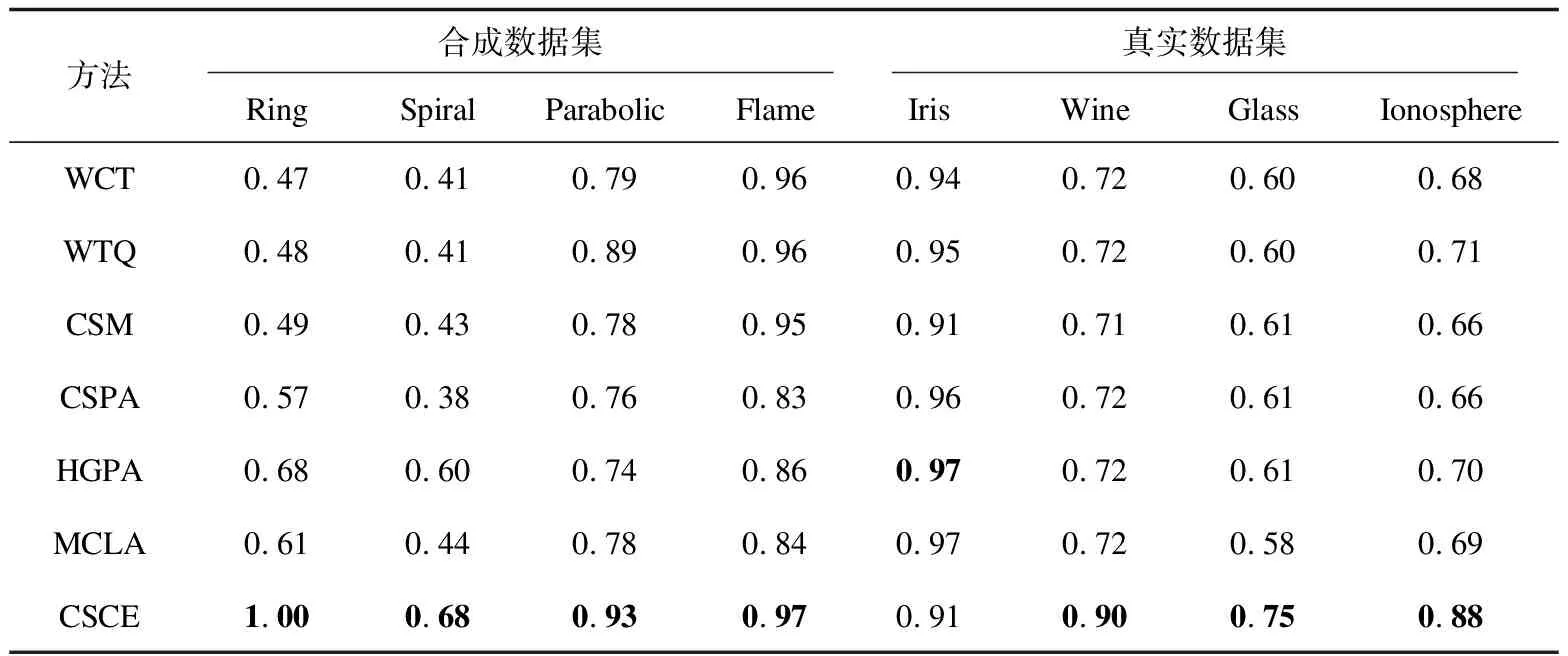
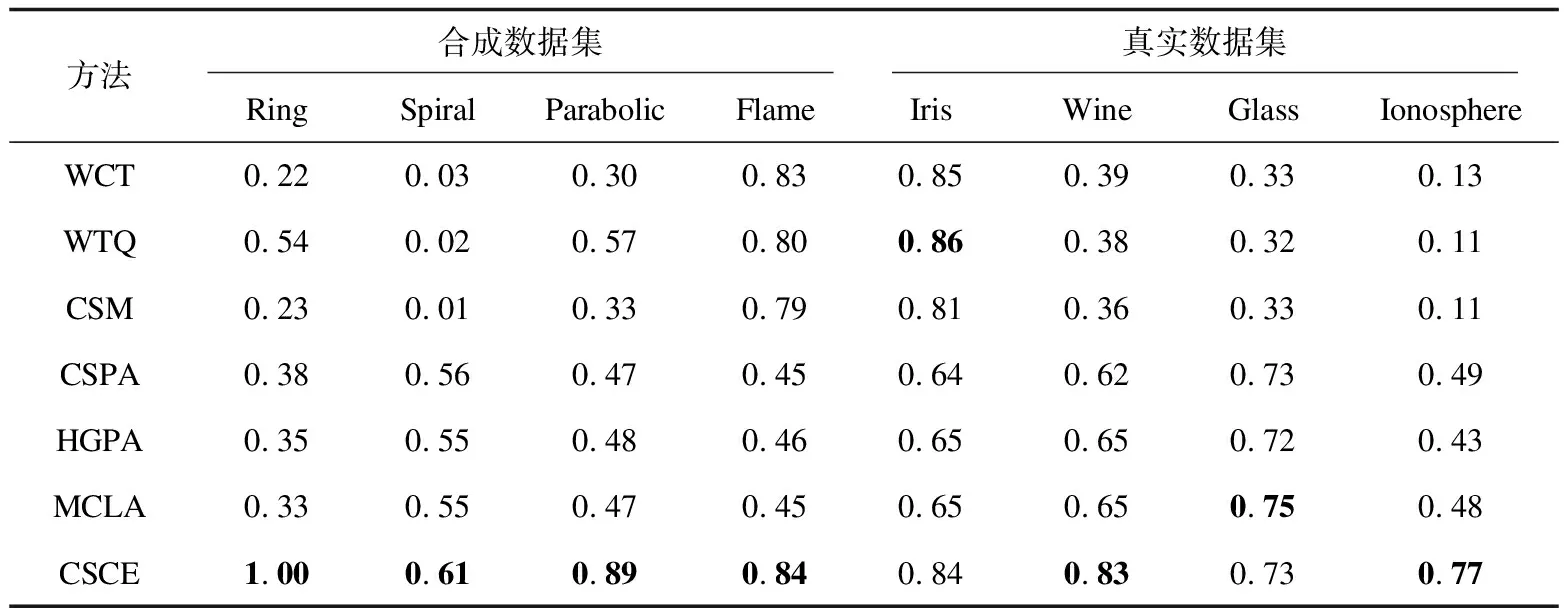
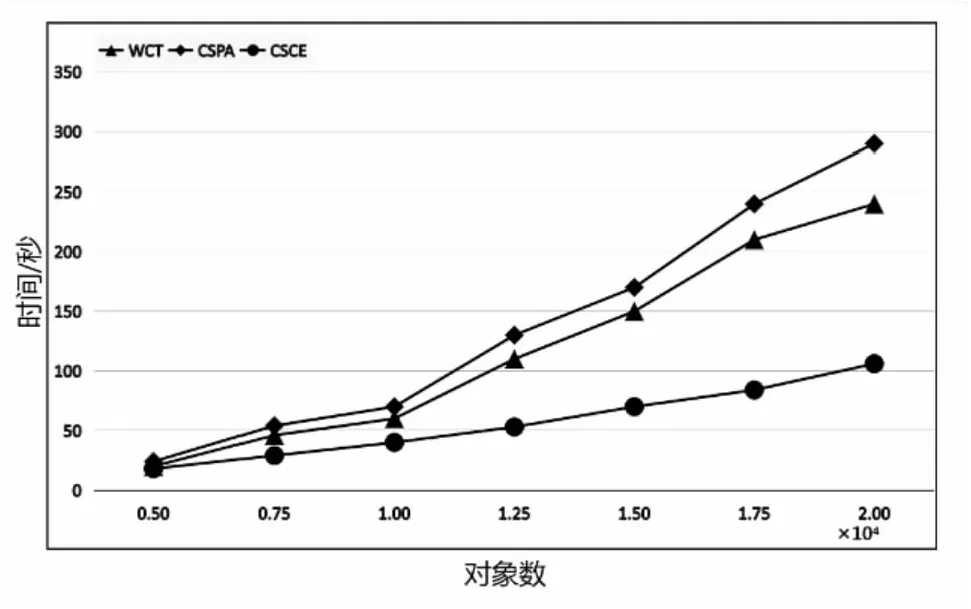
接著以圖1為例,S1={x1,x3,x4},S4={x8}。x1和x8在π6同屬一類,x3和x8在π6同屬一類,所以按公式(3)所得,S1和S4的相似度為2/(1×3×6)=1/9,其余相似度同理可得。該過程的時間復雜度為O(pqTN),qpT 該方法在8個數據集上進行了測試,其中4個是合成的數據集,4個是真實的數據集,合成數據集可從https://github.com/deric/clustering下載,真實數據集為UCI,其下載地址也在下方給出(http://www.ics.uci.edu/mlearn/MLRepository.html)。這8個數據集的詳細說明如表2所示:數據對象數(N)、維度數(D)、集群數(K)。 表2 數據集描述 采用CA和NMI來衡量聚類結果與真實數據分區之間的相似性。 (4) CA是通過計算錯誤率來衡量聚類結果的另一個外部標準。 (5) 為了正確檢驗所提算法的性能,將其與以下幾種經典的聚類集成算法進行了比較。這些比較算法的代碼是開放的和可訪問的。選擇了基于鏈接的相似性方法和基于圖的集成方法。 基于鏈路的相似性方法:由Iam On等人提出的[15]加權鏈接三元組(WCT),加權三重質量(WTQ),組合相似性度量(CSM)。 表3和表4分別展示了不同算法在8個數據集上的CA和NMI結果,每列最好的結果進行了加粗顯示。 