基于詞向量模型的漏洞檢測方法
2023-11-24 08:29:50胡景浩侯正章
吉林大學學報(理學版) 2023年6期
肖 巍,胡景浩,侯正章,王 濤,潘 超
(1.長春工業大學 計算機科學與工程學院,長春 130012;2.吉林大學 軟件學院,長春 130012)
在萬物互聯的時代,網絡安全問題備受關注.目前最常見和影響力最大的網絡安全問題均由軟件漏洞引起[1].軟件漏洞不僅容易被發現、被利用,而且能讓非法入侵者竊取數據或阻止應用程序正常運行,常導致巨大的經濟損失,嚴重危害了網絡安全,如瀏覽器插件中的漏洞,威脅著數百萬互聯網用戶的安全和隱私.為解決軟件漏洞問題,研究人員提出了許多方法,包括靜態分析、動態分析和混合分析.靜態分析是指對于給定程序的源代碼進行分析,如基于規則/模板的分析、符號執行和代碼相似性檢測,主要依賴于對源代碼的分析;動態分析是指通過使用特定輸入數據執行給定程序并監視其運行時的行為對其進行分析,如模糊測試和污點分析;混合分析是指將靜態分析和動態分析技術相結合,對給定的程序進行分析.
機器學習和數據挖掘技術的進步以及它們在解決復雜應用問題上的成功案例,促使研究人員開始考慮如何有效地利用這些技術進一步解決計算機安全問題.目前已有許多研究利用數據挖掘和機器學習技術自動提取漏洞代碼段的特征和模式,通過模式匹配技術發現軟件漏洞[2].Yamaguchi等[3]將函數構建成AST(abstract syntax tree),利用詞袋技術將其映射到向量空間后,通過語義分析檢測軟件漏洞;Pang等[4]采用N-gram語法分析和統計特征選擇相結合的方式預測漏洞軟件;Grieco等[5]提出綜合使用N-gram和Word2vec模型對代碼進行向量表示,利用隨機森林等多種機器學習算法進行漏洞檢測.
近年來,神經網絡模型在漏洞檢測方面的應用也越來越廣泛.Russell等[6]使用Word2vec做為詞向量模型,通過卷積神經網絡結合隨機森林的方法檢測代碼漏洞,獲得了很好的實驗效果;Li等[7]提出的VulDeePecker系統在SARD(software assurance reference dataset)數據集上使用Word2vec詞向量模型作為神經網絡的輸入,檢測切片級C/C++代碼漏洞,通過SySeVR框架對代碼的語法和語義進行表征,提高了漏洞檢測的準確性;Lin等[8]通過在手動標記的漏洞數據集上進行實驗,將代碼序列化為抽象語法樹,經過Word2vec模型輸入到以雙向長短期記憶網絡為基本框架的神經網絡模型中檢測漏洞,與傳統方式相比,漏洞檢測效果更顯著.
在漏洞檢測領域,目前研究者大多數在自己收集的數據集或SARD上進行研究和測試.數據集與實驗環境的不同,會導致無法準確衡量算法的優劣.多數漏洞檢測的研究是通過在同一種詞向量模型上應用不同的神經網絡提高準確率,而對于多種詞向量模型,哪種詞向量模型與神經網絡相結合能更有效地檢測漏洞還沒有準確結論.
本文通過在同一數據集同一實驗環境中對不同的詞向量模型結合不同的神經網絡進行實驗,分析得出最適用于漏洞檢測的詞向量模型和神經網絡模型.本文的貢獻主要有以下三方面:
1) 本文在同一數據集上對數據進行預處理,先采用不同的詞向量進行轉化,再結合不同的神經網絡進行實驗,通過比較統一平臺、統一框架下產生的不同實驗結果,分析出代碼漏洞的特點;
2) 本文在C/C++函數漏洞數據集上使用Word2vec,Fasttext,GloVe(global vectors for word representation),ELMo(embeddings from language models)和BERT(bidirectional encoder representation from transformers)詞向量模型,對源代碼生成的抽象語法樹結構進行知識表示,由于不同模型生成的詞向量對代碼的語義和語法關系表征不同,漏洞檢測結果不同,分析出適用于漏洞檢測的詞向量模型;
3) 本文使用主流神經網絡模型對代碼漏洞進行檢測,如DNN(deep neural networks),GRU(gate recurrent unit),LSTM(long short-term memory),Bi-GRU(bidirectional gated recurrent unit),Bi-LSTM(bidirectional long short-term memory)和Text-CNN(convolutional neural networks for text classification),不同網絡結構的神經網絡模型對漏洞檢測效果不同,根據實驗結果分析出適用于漏洞檢測的神經網絡模型.
