基于深度Q學習的無線傳感器網絡目標覆蓋問題算法
2023-11-24 08:28:54高思華賀懷清
吉林大學學報(理學版) 2023年6期
關鍵詞:智能
高思華,顧 晗,賀懷清,周 鋼
(1.中國民航大學 計算機科學與技術學院,天津 300300;2.吉林大學 計算機科學與技術學院,長春 130012;3.中國民航信息網絡股份有限公司 科技管理部,北京 101300)
無線傳感器網絡(wireless sensor networks,WSNs)[1]因具有部署速度快、網絡規模大、自組織性強、網絡健壯性好等特點,已廣泛應用于醫療衛生、環境保護、軍事偵查等領域.覆蓋質量和網絡生命周期是無線傳感器網絡最基本、最重要的問題.如何在滿足覆蓋要求下延長網絡生命周期被定義為無線傳感器網絡的覆蓋問題[2].按感知目標屬性不同,覆蓋問題可分為目標覆蓋、區域覆蓋和柵欄覆蓋.其中,目標覆蓋問題應用場景豐富,其求解方法主要分為整數規劃方法、基于博弈理論的方法和智能算法.文獻[3]對多感應半徑下無線傳感器網絡的目標覆蓋問題進行研究,通過列生成方法建模求解;文獻[4]通過列生成方法對無線傳感器網絡的覆蓋連通問題建模,針對列生成方法輔助問題求解速度慢的問題,設計遺傳算法進行替換,有效加快了求解速度;文獻[5]提出了關鍵目標的概念,制定優先覆蓋網絡中被較少傳感器覆蓋目標節點的策略,設計混合列生成方法進行求解,延長了網絡生命周期;文獻[6]針對視頻傳感器感知范圍受限的特征,提出了一種基于列生成方法的有向傳感器網絡目標覆蓋問題的求解方法;Shahrokhzadeh等[7]將傳感器節點視為參加博弈的節點,使用非合作博弈模型對目標覆蓋問題建模,證明博弈必然存在Nash均衡;文獻[8]通過博弈模型對有向傳感器網絡的目標覆蓋問題建模,提出節點感知方向改變策略,設計了一種減少覆蓋漏洞的分布式算法進行求解.Cardei等[9]最先利用啟發式算法對目標覆蓋問題進行研究,提出休眠調度策略,僅激活部分傳感器節點保障目標覆蓋質量,其他傳感器節點通過休眠節約能量,考慮覆蓋目標數量和傳感器節點剩余能量,通過貪心策略選擇被激活的傳感器;文獻[10]針對有向傳感器網絡的目標覆蓋問題提出主動冗余策略,要求每個目標需要被多個傳感器節點覆蓋,確保信息不會丟失,分別利用先驗進化算法和后驗進化算法調整有向傳感器節點的感應角度,在保證所有目標均被覆蓋的前提下,盡可能提高冗余覆蓋的目標數量;文獻[11]提出了一種基于分布式算法求解目標覆蓋問題的方法,假設每個傳感器節點可以獲取鄰居節點的工作狀態,幫助改變傳感器節點被選擇的概率,減少冗余現象發生,延長網絡生命周期;文獻[12]提出了興趣區(ROI)概念,將目標覆蓋問題通過二部圖轉化為匹配問題,提出了一種啟發算法和3種不同的近似優化算法,通過選擇興趣值最大的傳感器節點完成目標覆蓋任務.文獻[13]提出了一種改進的麻雀搜索算法優化無線傳感器網絡的覆蓋,通過引入佳點集改善初始化策略,避免算法的早熟現象,在麻雀搜索過程加入動態學習策略,優化算法的尋優模式;文獻[14]提出了一種基于學習自動機的節點選擇方法,該方法增加滿足能量限制條件傳感器的激活概率,降低冗余傳感器的選擇概率,通過構建更多可行解集延長網絡生命周期;文獻[15]提出了一種用遺傳算法求解有向傳感器的K-目標覆蓋問題,用每個染色體表示網絡中能構建的所有解集合,通過交叉、變異等操作逐漸優化種群,構建更多的可行解集.