表3 不同方法在8個不同數據集的CA結果 表4 不同方法在8個不同數據集的NMI結果 在這部分,將分析文中算法與對比算法的時間效率。選用KDD-CUP’99數據集進行本次時間效率分析,該數據集共有500萬條數據,41個特征,從中選取了一部分進行時間效率分析實驗。選用基于鏈接的聚類集成算法(WCT)、基于圖的聚類集成算法(CSPA)與CSCE進行比較,參數設置與對比實驗部分相同。不斷增加數據集,記錄不同算法的運行時間,結果如圖3所示。其中X軸為對象數量,Y軸為運行時間(s)。從實驗結果可以看出,與其他算法相比,文中算法非常有效。這表明CSCE在對大規模數據集進行聚類時有很好的效果。 圖3 不同算法的時間比較 該文提出了一種基于簇間相似性的聚類集成方法。首先,通過計算樣本相似性暫時劃分為多個小簇,然后,計算對象集之間的相似性并形成對象集的相似矩陣,最后,通過NCUT切圖的方法得到最終聚類劃分。該方法形成的相似矩陣對比傳統的共協矩陣,有效地縮減了空間復雜度,提升了聚類的性能,并能夠快速得到最終聚類結果。3 實驗結果與分析
3.1 實驗數據集
3.2 評價標準
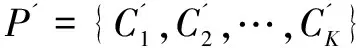
3.3 對比實驗
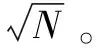
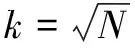
3.4 時間效率分析
4 結束語
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