1 詞向量模型的基本原理
1.1 Word2vec模型
NNLM(neural network language model)[9]以前饋神經網絡模型為基礎,使用低維緊湊的詞向量對上下文進行表示,解決了詞袋模型產生的數據稀疏和語義鴻溝等問題.RNNLM(recurrent neural network language model)[10]在NNLM的基礎上將上一輪計算狀態應用到新一輪計算中,不再計算相同的詞表征,從而提高了模型的時間效率.CBOW(continuous bag-of-words)模型[11]采用先求和再求平均的計算方法,在降低向量維度和減少參數數量的同時采用線性分類,從而提高了模型效率.CBOW模型的輸入是中心詞的上下文,輸出是預測的中心詞.Skip-gram模型[11]是在已知當前詞的情況下去預測上下文.由于序列化數據的局部信息具有關聯性,Word2vec模型將自然語言中的詞一一映射為長度相等的詞向量.使用該模型能分析出前后文的語義和語法關系,因此其廣泛應用于自然語言處理的情感分析[12]、文本分類[13]和關系抽取[14]任務中.
1.2 Fasttext模型
基于CBOW模型的文本分類模型Fasttext[15]與CBOW模型結構基本一致,不同的是輸出結果為輸入文本對應的類型標記.該模型利用子詞N-gram信息,獲得字符之間的順序關系,以便更好地捕捉單詞內部的語義信息,特別是在處理大數據時,能更準確地對生僻詞和詞的變形進行向量表示.Fasttext在保持分類效果的前提下,采用線性分類并在輸出層使用層次Softmax和負采樣技術,加快了訓練速度,縮短了訓練時間,常應用于情感分析[16]、攔截垃圾郵件[17]和文檔語言識別等方面.
1.3 GloVe模型
詞向量生成模型GloVe[18]通過構建單詞上下文的共現矩陣,計算詞間的共現比率,再建立詞與共現比率之間的映射關系,得到GloVe的模型函數,用加權平方差作為損失函數,通過AdaGrad優化算法學習生成詞向量.GloVe模型廣泛應用于命名實體識別[19]、情感分類[20]和區別相似詞[21]等問題中.
1.4 ELMo模型
基于Bi-LSTM的語言模型ELMo[22]包含前向語言模型和后向語言模型.前向語言模型根據前面的詞匯預測當前詞的概率,后向語言模型根據后面的詞匯預測當前詞的概率,通過最大化前向和后向語言模型的對數概率得到當前詞的預測概率.該模型包含兩層Bi-LSTM,第一層主要嵌入詞的語法結構信息,第二層主要嵌入句子的語義信息.ELMo能根據不同的上下文場景生成不同的詞向量,有效解決了一詞多義的問題.ELMo模型在情感分析[23]、命名實體識別[24]及文本分類[25]等方面性能優異.
1.5 BERT模型
BERT模型[26]是由MLM(MASKed language model)和NSP(next sentence prediction)構成的深度雙向Transformer語言模型.MLM以15%的概率用[MASK]隨機對訓練序列中的標記進行替換,其中80%的標記被替換為[MASK],10%的標記被隨機替換,10%的標記保持不變,根據所給的標記學習被替換的詞.NSP是一個二分類任務,主要判斷兩個語句中的其中一條語句是否是另一條語句的下一句.訓練數據中50%的數據從真實的上下文中抽取,剩余的50%數據從語料庫中隨機選擇用于加深學習其中的相關性.MLM能抽取標記層次的表征,但不能直接獲取句子層次的表征,NSP能幫助理解句子間的關系進行預測.因此BERT模型在解決句子或段落的匹配、句間關系、理解深層語義特征等任務中效果顯著,如知識圖譜補全[27]、問答任務[28]、閱讀理解[29-30]、文本分類[31]和關系抽取[32]等.