整數規劃方法和基于博弈理論的方法在求解過程中忽略目標覆蓋問題的內在特征,通過設計大量限制條件尋找最優解,易出現收斂速度慢的問題.啟發式算法與目標覆蓋問題的特征緊密聯系,算法根據網絡當前狀態激活最合適的傳感器以覆蓋目標.該類算法求解速度快,但對影響無線傳感器網絡生命周期的原因分析較片面,自我學習能力不足,解的質量有待提高.進化算法解的構建較容易,進化過程可隱性揭示覆蓋問題的內在特征,但初始解的構建經常依賴貪心算法,易發生求解速度較慢、陷入局部最優等問題.
針對上述問題,本文提出一種基于深度Q學習的傳感器調度算法.首先,根據網絡中傳感器節點的能量、是否激活和目標節點的覆蓋情況3個特征描述當前網絡狀態;其次,智能體通過深度Q學習選擇激活的傳感器節點;再次,從傳感器節點覆蓋目標數量與自身能量消耗的關系設計獎勵函數,指導環境給予智能體瞬時獎勵;最后,智能體進入新的網絡狀態.該過程迭代進行,直到無法構建新的可行解集為止.智能體以獲取最大累計收益為目標,不斷學習傳感器節點調度策略,構建更多的可行解集,延長網絡生命周期.

圖1 強化學習原理示意圖Fig.1 Schematic diagram of reinforcementlearning principle
1 深度Q學習原理
強化學習是機器學習的一個重要分支.智能體(Agent)在與環境交互中學習動作策略π,獲得最大的累計獎勵值.在給定某時刻t,智能體在狀態空間S中觀測當前狀態st,在動作空間A中選擇動作at與環境互動[16].環境給予智能體獎勵rt,并遷移到新的狀態st+1.智能體根據rt逐步學習完善策略π.圖1為強化學習方法的原理示意圖.
Q學習是一種基于價值的無模型強化學習方法.通過動作-價值函數Qπ(st,at)評估在當前狀態st下,智能體根據策略π選擇動作at后可獲得累計獎勵Ut的期望值,計算公式為
Qπ(st,at)=ESt+1,At+1,…,Sn,An[Ut|St=st,At=at],
(1)
其中:Ut為折扣回報;γ∈[0,1]為折扣因子,用公式表示為
Ut=rt+γrt+1+γ2rt+2+…+γn-trn.
(2)
由式(1)可知,Qπ(st,at)依賴于策略π.假設π*為最佳策略,則Q*(st,at)為最優動作-價值函數,此時Q*(st,at)只依賴于st和at,與π不再相關,即
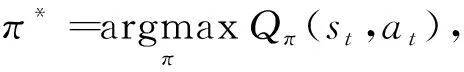
(3)
Q*(st,at)=maxQπ*(st,at).
(4)
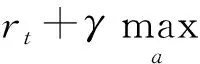
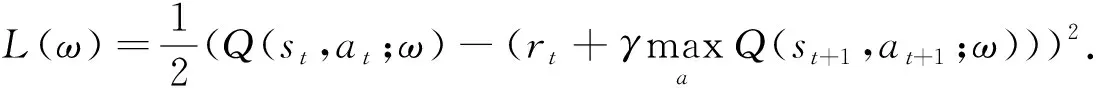
(5)
2 系統模型和問題描述
2.1 網絡模型

圖2 由5個傳感器和3個目標組成的網絡Fig.2 Network consisting of five sensors and three targets
在X×Y的二維空間內隨機部署n個傳感器節點覆蓋m個靜態目標.設P={p1,p2,…,pn}為傳感器節點集合,T={t1,t2,…,tm}為目標節點集合.本文假設網絡中傳感器具有相同的覆蓋能力和初始能量,且節點部署后位置不再發生變化.圖2為由5個傳感器和3個目標組成的網絡.
2.2 傳感器模型
本文傳感器節點的感知范圍是以傳感器為圓心、半徑為k的圓形區域.傳感器節點pi與目標節點tj的覆蓋關系采用確定性覆蓋模型[19],即pi和tj的覆蓋關系僅與雙方距離d相關.pi和tj的位置通過二維坐標表示,分別為(xi,yi)和(xj,yj).pi和tj的歐氏距離d計算公式為
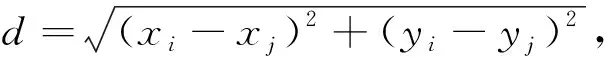
(6)
當d≤k時,本文記作pi覆蓋tj.ci記錄傳感器節點pi可覆蓋的目標集合.由圖2可見,c1={t1,t2},c2={t1,t3},c3={t2},c4={t3},c5={t3}.
2.3 能量模型
網絡中所有傳感器節點具有容量為E個單位的初始能量,其中E>1.傳感器具有兩種狀態,分別為休眠狀態和激活狀態[20].處于休眠狀態的傳感器節點不消耗能量,也無法覆蓋網絡中的目標;處于激活狀態的傳感器節點單位時間內消耗1單位能量,對其覆蓋范圍內的目標持續感知.本文假設傳感器節點在兩種狀態轉換過程中能量消耗忽略不計.傳感器節點在能量耗盡后被視為死亡節點,無法被再次激活.
本文各變量含義如下:n為傳感器節點數量,P為傳感器節點集合,pi為第i號傳感器節點,m為目標節點數量,T為目標節點集合,tj為第j號目標節點,ci為傳感器節點pi可覆蓋的目標集合,CS為可行解集的集合,csi為第i個可行解集,actx為可行解集被激活的時間,L為可行解集的總數,E為傳感器節點具有的初始能量,eix為pi節點單位時間消耗的能量.
2.4 目標覆蓋問題
定義1可行解集是P的子集,該子集可覆蓋網絡中的所有目標節點.
可行解集的集合記作CS={cs1,cs2,…,csL},任一可行解集csi應滿足以下公式:
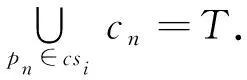
(7)
圖2中存在可行解集cs1={p1,p4},cs2={p1,p2,p3}等.
定義2可行解集中單獨覆蓋目標節點數為零的傳感器節點稱為冗余傳感器節點.
冗余傳感器覆蓋的全部目標均可由可行解集中其他傳感器節點覆蓋.如圖2所示,存在可行解集{p1,p3,p5},傳感器節點p3覆蓋的目標t2同時也被傳感器p1覆蓋.因此,傳感器p3為冗余傳感器節點.
定義3存在冗余傳感器節點的可行解集稱為冗余可行解集.
冗余可行解集會額外消耗傳感器能量,嚴重影響網絡生命周期.例如,傳感器p3所在的冗余可行解集{p1,p3,p5}激活,影響另一個可行解集{p2,p3}的激活時長,導致網絡生命周期縮短.
定義4不存在冗余傳感器節點的可行解集稱為非冗余的可行解集.
定義5無線傳感器網絡持續覆蓋所有目標節點的時間長度稱為網絡生命周期.
定義6構建并調度無線傳感器網絡中的可行解集,使得網絡生命周期最大稱為目標覆蓋問題.
目標覆蓋問題建模為
其中L表示可行解集的總數,actx表示可行解集被激活的時間,限制條件(9)表示任意傳感器節點pi在各可行解集中消耗的能量總和不超過其自身初始能量E,eix表示pi單位時間消耗的能量,限制條件(10)表示任一可行解集的工作時間非負.
定理1目標覆蓋問題得到最優解時,被激活的可行解集可全部為非冗余的可行解集.
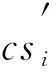
3 算法設計
本文假設每個傳感器節點單位時間能耗相同,且每個可行解集的工作時間相同.求解目標覆蓋問題的核心變為構建更多數量的可行解集.構建可行解集過程中,當前網絡狀態只與網絡的前一個狀態和激活的傳感器節點相關,具有Markov性.狀態空間無法窮舉,且依次激活休眠節點符合離散問題特征.因此,本文采用深度Q學習算法對目標覆蓋問題建模并求解.
3.1 算法建模
深度Q學習算法需要對狀態空間、智能體的動作空間和環境給予的獎勵函數進行定義.
3.1.1 狀態
無線傳感器網絡的狀態通過無線傳感器節點狀態和目標覆蓋狀態進行描述,t時刻無線傳感器網絡狀態可表示為
St={state1,state2,…,staten,{tc1,tc2,…,tcm}},
(11)
其中: {tc1,tc2,…,tcm}記錄每個目標被當前網絡激活狀態下傳感器節點覆蓋的次數;statei={ei,isActivei}記錄傳感器節點pi狀態,ei為pi的剩余能量,isActivei表示pi是否被激活,取值為
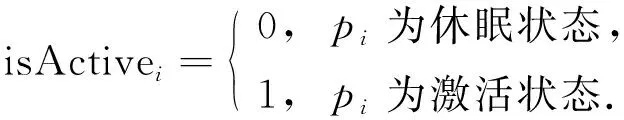
(12)
初始狀態下,網絡中各傳感器節點均處于休眠狀態.將無線傳感器網絡狀態St輸入到Q網絡中,估算出激活每個傳感器節點對應的動作價值,并基于此選擇被激活的傳感器節點pi.狀態的轉移根據此時pi的情形可分為以下4種.