表1列出了各詞向量模型的特點及其在漏洞檢測方面的應用程度.

表1 各詞向量模型的特點及其應用程度
2 詞向量模型在漏洞檢測上的應用
詞向量模型在各自然語言處理任務中均有不同程度的應用,效果也較好.在漏洞檢測方面,Word2vec作為早期的詞向量模型被廣泛應用,Fasttext和BERT模型應用較少,GloVe和ELMo模型尚未發現應用于漏洞檢測方面.
2.1 Word2vec模型在漏洞檢測上的應用
Word2vec模型將源代碼轉化為向量作為神經網絡的輸入,由于生成的詞向量維數少、速度快、通用性強被廣泛應用于漏洞檢測中.
Russell等[6]使用Word2vec詞向量模型,將CNN(convolutional neural networks)結合RF(random forest)實現代碼漏洞檢測.實驗結果表明,將源代碼通過神經網絡訓練生成的特征向量作為隨機森林分類器的輸入比單獨使用神經網絡在漏洞檢測上的效果更好,在準確率、精確率及F1值上均有約2%~3%的提升.Fidalgo等[33]使用Word2vec模型對PHP語言的代碼進行向量表示,應用LSTM進行代碼漏洞預測.LSTM模型有助于理解代碼之間的語法和語義信息,可更好地處理序列化的文本信息,準確率和召回率均達95%以上.文獻[7-8,34-38]采用Word2vec作為詞向量模型,將C/C++語言的源代碼轉換為向量,使用不同的神經網絡模型進行漏洞檢測.其中,Zou等[34]提出了多類別的深度學習漏洞檢測系統,同時提供了用于測評漏洞系統的標準檢測數據集.文獻[7-8,35-36]分別采用抽象語法樹、最小中間表征以及代碼段表征等技術對源代碼進行預處理,通過Bi-LSTM捕捉上下文語義關系檢測漏洞,實驗結果的準確率均有不同程度提升.Li等[37]為更好地學習漏洞特征采用了Bi-GRU代替Bi-LSTM,比其他神經網絡模型更有效.Xu等[38]提出了使用基于上下文的長短期記憶神經網絡模型對源代碼進行漏洞檢測,該模型性能比CNN和LSTM模型更好,準確率可達96.71%,F1值最高為97%.
Zhou等[39]提出了基于圖神經網絡的漏洞檢測模型.該模型將源代碼轉換為抽象語法樹,結合不同層次間的程序控制和數據依賴關系,形成具有全面程序語義結構的聯合圖.通過Word2vec對代碼進行編碼,采用Bi-GRU模型學習節點嵌入.該模型檢測漏洞的準確率提高10.51%,F1值提高8.68%.
2.2 Fasttext模型在漏洞檢測上的應用
Alenezi等[40]通過Fasttext模型訓練后得到詞向量,采用DNN模型從輸入向量中學習更深層的隱藏特征并進行漏洞檢測.實驗結果表明,該方法的效果及性能較好,在不同的數據集上,最好實驗結果達到準確率98.6%,召回率98.6%,F1值為98.55%.
Fasttext模型與Word2vec模型相比,更注重詞語內部的形態,有助于模型對低頻詞和集外詞更好地表示.由于Fasttext模型需要提取子詞與詞本身的特征,因此隨著語料庫的增加,內存需求也不斷增加,嚴重影響了模型的構建速度,從而限制了Fasttext模型在漏洞檢測問題上的應用.
2.3 BERT模型在漏洞檢測上的應用
Ziems等[41]采用SARD作為數據集,通過BERT模型使代碼具有更深層的語義表征,分別使用了LSTM和Bi-LSTM神經網絡進行訓練,實驗準確率為93%.實驗結果顯示,Bi-LSTM模型的準確率并沒有在LSTM模型的基礎上有所提升.原因在于BERT是基于雙向Transformer的結構,多一層雙向機制并不能提取更有益的信息.目前BERT模型在漏洞檢測方面的應用較少.