1)pi處于休眠狀態,此時pi從休眠狀態轉為激活狀態,且網絡中激活的傳感器節點未構成可行解集,即?tcj=0,j∈{1,2,…,m}.St+1中更新statei和目標覆蓋情況,即statei={ei-1,1},目標覆蓋更新公式為
tcj=tcj+1, ?tj∈ci;
(13)
2)pi處于激活狀態,此時環境狀態St+1=St;
3)pi處于死亡狀態,此時環境狀態St+1=St;
4)pi處于休眠狀態,此時pi從休眠狀態轉為激活狀態,網絡中處于激活狀態的傳感器節點可構成一個可行解集;St+1首先按情形1)進行更新,然后對所有傳感器節點狀態以及目標覆蓋情況更新.
傳感器節點狀態更新公式為
statei={ei,0}, ?i∈{1,2,…,n}.
(14)
目標覆蓋更新公式為
tcj=0, ?j∈{1,2,…,m}.
(15)
3.1.2 動作
智能體的動作空間表示為A={p1,p2,…,pn}.根據當前無線傳感器網絡狀態,智能體的動作為選擇一個傳感器節點并嘗試激活.本文根據ε-greedy策略選擇出當前動作at,用公式表示為

(16)
3.1.3 獎勵
本文從傳感器節點覆蓋目標數量和自身能量消耗兩方面設計獎勵函數.由定理1可知,智能體應構建非冗余可行解集.因此,環境應對智能體有助于構建非冗余可行解集的動作給予獎勵,對導致冗余的動作進行懲罰.具體到每一個動作,傳感器節點單獨覆蓋目標數量越多,對應的獎勵越多;單獨覆蓋目標數量相同的情況下,剩余能量越多,對應的獎勵越多.冗余傳感器節點應該得到懲罰,且能量越少獲得的懲罰越多.已激活和死亡的傳感器節點沒有對構成可行解集做出貢獻,也沒有能量消耗,故設置獎勵為0.隨著訓練的進行,智能體會逐漸學習到構建更多非冗余可行解集的策略,延長網絡生命周期.因此,智能體在時刻t選擇激活傳感器節點si后的獎勵函數可表示為
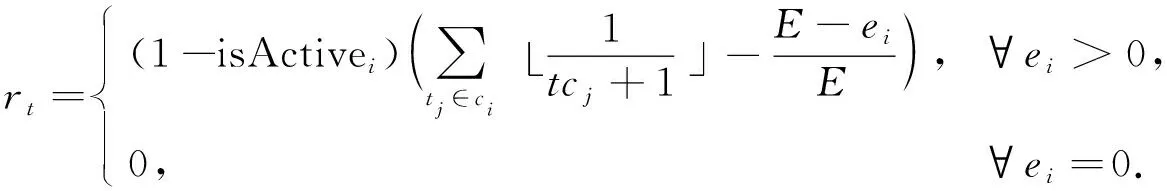
(17)
3.2 網絡結構及算法流程
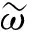

(18)