3 實驗設計
本文使用手動收集的真實漏洞數據集進行實驗,主要包括4個階段: 1) 數據預處理;2) 利用CodeSensor解析器提取源代碼的語法和語義信息,生成對應的抽象語法樹;3) 通過預訓練的詞向量模型將序列化的抽象語法樹向量化;4) 使用神經網絡對漏洞表征進行學習,檢測漏洞函數.實驗設計的整體框架如圖1所示.
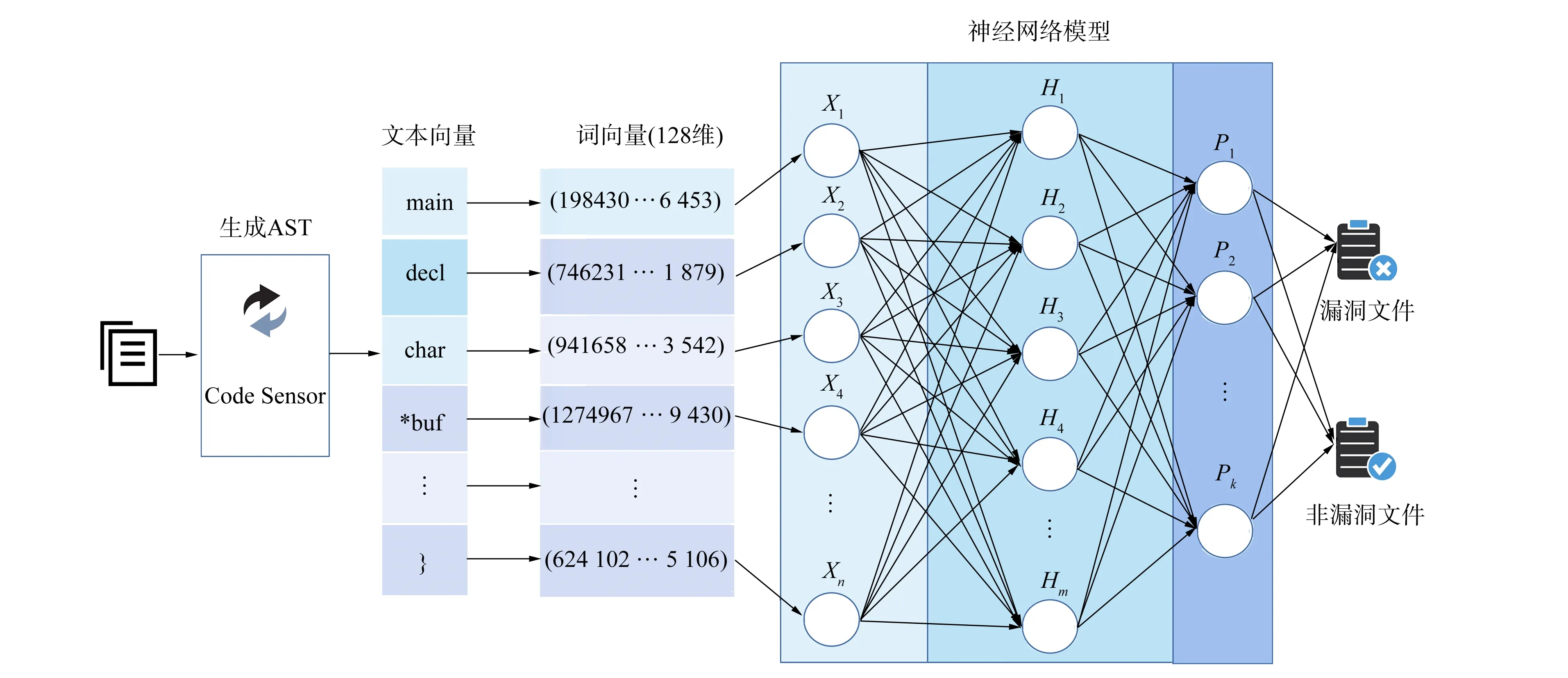
圖1 漏洞檢測整體框架Fig.1 Overall framework of vulnerability detection

圖2 示例代碼Fig.2 Example code

圖3 代碼的抽象語法樹Fig.3 Abstract syntax tree of code
3.1 數據預處理
本文將數據集按6∶2∶2的比例劃分為訓練集、驗證集和測試集.為從數據中去除不必要的噪聲,刪除了函數中所有的注釋與常見的停用詞,如空格、換行和制表符等.