由于yt部分基于事實,因此Q(st,at;ω)應向yt靠近.本文采用均方差損失函數L(ω)訓練網絡,計算公式為

(19)
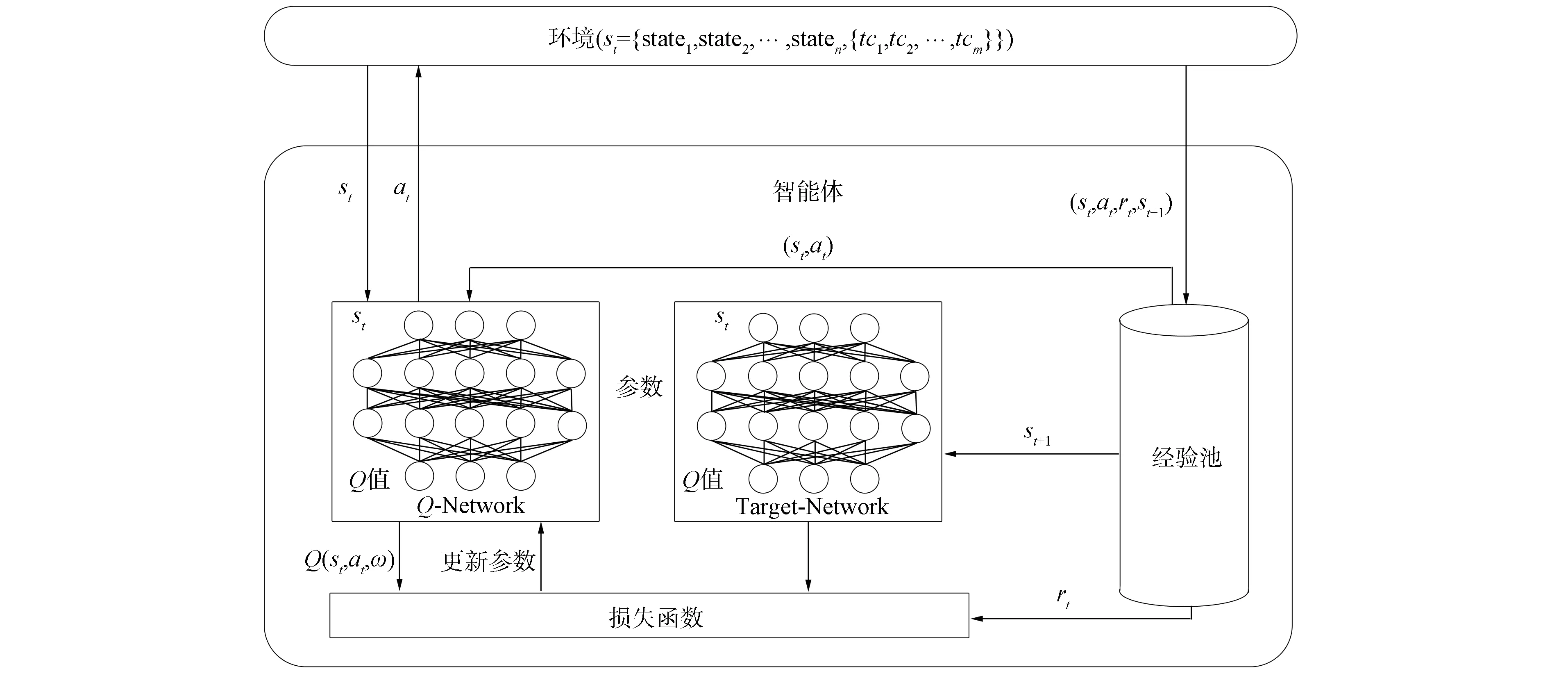
圖3 深度Q學習算法網絡結構Fig.3 Network structure of deep Q learning algorithm
算法1目標覆蓋問題的深度Q學習算法.
輸入: 訓練輪數e,同步參數間隔值C,記憶池容量M,數據提取批數b;
輸出: 累計獎勵和網絡生命周期;
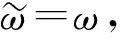
步驟2) 開始訓練循環,初始化累計獎勵和網絡生命周期為0;
步驟3) 智能體感知環境得到狀態st;
步驟4) 進入構造可行解集循環;
步驟5) 網絡根據ε-greedy策略選擇當前動作at;
步驟6) 獲得瞬時獎勵rt并更新執行動作at后的環境狀態st+1;
步驟7) 將(st,at,rt,st+1)存入記憶池;
步驟8) 更新累計獎勵;
步驟9) 根據式(18)預測動作價值;
步驟10) 隨機選取經驗池中b批數據訓練,更新Q網絡參數ω;
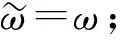
步驟12) 判斷是否能繼續構成可行解集,若無法構建,則跳出循環;
步驟13) 輸出本次得到的累計獎勵和網絡生命周期;
步驟14) 轉至步驟2)開啟下一輪訓練,直到訓練輪次達到預定數量e后停止訓練.
4 仿真實驗
將無線傳感器網絡布置在80 m×80 m的矩形區域內.在該區域內隨機部署50,100,150個傳感器節點,隨機部署10,20,30個目標節點.傳感器節點的感知半徑為10,20,30,40 m,初始能量為3單位能量.深度Q網絡共有4層,其中輸入層神經元個數與狀態維度相關,中間兩個全連接層的神經元個數分別為256個和128個,輸出層神經元個數與網絡中傳感器節點個數相同,實驗采用ReLU激活函數.經驗池中可存儲5 000條數據,每次隨機提取64批數據參與訓練.當經驗池中數據存滿后,新產生的數據會替換原有舊數據.實驗設置學習過程中的折扣因子為γ=0.9.