3.2 生成抽象語法樹
抽象語法樹是常見的代碼表征方式,用于代碼基本結構和語法語義的中間表示.本文將如圖2所示的源代碼輸入到CodeSensor解析器中,經過解析輸出如圖3所示對應的抽象語法樹.代碼被解析為函數聲明、代碼塊、語句等不同類型的節點,其中內部節點表示運算符及節點類型,葉節點表示操作符,有向邊表示節點間的層次關系.
3.3 向量化
考慮到樹的層次結構,本文使用深度優先遍歷算法將抽象語法樹中的節點用文本向量的形式進行表示,向量中元素的順序反映了抽象語法樹中節點的層次關系,圖3的抽象語法樹轉換為文本向量如下: (main,decl,char,*buf,assign,buf,=,express,(char*),call,malloc,arg,BUFSIZE,if,pred,call,…).
將所得的文本向量通過詞向量模型生成128維向量,作為神經網絡模型的輸入.詞向量轉換過程中,本文分別使用Word2vec,Fasttext,GloVe,ELMo和BERT詞向量模型進行實驗,以檢驗哪種詞向量模型更適用于漏洞檢測.
3.4 訓練及測試
本文分別使用DNN,GRU,LSTM,Bi-GRU,Bi-LSTM和Text-CNN神經網絡模型對數據進行訓練,根據訓練后的模型結果不斷調整迭代次數、學習率、損失函數和激活函數等參數,保留效果最好的模型進行測試.在相同實驗條件下,將各詞向量模型結合神經網絡模型對真實數據集中的數據進行漏洞檢測,以獲得實驗效果最好的詞向量模型和神經網絡模型.
4 實 驗
4.1 數據集
采用文獻[42]提供的數據集,該數據集是從NVD網站中手動收集的C語言函數,共包含9個開源項目: Asterisk,FFmpeg,HTTPD,LibPNG,LibTIFF,OpenSSL,Pidgin,VLC Player和Xen.收集函數數據60 768個,其中漏洞函數1 471個,非漏洞函數59 297個.本文已將漏洞數據集和源代碼開源到GitHub(https://github.com/ithicker/MWEMVD)上.為能獲得準確的檢測結果,保證數據的均衡性,將9個項目均以6∶2∶2的比例劃分為訓練集、驗證集和測試集.
4.2 實驗環境及參數配置
實驗在Ubuntu Linux系統上運行,硬件配置為處理器IntelXeon(R) Silver 4210 2.2 GHz,內存78 GB,GPU Quadro P2200,硬盤1.3 TB.軟件分別使用Keras 2.2.4,TensorFlow 1.12.0,Keras 2.3.1和TensorFlow 1.15.0.詞向量模型及配置環境列于表2.