4.1 算法收斂性驗證
在無線傳感器網絡中隨機部署10個目標節點,感知半徑為40 m的傳感器節點50個.圖4記錄了3 000輪訓練中智能體的累計收益.由圖4可見,智能體在訓練初期選擇動作較盲目,選擇較多的冗余傳感器、已激活傳感器和死亡傳感器;隨著訓練輪數增加,智能體逐漸學習到獲取較多單步獎勵的策略,累計獎勵逐漸增加;訓練2 500輪后,智能體在每輪訓練中獲取的累計收益逐漸平穩,算法趨于收斂.
4.2 與其他目標覆蓋算法的對比
在無線傳感器網絡中隨機部署10,20,30個目標節點,感知半徑為40 m的傳感器節點50,100,150個.用本文提出的深度Q學習算法、3種貪心策略算法(Greedy1采取的策略為每次選擇覆蓋目標數量最多的傳感器節點;Greedy2算法采取的策略為選擇剩余能量最高的傳感器節點;Greedy3算法采取的策略為選擇覆蓋最多未被覆蓋目標的傳感器節點)、最大壽命目標覆蓋率算法(MLTC)[21]和自適應學習自動機算法(ALAA)[14]分別計算網絡生命周期,實驗結果如圖5~圖7所示.由圖5~圖7可見: Greedy1算法和Greedy2算法在傳感器數量少的情況下,網絡生命周期與其他算法相差很小,當傳感器數量增加,覆蓋情況復雜后,兩種算法效果均不佳;Greedy3算法、MLTC算法和ALAA算法結果較好,但在不同網絡環境下穩定性有待提高;深度Q學習算法的結果優于其他幾種算法,取得了較長的網絡生命周期.同時,實驗結果表明,網絡生命周期與傳感器節點數量呈正相關.
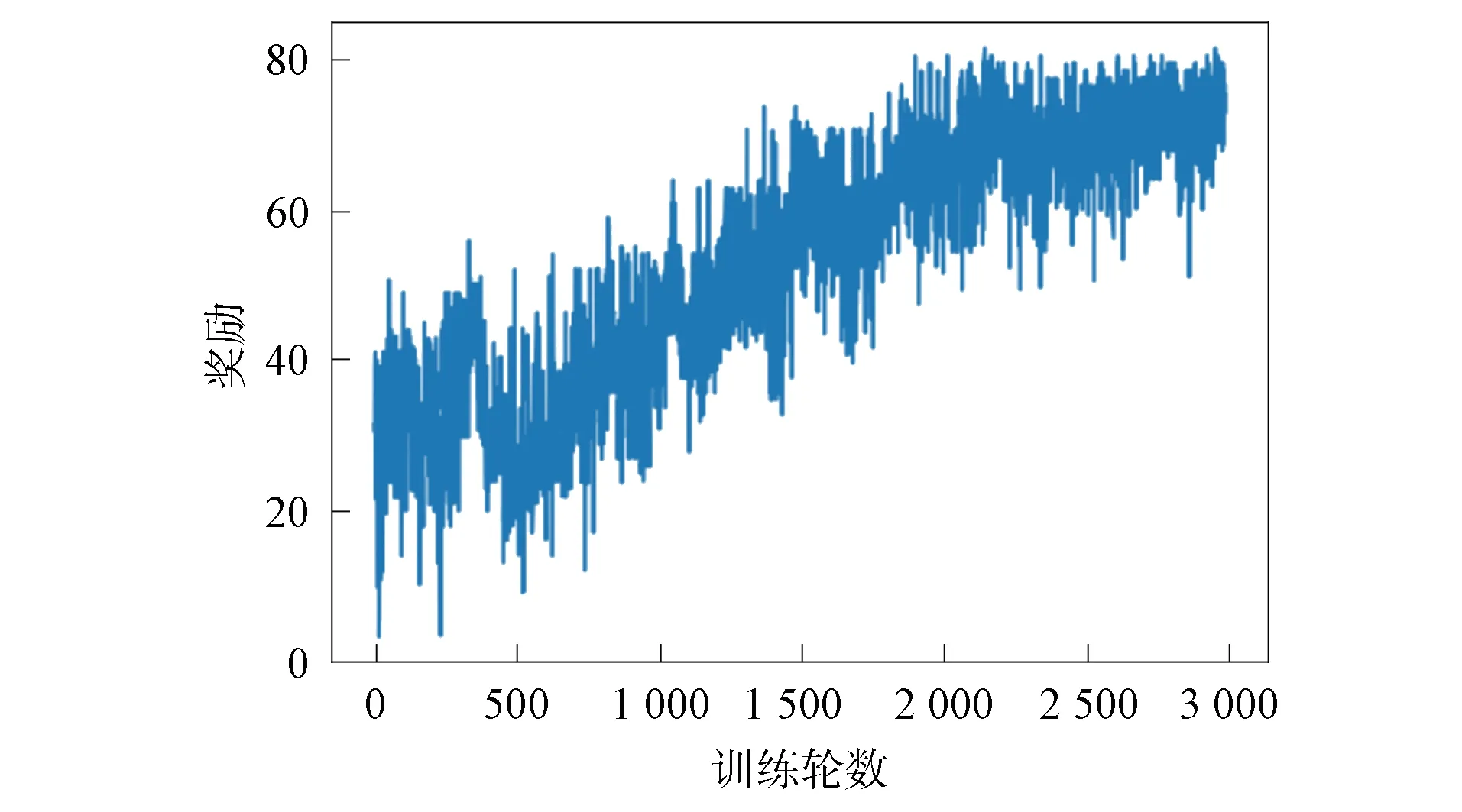
圖4 獎勵收斂曲線Fig.4 Convergence curves of rewards
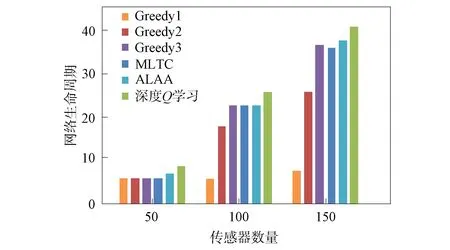
圖5 不同算法目標數為10的網絡生命周期對比Fig.5 Comparison of network lifecycles with targetnumber of 10 for different algorithms
4.3 傳感器節點感應半徑對網絡生命周期的影響
在無線傳感器網絡中隨機部署100個傳感器節點和40個目標節點,傳感器節點的感知半徑分別為10,20,30,40 m.利用上述各算法分別計算網絡生命周期,實驗結果如圖8所示.由圖8可見,當感應半徑為10 m時,網絡中各傳感器節點覆蓋的目標數量少,各算法計算的網絡生命周期近似.隨著感應半徑的增加,每個傳感器節點覆蓋的目標數量增加,每個目標節點可以被更多傳感器節點覆蓋.因此,雖然各算法計算的網絡生命周期存在差異,但均顯示網絡生命周期與傳感器的感知半徑呈正相關.
4.4 傳感器節點初始能量對網絡生命周期的影響
在無線傳感器網絡中布置100個傳感器節點,同時布置20個目標節點,傳感器節點感應半徑固定為30 m,攜帶的初始能量從3單位能量開始逐級提高至12單位能量,仿真實驗結果如圖9所示.由圖9可見,當傳感器攜帶能量較少時,各算法網絡生命周期均較短.隨著攜帶能量的提高,其網絡生命周期對應延長.因此,實驗表明網絡生命周期與傳感器初始能量呈正相關.