表2 詞向量模型及配置環境
4.3 結果處理
為能準確地衡量神經網絡模型在漏洞檢測上的效果,實驗以精確度和召回率為評估指標.精確度是指正確預測為漏洞的函數占全部預測正確函數(漏洞函數和非漏洞函數之和)的比例;召回率是指正確預測為漏洞的函數占全部漏洞函數的比例.由數據集特征可見,漏洞函數和非漏洞函數占比不均衡,非漏洞函數數量遠多于漏洞函數數量,從而導致無法準確判斷.為解決該問題,本文對神經網絡模型輸出結果的權重(預測為漏洞函數的可能性)從高到低排序,求取前k個值(Top-k)計算精確度和召回率,精確度和召回率公式表示如下:
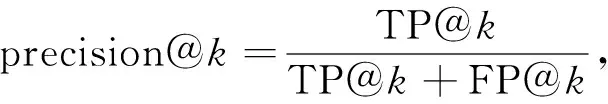
(1)
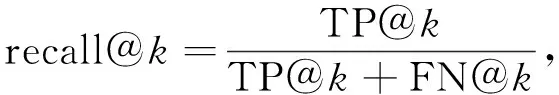
(2)
其中TP@k表示檢測前k個函數正確預測為漏洞的函數數量,FP@k表示檢測前k個函數錯誤預測為漏洞的函數數量,FN@k表示檢測前k個函數未被預測為漏洞的函數數量.
4.4 結果分析
對于高級程序設計語言,代碼漏洞通常是由于多行代碼間存在的邏輯關系產生的問題,漏洞代碼段與前文或后文的代碼有關,因此上下文信息對代碼漏洞檢測十分重要.函數級別的代碼通常由多個if-else條件分支語句及for和while等循環語句構成,但條件分支語句和循環語句代碼塊相對獨立,代碼塊內的語句相互之間存在上下文語義關系,而代碼塊與代碼塊之間雖有關聯但并不緊密.表3列出了實驗結果.
從詞向量方面分析表3的實驗結果得出如下結論: Word2vec模型能表征淺層語義關系,通過滑動窗口處理代碼段能抓住程序的局部特征,應用于漏洞檢測總體效果相對較好;Fasttext模型在RNN上實驗效果與Word2vec模型相近,其原因在于兩個模型的原理相似,Fasttext模型更注重單詞內部的形式,而代碼更注重單詞之間的語義關系,因此在DNN與Text-CNN上的實驗效果不如Word2vec模型;Glove模型通過共現矩陣統計單詞共現比率計算詞向量,不僅增加了模型的計算量,且易誤導詞向量的整體訓練方向,因此整體效果較差;ELMo模型在循環神經網絡中實驗效果差異較小,歸因于ELMo是以Bi-LSTM構建生成的詞向量模型,雙層循環神經網絡對漏洞檢測并無太大影響.Word2vec,Fasttext,Glove和ELMo模型在Text-CNN神經網絡上漏洞檢測效果最好.BERT模型能通過上下文抽取代碼特征,在循環神經網絡上實驗效果較好,由于BERT是雙向Transformer模型,因此其實驗結果在LSTM和Bi-LSTM神經網絡上無明顯差異,這種現象與文獻[41]中分析得到的結論相符.由于BERT模型適用于處理長距離依賴關系的文本,而漏洞檢測需要處理短距離文本代碼塊,因此實驗效果并非最好.
從神經網絡方面分析表3的實驗結果得出如下結論: 循環神經網絡模型能捕捉代碼之間的依賴關系,因此在代碼漏洞檢測方面效果好于DNN模型,但由于代碼之間并沒有長距離的上下文依賴關系,因此使用循環神經網絡并未能取得最好的實驗效果;Text-CNN模型通過卷積層的局部窗口學習代碼的局部特征,通過池化層將各代碼塊的局部特征整合形成復雜抽象的特征,使模型更注重代碼塊內的關系,而不過分關注代碼塊間的聯系,因此Text-CNN模型在神經網絡中效果最佳.