圖6 不同算法目標數為20的網絡生命周期對比Fig.6 Comparison of network lifecycles with targetnumber of 20 for different algorithms
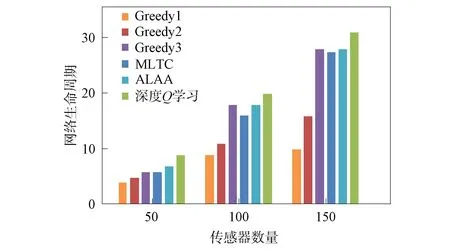
圖7 不同算法目標數為30的網絡生命周期對比Fig.7 Comparison of network lifecycles with targetnumber of 30 for different algorithms
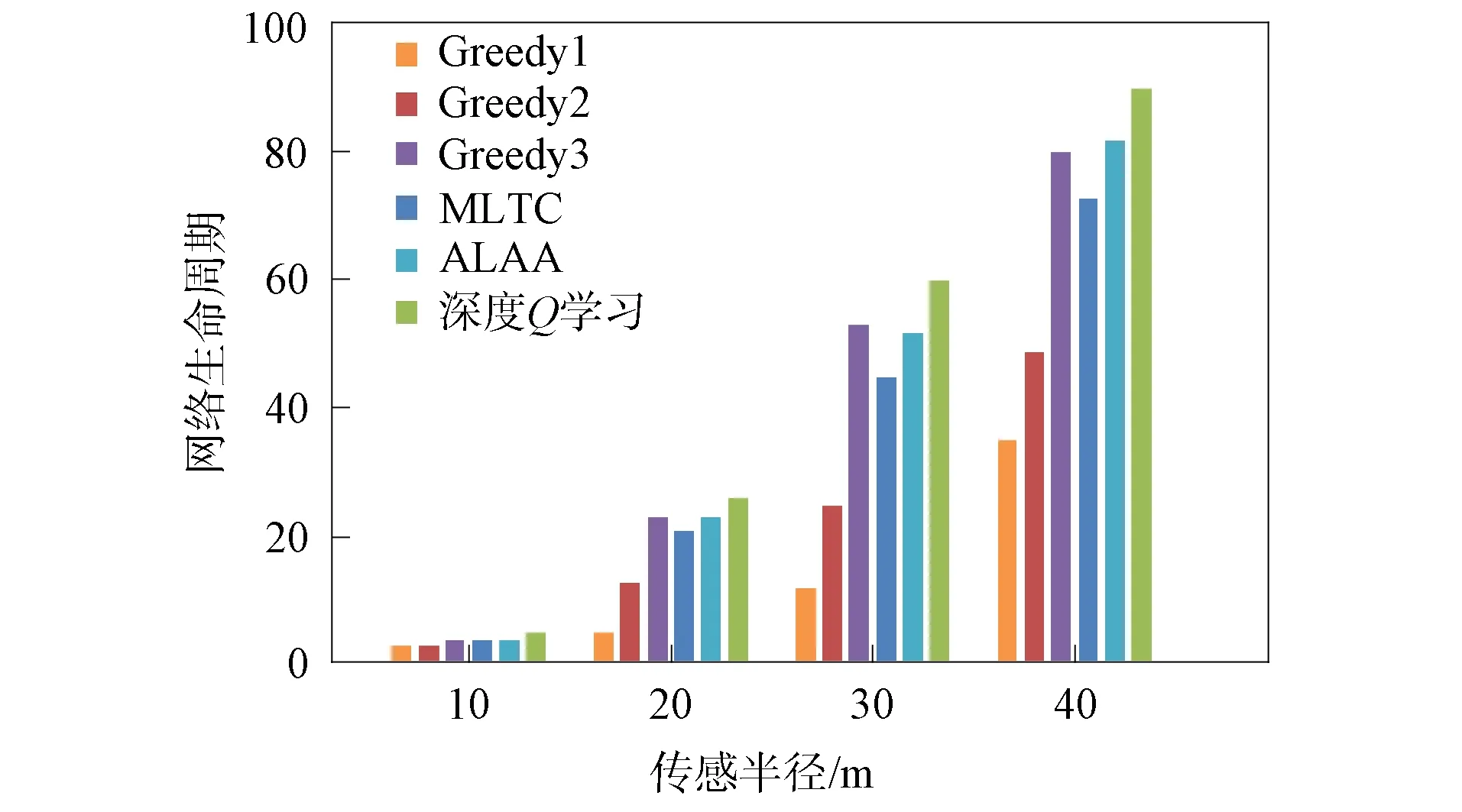
圖8 各算法對不同傳感半徑的網絡生命周期的影響Fig.8 Effect of each algorithm on network lifecyclewith different sensing radii

圖9 各算法對不同初始能量的網絡生命周期的影響Fig.9 Effect of each algorithm on network lifecyclewith different initial energies
綜上所述,針對求解無線傳感器網絡目標覆蓋問題過程中存在的節點激活策略機理不明確、可行解集存在冗余等問題,本文提出了一種基于深度Q學習的目標覆蓋算法對無線傳感器網絡目標覆蓋問題進行建模并求解.首先,用傳感器節點的能量、是否激活和目標覆蓋情況描述網絡狀態;其次,將智能體的動作作為網絡中待激活的傳感器節點;最后用智能體的獎勵綜合考慮傳感器節點覆蓋目標數量與自身能量消耗.通過訓練,智能體學習調度網絡中傳感器節點的策略,可減少冗余現象發生,增加可行解集的數量.仿真實驗結果表明,本文算法可合理調度傳感器節點,延長網絡生命周期.
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學科學(學生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