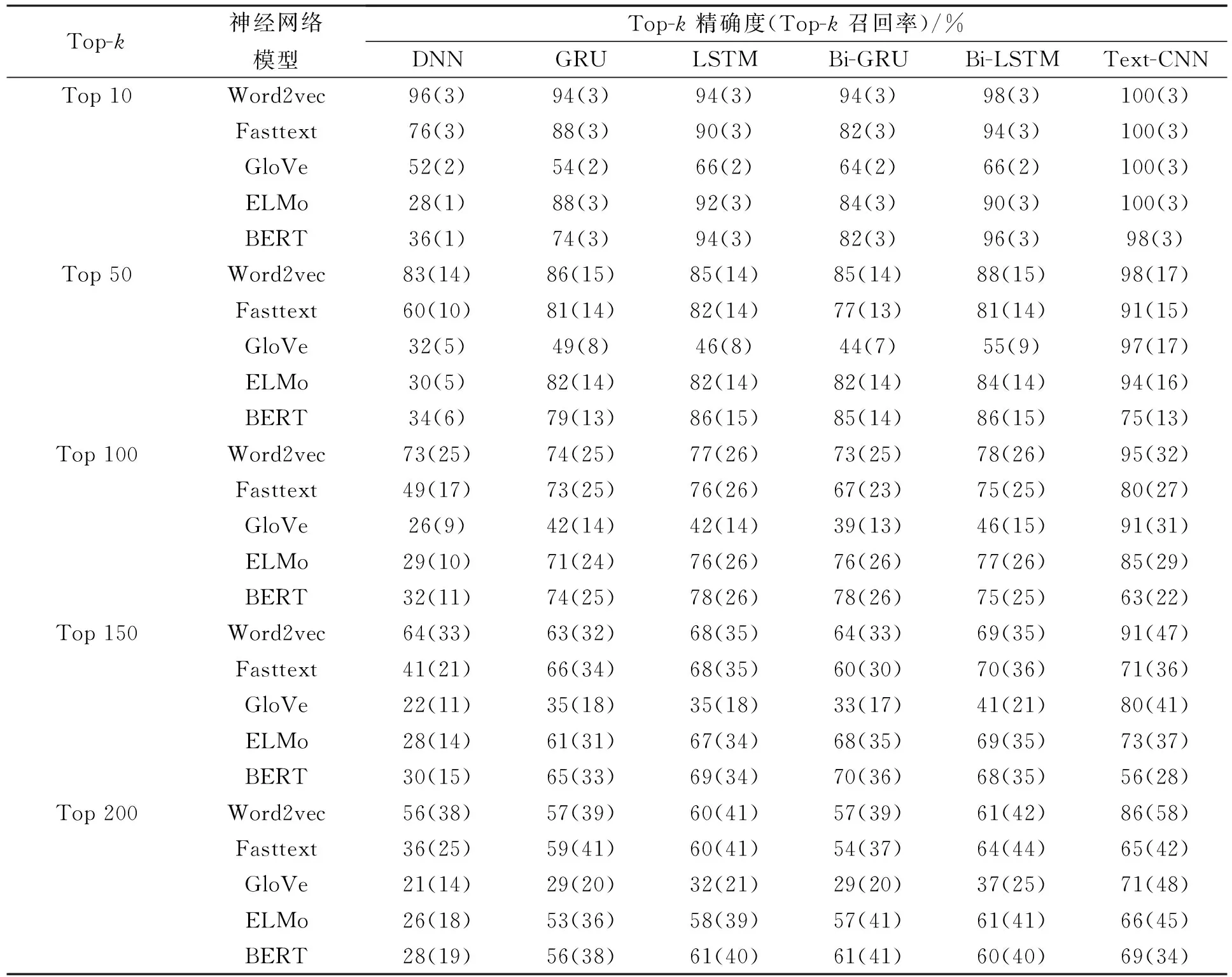
表3 實驗結果
根據漏洞代碼的特點及實驗結果綜合分析可知,使用Word2vec作為詞向量模型并結合Text-CNN模型檢測代碼漏洞的效果最好.
綜上所述,本文在介紹了各詞向量模型的基本原理和詞向量模型在漏洞檢測方面的應用后,將各詞向量模型結合神經網絡模型在相同實驗條件下進行了漏洞檢測,并分析了實驗結果.對于函數級別的漏洞,代碼之間存在著上下文關聯而代碼塊之間的聯系并不緊密,因此代碼之間屬于淺層的語義關系.在5個詞向量模型中,Word2vec模型具有簡單的模型結構,對于描述淺層的語義關系效果相對較好;在6個神經網絡模型中,Text-CNN模型對文本淺層特征的抽取能力強.實驗結果表明,Word2vec詞向量模型結合Text-CNN神經網絡檢測代碼漏洞的效果最佳.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
